
На наш взгляд, объектный язык ограничений (Object Constraint Language, OCL) должен знать каждый, кто занимается моделированием или кому интересна модельно-ориентированная разработка. Однако, он незаслуженно обделен вниманием в сети вообще, а, уж, в русскоязычном сегменте информации просто мизер. Что это за язык и зачем он нужен, описано в этой статье. Статья не претендует на фундаментальность, полноту охвата, точность определений и т.п. Её задача: 1) на простых примерах познакомить с OCL тех, кто никогда не слышал об этом языке, 2) а для тех, кто о нём слышал, возможно, открыть новые способы его применения.
Структурные и дополнительные ограничения
Начнём сразу с примера. Допустим мы разрабатываем программу типа Jira для учета проектов, задач, для распределения этих задач по сотрудникам. Модель данных для такой программы очень упрощенно может выглядеть так.
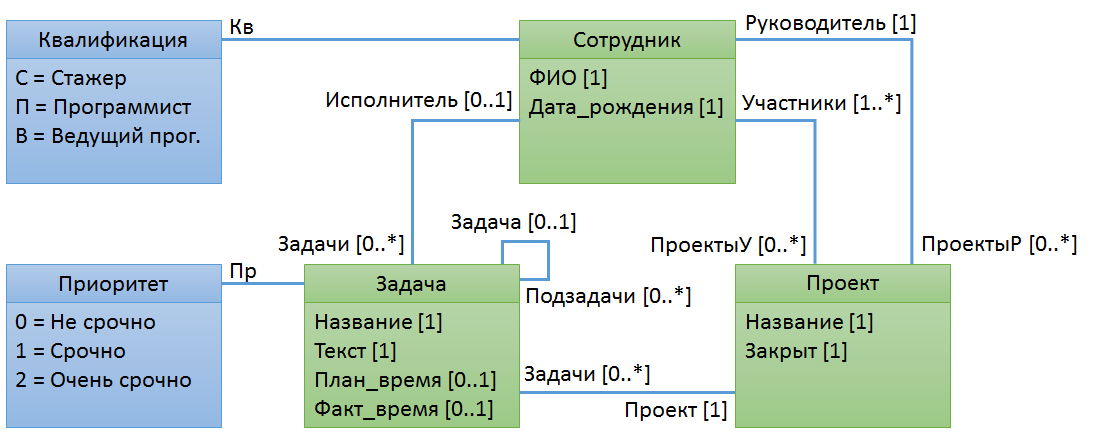
Нарисовав такую диаграмму, мы наложили ограничения на нашу предметную область: зафиксировали, что в ней могут существовать только сотрудники, задачи и проекты, что они обладают именно такими атрибутами, что они могут быть связаны именно такими связями. Например, в нашей предметной области у сотрудника обязательно должны быть ФИО и дата рождения. А у задачи или проекта таких атрибутов быть не может. Или исполнителем у задачи может быть только сотрудник, но не может быть исполнителем другая задача или проект. Это очевидные вещи, но важно понимать, что, создавая такую модель, мы именно формулируем ограничения. Такие ограничения иногда называют структурными ограничениями.
Однако, часто структурных ограничений при моделировании предметной области недостаточно. Например, нам может потребоваться ограничение, что руководитель проекта не может быть одновременно и участником проекта. Сейчас из этой диаграммы такое ограничение никак не следует. Приведем другие примеры (с подвохом ;-) ) дополнительных (не структурных) ограничений:
- Стажер не может руководить проектами
- Программист может руководить одним проектом, но при этом не может участвовать в других проектах
- Ведущий программист может руководить не более чем двумя проектами одновременно
- У проекта должен быть только один руководитель
- В одном проекте не могут участвовать полные тезки
- В закрытом проекте не может быть открытых задач (задача считается закрытой, если у неё выставлено фактическое время выполнения)
- Перед назначением исполнителя для задачи должно быть определено планируемое время выполнения
- Перед закрытием для задачи должно быть определено планируемое время выполнения
- У сотрудника в одном проекте может быть только одна открытая задача и не более 5 задач по всем проектам
- Сотрудник должен быть совершеннолетним
- ФИО сотрудника должно состоять из трёх частей (фамилия, имя и отчество), разделенных пробелами (пробелы не могут быть двойными, тройными и т.п.)
- Ведущего программиста не могут звать Зигмунд
- Фактическое время работы над задачей не может превышать планируемое более, чем в два раза
- Задача не может быть своей подзадачей
- Планируемое время выполнения задачи должно быть не меньше, чем время, запланированное на подзадачи
- … придумайте сами несколько ограничений ...
Резюме
Различные языки моделирования позволяют описывать структурные ограничения, накладываемые на предметную область:
- на виды объектов: объект может быть только экземпляром соответствующего класса (сотрудник не может обладать свойствами проекта, задачу нельзя сохранить в таблицу с сотрудниками и т.п.);
- на допустимые свойства и ассоциации;
- на типы: свойства могут принимать значения только определенного типа;
- на множественность: значения обязательных свойств/ассоциаций должны быть указаны, для свойств/ассоциаций с множественностью «1» не может быть указано несколько значений и т.п.
Дополнительные ограничения можно описывать с помощью дополнительных языков, таких как OCL.
Настройка Eclipse
Если вы хотите попробовать всё это на практике, то потребуется Eclipse. Если нет, то переходите к следующему разделу.
- Скачайте и распакуйте Eclipse, желательно Eclipse Modeling Tools. Если вы уже используете Rational Software Architect 9.0 (который основан на Eclipse), можете использовать его.
- Установите необходимые библиотеки:
- Для Eclipse. Выберите в меню Help -> Install Modeling Components. В появившемся окне выберите: «Graphical Modeling Framework Tooling», «OCL Tools» и не помешает «Ecore Tools».
- Для RSA 9.0. Скопируйте файлы org.eclipse.gmf.tooling.runtime_*.jar и org.eclipse.ocl.examples.interpreter_*.jar в папку «C:\Program Files\IBM\SDP\plugins\» (в зависимости от особенностей установки папка может быть немного другая).
- Установите плагины pm*.jar с тестовой метамоделью:
- Для Eclipse. Скопируйте эти файлы в папку «$ECLIPSE_HOME/dropins»
- Для RSA 9.0. Скопируйте эти файлы в папку «C:\Program Files\IBM\SDP\plugins\» (в зависимости от особенностей установки папка может быть немного другая). Папку dropins не рекомендуется использовать из-за каких-то багов.
- Перезапустите Eclipse. Выберите в меню File -> New -> Other… В строке поиска напишите «pm». Должны появиться «Pm Model» и «Pm Diagram».
- Вы можете либо самостоятельно создать тестовую модель, либо взять готовую
- Откройте консоль: Window -> Show View -> Other… Найдите в списке «Console».
- В окне консоли раскройте выпадающий список «Open Console» и выберите в нём «Interactive OCL» (см. рисунок ниже).
- Выберите любой объект на диаграмме и напишите в нижней части консоли «self», нажмите «Enter». Если всё настроено правильно, то вы увидите нечто подобное:

Если у вас не работает плагин с метамоделью, можете собрать его самостоятельно из исходных кодов. В нем используется относительно древняя версия GMF, чтобы он работал в RSA 9.0.
Пример № 1. Планируемое время выполнения задачи должно быть не меньше, чем время, запланированное на подзадачи
Первая вещь, которую вы должны знать об OCL, это то, что ограничение всегда относится к конкретному классу объектов. Перед написанием OCL-правила нам нужно выбрать этот класс. Иногда этот выбор не очень очевиден, но сейчас всё просто: правило относится к задаче. Мы можем обратиться к конкретному экземпляру задачи с помощью переменной self. Если необходимо получить значение некоторого свойства задачи, то после имени переменной пишем точку и затем имя этого свойства. Аналогично можно указать имя ассоциации. Попробуйте сделать это в Eclipse.
Примечание
Чтобы избежать лишних проблем, в модели все классы, свойства и т.п. названы с использование символов латинского алфавита. Узнать как именно называется то или иное свойство вы можете с помощью автодополнения (вызывается нажатием Ctrl + SPACE).
Итоговое правило контроля показано на рисунке.
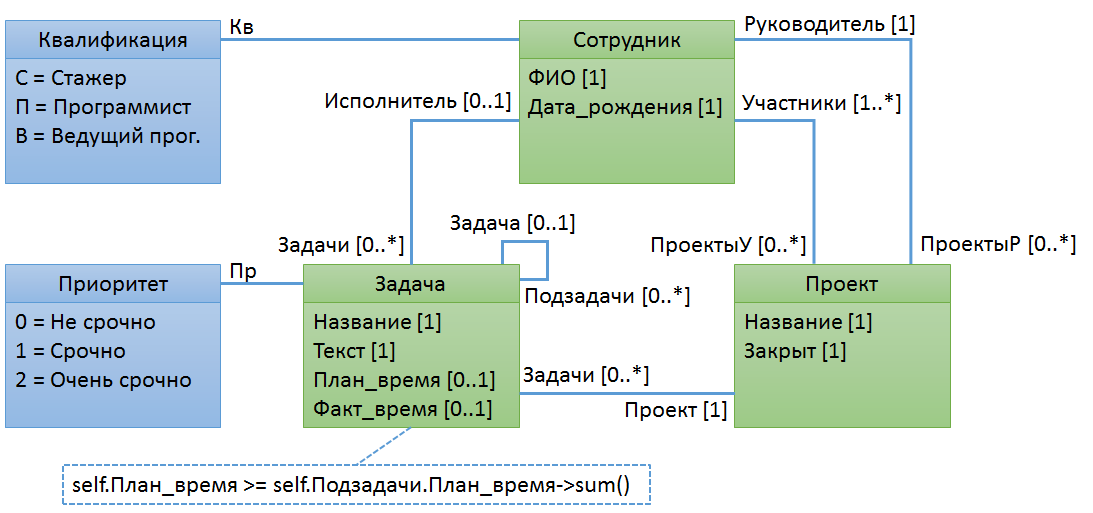
Не очень тривиальная вещь для новичков в OCL – это разница между символами «.» и «->».
То, что идет после точки, относится к каждому элементу из коллекции значений или объектов.
То, что идет после стрелки, относится ко всей коллекции значений или объектов.
В таблице приведены некоторые примеры использования точки и стрелки.
| OCL-выражение | Интерпретация OCL-выражения |
|---|---|
| Получить значение свойства «План_время» | |
| Получить множество подзадач | |
| Для каждой подзадачи в множестве получить значение свойства «План_время» и в итоге получить множество таких значений | |
| Посчитать сумму на всем множестве значений | |
| Несмотря на то, что у задачи может быть указано максимум одно значение для свойства «План_время», это значение неявно преобразуется в множество (с единственным элементом). К полученному множеству применяется операция sum() |
Примечание
Посмотрите в спецификации OCL описание операций collect() и oclAsSet().
Пример № 2. Руководитель проекта не должен быть участником проекта
На рисунке представлено несколько эквивалентных формулировок данного правила: получаем перечень участников проекта и убеждаемся, что в нем нет руководителя.
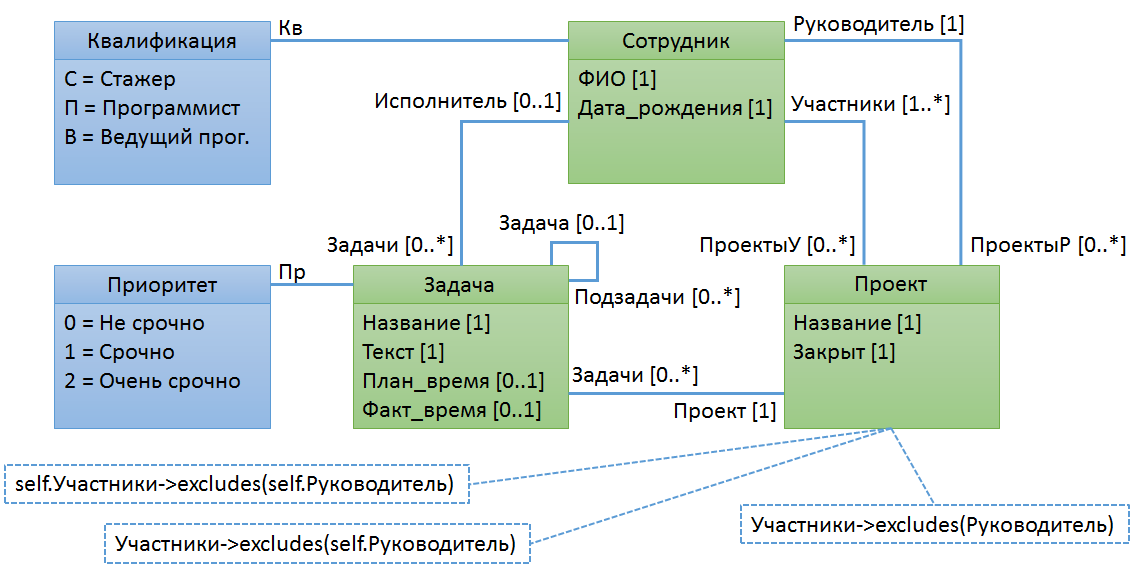
Переменную self можно не указывать, она подразумевается неявно. Однако, важно отметить, что некоторые операции (select, exists, forAll, ...) создают новую область видимости с дополнительными неявными переменными (итераторами). При этом достаточно затруднительно понять к какой именно неявной переменной относится цепочка свойств. В таких ситуациях крайне желательно все переменные (или все кроме одной) указывать явно.
Пример № 3. Ведущий программист может руководить не более чем двумя проектами одновременно
Новички при написании подобных правил обычно первым делом спрашивают есть ли в OCL if-then-else. Да, есть, но в большинстве правил вместо него лучше использовать импликацию.
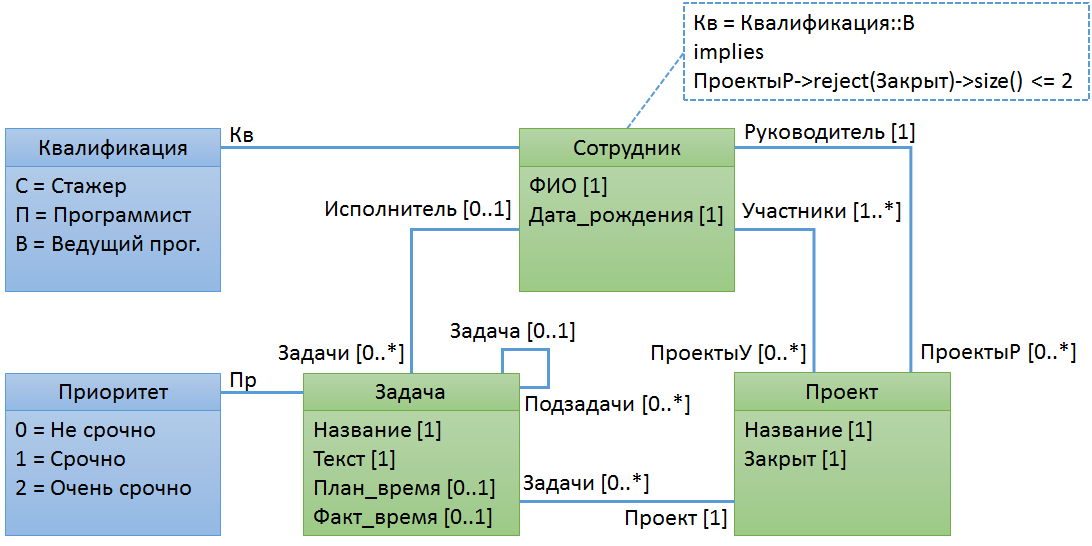
Если посылка импликации ложная, то даже и не пытаемся проверять остальные условия. А если истинная, то получаем перечень проектов, которыми сотрудник руководит, исключаем из них закрытые проекты, и, если количество таких проектов будет не более двух, считаем, что условие выполнено.
Пример № 4. В одном проекте не могут участвовать полные тезки
Вот, пожалуй, первое нетривиальное правило. Можно попытаться его сформулировать начиная как с сотрудника, так и с проекта. Важно начать с правильного класса :-) Если вы не знаете о существовании операции isUnique(), то можете начать городить достаточно монстроидальные конструкции, как я, когда впервые столкнулся с такой задачей.
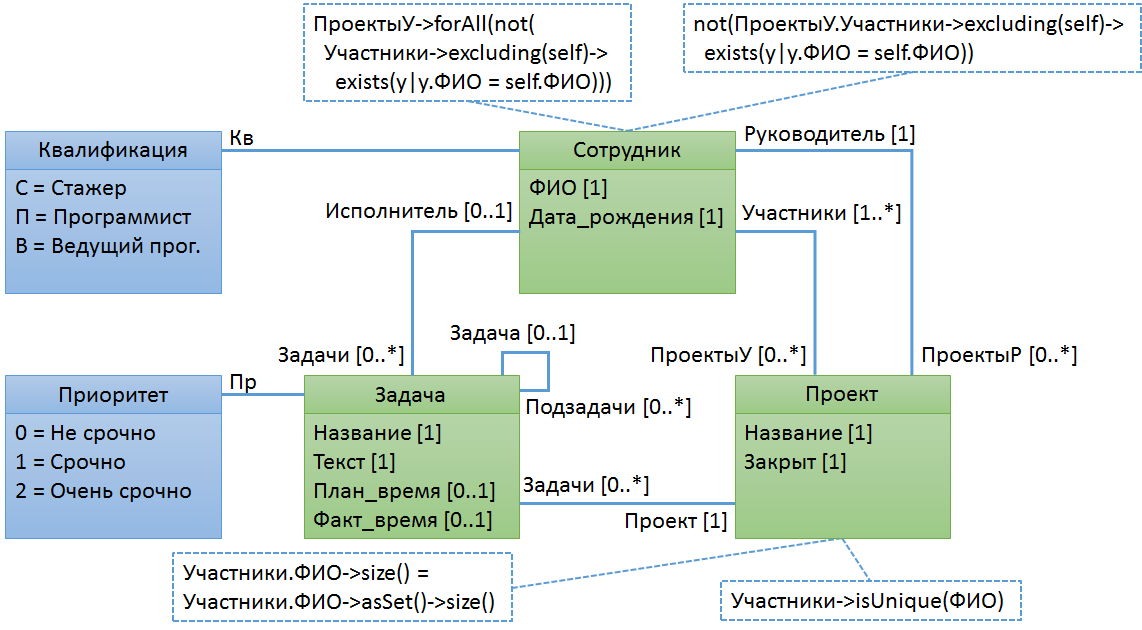
Уберите из правила явное объявление итератора (переменная «у»), и попробуйте интерпретировать правило. Лично я не помню точно что произойдёт. Может быть будет ошибка, что невозможно однозначно определить о каком именно ФИО идет речь. А может быть итератор имеет приоритет над self. Нужно смотреть спецификацию. В любом случае, желательно избегать таких ситуаций, и указывать переменные явно.
Примечание
Итераторов может быть более одного. Посмотрите спецификацию OCL, поэкспериментируйте в консоли OCL. Посмотрите как в спецификации определена операция isUnique().
Пример № 5. У сотрудника в одном проекте может быть только одна открытая задача и не более 5 задач по всем проектам
В данном правиле мы сначала объявляем переменную с перечнем открытых задач. Затем проверяем для них два условия. Будем считать, что задача считается открытой, если для неё не указано фактическое время выполнения.
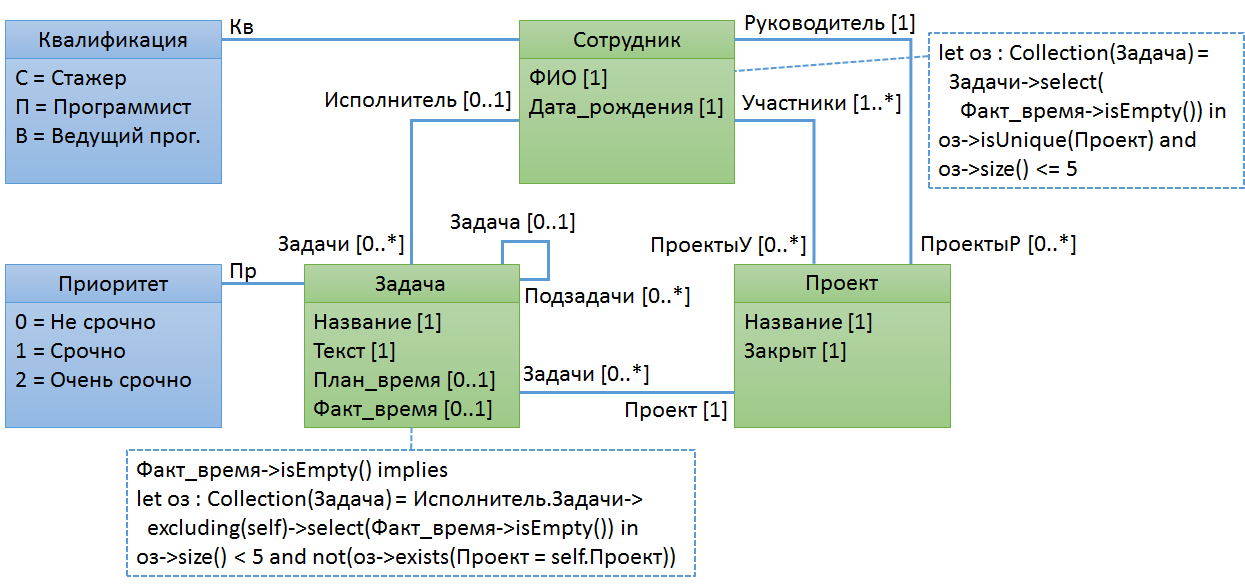
Как вы считаете, для какого класса лучше определять это правило? Для сотрудника или задачи?
Пример № 6. Задача не может быть своей подзадачей
Если вы не сразу поняли суть правил, изображенных на рисунке, то это вполне естественно. С одной стороны, есть класс объектов «Задача», с другой – у задачи есть ассоциация «Задача», которая указывает на родительскую задачу. Желательно именовать классы и свойства/ассоциации по-разному, это повышает качество модели и упрощает понимание OCL-правил.
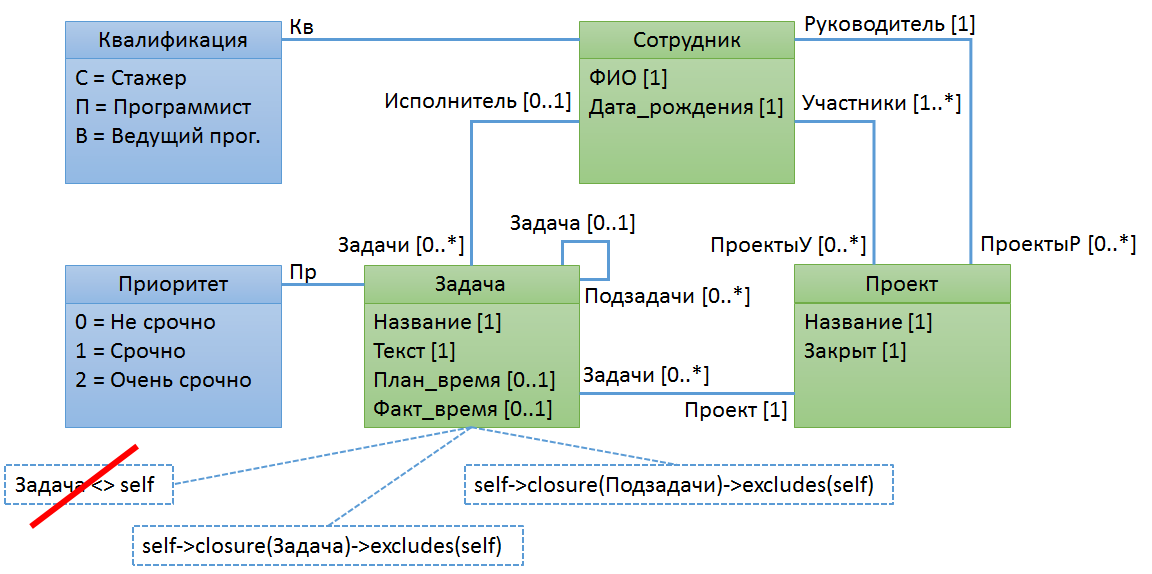
Начнем с реализации правила «в лоб». Проверим, не указывает ли ассоциация «Задача» у некоторой задачи на саму задачу: «self.Задача <> self». На рисунке мы убрали явное указание на переменную self. Казалось бы, в этом нет ничего фатального, однако в OCL-выражениях мы можем ссылаться не только на свойства или ассоциации, но и на классы. Например, с помощью такого выражения мы можем получить перечень всех задач: «Задача.allInstances()». В данном примере, интерпретатор OCL скорее всего решит, что речь идет об ассоциации «Задача», а не о классе. Однако, повторюсь, желательно избегать такие неоднозначности.
Второй недостаток этого правила заключается, в том, что оно не учитывает, что у подзадач могут быть свои подзадачи. Задача может запросто оказаться подзадачей своей подзадачи. Чтобы убедиться, что это не так нам могли бы потребоваться циклы или рекурсивные функции. Но циклов в OCL нет, а с функциями всё не очень просто. Зато есть замечательная операция closure(). Эта операция определена для коллекций, поэтому перед ней необходимо ставить стрелочку, а не точку. Для каждого элемента коллекции операция closure() вычисляет выражение, указанное в качестве её аргумента, затем объединяет полученные значения в коллекцию, для каждого элемента которой снова вычисляет это выражение, добавляет полученные значения к результирующей коллекции и так далее:
self.Задача->union(self.Задача.Задача)->union(self.Задача.Задача.Задача)->union(...)
На рисунке приведены два варианта правила, основанные на рекурсии по родительским задачам и подзадачам соответственно. Как вы считаете, какой вариант лучше (вопрос с подвохом)?
Примечание
Наверняка, рано или поздно вам потребуются циклы. В большинстве случаев, вместо них можно использовать операции, определенные для коллекций (select, exists, ...).
Если всё-таки нужен цикл, то можно попробовать что-то подобное:
Sequence{1..10}->collect(...)
Также обратите внимание на операцию iterate().
Пример № 7. ФИО сотрудника должно состоять из трёх частей (фамилия, имя и отчество), разделенных пробелами (пробелы не могут быть двойными, тройными и т.п.)
Очевидно, что подобное правило проще всего было бы реализовать с помощью регулярных выражений. Однако, в спецификации OCL нет операций для работы с ними. На рисунке вы видите примеры реализации такого правила без использования регулярных выражений. Хорошая новость заключается в том, что стандартная библиотека OCL расширяемая, и в некоторых реализациях операция matches() всё-таки есть, либо есть возможность реализовать её самостоятельно.
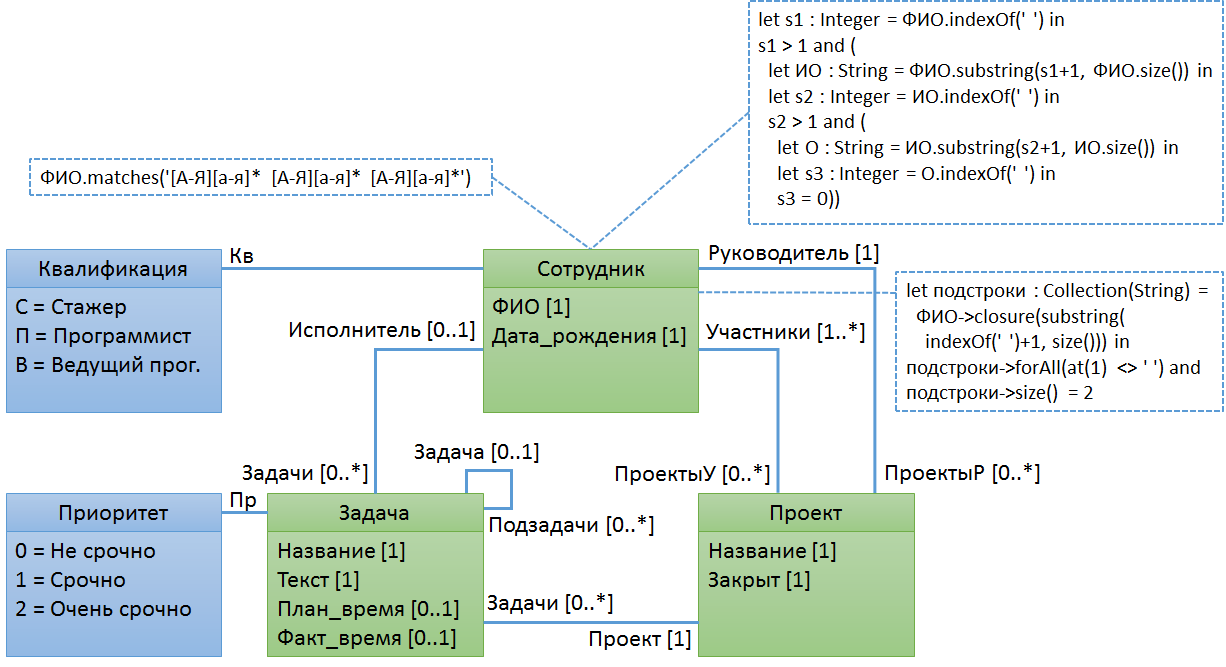
Конструкции OCL
Все OCL-выражения, которые мы с вами рассмотрели, написаны на Basic OCL (Essential OCL). (Кстати, как вы думаете, чем они отличаются?) Перечислим основные конструкции, которые мы использовали:
- Переменная self – выражение всегда привязано к определенному классу объектов
- Обращение к свойствам (и ассоциациям) по имени:
- self.Исполнитель.Задачи.Проект.Руководитель.Задачи...
- Арифметические и логические операции
- Вызов функций:
- ФИО.substring(1, 5)
- ФИО.size() = длина строки
- Работа с коллекциями:
- ФИО->size() = 1, т.к. у сотрудника должно быть единственное ФИО
- Задачи->forAll(задача | задача.План_время > 10)
- Объявление переменных:
- let s1: Integer = ФИО.indexOf(' ') in
- Условный оператор (if-then-else)
В Complete OCL есть некоторые дополнительные конструкции, которые мы не будем подробно рассматривать, вы можете самостоятельно познакомиться с ними, прочитав спецификацию:
- Сообщения, состояния
- Пакеты, контекст, назначение выражения (package, context, inv, pre, post, body, init, derive)
Домашнее задание
Посмотрите спецификацию OCL.
Разберитесь с примитивными типами данных, с видами коллекций (множество, последовательность и т.д.). Как вы думаете почему в OCL нет примитивных типов для работы с датой и временем? Что делать, если они всё-таки нужны?
Разберитесь чем отличаются Basic OCL, Essential OCL, Complete OCL.
Реализуйте самостоятельно другие OCL-правила, проверьте их в Eclipse.
Все OCL-выражения, которые приведены в статье могут принимать только истинное или ложное значение. (Кстати, согласны ли вы с этим утверждением?) Как вы считаете могут ли OCL-выражения иметь числовую область значений, возвращать строки, множества значений или объектов? Как можно было бы использовать такие не булевы OCL-выражения?
Как вы считаете, может ли результатом вычисления OCL-выражения быть другое OCL-выражение?
Бонус. Немного про метамодели
Всё, что мы с вами до этого делали – это описывали ограничения нашей модели и проверяли эти ограничения на конкретных сотрудниках, задачах, проектах. Например, мы описали правило, что руководитель проекта не может быть одновременно и участником проекта. Причём мы описали это правило для всех проектов и сотрудников вообще. А затем проверяли его для конкретных проектов и сотрудников.
Пример № 1. Метамодель «Сотрудник-Задача-Группа»
Теперь давайте поднимемся на уровень выше. Например, мы хотим разработать ещё одно приложение – для службы заказа такси. Там будет аналогичная модель данных. Вместо сотрудников пусть будут водители, вместо задач – заказы, а вместо проектов – города. Конечно это очень условный пример, но он нужен только для демонстрации идеи. Или, допустим, нам нужно разработать приложение для записи на прием к врачу. Там будут врачи, отделения и приемы.
Мы можем посмотреть на все эти модели, и увидеть в них общие закономерности. Программист, водитель и врач – это по сути одно и тоже – просто сотрудник. Заказ, прием – это, если обобщить, то просто задача. Ну и обобщим город, отделение, проект. Назовем их просто группой. Связь между сотрудником и задачей назовем выполнение. Связь между сотрудником и группой назовем участие.
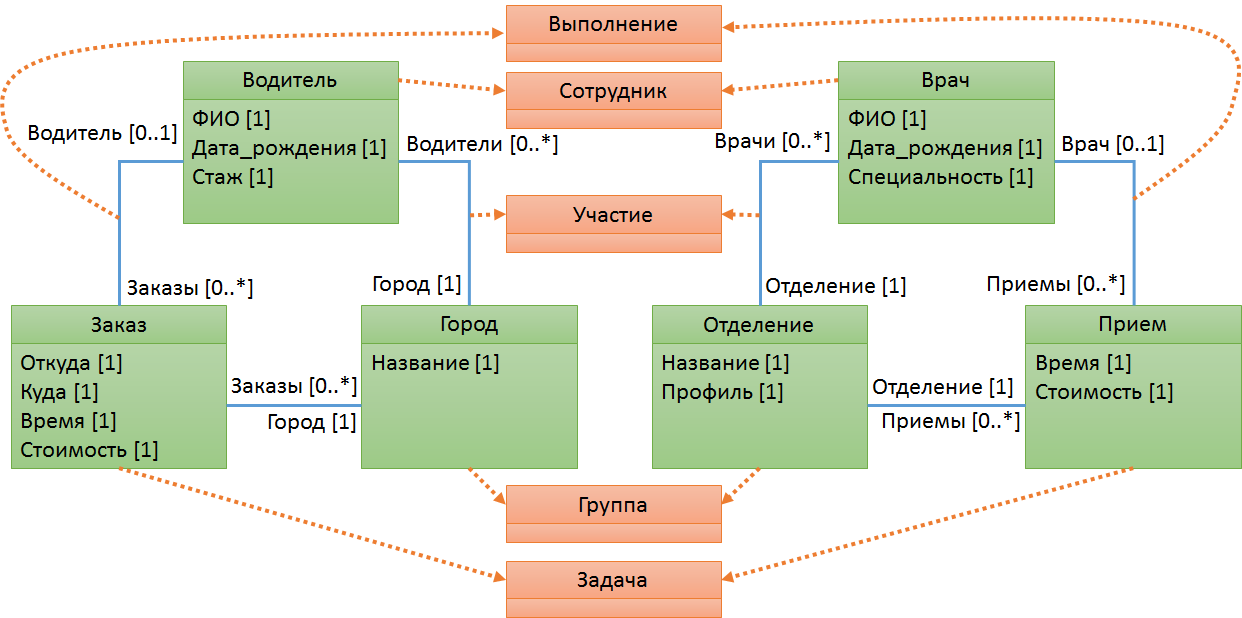
Нарисовав такую картинку, мы с вами поднялись на новый уровень осознания предметной области – разработали метамодель, язык, на котором можем описывать любые подобные модели.
Напомню, что модель, которую мы построили в первой части статьи, накладывала некоторые структурные и неструктурные ограничения на сведения об объектах в нашей предметной области.
Аналогично и метамодель накладывает структурные и неструктурные ограничения на модели, которые строятся в соответствии с этой метамоделью. Например, в любой модели, которая соответствует данной метамодели, могут быть только элементы, которые основаны на метаклассах, отмеченных красным цветом на рисунке. В модели не может появиться, например, класс «Здание», «Дорога» или что-то подобное, не являющееся сотрудником, задачей и т.п.
Примечание
К слову, метамодели строятся на основе метаметамоделей (например, MOF, Ecore). Если вам это интересно, почитайте спецификацию OMG MOF. В общем случае, может быть произвольное количество уровней моделирования, однако обычно достаточно 2-3.
Кстати, как вы считаете на основе какой метаметаметамодели построена сама MOF?
Если вы не боитесь вывихнуть мозг, то почитайте статью Dragan Djuric, Dragan Gasevic и Vladan Devedzic «The Tao of Modeling Spaces» (лично у меня вывих мозга уже от их фамилий). По большому счету, при разработке программного обеспечения всё является моделью (от мысленного образа в сознании разработчика до исходного кода, документации, сценариев тестирования и т.п.), а процесс разработки – это преобразование одних моделей в другие. Тему преобразования моделей мы постараемся раскрыть в последующих статьях.
Как вы считаете, соответствует ли модель, изображенная на рисунке выше (зеленые прямоугольники, синие линии), метамодели (красные прямоугольники)?
Очевидно, что кроме структурных ограничений метамодель может содержать и неструктурные ограничения. Последние мы можем описывать опять-таки на языке OCL. Примеры подобных правил приведены на рисунке.

Примечание
На самом деле этот рисунок не очень корректный. Вместо полноценной метамодели тут используется UML-профиль, который, строго говоря, является обычной UML-моделью, построенной на основе метамодели UML (которая, в свою очередь, построена на основе метаметамодели MOF). Однако, по сути, метамодели часто строятся не с нуля, а в виде UML-профиля. Например, в стандарте ISO 20022 метамодель реализована в двух равнозначных вариантах: 1) полноценная метамодель, основанная на Ecore, и 2) UML-профиль. С точки зрения целей данной статьи эти нюансы не очень существенны, поэтому будем считать UML-профиль «метамоделью».
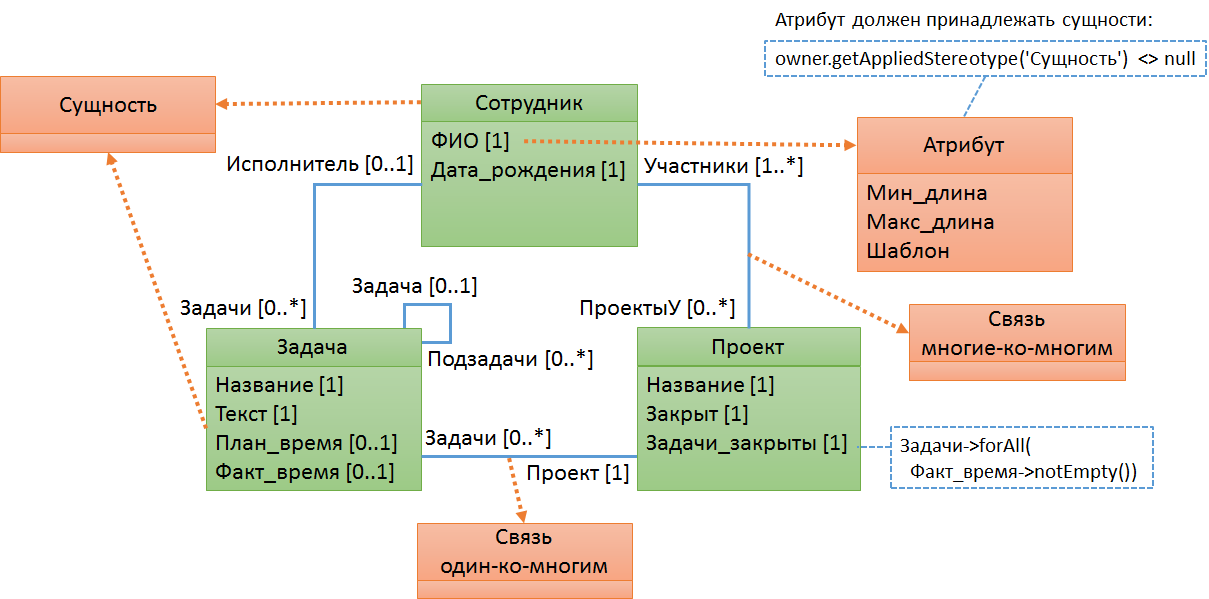
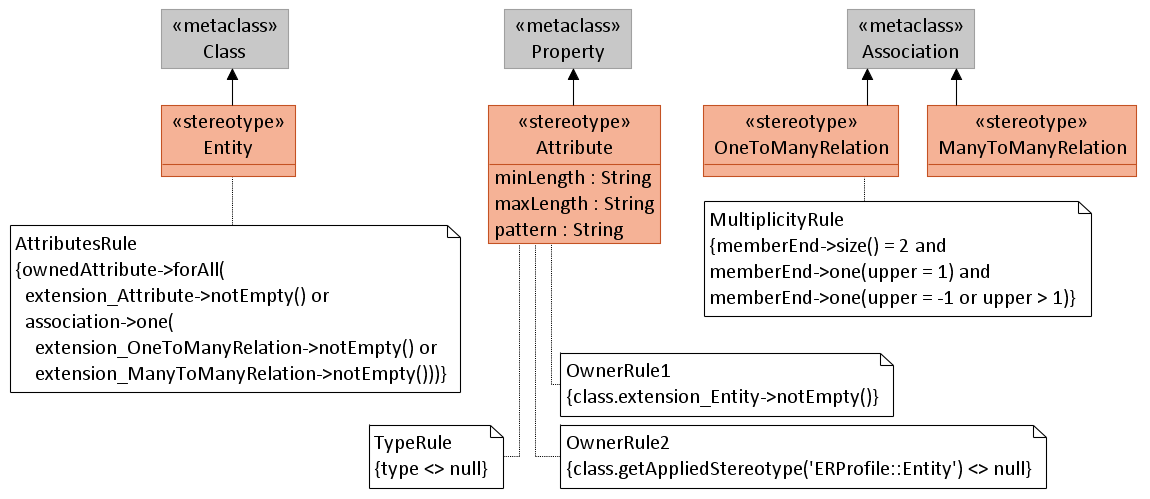
Пример № 2. Метамодель «Сущность-Атрибут-Связь»
Описанная выше метамодель выглядит немного искусственной и бесполезной. Попробуем построить более адекватную метамодель. Допустим, нам необходимо разработать язык, который позволяет описывать структуру данных в реляционной базе данных. При этом разница между участниками, задачами, проектами и т.п. не так важна. Всё это сущности, у которых могут быть атрибуты, и которые связаны между собой связями. В нашем примере есть два вида связей: один-ко-многим, многие-ко-многим. Метаклассы такой метамодели описаны на рисунке красными прямоугольниками. Как вы считаете, соответствует ли модель, изображенная на рисунке (зеленые прямоугольники, синие линии), метамодели? Каждый ли элемент этой модели можно отнести к одному из метаклассов?
Теперь перейдём, наконец, к практике. Для этого я буду использовать Rational Software Architect, вы можете использовать любой вменяемый UML-редактор. Можно было бы показать всё на примере бесплатного и идеологически правильного Papyrus, но, к сожалению, он не очень удобный.
Итак, создайте в UML-редакторе новый пустой проект. Создайте в нем UML-профиль со следующими стереотипами.
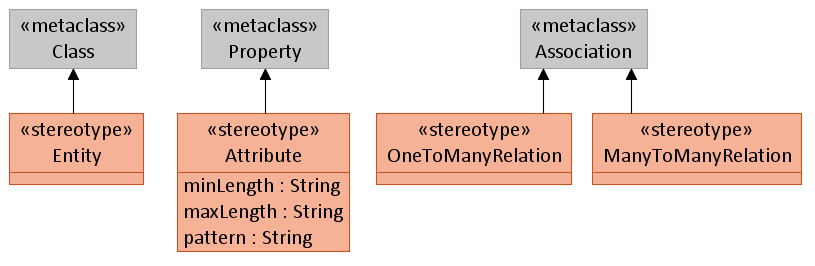
Примечание
Обратите внимание на свойства стереотипа «Attribute». Это перечень свойств, которыми может обладать любой атрибут в нашей модели.
Затем создайте следующую UML-модель, примените к ней только что созданный профиль, примените нужные стереотипы. Если лень всё это создавать, можете взять готовый проект.
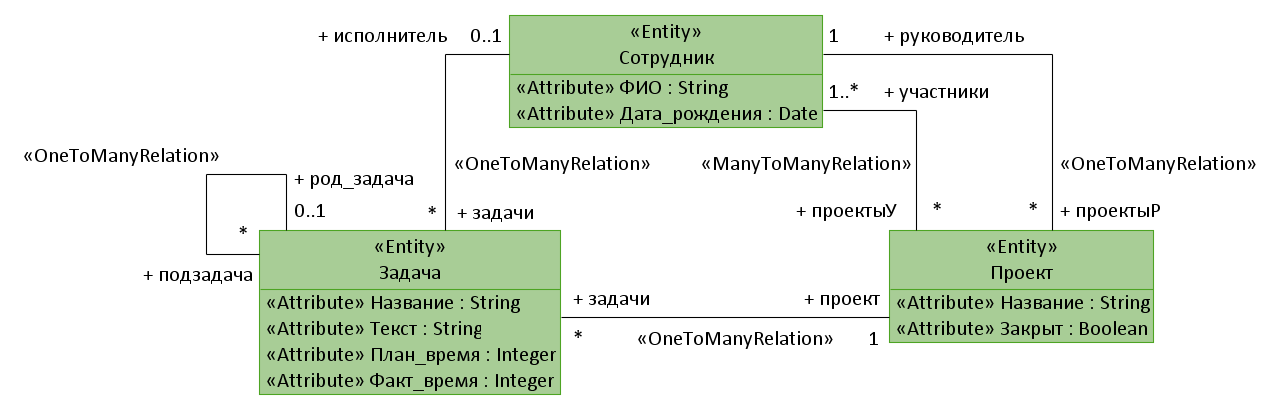
Грубо говоря, мы построили модель в соответствии с нашей «метамоделью». Каждый элемент нашей модели является «экземпляром» некоторого метакласса из «метамодели».
Примечание
Ещё раз повторюсь, что, строго говоря, это не так. И профиль, и стереотипы, и модель, и все элементы модели – всё что мы с вами создали – это экземпляры метаклассов из метамодели UML. Т.е. и профиль, и модель, которая его использует, находятся на одном уровне моделирования. Но с практической точки зрения, мы можем считать этот профиль «метамоделью», в соответствии с которым создана наша модель. Если вы понимаете о чём идет речь, то до понимая того что такое метамодели вам остается ещё один шаг – понять чем являются прямоугольники и линии на диаграммах, и понять чем является xmi-файл с точки зрения моделирования. В этом вам поможет статья, которая упоминалась выше.
Теперь опишем некоторые дополнительные ограничения нашей метамодели на языке OCL. Например, атрибуты должны принадлежать сущностям. Если бы мы создавали метамодель в виде полноценной метамодели, а не профиля, то такое правило выглядело бы очень просто:
owner.oclIsKindOf(Entity)
Более того, нам даже не пришлось бы описывать такое правило. Мы бы просто создали ассоциацию owner между Attribute и Entity, которая в принципе не может связывать элементы других видов.
Однако, наша метамодель создана в виде UML-профиля, поэтому правило необходимо и, на первый взгляд, оно выглядит не очень тривиально:
base_Property.class.getAppliedStereotype('PMProfile::Entity') <> null
Это правило относится к стереотипу «Attribute», который расширяет UML-метакласс «Property». Это значит, что в модели мы можем к некоторому свойству (экземпляру UML-метакласса «Property») привязать экземпляр стереотипа «Attrbiute». У последнего мы можем задать определенные значения minLength, maxLength и pattern. OCL-правило, которое мы написали выше, будет проверять как-раз этот экземпляр стереотипа «Attribute».
Через свойство base_Property мы переходим от экземпляра стереотипа к свойству. Затем через ассоциацию class переходим к классу, которому принадлежит свойство. И, наконец, проверяем, применен ли к этому классу стереотип «Entity».
Примечание
Не знаю на сколько это соответствует спецификации, но иногда ассоциацию между экземпляром стереотипа и экземпляром UML-метакласса (в данном случае, base_Property) можно не указывать, она будет неявно подразумеваться так же как self.
Примечание
Если у вас возник вопрос, откуда я узнал, что нужно использовать именно ассоциацию class, то есть два пути: 1) автодополнение в Eclipse (Ctrl + SPACE) и 2) спецификация OMG UML.
В правиле выше используется стандартный прием для UML-редакторов, основанных на Eclipse. Однако операция getAppliedStereotype() является нестандартным расширением OCL, в других инструментах она может не поддерживаться. Это же правило можно записать следующим образом:
class.extension_Entity->notEmpty()
Проверяем есть ли у класса, которому принадлежит свойство, связь (через ассоциацию extension_Entity) с расширением, основанным на стереотипе «Entity».
Примечание
2-ой вариант теоретически выглядит более соответствующим стандарту. Однако в старых версиях Eclipse с ним могут быть проблемы, для них рекомендуется использовать 1-ый вариант.
Примечание
Попробуйте найти ассоциации base_Property, extension_Entity и class в профиле.
На рисунке изображены ещё три правила
- У атрибута должен быть указан тип.
- У отношения один-ко-многим множественность на одном конце должна быть не больше 1, а на другом конце – больше 1.
- Все свойства, принадлежащие сущности, должны быть либо обычными атрибутами, либо ролями отношения.
Как вы считаете, можно было бы заменить эти правила на обычные структурные ограничения, если бы мы создавали модель не в виде UML-профиля, а в виде метамодели, основанной на MOF?
MOF и Ecore очень похожи друг на друга. Можете ли вы представить какую-то принципиально иную метаметамодель?
Примеры ограничений на уровне метамодели
Ниже приведены примеры самого простого и самого сложного правил из одной реальной метамодели, которую мы создавали. С одной стороны, это конечно пример ужасного кода, но с другой – демонстрация некоторых конструкций OCL :-)
Максимальная повторяемость компонента АТД должна быть больше 0:
upper > 0
Компонент АТД, который унаследован через отношение «ограничение», должен находиться на той же позиции, что и соответствующий ему компонент родительского типа:
datatype.generalization->exists(
getAppliedStereotype('SomeProfile::restriction') <> null)
implies (
let parent : DataType = datatype.general->any(true).oclAsType(DataType) in
let props : OrderedSet(Property) = parent.ownedAttribute->
select(getAppliedStereotype('SomeProfile::Component') <> null) in
let cur : Property = props->select(x|x.type=self.type)->any(true) in
cur <> null implies (
let prevEnd : Integer = props->indexOf(cur) - 1 in
prevEnd = 0 or (
let allPrev : OrderedSet(Property) = props->subOrderedSet(1, prevEnd) in
let requiredPrev : OrderedSet(Property) = allPrev->select(lower > 0) in
requiredPrev->isEmpty() or (
let prevStart : Integer = allPrev->indexOf(requiredPrev->last()) in
let allowedPrev : OrderedSet(Property) = allPrev->
subOrderedSet(prevStart, allPrev->size()) in
let index : Integer = datatype.ownedAttribute->
indexOf(self.oclAsType(Property)) in
index > 1 and (
let selfAllPrev : OrderedSet(Property) = datatype.ownedAttribute->
subOrderedSet(1, index - 1)->
select(getAppliedStereotype('SomeProfile::Component') <> null) in
selfAllPrev->isEmpty() or (
let prevType : Type = selfAllPrev->last().type in
allowedPrev->exists(x|x.type=prevType)))))))
Зачем нужен OCL
Правила контроля в профиле или метамодели – об этом вы уже всё знаете.
Правила контроля в модели – и об этом тоже.
Спецификация операций и вычисляемых свойств – с этим можете самостоятельно познакомится, прочитав спецификацию OCL.
Преобразование моделей (QVT, MOF M2T) – об этом мы расскажем в следующих статьях.
Познание смысла бытия – для этого помедитируйте на первый рисунок. Где бы вы нарисовали Иисуса? А Матрицу?
Комментарии (20)

Throwable
19.08.2015 10:01Спасибо. Всегда интересовали возможности моделирования с помощью Eclipse Modelling Tools. К сожалению, существует очень мало информации на этот счет.
Насколько я могу судить, последнее поколение тулзов отошло от OMG в сторону генерации собственных описательных языков (Epsilon).
Если Вы специалист в EMFT, будет очень интересно увидеть статьи, освещающие использование полного стека технологий на примере от создания модели и до работающего приложения, включающего persistence и xml-mapping.
Ares_ekb
19.08.2015 10:21Мне самому очень интересна эта тема. Я уже начал писать следующую статью :) От стандартов OMG они не уходят. По крайней мере, их реализации UML, OCL, QVTo основаны на последних версиях стандартов и вполне поддерживаются. Разработчики на форуме оперативно отвечают на вопросы, исправляют ошибки. Уже есть какая-то реализация QVTd.
Немного в стороне Acceleo (который основан на MOF M2T). Сам Accelo вроде активно используется, но стандарт MOF M2T с 2008-го года не обновлялся.
И вы правы, действительно, появляются альтернативные технологии типа Epsilon. Но идейно они не очень сильно ушли от стандартов OMG. Тот же Epsilon Object Language в значительной степени основан на OCL. Я думаю, что просто растет популярность MDA и поэтому появляются новые альтернативные технологии. Чем больше их будет, тем лучше — больше выбор.

maxstroy
19.08.2015 10:38+1Статья и в самом деле насколько специфична, настолько и полезна. Спасибо автору! Правда, я не сторонник использования ООПешных терминов для моделирования предметных областей, например, когда используется странный на мой взгляд термин экземпляр сотрудника вместо просто сотрудник. Но пока мы только начинаем изучать моделирование и любая информация на эту тему на вес золота! Спасибо!
Ares_ekb
19.08.2015 13:20Да, хотя в тексте много UML, классов, объектов, всё это относится не только к ООП, но к моделированию в целом. Тот же BPMN — это тоже стандарт OMG, основанный на MOF. Или ещё у них есть метамодель для онтологий.
Даже «Войну и мир» можно разложить по уровням моделирования :) M0 — реальные или выдуманные события, люди, объекты. М1 — текст, написанный Толстым, М2 — русский язык. Аналогично можно выделить уровни и для музыкальных или художественных произведений. Они отличаются от привычных языков моделирования и метамоделирования только меньшей формализованностью.
Если посмотреть на это совсем глобально, с точки зрения теологии или философии, то весь наш мир можно рассматривать как уровень М1. При этом Бог — это уровень М2. Абсолютно каждый объект на уровне М1 создан по образу и подобию (является экземпляром) некоторого метакласса на уровне М2.
Я пишу это не ради каких-то религиозных споров и т.п., а чтобы показать, что разработка, управляемая моделями — это качественно новый подход к разработке ПО, который даёт целостный взгляд на моделирование, DSL, рефлексию в языках программирования, сам процесс разработки и т.п.
Например, в статье сотрудники, задачи и проекты описаны в виде UML-классов. Но с тем же успехом их можно описать в виде Java-классов. При этом в качестве метамодели вместо UML используется Java, а в качестве метаметамодели вместо MOF используется EBNF. Практически любой артефакт, создаваемый при разработке ПО можно разложить по уровням моделирования.
Кстати, в сторону ISO 15926, 4D-онтологий мы тоже смотрим…
vvagr
21.08.2015 00:37Ну да. Чтобы представить себе принципиально иную метамодель — надо уйти от MOF-UML. В RDF-OWL мире вообще можно не заботиться о границе между уровнями мета.
Но писать ограничения для OWL, да ещё транслируемые в какой-то код на языках программирования, пока не так удобно, как строить OCL в Эклипсе.Ares_ekb
21.08.2015 09:08OWL — это действительно немного другой мир. Я думаю, что он более выразительный, чем MOF. И многие вещи, которые в MOF приходится описывать с помощью OCL, в RDF/OWL описываются без дополнительных языков. Кстати в Ontology Definition Metamodel пишут, что OCL для онтологий не очень подходит, потому что он слишком неформальный (раздел 8.5):
8.5 Why Common Logic over OCL?
Common Logic (CL) is qualitatively different from some of the other metamodels in that it represents a dialect of traditional first order logic, rather than a modeling language. UML already supports a constraint (rule) language, which includes similar logic features, OCL [OCL], so why not use it?
The short answer to that question is that the ODM does include OCL in the same way it includes UML. Unfortunately, just as UML lacks a formal model theoretic semantics, OCL also has neither a formal model theory nor a formal proof theory, and thus cannot be used for automated reasoning (today). Common Logic, on the other hand, has both, and therefore can be used either as an expression language for ontology definition or as an ontology development language in its own right.
Но при всех плюсах OWL его сложно представлять в виде диаграмм. И на нём сложно описывать конкретные, строго определенные структуры данных. Т.е. он хорош для концептуального моделирования, когда нужно описать какие сущности, свойства, отношения могут быть в принципе. Но если нужно описать, например, структуру конкретного сообщения, то MOF/UML использовать удобней.
Кстати OCL можно использовать не только для описания ограничений, но и для описания преобразований моделей. QVT, MOF M2T, ATL и другие используют OCL для работы с элементами модели. При этом неважно из какого пространства моделирования эти модели (MOF, RDF, EBNF). Например, можно описать преобразование OWL в UML по каким-то правилам. И OCL тут очень полезен, именно как язык для навигации по модели. OCL можно сравнить XPath или SQL. Все эти языки могут использоваться не только для описания ограничений, но и для манипуляции данными.vvagr
21.08.2015 11:12Ну, с диаграммами не сильно сложнее, для большой модели что на OWL, что в UML- проблем грамотно распределить по листам, и красиво развести стрелочки.
Под «сложно описывать структуры данных» Вы имеете в виду переход к реальным структурам таблиц СУБД и исполняемых правил для них? Да, для этого нужен ещё один уровень мэппинга, выбор таблиц, колонок, и это работа для модельера логического и физического уровней.
Однако зачем таблицы, если есть triple stores и reasoning? C triple stores вообще всё уже почти хорошо в смысле быстродействия по сравнению с СУБД. C reasoning пока не так хорошо, но сделать проверку фиксированного (без вывода новых) набора правил над триплетами не сложнее, чем проверку фиксированного набора правил OCL.
Как использовать OCL для описания мэппинга из OWL — я что-то не понимаю. Для описания мэппинга нужны два языка поиска по структурам двух исходных языков. Для RDF это SPARQL, который сейчас слегка расширяют в рамках проекта www.w3.org/2014/data-shapes/wiki/Main_Page. Вот на связке SPARQL и SQL можно описывать преобразование сразу в таблицы.Ares_ekb
21.08.2015 12:07Вообще, да, онтологию всегда можно нарисовать в виде графа. Но там будет много вспомогательных узлов. Чтобы диаграмма была понятна не специалистам, приходится придумывать упрощенную, более наглядную нотацию. Например, классы обозначаем кружками, объекты прямоугольниками со скругленными углами, значения просто прямоугольниками. Приходится придумывать нотацию для объединения или пересечения классов. Или как, например, показать на диаграмме, что между некоторыми сущностями НЕ должно быть отношения? Можно обозначить, например, перечеркнутой линией. Сложно показывать отношения между отношениями. Ограничения на множественность в rdf выглядят сложнее, чем в UML.
Есть разные попытки придумать визуальную нотацию для онтологий: VOWL, EXPRESS-G или что-то такое. Но все эти языки гораздо сложнее, чем диаграммы классов, к которым все более-менее уже привыкли.
Отображение моделей в MDA обычно выглядит так. Если исходная или целевая модель не MOFовская, то сначала её нужно сделать такой. Например, на входе RDF-файл.
Создаем MOF-метамодель, в которой описываем все сущности в виде MOF-классов, которые есть в спецификации RDF. Описываем триплеты, графы, ресурсы и т.д. в виде такой диаграммы классов (раздел 10):

Таким образом мы получили объектную модель для RDF. Аналогичная объектная модель уже есть для UML.
И всё, теперь мы можем использовать OCL для работы с RDF. Аналогично с реляционными моделями, описываем их в виде объектной MOF-метамодели. В итоге нам не важно онтологии это или реляционные модели, мы сначала делаем их объектными и манипулируем ими с помощью единого языка — OCL. Это сложно описать в комментарии, я планирую серию статей на эту тему.
Ares_ekb
21.08.2015 12:25Насчет triple store… Могут быть организационные или технические причины, по которым, например, для хранения должны использоваться реляционные базы, а для обмена — XML или ещё что-то. Причём, XML с «простой и понятной» XML-схемой, а не RDF/XML :)
Я не думаю, что RDF будет универсальным языком моделирования, который заменит все остальные. Наверное всегда будут существовать разные языки моделирования. При этом всегда будет потребность в преобразовании одних моделей в другие. OMG описывает эти идеи в Model-driven architecture.
VAE
21.09.2015 12:17>Спасибо за внимание к статье! Я думал, что это слишком специфическая тема, и никто не будет читать.
Скорее не тема специфична, а подача материала. Обе статьи начинаются не с объяснения причин возникновения и представления проблемы.
Отсылки на первичные источники отсутствуют. Реляционная алгебра не упоминается и ее плюсы и минусы опускаются.
Любопытно, что автор не вникает в семантику нормализации. Хорошо было бы напомнить определения и требования к нормальным формам.Ares_ekb
21.09.2015 13:11Согласен, но это не научная статья :) Поэтому я не уделял особого внимания источникам, проблематике.
Реляционная алгебра и вообще моделирование данных имеют очень опосредованное отношение к основной теме статей (разработка, управляемая моделями). Поэтому я их затронул ровно на столько, чтобы было вообще понятно что такое Anchor и зачем он может быть нужен. Я ориентировался на человека, который возможно никогда не занимался моделированием данных. Плюсы и минусы реляционной алгебры для него явно лишние. Тем более, я не утверждаю, что какие-то подходы лучше или хуже. Просто говорю, что есть разные подходы к моделированию. И есть инструмент, который позволяет реализовывать эти языки моделирования.
Но замечание конечно принимается. Если затрагиваешь какую-то тему, то будь добр, раскрыть её нормально.
matiouchkine
> В общем случае, может быть произвольное количество уровней моделирования, однако обычно достаточно 2-3.
Да ну? Перечитайте спецификацию MOF, оно же сворачивается в точку на третьей итерации.
Ares_ekb
Спасибо за внимание к статье! Я думал, что это слишком специфическая тема, и никто не будет читать.
В MOF 1.4 действительно говорят о 4-х уровнях (M0-M3). Но начиная с версии 2.0 в спецификацию добавили уточнение. Вот, цитата из последней версии 2.5, раздел 7.3:
matiouchkine
Комитет и так особой ясности в вопрос не вносил, а тут вообще, кажется, перехитрили сами себя. Четвертый и следующие слои просто не имеют смысла. В рамках MOF моделей — уже M4 это 1 сущность, определяющая _всё_.
Ares_ekb
Согласен, я не смог найти ни одного примера М4. Не могу представить где это могло бы потребоваться.
Сам MOF написан на MOF :) Выше MOF точно ничего нет, но нижних уровней может быть больше. Представьте UML-диаграмму, на которой изображены такие классы: сущность, связь, атрибут. У сущности и атрибута есть свойство «имя». У связи есть две ассоциации с сущностью: «исходный_объект» и «целевой_объект». И ещё у связи есть два свойства: «множественность_для_исходного_объекта» и «множественность_для_целевого_объекта». Есть ассоциация один-ко-многим между сущностью и атрибутом. Нарисовав такую диаграмму классов мы фактически создали метамодель для ER-моделей.
Посчитаем уровни:
M4 — MOF
M3 — UML
M2 — описанная выше UML-модель с классами сущность, связь, атрибут
M1 — некоторая ER-модель
M0 — сведения, структурированные в соответствии с этой ER-моделью
Конечно, в реальности таких иерархий не бывает. Модель на уровне M2 нет никакого смысла описывать на UML, её можно сразу описывать на MOF. Т.е. UML тут лишний промежуточный слой. Но, вообще, такая иерархия не запрещена. UML вполне может использоваться для описания других языков моделирования.
Кроме MOF есть и другие метаметамодели (т.е. языки для описания языков). Самая известная — это EBNF. Вообще, язык для описания других языков сам является языком, поэтому может быть описан сам на себе :) MOF описан на MOF. EBNF можно описать на EBNF. Поэтому потребности в М4 просто нет. Если метаметамодель не может быть описана сама на себе, значит, наверное, это не очень хорошая метаметамодель. Эта тема очень хорошо описана в этой статье.
Точно так же как и компилятор языка программирования часто пишется на этом же языке.
Но с другой стороны. Вот, есть 2 метаметамодели: MOF и EBNF. Наверное можно придумать какой-то M4-язык, на котором можно описать оба этих M3-языка. А может и нельзя, потому что они в разных пространствах моделирования. MOF описывает концептуальные вещи, а EBNF — синтаксические. А может и можно. Ну, короче это вынос мозга :)
matiouchkine
Все проще, вы лишнего начитались :)
И MOF и EBNF можно описать и на MOF и на EBNF. Они изоморфны. Метамодель третьего уровня может описать любую модель, включая метамодели третьего уровня, по определению. Иначе она не имеет права называться М3.
Теперь про ваш пример: модель М2 из него не «нет никакого смысла описывать на UML», а нельзя описывать на UML. Вас запутало то, что у MOF и UML одинаковый синтаксис. Объект «class MyClass» в любом языке программирования с рефлексией — играет как бы сразу двух персонажей, это и инстанс и класс. Так вот создавая объект UML вы получаете модель, а не метамодель. В вашем примере М2 на самом деле инстанс М4. то есть непосредственно MOF.
Ares_ekb
Возможно я перемудрил с примером. Пусть будет другой. Мы можем на EBNF описать BNF. А на BNF описать, например, Java. Получаем:
M4 — EBNF
M3 — BNF
M2 — Java
M1 — программа на Java (с классами «Сотрудник», «Задача», ...)
M0 — объекты реального мира
Практического смысла использовать разные языки на М3 и М4 нет, но всё-таки это возможно.
Описать EBNF с помощью MOF можно. Хотя, есть сомнения. Потому что EBNF описывает синтаксические конструкции, последовательности символов. А MOF описывает сугубо концептуальные вещи (некие абстрактные классы, понятия) и не описывает их представление в виде последовательности символов или квадратиков, стрелочек. Ну, допустим, у нас будут классы «Терминальный символ», «Нетерминальный символ», «Правило», «Конкантенация», «Выбор»,…
Но описать MOF на EBNF точно не получится. На EBNF можно описать одно из текстовых представлений MOF. Например, в виде XMI-файла. Т.е. EBNF в принципе описывает только строки, а не понятия.
matiouchkine
А чем это описание в виде XMI вам не угодило? Оно совершенно изоморфно MOF M3.
Ares_ekb
Тут скорее эпиморфизм (из множества XMI-файлов в множество MOF-моделей), чем изоморфизм. Одна и та же MOF-модель может быть представлена в виде различных XMI-файлов с разными пробелами, разными идентификаторами (xmi:id), разным порядком XML-элементов, XML-атрибутов.
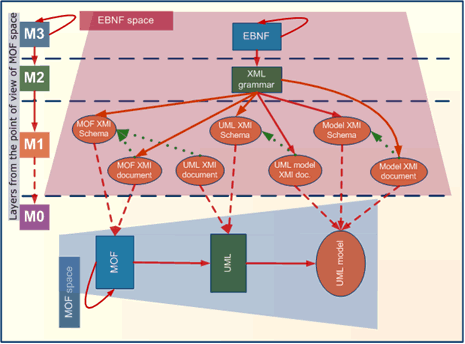
MOF и XMI соотносятся так же как понятие и символ в семантическом треугольнике. Например, есть некий реальный объект — допустим, автомобиль. Мы можем обозначить этот автомобиль с помощью слова «автомобиль», слова «car», картинки со схематичным изображением автомобиля, жестами или как-то ещё. Но независимо от способа обозначения у человека в сознании будет одно и тоже понятие «автомобиль».
MOF позволяет описывать понятия независимо от формы их представления. А XMI позволяет упаковать эти абстрактные понятия в последовательность символов. Т.е. для MOF объект моделирования (М0) это объекты реального мира, а на уровне М1 понятия об этих объектах. А для XMI — объект моделирования (М0) это не объекты реального мира, а понятия об этих объектах, а на уровне М1 будут последовательности символов, описывающие понятия.
Кстати, как-раз картинка на эту тему:
Другая форма представления MOF-моделей — это диаграммы. Или, например, в Eclipse MOF-модели можно представить в виде дерева. Нельзя сказать, что диаграмма или XMI-файл тождественны самой модели. Точно так же как нельзя сказать, что понятие «автомобиль» в сознании человека тождественно слову «автомобиль» или рисунку с автомобилем.
Ares_ekb
Я кажется сам понял почему MOF и EBNF (или XMI) не изоморфны. М3-модели позволяют описывать М2-модели, которые позволяют описывать М1-модели, которые позволяют описывать объекты реального мира (М0).
У MOF и EBNF это множество объектов реального мира разное. И способ описания разный, описываются разные аспекты этих объектов.
Для MOF объектом может быть любой реальный или воображаемый объект. При этом с помощью семейства MOF-моделей мы можем описывать свойства этого объекта, область значений свойств, отношения между объектами. Можем в модели указать, что одно множество объектов включает в себя другое множество объектов с помощью отношения обобщения.
Для EBNF объектом могут быть только понятия, а не любые объекты. И с помощью EBNF мы не можем описывать свойства объектов, их отношения, не можем описать отношение обобщения. Зато можем описать как это понятие можно представить в виде последовательности символов.
Конечно в EBNF мы можем описать подобный язык:
А можем сделать такой язык:
или ещё какой-то.
Все эти языки будут описывать не объекты сами по себе, а только понятия об объектах, представленные в виде определенной последовательности символов. Когда мы создаём подобный язык на EBNF, то неявно подразумевается, что уже существует MOF, в котором определены такие понятия как «класс», «свойство», «отношение» и т.п. И в EBNF мы только указываем как описать эти понятия из MOF в виде последовательности символов. Но в самом EBNF при этом нет никаких классов, свойств и отношений. В нём есть только терминальные и нетерминальные символы, правила, конкантенация, выбор и т.д.