Введение и куча контекста
Intel недавно раскрыла спецификацию AVX10 как средства консолидации подавляющего большинства расширений AVX-512 в единую спецификацию. Целью этого было решение нескольких проблем, в частности, поразительного количества конфигураций, целевых платформ и спагетти из реализаций AVX-512 с несогласованной поддержкой команд. Следует помнить о том, что в первую очередь она используется как средство для объединения всех любимых преимуществ AVX-512 в более мелкие реализации, целевые платформы для которых — это потребительские машины, micro-edge и встроенные системы, у которых нет или не будет тридцати двух 512-битных регистров, необходимых для AVX-512.
После публикации спецификации я публично выразил свой энтузиазм, сделав доклад для сообществ разработчиков Easy Build/HPC с названием «AVX10 for HPC: a reasonable solution to the 7 levels of AVX-512 folly». Статья, которую вы читаете, изначально должна была стать частью доклада, но я решил написать её, чтобы ссылаться в дальнейшем (а ещё потому, что я уже с трудом могу урезать доклад до 90 минут, не говоря уже о предоставленных мне 60 минутах).
Что такое AVX10?
Для начала разберёмся с обозначением AVX10.N/M: AVX10 — это новый «фундаментальный» векторный/SIMD набор команд для x86_64. .N обозначает версию AVX10 как модификатор версии, что позволяет вносить инкрементные дополнения. Важно заметить, что если вы поддерживаете AVX10.N+3, то должны также поддерживать AVX10.N, N+1 и N+2. Иными словами, пользователям гарантированы надмножества предыдущих наборов команд.
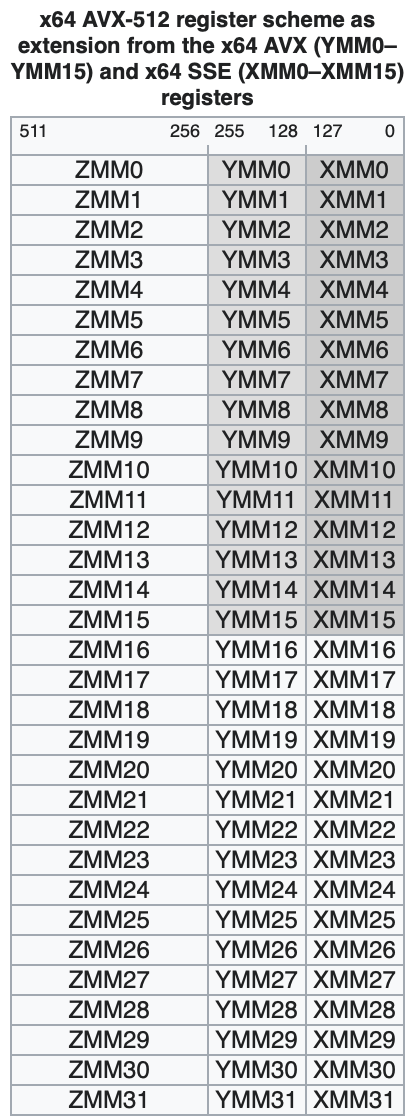
Что значит /M? Это отсылка к размеру реализации векторных регистров конкретной версии AVX10.N. В частности, они могут быть 512-битными, 256-битными, или (тема этой статьи) 128-битными.
128-битные регистры, или регистры XMM, были введены в 1999 году в рамках SSE(1) для 32-битных Pentium 3. 256-битные регистры были введены с появлением AVX1 и впервые реализованы в 2011 году в микроархитектуре Sandy Bridge. 512-битные регистры появились в AVX-512 и были реализованы примерно в 2016 году в Xeon Phi, но не были широко доступны до 2017 года, когда выпустили Skylake-X.
Чтобы получить представление о том, как все они выглядят, взгляните на сравнение команды сложения упакованных значения одинарной точности с плавающей запятой (add packed single-precision floating-point values, ADDPS), взятое из визуализатора SIMD-команд на сайте officedaytime.com.

Примечание о наименованиях
От AVX к AVX2, к AVX-512, к AVX10
Поговорив со своими любимыми сотрудниками Intel, я узнал, что не было «конкретных» причин выбора названия AVX10 в качестве потомка AVX512, за исключением маркетинговых.
У меня есть альтернативная теория:
Та спецификация AVX-512, которая известна нам сегодня, начиналась как гораздо меньшая архитектура набора команд со схемой кодирования VEX, внутри компании и в ранних маркетинговых материалах известная как AVX3. AVX3 была «довольно» скучной, потому что лишь расширяла регистры, оставалась VEX и предоставляла более универсальное fused multiply add, схожее с тем, что AMD пыталась реализовать при помощи команд FMA4. Учитывая эту информацию, можно обозначить расширения AVX512f как AVX3, а если затем исключить расширения только для Xeon Phi, то получится, что у AVX512 есть примерно 6 групп расширений, которые вполне можно назвать отдельными поколениями. Примерно их можно разбить так:
AVX3 F, CD, ER, PF
AVX4 VL, DQ, BW
AVX5 IFMA, VBMI
AVX6 BF16
AVX7 VPOPCNTDQ VNNI, VBMI2, BITALG
AVX8 VP2INTERSECT – больше не поддерживается
AVX9 FP16
AVX10 — новая «большая» спецификация
Вернёмся к хорошему
Следует ожидать, что на серверах и HPC все реализации будут соответствовать спецификации AVX10.N/512. Иными словами, следует ожидать, что реализации будут использовать AVX10.N с 512-битными векторами. Это гарантирует полную поддержку любого уже имеющегося кода AVX-512 и продолжение традиции обратной совместимости для x86_64.
На потребительских платформах наличие огромного регистрового файла с 32 регистрами, каждый из которых имеет размер 512 битов, можно считать проблематичным и нежизнеспособным решением. Однако, как видно на примерах Zen 4, Alder Lake, Tiger Lake и других архитектур, это вполне реализуемо. Проблема в том, что в мелких «эффективных» ядрах, в частности, в недавних микроархитектурах Intel Gracemont (в Alder Lake и Raptor Lake) и Crestmont (в новых Meteor Lake и Sierra Forest) предпочитают реализовывать только 128-битные физические АЛУ, обеспечивая поддержку AVX2 при помощи так называемой «двойной накачки» (более урезанная версия конвейерной обработки регистров эпохи векторных процессоров). Благодаря этому возможно реализовать 16 x 256-битных регистров AVX2, но при этом требуется реализовать только 128-битные блоки работы с плавающей запятой и целыми числами. Но за это приходится расплачиваться: хотя можно сэкономить на размере кристаллов и мощности, при некоторых нагрузках может наблюдаться серьёзная регрессия производительности.
Зная об этом, умные ребята из Intel, проектирующие спецификацию AVX10, затребовали, чтобы все реализации имели 32 регистра, но эти регистры должны иметь ширину, равную /M. Это значит, что AVX10/256 будет иметь те же возможности команд, что и AVX10/512, но требует, чтобы 32 регистра имели ширину всего 256 битов.
По большей части, любой код, написанный для старых расширений AVX-512, ограниченных 256-битными регистрами, должен* нормально работать, достаточно лишь его перекомпилировать. Подобный код возникал в результате знаменитой угрозы «AVX-512 down-clocking», которая «наказывает» за использование 512-битной части AVX-512. Хорошая сторона заключается в том, что большая часть кода уже спроектирована под «упрощённую» 256-битную версию AVX-512, и его не будет легко подвергнуть миграции, когда настанет время.
*Ситуация чуть сложнее, чем описано выше, но код можно заставить работать за несколько часов или дней.
Но что гласит Спецификация?
При чтении спецификации AVX10 (технический документ Intel по AVX10, полная спецификация AVX10) внимание привлекают несколько пунктов.

А именно, в техническом документе многократно используется слово «converged». Какие фичи являются converging? Это все уникальные фичи AVX-512 которые не являются просто «большими регистрами». Например, такие вещи, как числа с плавающей запятой с половинной точностью IEEE-754 поддерживаются как часть AVX10. А как насчёт brain floating point 16 (BF16), урезанной версии FP32, используемой в модном сегодня ИИ? Они поддерживаются как часть AVX10. А как насчёт любимых всеми программистами на ассемблере AVX-512 команд динамически перепрограммируемых операторов троичной логики? Они поддерживаются как часть AVX10. По сути, все крутые штуки, которые нужны программистам ассемблера и компиляторов для ускорения приложений благодаря более умной архитектуре алгоритмов, включены как часть AVX10.
Ещё одно важное требование AVX10 заключается в том, что все реализации должны полностью реализовывать AVX2 и его 16 x 256-битных регистров. В свою очередь, вы гарантированно получаете поддержку кода AVX2 на своём процессоре. Если говорить математически, можно воспринимать это как то, что AVX10 имеет в своём множестве полное множество AVX2. В свою очередь, AVX2 требует полного множества AVX1.
И, наконец, к самой сути: AVX10.N/128
С моей точки зрения, существуют три «базовых» проблемы:
Любые реализации в той или иной степени будут «прокляты».
Это вызывает проблемы у ПО, разработчики которого пытаются реализовать спецификацию.
По сути, это утраивает трудозатраты разработки для каждого поколения.
«Проклятие» реализаций
Любая реализация AVX2 должна иметь 16 x 256-битных регистров. AVX10 требует 32 векторных регистров вне зависимости от размера вектора. В случае AVX10.N/128, это будет 32 x 128-битных регистров. С точки зрения (предполагаемой) инженера/архитектора, занимающегося проектированием ядра, дерево принятия решений для AVX10/128 будет выглядеть так:
Любая реализация, которая обеспечивает поддержку только до AVX10/128, должна поддерживать 16 256-битных регистров YMM, они же YMM0-15, и вторичный набор 128-битных регистров XMM в интервале XMM16-31. У архитектора возникает ещё несколько вариантов выбора.
Выбрать ли два разных класса векторных регистров SIMD разного размера?
Можно ли альтернативно использовать верхнюю половину битов 128-255 ymm0-15 в качестве битов 0-127 xmm16-31?
Можно ли расширить xmm16-31 до 256 битов?
Третий вариант наиболее вероятен для «чистой» реализации. Но потом вас осеняет: постойте-ка! Я создал тот регистровый файл, который нужен мне для AVX10/256! Если бы я реализовал чуть больше логики управления, то у меня была полнофункциональная реализация AVX10/256 и я бы мог сэкономить свои 128-битные FPU и АЛУ!
А знаете, мы ведь делали так раньше! А именно для Zen 4 и Zen4c AMD реализовала AVX512 на основе 256-битных FPU. Когда в Zen 1 приняли AVX2, там также выполняли «двойную накачку» 128-битного целочисленного блока. До этого в микроархитектуре Bulldozer был реализован AVX1 с 128-битными FPU! И это относится не только к AMD! Сегодня Intel делает тоже самое с 128-битными FPU и целочисленными АЛУ в Gracemont.
Поэтому вы делаете шаг назад и осознаёте, что изначально реализовали «двойную накачку», потому что вам нужна поддержка 16 x 256-битных регистров для AVX1 и 2! В частности, AVX требуется логика для адресации, маскирования, загрузки и сохранения и верхней, и нижней части регистра.
Проблемы реализации ПО
Следующий шаг относительно прост: устранение проблем оптимизации реализации ПО в современных реализациях ISA. Одна из гарантий AVX10 заключается в том, что любая реализация будет поддерживать все меньшие валидные реализации. Иными словами, хотя платформы AVX10/512 поддерживают AVX10/256, платформы AVX10/256 не поддерживают AVX10/512. Следовательно, платформы AVX10/256-512 поддерживают AVX10/128.
Но вот в чём проблема: с точки зрения нацеленности ПО, когда AVX10 станет достаточно распространённым, чтобы стать целевой платформой x86_64 по умолчанию (а это случится примерно в течение десятка лет), AVX10/128, как самый совместимый вариант, станет в конечном итоге даунгрейдом по сравнению с AVX2 для SIMD-программ. Если AVX10/128 валиден и проложит себе дорогу на рынок, то он станет де-факто минимальной целевой платформой для AVX10, потому что поддерживает все сетевые и потребительские опции. Хотя справедливо, что лучшее в AVX-512 — не 512 битов, одновременно справедливо и то, что даунгрейд до 128-битных регистров в качестве стандартной целевой платформы пойдёт во вред генерации SIMD-кода: напоминаю, что мы поднялись выше 128-битных регистров на потребительских платформах более десятка лет назад. Генерация кода ушла дальше. Действительно ли спустя десять лет мы захотим быть привязанными к 128-битным регистрам с улучшенными командами?
Вы хотите ещё больше целевых платформ?!?!
Мой последний аргумент заключается в том, что с точки зрения ПО AVX10 только с 256-битными и 512-битными опциями, по сути, удваивает бремя для каждого поколения. Это уже произошло с потребительскими Golden Cove и корпоративными Golden Cove. А именно, первые поддерживают архитектуры только до AVX2, а в последних реализован весь AVX512 (вплоть до совместимости с AVX10.1/512).
«Одна и та же» микроархитектура (uArch) может иметь разные конфигурации памяти, различное количество блоков Fused Multiply Add (FMA), разные количества блоков векторного сложения и так далее.
В примере с Golden Cove мы имеем: потребительский AVX2 с DDR4 и DDR5, AVX-512 для рабочих станций с DDR5, серверный AVX-512 с DDR5, серверный AVX-512 только с HBM и серверный AVX-512 с основной памятью DDR5 и кэшем HBM.

В HPC привыкли к использованию множественных версий для различных подплатформ ISA, но разработчики потребительского ПО избегают этого любой ценой. Вам повезёт, если мейнтейнеры потребительского ПО включат поддержку чего-то выше SSE2, не говоря уже о какой-нибудь разновидности AVX.
И я их не виню. С точки зрения поддержки неразумно просить каждый менеджер пакетов компилировать разные версии проектов под разные версии ISA, подстраиваться под разные платформы и каким-то образом умудряться всегда их собирать. И теперь вы хотите добавить всё это поверх уже существующей нагрузки на управление пакетами? Не думаю, что это хорошая идея. В сфере HPC можно рассчитывать, что большинство пользователей перекомпилирует ПО под свои кластеры, но на потребительских платформах такого не случится. Да даже Arch Linux не реализует это в экспериментальном режиме!
Заключение: чего же я хочу?
Моя просьба к Intel проста. На странице 1-2 документа Intel 355989-001US, rev 1.0, сейчас написано:
Для Intel AVX10/256 поддерживаются 32-битные длины регистров маски операндов. Для Intel AVX10/512 поддерживается 64-битная маска операндов. Пока нет планов на поддержку реализации Intel AVX10/128.
Я прошу, чтобы текст поменяли на такой:
Для Intel AVX10/256 поддерживаются 32-битные длины регистров маски операндов. Для Intel AVX10/512 поддерживается 64-битная маска операндов. Поддержка для реализации только Intel AVX10/128 не предоставляется в этой спецификации. Все реализации AVX10/256 и AVX10/512 должны обеспечивать возможность операций со скалярными и 128-битными векторными регистрами.
Такая конкретная формулировка нужна для гарантий того, что если Intel когда-нибудь захочет исследовать архитектуру на основе AVX10, предназначенную для многоядерного продукта, концептуально подобного Xeon Phi, то у компании была бы такая возможность. Благодаря этому компиляторы, разработчики библиотек и другие поставщики ПО не будут находиться во подвешенном состоянии. Это позволяет не оставлять возможности для того, что допускается по спецификации, но не попадёт на рынок. В конечном итоге, изменения всё равно позволят им создать продукт, но проектирующие продукт могут взять на себя ношу его поддержки, оставив в покое нас, обычных разработчиков. Продукт, вероятно, будет «простым» ядром Atom, реализующим скалярные версии AVX10, и у каждого ядра будет собственный блок AMX. Но пусть такими рассуждениями о продуктах занимаются другие части нашей отрасли.
Так что я смиренно прошу: Intel, пожалуйста, сделай AVX10/128 недопустимой реализацией в текущей спецификации.
Комментарии (8)

Sap_ru
17.11.2023 17:32+1Несколько сумбурно. Настолько, что из первой части вообще не ясна суть проблемы. Аналогично неясно толком, что именно предлагается.
Balling
"Благодаря этому компиляторы, разработчики библиотек и другие поставщики ПО не будут находиться во подвешенном состоянии."
Код для gcc пишет сама Intel. И вообще, у Intel уже есть свой новый (ну как новый, 2011 года) компилятор для AVX10.
https://github.com/search?q=repo%3Aispc%2Fispc+avx&type=issues
Sap_ru
К сожалению динамическое переключение SIMD инструкций пока нормально работает только в проприетарном компиляторе Intel (и только для процессоров Интел). Да, и в целом рантайм переключение не панацея, так как ограничивает оптимизацию. Сейчас действительно всё компилируется/оптимизируется под SSE (или SSE2?) и есть возможность надолго застрять на 128 битах, при том, что практически всё железо уже будет поддерживать 256 бит и выше.
С другой стороны, автор немного драматизирует. Всё идёт к тому, что в рамках платформы x64 через 5 лет совершенно везде будет 256 бит и много где будет 512 бит, что позволит изменить настройки компиляции массового сегмента вне зависимости от спецификаций. Уже сейчас много софта просто не заработает без AVX (кое что даже не заработает без AVX2), при том, по-умолчанию до сих пор SSE стоит, если не ошибаюсь. AVX уйдёт в легаси. AVX2 станет мейнстримом. AVX512 будет использоваться либо через рантайм переключение, либо в софте для тяжёлых задач. Грубо говоря, если ментейнеры основных ОС и дистрибутивов сделают ядра и окружение по-умолчанию под AVX2, то и софт весь дружно переключит дефолтные настройки компиляции. Короче, всё само собой, как оно и шло ранее. Страхи же того, что Интел или кто-то другой будет новые (!!!) процессоры с поддержкой SIMD ниже AVX2 выпускать, мягко говоря странные. Зачем? Не говоря уже о конкуренции и прочем. Интел в современном мире видео, аудио, шифрования и прочих потоковых данных сделает шаг назад от AVX2? При наличии набирающего обороты конкурента?! Серьёзно? Одно только распространение AI так производителей в спину толкает, что в они думают не о 128 битах, а том как бы так упихать хоть какой-то AVX-512 даже в нижний сегмент, энергоэффективные ядра и мобильные платформы. Собственно, энергоэффективные ядра и есть отличный показатель того, что именно становится абсолютным минимумом векторных расширений. Для других платформ будет пара тройка вариантов компиляции и оптимизации, но это уже не забота Интел - там пусть у ARM и NVIDIA голова болит.
Гораздо веселее складывается ситуация с AI-ускорителями. Вот там уже зреет такой зоопарк, что цирк SIMD-расширениями времён Pentium-III и дальнейший цирк с расширениями виртуализации цветочками покажутся. Этот ад можно сравнить только с эпохой становления стандартов видеоускорителей - кто во что горазд, война патентов, война технологий, логические и патентные бомбы в OpenGL и всё прочее.
Mike-M
Поддерживаю. Именно такое переключение реализовано сейчас, например, в текстовом редакторе EmEditor:
скриншот
Sap_ru
Идрыть... А нафига ему аж AVX2 ?!
И вообще-то, это криворукость. Переключение делается на этапе загрузки библиотек, загрузчиком, которые вибирает нужное в зависимости от возможностей процессора. Заставлять это делать пользователя... зачем?!
Mike-M
Чтобы быть "world's fastest text editor".
Никто не заставляет. Первым же элементом в раскрывающемся списке стоит Auto.
Sap_ru
Это я понимаю :) я смысла в этом не понимаю :)
n_bogdanov
Смысл простой - чтобы батарейку экономить. То есть на мобильных устройствах есть смысл уходить от максимально быстрого решения в угоду мобильности.