Мы пришли к выводу, что доступ к большинству объектов в смещённых нагрузках кэша выполняется только за короткий промежуток времени, поэтому критически важно быстро вытеснять их из кэша. А главная особенность S3-FIFO — это небольшая очередь FIFO, отфильтровывающая большинство объектов, не давая им попасть в основной кэш.
Предисловие
Программные кэши, например, кэши ключей и значений, пулы буферов баз данных, страничные кэши и кэши объектов сегодня широко используются для ускорения доступа к данным.
Кэш должен обладать следующими свойствами:
- практичностью/эффективностью: он должен обеспечивать низкий уровень промахов, что позволит ему выполнять большее количество запросов;
- производительностью: при передаче данных из кэша необходимо выполнять минимальное количество операций; и
- масштабируемостью: количество попаданий кэша, которое он может передать в секунду, должно увеличиваться с ростом количества ядер CPU. В основе кэша лежит алгоритм вытеснения данных, определяющий его эффективность, пропускную способность и масштабируемость.
Вытеснение на основе LRU и FIFO
Хотя FIFO и LRU стали классикой алгоритмов вытеснения данных из кэша, в стремлении повышения эффективности за последние десятилетия было разработано множество алгоритмов вытеснения, например, ARC, 2Q, LIRS, TinyLFU.
Так как считается, что LRU обеспечивает меньший уровень промахов по сравнению с алгоритмами на основе FIFO, например, CLOCK (хотя мы недавно выяснили. что это неправда), эти усовершенствованные алгоритмы часто основаны на LRU и используют различные техники и метрики поверх одной или нескольких очередей LRU.
Однако у алгоритмов на основе LRU есть три проблемы: (1) они требуют по два указателя на объект, что приводит к большим тратам ресурсов для нагрузок, состоящих из мелких объектов; (2) они не масштабируемы, потому что каждое попадание кэша требует продвижения требуемого объекта в голову очереди, контролируемой блокировкой; и (3) неудобен для флэш-памяти из-за произвольной записи.
Важность масштабируемости
Современные CPU обладают большим количеством ядер. Например, AMD EPYC 9654P имеет 192 ядра/потока. Масштабируемость кэша — это показатель того, как его пропускная способность увеличивается при росте количества ядер CPU.
В идеале пропускная способность кэша должна масштабироваться линейно с повышением количества ядер CPU. Однако в алгоритмах на основе LRU операциям чтения требуются обновления метаданных при блокировке. Следовательно, они не могут полностью воспользоваться вычислительными мощностями современных CPU.
Стремление к простоте
«Прогнозирование страниц, к которым будет выполняться доступ в ближайшее время — это сложная задача, и в ядре возникло множество механизмов, спроектированных с целью повышения вероятности правильной догадки. Но ядро не только часто ошибается, но и может потратить много времени CPU на то, чтобы сделать неверный выбор». — Разработчики ядра
Сложность алгоритма вытеснения данных из кэша играет важную роль в его использовании. Хотя сложность часто коррелирует с пропускной способностью, простая структура также уменьшает количество багов и затраты на поддержку.
FIFO — это будущее
Хотя алгоритмы вытеснения раньше брали за основу LRU, я считаю, что современные алгоритмы должны проектироваться на основе очередей FIFO.
FIFO можно реализовать при помощи кольцевого буфера без метаданных указателей для каждого объекта, и они не поднимают объект при каждом попадании кэша, таким образом устраняя узкое место, мешающее масштабированию. Более того, FIFO вытесняет объекты в том же порядке, что и при вставке, а это удобный для флэш-памяти паттерн доступа, он минимизирует количество записей во флэш-память и её износ. Однако FIFO отстают по эффективности от LRU и от современных алгоритмов вытеснения.
Наблюдение: количество one-hit wonder больше, чем можно ожидать
Термин «показатель one-hit-wonder» характеризует долю объектов, запрашиваемых только один раз в последовательности. Он широко используется в content delivery network (CDN) из-за высоких показателей one-hit-wonder. Хотя показатель one-hit-wonder сильно меняется в зависимости от типа нагрузок, мы вы выяснили, что более короткие последовательности запросов (с меньшим количеством объектов) часто имеют более высокие показатели one-hit-wonder.
▍ Искусственный пример

Рисунок выше иллюстрирует это наблюдение на искусственном примере. Последовательность запросов состоит из семнадцати запросов к пяти объектам, из которых доступ к одному (E) происходит только один раз. Таким образом, показатель one-hit-wonder для этой последовательности составляет 20%.
Если рассмотреть более короткую последовательность запросов с 1 по 7, то запрашиваются один раз два (C, D) из четырёх уникальных объектов, что приводит к показателю one-hit-wonder, равному 50%. Аналогично, показатель one-hit-wonder более короткой последовательности запросов с 1 по 3 равен 67%.
▍ Примеры из трассировок в продакшене
Справедливо ли это для нагрузок кэша в продакшене?

На рисунке выше показана трассировка кэша блоков (MSR hm_0) и кэша ключей и значений компании Twitter (кластер 52). На оси X отложена доля объектов в трассировке (в линейном и логарифмическом масштабах). По сравнению с показателем one-hit-wonder полной трассировки, равным 13% (Twitter) и 38% (MSR), случайная подпоследовательность, содержащая 10%, имеет показатель one-hit-wonder 26% (трассировка Twitter) и 75% (трассировка MSR).

Мы проанализировали большую коллекцию из 6594 трассировок кэшей (подробнее см. в разделе о результатах) и составили диаграмму распределения показателей one-hit-wonder. По сравнению с полными трассировками, медианный показатель one-hit-wonder которых равен 26%, последовательности, содержащие 50% объектов трассировки, демонстрируют медианный показатель one-hit-wonder 38%. Более того, последовательности, содержащие 10% и 1% объектов, демонстрируют показатели one-hit-wonder 72% и 78%.
▍ Последствия большого показателя one-hit-wonder
В анализе в основном использовались трассировки за неделю, а также несколько трассировок за месяц. Так как размер кэша часто намного меньше, чем объём трассировки (количество объектов/байтов в трассировке), вытеснение начинается спустя короткую последовательность запросов. Наши наблюдения позволяют сделать вывод, что если размер кэша составляет 10% от объёма трассировки. то примерно 72% объектов не будет повторно использовано после вытеснения.

Мы подтвердили результаты наблюдений благодаря симуляции кэшей. На рисунке выше показано распределение частот объектов при вытеснении. Наш анализ трассировок показывает, что трассировка Twitter имеет показатель one-hit-wonder 26% для последовательностей в 10% от объёма трассировок. Симуляция показывает схожий результат: 26% вытесненных LRU объектов не было запрошено после вставки при размере кэша в 10% от объёма трассировки. Аналогично, трассировка MSR демонстрирует повышенный показатель one-hit-wonder в 75% для длин последовательностей в 10% от объёма трассировок, а симуляции показывают, что 82% вытесненных LRU объектов повторно не используется.
Очевидно, что кэш должен отфильтровывать эти one-hit wonder, потому что они занимают место, не давая никаких преимуществ.
S3-FIFO: алгоритм вытеснения на одних очередях FIFO
Мотивировавшись наблюдениями из предыдущего раздела, мы спроектировали новый алгоритм вытеснения данных из кэша под названием S3-FIFO: Simple, Scalable caching with three Static FIFO queues.

В S3-FIFO используется три очереди FIFO: малая очередь FIFO (S), основная очередь FIFO (M) и призрачная очередь FIFO (G). На основании экспериментов с 10 трассировками мы решили, что S должна занимать 10% от пространства кэша и выяснили, что 10% хорошо обобщаются.
M занимает 90% пространства кэша. Призрачная очередь G хранит то же количество призрачных элементов (не данных), что и M.
Чтение кэша: S3-FIFO использует по два бита на объект для отслеживания статуса доступа к объекту, схожего с ограниченным счётчиком с частотой до 31. Попадания кэша в S3-FIFO атомарным образом выполняют инкремент счётчика на один. Стоит отметить, что большинство запросов к популярным объектам не требует обновления.
[1] Также мы экспериментировали с порогом перехода 1 из малой в основную очередь, показавшим почти такую же эффективность; однако мы решили использовать 2-битный, потому что он более устойчив и отфильтровывает больше объектов.
Запись в кэш: новые объекты вставляются в S, если их нет в G. В противном случае они вставляются в M. Когда S заполнена, объект в хвосте, если доступ к нему выполняется более одного раза, перемещается в M, а в противном случае он перемещается в G. При перемещении его биты доступа сбрасываются. Когда G заполнена, она вытесняет объекты в порядке FIFO. M использует алгоритм, схожий с FIFO-Reinsertion, но при помощи двух битов отслеживает информацию о доступе. Объекты, доступ к которым выполняется хотя бы один раз, вставляются заново, а один их бит становится равным 0 (это аналогично снижению частоты на 1).

▍ Реализация
Хотя S3-FIFO имеет три очереди FIFO, его можно также реализовать с оной или двумя очередями FIFO.
Так как объекты, вытесненные из S, могут попасть в M, их можно реализовать при помощи одной очереди с указателем, указывающим на отметку 10%. Однако объединение S и M снижает масштабируемость, потому что удаление объектов из середины очереди требует блокировки.
Призрачную очередь FIFO G можно реализовать как часть инфраструктуры индексирования. Например, если мы храним отпечаток и время вытеснения в призрачных элементах в хэш-таблице на основе бакетов. Отпечаток (fingerprint) хранит хэш объекта в 4 байтах, а время вытеснения — это временная метка, измеряемая в количестве объектов, вставленных в G.
Мы можем узнать, находится ли объект по-прежнему в очереди, вычислив разность между текущим временем и временем вставки, так как это очередь FIFO. Призрачные элементы остаются в хэш-таблице, пока не перестанут находится в призрачной очереди. Когда элемент вытесняется из призрачной очереди, он не сразу удаляется из хэш-таблицы. Вместо этого элемент хэш-таблицы удаляется во время коллизии хэшей, когда требуется слот для хранения других элементов.
Сравнение S3-FIFO с другими алгоритмами
▍ Использованный в этой статье датасет
Мы оценивали S3-FIFO при помощи большой коллекции из 6594 трассировок продакшена из 14 датасетов, включающих в себя 11 оперсорсных и 3 проприетарных датасетов. Эти трассировки создавались с 2007 по 2023 год и содержат кэши ключей и значений, блоков и объектов CDN. Суммарно датасеты содержат 856 миллионов запросов к 61 миллиардам объектов 21088 ТБ трафика к 3573 ТБ данных. Подробности датасетов приведены в таблице.
| Коллекции датасетов | Прибл. время | Тип кэша | Интервал (в днях) | Трассировки | Запросы (млн) | Запросы (ТБ) | Объекты (млн) | Объекты (ТБ) | Показатель One-hit-wonder (полная трассировка) | Показатель One-hit-wonder (10%) | Показатель One-hit-wonder (1%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MSR | 2007 | Блоки | 30 | 13 | 410 | 10 | 74 | 3 | 0.56 | 0.74 | 0.86 |
| FIU | 11.2008 | Блоки | 9-28 | 9 | 514 | 1.7 | 20 | 0.057 | 0.28 | 0.91 | 0.91 |
| Cloudphysics | 2015 | Блоки | 7 | 106 | 2114 | 82 | 492 | 22 | 0.40 | 0.71 | 0.80 |
| CDN 1 | 2018 | Объекты | 7 | 219 | 3728 | 3640 | 298 | 258 | 0.42 | 0.58 | 0.70 |
| Tencent Photo | 2018 | Объекты | 8 | 2 | 5650 | 141 | 1038 | 24 | 0.55 | 0.66 | 0.74 |
| WikiMedia CDN | 2019 | Объекты | 7 | 3 | 2863 | 200 | 56 | 13 | 0.46 | 0.60 | 0.80 |
| Systor | 2017 | Блоки | 26 | 6 | 3694 | 88 | 421 | 15 | 0.37 | 0.80 | 0.94 |
| Tencent CBS | 2020 | Блоки | 8 | 4030 | 33690 | 1091 | 551 | 66 | 0.25 | 0.73 | 0.77 |
| Alibaba | 2020 | Блоки | 30 | 652 | 19676 | 664 | 1702 | 117 | 0.36 | 0.68 | 0.81 |
| 2020 | Ключ-значение | 7 | 54 | 195441 | 106 | 10650 | 6 | 0.19 | 0.32 | 0.42 | |
| Social Network 1 | 2020 | Ключ-значение | 7 | 219 | 549784 | 392 | 42898 | 9 | 0.17 | 0.28 | 0.37 |
| CDN 2 | 2021 | Объекты | 7 | 1273 | 37460 | 4925 | 2652 | 1581 | 0.49 | 0.58 | 0.64 |
| Meta KV | 2022 | Ключ-значение | 1 | 5 | 1644 | 958 | 82 | 76 | 0.51 | 0.53 | 0.61 |
| Meta CDN | 2023 | Объекты | 7 | 3 | 231 | 8800 | 76 | 1563 | 0.61 | 0.76 | 0.81 |
▍ Структура эксперимента
Мы реализовали S3-FIFO и популярные алгоритмы в libCacheSim, а для выполнения крупномасштабной оценки применили собственную распределённую вычислительную платформу. Если не сказано иное, мы игнорируем размер объектов, потому что большинство систем в продакшене использует для управления памятью slab-хранилище, где вытеснение выполняется в одном slab-классе (объектов схожих размеров). Так как в большом количестве трассировок присутствовал очень широкий диапазон показателей промахов, мы решили показать снижение показателя промахов по сравнению с FIFO. Кроме того, мы реализовали прототип на Cachelib, подробности можно прочитать в нашей научной статье. Симуляция обрабатывала датасеты почти в ста проходах разными алгоритмами, с разными размерами кэша и параметрами. По нашим оценкам — было обработано более 80 триллионов запросов и затрачен миллион ядро-часов CPU.
▍ Результаты по эффективности
Основной причиной критики алгоритмов вытеснения на основе FIFO является их эффективность — самая важная для кэша метрика. Мы сравнили S3-FIFO с 12 лучшими алгоритмами вытеснения, созданными за последние несколько десятков лет. Мы используем размер кэша в 10% от объёма трассировок (количества объектов в трассировке), основываясь на нашем опыте работы со множеством систем в продакшене. В научной статье мы указали, что при других размерах кэшей результаты оказываются схожими.

На рисунке выше показано снижение показателя промахов (запросов) разных алгоритмов (по сравнению с FIFO). В большинстве перцентилей S3-FIFO имеет наибольшее снижение по сравнению с другими алгоритмами. Например, S3-FIFO снижает показатель промахов более чем на 32% для 10% трассировок (P90) со средним значением 14%.
Самый близкий конкурент — это TinyLFU. TinyLFU использует окно 1% LRU для отфильтровывания непопулярных объектов и хранит большинство объектов в кэше SLRU. Высокая производительность TinyLFU подтверждает наше наблюдение, что для эффективности критически важно быстрое понижение (quick demotion). Однако TinyLFU справляется хорошо не со всеми трассировками, его показатели промахов ниже, чем у FIFO почти на 20% трассировок (точка P10 ниже -0.05 и не показана на рисунке). Это явление более выражено при малом размере кэша, когда TinyLFU хуже, чем FIFO почти на 50% трассировок (на рисунке не показано).
TinyLFU терпит неудачу по двум причинам. Во-первых, окно 1% LRU слишком мало и объекты вытесняются слишком быстро. Следовательно, увеличение размера окна до 10% от размера кэша (TinyLFU-0.1) существенно повышает эффективность в хвосте (низ рисунка). Однако увеличение размера окна снижает результаты на трассировках, с которыми алгоритм проявляет себя лучше всего. Во-вторых, когда кэш заполнен, TinyLFU сравнивает наименее давний использованный элемент из оконного LRU и основного SLRU, а затем вытесняет наименее часто используемый. Это позволяет TinyLFU быть более адаптивным к различным нагрузкам. Однако если окажется, что хвостовой объект в SLRU имеет очень высокую частоту, то это может привести к вытеснению излишнего количества новых и потенциально полезных объектов.
Для выбора кандидатов на вытеснение LIRS использует расстояние повторного использования стека LRU. Так как one-hit wonder не имеют расстояния повторного использования, для их хранения LIRS использует очередь в 1%. Эта малая очередь выполняет быстрое понижение и является тайным источником высокой эффективности LIRS. Как и в TinyLFU, очередь слишком мала и с некоторыми нагрузками кэшей терпит неудачу. Однако по сравнению с TinyLFU меньшее количество трассировок демонстрирует показатели промахов выше, чем у FIFO, потому что метрика взаимной недавности в LIRS более надёжна, чем частотность в TinyLFU. В частности, TinyLFU не может различать множество объектов с одинаковой низкой частотой (например, 2), но эти объекты будут иметь разные значения взаимной недавности. Недостаток заключается в том, что LIRS требует более сложной реализации, чем TinyLFU.
2Q имеет самую близкую к S3-FIFO структуру. Он использует под очередь FIFO 25% от пространства кэша, остальное под очередь LRU, а также имеет призрачную очередь. Кроме различий в типе и размере очередей, объекты, вытесненные из малой очереди, не вставляются в очередь LRU. Наличие большой испытательной очереди и отсутствие перемещения объектов, к которым осуществлялся доступ, в очередь LRU — главные причины того, что 2Q не так хорош, как S3-FIFO. Более того, по нашим наблюдениям, очередь LRU не обеспечивает заметных преимуществ по сравнению с очередью FIFO (с повторной вставкой) алгоритма S3-FIFO.
SLRU использует четыре очереди LRU равного размера. Объекты сначала вставляются в очередь LRU самого низкого уровня, а затем при попадании кэша повышаются до очередей более высокого уровня. Вставленный объект вытесняется, если не используется повторно в самой нижней очереди LRU, которая выполняет быстрое понижение и позволяет SLRU демонстрировать хорошую эффективность. Однако в отличие от других схем, SLRU не использует призрачную очередь, из-за чего он не толерантен к сканированиям, поскольку смешанные в сканировании популярные объекты невозможно различить. Поэтому мы наблюдали, что SLRU имеет низкую производительность со многими нагрузками блоковых кэшей (на рисунке не показаны).
ARC использует четыре очереди LRU: две для данных, две для призрачных элементов. Две очереди данных используются для разделения недавних и частых объектов. Попадания кэша в объекты в очереди недавности повышают объекты в очередь частотности. Объекты, вытесненные из двух очередей данных, попадают в соответствующую призрачную очередь. Размеры очередей адаптивно настраиваются на основании попаданий в призрачных очередях. Если очередь недавности мала, новые вставляемые объекты быстро вытесняются, обеспечивая высокую эффективность ARC. Однако ARC менее эффективен, чем S3-FIFO, потому что адаптивного алгоритма недостаточно. Подробнее мы расскажем об этом в следующем разделе.
Также мы оценили новые алгоритмы, в том числе CACHEUS, LeCaR, LHD и FIFO-Merge. Однако мы выяснили, что эти алгоритмы часто менее конкурентоспособны, чем традиционные. В частности, FIFO-merge был спроектирован для хранилищ со структурой журнала и нагрузок кэшей «ключ-значение» без устойчивости к сканированию. Поэтому, как и SLRU, он лучше проявляет себя с нагрузками веб-кэшей, но гораздо хуже с нагрузками блоковых кэшей.
Обобщённые алгоритмы наподобие B-LRU (Bloom Filter LRU), CLOCK и LRU. CLOCK и LRU не обеспечивают быстрого понижения, поэтому для них уменьшение показателя промахов мало. B-LRU представляет собой другую крайность. Он отклоняет все one-hit wonder ценой второго запроса всех объектов, которые оказываются промахами кэша. Из-за этих промахов B-LRU в большинстве случаев хуже LRU.
Негативные для S3-FIFO нагрузки: мы исследовали ограниченное количество трассировок, с которыми S3-FIFO показывал низкую производительность, и выявили один паттерн. Доступ к большинству объектов в этих трассировках выполнялся только дважды, и второй запрос выпадал из малой очереди FIFO S, из-за чего второй запрос к этим объектам был промахами кэша. Такие нагрузки негативны для большинства алгоритмов, разбивающих пространство кэша, например, для TinyLFU, LIRS, 2Q и CACHEUS. Так как сегмент для этих новых вставленных объектов меньше, чем размер кэша, может быть так, что второй запрос становится попаданием кэша в LRU и FIFO, но не в этих сложных алгоритмах.

S3-FIFO не просто эффективен, его эффективность ещё и устойчива. На рисунке выше показано среднее снижение показателя промахов для каждого датасета при использовании выбранных алгоритмов. S3-FIFO часто опережает другие алгоритмы с большим отрывом. Более того, это лучший алгоритм для 10 из 14 датасетов, и в тройке самых эффективных алгоритмов для 13 датасетов. Для сравнения: TinyLFU и LIRS находятся в списке лучших алгоритмов для некоторых датасетов, но для других датасетов они среди худших алгоритмов.
Хотя показатель промахов (запросов) важен для большинства (а то и для всех) размещений в кэше, в CDN также широко используется показатель байтовых промахов для измерения снижения загрузки сети.
По сравнению с другими алгоритмами S3-FIFO демонстрирует большее снижение показателей байтовых промахов, схожее с показанным выше рисунком.
▍ Показатели пропускной способности
Легко заметить, что как и другие алгоритмы на основе FIFO, S3-FIFO более масштабируем, чем алгоритмы на основе LRU. Наша реализация на Cachelib при 16 потоках достигает в шесть раз большей пропускной способности, чем оптимизированный LRU на Cachelib. Подробности см. в научной статье.
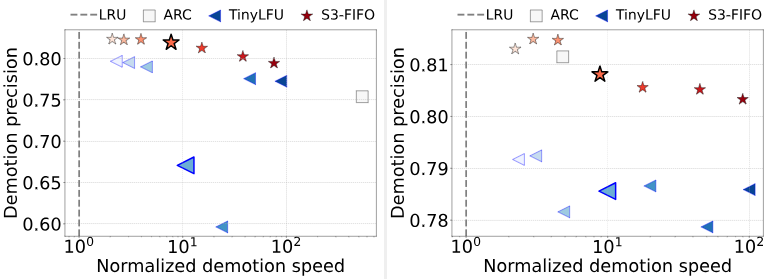
Почему адаптивные алгоритмы работают плохо?
Существует множество адаптивных алгоритмов, например, ARC и TinyLFU, которые также выполняют быстрое понижение, и которые теоретически должны работать так же хорошо, как S3-FIFO. В чём же они терпят неудачу? Чтобы стало понятнее, мы внимательнее присмотримся к скорости и точности понижения. Нормализованная скорость быстрого понижения показывает, как долго объекты остаются в S, прежде чем будут вытеснены или перемещены ы M.
Мы используем для сравнения длительность вытеснения LRU и вычислим скорость как
длительность вытеснения LRU / время нахождения в S. Здесь мы используем логическое время, измеряемое в количестве запросов.Точность быстрого понижения показывает, сколько объектов, вытесненных из S, не используются повторно вскоре после этого. Если количество запросов до следующего повторного использования объекта больше, чем
размер кэша / показатель промахов, то мы считаем, что быстрое понижение приводит к правильному раннему вытеснению.Алгоритм с более быстрым и точным быстрым понижением демонстрирует более низкий показатель промахов.
Показатели промахов для трассировок Twitter и MSR при использовании разных размеров S. На трассировке Twitter ARC имел показатель промахов 0.0483, а LRU — 0.0488. На трассировке MSR ARC имел показатель промахов 0.2891, LRU — 0.3188.
| Трассировка | Размер S | 0.01 | 0.02 | 0.05 | 0.10 | 0.20 | 0.30 | 0.40 |
|---|---|---|---|---|---|---|---|---|
| TinyLFU | 0.0437 | 0.0437 | 0.0586 | 0.0530 | 0.0441 | 0.0445 | 0.0451 | |
| S3-FIFO | 0.0423 | 0.0422 | 0.0422 | 0.0424 | 0.0432 | 0.0442 | 0.0455 | |
| MSR | TinyLFU | 0.2895 | 0.2904 | 0.2893 | 0.2900 | 0.2936 | 0.2949 | 0.2990 |
| MSR | S3-FIFO | 0.2889 | 0.2887 | 0.2884 | 0.2891 | 0.2896 | 0.2936 | 0.2989 |
Для выбора S (очереди недавности) ARC использует адаптивный алгоритм. Мы обнаружили, что алгоритм может выявлять нужное направление для изменения размера, но находимый им размер слишком велик или слишком мал. Например, ARC выбирает очень малую S для трассировки Twitter, из-за чего большинство новых объектов слишком быстро выталкивается с низкой точностью. Это происходит из-за двух свойств трассировки. Во-первых, объекты в трассировке Twitter часто имеют множество запросов; во-вторых, постоянно генерируются новые объекты. Поэтому объекты, вытесненные из M, запрашиваются очень скоро, из-за чего S уменьшается до очень малого размера (примерно 0,01% от размера кэша).
Тем временем, постоянно генерируемые новые (и популярные) объекты в S сталкиваются с конкуренцией и часто страдают от промахов до вставки в M, что приводит к низкой точности и высокому показателю промахов. На трассировке MSR ARC имеет приличную скорость с относительно высокой точностью, что коррелирует с его низким показателем промахов.
TinyLFU и S3-FIFO имеют предсказуемую скорость быстрого понижения — уменьшение размера S всегда повышает скорость понижения. При использовании одинакового размера S TinyLFU выполняет понижение чуть быстрее, чем S3-FIFO, потому что использует LRU, который сохраняет старые объекты, доступ к которым выполнялся недавно, уменьшая пространство, доступное новым вставляемым объектам.
Кроме того, S3-FIFO часто демонстрирует повышенную по сравнению с TinyLFU точность при схожей скорости быстрого понижения, что объясняет более низкий показатель промахов S3-FIFO. TinyLFU сравнивает кандидатов на вытеснение и S, и M, а затем вытесняет наименее часто используемого кандидата. Когда кандидат на вытеснение из M имеет высокую частотность, это приводит к вытеснению из S множества объектов, которые стоило сохранить. Это вызывает не только низкую, но и непредсказуемую точность, а также резкие скачки показателя промахов. Например, точность резко падает при размере S в 5% и 10%, что соответствует резкому повышению показателя промахов (в таблице).
Хотя в S3-FIFO не используются сложные техники, он достигает устойчивых и предсказуемых скорости и точности быстрого понижения. С увеличением размера S скорость уменьшается монотонно (сдвигаясь на рисунке влево), а точность также увеличивается, пока не достигнет пика. Когда S очень мала, у популярных объектов недостаточно времени для накопления попаданий до вытеснения, поэтому точность низка. Увеличение размера S приводит к увеличению точности. Если S очень велика, многие непопулярные объекты запрашиваются в S и перемещаются в M, что тоже приводит к снижению производительности. Показанные в таблице показатели промахов демонстрируют, что при схожей скорости быстрого понижения повышенная точность всегда приводит к пониженным показателям промахов.
▍ Можно ли заставить адаптивные алгоритмы работать лучше?
Также мы поэкспериментировали с использованием адаптивных алгоритмов для изменения размеров очередей FIFO в S3-FIFO. Результаты экспериментов показывают, что использование адаптивного алгоритма позволяет повысить показатели для хвостов, но снижают общую производительность. Мы выяснили, что настройка адаптивного алгоритма — очень сложная задача.
На самом деле, адаптивные алгоритмы имеют большое количество параметров. Например, для изменения размеров очереди требуется множество параметров, в частности, частота изменения размера, объём перемещаемого каждый раз пространства, нижняя граница размеров очередей и пороговое значение, приводящее к изменению размера.
Наряду с использованием сложных в настройке параметров, адаптивные алгоритмы адаптируются на основании наблюдений из прошлого. Однако прошлое не может предсказать будущее. Мы выяснили, что небольшие изменения в нагрузке могут приводить к излишней реакции адаптивного алгоритма. Непонятно, как балансировать недостаточную и чрезмерную реакции, не вводя дополнительные параметры. Более того, некоторые адаптивные алгоритмы косвенно подразумевают, что кривая показателей промахов выпуклая, потому что следование в направлении градиента приводит к глобальному оптимуму. Однако кривые показателей промахов в нагрузках с активным использованием сканирования часто бывают невыпуклыми.
Заключение
Мы показали, что кэш часто сталкивается с более высоким показателем one-hit-wonder, чем при обычном анализе полных трассировок. Наше исследование 6594 трассировок продемонстрировало, что быстрое устранение one-hit wonder (быстрое понижение) является тайным оружием многих сложных алгоритмов. Вдохновившись этим, мы спроектировали S3-FIFO — простой (Simple) и масштабируемый (Scalable) алгоритм вытеснения данных из кэша, состоящий из одних статических (Static) очередей FIFO. Наша оценка показала, что S3-FIFO достигает более высокой и устойчивой эффективности, чем другие современные алгоритмы. В то же время он более масштабируем, чем алгоритмы на основе LRU.
Благодарности
Я бы хотел поблагодарить многих людей, в том числе моих соавторов, Parallel Data Lab Университета Карнеги — Меллона (и наших спонсоров), а также Cloudlab. Также я выражаю огромную благодарность людям и организациям, выложившим трассировки в опенсорс и поделившихся ими с нами.
▍ Информация о датасетах
Эта работа была опубликована на SOSP’23, подробности см. здесь, а слайды можно найти здесь.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ????️

Комментарии (4)

gybson_63
06.09.2023 19:55+1Ловкость рук =)) Принцип FIFO сломан же, первым выходит не первый вошедший.
"Если количество запросов до следующего повторного использования объекта больше, чемразмер кэша / показатель промахов"
Т.е. чем больше промахов и меньше кэш, тем цель ближе. Если промахов нет, то приплыли. Очень сомнительная метрика.


WVitek
06.09.2023 19:55Хех, как-то давно пилил сборку мусора для самописного key-value персистентного хранилища,
там было 8 уровней частоты изменения объектов и принцип "чехарды" (ну почти FIFO) - когда активные данные (на которые есть ссылки) переносились в конец секционированного лог-журнала, как бы "перепрыгивая" через другие данные, а мусорные записи оставались и когда в начальной секции не оставалось активных данных, начальная секция удалялась.
Также, если данные с прошлой сборки мусора не менялись, они переносились в конец следующего по частоте изменения уровня (на 0 уровне хранились наиболее часто изменяемые данные, на последнем 7-м - самые редко изменяемые).
Из преимуществ - можно было приостанавливать сборку мусора и делать бекапы файлов хранилища "на лету", в т.ч. rsync'ом, без рисков потери согласованности (ну это у всех лог-журнальных схем хранения так).
Короче, похожая тема, 3 бита в адресе под уровень частоты изменения и 1 бит под признак изменённости с прошлой сборки мусора. Адреса, соответственно, кратны 16...
mentin
Эту статью надо назвать - как изобрести заново и добавить в алгоритмы FIFO три поколения из современных сборщиков мусора с поколениями (generational garbage collection). Интересно, действительно изобрели заново или скопировали, но ни разу не упомянули GC?