
1 июня 2022 года вышла статья Янниса Дараса и Александроса Димакиса из Техасского университета в Остине, названная «Открытие скрытого словарного запаса DALLE-2» (Discovering the Hidden Vocabulary of DALLE-2). Она произвела небольшой фурор в сети, заполнившейся заголовками «нейросеть создала свой язык!» — но, увы, не вполне заслуженно.
Для начала — пару слов о том, что из себя представляют генераторы изображений серии DALL-E вообще, и DALLE-2 в частности. Точнее, DALL·E 2 (через точку и пробел). Так называется выпущенная в начале апреля в ограниченный доступ — нейросеть, позволяющая генерировать изображения по запросам на английском языке. Как и первую DALL·E, её создала американская компания OpenAI, связанная с Илоном Маском и занимающаяся разработками в сфере нейросетей и самообучающегося искусственного интеллекта.

DALL·E первой версии вышла в январе 2021 года. Она была основана на разработанном OpenAI годом ранее GPT-3: третьем поколении алгоритма обработки естественного языка, а именно, английского, считавшемся к сентябрю 2020 года «самой крупной и продвинутой языковой моделью в мире».
Для обучения этой нейросети на суперкомпьютере Microsoft Azure AI «скормили» более 600 Гб текстов, включая англоязычную «Википедию» целиком, книги и стихи вагонами, статьи из медиа, GitHub, путеводители и рецепты, и даже «откровения» конспирологов про заговоры рептилоидов .
В результате GPT-3 научилась генерировать весьма внятные и сложные тексты, которые далеко не всегда можно было отличить от написанных человеком. Она находилась в закрытом доступе по заявкам — но с примерно аналогичным функционалом можно ознакомиться на русскоязычной текстовой нейросети ruGPT-3 от Sber AI . Только осторожно: сочетание реалистичности и внятности текста с некоторой странностью содержания (особенно если задавать, скажем, близкие мне исторические темы) создают психоделический эффект лёгкого провала в параллельные миры.
Именно на архитектуре GPT-3 и была создана DALL·E, которая совместила передовую лингвистическую модель с функционалом генерации изображений (с чем справлялась сильно лучше своей предшественницы от OpenAI, Image GPT на базе GPT, версии 2). Она позволяла генерировать по текстовому запросу наборы картинок с разрешением 256 на 256 пикселей. И не просто генерировать, а порой очень причудливо соединять в объекте заданные качества: классическим примером стало — кресло-авокадо. Вскоре соцсети заполнились самыми невероятными изображениями, сооружёнными DALL·E по запросам пользователей разной степени фантазии и упоротости.

К слову, в ноябре 2021 года команда разработчиков, в том числе из Sber AI, выпустила генератор изображений для запросов на русском языке под названием ruDALL-E (https://rudalle.ru/). Как сообщают авторы, обучение нейросети ruDALL-E стало самой большой вычислительной задачей в России, заняв 24 256 GPU-дней.
Но прогресс не стоит на месте. DALL·E 2, представленная OpenAI в начале апреля 2022 года, стала новым прорывом в сфере основанных на нейросетях генераторов изображений. В числе прочего в её основу легла система искусственного зрения CLIP, от всё той же OpenAI.
Качество картинок зримо улучшилось, их разрешение достигло 1024 на 1024 пикселей. Сильно уменьшились (или исчезли) характерные для сгенерированных нейросетями картинок смазанности и искажения. Более того, появилась опция редактирования уже существующих изображений: скажем, добавления на них новых объектов или редактирование каких-то деталей. Всё — через текстовые запросы. В том числе длинные и подробные, состоящие из нескольких предложений. Можно утверждать, что DALL·E 2 сейчас является самым совершенным и продвинутым генератором изображений из текста на живом языке из существующих.

Увы, пока что доступ к ней ограничен. Создатели заявили, что опасаются возможных последствий создания настолько качественных и подробных изображений. Пользователям официально запрещается загружать или создавать изображения, которые «могут причинить вред», включая всё, что связано с символами ненависти, наготой, непристойными жестами или «заговорами или событиями, связанными с текущими геополитическими событиями».
Посему доступ даётся лишь немногим избранным через запись по особой, весьма подробной форме запроса, в число которых и вошли Яннис Дарас и Александрос Димакис из Техасского университета. Они и обнаружили в ходе экспериментов нечто странное и загадочное.
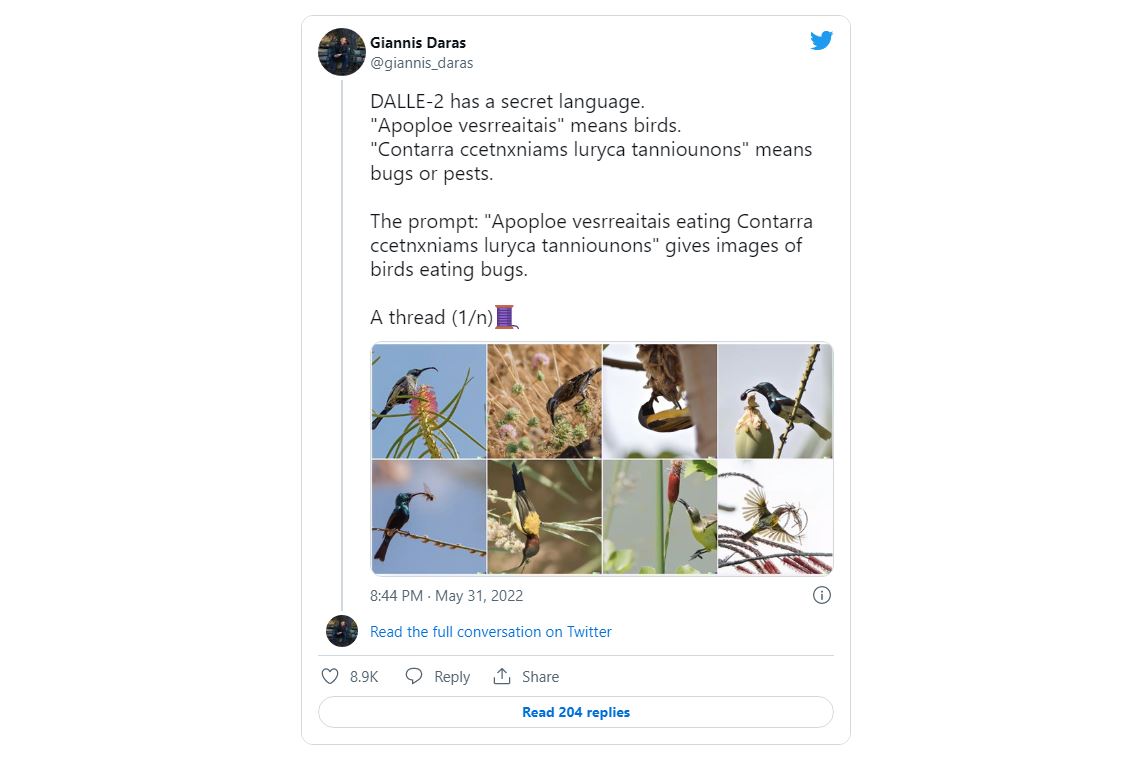
В преамбуле исследователи утверждают: «Мы обнаружили, что DALLE-2, похоже, обладает скрытым словарным запасом, который можно использовать для создания изображений с абсурдными подсказками. Например, оказывается, что Apoploe vesrreaitais означает птиц, а Contarra ccetnxniams luryca tanniounons (в ряде случаев) означает насекомых или вредителей. Мы обнаружили, что эти подсказки часто согласуются по отдельности, но иногда и в сочетании. Мы представляем наш метод чёрного ящика для обнаружения слов, которые кажутся случайными, но имеют некоторое соответствие визуальным концепциям. Это создаёт важные проблемы безопасности и интерпретируемости».

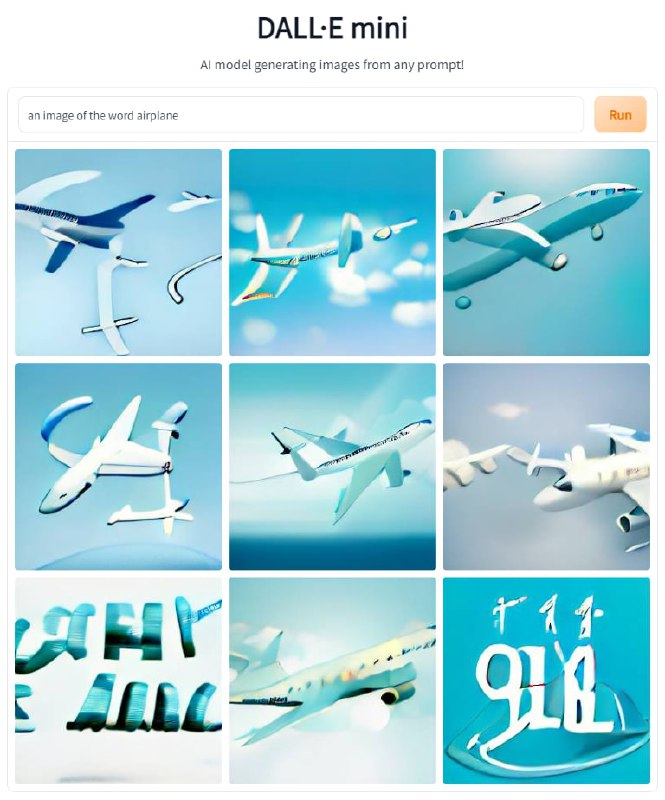
Дело в том, что при всей продвинутости DALLE-2, с написанием текста в изображении, даже по прямому текстовому запросу, она справляться не умеет. Дарас и Димакис пишут, в частности, о том, что на запрос «an image of the word airplane» система генерирует gibberish text, то есть бессмыслицу, тарабарщину, абракадабру. Однако именно в этой абракадабре они опытным путём обнаружили некую систематичность и даже воспроизводимость.
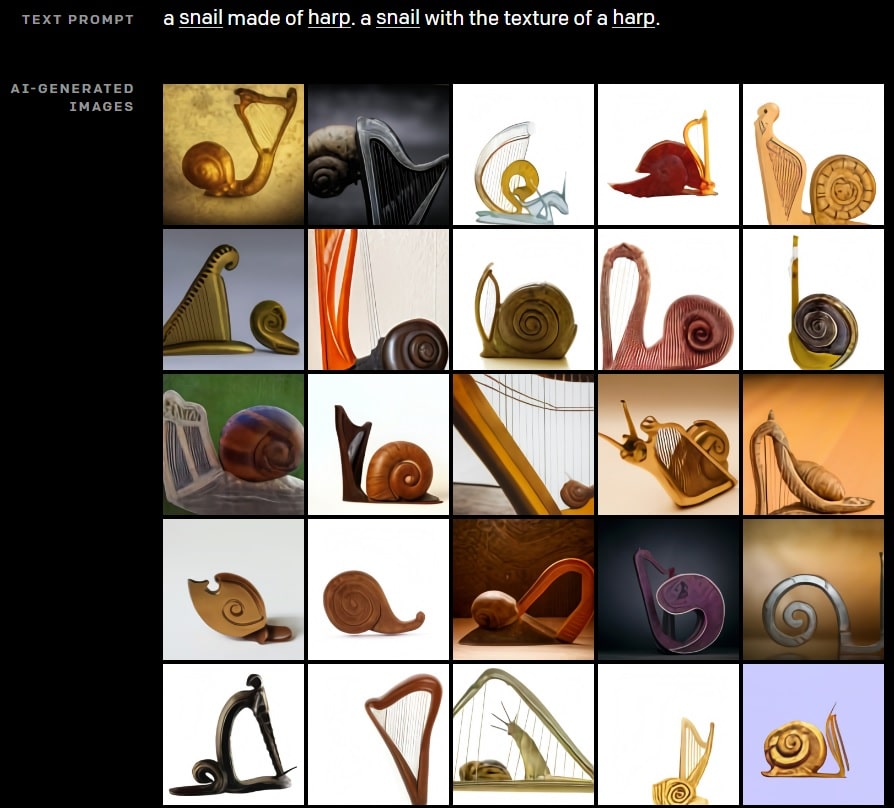
Всё началось с запроса «two farmers talking about vegetables, with subtitles», сиречь «два фермера разговаривают об овощах, с субтитрами». DALLE-2 выдала изображение беседующих фермеров с двумя блоками текста, напоминающего слегка искажённую латиницу. В верхнем блоке отчётливо читается частично обрезанное Vavcopinitegoos vicootes, в нижнем — несколько размытое Apoploe vesrreaitais. Эдакий «Этис, атис, аниматис» в исполнении нейросети, только что без белых кроликов.
Дарас и Димакис стали задавать запросы со словами из сгенерированной картинки. Оказалось, что запрос vicootes, как и было сказано в исходном запросе авторов, порождает изображения… не уверен, что это именно овощи, но точно что-то кулинарное и предположительно съедобное. А вот Apoploe vesrreaitais чаще всего формирует изображения птиц. По предположению авторов, фермеры на сгенерированной нейросетью картинке обсуждают птиц, вредящих их овощам.

Далее Дарас и Димакис задали запрос «two whales talking about food, with subtitles»: «два кита разговаривают о еде, с субтитрами». На полученном изображении, действительно, беседовали два кита. Между ними красовалась слегка фхтагническая надпись, которую авторы расшифровали на латиницу как «wa ch zod ahaakes rea».
Авторы ввели эту фразу в запрос — и получили от DALLE-2 картинки с жареной рыбой, приготовленными креветками и моллюсками в ракушках. То есть, морской едой.

По утверждениям Дараса и Димакиса, комбинация сгенерируемых нейросетью выражений тоже даёт вполне определённые результаты. Так, в ответ на «Apoploe vesrreaitais eating Contarra ccetnxniams luryca tanniounons». DALLE-2 генерирует изображения птиц, поедающих нечто насекомообразное.
Авторы, впрочем, осторожны и корректны в выводах. Никакого «созданного нейросетью языка» в их интерпретации нет, лишь некий vocabulary, то есть словарный запас, лексика:
«Заметим, что этот простой способ работает не всегда. Иногда сгенерированный текст даёт случайные изображения при запросе модели. Однако мы обнаружили, что с помощью некоторых экспериментов (выбор нескольких слов, запуск различных созданных текстов и т. д.) мы обычно можем найти слова, которые кажутся случайными и коррелируют с некоторой визуальной концепцией (по крайней мере, в некоторых контекстах). Мы рекомендуем заинтересованным читателям обратиться к разделу «Ограничения», для получения дополнительной информации».Также они уточняют, что наблюдается не столько устойчивая воспроизводимость результата, как обычно бывает с запросами на английском языке, сколько некоторая частотная корреляция. К примеру, Contarra ccetnxniams luryca tanniounons создаёт изображения насекомых лишь примерно в половине случаев, в других — чаще всего различных животных. Apoploe vesrreaitais ещё более неустойчив, и помимо птиц, часто генерирует картинки с летающими насекомыми.
Нооо… это же скучно. Помимо публикации Дарас и Димакис, выложили свои заключения в твиттере, где Янис, собственно, на радостях от открытия и «ляпнул» про «тайный язык». Ну а журналисты и блогеры подхватили.
В результате исходно осторожные тезисы превратились в «Нейросеть DALLE-2 создала собственный язык!!1 и мы все умрём». Ну или хотя бы «Нейросеть создала собственный язык, который учёные не могут расшифровать!». В общем, всё как в старом меме.

Ещё в твиттере заключения Дараса и Димакиса немедленно подвергли критике — в том числе люди, также имеющие доступ к DALLE-2. Некто Бенджамин Хилтон, скажем, получил на запрос Contarra ccetnxniams luryca tanniounons множество разных животных (впрочем, о том же пишут и сами авторы), а вот запрос Contarra ccetnxniams luryca tanniounons 3D render неожиданно стал выдавать различные объекты, связанные с морем. Apoploe vesrreaitais eating Contarra ccetnxniams luryca tanniounons, кроме «каноничных» птиц с пойманными насекомыми, рисует бабушек и растения.
Введённый текст на естественном (или не очень) языке нейросеть подвергает токенизации — то есть, разбиению на символы, слова и предложения. В том числе на основе модели BPE, Byte Pair Encoding или токенизации пар байтов, работающей с «подсловами». После обучения на сотнях гигабайтов текстов это позволяет ей «понимать» с той или иной степенью точности даже тексты, содержащие ошибки. Или не совсем определимым способом генерировать некие изображения, которые она «считает» наиболее «близкими» к введённой в форму тарабарщине.

Не выдавать вообще никакого изображения генераторы картинок на базе нейросетей не умеют в принципе, даже если задать произвольный набор букв. Причём при анализе введённого текста, нейросети могут «показаться» похожими на запрос разные «скормленные» ей слова и выражения.
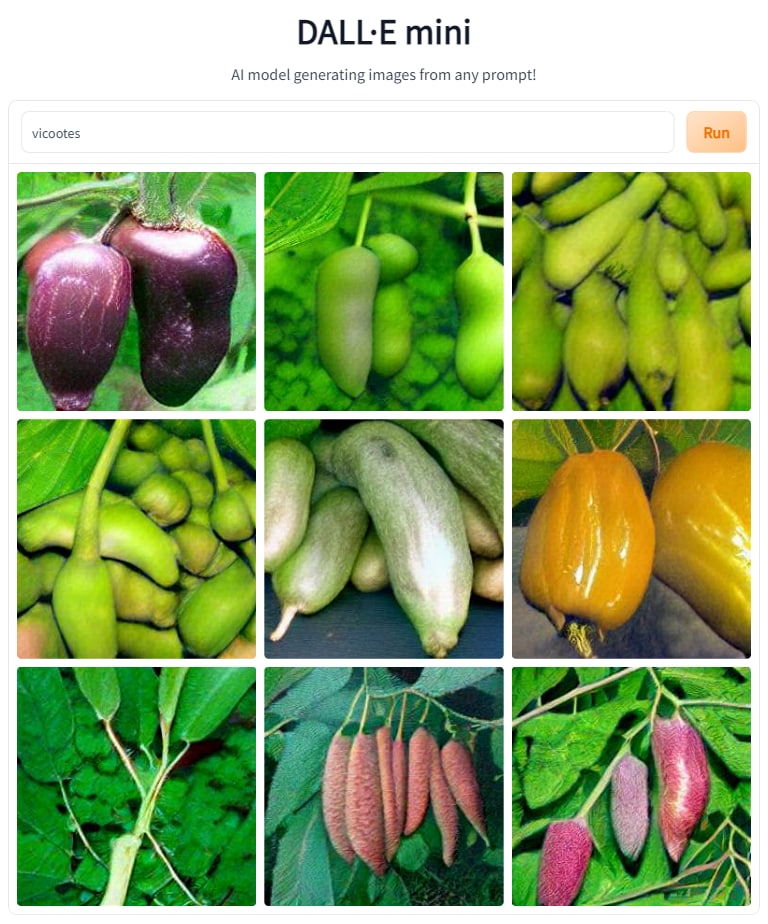
Вероятно, именно этим объясняется и появление неких корреляций между «тарабарщиной» со сгенерированных текстоподобных изображений, и неустойчивость таких корреляций. Можно даже предположить некие параллели. Так, Apoploe похоже на Apodidae, латинское название таксономического семейства стрижей. Ну или Apodiformes, стоящего выше отряда стрижеобразных птиц. Contarra ccetnxniams, вероятно, «напомнило» нейросети что-то из бесчисленных латинских же названий насекомых. Vicootes, похоже, то ли, по мнению нейросети, похоже на английское vegetables, то ли она где-то наткнулась на финское vihannes с тем же значением — но даже упрощённая нейросеть DALLE Mini уверенно рисует по этому запросу… кабачки или перцы разных форм и размеров.
А вот как именно нейросеть DALLE-2 генерирует эти самые текстоподобные изображения — пока в принципе не очень понятно.
Ну а покуда доступ к DALL·E 2 остаётся затруднённым, можно покрутить другую новую нейросеть, с открытым доступом. Недавно OpenAI выпустила в открытый доступ ещё один генератор изображений, получивший название Dall-E Mini. Он проще глубоко продвинутого DALL·E 2, но превосходит исходную нейросеть по качеству, скорости и точности генерации изображений. В силу чего обрёл изрядную популярность, а сгенерированные им сеты из девяти изображений по запросу успели заполнить соцсети.
Dall-E Mini, в отличие от предшественницы, неплохо понимает и отражает в изображениях не только статичные объекты и пейзажи, но заданные запросом действия персонажей и взаимодействия между ними. Также его характерной особенностью стало умение неплохо ориентироваться в персонажах массовой культуры, а также стилях живописи и кинематографа. Если вам нужен Годзилла в стиле наскальных изображений палеолита, или Ктулху в исполнении Хаяо Миядзаки — Dall-E Mini сделает это на удивление неплохо. Хотя и не идеально, конечно. За почти идеальными изображениями способными поспорить по качеству с творениями CGI-художников — нужно обращаться к DALL·E 2.
Ну и даже по прямому запросу писать тексты Dall-E Mini отказывается напрочь — поэтому провести над ней те же эксперименты, что и над DALL·E 2, не получается.
Впрочем, создаваемые ей по тем же «странным» запросам из статьи Дараса и Димакиса наборы картинок, тоже имеют повторяющийся и определённый характер: но, кроме уже приведённых Vicootes, сильно отличающийся от того, который описывают Дарас и Димакис. На запрос Contarra ccetnxniams luryca tanniounons она вместо насекомых выдаёт наборы портретов людей в стиле разных эпох:
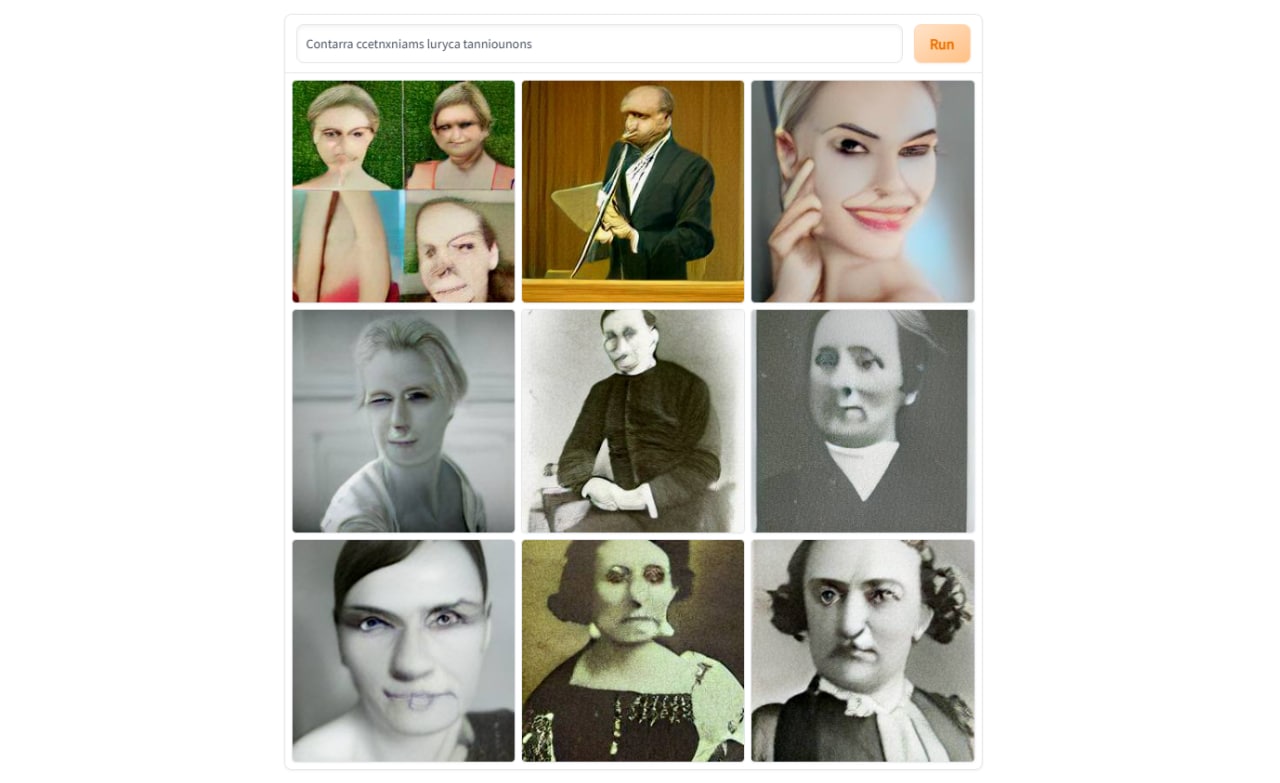
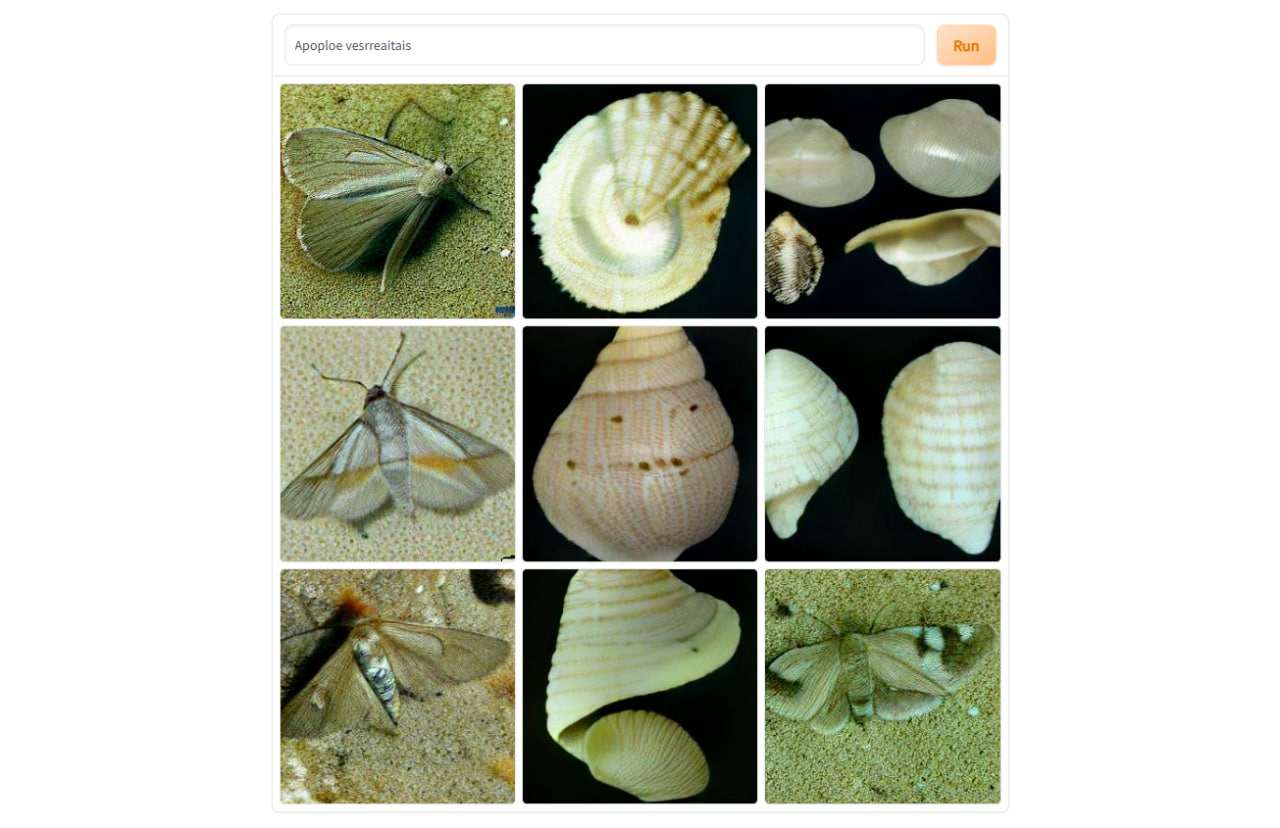
На запрос Apoploe vesrreaitais вместо птиц получаются мотыльки и ракушки. Что можно объяснить схожестью написания этих слов с научными наименованиями видов живой природы. А вот почему из предыдущего запроса генерируются портреты, да ещё и обязательно характерные для разных времён — загадка.
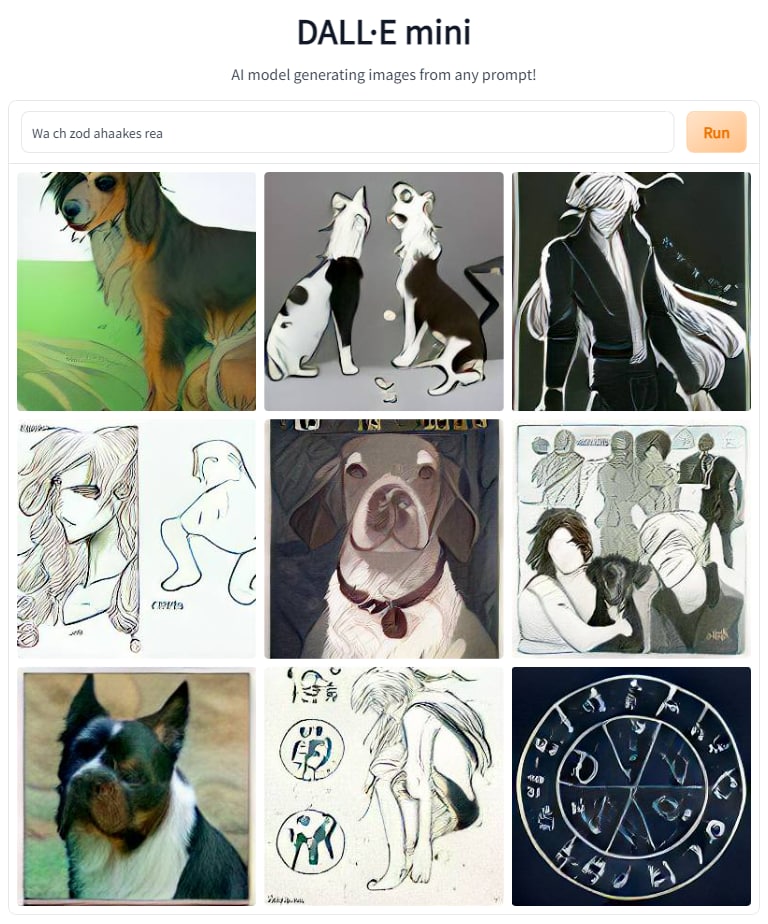
Если задать ей запрос wa ch zod ahaakes rea, то на выходе мы получаем отнюдь не морепродукты с показом рыбов, а фигуры анимешных персонажей, собак и почему-то оккультные символы.
В общем, говорить с определённой уверенностью можно о том, что генераторы изображений на основе нейросетей способны генерировать изображения на «тарабарские» запросы, причём в том, что именно генерируется, прослеживаются определённые статистические закономерности.
Продвинутая система DALL·E 2 может генерировать на изображениях тексты, которые — вероятно, примерно в той же логике токенизации и сопоставления с уже «знакомыми» токенами и их сочетаниями — могут проявлять в генерируемых изображениях некие параллели с исходным запросом. Пусть и чаще явно натянутые хуже пресловутой совы на глобусе: вряд ли даже DALL·E 2 при генерации текста в изображении проявила настолько глубокий уровень концептуализации, чтобы «наделить» фермеров беседой о вредящих кабачкам птицах, или китов обсуждением достоинств рыбов и креветков. Это было бы потрясающе — но, всё же, пока что крайне маловероятно.
И это пока что никаким образом нельзя назвать языком. И даже совсем не факт, что речь идёт о том, что с любым уровнем натяжки можно было бы назвать лексикой или словарным запасом. Это лишь некие статистические корреляции сочетаний букв, не имеющих прямого смысла на «живом» языке, с генерируемыми обученной на сотнях гигабайт текстов нейросетью изображениями.
Другой вопрос, что знакомство с хотя бы каким-то нечеловеческим языком для учёных и увлекающихся людей — столь же невероятная мечта и научный интерес, как знакомство с какой бы то ни было внеземной жизнью. И если нейросети по мере своего развития смогут порождать настоящие языки, с устойчивым лексическим запасом, синтаксическими и грамматическими закономерностями — это будет потрясающим воображение научным прорывом.
Хотя, конечно, было бы куда интереснее добраться до языков инопланетян.
Так что, коллеги-рептилоиды, не бойтесь конспирологов, бойтесь биологов и лингвистов, они, если найдут, точно не слезут…

Комментарии (9)

Sadler
18.06.2022 13:42+9Естественно, модель будет на любой непонятный ей запрос выдавать результаты, сдвинутые определённым, нестабильным, зависящим от процесса обучения, образом во внутреннем пространстве представлений, ведь выдавать что-то надо. И это отлично согласуется с предложенными в статье фактами о похожести выдачи на опечатки, другие языки и классификацию.
Получился очень наглядный пример работы принципа garbage in, garbage out.
Удивление здесь могла бы вызвать согласованность текстовой выдачи внутри изображения и текстом запроса, если бы мы не знали, что такое сопоставление -- и есть scoring-функция сети, она обучалась именно сопоставлению текстов и изображений, хоть и из более узкого множества языковой лексики.

vassabi
18.06.2022 16:00ИМХО это чем-то похоже на "неподвижные точки" - текст, который отображается на рисунки с этим же текстом ...

CrazyOpossum
18.06.2022 17:48+3Ссылка на фиговый клон википедии случайна?

phenik
18.06.2022 17:26+2Глокая куздра тоже вызывает определенные смысловые ассоциации, в том числе визуальные. Из найденных в сети
Щерба
Другой вариант



Static_electro
18.06.2022 20:04DALL-E Mini забавная. Она настолько отчаянно отказывается генерить текст, что создается впечатление, будто это специально подрезали. По запросу "advertisement billboard" генерирует чисто белый биллбоард, например :)

Vasyutka
18.06.2022 22:16+1Да в общем ничего удивительно, слова проецируются в токены. Причем даже можно подобрать кучу разных написаний (и весьма неожиданных, если брать редкие символы), приводящим к близким токенам. Потом при генерации сетка просто никак не может отличить слово абракодабру от исходного слова (при обучении дискриминтора, например). Апприорно наделили систему дислексией - странно что неправильные слова пишет потом и читает :).

Refridgerator