21 марта 2022 года суд признал деятельность Instagram* и Facebook* экстремистской и запретил оба сервиса на территории России. Бизнесу и СМИ нужно было отреагировать на изменения законодательства в кратчайшие сроки и удалить символику запрещённых сетей с сайтов и из доступных материалов. Мы не стали исключением.
Как только Meta* признали террористической организацией, появились риски, что размещение символики её продуктов повлечёт за собой санкции со стороны государства. СМИ перечисляли разные меры: от штрафов до закрытия бизнеса и арестов руководства. До вступления решения суда в законную силу оставалось всего 1–1,5 месяца, все сроки поджимали.
Мы обсуждали вопрос с юристами и понимали, что рисковать бизнесом и репутацией нельзя. С текстами проблема решалась просто: дисклеймер при упоминании запрещённых сетей, как в СМИ. А вот с видеоматериалами вопрос уже был гораздо сложнее. За демонстрацию логотипов Facebook* и Instagram* могли привлечь к ответственности. Надо было как можно быстрее удалить символику из всех видео. Мы решили эту задачу с помощью нейросети.
Что нам грозило за невыполнение
Запрос на удаление нежелательной информации поступил к нам 25 марта. Изначально было не до конца понятно, что именно нам грозит за упоминания Facebook* и Instagram*. Ещё за несколько месяцев до этого прогнозы о возможном их запрете казались необоснованной паникой, но с изменением политической обстановки они быстро становились реальностью.
Среди возможных санкций за упоминание запрещённых сетей называли штраф на сумму от 50 000 рублей и арест генерального директора на 15 суток. При доказанном участии группы лиц по предварительному сговору меры распространялись на всех. Последнее — как раз наш случай: все продукты мы делаем сообща, и идти под статью не хотел никто. Стало ясно: искать выход надо срочно, иначе работать, как раньше, мы не сможем.
Как выяснилось со временем, самым вероятным взысканием был штраф размером 50 000 рублей согласно ст. 20.3 КоАП РФ. Но на фоне всеобщей паники задача выглядела как «надо было ещё вчера». Тем более, полностью обезопасить себя от жалоб со стороны было нельзя.

Гарри Марковский
Руководитель видеопродакшна Нетологии
Жалоб на нарушение законодательства в теории могло быть много, но это уже лирика. Суть задачи состояла вот в чём: если как-то автоматизировать процесс распознавания и зачистки лого в видео и PDF-документах, это бы очень помогло в сложившейся непредсказуемой ситуации.
Дано: тонны видео и сроки «ещё вчера»
Дедлайн на всё был месяц, а видеоматериалов за всё время нашей работы накопилось много. Делать в таких условиях полноценную разметку, тем более вручную, не представлялось возможным. Чтобы сэкономить время, мы решили использовать нейросеть. Она должна была находить координаты логотипов запрещённых соцсетей на каждом кадре, чтобы затем наложить на них соответствующий фильтр.
Для начала нейросеть надо было обучить на некой базе скриншотов, затем она должна была разметить видео и «почистить» их от символики Instagram* и Facebook*. С учётом ситуации сделать это надо было «или вовремя, или никогда»: слишком велики были риски.
Нашим подрядчиком стал центр ML-экспертизы (Machine Learning Center of Excellence) разработчика HRtech-решений TalentTech: их работа — решение прикладных задач с помощью искусственного интеллекта. Адресованное им ТЗ звучало как «ребята, можете ли помочь, а то у нас беда». Они согласились и предложили дописать нейросеть, чтобы можно было автоматически обработать большой массив данных.

Владимир Ли
Руководитель отдела машинного обучения Нетологии, в прошлом — руководитель ML-центра экспертизы TalentTech
У коллег из Нетологии лежали тонны видео в Кинескопе (это сервис, который хранит и транслирует видео). В них содержалась символика запрещённых сетей, которую надо почистить. У нашей команды уже были совместные наработки по Computer Vision с «Фоксфордом»: мы отслеживали качество вебинаров, в том числе наличие логотипов в кадре. Так как новая задача была отчасти похожа, запрос адресовали нам. Стали уточнять, с чего начать, сделали чат в Telegram. Проектом занялись команда ML и люди из Нетологии: CPO Яна Арсютина, проектный менеджер Дмитрий Дворяшин, руководитель видеопродакшна Гарри Марковский.
Сбор и разметка данных: что пошло не так
29 марта 2022 года мы приступили к сбору разметки: этот этап работы длился неделю. Нам был нужен датасет, содержащий изображения с выделением запрещённой символики.
Владимир Ли
Руководитель отдела машинного обучения Нетологии, в прошлом — руководитель ML-центра экспертизы TalentTech
Датасет требовался, чтобы обучить нейросеть под конкретную задачу: детекцию логотипов Facebook* и Instagram* именно в видеоматериалах. На первом этапе нам нужно было «нарезать» скриншотов из видеоматериалов с символикой и «разметить» место, где они расположены, чтобы нейросеть, обученная на этих данных, смогла выполнять такую же задачу на других датасетах. Чем больше таких разметок, тем выше точность работы нейросети.
Для разметки использовали инструмент от Intel под названием CVAT. В него загружались скриншоты с видеороликов и далее обозначались области, содержащие логотипы. Можно выделить четыре типа необходимых логотипов: логотипы Facebook* — значок и полное написание, а также логотипы Instagram* — значок и полное написание. На этапе EDA возникла проблема, что в видеоматериалах могут быть и кастомные логотипы, то есть имеющие другой цвет, наклон, пропорции размеров в отличие от реальных логотипов.


Евгений Медведев
Data scientist ML-центра экспертизы TalentTech
CVAT — инструмент для разметки данных: пользователь обводит мышкой объект, делает метку, и этот объект сохраняется вместе с координатами. Результат можно выгружать через API и использовать дальше для обучения сети.
Скриншотов нам нужно было много. Нашей первой задачей было нахождение по картинке объекта с выдачей координат и определением класса. Точный объём данных подсчитать было сложно: всё зависело от ситуации. Изначально мы определили, что для обучения нейросети с применением Transfer Learning нужно 1 тыс. изображений, но по факту собрать вручную получилось меньше.
В CVAT все приходилось делать вручную: нарезать кадровку, загружать в систему и уже в ней все размечать. Это оказалось слишком трудоёмко. Разметить таким образом удалось всего лишь около 200–300 скриншотов. На выходе получили неудовлетворительные метрики: Recall на валидации ~ 0,5. Для обучения требовалось больше данных. В ручном режиме на их сбор ушёл бы примерно месяц, в то время как за этот срок надо было уже доделать всю задачу до конца.
Выходом стала генерация синтетических данных. Для фона мы взяли наши готовые презентации, отдельно нашли логотипы. На каждый фон в произвольном порядке наносили от одного до трёх логотипов разных размеров. Минимальные и максимальные параметры размеров логотипа выбирали из разметки в CVAT, далее размер генерировался из равномерного распределения. Чтобы сгладить края, мы наносили логотипы с прозрачностью 0,05, а чтобы они не пересекались между собой — смотрели на IoU (коэффициент перекрытия, Intersection over Union).
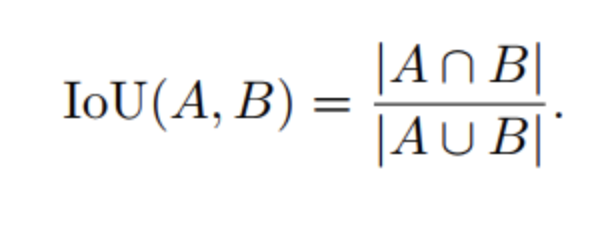
IoU — это соотношение пересечения двух логотипов и их общей площади, где A — множество пикселей логотипа 1, B — множество пикселей логотипа 2.
Так получились искусственные картинки.

Для решения проблемы с определением кастомных логотипов мы применили аугментацию (библиотеку albumentations). Для фона использовали горизонтальное и вертикальное зеркальные отображения, для логотипов — смещение цветов (этим методом мы меняли цвет логотипа Facebook*). Так у нас был готов большой датасет из более чем 10 000 изображений. На написание кода и формирование датасета ушла неделя.
Как мы обучали модель и ускоряли процессы
Мы выбирали между тремя архитектурами нейросети для обучения — SSD, EfficientDet и YOLOv5. Все они относятся к одностадийным и могут использоваться в видеообработке в режиме онлайн. Изучали статьи, смотрели метрики на общедоступном датасете COCO и пришли к выводу, что с учётом скорости и точности оптимальным решением для нас является YOLOv5, а точнее — YOLOv5m. Эта архитектура обеспечивала самую быструю реализацию алгоритма.

Для работы с YOLOv5 достаточно было подготовить данные, как на рисунке ниже, а также создать конфигурационный файл yaml с указанием путей к данным и информации про классы, а затем сделать запуск.

Мы начали обучать сеть на синтетических данных. В процессе обнаружили проблему с разрешением изображения: чем оно больше, тем лучше оказывались метрики. С другой стороны, при высоком разрешении времени на обработку уходило больше. Пришлось искать компромисс между скоростью обработки и параметрами видео. Сначала мы работали с разрешением 461*461, потом — с 720p и 1080p. После получения метрик и совместного обсуждения мы остановились на 1080p.
В качестве основной метрики мы выбрали Recall, так как главной задачей была детекция всех имеющихся логотипов. При этом параметр Precision был не так важен. После обучения на синтетических данных мы получили метрики на разметке из CVAT: Recall = 0,9 и Precision = 0,8. Затем мы дообучали нейросеть на реальных данных, после чего метрики на контрольной выборке выросли: Recall = 0,98, Precision = 0,975 при IoU > 0,5. Их можно увидеть на рисунке ниже:

Последней большой задачей стал инференс (получение результатов оценки) модели. Нужно было обработать большое количество видеоматериалов общей длительностью 15 472 часа. Мы посчитали, что на обработку всех данных уйдёт почти год, а наш дедлайн составлял месяц. Чтобы ускорить процесс, мы распараллелили его на пять GPU (graphic procession units, говоря проще — видеокарт) и использовали мультипроцессинг. В итоге всё удалось сделать за 14 дней.

Дарья Макеева
Data scientist ML-центра экспертизы TalentTech
В результате мы должны были получить конкретный вид CSV-файлов, поэтому мы распараллелили работу, выделив две задачи:
• дообучение модели YOLO и формирование датасета;
• разработка алгоритма, преобразующего датафрейм-выхлоп из модели YOLO в датафрейм с разбивкой по временным интервалам.Итоговый датафрейм был сформирован следующим образом: через модель прогонялся каждый первый кадр каждой секунды. Это было сделано для ускорения процесса: больше кадров — дольше обработка, меньше кадров — выше погрешность.
Если на серии последовательных кадров или внутри одного кадра нейросеть обнаруживала несколько объектов, то для каждого из них проверялось условие на пересечение в рамках одного или ближайших кадров. Если этот показатель превышал 70%, объекты объединялись в один. Координаты в таком случае считались по максимуму, чтобы полностью поместить в прямоугольник все объединённые объекты. Если же пересечения не было или оно составляло менее 70%, то объекты считались разными.
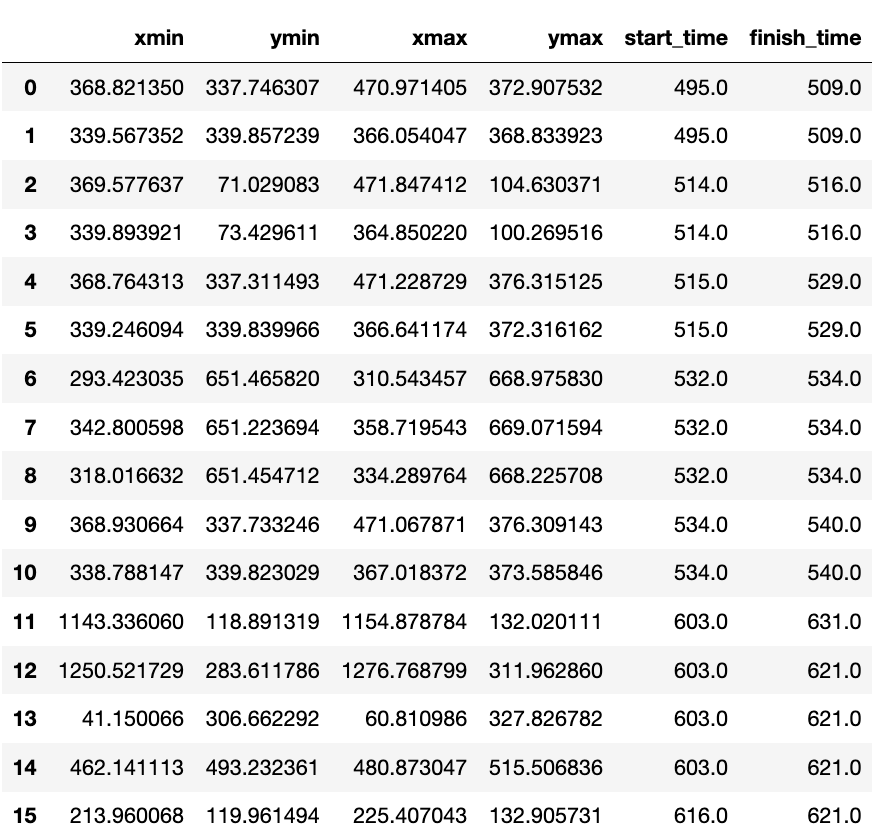
Так как нашей основной метрикой был Recall, мы приняли решение для итогового выхлопа использовать «захлёст» в секунду. Если на фрейме N, соответствующем N-ой секунде видео, были обнаружены объекты, по умолчанию мы считали, что они начались на секунде N-1. На скриншоте можно увидеть пример выхлопа такого алгоритма для одного из видео:
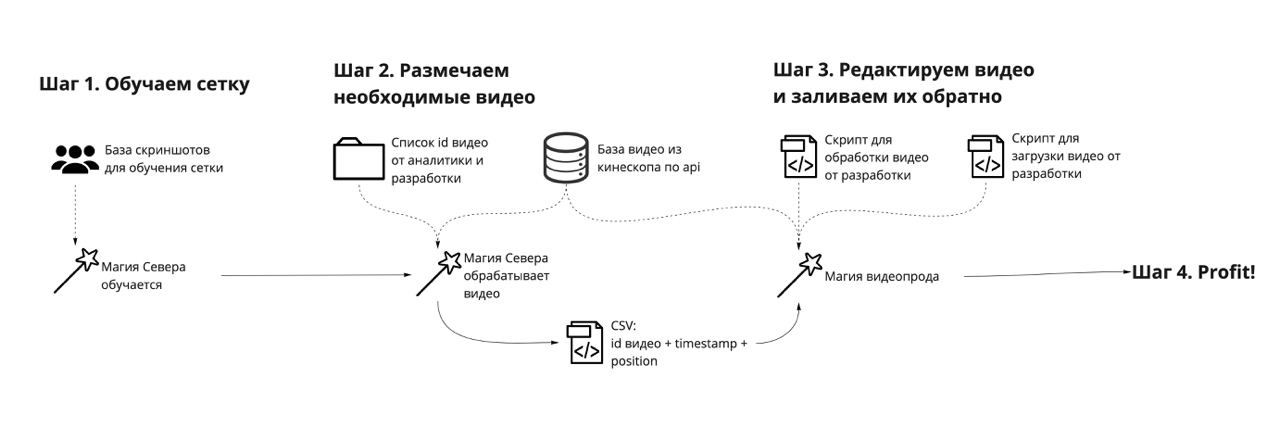
Удалили логотипы запрещённых сетей всего за 28 дней
В результате мы получили массив CSV-файлов с координатами бибоксов, соответствующих координатам логотипов на видео. Также были указаны start time и finish time — c какого момента и по какой нужно закрашивать каждый квадратик. Полученные бибоксы оставалось только передать в алгоритм, который вырезал запрещённую символику из видео.

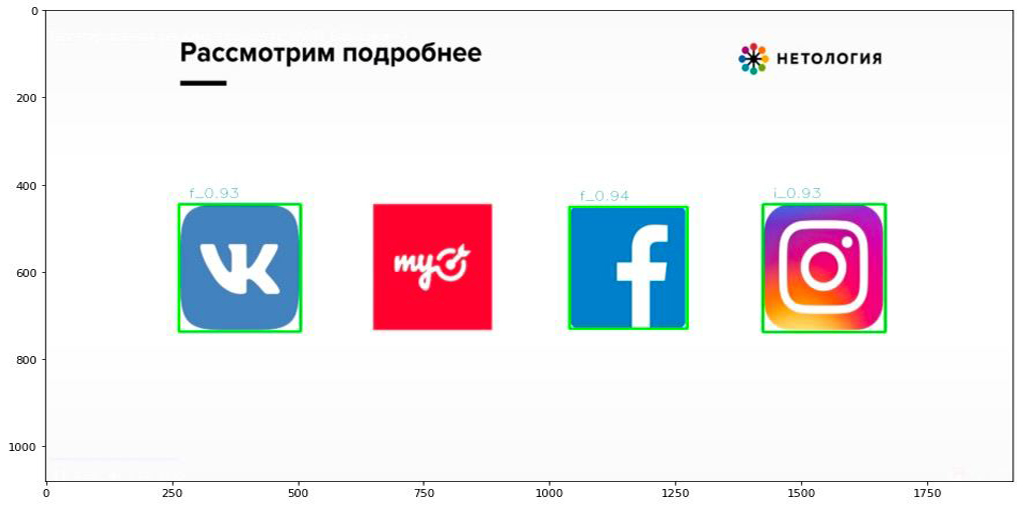

Нам дали файлы с разметкой, где на каждом видео находятся логотипы. Мы уже написали скрипт, который запускал программу и вырезал их. Эта работа продолжалась до середины мая. После этого мы до конца мая заливали изменённые файлы в Кинескоп.

Владимир Семенюк
CTO Нетологии
Всего мы обработали алгоритмом 26 547 видеофайлов общей длительностью 15 472 часа (644 дня), где нашли бибоксы с нужными логотипами. Работали только с активными курсами из Кинескопа — это 16 922 видео (7 245 часов). 71 видео не удалось скачать — это всего 15,6 часов. Логотипы запрещённых сервисов убрали в 11 114 файлах, что соответствует 6 000 часов видеоконтента.
Что такое 6 000 часов контента
Чтобы понять, что такое 6 000 часов готового контента, вы должны в один прекрасный день сесть и посмотреть всю «Санта-Барбару» 4 раза подряд.
Мы работали над удалением упоминания запрещённых сетей из всех наших продуктов с 25 марта по 21 апреля, то есть выполнили задачу менее чем за месяц. Для настолько сжатых сроков наше решение было единственно приемлемым. Чтобы просмотреть более 15 000 часов видеоматериала своими глазами, потребовалось бы несколько лет.
Конечно же, мы визуально удостоверились в результате работы на выборке из видео. Полный просмотр библиотеки видеоконтента человеком — это долго и бессмысленно. Пока что ничего пропущенного не попалось. Но даже если где-то лежит одно видео с одним логотипом, за это санкций не будет. Основной вопрос в управлении рисками. Опасно оставить лого на главной странице или во всех видео. Если регулятор обнаружит пропущенный нами логотип, то мы сможем поблагодарить его за помощь и оперативно убрать ненужное изображение по требованию.
Наш «экстремальный» опыт по решению сверхсрочной задачи оказался более чем удачным. Хотелось бы применять ИИ и для более масштабных проектов в будущем. Сейчас у нас ждёт апробации усовершенствованный вариант нейросети с более высоким показателем Precision: мы планируем пройтись им ещё раз по всему массиву данных, чтобы снизить вероятность ложных срабатываний.
*Компания Meta, а также её продукты Facebook и Instagram, которые упоминаются в этой статье, признаны экстремистскими и запрещены на территории РФ.