

Автор статьи: Роман Козлов
Руководитель курса BI-аналитика
Введение
В наше время объемы информации растут неимоверными темпами. С каждым днем, все больше и больше данных генерируется и хранится в компьютерах, смартфонах, облачных сервисах и т.д.
Рост объемов хранения данных в последние годы привел к развитию и использованию более сложных и гибких структур для их хранения. Одной из таких структур является JSON (JavaScript Object Notation), который быстро стал популярным и широко используется благодаря своей легкости в чтении и гибкости. JSON позволяет организовывать данные в виде вложенных ключ- значение пар, что позволяет эффективно хранить и передавать структурированные данные.
Вложенные структуры данных в формате JSON встречаются в самых разных областях. Например, они используются в API для обмена информацией между клиентами и серверами, в NoSQL базах данных для хранения и обработки больших объемов полуструктурированных данных, а также в различных приложениях и сервисах, где требуется гибкость и эффективность в работе с данными. Все это делает важным умение обрабатывать и анализировать сложные структуры данных, такие как JSON, и интегрировать их в процессы обработки и анализа данных с использованием инструментов, таких как Pandas.
В этой статье мы рассмотрим различные подходы к работе со вложенными структурами данных в Pandas, а также обсудим процесс нормализации JSON- структур. На примерах мы продемонстрируем, как можно эффективно извлекать и обрабатывать вложенные данные, преобразовывая их в удобный для анализа формат.
Иерархическая структура в JSON формате данных.
JSON (JavaScript Object Notation) был разработан в начале 2000-х годов Дугласом Крокфордом как простой и удобный формат обмена данными.
Основная идея заключалась в том, чтобы предоставить легковесный и понятный формат для представления структурированных данных, который можно использовать как в браузерах, так и на серверах. JSON произошел от подмножества языка программирования JavaScript, но со временем стал независимым от него, и теперь поддерживается многими другими языками программирования.
Одной из причин, по которой JSON стал популярным форматом хранения данных, является его простота и удобочитаемость как для людей, так и для компьютеров. JSON использует структуру ключ-значение и поддерживает вложенность, что позволяет эффективно хранить иерархические данные. Такая гибкость делает JSON подходящим для разнообразных приложений, включая обмен данными между сервером и клиентом, хранение конфигурационных файлов и даже в качестве альтернативы традиционным реляционным базам данных.
JSON предоставляет возможность комбинировать различные типы данных, такие как числа, строки, булевы значения, списки и объекты (словари), что позволяет представлять сложные структуры данных и облегчает обмен данными между различными системами и языками программирования.
Из-за гибкости и удобства в представлении иерархических данных в структуре json-объектов часто встречаются такие комбинации данных как списки словарей
Списки словарей в JSON-структурах имеют ряд преимуществ:
Порядок элементов: В отличие от обычных словарей, списки поддерживают порядок элементов, что позволяет сохранять последовательность данных.
Гибкость: Списки словарей могут содержать различное количество элементов и словарей с различным набором ключей, что позволяет хранить данные разной структуры и сложности.
Поддержка вложенности: JSON позволяет хранить вложенные структуры данных, такие как списки словарей внутри других словарей или списков. Это позволяет представлять иерархические данные, такие как деревья или графы.
Json-объект с использованием структуры списка словарей может выглядеть следующим образом:
[
{
"id":1
"name":"Alice",
"subjects":[
{
"subject":"math",
"score":85
},
{
"subject":"history",
"score":90
}
]
},
{
"id":2,
"name":"Bob",
"subjects":[
{
"subject":"math",
"score":95
},
{
"subject":"history",
"score":88
}
]
}
]
Каждый элемент списка представляет собой словарь с информацией о студенте, а внутри каждого словаря находится список словарей subjects, содержащий информацию об оценках студента по разным предметам. Такая структура позволяет удобно хранить и обмениваться информацией о студентах и их оценках.
Метод раскрытия иерархии из списка словарей. Метод explode
Преобразование списка словарей в привычный нам табличный формат Dataframe из Pandas может быть сложным, особенно если структура данных неоднородна или содержит несколько уровней вложенности. В таких случаях, можно применять метод explode, чтобы преобразовать данные в удобный для анализа формат.
Метод explodeв Pandas предназначен для преобразования столбцов с вложенными списками или списками словарей в отдельные строки, копируя при этом значения остальных столбцов. Это позволяет упростить структуру данных для дальнейшего анализа. В случае, если в JSON-структурах есть списки словарей, метод explode может быть особенно полезным.
Рассмотрим пример работы с методом explodeна примере JSON-структуры, содержащей списки словарей. Предположим, у нас есть JSON-объект из предыдущего примера:
your_json_string = [
{
"id": 1,
"name": "Alice",
"subjects": [
{
"subject": "math",
"score": 85
},
{
"subject": "history",
"score": 90
}
]
},
{
"id": 2,
"name": "Bob",
"subjects": [
{
"subject": "math",
"score": 95
},
{
"subject": "history",
"score": 88
}
]
}
]
Сначала импортируем необходимые библиотеки и загрузим JSON-данные в Pandas DataFrame:
import pandas as pd
import json
data = json.loads(your_json_string)
df = pd.DataFrame(data)Получим Dataframe, выглядящий следующим образом:

Чтобы развернуть столбец subjects, который содержит списки словарей, применим метод explode :
exploded_df = df.explode("subjects",ignore_index = True)Теперь наш DataFrame выглядит так:

Как видно, столбец subjects теперь содержит отдельные словари, а не списки словарей. Это упрощает дальнейшую обработку и анализ данных, поскольку теперь каждая строка соответствует отдельному словарю из исходного списка.
Нормализация данных. Метод json_normalize
Следующим шагом может быть дополнительное преобразование этих словарей в отдельные столбцы, чтобы сделать данные еще более удобными для анализа и визуализации. Для решения этой задачи можно использовать метод json_normalizeиз библиотеки Pandas для преобразования JSON-структур в табличный формат.
pd.json_normalize(exploded_df['subjects']) С помощью метода pd.json_normalizeнормализуются данные внутри столбца subject, где хранятся вложенные данные по успеваемости студентов по предметам.

Для объединения исходного DataFrame exploded_df с нормализованным DataFrame, созданным из столбца subjects , используем метод pd.concat().
Объединяем данные по горизонтали с использованием параметра axis=1 и не забываем с помощью метода drop() удалить столбецsubjectsиз исходного DataFrame ,т.к. они будут просто дублировать нормализованные данные.
pd.concat([exploded_df.drop('subjects', axis = 1), \
pd.json_normalize(exploded_df['subjects'])], axis = 1)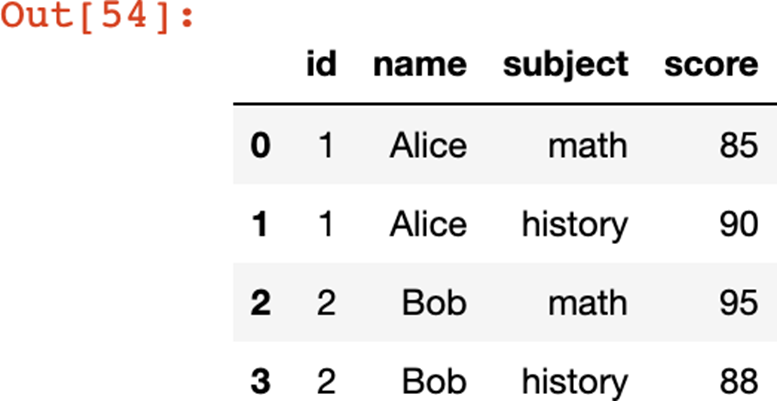
Так с помощью сочетания методов explode и json_normalize мы получили из сложной json_структуры, содержащей внутри ключей значения в виде списков словарей, понятную и удобную для аналитики табличную форму записи данных.
Стоит отметить, что методjson_normalizeприменяется к данным словарного типа, поэтому в качестве аргумента мы передали в него не весь датафрейм, а только тот столбик, данные внутри которого как раз организованы таким образом.
Заключение
В данной серии статей мы изучили множество методов и техник обработки и анализа данных с использованием Python и библиотеки Pandas. Охватывая широкий спектр проблем и задач, мы осветили различные аспекты работы с данными, такими как разделение данных на интервалы, квантильное разделение, применение скользящих окон для вычислений, смещение данных для временных рядов, преобразование вложенных структур данных, нормализация сложных JSON-структур.
Использование методов, описанных в серии статей, позволяет углубить подход к анализу исследуемых данных и облегчить работу с ними. Они предоставляют обширный инструментарий для обработки, очистки и преобразования данных, что является важным этапом в любом проекте анализа данных.
Разделение данных на интервалы и квантильное разделение помогают в создании сегментов или групп данных, что может быть полезным для различных целей, таких как идентификация групп клиентов, определение диапазонов значений показателей и выявление статистических закономерностей. Эти методы также могут помочь упростить анализ данных, путем преобразования непрерывных значений в дискретные категории.
Применение скользящих окон и смещение данных для временных рядов являются ключевыми методами при работе с последовательностями данных. Они позволяют определить тренды, сезонные изменения и другие особенности временных рядов, а также могут быть использованы для создания моделей прогнозирования и оценки их точности.
Работа с вложенными структурами данных и JSON-структурами становится все более актуальной из-за роста сложности и разнообразия источников данных. Методы преобразования и нормализации этих структур позволяют аналитикам извлекать полезную информацию из сложных и вложенных данных, облегчая их обработку и интеграцию с другими наборами данных.
Освоение и использование всех этих методов в комбинации с другими инструментами анализа данных позволяет углубиться в изучение исследуемых данных и выявить скрытые закономерности и взаимосвязи. Это, в свою очередь, может привести к новым инсайтам, улучшению принятия решений и оптимизации процессов, основанных на данных.
В завершение хочу порекомендовать бесплатный вебинар, на котором мои коллеги расскажут о том, что такое гипотезы и правильном их формулировании. Кому и когда подойдут А/В - тесты и когда А/В тесты не подходят? А также расскажут про альтернативные способы проверки гипотез.
Вебинар подойдет: аналитикам, менеджерам продукта, маркетологам.