Последнее время мне приходится много ревьювить, анализировать, рефакторить C# код. Практика показывает, что принципы Объектно-Ориентированного Программирования не просто вызывают затруднения в понимании, и в применении, в большинстве случаев разработчики просто избегают их использования на практике. Я очень надеюсь, что мой относительно простой пример, который можно не только скомпилировать и выполнить, но и написать свой класс расширения и снова скомпилировать, и оценить результат уже своего труда внутри небольшой законченной программы, надеюсь это поможет кому-то преодолеть барьер к использованию принципов ООП на практике.
Конечно, мне придется продемонстрировать применение на практике принципов ООП: инкапсуляция, наследование, полиморфизм и то, как они работают.
Конечно, разберем как все это влияет на производительность. Я надеюсь, что получится сформулировать некое подобие ответа на критику постулатов «чистого» кода от достаточно успешного (видимо) иностранного программиста в переводе на Хабре: «Чистый» код, ужасная производительность.
Правила «чистого» кода, изложенные в той статье помогут нам подойти к реализации принципов ООП в нашей задаче.
Мне довелось лицезреть множество абстрактных оторванных от жизни примеров с кошками, собачками, машинками, трансформерами, треугольниками, кружочками, … которые призваны объяснить принципы ООП. Ну не серьезно как-то это все. Все такие примеры приводят к тому, мне кажется, что начинающие программисты, которые уже решают реальные практические задачи, так и относятся к этой концепции, как к какой-то красивой, но абстрактной идее, которую никто не смог применить на практике. Давайте попробуем разобрать задачу, которую не только интересно порешать, но также интересно поработать с результатом ее решения, или даже попросить кого-то поработать с этим результатом чтобы оценить то, что называется “user experience” со стороны.
Формулировка задачи и того, где она может быть полезна
Сразу хочу обратить внимание: пример, который я собираюсь рассмотреть, никак не будет связан с функциональностью баз данных, хранением, доступом к данным. Я предлагаю сосредоточиться только на логике генерации арифметических выражений, проверке их решения пользователем и взаимодействии с пользователем программы при такой проверке. Для максимальной простоты и компактности примера мы будем использовать консольный ввод вывод. Но если кто-то захочет использовать идею и продавать соответствующую визуальную версию программы для Андроида например, буду благодарен за любые отчисления с продукта, Шутка :) .
Мы будем рассматривать нашу программа-задачу как будто существует некоторое задание на разработку этой программы непрофессионально сформулированное, но вполне понятное (как это обычно и происходит на практике).
Итак, мы должны написать прототип программы, которая будет проверять способность к устным вычислениям школьника, хотя, кто может гарантировать что в ходе какого-нибудь исследования (про него см. далее) не появится интереса собрать статистику по взрослым? А значит нельзя исключать расширения списка операций в любую сторону.
программа должна случайным образом выбирать арифметическую операцию, из списка, например: умножение, деление, сложение-вычитание двухзначных чисел, … (возможно даже составные примеры, примеры со скобками)
для этого должны случайным образом генерироваться числа для формирования операции для пользователя;
программа должна выводить такой случайный пример для решения-вычисления и ввода ответа пользователем;
программа должна ждать ответа, или команды на завершение программы, если решили зациклить программу (пускай по символу "q", например);
похвалить в случае правильного ответа или сообщить правильный результат в случае ошибки.
Можно вывести некоторую статистику по завершении программы.
Я даже рискну изложить здесь описание некоторого практического контекста, в рамках которого, гипотетически, могла бы использоваться программа-задача, которую мы будем рассматривать. Возможно, это поможет мне сократить количество критики относительно практической ценности такой обучающей задачи. Хотя не приходится, конечно, надеяться, что критики совсем не будет. Критика в любом случае приветствуется, это не только мое отношение, это политика Хабра, насколько я понимаю.
Представьте, что некоторая образовательная структура собирается провести исследование статистики по способностям школьников младших классов к устному счету. Требуется написать программу, которая случайным образом генерирует простые (и не очень) арифметические примеры, фиксирует-регистрирует ответы и, в каком-то виде, сохраняет их для дальнейшего анализа. Формат исследования предполагает, что параметры тестовых заданий и их содержание могут изменяться, варьироваться, дополняться на разных этапах … и т. д. ... и т. п.
Возможно, кому-то покажется что требования слишком общие и/или плохо сформулированы, но заказчик и не должен хорошо разбираться в том, для чего он пригласил нас как специалистов, наша задача состоит, в том числе, в том, чтобы продемонстрировать заказчику возможности программы, которую мы собираемся ему предложить, чтобы удовлетворить даже те его потребности, о которых он может иметь даже ошибочное представление.
Вообще, надо заметить, что задача интересна в том числе тем, что ее можно практически бесконечно уточнять и в то же время расширять для покрытия все новых и новых требований, например на способы контроля заданных уровней вероятности разного типа операций, последовательности выпадающих чисел, регистрации разного рода аспектов процесса, статистик и т. д. и т. п.
Я постараюсь, насколько это возможно, не отвлекаться на то, что можно добавить в такую программу, я постараюсь сосредоточиться на демонстрации применения принципов ООП при минимальном количестве кода и на оценке производительности полученного решения с реализованными принципами ООП.
Первая версия программы
Рассмотрим для начала код с реализацией пары операций ("*" умножить и "-" минус):
static void Main(string[] args)
{//Main1.5
const string spliter = "--------------------------------------------------------";
Console.WriteLine("Hello, colleague!");
Console.WriteLine(spliter);
Random rnd = new Random();
int[] operStat = { 0, 0 };
while (true)
{
int oIndx = rnd.Next(2);
int res;
int num1;
int num2;
if (oIndx == 0)
{
num1 = rnd.Next(2, 10);//it is one digit multiplication
num2 = rnd.Next(2, 10);//const 10 is linked to mul where we should define it?
Console.WriteLine($"Please Solve: {num1} * {num2} = <..>");
res = num1 * num2;
}
else
{
num1 = rnd.Next(2, 100);//it is two digit subtraction
num2 = rnd.Next(2, 100);//const 100 is linked to sub where we should define it?
if(num1 > num2) { res = num2; num2 = num1; num1 = res; }
Console.WriteLine($"Please Solve: {num2} - {num1} = <..>");
res = num2 - num1;
}
operStat[oIndx]++;
Console.Write("type answer here:");
string answer = Console.ReadLine();
if (answer == "stop")
{
break;
}
int.TryParse(answer, out num1);
if (num1 == res)
{
Console.WriteLine("Congratulations it is correct answer!");
}
else
{
Console.WriteLine($"{num1} is wrong answer. Correct is {res}");
}
Console.WriteLine(spliter);
}
Console.WriteLine(spliter);
Console.WriteLine($"Count of * operations={operStat[0]}");
Console.WriteLine($"Count of + operations={operStat[1]}");
Console.WriteLine(spliter);
}Если ее скомпилировать и запустить на исполнение, можно получить такой результат, просто нажимая Enter несколько раз (про удобство при тестировании всегда надо помнить), что интерпретируется как неправильный ответ:
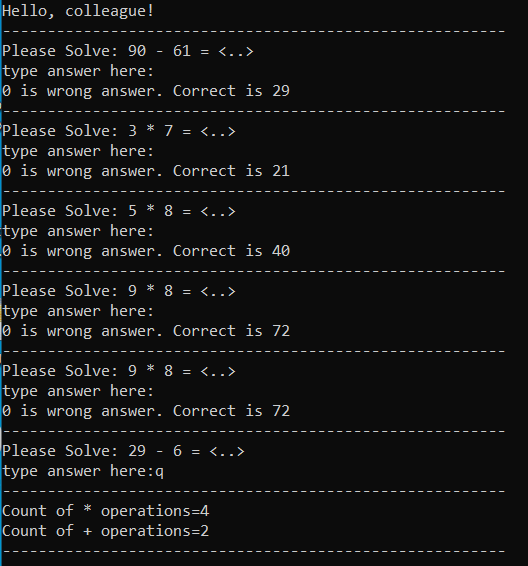
В общем и целом, все работает для двух операций, но как нам добавить третью и четвертую? А как расширять статистику?.. Это пара самых простых вопросов, которые приходят на ум с первого взгляда. И тут нам придут на помощь правила «чистого» кода, взятые из статьи с критикой этого самого «чистого» кода:
Используйте полиморфизм вместо «if/else» и «switch»;
Код не должен знать о внутренностях объекта, с которыми он работает;
Функции должны быть короткими;
Функции должны выполнять одну задачу;
«DRY» — Don't Repeat Yourself (не повторяйся)
Только тут есть одна загвоздка, эти правила ничего не говорят о том, что мы должны выбрать в качестве объекта, для которого мы будем реализовывать принципы ООП: полиморфизм, наследование, инкапсуляция.
Выбор объекта базового класса, философское отступление
Дело в том, что одна из самых значимых сложностей при реализации принципов ООП как раз состоит в том, чтобы правильно идентифицировать объект (класс объектов), для которых и надо применить эти принципы. Проблема состоит в том, что объекты в программе обычно совсем не похожи на объекты из привычного нам материального мира.
Для нашей задачи я предлагаю выбрать в качестве объекта математическую операцию, к классу которой относятся умножение и вычитание, которые мы использовали выше. С этого момента мы начинаем оперировать термином «абстракция» в виде обобщенной математической операции по отношению к конкретной операции, такой как «умножение», например.
Наш объект в виде математической операции в каком-то смысле является идеальным примером абстракции или абсолютной абстракцией. Математическая операция не существует как материальный объект, не принадлежит миру реальных вещей. Математическая операция — это идея о том, что можно делать с числами. Любая программа — это реализация мира идей. Это мир, в котором идеи обретают форму и наполнение, идеи становятся-превращаются в видимый, а значит осязаемый нашими органами чувств ИСХОДНЫЙ КОД. Исходный код позволяет достать нам свои идеи из головы и заставить их работать в реальном мире, позволяет нам передать идеи другим людям, через GIT, например, чтобы они их пощупали, потрогали, приспособили, присобачили куда-то, эти идеи.
Версия программы с классами
Теперь, когда мы определились с нашим абстрактным объектом, можно приступить к чистке кода. В первую очередь нам надо избавиться от if/else. Собственно этот if/else нам как бы и намекает: «Вы выбираете тут, по сути, тип объекта через индекс операции (oIndx). Может вам все-таки создать объект для этой операции, и обращаться к объекту этой операции через абстрактный интерфейс?». Если мы так и сделаем, может получиться что-то в таком роде:
static void Main(string[] args)
{//Main2
const string spliter = "--------------------------------------------------------";
Console.WriteLine("Hello, colleague!");
Console.WriteLine("To stop the program type \"q\" in answer.\n");
Console.WriteLine(spliter);
Random rnd = new Random();
MathOperation[] operArr = new MathOperation[]
{
new MulOperation(),
new DivOperation(),
new Sub2PosOperation()
};
while (true)
{
int oIndx = rnd.Next(operArr.Length); //(ocnt ++) % operArr.Length;
MathOperation proc = operArr[oIndx];
proc.init(rnd);
Console.WriteLine($"Please Solve: {proc.Visualise()} = <..>");
proc.execute();
Console.Write("type answer here:");
string? answer = Console.ReadLine();
if (answer == "q")
{
break;
}
int.TryParse(answer, out int res);
if (proc.check(res))
{
Console.WriteLine("Congratulations it is correct answer!");
}
else
{
Console.WriteLine($"\"{answer}\" is wrong answer. Correct is {proc.GetResult()}");
}
Console.WriteLine(spliter);
}
Console.WriteLine(spliter);
foreach (var op in operArr)
{
Console.WriteLine($"Count of {op.View} operations={op.Count}");
}
Console.WriteLine(spliter);
}Теперь у нас определены три операции. Теперь мы можем добавлять операции просто добавив создание объекта нового класса, предварительно написанного класса:
new MulOperation(),
new DivOperation(),
new Sub2PosOperation()Далее мы случайным образом выбираем одну из них и работаем мы с любой из них через интерфейс их базового класса: MathOperation.
С точки зрения интерфейса базового класса они не различаются, в этом суть полиморфизма. Код в цикле не знает с какой конкретной операцией он работает. Раз у нас есть код, который не знает внутреннего устройства объектов, с которыми он работает, это значит мы применили принцип инкапсуляции в этом коде, конкретные реализации скрыты. С наследованием все совсем просто, все это не работает если нет базового класса, от которого и унаследованы все конкретные операции.
Я только хочу здесь отметить, что все три понятия тесно связаны, наследование определяет подобие на основе базового класса и значит определяет полиморфизм. Переменные и код определенные наследником всегда можно скрыть от кода, который работает с объектом только через интерфейс базового класса.
Вот такой базовый класс у меня получился, что называется на вскидку:
abstract class MathOperation
{
public readonly string View;
protected int op1;
protected int op2;
protected int result;
public int Count;
protected MathOperation(string view) { View = view; }
public virtual void init(Random rnd)
{
op1 = rnd.Next(2, 10);
op2 = rnd.Next(2, 10);
}
public abstract string Visualise();
public abstract void execute();
public bool check(int answer)
{ Count++; return answer == result; }
public int GetResult() => result;
}И пара классов для операций умножения и вычитания:
class MulOperation : MathOperation
{
public MulOperation() : base("*") { }
public override string Visualise() => $"{op1} {View} {op2}";
public override void execute() => result = op1 * op2;
}
class Sub2PosOperation : MathOperation
{
public Sub2PosOperation() : base("-") { }
public override void init(Random rnd)
{
op1 = rnd.Next(2, 100);
op2 = rnd.Next(2, 100);
if (op2 > op1)
{ int tmp = op2; op2 = op1; op1 = tmp; }
}
public override string Visualise() => $"{op1} {View} {op2}";
public override void execute() => result = op1 - op2;
}Я уверен, что большинство знающих язык С# смогут написать лучше, чем у меня тут получилось, было бы кому тестировать.
Заметьте, операции отличаются не только самим действием операции, они также могут отличаться разрядностью чисел участвующих в операции. Для деления генерируются цифры от 2 до 9, но для вычитания это было бы уж слишком тривиально, поэтому выбран диапазон от 2 до 99.
Вообще говоря, можно написать классы, которые поддерживают составные операции. Например, такие:
2 + 3 * 7 = <..> или (2 + 3) * 7 = <..>
Возможно это будет темой следующей статьи, а пока рекомендую почитать «Erich Gamma, Richard Helm, Ralph Johnson, John M. Vlissides-Design Patterns_ Elements of Reusable Object-Oriented Software -Addison-Wesley Professional (1994)»
Design Pattern Catalog => Structural Patterns => COMPOSITE
В качестве подготовки. Они там графические объекты рассматривают для примера, поэтому там достаточно сложно, у нас должно получиться попроще в консольном приложении.
Да, кстати, для операции деления код писать не буду, она почему-то очень не понравилась аудитории моей предыдущей статьи про эту операцию.
Если скопировать все это в класс Program консольного C# проекта, все должно заработать, обычно после исправления пары простых опечаток, которые каким-то волшебным образом всегда остаются не замеченными.

Повторяя за статьей оппонента, можно подвести итог:
Как и требовалось по правилам, мы используем полиморфизм. Наши функции выполняют только одну задачу (в основном, но это легко довести до конца). Они короткие. Все эти хорошие штучки. В итоге у нас получается «чистая» иерархия классов, где каждый дочерний класс знает, как вычислить свою площадь, и хранит данные, необходимые для вычисления площади выполнять разные функции, привязанные к представлению этого конкретного объекта как обезличенного объекта базового класса.
Теперь попробуем разобраться на сколько лет назад нас отбросило применение ООП, да еще и вместе с C# вместо С++ по производительности.
Вопросы производительности и анекдот в тему
Даже если бы мы писали ту же самую программу на С++ мы не смогли бы применить изложенные в статье оппонента методы измерения производительности, минимум по трем причинам:
у нас нет точной последовательности обращения к объектам, с которыми происходит работа;
программа зависит от ввода данных человеком;
программа использует функции, предоставленные системой (функции консоли).
Даже если исходить из того, что вызовы виртуальных функций занимают больше времени чем заменяющие их переходы в switch/IF, а это правда хотя разница микроскопическая и зависит от контекста в общем случае. Но исследование из статьи оппонента в этом смысле нас не обманывает. Только в нашем случае это увеличение времени локальных кусочков кода в главном цикле программы будет ничтожно мало по сравнению с теми задержками, которые формируют обращения к консоли. Короче говоря, никаких проблем с производительностью для ООП реализации в этой задаче вы не сможете обнаружить.
В какой-то степени десятикратный результат снижения производительности в задаче оппонента можно назвать подтасовкой так как:
А. задача была специально подобрана, по сути сконструирована, чтобы получить тот результат, который и был получен
Б. была использована аккумуляция-накопление по нескольким аспектам, которые в других задачах никогда не суммируются. Обычно эффекты, связанные с вызовом виртуальных функций сильно размазаны по алгоритму, поэтому ни на что не влияют, а в статье оппонента их как будто специально саккумулировали.
Таким образом то что в нашей задаче не будет проблем с производительностью это не случайность, это нормальная ситуация.
А вот задача оппонента, если кто-то сможет найти ей практическое применение хотя бы гипотетическое, похоже, действительно требует использования подхода со структурами данных (классов без методов) вместо классов в стиле ООП.
По поводу того надо ли бояться ужасной производительности у меня есть подходящий, как мне кажется, анекдот собственного сочинения:
Очередная подруга Джеймс Бонда любуясь на себя в зеркало после сумасшедшей ночи спрашивает:
"Я страшная?"
На что Джеймс Бонд невозмутимо отвечает:
"Ты же знаешь, дорогая, я ничего не боюсь. Я бесстрашный."
Заключение
Ну вот, я, кажется, написал обо всем что хотел или написал достаточно чтобы утомиться – трудно отделить одно от другого. Всегда остается чувство, что о чем-то забыл или что-то не до формулировал. Возможно, это то чувство из-за которого многие писатели становятся неврастениками. Я вроде пока держусь :). В связи с этим хотелось бы обратиться с призывом к читателю: помните, если вам чего-то в статье не хватает, возможно это признак того, что статья помогла вам шире открыть глаза. И не надо стесняться и маскировать свою точку зрения под недовольство способом изложения материала.
С уважением,
Автор
Комментарии (34)

Gorthauer87
05.10.2023 06:57+6А крокодилы более длинные, чем зелёные
Данная статья напомнила мне эту фразу. По сути, она пытается опровергнуть частный случай при помощи специально подобранного примера, то есть, с помощью другого частного случая. Но вывод то делается общий.
Причем тут ещё и подмена понятий есть (как и в исходной задаче), речь то всего лишь идёт о различии открытой и закрытой диспетчеризации, а выводы делаются обо всем ООП сразу

hardtop
05.10.2023 06:57+1ООП сложен. Сложен в понимании и проектировании. Вот эти интерфейсы и абстрактные классы, с кошками и утками, которые двигаются но не все плавают... Размазывание логики по классам и файлам, где есть this.value=value; и метод calculate(); Просто когда Вы пишете на Java или C# - у Вас нет выбора.
Кому-то ультимативный подход "всё есть объект" не нравится. И так появился Kotlin. Другие отказались от классического наследования и появился Rust и Go.

s207883
05.10.2023 06:57Так можно же писать на шарпе и не использовать ООП (если не считать, что все неявно наследуется от object). Это скорее опциональная фича, чем нечто прибитое гвоздями.

iamawriter
05.10.2023 06:57+3Какой-то черт раззадорил меня, и я решил на скорую руку переписать ваш пример в несколько другой парадигме. Не без изъянов, конечно, но для демонстрации сгодится. От знатоков Питона жду снисхождения, давненько не имел с ним дело.
from random import randint Operation = { "-": lambda a, b: (a - b, f"{a}-{b}"), "+": lambda a, b: (a + b, f"{a}+{b}"), "*": lambda a, b: (a * b, f"{a}*{b}"), } Spliter = "-" * 50 def randomOp(): randomIndex = randint(0, len(Operation) - 1) opView = list(Operation.keys())[randomIndex] return opView, Operation[opView] def output(*msgs): print("\n".join(map(str, msgs))) def sayHello(): output( "Hello, colleague!", 'To stop the program type "q" in answer.', Spliter, ) def testUser(calls): opView, op = randomOp() calls[opView] += 1 a = randint(2, 10) b = randint(2, 10) opResult, opRepr = op(a, b) inputString = input(f'"Please Solve: {opRepr} = <..>"') if inputString == "q": return None, None userAnswer = int(inputString) return userAnswer, opResult def giveFeedback(userAnswer, opResult): output( "Congratulations it is correct answer!" if userAnswer == opResult else f'"{userAnswer}" is wrong answer. Correct is {opResult}', Spliter, ) def sayGoodby(calls): resume = [f"Count of {opView} operations={n}" for opView, n in calls.items()] output(Spliter, *resume, Spliter) def main(): sayHello() calls = {o: 0 for o in Operation} continueTesting = True while continueTesting: userAnswer, opResult = testUser(calls) continueTesting = userAnswer != None if continueTesting: giveFeedback(userAnswer, opResult) sayGoodby(calls) main()Примерно в таком стиле я пишу свой последний проект, работа над которым идет уже более 3-х месяцев, но финал виден на горизонте. Сейчас в проекте около 15 000 строк кода, а в ходе разработки и экспериментов было выброшено в разы больше (мне так кажется, не судите строго). Взявшись за этот проект, я решил отбросить условности, которые создавали мне дискомфорт во время разработки и тормозили работу, в итоге мой стиль, может быть, несколько и вышел за рамки дозволенного высоколобыми энтерпрайз-разработчиками, на работа спорится. Чего и вам желаю.
s207883
05.10.2023 06:57Тут больше похоже на композицию. Это намного проще, чем строить иерархию классов и не надо париться насчет наследования.
iamawriter
05.10.2023 06:57+1Разве "писать проще" - это не то, к чему нужно стремиться?..

SpiderEkb
05.10.2023 06:57+1Да, но при соблюдении прочих условий.
Заказчику ваш код не интересен. Ему нужен конечный продукт с заданным функционалом в оговоренные сроки. При этом ему еще хочется чтобы этот продукт работал быстро и не требовал слишком много ресурсов.
"Писать проще", "писать быстрее" - это все мы делаем для себя. Чтобы потом проще было сопровождать, расширять или дорабатывать функционал и все такое прочее.
Но платит нам в конечном итоге заказчик. А ему все равно - ООП там, не ООП...
iamawriter
05.10.2023 06:57Разве я не об этом же?
SpiderEkb
05.10.2023 06:57Ну не совсем :-)
Если выбирать между "просто, но не медленно работает" и "сложно, но быстро работает" в наших условиях приходится выбирать второе...
iamawriter
05.10.2023 06:57Вы считаете, что мой код будет работать медленнее, чем код, написанный в стиле кода из статьи?.. И мне почему-то кажется, что вы для себя решили, что моя позиция заключается в том, что "пусть медленно, лишь бы просто". Не думаю, что давал повод для такого умозаключения. Мой код обычно работает быстро, поскольку, как правило, он опирается на хорошие алгоритмы. И при этом, иногда, мне удается сделать его хорошо читаемым и легко сопровождаемым во всех смыслах.
SpiderEkb
05.10.2023 06:57Я ничего не могу сказать по поводу конкретного кода без прогона его через профайлер.
Я просто говорю что часто видел как ООП код с несколькими уровнями абстракции работал медленнее простого процедурного кода. За счет динамического выделения памяти, за счет вызовов конструкторов (развертка-свертка стека тоже занимает некоторое время).
Естественно, что все это становится заметно при больших плотностях вызовов. На одиночном вызове разницы не заметите.
В целом я за то, что код должен быть максимально простым. И против того, чтобы плодить сущности сверх необходимого. И если выборка заполняет некую структуру данных, которую мы можем передать в некую процедуру, то совершенно необязательно оборачивать эту структуру в класс и передавать в ту же процедуру объект класса. Или класс, который ту же самую процедуру будет содержать как метод.
Такой подход не дает ровным счетом ничего.
Набор базовых классов хорошо когда ограничен набор сущностей и количество связей между ними также ограничено. При этом базовые классы не должны меняться (а в постоянно меняющейся и развивающейся системе это достаточно сложно соблюсти - там изменения достаточно часты как под давлением внешних обстоятельств, так и в силу изменения каких-то бизнес-процессов).
iamawriter
05.10.2023 06:57И опять мне хочется вопросить: "разве я не об этом же"?
SpiderEkb
05.10.2023 06:57Ну вообще в статье был посыл "как здорово ООП".
Я говорю что иногда здорово, иногда нет. И чистый код можно и без ООП писать.
А если смотреть еще шире, то ООП жто не обязательно классы, наследование полиморфизм и инкапсуляция.
Мы вот рвботаем на платформе где все есть объект. На уровне ОС. Но ни наследования ни полимрфизма тут нет. Просто любая сущность рассматривается как объкт того или иного типа, обладающая неким набором атрибутов. И для каждого типа объектов определен свой набор допустимых для данного типа действий.
s207883
05.10.2023 06:57Все относительно. Можно написать просто, а можно сложно. Причем, оба варианта будут иметь право на жизнь.
Типа, усложнить проект, но получить удобную площадку для расширения функционала.
Или не усложнять там, где "сделал и забыл" и даже примерно не нужно будет ничего расширять в будущем.iamawriter
05.10.2023 06:57+1"Можно написать просто, а можно сложно". Мой опыт говорит мне, что писать сложно - это просто. А писать просто - это трудно. Не настаиваю, у каждого свой опыт.
SpiderEkb
05.10.2023 06:57А вот 100500 базовых классов там, где можно написать пару-тройку процедур - это "просто" или "сложно"?
Причем, процедуры будут логически атомарными - каждая выполняет свою логически законченную функцию.
А базовый класс не выполняет ничего. От него потом еще надо наследоваться для получения нужного функционала.
s207883
05.10.2023 06:57Не совсем понял вопрос. Вообще, мы пишем сервисами, где ты ему А, он это как-то обрабатывает и отдает (или не отдает) тебе Б. Объекты используются чисто для хранения и передачи состояния и никакой логикой не владеют. Есть пара мест, где внутри сервисов скрывается ООП, чтобы несколько упростить кодовую базу и не писать одно и тоже десять раз.
Сервисы, соответственно, содержат в себе минимальный функционал, только то, что относится непосредственно к ним и прочий solid.
Имхо, логику в ООП вообще опасно пихать. Она любит подкидывать проблем при дальнейшем развитии.
SpiderEkb
05.10.2023 06:57Имхо, логику в ООП вообще опасно пихать. Она любит подкидывать проблем при дальнейшем развитии.
Вроде бы считается, что ООП - это инкапсуляция данных и логики, которыми она обрабатывается.
Объекты используются чисто для хранения и передачи состояния и никакой логикой не владеют
Тогда это не объект класса, а просто структура. Которая есть просто область памяти, условно поделенная на поля.
У нас вот есть embedded sql где можно написать запрос и сказать - вот тебе массив структур из 1000 элементов, заполни его очередными 1000 строками выборки. И он заполнит. Массив структур выделяется статически, в момент компиляации. Никаких конструкторов там нет, никакого динамического выделения памяти там нет.
А дальше очередной элемент массива передается в процедуру, которая содержит логику работы с ним.
как-то так:
dcl-c sqlRows const(1000); dcl-ds t_dsSQLData qualified template; CUS char(6) inz; CLC char(6) inz; ClTp char(1) inz; ActDte zoned(7: 0) inz; MsgTp char(1) inz; end-ds; .... // массив структур куда будем читать dcl-ds dsSQLData likeds(t_dsSQLData) dim(sqlRows); // определение выборки (SQL) exec sql declare curRDMS09Clients cursor for ... (тут тело запроса на пару экранов) ... .... dou lastBlock; // Читаем очередной блок записей exec sql fetch curRDMS09Clients for :sqlRows rows into :dsSQLData; // определение сколько записей реально прочитано // и есть ли еще записи в выборке lastBlock = sqlGetRows(rowsRead); for row = 1 to rowsRead; // Обработка очередного элемента procClient(dsSQLData(row)); endfor; enddo;Вот как-то так... Просто и никаких лишних телодвижений. Куда тут ООП? Создавать объект класса из каждого элемента массива dsSQLData? А зачем?
iamawriter
05.10.2023 06:57+2Должен поправить код. Отходил от компьютера, поэтому не смог сделать это сразу, как сообразил.
from random import randint Operation = { "-": lambda a, b: (a - b, f"{a}-{b}"), "+": lambda a, b: (a + b, f"{a}+{b}"), "*": lambda a, b: (a * b, f"{a}*{b}"), } Spliter = "-" * 50 def randomOp(): randomIndex = randint(0, len(Operation) - 1) opView = list(Operation.keys())[randomIndex] return opView, Operation[opView] def output(*msgs): print("\n".join(map(str, msgs))) def sayHello(): output( "Hello, colleague!", 'To stop the program type "q" in answer.', Spliter, ) def testUser(): opView, op = randomOp() a = randint(2, 10) b = randint(2, 10) opResult, opRepr = op(a, b) inputString = input(f"Please Solve: {opRepr} = <..>: ") if inputString == "q": return None, None, None userAnswer = int(inputString) return opView, userAnswer, opResult def giveFeedback(userAnswer, opResult): output( "Congratulations it is correct answer!" if userAnswer == opResult else f'"{userAnswer}" is wrong answer. Correct is {opResult}', Spliter, ) def sayGoodby(stat): output(Spliter, *stat, Spliter) def main(): sayHello() calls = {o: 0 for o in Operation} continueTesting = True while continueTesting: opView, userAnswer, opResult = testUser() continueTesting = opView != None if continueTesting: calls[opView] += 1 giveFeedback(userAnswer, opResult) stat = [f"Count of {opView} operations={n}" for opView, n in calls.items()] sayGoodby(stat) main()Надо бы еще заняться неймингом, но в данном контексте это уже будет перебор, пожалуй.

rukhi7 Автор
05.10.2023 06:57-2Да нормально все у вас с неймингом, я вообще никогда не писал на Питоне, но даже мне все понятно.
Вот только… У меня там разрядность разная была у чисел для умножения и для сложения-вычитания, для сложения используются числа меньше ста, для умножения меньше десяти. И вы это, видимо, недосмотрели.
Но я вам даже могу посоветовать, как это поправить: надо кроме
lambda a, bеще константу (DigitCount) как-то засунуть в объект, который вы из мапа достаете, и вместо
a = randint(2, 10)написать что-то вроде:
a = randint(2, <op.DigitCount>)Еще у вас там отрицательные числа могут получаться при вычитании, а это не всегда подходит.
А еще ужасно интересно почему же вы постеснялись написать операцию «деление»? Не получилась? Или в одну строчку не убралась?
Ну и вопрос на засыпку: получится у вас с вашим подходом расширить программу чтобы поддерживать составные операции, например:
2 + 3 * 7 = <..> или (2 + 3) * 7 = <..>
Код это, всегда хорошо, код это – идея. Только вы, мне кажется, и к большому сожалению, демонстрируете исключение из этого правила. Я боюсь, что для вас код это идея о том какую функциональность выкинуть, чтобы запихать операции в одну строчку.
Судя по тому, что вы написали, у вас корнем иерархии является «клиент», а насколько я знаю-понимаю банковскую специфику, правильным выбором для корня иерархии там обычно является «Счет». Я понимаю, что это практически нельзя уже исправить в работающей системе, но вы хотя бы гипотетически рассматривали, что бы было, если бы у вас иерархия была построена от другого корня?
Ну, а вообще, технологии перехода (миграции) данных в другую базу данных с другой структурой существуют, хотя они, конечно, очень сложные, даже организационно.
SpiderEkb
05.10.2023 06:57а насколько я знаю-понимаю банковскую специфику, правильным выбором для корня иерархии там обычно является «Счет»
Нет.
Счет - это самостоятельная сущность. Оно не может быть корнем иерархии. У клиента, как правило, не один счет. Клиент является постоянным и неизменным. Счета могут открываться и закрываться.
У клиента, в свою очередь, огромное количество данных, которые к счетам вообще никакого отношения не имеют.
Я же говорю - тут слишком много сущностей и слишком много связей чтобы построить какую-то внятную иерархию.
Я понимаю, что это практически нельзя уже исправить в работающей системе, но вы хотя бы гипотетически рассматривали, что бы было, если бы у вас иерархия была построена от другого корня?
Да нет у нас никакой ООП иерархии. Это траты времени впустую.
Есть набор таблиц (несколько десятков тысяч) где разложены данные по темам. Клиенты, карточки клиентов, адреса клиентов, документы, доверенности, субъекты клиентов и т.п. Есть таблицы счетов, есть таблицы платежных документов, таблицы рисков клиентов. Есть таблицы пластиковых карт, связи между клиентами-владельцами счетов и держателями карт. Есть таблицы системы комплаенс - там всякие списки росфина, стоплисты и т.д. и т.п. Куча справочных и настроечных таблиц. Достаточно количество "витрин" где хранится наиболее плотно востребованная актуальная информация по разным темам (то, что можно быстро взять из одной таблицы а не собирать каждый раз по нескольким).
И, строго говоря, процентов 70-80 работы банка - это не работа с объектами (клиент, счет и т.п.), но работа с некоторыми выборками данных. Т.е. то, что описывается не функциональной моделью, но моделью потока данных.
И конкретный состав выборки определяется конкретным бизнес-процессом (которых у нас десятки тысяч, которые могут добавляться, меняться...).
Я уже приводил пример выше - делаем выборку конкретных данных по конкретным условиям и отдаем ее на обработку. Вот так это работает.
Так что тут не за что зацепиться для построения какой-то "иерархии". В том смысле, что даже если вы что-то такое построите, оно будет очень запутанным, громоздким и вам придется ее постоянно менять в связи с изменением бизнес-процесса и каких-то внешних условия (законодательство, требования регулятора и т.п.).
Я уже говорил что раньше работал с простоя ситемой. Там да - есть корневой тип "обьъект" (улица-дом-подъезд...) и есть корневой тип "устройство" (конечное устройство - контроллер нижнего уровня - контроллер верхнего уровня).
Любое устройство физически связано с объектом (установлено на объекте) Объект типа улица включает в себя объекты типа дом, а те в свою очередь объекты типа подъезд. Конечное устройство подключено к контроллеру нижнего уровня, а тот к контроллеру верхнего уровня.
Все! Конечно тут можно построить ООП модель которая будет проста и непротиворечива.
В банке этого нет. Все слишком сложно и запутано. Даже если вы создадите объект типа клиент, то в реальной работе оно вам никак не поможет. Ну разве что при работе с карточкой клиента когда вам нужно работать с клиентскими данными по конкретному ПИНу.
Но большая часть работы это выборки. По многим таблицам и множеству условий выбрать небольшой набор данных под логику конкретного процесса. Таблицы, условия, набор данных под каждый процесс будут свои. А процессов, повторюсь, десятки тысяч и они могут меняться.
В общем, это не тот случай, где ООП что-то реальное может дать. Затраты на разработку иерархии не окупятся.
SpiderEkb
Ну да, ну да... Зато вот это серьезно?
При том, что большинство реальных задач намного сложнее чем реализация четырех арифметических операций. И намного ближе (по уровню сложности) к "функциональности баз данных, хранением, доступом к данным".
До того, как работать в банке, занимался разработкой системы мониторинга инженерного оборудования зданий (софт верхнего уровня обеспечивающий работу с сетью промконтроллеров и подключенных к ним конечных устройств). И там активно использовал принципы ООП - структура классов отражала физическую сущность системы - был класс "объект" (на котором установлены устройства), был базовый класс "устройство" с производными от него классами для "УСО" (контроллер нижнего уровня), "IP-шлюз" (контроллер верхнего уровня) и т.д. и т.п.
И да, все это бы красиво, удобно, работало. Но. Только потому что сущностей было относительно немного, и относительно немного было свойств у каждой сущности.
В банке же первое желание было "ну можно же что-то ООПное сделать...". Но очень быстро пришло понимание того, что все это на практике нереализуемо.
Количество сущностей (клиент, счет и т.п.) зашкаливает. Это даже не десятки, сотни.
Количество свойств у каждой сущности зашкаливает. При этом свойство может быть самостоятельной сущностью со своими свойствами и "вложенными" сущностями.
Связи между сущностями крайне сложны и запутаны.
Все это приводит к тому, что количество типов будет огромным. Структура классов крайне сложной. И все это отрицательно скажется на производительности по одной простой причине - создавая объект типа "клиент" мы не может сразу в конструкторе подтянуть все, что с ним связано - это огромный объем информации - собирать ее долго, хранить в памяти нерационально. Т.е. выход в "ленивых" методах. Но тут другая засада - получим огромное количество атомарных ленивых свойств каждое из которых получает свое значение в результате некоторого запроса к БД. А логика работы такова, что в подавляющем большинстве случаев нужно не одно свойство, а некоторый их набор. Который приведет к выполнению соответствующего набора запросов к БД. В то время как все это можно получить в рамках одного запроса (если не упираться в ООП).
Вообще, под каждую конкретную задачу тут рисуется соответствующий запрос. Который, как правило, достаточно сложен - может содержать несколько подзапросов (with ... as ...), join по нескольким таблицам (и/или подзапросам) и т.д. и т.п. Если пытаться все это запихнуть в ООП (в виде набора сущностей и их свойств), получим существенный оверкод и снижение производительности. Или под каждую задачу придется писать свой набор объектов со своими свойствами и методами, но тогда теряется смысл - получим фактически тот же процедурный подход, но с
вистом и профурсеткамиклассамиДаже в приведенном примере:
Это не бесплатно. Это вызовы конструкторов. Для каждого из них будет создаваться, а потом схлапываться уровень стека, будет динамически выделяться память, будет выполняться некий код. Если вы делает это один раз, вы этого не заметите. Если это выполняется 100500 раз в секунду - любой приличный профайлер вам покажет что на это уходит время и ресурсы процессора.
Если вы прогоните оба примера в цикле, скажем, 1 000 000 раз с засечкой времени - вы увидите разницу.
ООП хорошая парадигма. Во многих ситуациях она упрощает разработку. Но это не серебряная пуля. В сложных системах затраты на разработку адекватной структуры объектов могут превысить разумные пределы прежде чем начнут давать какую-то реальную отдачу в плане скорости и удобства использования.
rukhi7 Автор
Тут я с вами вполне согласен! Но обучающий пример нельзя сделать абсолютно серьезным, мне кажется. Но с моим примером можно, хотя бы, самостоятельно поупражняться.
Далее, судя по тому что:
а в банке
я возьмусь предположить (исключительно предположить! я ничего не утверждаю!),
что для системы мониторинга иерархия объектов была построена правильно, или как вы это формулируете:
а вот в банке иерархия была построена НЕ правильно и НЕ отражала физическую сущность системы. Проблемма обычно именно в этом! Я как раз пытался подойти к формулировке такой проблемы в своей статье, в разделе: "Выбор объекта базового класса, философское отступление"
Я это много раз на практике видел, когда выбранная иерархия объектов буквально стоит поперек тех реальных задач, которые надо решать, как раз такая поперечность ведет к последствиям которые вы описали:
К счастью я видел и работал с системой в которой все хорошо и, даже, я бы сказал превосходно, в этом плане, и именно это меня вдохновляет на применение ООП.
Правильный выбор иерархии объектов в соответствии с решаемыми задачами - это действительно ужасная-страшная проблема для ООП! Это очень не просто, правильная иерархия никогда не появляется с первого раза, обычно разработка иерархии это итерационный процесс!
Но хоть анекдот-то понравился? или тоже нет?
SpiderEkb
Я попытался объяснить что построить "правильно" иерархию объектов в столь сложной системе задача крайне нетривиальная, более того, мне она кажется невозможной в практическом плане.
Ну вот очень упрощенно. Есть сущность "клиент". У него куча клиентских данных (там одних адресов может быть штук шесть разных, а адрес это отдельная сущность со своими атрибутами).
У клиента еще много всяких свойств. Например, счета. У счета свои признаки (которых тоже несколько десятков). Дальше к счету могут быть привязаны карты. Со своими признаками. Далее, у клиента могут быть "субъекты" - всякие доверенные лица (т.е. есть еще доверенности), которые не являются клиентами банка, но у которых тоже много всяких данных (те же адреса, доверенности и т.п.).
И это далеко не все. Даже не малая доля того, что там есть. И все это достаточно сложно между собой связано. Так скажем, более десятка тысяч таблиц, описывающих сущности и взаимосвязи между ними.
А теперь простенькая задачка. Нужно выбрать клиентов определенного типа (скажем, ФЛ и ИП), имеющих счета открытые типа 40817, последняя дата актуализации клиентских данных у которых не ранее чем год от текущей а дата окончания срока действия основного ДУЛ (документ удостоверяющий личность) не более чем +месяц от текущей. Есть этому клиенту еще не посылалось уведомление об окончании срока действия ДУЛ, послать уведомление. После чего проверить наличие у данного клиента держателей карт (когда клиент делает к своему счету карту третьему лицу) и если им еще не посылалось уведомление - разослать.
Это (на нашем уровне) достаточно тривиальная задача. Как ее решать в рамках ООП?
В процедурном подходе все достаточно просто - один запрос (да, он будет "разлапистым", но работает достаточно быстро) выдает полный набор всех необходимых данных, которые просто передаются в функцию отправки уведомления. Далее второй запрос дает необходимые данные для рассылки уведомления держателям карт. Тоже быстро.
Что буде в ООП? Получим выборку, для каждого элемента создадим объект "клиент" и для него вызовем метод "послать уведомление"? А представляете сколько таких методов будет у класса "клиент"? Сотни, если не тысячи. И каждый новый бизнес-процесс потребует добавления новых методов.
Или у нас будет функция послать уведомление, которая будет принимать на вход объект типа "клиент"? Но зачем, когда у нас уже есть такая функция, которая принимает на вход набор данных из выборки и у нас нет необходимости тратить время и ресурсы процессора на создание объекта. К слову сказать, достаточно много выборок, которые могут вернуть несколько миллионов (а то и десятка миллионов) записей. И на каждую запись объект создавать а потом удалять?
У нас огромные объемы данных и огромное количество разных бизнес-процессов. И вопрос эффективности использования ресурсов стоит крайне остро. Посему стараемся минимизировать (кроме ситуаций когда без этого ну совсем никак) работу с динамической памятью, отдавая предпочтение статике.
А теперь попробуйте обосновать необходимость затрат времени и ресурсов на этот процесс. Главные критерии:
оно будет быстрее работать?
оно будет потреблять меньше ресурсов процессора?
и, главное - сколько на этом заработает банк?
Есть огромная система. Это не монолит, это скорее модель акторов. В ней десятки тысяч таблиц и индексов. Десятки тысяч программных объектов. Сотни миллионов бизнес-операций в сутки. Тысячи параллельных бизнес-процессов.
Построить подо все это "правильную" и непротиворечивую ООП модель ну такое себе занятие.
К слову сказать, у нас есть команда, которая этим занимается. Лет уже наверное десять (ну может чуть меньше). Результат - практически нулевой. Нет, что-то там у них работает, но работает локально, до охвата всего-всего там как до луны пока. И никто так и не смог доказать, что их подход быстрее или экономичнее по ресурсам (а у нас есть объективные инструменты для измерения этих параметров) чем традиционный процедурный подход (который в разработке ничуть не сложнее на самом деле).
as_serg
Интересная дискуссия, хочу продолжить рассуждения. Почему-то в процедурном подходе вы спокойно мыслите всей пачкой объектов, а когда речь заходит за ООП, то хотите строго выполнять работу как некоторые методы от конкретных объектов назначения. Нам нужно обрабатывать объекты также пачками. То есть скорее всего у нас эта задача выполняется по расписанию, и корневой объект это некоторый NotificationTask. А внутри него никто не мешает нам собрать необходимые подготовленные данные целиком (даже странно так не делать), то есть не по одному забирать клиентов, а сразу нужных с фильтрами и джойнами. Дальше все упирается в мощь и понятность выбранной ORM, и реально возможны ситуации где написать сырой запрос окажется проще. Но мне кажется некорректным утверждение про "разлапистый" запрос, потому что в итоге он сам будет быстрый, но не известно насколько быстро он будет написан программистом.
Здесь под выборкой имеется в виду курсор базы данных, из которой фетчатся данные? И дальше работа с сырыми данными-строками в функции-рассылке? Эффективно, но когнитивно кажется неудобно, легко например порядок полей попутать, или дату криво распарсить, и потом долго искать проблему. А иначе мы в любом случае эти данные как-то сохраняем в памяти, и сравнение с созданием объектов тогда уже выглядит как экономия на пакетах.
Насчет связей. Сами по себе они по задумке призваны нам помогать) Как буквально не удалить объект, на который кто-то другой ссылается, так и косвенно. Например, банк присылает уведомление по смс. И решено мониторить, сколько СМС на пользователя в среднем тратится в месяц, а для этого данные складываются еще в одну табличку. В вашем процедурном подходе (если только задача не была максимально исчерпывающе описана аналитиком) вы забудете это сделать, т.к. просто не знаете про это. В случае с ООП вы вероятно захотите узнать, умеет ли объект делать что-то подобное уже сейчас. И между делом с удивлением обнаружите, что есть такой сайд-эффект, и решите что делать дальше.
Действительно, ООП само по себе дает возможность излишнего усложнения и запутывания кода (ради кода, а не бизнес-процесса), а ленивые методы это всегда проблема N+1 запроса. Но тогда справедливо будет говорить, что процедурный подход дает возможность каждую задачу делать заново и плодить свои велосипеды, а сложность кода снижать просто игнорированием сложности бизнес-процесса. Впрочем, и в ООП можно не разобраться в структуре и проигнорировать часть бизнес-процесса, а в прямом процедурном подходе написать запутанный спагетти-код.
Я для себя решение вижу в четко организованной структуре проекта (слоях), и осмысленном делении сущностей (в том числе и самих сущностей) по доменам. Тогда мы ожидаем, что междоменное взаимодействие сведено к минимуму, и в основном представлено агрегацией данных. А связанность между доменами мы уже обеспечиваем логически чисто в коде (а не базе), и получаем возможность денормализации для упрощения задач при необходимости. В таком случае, кажется что внутри домена подход написания будет уже не так важен.
SpiderEkb
Просто потому что тут под ООП понимается "базовые классы, наследование, полиморфизм и бла-бла-бла".
Я уже писал - мы работаем на платформе (железо + ОС), которая сама по себе объектная. Тут все есть объект (даже переменные в программе системой воспринимаются как некий "объект" для которого кроме значений в системе еще и свойства хранятся. В те жа процедуры можно кроме параметров передавать т.н. "операционные дескрипторы" (специальным модификатором в нашем языке или прагмой в С/С++) по которым можно узнать, например, что реально скрывается за парамеnром char* - на что реально он указывает.
И там снизу до верху - здесь нет файлов - есть объект типа *FILE с дополнительными атрибутами - pf-src (файл исходных текстов), pf-dta (файл данных, сиречь таблица), lf (логический файл - что-то типа индекса, но более широкое - там и джойны могут быть допусловия...). Нет программ - есть объект типа *PGM. И т.д. и т.п.
Но ни базовых типов, ни наследования, ни полиморфизма тут нет на уровне ОС. Тем не менее мыслить "объектами" тут привычно и естественно. Даже при процедурном подходе.
Именно так и делается. См. мой комментарий с примером Только как это запихать в ООП "с наследованием и полиморфизмом"? А, главное, зачем?
И опять см. выше. Никаких там "сырых данных" нет. fetch заполняем массив структур (мы работаем блоками, но можно и по одной записи, но это не так эффективно). Т.е. на выходе имеем сразу заполненную структуру со всеми полями.
Если формат структуры не соответсвует тому, что написано в select ... в объявлении курсора, оно просто не скомпилится - SQL препроцессор нашего языка выкатит ошибку.
И да, наш язык поддерживает все типы данных, которые есть в SQL. И умеет с ними работать. И "парсить дату" нам нет необходимости. Мы можем с ней работать как с датой (вычесть/прибавить нужное количество лет/месяцев/дней, преобразовать ее в строку в нужном формате - *ISO/*EUR или еще каком...)
Т.е. после fetch мы сразу имеем заполненный массив структур с нужными нам данными, а дальше каждый элемент структуры отдается на обработку.
Дело в том, что считать сколько там тратится на смс вообще не наша задача. Мы даже не знаем как будет доставляться уведомление клиенту - смс, пушом, курьером на дискете, почтовым голубем... Это не наша забота. Мы - мастер-система. Ядро АБС банка. Наша задача собрать данные и выложить их в очередь с тем, чтобы некая внешняя система их оттуда взяла и уже делала с ними то, что считает нужным.
Мы только смотрим кому нужно посылать уведомление и проверяем посылали его или нет. Если нет - формируем пакет, выкладываем в очередь и делаем отметку что мы со своей стороны уведомление отослали. Все.
И, повторюсь, это всего лишь одна мелкая задачка из многих десятков тысяч. Просто как пример того, что 80% (условно) работы банка (на нашем уровне) происходит именно по такой схеме:
есть набор таблиц, в которых содержатся данные
есть список условий, по которым нужно выбрать данные.
есть набор данных, которые необходимы для реализации логики процесса
есть логика что и как делать с этим данными
Вот общая канва. И все 4 пункта в каждом случае разные - нет каких-то общих точек. Для каждого бизнес-процесса все будет свое. По каждому пункту.
Все это не более чем общие слова.
А на практике так:
ООП (с наследованием и полиморфизмом) хорошо там, где вы можете определить "базовый класс", объединяющий большую часть свойств и логики. А потом от него наследовать, модифицируя какие-то отдельные части (дополнительные специфические свойства, конкретную логику...). тогда все это реально экономит время и имеет смысл.
Или когда у вас есть какие-то общие операции, которые не зависят от конкретики, куда можно передавать любой объект, унаследованный от данного базового класса.
Здесь ничего этого нет. Каждый бизнес-процесс работает со своим набором данных по своей логике. И, соответственно, нет возможности построить базовый класс для всех процессов, а потом от него наследовать слегка модифицируя логику. Тут вам придется под каждый процесс писать свой класс с нуля.
Вернемся в примеру выше. У нас есть массив структур, память под который выделяется в процессе компиляции. Операцией exec sql fetch этот массив заполнятся нужными нам данными. Далее, мы берем очередной элемент массива и отправляем его в процедуру обработки, где уже происходит вся магия.
Ок. Допустим мы ударились в концептуальность и написали свой класс в котором содержатся все данные и методы их обработки. Что с того? А ничего. exec sql fetch нам не заполнит массив объектов. Он так не умеет. Т.е. нам все равно придется объявлять массив структур, потом каждый элемент массива запихивать в объект класса и дергать нужный метод (причем время жизни объекта ограничено временем работы этого самого метода - ни до ни после нам этот объект не нужен). Извините, а зачем, когда мы все это и так уже имеем, но без всего вот этого вот? Нам тут не нужен объект, нужны только данные. Которые у нас уже есть. Та же самая логика написана в виде процедуры, получающий на вход заполненную в fetch структуру (элемент массива). Т.е. все то же самое, но проще. Ну не концептуально, да...
SpiderEkb
Еще добавлю.
На мой взгляд использование объектов (в классическим понимании - "наследование-инкапсуляция-полиморфизм") оправдано тогда, когда время жизни объекта существенно. Т.е. создали его, потом он живет своей жизнью по заложенной в нем логике.
В нашем случае это не так. Есть считать "объектом" (без "н-и-п") элемент выборки из БД, то время его жизни крайне мало - от момент попадания в выборку до момента когда он трансформируется в некое сообщение и кладется в очередь.
И никакой особой логики в нем не заложено кроме форматирования сообщения. Вся логика в самой выборке.
Так что тут нет никакого смысла в том, чтобы тратить время и ресурсы на создание (или заполнение) объекта из элемента выборки.
rukhi7 Автор
элемент выборки из базы данных - это обычно МАП который позволяет обращаться к своим полям через имя этого поля. Проблема в том что поля могут быть разных типов, поэтому желательно иметь какой-то базовый класс (см. переменную ConvertedObjectClass forConvert в примере ниже) который позволяет применять конверсию данных из объекта унаследованного от этого базового класа к типу в который надо привести данные конкретного поля при обращении, как-то так чтобы можно было писать:
Вроде как и на С++ такое вполне можно сделать.
у вас будет место где определены все нужные вам преобразования типов, это класс ConvertedObjectClass, и вы сможете ими управлять и анализировать их. Вы сможете очень много чего контролировать-проверять уже на этапе компиляции. Это позволит в какой то степени структурировать ваш код.
И проблем с производительностью тоже не должно быть (если конечно чего то не намудрить из ряда вон. С дуру как говорится что хочешь можно сломать :) ). Все что здесь написано предполагает вызовы функций в любом случае, мы просто применяем определенную форму вызова этих функций, оформляем их как функции специального класса (типа). Приведение типа это тоже вызов функции, и он у вас все равно присутствует только переписанный много раз в разных местах, а так будет в классе и перестанет дублироваться.
SpiderEkb
Зачем так сложно-то?
Я же привел пример. С реальным кодом.
Наш я зык поддерживает все типы данных БД - date, time, decimal, numeric, chr, varchar, integer и т.п. Никакой маппинг и конвертация тут не нужны.
Все, что вы написали - от бедности. Попытки прикрутить к языку то, чего там нет изначально. Все это приводит к лишним телодвижениям.
Если мы описываем структуру
для понимания - zoned(7:0) это тип данных с фиксированной точкой, соответствующий SQL'ному NUMERIC(7,0)
Затем объявляем курсор
и массив структур куда будем читать блоками по 1000 записей
где sqlRows - константа равная 1000.
А потом цикл чтения
sqlGetRows - функция возвращающая количество реально прочитанных записей и признак есть ли еще записи в выборке (точнее признак последнего блока)
Итого:
Не мап, а заполненная структура с полями поддерживаемых языком типов данных.
Зачем???
Вот вам пример. Там поля двух типов - char и zoned (numeric в sql). Нормальная структура. Зачем тут "базовый класс"?
Откуда и куда предлагаете пребразовывать? И, главное, зачем?
Что именно? Соответствие полей структуры t_dsSQLData набору полей в select и так контролируется на этапе компиляции.
Все типы полей структуры нативные для данного языка. Нет никаких "мапов", нет никакой "конвертации". Все это просто не нужно. Fetch заполняет структуру, дальше с ней работаем.
Чем вам не нравится код в данном примере? Это из реального взято. Он достаточно прозрачен и легко читаем (для тех, кто с этим языком работает, конечно).
И здесь нет ничего лишнего. Никаких конструкторов, никаких операций выделения память, копирования туда-сюда, маппинга, конвертаций - все это будет занимать лишнее время когда речь идет об обработке 10-30млн записей (да, для нас это вполне обычные объемы данных) которую нужно уложить в приемлемое время. Все это работает предельно быстро и при этом потребляет минимум ресурсов (в т.ч. реального процессорного времени).
SpiderEkb
По поводу анекдота. И производительности.
Это реальное письмо от сопровождения. Увеличение потребления ресурсов связано с увеличением объема данных с которыми работает данный сервис. Т.е. обычное масштабирование - количество клиентов растет, соответственно растут объемы данных. И в какой-то момент то, что удовлетворительно (по времени и процессору) работало многие годы, перестает удовлетворять. Вплоть до того, что оно может начать тормозить какие-то другие процессы, а дальше уже может начаться лавинообразный процесс торможения всего и вся.
На такие вещи у нас заводится "дефект производительности на промсреде". А дефект - это значит что откладываем все остальное и правим его.
И это не анекдот, увы. Это реальная жизнь у нас. Так что вся концептуальность и уровни абстракции идут лесом если они привносят лишние уровни стека, динамическую работу с памятью и все вот это вот.
Это не значит что мы тут все пишем какой-то спагетти-говнокод. Отнюдь. Сопровождаемость кода в дальнейшем для нас также важна. Но производительность и эффективность - это те моменты, которые постоянно держишь в голове в процессе разработки.
panzerfaust
Справедливости ради, IRL же никто не будет конструкторы в цикле гонять. Объвят стейтлесс-классы, создадут инстансы 1 раз - потом самую тривиальную стратегию напишут.
UstasAlex
Абсолютно согласен. Особенно с последним абзацем. Искусство программирования это, во многом, искусство компромиса.
SpiderEkb
Верно. Компромисса и умения отделять главное от второстепенного.