
Это 5-я статья цикла по разработке, управляемой моделями. В предыдущих статьях мы уже разобрались с метамоделями, валидацией моделей, некоторыми нотациями для моделей (диаграммы и таблицы). Всё это было в рамках пространства моделирования MOF. Сегодня мы построим мост в пространство моделирования EBNF – познакомимся с текстовой нотацией для MOF-моделей.
Введение
Вообще на тему разработки языков программирования общего назначения и предметно-ориентированных языков очень много информации. Каждый, кто этим интересовался, наверняка имеет общее представление о лексерах, парсерах, синтаксических деревьях и т.п. Но мы подойдем к этому немного с другой стороны. Мы не будем рассматривать разработку DSL вообще, нас она интересует только с точки зрения модельно-ориентированной разработки.
Примечание
Честно говоря, введение получилось какое-то мозговыносное. Оно ориентировано в основном на специалистов по разработке, управляемой моделями. Можно его пролистать.
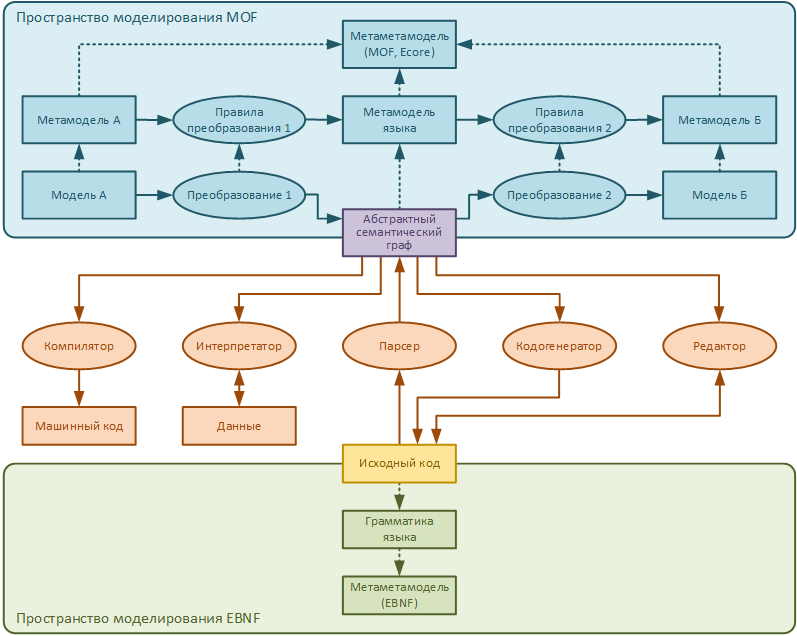
На рисунке красным, желтым, фиолетовым и зеленым цветами обозначено то, что обычно рассматривается в теории языков программирования. На языке EBNF (или каком-то другом) разрабатывается грамматика языка. Затем программисты пишут исходный код в соответствии с грамматикой. Исходный код скармливается парсеру, который преобразует текст программы в некоторое внутреннее представление (назовём его абстрактный семантический граф). Затем этот граф используется интерпретатором, компилятором, редактором или кодогенератором.
Это очень упрощенная и схематичная классика теории языков программирования. Мы не будем слишком подробно её рассматривать.
Параллельно со всем этим есть другая область – модельно-ориентированная разработка, которой посвящен данный цикл статей.
В модельно-ориентированной разработке совершенно всё от мыслей в голове разработчика до исходного кода, модульных тестов или документации рассматривается как модель (это основная, первичная сущность). А процесс разработки – это преобразование одних моделей в другие.
- Например, сначала в сознании разработчика возникает некий образ (модель) будущей программы.
- Затем он преобразует этот мысленный образ в UML-модель.
- На основе UML-модели пишет исходный код (тоже модель с точки зрения модельно-ориентированной разработки).
- Для исходного кода пишет модульные тесты (и это модель).
- Пишет документацию (всё – модель).
Некоторые из этих преобразований легко автоматизировать, другие – сложнее или в ближайшей перспективе вообще невозможно. Но сути это не меняет – есть только модели и преобразования моделей – больше ничего (на самом деле, преобразования – это тоже модели, но об этом в следующих статьях).
Некоторые модели очень похожи друг на друга. Например, все UML-модели строятся по определенным правилам в единой нотации (у них общая метамодель – UML). Какие-нибудь BPMN- или ER-модели уже отличаются от UML. Но, тем не менее, они гораздо ближе к UML чем исходный код или мысли программиста.
Это связано с тем, что UML, BPMN и ER – это метамодели, построенные на основе одной метаметамодели MOF. А грамматика (метамодель) языка программирования построена на другой метаметамодели – EBNF. Мысли программиста соответствуют тоже некоторой метамодели, которая соответствует некоторой метаметамодели, которая на данный момент совершенно неформализуемая.
Каждая метаметамодель образует своё пространство моделирования, которое достаточно сильно отличается от других.
Примечание
Если вы не понимаете о чём я толкую, то можете прочитать первую статью цикла про OCL и метамодели. А также статью про пространства моделирования.
Если необходимо преобразовывать модели внутри одного пространства моделирования (например, MOF), то это элементарно. Есть соответствующие спецификации и инструменты, к которым мы вернёмся в следующей статье.
Но если необходимо а) преобразовать исходный код в UML или б) из BPMN-моделей формировать модульные тесты или документацию, то это сделать уже несколько сложнее. Для этого нам нужен мост между двумя пространствами моделирования. И тут к нам на помощь приходит теория языков программирования.
В данной статье мы рассмотрим метамодель одного очень простого предметно-ориентированного языка (синий блок на рисунке), опишем его грамматику (зеленый блок на рисунке). А также сгенерируем (в модельно-ориентированной разработке вообще не очень принято писать код вручную парсер и кодогенератор – мост между пространствами моделирования MOF и EBNF. Также сгенерируем редактор этого языка, в будущем он нам не понадобится, но пусть будет.
Для Eclipse Modeling Framework есть несколько инструментов, которые могут нам с этим помочь.
MOF Model to Text Transformation Language (Acceleo)
Это язык шаблонов для генерации текста из MOF-моделей, описанный в спецификации OMG. Acceleo – это реализация спецификации OMG. Спецификация не обновлялась с 2008 года, однако, Acceleo успешно используется во многих проектах. Язык очень простой, может быть и не нужно в нём ничего обновлять. Мы рассмотрим его в одной из следующих статей более подробно.
Плюс этого языка в том, что он позволяет достаточно легко формировать из моделей текст. Если нужно по-быстрому сформировать из UML- или ER-модели SQL-запросы или сделать выгрузку из модели в CSV-формате, то этот язык оптимален.
Основной недостаток заключается в том, что этот мост односторонний. Он не позволяет распарсить текст и превратить его обратно в модель. Также приходится уделять много внимания форматированию шаблонов (пробелам, переводам строк), чтобы результирующий текст был правильно отформатирован. При этом сами шаблоны становятся не очень читаемыми.
Кстати, Acceleo – это фактически шаблонная надстройка над OCL. Если вы читали эту статью, то для освоения Acceleo вам остаётся узнать ещё несколько конструкций.
EMFText
EMFText – это уже гораздо более интересная штука, чем Acceleo. Вы описываете метамодель и синтаксис языка. В итоге получаете двунаправленный мост между пространствами моделирования MOF и EBNF. Для вас автоматически формируется парсер (из текста в модель), кодогенератор (из модели в текст), а также редактор (с подсветкой синтаксиса и автодополнением) и заготовки для компилятора, интерпретатора и отладчика языка.
Тут есть примеры реализованных с помощью EMFText языков.
В данной статье мы будем использовать EMFText.
Xtext
Xtext по функциональности аналогичен EMFText. Отличается более активным коммьюнити. И подходом к генерации парсера и кодогенератора, которые зависят от runtime-библиотек Xtext. В отличие от EMFText, который нужен только в design-time и не нужен в runtime. По этой причине в наших проектах мы используем именно EMFText, а не Xtext.
Epsilon Generation Language
Аналог Acceleo для Epsilon.
Human Usable Textual Notation
Также стоит отметить OMG HUTN. Это текстовый синтаксис для сериализации MOF-моделей. Можете воспринимать его как JSON для MOF-моделей. Для Epsilon существует его реализация. Однако, нам эта штука не подходит, потому что нам потребуется описывать произвольный синтаксис, а не только с фигурными скобками.
Немного теории
Прежде чем перейти к практике всё-таки потребуется немного теории.
Примечание
Этот раздел не претендует ни на полноту охвата, ни на точность. Всё описывается очень упрощенно и схематично, только чтобы были понятны последующие разделы. Если вас интересует теория языков программирования, то лучше обратиться к источникам, которые посвящены этой теме.
Мы строим мост между пространствами моделирования EBNF и MOF. С одной стороны моста исходный код, с другой – некая модель программы (для определенности будем называть её абстрактный семантический граф).
Обычно абстрактный семантический граф скрыт от программиста. Как именно он устроен – вопрос реализации компилятора или интерпретатора. Программисты с этим графом напрямую не работают, они работают только с исходным кодом.
В модельно-ориентированной разработке абстрактный семантический граф, наоборот, играет ключевую роль. Это уже не какая-то техническая внутренняя структура парсера, а модель с которой будет работать программист. Для программиста важно, как именно эта модель устроена, на сколько она удобна.
Примечание
Конечно, когда программисты пользуются рефлексивными возможностями языка, они работают именно с моделью программы, а не исходным кодом. Но при этом они, наверное, сами не понимая этого, попадают в область модельно-ориентированной разработки. Они рассматривают программу как модель.
На рисунке схематично показано как работают парсер и кодогенератор языка.

Лексический анализ
Сначала производится лексический анализ исходного кода, в результате которого текст разбивается на последовательность токенов. Обычно лексер выделяет токены с помощью контекстно-независимых регулярных выражений. Именно по этой причине в языках
- существуют зарезервированные слова, которые нельзя использовать в идентификаторах, чтобы лексер мог отличить ключевое слово от идентификатора;
- текстовые литералы заключаются в кавычки, чтобы лексер мог отличить их от зарезервированных слов или идентификаторов;
- идентификаторы не могут начинаться или полностью состоять из цифр, иначе лексеру было бы сложно понять идентификатор это или числовой литерал.
Т.е. регулярные выражения для разных видов токенов по возможности не должны пересекаться. К сожалению, иногда они всё-таки пересекаются. Иногда это не проблема. А иногда это приводит к усложнению грамматики языка – мы столкнёмся с такой ситуацией в следующей статье про парсер SQL.
Синтаксический анализ
Затем производится синтаксический анализ последовательности токенов. Парсер, глядя в грамматику языка, упорядочивает токены в конкретное синтаксическое дерево. По структуре это дерево идентично EBNF-грамматике языка:
- для начального нетерминального символа строится корневой узел дерева,
- для других нетерминальных символов строятся внутренние узлы дерева,
- для терминальных символов (токенов, лексем) строятся листовые узлы дерева.
Упрощение конкретного синтаксического дерева
С конкретным синтаксическим деревом обычно очень неудобно работать, даже для очень простых языков оно получается очень глубокое.
В одной из следующих статей мы, вероятно, рассмотрим язык для арифметических выражений. Вы увидите, что конкретное синтаксическое дерево для такого языка напоминает Пизанскую башню.
Для простых языков достаточно удалить лишние промежуточные этажи башни. Для более сложных языков требуются более сложные упрощения. В итоге мы получаем абстрактное синтаксическое дерево.
У нас каждый узел дерева будет объектом определенного класса. Хотя, вообще, это не обязательно, мы вполне могли бы обойтись без классов и объектов, представив дерево, например, в виде XML-документа. Но нам нужна именно объектная модель, потому что MOF, к которому мы движемся объектный. Если бы мы строили мост к какому-то пространству моделирования отличному от MOF, то нам была бы нужна не объектная модель программы, а какая-то другая.
Семантический анализ
Очевидно, что программу, написанную на относительно сложном языке, мы не сможем представить в виде дерева. Например, если этот язык позволяет объявлять переменные, классы, типы, функции, а потом ссылаться на них, то при разрешении таких текстовых ссылок мы получаем абстрактный семантический граф.
Кодогенерация
Кодогенерация – это обратный парсингу процесс, когда из некоторого абстрактного представления программы (например, в виде абстрактного семантического графа) формируется текстовое представление программы.
Есть два подхода к кодогенерации: шаблоны и универсальный кодогенератор.
При использовании шаблонов пишется примерный текст будущей программы. Например, имена классов, переменных, функций в этом тексте заменены на специальные последовательности символов, вместо которых впоследствии подставляются фактические имена. Очевидно, что произвольный код с помощью шаблонов не сгенерируешь.
Универсальный кодогенератор принимает на вход некоторую модель программы (например, абстрактный семантический граф), а на выходе выдаёт соответствующий исходный код. Таким образом можно сгенерить какой угодно код. Однако реализовать универсальный кодогенератор гораздо сложнее, чем шаблон. Также могут возникнуть сложности с форматированием результирующего кода. Нужны либо дополнительные аннотации в модели, содержащие информацию о пробелах, переводах строк и т.п. Либо нужен форматировщик кода, который тоже нужно писать или где-то брать. В варианте с шаблонами это не нужно, вы прямо в шаблоне форматируете всё как надо.
К счастью, EMFText автоматически генерирует кодогенератор с простейшими возможностями форматирования кода.
Настройка
Как обычно, понадобится Eclipse Modeling Tools. Установите последнюю версию EMFText отсюда http://emftext.org/update_trunk.
Создание проекта
В отличие от предыдущих статей готового проекта нет. Да, он и не нужен, воспользуемся проектом, который создаётся по умолчанию (File -> New -> Other… -> EMFText Project).

В папке metamodel вы увидите заготовки для метамодели языка (myDSL.ecore) и его грамматики (myDSL.cs). Два этих файла полностью описывают язык. Почти всё остальное генерируется из них.

В данной статье мы ограничимся этим простым демонстрационным DSL.
Метамодель языка
Метамодель – это то о чём язык. Например, метамодель языка Java будет содержать метаклассы: класс, метод, переменная, выражение и т.д. Вы не можете описать на языке что-то, чего нет в его метамодели. Например, в метамодели Java 7 нет лямбда-выражений. Поэтому они недопустимы в коде, который пишется под Java 7.
На следующем рисунке изображена метамодель демонстрационного предметно-ориентированного языка, которую сгенерировал для нас EMFText.

Примечание
Если вы не понимаете, что изображено на рисунке, то можете прочитать статью про Eclipse Modeling Framework.
Наш предметно-ориентированный язык позволяет описывать некоторую модель сущностей (EntityModel), которая состоит из типов (Type) двух видов: сущности (Entity) и типы данных (DataType). Сущности могут быть абстрактными (abstract). У сущностей могут быть свойства (Feature) трёх видов (FeatureKind): атрибуты (attribute), ссылки (reference) и составные части (containment). Свойства очень простые, у них нет даже множественности.
По идее, атрибуты должны ссылаться только на типы данных. А ссылки и составные части должны ссылаться только на сущности. Но в данной метамодели на структурном уровне это никак не ограничивается. Вы вполне можете сделать тип данных составной частью некоторой сущности или можете в качестве типа атрибута указать сущность вместо типа данных. Что, наверное, не очень правильно. Исправить это можно двумя способами: 1) на структурном уровне или 2) с помощью дополнительных ограничений.
В первом случае для каждого вида свойств создаётся отдельный метакласс (именно так реализована сама метаметамодель Ecore). Т.е. удаляем перечисление FeatureKind, удаляем ассоциацию type, метакласс Feature делаем абстрактным и наследуем от него три метакласса: Attribute, Reference и Containment. Первому добавляем ссылку на DataType, а второму и третьему – на Entity.
Второй способ описан в статье про OCL.
Мы не будем исправлять этот недочёт. Более того, далее он даже поможет нам разобраться с механизмом разрешения ссылок.
Запуск редактора языка
Итак, мы более-менее разобрались с метамоделью демонстрационного предметно-ориентированного языка, который сгенерировал для нас EMFText. Прежде чем перейти к описанию синтаксиса этого языка, посмотрим пример исходного кода.
Для этого создайте и запустите второй экземпляр Eclipse (Run -> Run Configurations…):

Во втором экземпляре Eclipse создайте новый myDSL-проект (File -> New -> Other… -> EMFText myDSL project):

На рисунке ниже вы видите пример кода, написанного на myDSL. Как видите, наш предметно-ориентированный язык действительно позволяет описывать сущности, свойства, типы данных.
Слева снизу синтаксическое дерево, которое соответствует метамодели языка. Снизу справа свойства одного из узлов дерева, которые также соответствуют метамодели. Если вы хотите получить какое-то другое синтаксическое дерево (добавить в него новые виды узлов, новые свойства узлов), то необходимо изменить метамодель языка.

Вы видите, что в редакторе есть подсветка синтаксиса. Позже мы её несколько усовершенствуем.
Также через Ctrl + Space вызывается автодополнение, которое по умолчанию работает не так как хотелось бы. Для атрибутов должны предлагаться только типы данных, а не сущности. Позже мы это исправим.

Описание конкретного синтаксиса
Теперь, когда вы увидели пример кода на тестовом DSL, вернёмся к описанию синтаксиса в файле myDSL.cs.

В строке 1 указано расширение файлов описываемого DSL.
В строке 2 указано пространство имен метамодели описываемого DSL.
В строке 3 указан начальный нетерминальный символ грамматики и по совместительству корневой метакласс синтаксического дерева.
В строке 6 указан один из параметров EMFText. Таких параметров порядка сотни, вы можете самостоятельно познакомиться с ними в руководстве.
Далее идут правила грамматики языка. Вы видите, что язык описания правил очень похож на EBNF. Однако, имена нетерминальных символов в левой части правила должны совпадать с именем некоторого метакласса из метамодели языка. А имена (не)терминальных символов в правой части правила должны совпадать с именами некоторых свойств этого метакласса.
Множественность символов в правой части правил должна соответствовать множественности соответствующих свойств в метамодели.
Разберём правила подробней.
В строке 10 мы утверждаем, что любой код на нашем DSL должен начинаться с ключевого слова «model», после которого может следовать описание нескольких типов. Причём, как вы должны помнить, в метамодели есть типы двух видов: сущности (Entity) и типы данных (DataType).
В строке 11 описан синтаксис для сущностей. Описание сущности может начинаться с ключевого слова «abstract», в этом случае одноименное свойство сущности в синтаксическом дереве будет установлено в истинное значение. Затем обязательно должно следовать ключевое слово «entity».
Затем следует имя сущности, которое будет сохранено в свойстве name. В квадратных скобках должен указываться вид токена для имен. В данном случае он не указан, поэтому парсер будет ожидать токен по умолчанию – TEXT. К токенам мы вернемся чуть позже.
Затем в фигурных скобках должны перечислять свойства (features) сущности. Это нетерминальный символ – в грамматике для свойств есть собственное правило (строка 13), а в метамодели – отдельный метакласс. Поэтому тут нет квадратных скобок, нет возможности указать вид токена.
В строке 12 описан синтаксис для типов данных. Описание типа данных должно начинаться с ключевого слова «datatype», после которого следует имя типа и точка с запятой.
В строке 13 описан синтаксис для свойств сущностей. Описание свойства может начинаться с одного из трёх ключевых свойств («att», «ref» или «cont»). В синтаксическом дереве в зависимости от указанного ключевого слова свойство kind узла примет одно из значений перечисления FeatureKind.
Далее должны следовать тип свойства, имя свойства и точка с запятой. Причём, тип свойства в коде указывается как строка символов, но в синтаксическом дереве ссылка по имени превращается в физическую ссылку на соответствующий тип. Таким образом, при парсинге мы получаем граф, а не дерево. К разрешению ссылок мы ещё вернёмся позже.
Вообще, что именно мы получаем при парсинге – не очень тривиальный вопрос. С одной стороны, полученная структура практически полностью дублирует грамматику языка и, вроде как, это конкретное синтаксическое дерево. С другой стороны, EMFText разрешает символьные ссылки, превращая конкретное синтаксическое дерево в абстрактный семантический граф. Также он позволяет прикручивать к парсеру постобработчики, с помощью которых можно упрощать модель.
Иными словами, парсер выдаёт на выходе какой-то гибрид конкретного синтаксического дерева и абстрактного семантического графа. Для такого простого языка это не очень принципиально. Но в следующей статье при разработке метамодели для SQL придётся снова вернуться к вопросу «какую метамодель мы делаем: конкретную или абстрактную?».
Добавление новых видов токенов
Теперь немного усовершенствуем DSL. В myDSL.cs после некоторых терминальных символов (name и type) стоят пустые квадратные скобки. Для таких символов используется токен по умолчанию TEXT с шаблоном
('A'..'Z'|'a'..'z'|'0'..'9'|'_'|'-')+Это значит, что имена сущностей могут полностью состоять из десятичных цифр или начинаться с минуса, что, наверное, не очень правильно.
Примечание
Также имена сущностей не могут содержать не латинские буквы, наверное, нашему языку не помешала бы поддержка юникода.
EMFText использует регулярные выражения ANTLR, которые поддерживают юникод, но не поддерживают классы символов. Поэтому придётся явно перечислять диапазоны допустимых символов. Пока не будем с этим заморачиваться.
Итак, пусть имена типов начинаются только с заглавной буквы латинского алфавита и не могут начинаться с других символов. А имена свойств – только со строчной буквы латинского алфавита.
Чтобы описать новые виды токенов, создаём раздел TOKENS (строки 9-16).

В строках 10-12 определены фрагменты токенов.
В строках 14 и 15 определены токены соответственно для имён типов и имён свойств.
В строках 20-22 в квадратных скобках указаны ожидаемые парсером токены.
Однако, есть проблема. Регулярные выражения для новых токенов пересекаются с токеном по умолчанию TEXT, о чём мы получаем предупреждение (см. рисунок выше). К чему это может привести?
Например, в исходном коде определена сущность «Car». Имя этой сущности соответствует обоим регулярным выражениям: TEXT и TYPE_NAME. Если лексер решит, что «Car» – это TYPE_NAME, тогда всё будет нормально. Но если он решит, что это TEXT, то на следующем этапе разбора исходного кода парсер выдаст ошибку типа такой: «После ключевого слова «entity» ожидается токен TYPE_NAME, а указан токен TEXT».
Примечание
Если вы не понимаете смысл предыдущего абзаца, то посмотрите рисунок в разделе «Немного теории» выше и прочитайте подразделы про лексический и синтаксический анализ.
Разрешить эту неопределенность можно несколькими способами:
- Положиться на то, что EMFText для более специфических токенов назначает по умолчанию больший приоритет. Т.е. сначала лексер будет искать TYPE_NAME и FEATURE_NAME, а потом TEXT.
- Задать приоритеты токенов вручную.
- Удалить лишние токены.
- Усложнить грамматику. Например, вместо «name[TYPE_NAME]» написать «name[TYPE_NAME] | name[TEXT]».
В данном случае, токен TEXT нам не нужен, поэтому мы его просто удалим. Для этого в строке 7 отключим, предопределенные токены: TEXT, LINEBREAK и WHITESPACE. Но два последних токена нам всё-таки нужны, поэтому определим их явно в строках 18 и 19.

Теперь кликните правой кнопкой мыши на проект в дереве слева и в появившемся контекстном меню выберите «Generate All (EMFText)». После перегенерации исходного кода запустите второй экземпляр Eclipse.
Теперь если вы напишите имя сущности со строчной буквы, то лексер интерпретирует его как имя свойства (FEATURE_NAME), а парсер выдаст ошибку, что ожидался токен TYPE_NAME.
Если вы начнёте имя атрибута с подчёрка «_», то лексер вообще не поймёт, что это за токен.

Подсветка синтаксиса
По умолчанию EMFText раскрашивает все ключевые слова фиолетовым цветом. Добавим немного больше цветов, для этого создайте секцию TOKENSTYLES (строки 22-27).

Перегенерируйте исходный код «Geneate All (EMFText)» и запустите второй экземпляр Eclipse.
Выглядит жутковато, но идею вы поняли :) Обратите внимание на то, что «car» раскрашивается синим, а не розовым цветом. Это связано с тем, что лексер выделяет токены с помощью контекстно-независимых регулярных выражений. Он не знает, что тут должно быть имя сущности, а не имя свойства.

Разрешение ссылок
Ранее я обращал ваше внимание на то, что автодополнение имён типов в определениях свойств сущностей работает не очень корректно. Для атрибутов (att) должны предлагаться только типы данных, а для ссылок (ref) и составных частей (cont) должны предлагаться только сущности.
Найдите в проекте org.emftext.language.myDSL.resource.myDSL класс FeatureTypeReferenceResolver, который отвечает за автодополнение и разрешение ссылок.
Метод resolve должен искать подходящие по имени типы. Если параметр resolveFuzzy имеет истинное значение, то метод должен искать типы, которые примерно подходят под заданную строку (это происходит при автодополнении имени типа). Иначе метод должен искать тип в точности с указанным именем.
Метод deResolve должен для ссылки в абстрактном семантическом графе возвращать её текстовое представление в исходном коде.
Вот, одна из реализаций разрешения ссылок на типы:
package org.emftext.language.myDSL.resource.myDSL.analysis;
import java.util.Map;
import java.util.function.Consumer;
import java.util.function.Predicate;
import java.util.stream.Stream;
import org.eclipse.emf.ecore.EReference;
import org.eclipse.emf.ecore.util.EcoreUtil;
import org.emftext.language.myDSL.DataType;
import org.emftext.language.myDSL.Entity;
import org.emftext.language.myDSL.EntityModel;
import org.emftext.language.myDSL.Feature;
import org.emftext.language.myDSL.FeatureKind;
import org.emftext.language.myDSL.Type;
import org.emftext.language.myDSL.resource.myDSL.IMyDSLReferenceResolveResult;
import org.emftext.language.myDSL.resource.myDSL.IMyDSLReferenceResolver;
public class FeatureTypeReferenceResolver implements IMyDSLReferenceResolver<Feature, Type> {
// Ищем в модели типы с именем, указанным в параметре identifier
public void resolve(String identifier, Feature container, EReference reference, int position, boolean resolveFuzzy,
final IMyDSLReferenceResolveResult<Type> result) {
// Не самый удачный способ искать корень синтаксического дерева.
// Лучше у всех containment-ссылок в метамодели сделать обратную ссылку owner,
// и переходить к корню через container.getOwner().getOwner()
EntityModel model = (EntityModel) EcoreUtil.getRootContainer(container);
// Если разрешаем ссылку на тип у атрибута, то ищем типы данных,
// иначе ищем сущности
Predicate<Type> isRelevant = container.getKind() == FeatureKind.ATTRIBUTE
? type -> type instanceof DataType
: type -> type instanceof Entity;
Stream<Type> types = model.getTypes().stream().filter(isRelevant);
// С помощью этой функции будем добавлять подходящие типы в результаты поиска
Consumer<Type> addMapping = type -> result.addMapping(type.getName().toString(), type);
// Если поиск запущен из редактора при автодолнении имени, то ищем типы,
// которые начинаются на искомую последовательность символов без учёта регистра
if (resolveFuzzy) {
types.filter(type -> type.getName().toUpperCase().startsWith(identifier.toUpperCase()))
.forEach(addMapping);
}
// Иначе (если это не автодополнение), то ищем тип в точности с указанным именем
else {
types.filter(type -> type.getName().equals(identifier))
.findFirst()
.ifPresent(addMapping);
}
}
// Получаем текстовое представление ссылки на тип (его имя)
public String deResolve(Type element, Feature container, EReference reference) {
return element.getName();
}
public void setOptions(Map<?, ?> options) {
}
}Кодогенерация
С парсером и редактором в первом приближении разобрались. Осталась только кодогенерация.
Синтаксическое дерево в нижнем левом углу доступно только для просмотра. Чтобы получить возможность редактировать его, сохраните файл в формате xmi (File -> Save As…).
Если при этом произойдёт ошибка, что файл не может быть открыт с помощью MyDSLEditor, то проигнорируйте её и переоткройте xmi-файл. Вы увидите то же самое синтаксическое дерево, однако, теперь его можно редактировать.

Переименуйте сущность «Car» в «Vehicle» и установите истинное значение свойства «Abstract».
Сохраните xmi-файл с расширением myDSL. Закройте его и откройте снова:

Как видите, наши изменения синтаксического дерева учтены! Т.е. преобразование модели в текст (кодогенерация) работает.
Правда, при сохранении пропали переводы строк и некоторые пробелы.
Есть три способа добиться нормального форматирования генерируемого кода:
- Изменить метамодель, добавив каждому метаклассу ссылки на метакласс LayoutInformation из метамодели www.emftext.org/commons/layout. Я лично этого не делал и у меня ощущение, что при этом придётся считать количество требуемых пробелов, рассчитывать смещения в тексте и т.п. – выглядит очень сложно.
- Использовать отдельный форматировщик кода. Наверное, это оптимальный вариант при генерации Java-кода или чего-то, для чего уже есть готовый форматировщик.
- Добавить в грамматику языка несколько аннотаций, чтобы кодогенератор по умолчанию немного лучше форматировал код. Это самый простой вариант, так и сделаем.
В строки 30 и 31 добавлены аннотации «!0», «!1» и «#1». Эти аннотации игнорируются парсером, они предназначены для кодогенератора. Аннотация «#N» сообщает кодогенератору, что в данном месте необходимо вставить N пробелов. А аннотация «!N» обозначает перевод строки и N знаков табуляции.

Перегенерируйте исходный код «Geneate All (EMFText)» и перезапустите второй экземпляр Eclipse. Попробуйте снова сохранить модель в текстовом формате и убедитесь, что теперь код отформатирован лучше.
Заключение
После прочтения данной статьи вы должны по-новому взглянуть на разработку программного обеспечения – через призму моделей и преобразований моделей.
Модели можно представлять в разных нотациях (в виде диаграмм, таблиц, текста). С точки зрения разработки, управляемой моделями, предметно-ориентированный язык – это всего лишь одна из нотаций для некоторой метамодели.
С другой стороны, грамматика предметно-ориентированного языка – это метамодель в пространстве моделирования EBNF. А исходный код – модель в этом пространстве моделирования.
Парсер – это преобразование модели из пространства моделирования EBNF в модель в пространстве моделирования MOF или другом.
Кодогенератор – это обратное преобразование модели из семантико-ориентированного пространства моделирования (например, MOF) в пространство моделирования EBNF.
Также вы познакомились с одним из инструментов разработки языков программирования – EMFText.
Комментарии (22)

igor_suhorukov
18.11.2015 21:20+1Спасибо, интересная статья!
Знакомы с проектом sculptor?
Ares_ekb
18.11.2015 21:56+1Спасибо! В общих чертах представляю, но не использовал. Мы делаем идейно что-то подобное, но с другим назначением, и на входе немного другая модель, на выходе генерируется немного другой код.
Приходится часто сталкиваться со скепсисом. Для большинства людей EMFText, Xtext, QVTo и т.п. — это «какие-то сомнительные плагины, выдранные из не очень хорошей среды разработки Eclipse». И вообще, людям непонятно зачем нужны ещё какие-то языки, если то же самое можно написать на Java.igor_suhorukov
18.11.2015 22:19+1Приходится часто сталкиваться со скепсисом.
Такая особенность, понимаю…
Если группа специалистов пользуется удобным инструментом для решения своих задач, это не значит что эти инструменты будут популярными для всех. Для примера сравните популярность IDE Idea и MPS. Смиритесь и наслаждайтесь общением с теми кому полезно)
Тема действительно интересная!

Throwable
19.11.2015 15:09Хорошая демонстрация возможностей Xtext — это язык Xtend.
Но все-таки сейчас основная тенденция для метамоделирования — это создание DSL-ей в рамках самого же языка. В основном используются три метода:
1. Создание DSL на основе системы типов языка и вспомогательных API (Builders). Scala особенно этим пестрит. Есть еще Groovy DSL, на основе которого построен Gradle, etc… Синтаксис Java не особо способствует созданию собственных DSL, хотя с появлением лямбд ситуация немного улучшилась.
2. Доступ к синтаксическому дереву на этапе компиляции. Для Scala есть scala.meta, в Java есть для этого AST-трансформации.
3. Генерация кода в рантайме. Очень популярно у многочисленных фреймворков. В основном служат для прозрачного добавления функционала к уже готовой модели.
Ну и еще один очень неплохой метод — использовать стандартные средства XML: XSD для метамоделирования, XML для моделирования и XSLT для трансформации.Ares_ekb
19.11.2015 15:54Спасибо за комментарий, про Xtext я написал маловато. У него конечно больше отличий от EMFText. Для него есть язык описания выражений Xbase с трансляцией в Java-код. Xbase используется в Xtend, который вы упомянули. Также он используется в Xcore, о котором я писал немного раньше. И Xbase может использоваться в любом DSL, который транслируется в Java.
Вообще, если планируется создавать DSL на основе Java, то Xtext выглядит гораздо предпочтительней, чем EMFText. Но EMFText, на мой взгляд, проще и легче.
Я согласен, что DSL внутри языков сейчас очень популярны. Но не все DSL можно или нужно встраивать в какой-то язык программирования :) Например, SQL. В следующей статье я опишу парсер/генератор/редактор SQL на основе EMFText. А потом опишу транслятор из Anchor-моделей в SQL-код. Это как-раз пример задачи, в которой не нужно делать DSL внутри языка программирования.
XSLT отличная штука, но писать на нём сложные преобразования моделей не очень удобно. В одной из следующих статей я напишу про QVTo — это аналог XSLT для MOF-моделей. Кстати про отображение MOF-метамоделей в XSD-метамодели я тоже планирую статью. Если нужно парсить или генерить XML, то можно конечно делать что-то подобное, но можно проще.
guai
19.11.2015 20:24SQL впилили в C# и дотнетчики с него тащатся, linq который
Ares_ekb
19.11.2015 20:33Я сам в прошлом дотнетчик и тащился от linq :)
guai
19.11.2015 21:29я понял ваш камент так, что типа sql — пример того, что не надо встраивать в языки
Ares_ekb
20.11.2015 09:28Не точно выразился, имел в виду встраивание SQL в чистом виде. LINQ — уже не совсем SQL, а какая-то вариация. Например, в следующей статье нам понадобятся выражения для создания таблиц, а в LINQ их как-раз нет.
Кстати, есть примеры DSL, которые встраиваются в другие языки без изменений. Например, OCL встроен в Acceleo, QVTo, ATL. Или XPath встраивается в XSLT, XSD. Арифметические выражения в разных языках примерно одинаковые. Такие микроDSL очень клёвые тем, что позволяют при создании нового языка не изобретать уже существующие вещи.
Это наверное обратный подход тому, который описал выше Throwable. Мы не строим DSL на основе языка программирования общего назначения. А наоборот, создаём новый язык в который встраиваем существующий микроDSL.
guai
24.11.2015 17:00Вариация на тему первого пункта присутствует в цейлоне. Там любой вызов конструктора можно описать особым DSL-образным синтаксисом, позволяющим представлять деревья вообще без дополнительных телодвижений, и всё это со статической типизацией.

nomit
19.11.2015 08:40А вот такой вопрос, так как в проекте используется EMF, мы какую либо выгоду от этого имеем? Ну допустим вешая на какой либо класс emf адаптер, изменения будут слушаться? или как в Xtext модель постоянно уничтожается и создается заново?
Ares_ekb
19.11.2015 11:02Я не совсем понял вопрос :) Выгода от EMF или EMFText? Про смысл модельно-ориентированной разработки я планирую отдельную статью — в каких ситуациях стоит всё это использовать, в каких — нет.
Основная выгода от EMF — экономия времени на рутинном написании типового кода. Например, в одной из предыдущих статей мы описали модель в декларативном платформо-независимом виде:
Потратили на это не очень много времени. Затем нажали кнопку «сгенерировать исходный код» и получили целую кучу Java-классов, интерфейсов, фабрик со всякими геттерами, сеттерами и т.п.
Т.е. выгода:
- Экономия времени на написание типового кода.
- Сокращение вероятности ошибок в коде, потому что он генерится автоматически, уменьшена роль человеческого фактора.
- Упрощение сопровождения ПО. Например, через 50 лет (когда вместо Java будет какой-то более модный язык) мы просто снова нажмём кнопку «сгенерировать исходный код» и получим код уже на этом новом языке, не нужно будет переписывать тонны строк кода.
- Увеличение повторного использования. В этой статье мы использовали метамодель для генерации Java API и древовидного редактора, в этой статье эта же самая метамодель используется для создания графического редактора. Если мы захотим сделать DSL для таких моделей, то снова повторно используем ту же самую метамодель.
- Кросплатформенность. Можно генерить код на любом языке для любой платформы.
nomit
19.11.2015 11:25Про выгоду я понял, спасибо(имел ввиду EMF). Ну вот про адаптеры и отслеживания изменения в модели(через EAdapter).
Такой кейс: если мы перед запуском редактора (нашего DSL) помешаем слушателя(в понятиях EMF это EAdapter) на EntityModel.
Когда пользователь будет добавлять данные или еще как то изменить. Что будет происходить с моделью EntityModel? Она каждый раз будет заново создаваться (в xtext так)?Ares_ekb
19.11.2015 12:16Да, судя по всему, при любом изменении исходного кода он полностью парсится и создаётся новая модель.
Тут люди спрашивали про инкрементальный парсинг, но из коробки этого нет.
Я в основном пользовался парсером и кодогенератором, чтобы делать транслятор с одного языка на другой:
1) парсим код на языке 1 в AST
2) преобразуем это AST в AST для языка 2
3) преобразуем второе AST в код на языке 2
Редактор использовал только для отладки (чтобы посмотреть правильно ли работает парсер и т.п.).
А зачем отслеживать изменения в модели? Можно сделать постобработчик, который принимает новую модель после парсинга и что-то с ней делает.nomit
19.11.2015 12:35У меня задача стоит не совсем тривиальная. Необходим проекционный редактор в котором есть свой DSL, но не все данные можно ввести через этот DSL. И в самом редакторе когда мы встаем на какой либо объект(допустим в вашем примере пусть будет Entry) в PropertyView появляются редакторы таких скрытых сущностей. Ну и отсюда получается сложность: что если модель у нас перестаивается то сложно сохранять и сопоставлять такие данные. (не уверен что понятно описал)
Ares_ekb
19.11.2015 12:51А куда эти скрытые данные сохраняются?
Я бы попробовал разбить модель на две: 1) модель со скрытыми данными и 2) модель, которая генерится из исходного кода. Каждый раз при парсинге восстанавливал бы ссылки из 2-ой модели в 1-ую.nomit
19.11.2015 15:50Да в данный момент все модели разбиты на 2 модели.
Сейчас реализовано с помощью Xtext + EMF Compare.
Вот только с восстановлением ссылок проблема есть. Не всегда можно после парсинга найти соответствие между моделями.
Допустим в языке есть конструкция |xxxx| и в один прекрасный момент мы изменили ее на |yyyy| не как взаимно однозначно найти не получиться нет не ID не какого то другого поля.Ares_ekb
19.11.2015 16:02Ещё можно разрешать ссылки по контексту… Искать родительский объект с нужным ID, а потом дочерний нужного типа с определенным порядковым номером. Или искать не родительский, а предыдущий или последующий объект.
Или всё-таки сохранять эти скрытые данные в исходном коде, но скрывать средствами редактора, хотя я такого никогда не делал.
А что это за данные, если не секрет? Немного странно, что их можно редактировать в окне свойств, но нельзя в коде :)nomit
19.11.2015 16:14Пишу редактор шаблонный конструкций (типа регулярок). Основные пользователи это лингвисты, поэтому слишком сложный язык им не нужен.
Простой пример: ищем слова со всеми возможными окончаниями, слово |писал|.
В шаблона нам нужно указать, что в конце может быть(а может и не быть) окончания, с длинной от 0 до 1. Или это слово должно быть зависимо от регистра. — примерно такие данные хранятся в «метаинформациии», там еще много всяких кейсов, которые сложно описать с помощью языка.
А можно пример с ID, EMFText после построения умеет выставлять ID? Как он отнесется к обмену 2 объектов местами?Ares_ekb
19.11.2015 16:44Интересная штука, получается комбинированный редактор. Кстати, на что-то такое тут уже была ссылка (см. слайд на котором вместо switch/case в коде таблица).
EMFText обмен объектов местами не заметит: модель AST создаст с нуля, а о 2-ой модели со скрытыми данными он ничего не знает. Но в разрешателе ссылок можно реализовать какую угодно логику. В статье выше есть пример — класс FeatureTypeReferenceResolver. Метод resolve разрешает ссылку type у некоторого объекта класса Feature:
Для этого мы сначала от Feature (который передается в параметре container) переходим к EntityModel:
EntityModel model = (EntityModel) EcoreUtil.getRootContainer(container);
Потом находим в EntityModel некоторый Type с нужным идентификатором.
Но эта логика может быть совершенно другой. Во-первых, можем искать объект (на который хотим сослаться) в другой модели. Во-вторых, можем сделать что-то такое… Неважно какой идентификатор передали в параметре identifier. Вместо него смотрим порядковый номер текущего объекта класса Feature в AST. И потом ищем во второй модели нужный объект уже не по идентификатору, а с таким же порядковым номером.
Я не рекламирую EMFText, на самом деле в нём хватает косяков :) Но в Xtext, я думаю, это должно делаться аналогично.
Ares_ekb
20.11.2015 10:07По умолчанию Xtext (как и EMFText) разрешает ссылки по имени. Но это можно изменить, создав свой ILinkingService. Вот, обсуждение и пример.
kenoma
КДПВ просто великолепная!