Так совпало, что я недавно прочёл статью Transparency of deep neural networks for medical image analysis и пост от канала Reliable ML про интерпретируемость. Я работаю в сфере медицины уже почти пять лет, и всё это время постоянно где‑то на орбите внимания мелькает эта тема.
Что такое интерпретируемость, если решается задача классификации всего рентгенологического исследования — в целом понятно. Врачи не доверяют системам, которые просто говорят «тут где‑то на картинке есть рак», а значит нужны какие‑то методы, которые будут «объяснять» итоговое предсказание. Их придумано довольно много — разнообразные виды GradCAMа, окклюзия, LIME. Из коробки многие из них можно взять из библиотеки Captum для Pytorch.
Если вы хотите узнать ещё больше об организации процессов ML‑разработки, подписывайтесь на наш Телеграм‑канал Варим ML.

Однако, жизнь показывает, что качество локализации клинически значимых признаков у этих методов, мягко говоря, неудовлетворительное. При этом вряд ли кто‑то будет всерьёз рассматривать ИИ‑систему, которая не решает задачу локализации — детекции или сегментации. Да и реально хороших метрик на чистой классификации достичь удаётся разве что при наличии очень больших, чистых датасетов. На данный момент у нас четыре системы в проде, из них одна — это детекция, две — инстанс‑сегментация, и ещё одна — семантическая сегментация.
Когда система умеет локализовывать области интереса и присваивать им класс (например, злокачественное образование, лимфоузел и так далее), вопрос интерпретируемости как будто бы отпадает. Действительно, несколько лет мы работали, вспоминая про интерпретируемость только на внутренних митапах.
Зачем нужна интерпретируемость?
В прошлом году мы решили, что не Москвой единой, и начали разводить активности и в других регионах — и в государственных, и в коммерческих клиниках. Процесс продажи в 99% случаев включает тестирование системы на данных заказчика. Кто‑то смотрит только на агрегированные результаты и метрики, но большинство главврачей и медицинских директоров любят визуально оценить результаты работы системы. Кроме того, с сентября 2022 года в Московском эксперименте появилась процедура клинической оценки. Врачи‑эксперты ежемесячно оценивают результаты работы системы на случайно выбранных 80 исследованиях. В общем, количество обратной связи и вопросов выросло в разы.
Вот примеры вопросов и замечаний:
«Почему ИИ выделил эту область как патологию, а соседнюю нет? Они же выглядят почти одинаково!»
«Почему суммация теней и артефакты оцифровки расценены как злокачественные образования?»
«Почему патология выделена на одной проекции, а на другой нет?»
«Почему выделена область потенциальной патологии, но общая оценка исследования — норма»?
Подобные «косяки» вызывают недоумение врачей и ощутимо снижают вероятность продажи. Что можно делать?
Улучшать системы за счёт дообучения и изменения архитектуры.
Добавлять разные эвристики и хаки, чтоб избегать определённых типов ошибок.
Вести просветительскую работу, чтобы врачи лучше понимали источники тех или иных ошибок и общую суть работы ИИ‑систем.
Добавлять механизмы интерпретации и объяснения предсказаний, которые помогут отвечать на эти «почему».
Я как раз и хочу разобрать некоторые способы интерпретации из статьи из первого абзаца и привести примеры использования из нашей практики.
Способы интерпретации
Клинические концепты
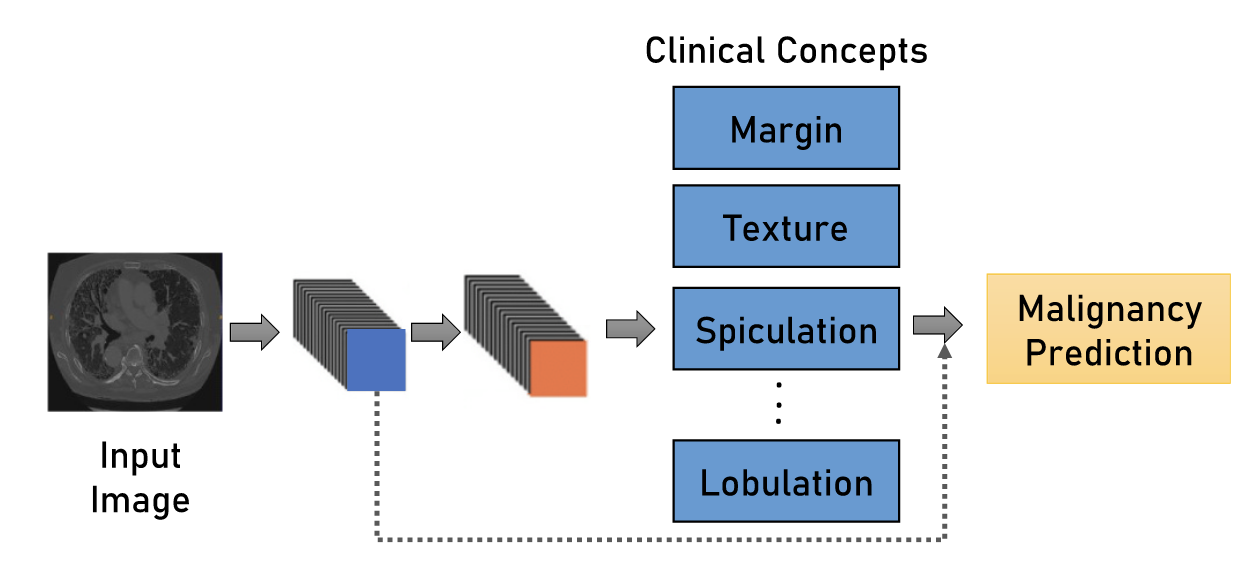
Суть этого метода достаточно проста, но при этом привлекательна. Вместо прямого предсказания класса RoI (Region-of-Interest) с помощью сетки, будем сначала определять его различные свойства, связанные с текстурой, формой, плотностью относительно окружающей ткани, размером. А уже на основе этих свойств мы можем на основе правил или с помощью простой линейной модели определять конкретный тип объекта - например, злокачественный он или доброкачественный. Звучит крайне приятно - для каждого предсказания мы можем объяснить врачу, почему оно именно такое. Метод, конечно же, не идеален:
Скорее всего, для корректного расчёта большинства признаков потребуется очень точная сегментация контура RoI.
Метрики могут упасть по сравнению с прямой классификацией.
Модель может просто пропустить нужный RoI, и тогда вопросы всё равно возникнут.
Некоторые клинические признаки сложно перевести в численную форму.
Мы используем похожую идею для присваивания общего риска патологии на исследовании. Вместо того, чтобы напрямую решать задачу бинарной классификации (0 - норма, 1 - патология) по картинкам, мы используем найденные объекты, их вероятности, классы и размеры в качестве фичей простой мета-модели - например, LightGBM.
Concept attribution
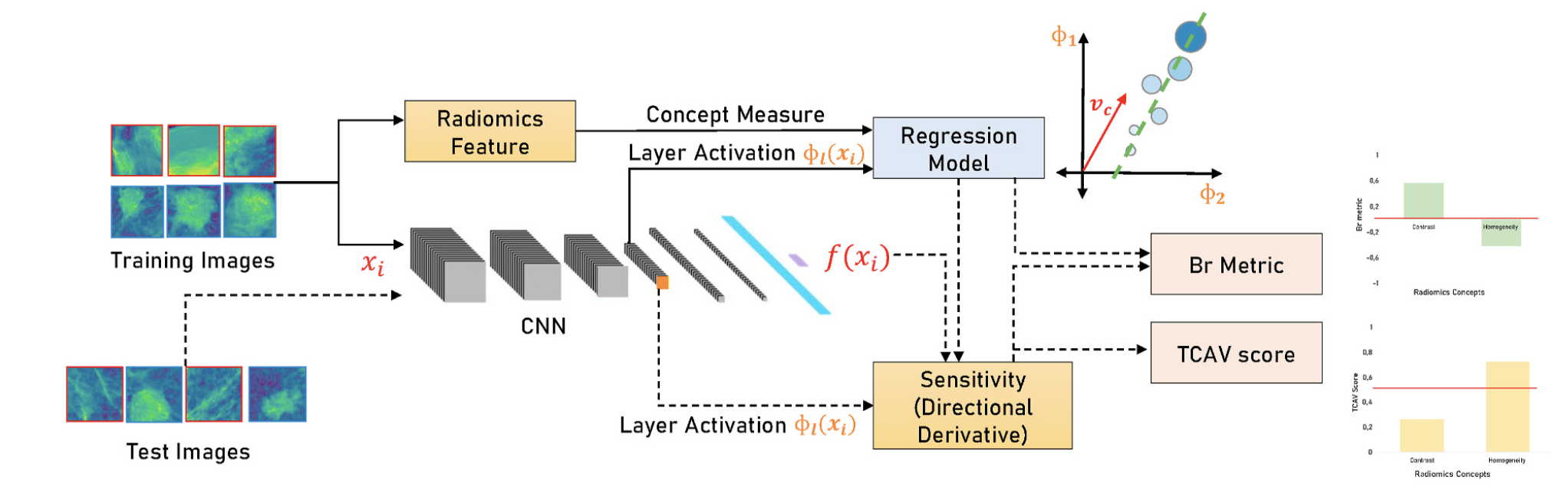
Схожая по духу идея, которая позволяет решить один из недостатков предыдущего метода - вероятное падение метрик. И снова ничего сложного - считаем так называемые радиомические фичи объекта (как базовые, характеризующие форму или размер, так и специфические для задачи), а затем строим модели, которые пытаются предсказать значение каждой фичи по репрезентациям из нашей нейронки. С помощью этих моделей можно для каждого входного изображения оценить чувствительность конечного предсказания к значениям тех или иных радиомических фичей. Подробности можно узнать в этой статье и в этой.

Мы пробовали такой подход для маммографии - есть любопытные результаты, некоторые фичи прям хорошо можно предсказать по нейронным репрезентациям. До прода пока не докатилось, но помогло сгенерить гипотезы по добавлению hand-crafted фичей в сетку.
Интерпретация по кейсам

Ещё одна группа методов основана на поиске похожих кейсов среди библиотеки патологий. Мы рассматривали такую идею - дать врачу возможность выделять область на изображении, вычислять её репрезентацию, а затем искать в векторной базе данных типа Milvus похожие области среди наших размеченных данных. Опять же - пока осталось на уровне идеи.
Counterfactual explanation

Метод, отсылающий нас к посту про робастное обучение - берём RoI и пытаемся каким-то способом (например, генеративной сетью) изменить его так, чтобы изменить предсказанный класс - например, со злокачественного образования на доброкачественное или background. Изменённые участки могут подсказать, на что смотрит сетка, и какие свойства объекта для неё оказались решающими. Сам не пробовал, но интуитивно сомневаюсь, что получатся визуально адекватные пертурбации.
Генерация заключений
Существует большая группа статей, которые нацелены на генерацию текстового заключения по медицинскому изображению. Подходы есть разные - с использованием фиксированного словаря, свободная генерация, заполнение пустых мест в шаблоне. В продакшне ничего лично не видел, хотя мы думали об этом много.
Что в итоге?
Как вы, наверное, догадались из текста - у нас это всё пока остаётся на уровне рисёча и развлечений. Причина проста - нет уверенности, что затраченное время окупится каким-то повышенным доверием от пользователей. На данном этапе кажется, что стоит больше внимания уделить просто улучшению качества работы моделей - до идеала нам и нашим конкурентам пока далеко. Хотя свои интересные применения у этих методов когда-нибудь найдутся - например, в образовательном процессе молодых рентгенологов или автоматической генерации детальных текстовых заключений.
Если вы хотите узнать ещё больше об организации процессов ML-разработки, подписывайтесь на наш Телеграм-канал Варим ML
Комментарии (3)

shamash
03.02.2023 05:13развитие системы должно быть двухсторонним, получившие эту систему врачи/патологисты должны дообучать ее, а выдавать вы ее должны as is, в лаборатории и другие системы бесплатно. Это целая система..
до идеала нам и нашим конкурентам пока далеко.
.тут я бы не делал такие выводы. Если остановитесь, то точно не догоните.
Причина проста - нет уверенности, что затраченное время окупится каким-то повышенным доверием от пользователей.
единственное что должна делать система в начале, выделять какие то области, не давая им названия.
если найдете на это инвесторские деньги, это довольно перспективное развлечение
vassabi
кстати, судя по вопросам - кроме анализа радиометрии, вы не пробовали сделать
совмещение проекций
анализ артефактов снимка (аналоговых и цифровых)
?
crazyfrogspb1 Автор
про проекции - конечно =) но это не так просто, там геометрия совсем неочевидная. небольшой спойлер - у меня в мае доклад на Codefest, я там расскажу в том числе подробнее про то, какие способы мы пробовали. потом на ODS Data Fest, может, еще расскажу, чтоб в открытом доступе было сразу.
про артефакты - мы их часто размечаем, чтоб сетке кормить как hard negatives, либо отрезаем на препроцессинге, если возможно