А можно ли парсировать текст голым железом? Вообще без программы?
— А как это?, — спросил меня знакомый, — С помощью Ардуино?
— Внутри Ардуино стоит вполне фон-неймановский процессор и работает программа, — ответил я, — Нет, еще более голое железо.
— А-а-а-а, этот, микрокод?, — догадался мой товарищ и взглянул на меня победно.
— Нет, термин «микрокод» использовался для специфической организации процессоров в 1970-е годы, потом его использование сошло на нет, — ответил я и добавил, — Правда есть еще микрооперации в интеловских процессорах, в которые перекодируется x86, но это тоже другое. Нет, я имею в виду парсинг текста устройством, состоящим из логических элементов И-ИЛИ-НЕ и Д-триггерами, как на картинке ниже.
— Невозможно! — воскликнул мой приятель, — в таком устройстве где-то сбоку должен сидеть процессор и хитро подмигивать!
— Почему это невозможно?, — парировал я, — Вот машину Тьюринга знаешь? Парсирует текст на ленте, а сбоку никакие интелы и ардуино не подмигивают.
— Нуу, машина Тьюринга, — протянул приятель, — это абстракция, типа Демона Максвелла.
— Никакой абстракции, сейчас увидишь работающую схему, парсирующую текст, — сказал я и прибавил, — но сначала расскажу, зачем мне вообще это понадобилось.
1. Зачем мне понадобилось парсировать текст хардвером без софтвера
В прошлом году я участвовал как один из организаторов в серии семинаров по MIPSfpga. MIPSfpga — это пакет, который содержит процессорное ядро в исходниках на Verilog, которое можно менять, добавлять новые инструкции, строить многопроцессорные системы, менять одновременно софтвер и хардвер и т.д. Систему MIPSfpga можно симулировать в симуляторе верилога, синтезировать и реализовать на плате ПЛИС, или при большом желании изготовить по ней микросхему на фабрике.
ПЛИС/FPGA-плату с MIPSfpga нужно программировать дважды — сперва залить в нее c PC конфигурацию хардвера (определить логическую функцию каждой ячейки ПЛИС и соединения между ними), а потом залить (тоже с PC) софтвер (последовательность команд процессора) в память синтезированной хардверной системы (в которую входит процессорное ядро MIPS microAptiv UP, интерконнект, два блока памяти и блок ввода-вывода).
С заливкой хардвера проблем нет — и Xilinx ISE/Vivado, и Altera Quartus II содержат софтвер, которые позволяет заливать конфигурацию хардвера в платы, с которыми я работаю, с помощью простого USB кабеля без никаких дополнений со стороны пользователя. К таким платам относятся Digilent Basys 3 и Nexys 4 DDR, Terasic DE0-CV и другие.
В отличие от конфигурации хардвера, софтвер в стандартном пакете MIPSfpga Getting Started заливается через отладочный интерфейс EJTAG, используя дополнительную плату, которая называется BusBlaster, в комбинации с софтвером, который называется OpenOCD. К сожалению, комбинация BusBlaster / Open OCD является достаточно сырой — у нее могут быть проблемы с драйверами в некоторых версиях Windows и Linux-а. Кроме этого, BusBlaster нетривиально купить в России. Поэтому перед семинарами я задумался о том, как заливать софтверную часть системы в MIPSfpga без BusBlaster/OpenOCD.

2. Какой именно файл нужно распарсировать и залить в память системы
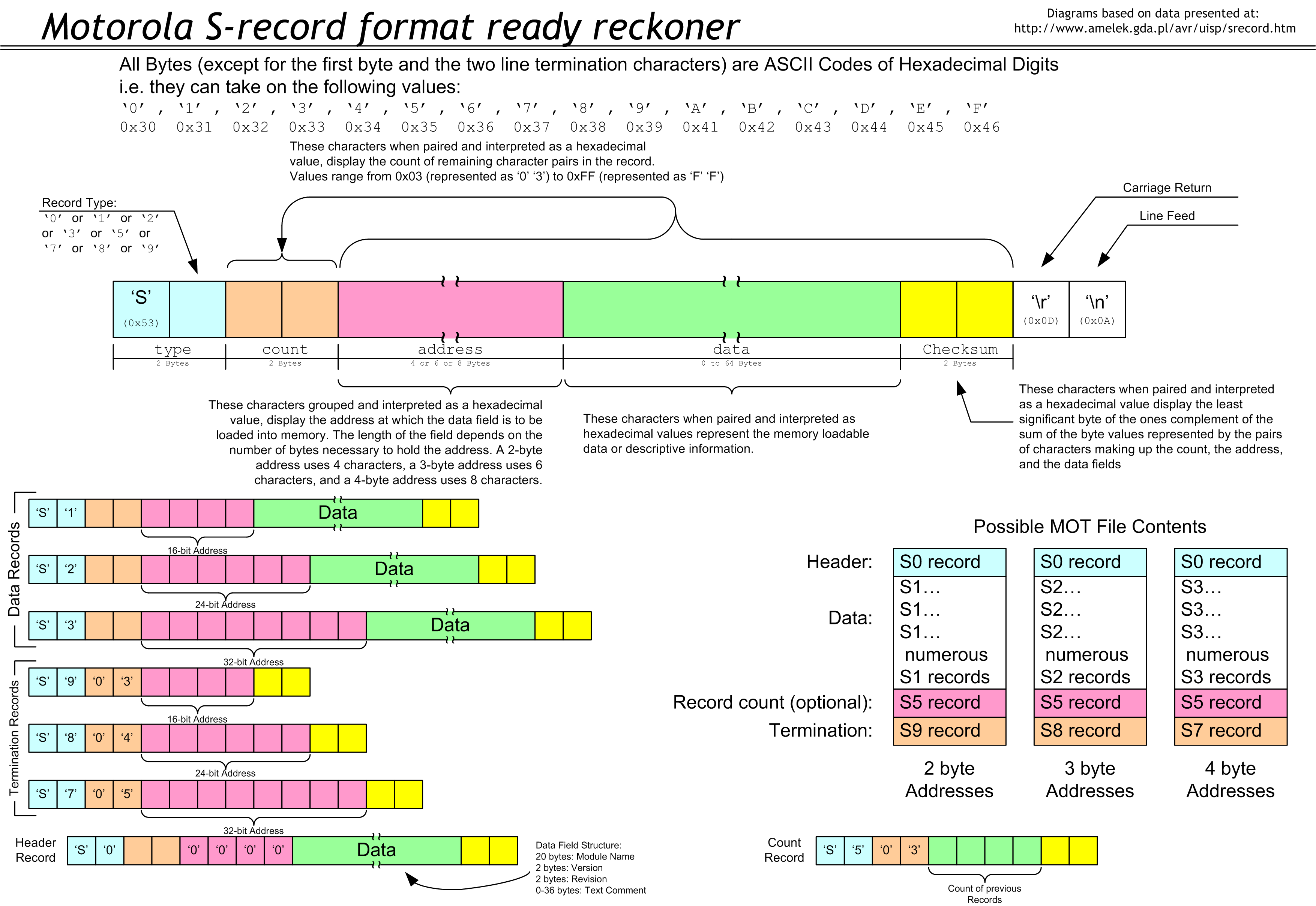
Софтвер, которую нужно залить в MIPSfpga — это самая обычная программа на Си или ассемблере, которая компилируется и линкуется обычным GCC в файл в формате ELF. Пакет GNU также содержит программу objcopy, которая умеет превращать ELF в разнообразные форматы, в том числе текстовые — Intel HEX, Motorola S-record и формат, который понимает встроенная подпрограмма $readmemh в языке описания аппаратуры Verilog. Сначала я хотел использовать формат Intel HEX, но обнаружил, что его не поддерживает тот из вариантов objcopy для MIPS, который я использовал. Вторым вариантом было использовать формат
Motorola S-record, и с ними все получилось хорошо. Вот шпаргалка по этому формату:
3. Чем заливать и как — варианты инженерных решений
3.1. Самый простой способ избежать заливки софтвера через BusBlaster — это просто поместить его в систему MIPSfpga во время ее синтеза — процесса, при котором код на языке описания аппаратуры Verilog превращается в граф из логических элементов и триггеров. Как программа-синтезатор Xilinx ISE/Vivado, так и Altera Quartus II распознают во время синтеза конструкцию языка Verilog $readmemh, и создают память, которая инициализируется данными из текстового файла. К сожалению такое решение очень непрактично, если пользователь собирается часто перекомпилировать софтвер, так как каждый раз ему прийдется еще и пересинтезировать хардвер, что может занимать от 15 до 30 минут.
3.1.1. Вариант возможности 3.1 — частичная переконфигурация ПЛИС. Я ее не исследовал, так как узнал, что и в таком случае ждать прийдется долго, а я хочу ждать не более нескольких секунд. Кроме этого я хотел что-нибудь, не зависящее от производителя ПЛИС-ов.
3.2. Наиболее интуитивно ожидаемый способ для программистов встроенных систем — это сделать часть программы фиксированной, которая помещается в систему во время ее синтеза (bootloader), а другую часть программы — загружаемой с PC через последовательный порт. Загрузочная программа должна была бы инициировать трансфер загружаемой программы с PC, получать эту программу в виде данных, которые потом записывать в память. Такой метод описал @Frantony в заметке на Хабре «MIPSfpga: вне канона»
3.2.1. У метода 3.2. есть две вариации — передавать загружаемую программу в виде текстового файла в формате типа Motorola S-record и парсировать этот файл в загрузчике на плате, или, альтернативно, парсировать текстовый файл на PC и передавать данные на плату в бинарном виде.
3.3. Метод, который я использовал — весь прием данных, парсирование и распихивание данных по памяти сделано полностью в хардвере, реализованном в ПЛИС-е. Преимущество этого метода — софтвер на плате вообще не знает о существовании хардверного загрузчика. Когда хардверный загрузчик замечает данные, идущие с PC, он ставит процессор на сброс (reset), получает и размещает в памяти все данные, снимает процессор с сброса, после чего процессор начинает читать и выполнять код обработчика исключения сброса.
3.3.1. В процессе обсуждения задачи с другими пользователями и разработчиками MIPSfpga также высказывалась идея сделать полноценный DMA-порт для записи данных с PC в память одновременно с работой процессора с памятью (а не когда процессор стоит на reset-е), но она была отвергнута как слишком сложная и по большому счету бессмысленная для типов задач, в которых предполагалось использовать MIPSfpga во время семинаров в России.
4. Как происходит соединение с PC?
Последовательный порт — это очень давнее изобретение. UART / RS-232C появился еще в конце 1960-х годов. Все PC в 1980-е были с COM-портами, в которые можно было писать как в файл. Вы не поверите, но это пережило MS-DOS и осталось в Windows до сих пор. Да, да, чтобы передать файл с PC на внешний последовательный порт, вы и сейчас можете написать в командной строке «type имя-файла COMномер-порта»:

В Линуксе такое соединение тоже есть (хотя MIPSfpga подсоединенный к Линуксу я еще не пробовал, но это пробовал один товарищ в Италии, который прислал мне об этом емейл). Пользователь Линукса, который копирует данные в файл, соответствующий COM-порту, должен входить в группу dialup:
stty -F /dev/ttyUSB0 raw 115200 cat srec program.rec > /dev/ttyUSB0
При этом древние порты RS-232C в современные PC не ставят, вместо этого делают «виртуальный COM-порт» через USB, используя вот такой переходник на основе чипа FT232RL от компании FTDI (Внимание! У этого чипа есть много глюкавых подделок) Также обращаю внимание, что для работы с ПЛИС переключатель 3.3/5V на переходнике нужно поставить на 3.3V, иначе теоретически можно повредить пины/выводы ПЛИС-а, которые как правило нежнее, чем например у микроконтроллеров:

Помимо переходника, показанного на фотографии выше, для соединения PC и UART на FPGA можно использовать кабель под названием PL2303TA USB TTL to RS232 Converter Serial Cable module for win XP/VISTA/7/8/8.1. Это кабель удобно использовать для небольших плат типа Terasic DE0-Nano с male GPIO выводами. На сайтах типа AliExpress также продается более дешевый кабель, основанный на чипе PL2303HX, но у этого чипа были какие-то проблемы совместимости с Windows 8.x, поэтому лучше все-таки использовать кабеля на основе PL2303TA:

5. Куда потребовалось залить полученные с PC данные?
До того, как я вставил модули загрузки загружаемой программы с PC в память синтезированной системы MIPSfpga+ (так я назвал свой вариант MIPSfpga), ее модульная иерархия выглядела так:

Что находится в каждом модуле:
- de0_cv — внешний модуль, специфичный для каждого типа FPGA-платы. Выводы этого модуля соответствуют физическим выводам на самой микросхеме. Конкретный модуль de0_cv написан для платы Terasic DE0-CV с ПЛИС Altera Cyclone V
- mfp_single_digit_seven_segment_display display_0, display_1, ... — драйверы семисегментного индикатора для альтеровских плат (по одному на цифру)
- mfp_system — системный модуль, одинаковый для всех FPGA плат
- m14k_top — верхний модуль микропроцессорного ядра MIPS microAptiv UP (также называемым MIPS microAptiv MPU), название m14k осталось от предыдущей версии процессора — MIPS M14Kc
- mfp_ejtag_reset — вспомогательный модуль для сброса отладочного интерфейса EJTAG
- mfp_ahb_lite_matrix — модуль, который объединяет в себя блоки памяти, схемотехническую реализацию логики шины AHB-Lite и логику ввода-вывода. Последняя связывает адреса на шине, приходящие от софтвера, с сигналами хардверных устройств ввода-вывода — кнопками, LED-индикаторами и т.д.
- mfp_ahb_lite_decoder — модуль, который декодирует адрес на шине AHB-Lite и определяет, какой из ведомых устройств (блоков памяти или модуль логики ввода-вывода) должен обрабатывать транзакцию на шине
- mfp_ahb_ram_slave reset_ram — оболочка блоков памяти, реализующая протокол ведомого устройства шины AHB-Lite. Данная группа блоков (reset_ram) предназначена для части программы, которая стартует сразу после выхода процессора из состояния сброса / reset
- mfp_dual_port_ram i0-i3 — модули, код на верилоге в которых синтезатор распознает как указание создать блочную память внутри ПЛИС. Чтобы синтезатор правильно воспринимал этот код, его нужно писать определенным образом. Блоков четыре с шириной памяти 8 бит (вместо 1 блока шириной 32 бита) чтобы можно было делать запись одного байта с шины AHB-Lite шириной 4 байта (синтезатор не понимает память с маской)
- mfp_ahb_ram_slave ram — еще одна оболочка блоков памяти, реализующая протокол ведомого устройства шины AHB-Lite. Данная группа блоков (ram) предназначена для основной части программы, которая работает на кэшируемой памяти
- mfp_dual_port_ram i0-i3 — см. аналогичные четыре блока выше
- mfp_ahb_gpio_slave — модуль ведомого устройства для ввода-вывода общего назначения (GPIO — General Purpose Input / Output). Отображает адреса на шине, приходящие от софтвера на сигналы хардверных устройств ввода-вывода — кнопки, LED-индикаторы и т.д.
- mfp_ahb_lite_response_mux — вспомогательный модуль для работы шины AHB-Lite — мультиплексор, чтобы направить ведущему устройству (микропроцессорному ядру) данные чтения с правильного блока памяти или модуля ввода-вывода
- mfp_pmod_als_spi_receiver — модуль, который реализует вариант протокола SPI для датчика освещения Digilent PmodALS, одного из примеров устройств, подсоединенных к системе MIPSfpga+. В этом посте данный модуль не обсуждается, я возможно напишу отдельный пост про интеграцию датчика освещения с MIPSfpga+
6. Как изменилась иерархия системы, когда я вставил в нее хардверный загрузчик?

Четыре новых модуля:
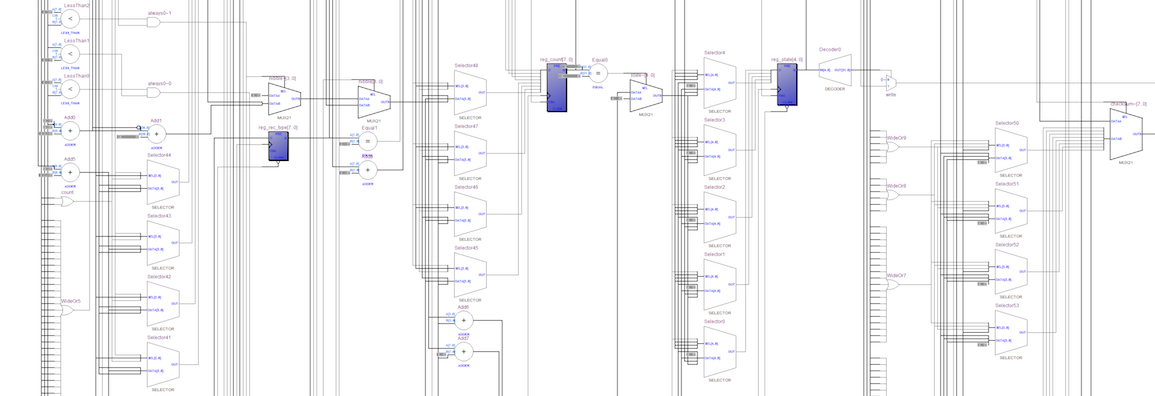
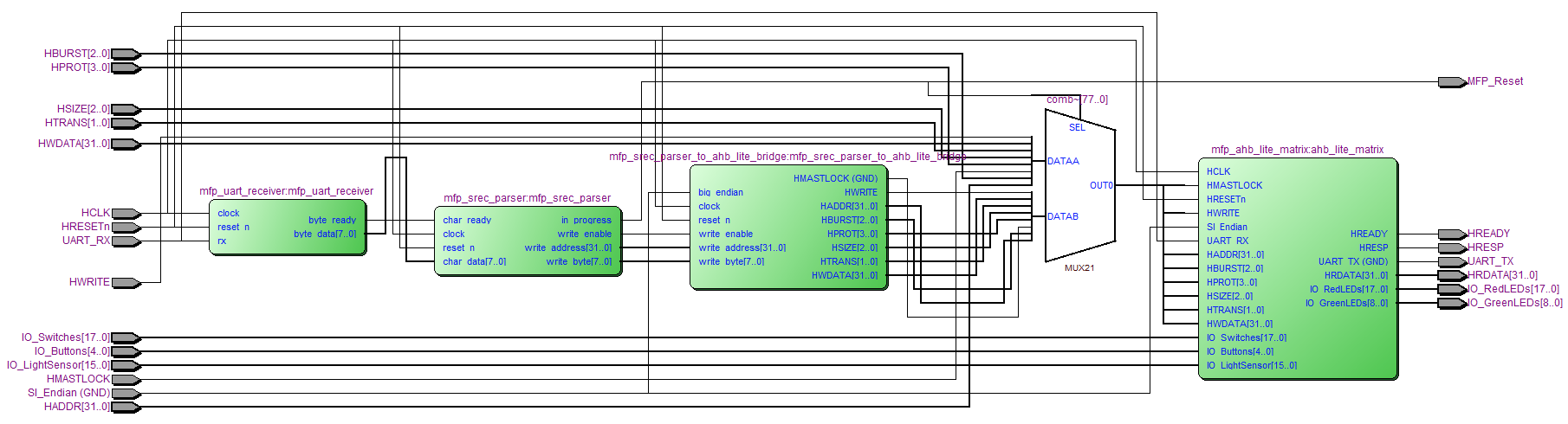
- mfp_ahb_lite_matrix_with_loader — ставится на место модуля mfp_ahb_lite_matrix из предыдущей иерархии. mfp_ahb_lite_matrix_with_loader содержит как модуль mfp_ahb_lite_matrix, так и три модуля с новой функциональностью:
- mfp_uart_receiver — получает данные с PC через UART и превращает их в поток байтов / алфавитно-цифровых символов
- mfp_srec_parser — парсирует цепочку байтов, полученных от модуля mfp_uart_receiver как текст в формате Motorola S-Record и генерирует последовательность транзаций (адрес/данные) чтобы наполнить память синтезированной системы заданными в тексте данными
- mfp_srec_parser_to_ahb_lite_bridge — преобразует транзакции, полученные от модуля mfp_srec_parser в транзакции, которые соответствуют протоколу шины AHB-Lite. Также превращает виртуальные адреса, которые использует софтвер, в физические адреса, которые использует хардвер, с помощью простого фиксированного отображения.
Ниже приведена схема на уровне иерархии модуля mfp_ahb_lite_matrix_with_loader, полученная после компиляции кода на верилоге, но до полного синтеза (оптимизации, отображения на ПЛИС-специфичные элементы, размещения и трассировки). Обратите внимание на мультиплексор между mfp_srec_parser_to_ahb_lite_bridge и mfp_ahb_lite_matrix, он направляет к подсистеме памяти и ввода вывода либо транзакции от микропроцессорного ядра, либо транзакции от хардверного загрузчика:
7. Пару слов про последовательный порт, UART
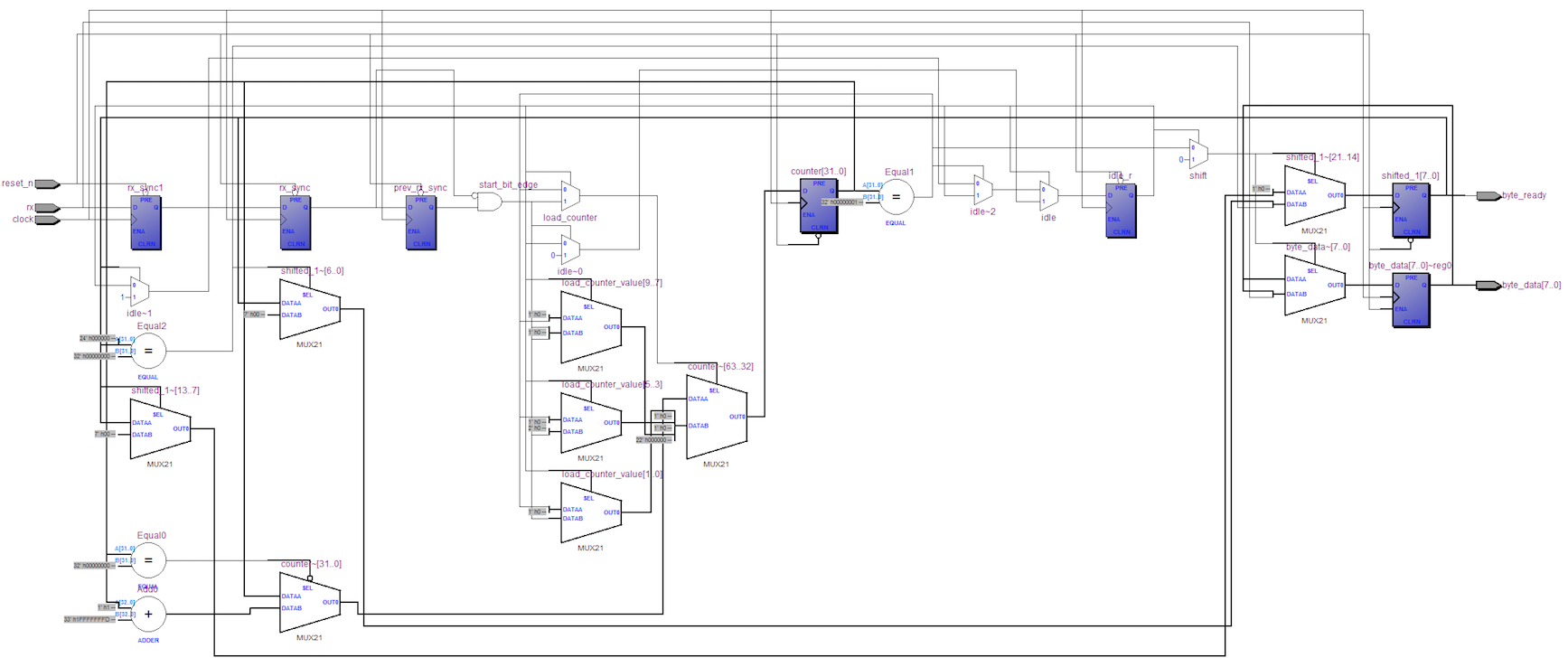
Тема UART обсуждалась на Хабре много раз, в том числе совсем недавно, поэтому я не буду задерживаться на ней в подробностях. Моя реализация приемника использует простейший вариант протокола UART, без контрольных сигналов, с одним начальный битом, без проверок четности, с фиксированной скоростью передачи и для фиксированной частоты синхросигнала / сигнала тактовой частоты / clock. Модуль mfp_uart_receiver получает данные с сигнала RX последовательно и выводит 8-битный байт параллельно, когда он готов. Модуль содержит конечный автомат, который ждет отрицательного фронта сигнала RX (таким образом определяя начальный бит), после чего считывает биты данных в правильные моменты времени, которые определяет, считая такты с помощью счетчика. Так как количество тактов на каждый бит довольно велико, 50,000,000 Hz / 115,200 baud = 434 тактов (или 217 тактов для 25 MHz), прием данных происходит довольно надежно. Вот интерфейс модуля:

Полный код модуля — http://github.com/MIPSfpga/mipsfpga-plus/blob/master/mfp_uart_receiver.v.
Схема модуля mfp_uart_receiver после первичной компиляции:
8. И наконец обещанное: парсер текста в формате Motorola S-Record голым хардвером, без процессора и без софтвера
Модуль mfp_srec_parser получает байты из модуля mfp_uart_receiver и парсирует их как текст в формате Motorola S-record, используя конечный автомат. Во время парсирования происходит также формирование транзакций к памяти синтезированной системы MIPSfpga+; эти транзакции заполняют память байтами, заданными из парсированного текста, по заданным в тексте же адресам. Интерфейс модуля:

Определяем идентификаторы констант для состояний конечного автомата и используемых ASCII символов:

Комбинационная логика для превращения символьных констант '0', '1',… '9', 'A', 'B',… 'F' в четырехбитовые числа 0, 1, 2,… 9, 10, 11,… 15.

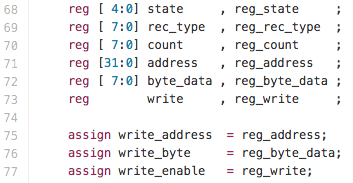
Переменные для конечного автомата. Слева — новое значение, создаваемое в текущем цикле/такте, справа — записанное в регистр / D-триггер / D-flip-flop значение, сформированное в предыдущем цикле. Замечу, что из верилоговского «reg» синтезатор далеко не всегда делает D-триггер / регистр в хардверном смысле. Ключевое слово «reg» нужно воспринимать только как вид переменной, которой можно делать присваивания внутри «always»-блоков:
Присваивания после определения переменных — это присваивания выводам модуля сгенерированных адресов (которые до этого записываются в регистры):
Логика конечного автомата состоит из комбинационной части и последовательностной части. Если вы не знакомы с этими концепциями, вы можете прочитать их в бесплатном учебнике Харрис & Харрис.
В комбинационной части мы вычисляем значения для следующего состояния, причем под словом «состояние» имеется в виду не только группа D-триггеров, в которую превращается переменная reg_state, но и вообще все D-триггеры / D-flip-flop / хардверные регистры в схеме (все три термина в контексте этого поста взаимозаменяемы). Есть пуристы, которые говорят что это «конечный автомат», а «конечный автомат с данными», но мы оставим этих схоластов и их чертей на кончике иглы в покое.
Вот начало комбинационной части. Для того, чтобы не следить за нежелательным в методологии синхронного дизайна появлением защелок (D-latch), присвоим всем вычисляемым переменным значение по умолчанию в самом начале комбинационного always-блока:

Любые изменения происходят только когда мы получаем новую литеру от UART-приемника («if (char_ready)»). В нашем конечном автомате сначала мы ждем появления литеры 'S', после чего парсируем тип записи (нас интересует тип '3') и адрес по которому мы будем записывать последующие байты:

Теперь начинаем парсировать данные и одновременно генерировать транзакции адрес/данное на вывод из модуля:

На положительном фронте генератора тактового сигнала записываем вычисленные ранее значения в регистры, которые не требуют сброса:

А теперь делаем запись в регистры, которые требуют сброс — либо чтобы начать работу конечного автомата с однозначного состояния, либо регистры, которые определяют контролирующие сигналы на выходе из модуля:

Сигнал in_progress («в процессе») включен с момента распознавания первой записи с адресом (типа S3) и выключается, когда модуль распознает последнюю запись в файле (типа S7). Этот сигнал может выводиться на внешний индикатор на плате, он также используется для мультиплексора в mfp_ahb_lite_matrix_with_loader и определяет, пишет ли в память микропроцессорное ядро или хардверный загрузчик. Кроме этого, in_progress используется для сброса микропроцессорного ядра, чтобы оно было «вырублено», пока хардверный загрузчик пишет в память. Когда софтвер в память записан, микропроцессор «просыпается» и начинает читать инструкции (с фиксированного физического адреса 1FC0_0000).

Логика для определения ошибок в входном тексте. Работает параллельно с главным конечным автоматом и использует его состояния:
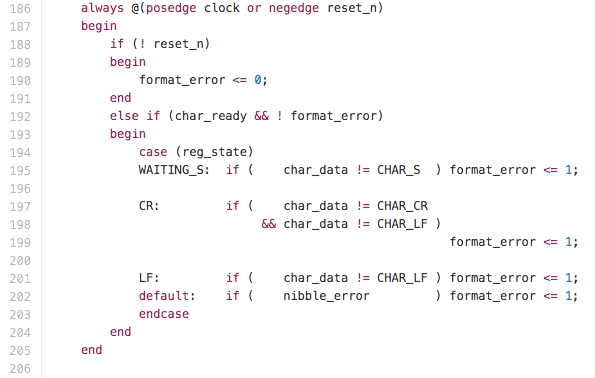
Логика для вычисления контрольных сумм и сравнения их с контрольными суммами из S-Record текста. Работает параллельно с главным конечным автоматом и использует его состояния:

Генерация сигнала ошибки. Хардверный парсер даже сообщает пользователю, на какой строке случилась ошибка:

Полный код модуля — http://github.com/MIPSfpga/mipsfpga-plus/blob/master/mfp_srec_parser.v
9. Пару слов про мост к шине AHB-Lite
Модуль mfp_srec_parser_to_ahb_lite_bridge превращает транзации адрес/данное, полученные из модуля mfp_srec_parser в транзакции для шины AHB-Lite, которую использует MIPSfpga.
Модуль также редактирует адреса — превращает виртуальные адреса, которые использует софтвер, в физические адреса, которые использует хардвер. Хотя у процессора MIPS microAptiv UP есть MMU TLB, которое позволяет гибкое и сложное отображение виртуальных адресов в физические, но в моих примерах использования MIPSfpga преобразование простое и фиксированное — простое обнуление трех верхних битов адреса. Если вас интересует работа устройства управления виртуальной памятью в MIPSfpga, вы можете посмотреть презентацию на русском языке «Устройство управления памятью в процессорах MIPS».
Код моста mfp_srec_parser_to_ahb_lite_bridge:
http://github.com/MIPSfpga/mipsfpga-plus/blob/master/mfp_srec_parser_to_ahb_lite_bridge.v

Схема модуля mfp_srec_parser_to_ahb_lite_bridge после первичной компиляции:
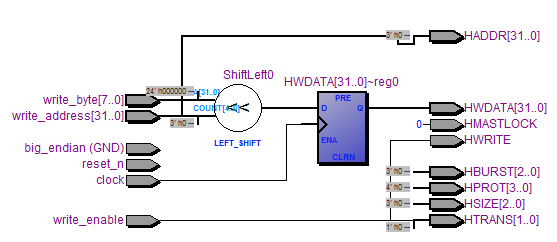
И наконец про саму шину AHB-Lite, которая используется для соединения устройств в системах на кристалле.
Ниже — отрывок из документации от Imagination Technologies, которую можно загрузить по следующей инструкции.

В частности, вы можете увидеть, почему передачу данных приходится задерживать на один такт по отношению к передаче адреса. В протоколе AHB-Lite адрес новой транзакции выкладывается на шине одновременно с данными из предыдущей транзакции:

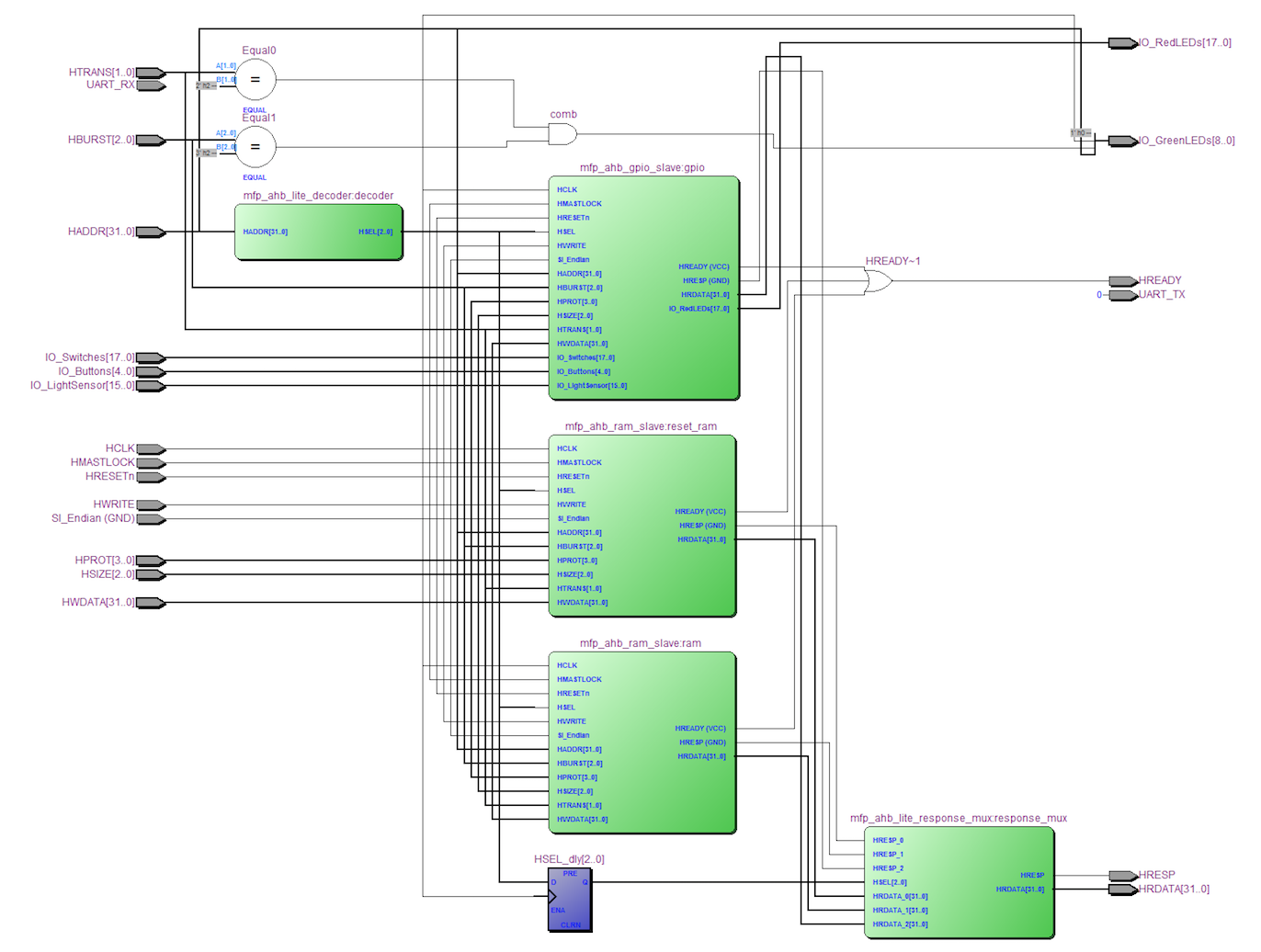
Схема модуля mfp_ahb_lite_matrix после первичной компиляции. Этот модуль содержит в себе три ведомых (slave) модуля — два блока памяти и модуль, который отображает обращения к памяти софтвера на работу ввода-вывода общего назначения — GPIO (General Purpose IO):
10. И что теперь? Продолжения, дополнения и предложения
В этом посте я описал только один из аспектов проекта MIPSfpga и его улучшения MIPSfpga+, которое я сделал, чтобы не мучаться с проблемами Bus Blaster / Open OCD во время путешествия по России в конце прошлого года. Замечу, что если вы хотите использовать отладчик на основе GDB с MIPSfpga, то вам все равно прийдется использовать Bus Blaster или другой отладочный адаптор, поддерживающий EJTAG.
Но тематика MIPSfpga гораздо больше. Ведь пакет содержит индустриальный процессор, который используется в новых продуктах от Samsung, Microchip и других компаний — и вы, дорогие читатели, можете экспериментировать с его структурой, используя тот же код, который используют и инженеры в этих компаниях. Вы можете написать свой модуль кэша с другой политикой выталкивания строк, разрабатывать многоядерные системы, прикручивать к MIPSfpga различную периферию. Если вам интересно сделать проект с MIPSfpga и вы при этом работает в каком-нибудь провинциальном вузе, у которого трудно получить бюджет на покупку FPGA плат — вы можете получить одну плату бесплатно, правда их осталось мало — подробности в «Раздача слонов: FPGA платы для образовательных проектов с MIPSfpga».
Также на Хабре уже была заметка про то, как прикрутить к MIPSfpga сопроцессор — см. https://habrahabr.ru/post/276205/.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (33)

mbait
10.03.2016 11:05+7
YuriPanchul
10.03.2016 11:21+3Да, но в контексте всего пространства возможных организаций вычислений цифровой схемотехники, так сказать с высоты птичьего полета, гарвардская архитектура — это небольшая вариация фон-неймановской архитектуры (ее было бы правильнее называть архитектурой Экерта-Мочли, но это другое обсуждение). Обе являются частными случаями того, как можно построить вычислительное устройство.
Ununtrium
10.03.2016 11:33-3"Парсировать" очень мешает получать удовольствие от статьи. Parse переводится как "парсить". А статья интересная.
YuriPanchul
10.03.2016 11:44+4Я завтра поправлю. В моей советской юности в компиляторных книжках издательства "Мир" по-моему переводили слово parse как "разбирать", "синтаксический разбор", "лексический разбор". Но сейчас слово "разбор" по-моему перегруженное.
Ununtrium
10.03.2016 12:49+1Да, я имел ввиду переводится в кавычках. Может нелитературно и тд, но это общеупотребительное слово.

zabbius
10.03.2016 17:25+2Заодно, сделайте, пожалуйста, что-нибудь с "софтвером" и "хардвером". Глаз об эти слова спотыкается, читать очень трудно.
YuriPanchul
10.03.2016 19:50+1Попробую писать "программное обеспечение" и "аппаратное обеспечение" или "программы" и "схемотехника" в другой статье. Какие еще слова лучше?
YuriPanchul
10.03.2016 11:47Да, еще переводили как "синтаксический анализатор", "лексический анализатор".





roller
10.03.2016 13:16+1Мм, ожидал в статье что-нибудь про парсинг финансовых данных (для более быстрого выставления ордеров на покупку-продажу, обычно для этого ПЛИС пытаются прикрутить сейчас все) но вместо этого просто потерял мысль о том зачем и что парсим. :(
YuriPanchul
10.03.2016 19:46Слышал, но об этом не задумывался. Да, оказывается применение FPGA для day-trading — эту судя по Гуглу уже типа мейнстрим — https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=day-trading%20fpga Спасибо за наводку.

leshabirukov
10.03.2016 15:01Интересно, нет ли варианта генератора парсеров типа yacc(bison) с hdl вместо "с" на выходе? По идее не только финансистам, но и в нагруженном вебе было бы интересно.
YuriPanchul
10.03.2016 19:43+1Это одна из вещей, которые сделать можно, но пользы от которых может быть меньше, чем кажется вначале. Аппаратный стек и несколько lookup-таблиц — и получаем LALR(1) парсер а-ля Yacc, но в хардвере. Но cразу приходят в голову две проблемы:
1) На FPGA, из-за более низкой тактовой частоты, такая реализация может быть медленнее процессора (хотя будет быстрее если делать ASIC).
2) Проблему более низкой тактовой частоты можно компенсировать большей параллельностью (несколько парсеров одновременно) и конвейеризацией, но с последним не совсем понятно как это конвейеризировать.leshabirukov
11.03.2016 15:271) Частоту надо сравнивать с пропускной способностью канала
2) Зачем конвеёер? один такт- один входной символ. Идея в том чтобы реализовать множество состояний парсера на hdl как конечный автомат (fsm). На входе автомата — текущий символ, верхушка стека состояний и возможно, предпросматриваемый символ. (если грамматика с предпросмотром).YuriPanchul
11.03.2016 18:51+11) Да
2) Я это понимаю. Но для большой грамматики и большого стека — и автомат будет большой, и далее если делать все операции по доступу к стеку и суммировать все требуемые задержки, то такт может получиться длинным по времени, что означает низкую тактовую частоту. В обычных условиях с длинными тактом борются, разрубая его на небольшие такты и делая конвейер. Но тут там может не получиться. В общем, тут нужно сделать эксперимент с какой-нибудь небольшой грамматикой.leshabirukov
12.03.2016 16:39Оказывается, очень давно над этим думают:
http://www.fpgacpu.org/usenet/re.html
Раз подход до сих пор не пошёл в жизнь, наверное в морг.
MichaelBorisov
10.03.2016 22:12+1Ожидал увидеть парсинг протоколов, типа HTTP, но SREC… Не из пушки ли это по воробьям? Зачем вообще нужен этот формат, что мешало сконвертировать SREC в двоичный формат и далее загружать его уже без сложностей с парсингом?
Но тема очень интересная. Спасибо вам, автор.YuriPanchul
10.03.2016 22:34что мешало сконвертировать SREC в двоичный формат и далее загружать его уже без сложностей с парсингом?
Но тогда бы не было этого поста :-) Также см. https://habrahabr.ru/post/278681/#comment_8801127

Wesha
12.03.2016 00:35-3Ничего не понял, а времени разбираться нет, но вспомнилось босоногое детство и реверс-инжиниринг контроллера дисковода БК-0010, поэтому ловите плюс ;)

mark_ablov
12.03.2016 12:13Занятно, разве что малость напрягает голосование с лидирующим вариантом про построение FSMов.
Это же практическая базовая вещь для hdl/verelog.
nerudo
А если пустить uart поверх jtag, то и проводов бы лишних не пришлось тянуть...
YuriPanchul
Во многих платах я использую встроенный UART без лишних проводов, например на Digilent Basys 3 и Nexys 4 DDR (обе с Xilinx Artix-7).
Я использовал для данного примера плату Terasic DE0-CV c Altera Cyclone V, так как ввоз плат с Xilinx в Россию сейчас непрост (прошлой весной Xilinx сделал ограничения и процесс занимает 3-4 месяца).
Как делать UART поверх JTAG на Альтере я перед поездкой в конце прошлого года разбираться не стал, так как у меня было мало времени. Но если вы покажете (и особенно если вы сами вставите это на гитхаб), я буду благодарен — https://github.com/MIPSfpga/mipsfpga-plus
nerudo
Если делать переносимое решение (и Altera и Xilinx), тогда не удобно. Если только под альтеру, то у них есть готовый компонент JTAG UART (на шину AvalonMM) к которому приделывается простенький мастер берущий данные из регистров. Со стороны компьютера можно пользоваться имеющимся альтеровским терминалом для засылки данных.
Вообще с этими проводами беда. На каждый чих ставится по собственному мосту usb-uart и количество проводов стремительно растет. А уж если соединять несколько плат… В самую пору ставить usb hub стандартно на всех платах и от него уже тянуть интерфейсы куда надо ;)
YuriPanchul
Спасибо.
Со стороны компьютера можно пользоваться имеющимся альтеровским терминалом для засылки данных.
А можно ли без альтеровского терминала? Чисто "type filename COMnn" в командной строке Windows (cp на tty в Linux) ?
nerudo
Насколько я знаю нет. У них есть библиотека (.dll), которую с некоторыми мучениями можно прикрутить к своему приложению, но драйвера в чистом виде нету. Разве что самому придумывать какую приблуду с перенаправлением в виртуальный порт.
ishevchuk
Есть такая вещь как http://www.alterawiki.com/wiki/System_Console.
Если вставить в Qsys модуль "JTAG to Avalon Master Bridge", а затем написать tcl-cкрипты, которые дергают функции вида master_write/read_8/16/32, то можно писать/читать в FPGA через USB-Blaster (который в Вашем случае уже находится на плате). Дергание функций происходит "через" квартусовские программы, поэтому какого-то быстродействия не будет, но для отладки может сойти.
Так же есть In-System Memory Content Editor, который, как понятно из названия, позволяет редактировать значения памяти (указанных до компиляции FPGA, естественно) в реал-тайме через JTAG/USB-Blaster.
Если честно, не очень понял мотивацию делать парсер текста в FPGA, когда можно было бы эту задачу переложить на компьютер, с которого шьется эта прошивка (сделать скрипт/утилиту, который конвертит текст в бинарник).
nerudo
Ну это уж для совсем эстетствующих ;) Тут ведь желание обратное — отвязаться от альтеровской инфраструктуры.
YuriPanchul
Спасибо за информацию.
Мотивация крайне простая: до поездки в Россию я представлял, что в 9 местах будет потенциально зоопарк из пары сотен компьютеров с разными версиями Windows (7, 8, 10, 32-битным, 64-битным) и Линукса (32-битным, 64-битным), административными опциями, версиями всяких перлов, динамических библиотек и т.д. Так как у меня не было возможности воспроизвести это в Калифорнии и так как я намучался до этого с зоопарками машин в других ситуациях, я решил минимизировать риск переносом всего в хардвер (чтобы на компьютере делалась ровно одна операция — копирование текста в com-порт). Для меня написать 250 строк на верилоге проще, чем собрать в одном месте все возможные платформы для тестирования. И даже если делать бинарник на компьютере, его все равно нужно как-то распихать по памяти синтезированной системы.
Вообще если вы можете взять мой код на гитхабе и показать, как сделать это проще и чтобы работало на всех платформах, было бы хорошо.