Привет! Я – Валерия Дымбицкая, технический руководитель команды дата-инженеров в oneFactor. Это вторая часть статьи о том, как автоматически подбирать параметры для Spark-приложений на примере spark.executor.memory.
В первой части мы разбирали, как читать логи событий Spark и как достать из них три показателя того, насколько можно уменьшить память экзекьюторам (а также зачем это делать). Здесь я расскажу о том, как превратить всё это в работающую систему на продуктиве, используя довольно простые средства.
Сила трёх в одном
Напомню, какие мы выделили правила по снижению памяти:
Не больше 10% в GC:
prediction1 = (total_gc / total_duration - 0.1) * <current spark.executor.memory>2. Накидываем за spill:
prediction2 = (mem_spill + disk_spill) / 2Чтения, шаффлы, временные объекты вмещаем в половину доступной для них памяти:
prediction3 = ((max_bytes_all + max_peak_mem) / <current spark.executor.memory>") - (<spark.memory.fraction> / 2)) * <current spark.executor.memory>Теперь нужно получить одно число – итоговую дельту снижения памяти. Комбинируем все три показателя какой-нибудь функцией:
prediction = f(prediction1, prediction2, prediction3)Но какой? Поэкспериментировав с разными, мы пришли к следующему: наиболее очевидные варианты типа взвешенного среднего (f(x, y, z) = (w1x + w2y + w3z) / 3) в нашем случае давали довольно медленную сходимость, а "выстрелил" неожиданно минимум (f(x, y, z) = min(x, y, z)). Это значит, что для того, чтобы перестать снижать память, нужен "стоп-сигнал" от всех трёх правил. Такое возможно потому, что эти правила задают мягкую границу успешности приложения: нарушение одного из них не приводит к тому, что приложение падает.
От числа к функции
Теперь, когда мы скомбинировали правила, можно обратить внимание на то, что базы – входные выборки – время от времени могут меняться. Чем больше база, тем меньше мы в реальности можем снижать количество памяти на её обработку. Значит, в реальности для каждого пайплайна нам нужно аппроксимировать функцию. Имея набор фактов вида [база] + [текущее значение параметра] + [метрики], мы можем обучить регрессию R и применять полученную функцию перед очередным запуском приложения, чтобы получить параметры запуска P:
P = R(features(base))
Это означает, что мы теперь обучаем ML-модели, чтобы лучше запускать наши ML-модели.

Но я же обещала простые средства? В самом деле, мы взяли очень простой, тупой, можно сказать, алгоритм: изотоническую регрессию прямиком из доступных алгоритмов в Spark ML (https://spark.apache.org/docs/latest/ml-classification-regression.html#isotonic-regression). Это монотонная – в нашем случае неубывающая – ломаная линия, и выглядит она примерно так:

Здесь по оси X – количество строк в базе. Для лидогенерации это наш единственный признак. По оси Y – предсказываемое значение spark.executor.memory. Видно, что один и тот же пайплайн на разных базах требует разных ресурсов.
У такого простого решения есть ряд плюсов:
Не нужно настраивать никаких параметров;
Можно обучаться как на 2-3 точках, так и на большом их числе;
Легко перевести в строковый вид, выведя координаты опорных точек; это значит простоту мониторинга – можно быстро понять, почему автотюнинг выдал именно столько;
Легко дообучать – об этом поговорим чуть дальше.
Минус тоже есть – не получится из коробки увеличить размерность ни признакового пространства, ни предсказываемого значения. Это значит, что как только нам понадобятся дополнительные параметры выборки (например, количество дат для данных за историю), придётся использовать другой тип модели. То же самое будет, когда мы захотим расширить список параметров для тюнинга. Однако для proof of concept и незатратного вывода в прод изотоническая регрессия оказалась весьма полезна.
Ставим тюнинг на рельсы
Теперь всё это нужно встроить в непрерывный продуктив. Для этого мы реализовали вот такой цикл взаимодействия компонент:

Над сервисом пакетной обработки ML-Batch мы поставили прокси-сервис, который и предсказывает параметры для запуска (ещё он научился разбивать приложения на части, когда сам Spark не справляется, и многое другое, но это отдельная тема – нас интересует именно тюнинг). Метрики успешных приложений раз в день обрабатываются батч-джобой, которая переобучает регрессии и складывает их в лог в Postgres. ML-Batch-Manager каждый раз берёт из лога активную итерацию и применяет её на входной выборке, чтобы получить параметры, с которыми ML-Batch будет запускать пайплайн.
Переобучение регрессий происходит постоянно, и через некоторое количество регулярных запусков триггера мы приходим от константного значения параметра к монотонной зависимости:

Переобучение никогда не заканчивается – таким образом тюнинг адаптируется к вариативности баз, долговременным изменениям на кластере, ручному тюнингу других параметров, оптимизации самого кода, и т.д.
Для самого переобучения нам нужно только добавить собранные за день точки к опорным и обучить новую модель:
import org.apache.spark.ml.regression.{IsotonicRegression, IsotonicRegressionModel}
import org.apache.spark.sql.functions._
val oldModel: IsotonicRegressionModel = ...
val stats: DataFrame = ... // rows: Double, sparkExecutorMemory: Double, prediction: Double
val oldPoints = oldModel.boundaries.zip(oldModel.predictions).toSeq.toDF("rows", "mem")
val newPoints = stats.select($"rows", ($"prediction" + $"sparkExecutorMemory").as("mem"))
val newTrainDF = oldPoints
.join(newPoints, oldPoints("rows") === newPoints("rows"))
.select(coalesce(newPoints("rows"), oldPoints("rows")).as("rows"),
coalesce(newPoints("mem"), oldPoints("rows")).as("mem"))
val newModel = new IsotonicRegression()
.setIsotonic(true)
.setFeaturesCol("rows")
.setLabelCol("mem")
.fit(newTrainDF)Что делать, если мы предсказали неправильно, и приложение всё-таки упало? Тогда мы откатываемся назад на такую итерацию, при которой мы предскажем больше, и делаем ретрай. Самой первой итерацией ставится дефолт – те же 16 Гб, например, – и если паттерн нагрузки сменился настолько, что даже дефолт не спасает, мы автоматом его увеличиваем. В следующий раз при переобучении мы будем добавлять данные к той итерации, которая осталась активна на конец дня. При этом в такой концепции мы толерантно относимся к падениям, коль скоро результат всё ещё считается к нужному времени.
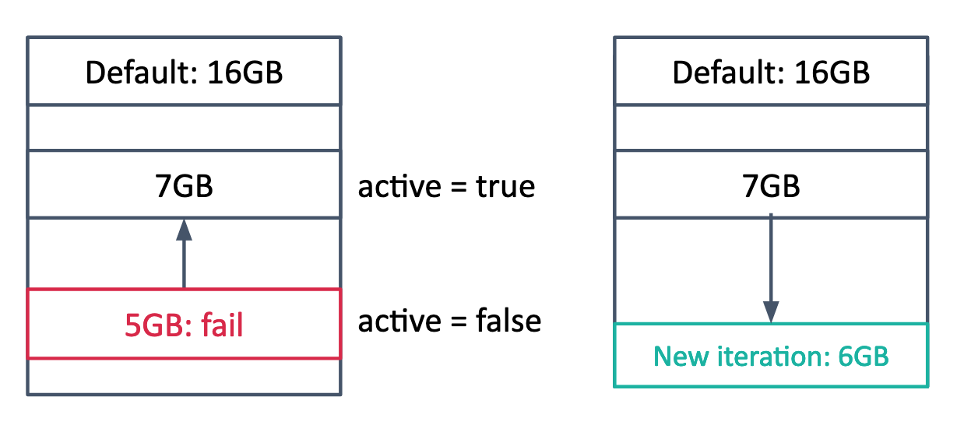
Было vs стало
Наша первоначальная проблема заключалась в том, что, не зная оптимальный размер контейнера, мы делали их всегда слишком большими. То есть, выделяли относительно малое количество больших по памяти контейнеров, оставляя недоутилизированными виртуальные ядра. "Ужимая" spark.executor.memory, мы смогли сдвинуть этот баланс на 16%: больше задействовать ядра и меньше память. Это также означает больший параллелизм.
Если раньше spark.executor.memory был статичным для всех расчётов одного типа, сейчас он меняется от пайплайна к пайплайну, от базы к базе, от дня ко дню. За пару месяцев после полного вывода в прод мы сняли примерно терабайт на контейнер – имеется в виду, что если просуммировать, сколько мы скостили spark.executor.memory для каждого приложения за это время, получится терабайт. Списки приложений в PENDING сократились, кластеру стало легче дышать.
Вместе с этим кластеру негоже и простаивать, поэтому такая оптимизация позволила нам существенно расширить ту же лидогенерацию. От 600 расчётов в день мы пришли к более чем 20 тысячам расчётов, из которых порядка 300 дневных, около 5 тысяч часовых и сверх 15 тысяч совсем коротких десятиминутных.
Что может пойти не так
Несмотря на относительную простоту системы автотюнинга, есть и подводные камни в её реализации. Они касаются того, как сама система будет влиять на кластер. Неосторожности могут привести к авариям и критическим ситуациям. Разберём те грабли, на которые мы наступили.
1. Слишком тяжёлые приложения
Прямое следствие масштабирования – джобе нужно обрабатывать всё больше и больше логов. Она делает это всё дольше и дольше и держит ресурсы, которые сама и должна экономить. При этом вам нужно обучить сотни моделей за раз, и чем дольше длится обучение, тем дольше держатся ресурсы. Если ошибиться и делать обучение последовательно, можно "съесть" гораздо больше, чем хотелось бы. Мы наблюдали, как наша джоба работает 13 часов и даже дольше, не всегда целиком успевая всё затюнить к следующему дню, и при этом выходит чуть ли не на первое место по потреблению среди всех приложений.

Вывод 1: отделяем агрегацию логов от переобучения.
Обработка логов требует больше ресурсов, чем непосредственно обучение. Чтобы разделить использование контейнеров, логи обрабатываются сразу после завершения приложения, складывая всё в единый, уже небольшой, датасет. Переобучение берёт на вход уже конкретные показатели для каждого прохождения.
Вывод 2: регрессии переобучаем параллельно.
Чтобы поменьше тратить времени на переключение между джобами, переобучаем в несколько потоков (в нашем случае в 10). Регрессии независимы друг от друга, но драйверу об этом нужно сказать.
2. Слишком много приложений
После первого вывода есть соблазн каждый лог обрабатывать отдельным приложением. Это легко реализовать, если есть способ повесить callback на завершение приложения. Мы не преминули этим воспользоваться, раз ML-Batch-Manager всё равно следит за выполнением приложения. Ресурсов система стала потреблять меньше, но появились другие проблемы.
Когда приложений в кластере становится слишком много, возникают разные побочные эффекты, в частности:
Увеличивается нагрузка на файловую систему из-за обилия служебных файлов;
Увеличивается нагрузка на YARN в целом;
При особой старательности можно положить Resource Manager по ООМ.
С нами случился именно третий пункт: из-за скакнувшей нагрузки, обилия мелких приложений, агрегации от мелких десятиминутных триггеров, а также добросовестных ретраев Resource Manager захлебнулся в попытках достать длиннющий список PENDING-приложений. Отсюда -
Вывод 3: самые мелкие приложения не нуждаются в тюнинге – их лучше туда вообще не включать.
Вывод 4: агрегацию проводим микробатчами (фиксированное количество приложений в день) либо потоком (одно потоковое приложение).

Будущее и применения
Тот подход, о котором я рассказала, можно использовать в любых регулярных процессах. Мы, например, применили тот же самый тюнинг для оптимизации другого процесса помимо лидогенерации – расчёта кэша кредитных скоров.
То же самое можно применить и для ETL. Здесь придётся учитывать, что входов у расчёта может быть несколько. Поскольку более вероятно, что со временем будет приходить больше данных на обработку, а не меньше, тюнинг может плавно адаптировать расчёты к этим изменениям.
Хотя рассказ был про spark.executor.memory, такой же подход можно применять и для других параметров – количество ядер, параметры драйвера, memoryOverhead, ограничения динамического аллоцирования, даже тонкие настройки вроде GC или ваши внутренние feature flag'и.
С дополнительными нюансами такой подход можно применить и для Spark Streaming, и вообще для всего, у чего в каком-то виде есть логи.
А ещё это хороший способ безопасно собрать разнообразные данные на проде, не выделяя дополнительных ресурсов. И вспомнить мечту о классификаторе.

Главное – действуйте аккуратно.
tolstoymv
странно что для этого всего нет стандартных каких-то средств - все что ли богатые и закидывают кластер деньгами?
sshikov
А вы думаете, это решение золотая пуля? Напрасно.
Оптимизация производительности всего кластера в целом, где бегает куча приложений, которые каждый день обсчитывают разные объемы данных, и имеют десятки параметров настройки каждое — это далеко не простая задача. Большинство статей по выбору параметров спарка вообще не заходят так далеко, как автор, и предполагают, что ваше приложение на кластере совсем-совсем одно. А в реальности автор тут описывает, как у них RM достигает пределов своего масштабирования, потому что там в очереди задач тысячи.
А это описанное решение — оно возможно очень даже хорошее, но все равно частное. Вот смотрите:
>Тогда мы откатываемся назад… и делаем ретрай.
А мы вот не можем делать. Просто потому, что у нас есть требование закончить работу к определенному времени, время на расчеты ограничено, и на ретрай его просто не остается. В итоге если представить, что мы вот так обучаемся, результат следующей попытки будет только послезавтра — потому что завтра мы откатились на старые параметры, а еще какие-то новые попробуем еще через день. Когда это решение сойдется — неизвестно.
А чтобы сделать ретрай быстро — нужно чтобы приложение было к этому готово, то есть ретрай с последней «контрольной точки» — а для этого эту точку надо сохранить. А это тоже все требует ресурсов.