
Google заменил начинающим программистам книги и справочники: в самом деле, почти любой вопрос кто-то уже решил до вас, остается только найти решение. Интересно другое: пользуются ли опытные программисты только своим опытом или предпочитают гуглить наравне с начинающими?
Гуглить не зазорно
Chris пишет в статье «How Much Does an Experienced Programmer Use Google»:
Я часто слышу, как начинающие программисты, нервно озираясь по сторонам, спрашивают: «Это нормально, если я часто пользуюсь Google?».
Ответ на этот вопрос — решительное да.
Google — неотъемлемая часть работы каждого разработчика. Люди, работа которых состоит из умственных усилий, называются работниками умственного труда, и установлено, что они тратят 40% их времени на поиск информации. Иными словами, почти половина вашей работы в качестве разработчика — умение пользоваться Google.
IDC в своем исследовании «The High Cost of Not Finding Information» (PDF) придерживается похожей оценки:
Мы используем общую оценку: типичный работник умственного труда тратит около 2,5 часов в день или примерно 30% от рабочего дня на поиск информации.
Кто владеет информацией, владеет миром. В случае с разработчиками — владеет решением.
Из статьи «Do Experienced Programmers Use Google Frequently?» Umer Mansoor:
«Часто ли опытные программисты пользуются Google?»
Громкий ответ — ДА, опытные и хорошие программисты используют Google… часто. На самом деле даже чаще начинающих.
Большая причина использовать Google в том, что сложно запомнить все мелкие детали и нюансы, особенно если вы программируете на нескольких языках и используете кучу фреймворков.
Синдром самозванца
Люди, подверженные синдрому самозванца, уверены в том, что они обманщики и не заслуживают успеха, которого достигли. Синдром самозванца ортогонален эффекту Даннинга — Крюгера: квалифицированные специалисты склонны занижать свои способности, в то время как низкоквалифицированные имеют завышенные представления.
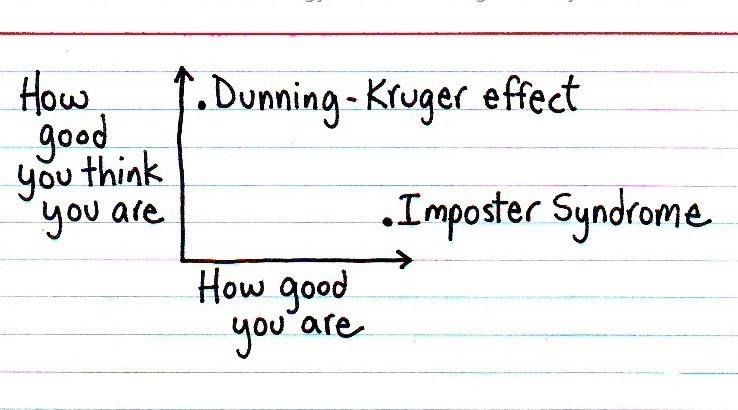
Иллюстрация из статьи «The Imposter Syndrome in Software Development»
Для программистов это часто выражается в рефлексии: «программист ли я, или просто хорошо гуглю?».
Scott Hanselman в статье «Am I really a developer or just a good googler?» пишет об этом:
Недавно я получил очень серьезное и хорошо сформулированное письмо от молодого человека за рубежом. Вот что он пишет:
«Иногда в моей голове звучит вопрос — действительно ли я разработчик или просто хорошо гуглю. Я не знаю правильного ответа — я гуглер или разработчик. Скотт, пожалуйста, помоги мне выяснить».
В другой статье «I'm a phony. Are you?» он пишет, что большинство программистов подвержено синдрому самозванца — в том числе и он сам. И вот что он считает по этому поводу:
Но вот в чем дело. Мы все иногда чувствуем себя обманщиками. Мы все обманщики. Это часть роста. Мы попадаем в ситуации, которые немного сложнее того, с чем мы можем справиться. Но мы справляемся с ними, мы не обманщики, и мы двигаемся к следующему испытанию.
Разница между начинающим и опытным
Мы выяснили: гуглят все. Разница в том, как.
«How Much Does an Experienced Programmer Use Google»:
Помимо этого, хорошие программисты знают, что они не первые, кто столкнулся с проблемой. Они используют Google для поиска возможных решений, аккуратно проверяют результат и отделяют зерна от плевел; они не слепо следуют или копипастят любое найденное решение.
Призываем уважаемых комментаторов: как Google помогает вам в работе? Считаете ли, что гуглить зазорно, и лучше пойти прочесть пару книг? Рассказывайте.
Комментарии (150)

cranium256
20.05.2016 17:01+9Применительно к статье, интернет можно считать (с определёнными оговорками) аналогом библиотеки. И, слава Гуглу и иже с ним, что поиск информации занимает минуты и часы, а не дни и недели.
С другой стороны, использование готовых решений из интернета не отменяет чтение книг. Чтение книг создаёт базу, а «готовые решения» — это для конкретной проблемы. Причём часто без базы невозможно подобрать или адаптировать «готовое решение» под конкретную проблему. И беда многих начинающих программистов, что они этого не понимают.
splatt
20.05.2016 17:12+26Я программирую вот уже почти 10 лет, и я признаюсь вам честно — за все это время я не дочитал ни одной книги по программированию. Я просто начинаю засыпать, когда читаю их, и усвоение материала начинает стремиться к нулю. В результате начинаешь просто пролистывать и искать то, что тебе более интересно и понятно. Мне кажется, это личное предпочтение. Лично мне вот не нравится сам формат книги, но я с удовольствем посмотрю видеоуроки и полистаю официальную документацию, что бы «включиться» в новый фреймворк или технологию. Для меня это тоже самое, что и книга, но гораздо быстрее. Ну и да — никакая книга не заменит вам практику, технику «просто возьми и начинай что-то делать (тестовый проект, todo list, итд), решая задачи по мере поступления».

AllexIn
21.05.2016 13:21+8Я тоже жил с таким подходом и добился определенного результата.
Но книги дают систематические знания. А практика дает знания отрывочные.
С систематическими знаниями можно решать задачи быстро и эффективно, а с отрывочными — просто решать. А скорость и эффективность — дело случая.
Можно сколько угодно много рассказывать о простоте и эффективности самообучения, но истина проста: систематическое обучение это другое и никакое самообуение не может его на 100% заменить.
Я лично перестал себя обманывать и стал больше времени уделять систематическим и структурированным источникам знаний. Чего и вам желаю.

eugzol
21.05.2016 20:22Сканирование оглавлений очень нахожу для себя полезным. В пару глав заглянуть глубоко, несколько бегло просмотреть, для остальных узнать лишь заголовок. Систематизирует знания весьма неплохо.
splatt
20.05.2016 17:06+15Сегодня в любой отрасли разработки умение пользоваться гуглом — это, на мой взгляд, один из ключевых навыков программирования. Конечно, когда я говорю «пользоваться гуглом», это значит не просто уметь слепо копи-пастить код со stackoverflow, а умение находить решения и адекватно применять их в своем проекте.
Именно поэтому лично я считаю идиотизмом задачи на собеседованиях вроде «а сбалансируйте-ка бинарное дерево». Недавно было такое собеседование, на мой вопрос «разрешается ли пользоваться гуглом», ответили «мы хотим проверить ваши навыки программирования, а не навыки пользоваться гуглом». Так и хотелось спросить, не запрещено ли у них случаем пользоваться гуглом в рабочее время, а то может быть, не стоит тратить время.
Как по мне, так гораздо более адекватно сегодня давать задачи более сложные (те, на которые невозможно найти ответ в гугле за 30 секунд поиска), но с возможностью пользоваться любыми источниками — такие задачи гораздо ближе к реальности, чем эфемерные «изобретите алгоритм, который точно кто-то уже изобрел до вас».kylt_lichnosti
23.05.2016 11:26+1Дерево то сбалансировали?
Это на какую должность такое спрашивают? Что за язык? А то у меня синдром самозванца начинает развиваться…splatt
23.05.2016 16:29+1Дерево не сбалансировал. Вакансия была — веб-разработчик на Python.
Сейчас работаю в компании, в которой на собеседовании не задали ни одного технического вопроса, зато предложили обсудить мои предыдущие проекты, самые трудные задачи, с которыми я сталкивался, как я их решил тогда и что бы я изменил в их решении сегодня.
Таких собеседований, к счастью, тоже было достаточно.
Собсеседования с вопросами из серии «вспомни первый курс по алгоритмам», были, но бинарные деревья были один раз. В основном задавали вопросы про всякие linked-list'ы, там все гораздо проще, если помнишь хоть что-нибудь.khim
23.05.2016 17:32В основном задавали вопросы про всякие linked-list'ы, там все гораздо проще, если помнишь хоть что-нибудь.
И тем не менее простейший вопрос типа «посчитайте количество элементов в бесконечном односвязном списке» ставит огромный процент претендентов в тупик.
Wesha
23.05.2016 18:39посчитайте количество элементов в бесконечном односвязном списке
Нормальный претендент в ответ на такой вопрос напишет единственную строчку:
return(INFINITY).
Потому что человек с программистким мышлением требует точной постановки задачи. В условии сказано: бесконечный — значит, размер равен бесконечности. Если Вы имели в виду "стопицот" — то это не "бесконечный", а "не помещающийся в памяти", и так и надо писать при постановке задачи; программист не играет в угадайку "а что постановщик вообще этим сказать хотел".
khim
23.05.2016 20:40Потому что человек с программистким мышлением требует точной постановки задачи.
Вы уж извините, но постановка задачи как раз вполне себе чёткая.
В условии сказано: бесконечный — значит, размер равен бесконечности.
Если сказано бесконечный, то это значит, что это списка без конца (по английски используется слово endless, что несколько упрощает задачу, но идея та же). А дальше — да, небольшой тест на разумность: хороший кандидат поймёт, что имелось в виду сразу или переспросит, а плохой да, напишетreturn(INFINITY).
Если Вы имели в виду «стопицот» — то это не «бесконечный», а «не помещающийся в памяти», и так и надо писать при постановке задачи; программист не играет в угадайку «а что постановщик вообще этим сказать хотел».
Мы как бы говорим не об аутсорсе, а о приёме человека в штат. Если человек не готов додумывать, задавать вопросы в случае непонимания условия задачи, и требует, чтобы ему всё разжевали и в рот положили — то он нам, извините, не нужен: с подобными задачами отлично справляются условные «индусы» на аутсорсе, которые стоят гораздо, гораздо, дешевле.
P.S. Про «постановку в тупик» — я имел в виду, конечно, неумение написать код. Понятно, чтоreturn(INFINITY)— это клиника, но большинство кандидатов, даже поняв — что именно от них хотят неспособны это сделать.Wesha
23.05.2016 21:37+1Если сказано бесконечный, то это значит, что это списка без конца (по английски используется слово endless, что несколько упрощает задачу, но идея та же)
"endless" — это в данном случае не "бесконечный", а "неограниченный". Переводчики такие переводчики.
Если человек не готов додумывать
Вот в этом-то и проблема: у большинства нанимателей почему-то не возникает даже и намёка на мысль о том, что разные люди могут думать по-разному, и воспринимать Ваше задание по-разному. Попытки "додумать" при этом могут привести к весьма плачевным результатам. Тут в соседнем треде кто-то "додумал", что при нечисловых данных на входе программа должна падать — "а чо, всё равно ничего сделать нельзя" — а если, утрируя, эта программа управляет реактором на АЭС?
Например, я в упор не понимаю Вашу задачу. "Посчитать количество слов" в неограниченном списке невозможно: если критерий останова есть, то список не является неограниченным, и наоборот, если критерия останова нет, то
return(INFINITY)является правильным ответом. Вы явно имеете в виду что-то другое, но — как собака: "знать-то знаю, но выговорить не могу".khim
23.05.2016 22:29Например, я в упор не понимаю Вашу задачу. «Посчитать количество слов» в неограниченном списке невозможно: если критерий останова есть, то список не является неограниченным, и наоборот, если критерия останова нет, то return(INFINITY) является правильным ответом. Вы явно имеете в виду что-то другое, но — как собака: «знать-то знаю, но выговорить не могу».
Это у Вас какой-то заскок. Бывает. При очном собеседовании всегда переспросить можно, а на Хабре понять малость сложнее.
Отсутствие конца в списке не обозначает, что элементов в нём бесконечное число. Тут вроде про python говорили, так что пусть пример будет на питоне:
Теперь у нас в переменной>>> a = [1, [2, [3, []]]] >>> a[1][1][1] = a[1]aсписок «без конца»:
Однако: ходить-то вы по этому списку можете сколько угодно, но элементов-то там больше не стало! Их там по прежлему три!>>> a[0] 1 >>> a[1][0] 2 >>> a[1][1][0] 3 >>> a[1][1][1][0] 2 >>> a[1][1][1][1][0] 3 >>> a[1][1][1][1][1][0] 2 >>> a[1][1][1][1][1][1][0] 3 >>> a[1][1][1][1][1][1][1][0] 2 >>> a[1][1][1][1][1][1][1][1][0] 3
Вот я и хочу, чтобы мне написали функцию, которая выдавала бы это число, оценили бы сложность (как зависит время работы вашей фукнции от размера списка?) и т.п. Элементарная, в общем-то, задача, но народ путается.Wesha
23.05.2016 23:17+3Дело в том, что для того, чтобы взять поток мысли, выдаваемый клиентом, и перевести его в однозначную формулировку, понятную программисту (software developer), предназначен специальный человек — software consultant. И платят ему, мягко говоря, несколько больше, чем программисту, потому что работа очень нервная — целый день с идиотами общаться.
(Иногда software developer и software consultant совмещаются в одном человеке — мне, например, но это далеко не всегда так ;)
Ваша задача по-
человеческипрограммистски будет звучать так:
Дан однонаправленный связный список (
a[i].next = a[j]) из конечного числа элементовL, при этом известно, что он зациклен (т.е.a[y].next = a[x]при некоторых неизвестныхxиy, таких, чтоx < y). ОпределитьL.
А есть ещё следующая ступень — software archaeologist: это когда есть куча кода без комментариев и документации, и надо понять, что эта куча делает, и почему она написана именно таким, а не иным образом. Это уже ещё более другие деньги.
khim
23.05.2016 23:47Дело в том, что для того, чтобы взять поток мысли, выдаваемый клиентом, и перевести его в однозначную формулировку, понятную программисту (software developer), предназначен специальный человек — software consultant. И платят ему, мягко говоря, несколько больше, чем программисту, потому что работа очень нервная — целый день с идиотами общаться.
Опять оказывается, что мы говорим «мимо» друг друга. «Клиенты» и «потоки мысли» существуют только в одном из миров (Консультационное ПО), во всех остальных програмист ну никак не может получить готовую формулировку, потому что важная часть его работы — это разработка требований и сочетание «хотелок» и «возможностей».
А ваша «человеческая» формулировка — невероятно узка. Можно же ведь переформулировать и так: «найти количество разных чисел, которые выдаст функция erand48 при заданном «зерне»» — ведь это та же самая задача, не так ли?
Но породить формулировку — это, как я уже заметил, полдела: да, совсем плохие кандидаты и на это не способны, но это позволяет отсеять только лишь небольшой процент. В любом случае: придумав точную формулировку нужно ведь потом эту задачу ещё и решить — и вот тут-то оказывается как-то, что мастера «Google-oriented programming»а на это зачастую неспособны.Wesha
23.05.2016 23:55+1вот тут-то оказывается как-то, что мастера «Google-oriented programming»а на это зачастую неспособны.
«найти количество разных чисел, которые выдаст функция erand48 при заданном «зерне»»
Это другая задача (Мне почему-то кажется, что это количество одинаково вне зависимости от зерна и ограничено разрядностью используемых чисел, но я могу ошибаться).
khim
24.05.2016 00:35Моё гугл-фу сильнее твоего ;)
Ну да — это половина решения. Но это всё-таки классическая задача, на практике всё-таки приходится придумывать «алгоритм похожий вон на то», а не просто copy-paste делать.
Это другая задача (Мне почему-то кажется, что это количество одинаково вне зависимости от зерна и ограничено разрядностью используемых чисел, но я могу ошибаться).
Вы имеете в виду, что генератор всегда обходит все 248 чисел? Это, конечно, хорошее замечание, но это ведь не мешает вам написать функцию и проверить — действительно ли это так? Это ведь верно только для линейно-конгруэнтного метода (и то не всегда). А для других PRNG количество чисел вполне может зависеть от зерна.Wesha
24.05.2016 01:57+1Видите ли, мало поставить задачу, нужны ещё и граничные условия. Например — где у нас ограничение: по памяти или по процессору? В случае с массивом в памяти решение одно, а в Вашем втором примере (про
res = erand48(res)), возможно, имеет смысл кешировать возвращаемые подопытной функцией результаты, чтобы два раза невставатьвызыватьerand48(x)(один раз — для "быстрого" указателя, второй — для "медленного"). Предлагаемые решения могут сиииильно отличаться в зависимости от.khim
24.05.2016 02:31В случае с массивом в памяти решение одно
Это кто ж вам сказал, что «в случае с массивом решение одно»? Во-первых не с массивом, а со списком, а во-вторых обращение в память — это тоже, в общем-то, недёшево. И вполне может оказаться, что кеширование окажется небесполезно.
Мы как раз обход одной структуры в памяти пару недель назад оптимизировали с помощью введения нескольких кешей и обсуждали — сколько этих кешей нужно, когда их заводить и т.п., так что это не просто теоретические рассуждения (правда структура была чуть-чуть посложнее вышеописанного списка).
Предлагаемые решения могут сиииильно отличаться в зависимости от.
Ну дык. Собственно в этом и заключается специфика работы не в области Консультационное ПО: когда у тебя нет чётких, заранее обговоренных криетериев «приёмки», то очень часто постановка задачи меняется в зависимости от того, что показывают эксперименты с той или иной реализацией. Так что выявлять «граничные условия» приходится, собственно, тому, кто решает задачу.
И да, все эти вещи обсудить с хорошим кандидатом тоже не грех… после того, как он напишет хоть какую-нибудь реализацию, конечно.Wesha
24.05.2016 02:51Во-первых не с массивом, а со списком,
Под "массивом" я подразумеваю структуру данных, имеющую интерфейсный метод
[], то есть допускающую доступ по индексу — а Ваш список это допускает: даже если для этого требуется вернуться к корню и добежать при помощи.nextдо нужного элемента — всё равно это возможно, а детали реализации нас в данный момент не интересуют. (И не надо мне тыкать на википедийное "набор компонентов, расположенных в памяти непосредственно друг за другом", а то я Вам припомню про отображение виртуальных страниц на физическое ОЗУ и файл подкачки ;)
А мой "бесконечный список" из
/dev/randтакого интерфейса не имеет иметь не может ;)khim
24.05.2016 03:29А мой «бесконечный список» из /dev/rand такого интерфейса не имеет иметь не может ;)
То есть списком и не является.
А вот списк erand48 таки списком является и «интерфейсный метод[]» он, разумеется, поддерживает.
(И не надо мне тыкать на википедийное «набор компонентов, расположенных в памяти непосредственно друг за другом», а то я Вам припомню про отображение виртуальных страниц на физическое ОЗУ и файл подкачки ;)
Припомните, почему нет. А заодно объясните — как именно всё это делает среднее время доступа по индексу зависящим от индекса для массива или не зависящим — для списка (это ведь практически самое важное различие между ними).Wesha
24.05.2016 03:37+1Мы с Вами просто опять говорим на разных языках. Я же сказал:
Под "массивом" я подразумеваю структуру данных, имеющую интерфейсный метод []
Всё. Про время доступа я ничего не говорил. Ваше определение "массива" отличается от него, всего-то делов. Бывает.
khim
24.05.2016 03:58Ваше определение «массива» отличается от него
Это не «моё определение». Это как раз то самое «википедийное» определение. На русской википедии:одинаковое время доступа ко всем элементам
На английской:Both store and select take (deterministic worst case) constant time
.
всего-то делов.
И действительно: когда задача на собеседовании определяется в неформальных терминах, то это ужас, это качмар, это небо падает на землю, когда одно из фундаментальных понятий Computer Scrience придаётся извращённый смысл — то это «всего-то делов».
Хороший подход. Объективный такой. Мне нравится.
grossws
24.05.2016 04:13Стоит заметить, что в русской вики определение получается некорректное в отличии от английской, где рассматривается determenistic worst case time.
Пример: доступ к элементу массива, находящемуся в той же кэш-линии, что и предыдущий использовавшийся элемент, и доступ к элементу, отсутствующему в кэше соответствующего уровня, осуществляется за разное время.
Wesha
24.05.2016 04:23+1одинаковое время доступа ко всем элементам
"Одинаковое время доступа" — это "достоинство" (Вы заголовки секций, на которые ссылаетесь, хоть читаете?), а не часть определения; а про то, что "одинаковое" оно преимущественно в теории — можно долго спорить (с учётом того, что искомая область памяти может оказаться высвопленной в файл подкачки).
одно из фундаментальных понятий Computer Scrience придаётся извращённый смысл
Извращённый смысл ему придан десятилетиями виртуализации. В наше время массив — это "структура данных, предоставляющая доступ к своим элементам по целочисленному индексу". Всё. Как оно хранится, как оно работает — это всё детали реализации. Это может быть обычный сишный массив —
*(base + sizeof(element) * index), это может быть memory mapped file, это может быть sparse array, это может быть всё, что угодно; если возможен доступarr[i]для любогоi— то для целей дискуссии за пивом, каковую мы с Вами тут имеем, это "массив". Dixi.

0xd34df00d
24.05.2016 04:56А вот списк erand48 таки списком является и «интерфейсный метод []» он, разумеется, поддерживает.
А кто мешает добавить такой метод в список as by Wesha?khim
24.05.2016 11:18Тот факт, что в «списке» на основе
/dev/rand
каждый элемент может быть прочитан лишь один раз.
0xd34df00d
24.05.2016 01:46У меня какой-то хаскель от вашего питона.
Сколько элементов в списке
Prelude> :t repeat repeat :: a -> [a] Prelude> take 10 $ repeat 1 [1,1,1,1,1,1,1,1,1,1]
?
Сколько элементов в списке
Prelude> let meh = 1 : meh Prelude> take 10 meh [1,1,1,1,1,1,1,1,1,1]
?
А сколько элементов в
Prelude> let fibs = 0 : 1 : zipWith (+) fibs (tail fibs) Prelude> take 10 fibs [0,1,1,2,3,5,8,13,21,34]
?
0xd34df00d
24.05.2016 01:42«endless» — это в данном случае не «бесконечный», а «неограниченный». Переводчики такие переводчики.
Я бы неограниченные вещи называл Unbounded. Endless в этом контексте ни разу не приходилось слышать.
Но такая задача меня тоже ставит в тупик.khim
24.05.2016 02:05В данном случае речь идёт не об «unbounded», а именно об «endless», но «bounded».
Ту же самую задачу можно хоть на Бейсике переписать и решить — суть-то не в синтаксисе.
Умение красиво рассказывать про ленивые вычисления в Хаскеле (где действительно бывают структуры, о размере которых нельзя говорить) не заменяет умение работать со структурами данных.
P.S. Можно, конечно, нарваться на условного «Нильса Бора», который всё знает и понимает, но не хочет отвечать потому, что его это всё достало и отсеять его — но так ли это страшно? Это ведь всего лишь обозначает, что этот самый условный «Бор» не очень-то и хочет работать конкретно у вас и вместо того, чтобы просто забрать CV вот так вот выкаблучивается — ну дык стоит ли тогда пытаться его силой затаскивать, если его душа реально чего-то другого хочет?0xd34df00d
24.05.2016 02:23+3Ту же самую задачу можно хоть на Бейсике переписать и решить — суть-то не в синтаксисе.
А пример ваш питоньий можете на C++ переписать? Мне просто очень интересно, что из этого получится, можно ли это будет называть списком, и так далее.
А скорее всего получится, что классический вопрос о нахождении петли в цикле был бы корректнее.
Умение красиво рассказывать про ленивые вычисления в Хаскеле (где действительно бывают структуры, о размере которых нельзя говорить)
А чем ваш зацикленный список отличается от моего примера сlet ones = 1 : ones? Рантайм точно так же будет вычислять thunk, который ссылается на себя же, который ссылается на себя же, который… А элемент один.
Или бесконечность.
Для меня такой вопрос на собеседовании был бы поводом начать дискуссию о том, что вообще называется списком, что называется его длиной, и так далее.
И если бы мы с вами сошлись на том, что это таки список, то, вполне вероятно, на построенной в ходе дискуссии аксиоматике удалось бы доказать, что и в списке с числами Фибоначчи всего один элемент.
Это ведь всего лишь обозначает, что этот самый условный «Бор» не очень-то и хочет работать конкретно у вас
Я вообще плохо представляю, кем надо быть, чтобы люди хотели не задачки интересные решать, не делать продукты в окрестности специализации вашей фирмы, не деньги зарабатывать, в конце концов, а именно работать у вас.khim
24.05.2016 02:44А пример ваш питоньий можете на C++ переписать?
На C++ будет чуть длиннее, но, в общем, всё то же самое:
struct Node { int value; Node* next; }; int main() { Node *head = new Node{1, new Node{2, new Node{3, nullptr}}}; head->next->next->next = head->next; std::cout << find_len(head) << std::endl; }Мне просто очень интересно, что из этого получится, можно ли это будет называть списком, и так далее.
А почему нет? SICP, упражнение 3.18, к примеру — как раз от таких говорит.
И если бы мы с вами сошлись на том, что это таки список, то, вполне вероятно, на построенной в ходе дискуссии аксиоматике удалось бы доказать, что и в списке с числами Фибоначчи всего один элемент.
Это — вряд ли. Там всё таки все элементы разные :-) Ну, почти.
Я вообще плохо представляю, кем надо быть, чтобы люди хотели не задачки интересные решать, не делать продукты в окрестности специализации вашей фирмы, не деньги зарабатывать, в конце концов, а именно работать у вас.
Работодателем. Собственно любой работодатель смотрит, в том числе, и на то, насколько кандидат заинтересован в том, чтобы устроиться к нему на работу.Wesha
24.05.2016 02:57+1Собственно любой работодатель смотрит, в том числе, и на то, насколько кандидат заинтересован в том, чтобы устроиться к нему на работу.
"Это было давно и неправда" ©. Последние лет так десять в нашей отрасли кандидаты смотрят на то, насколько работодатель заинтересован, в том, чтобы кандидат работал именно на него. Просыпайтесь.
khim
24.05.2016 03:45Последние лет так десять в нашей отрасли кандидаты смотрят на то, насколько работодатель заинтересован, в том, чтобы кандидат работал именно на него.
Ну дык. Финальная стадия пузыря, чего вы хотите.
А статья смешная, да. Достойна того, чтобы занять на полке место рядом с пресловутым Концом истории. Будет смотреться также смешно лет так через 10.
Одни рассказ про то, что ошибки, которые стоят, в буквальном смысле слова, сотни миллиардов долларов (Space Shuttle, ТУ-144) это ерунда по сравнению с тем, какой ужас способны устроить программисты — уже смешон. А уж выводы.
А правда заключается в том, что в любой отрасли есть люди, которые очень дорого стоят и за «головы» которых идёт настоящая охота.
Но к рядовым разработчикам это ни в одной области не относится — и IT исключением не является.Wesha
24.05.2016 03:52А правда заключается в том, что в любой отрасли есть люди, которые очень дорого стоят и за «головы» которых идёт настоящая охота.
;)
0xd34df00d
24.05.2016 05:04+4На C++ будет чуть длиннее, но, в общем, всё то же самое:
Не то же, принципиально не то. Не менее принципиальный вопрос вам на засыпку: какой тип элемента списка в вашем плюсовом коде?
Какой тип элемента списка в вашем питоньем коде?
Какой тип элемента в моём хаскель-коде?
Это — вряд ли. Там всё таки все элементы разные :-) Ну, почти.
Не более разные, чем в первых двух вариантах, где одни единички получаются, разве нет?
Собственно любой работодатель смотрит, в том числе, и на то, насколько кандидат заинтересован в том, чтобы устроиться к нему на работу.
Это какой-то оборзевший работодатель, наверное, ещё тимбилдинги с планкингом каждое утро устраивает.
Любому™ адекватному™ работодателю понятно, что мне, в общем-то, куда интереснее решать интересные задачи, желательно за интересные деньги, нежели чем испытывать благоговение от самого факта работы на Гундекс/Майкругл/етц.
Если работодателю это непонятно (равно как и мне непонятно, что самое важное для работодателя в тырпрайз-разработке — добавленная мной стоимость, а не то, насколько я хорошо понимаю монадки и способен ли рассуждать об аспектно-ориентированном проектировании в терминах кодекартовых квадратов в какой-то там категории), то нам с ним, вероятно, не по пути, и лучше, чтобы это выяснилось пораньше.khim
24.05.2016 11:27Не менее принципиальный вопрос вам на засыпку: какой тип элемента списка в вашем плюсовом коде?
Причём тут «тип элемента»? От этого у вас алгоритм изменится?
Не более разные, чем в первых двух вариантах, где одни единички получаются, разве нет?
«Более разные». В случае с однонаправленным списком (пусть он хоть на камешках реализован с мальчиками, бегающими по острову) мы можем гарантировать, что элементов там — конечное число и, главное, можем на них ссылаться и сравнивать.
В случае с Haskel-струкртурами ни того, ни другого делать нельзя.
Любому™ адекватному™ работодателю понятно, что мне, в общем-то, куда интереснее решать интересные задачи, желательно за интересные деньги, нежели чем испытывать благоговение от самого факта работы на Гундекс/Майкругл/етц.
Ну если вы так считаете — то значит вы к нам и не придёте, проблем-то.
Никто ведь не гонит вас под дулами автоматов именно в Гундекс/Майкругл/етц.0xd34df00d
24.05.2016 17:08Причём тут «тип элемента»? От этого у вас алгоритм изменится?
Алгоритм нахождения петли у меня не изменится, даже если там будетvoid*.
Однако, судя по русской википедии, вариант на питоне уже списком не будет:
Тип элементов — тот самый тип A, над которым строится список; все элементы в списке должны быть этого типа.
В случае с однонаправленным списком (пусть он хоть на камешках реализован с мальчиками, бегающими по острову) мы можем гарантировать, что элементов там — конечное число
Я запутался, как вы определяете число элементов?
Wesha
24.05.2016 02:06+2"Бесконечный" в математическом смысле — это infinite ("бесконечное множество" — infinite set). "Зацикленный" — looped.
Дело в том, что бесконечный незацикленный односвязный список вполне возможен — например,
while(1) { fread(fopen('/dev/rand', 'rb'), 1); }. То, про что пишет автор — это конечный зацикленный односвязный список.0xd34df00d
24.05.2016 02:14Я у вас тут в упор не вижу списка, извините.
Либо, если немножко послабить требования и назвать это списком, то список вполне себе зацикленный там, где указано, как перейти к следующему элементу.Да и вообще, вот же цикл while!Wesha
24.05.2016 02:18Ну как где, берёте значение, которое вернул
fread, и складываете его куда хотите — вот Вам и список, и продолжаться он может до тепловой смертиВселеннойкомпьютера.0xd34df00d
24.05.2016 02:25+2На собеседовании к этому времени я бы уже напрочь запутался в терминологии и полюбопытствовал бы, часто ли в фирме возникают задачи, требующие умения различать бесконечные незацикленные списки от конечных зацикленных.
khim
24.05.2016 02:50А вы что — собираетесь в будущем решать только задачи, которые встречаются часто? А кто будет решать задачи, которые встречаются редко?
А что касается зацикленных списков — не знаю что такое «бесконечный зацикленный список», но структуру сводяющуюся примерно к описанным «спискам с циклами» я разбирал примерно месяц назад. Там, правда, списков могло быть много, цикл мог быть не один и они ещё и переплетены могли быть… но это — уже детали же, согласитесь?0xd34df00d
24.05.2016 05:09+2Я собираюсь решать неэзотерические задачи. Эзотерические задачи я собираюсь решать за обедом с коллегами в качестве полезной разминки для мозгов, но я ведь нанимаюсь не команду в обед развлекать, поэтому логичнее спрашивать меня что-то более релевантное, не правда ли?
А что детали — это да. Поэтому и стоит быть готовым к тому, что кандидат вам не поймёт, а когда вы дадите ему наводящий пример на питоне, выдаст вам чего-нибудь на хаскеле, и начнёт с вами обсуждать это всё, ну, в том духе, что мы тут втроём обсуждаем. И это, наверное, даже хорошо, потому что такой человек таки с большей вероятностью осилит пустить два итератора по списку, или чего там в питоне с этим делать.khim
24.05.2016 11:33Поэтому и стоит быть готовым к тому, что кандидат вам не поймёт, а когда вы дадите ему наводящий пример на питоне, выдаст вам чего-нибудь на хаскеле, и начнёт с вами обсуждать это всё, ну, в том духе, что мы тут втроём обсуждаем.
Очень чувствуется отсутствие практического опыта проведения интервью, извините.
Вы проведите пару сотен интервью для начала, а потом начинайте рассуждать о том, что может случиться и когда. «Чего-нибудь на Хаскеле» выдаёт, дай бог, один кандидат из сотни (после чего его на работу, как мы знаем не берут — что и правильно, так как подобные ответы обозначают, что работа его интересует меньше, чем желание выпендрится), а написать хоть что-то вообще может, дай бог, один кандидат из трёх (если не один кандидат из десяти).
И это, наверное, даже хорошо, потому что такой человек таки с большей вероятностью осилит пустить два итератора по списку, или чего там в питоне с этим делать.
Ну вот если он это на интервью сделает — молодец, получит ещё пару вопросов, а затем и предложение о работе. Если нет… ну это его выбор, в конце-то концов.
khim
24.05.2016 11:48Эзотерические задачи я собираюсь решать за обедом с коллегами в качестве полезной разминки для мозгов, но я ведь нанимаюсь не команду в обед развлекать, поэтому логичнее спрашивать меня что-то более релевантное, не правда ли?
Да, в общем, почти всё равно что спрашивать — важно увидеть как кандидат год писать будет.
Почему вдруг типичная задача из типичного курса по структурам данным вдруг стала «эзотерической» — мне, в общем, неведомо, но если кандидат код не напишет, то резулюция «No Hire» следует, в общем, независимо от того не умеет кандидат это делать или не хочет: вы ведь нанимаетесь чтобы «решать задачи», как вы сами написали, а не «объяснять почему конкретно вы конкретную задачу решать не будете».
Специалистов по последнему, как показывает практика, гораздо больше — но они мало кому нужны.0xd34df00d
24.05.2016 17:09Ну не типичная же она!
Это скорее какая-то игра в угадайку, что именно имел в виду интервьювер.khim
24.05.2016 17:20Вы имеете в виду использование нестандартных терминов и прочее? Вот как ни странно это проблемой редко когда является.
Несколько дополнительных вопросов, пара картинок — и, если кандидат хоть какой-то опыт имеет, формулировка в стиле Wesha — готова.
А вот написание кода для большинства кандидатов — проблема. Ещё какая. Примерно как в широко известно опусе.
Может быть вам действительно везло с кандидатами.
khim
24.05.2016 03:00Нет, так не получится. Это всего лишь последовательность. В односвязном списке должна быть возможность во-первых как-то запомнить элемент, во-вторых их как-то сравнить, а в-третьих перейти от элемента к следующему. В двусвязном нужно уметь ещё и перейти к предыдущему элементу.
Поэтому edrand48 — это вполне себе односвязный список, а вот drand48 — уже нет (можно долго и упорно спорить является ли пара drand48/seed48 списком, впрочем...).0xd34df00d
24.05.2016 05:14+1В односвязном списке должна быть возможность во-первых как-то запомнить элемент, во-вторых их как-то сравнить
И тут я снова врываюсь со своим хаскелем…
Одного взгляда на сигнатуру repeat
Prelude> :t repeat repeat :: a -> [a]
достаточно, чтобы понять, что эта штука возвращает либо пустой список, либо бесконечное повторение переданного элемента, потому что больше никакой информации о типе нет вообще. Даже не факт, что элементы в получаемом списке сравнивать можно. «Запоминать» в контексте хаскеля ещё меньше смысла имеет (если вы имеете ввиду ссылку/указатель).
Тем не менее, эта штукенция возвращает вполне себе односвязный список.
Либо я вас не так понял.
К слову, вот если бы у вас было больше информации о типах, например,
Prelude> :t enumFrom enumFrom :: Enum a => a -> [a]
то уже всё куда интереснее:
Prelude> take 10 $ enumFrom 0 [0,1,2,3,4,5,6,7,8,9] Prelude> take 10 $ enumFrom 'a' "abcdefghij"khim
24.05.2016 11:41«Запоминать» в контексте хаскеля ещё меньше смысла имеет (если вы имеете ввиду ссылку/указатель).
«Запоминать» в конексте Хаскеля можно, конечно. Позицию в erand48 запомнить можно, а в «списке»/dev/rand(который, напоминаю, получает энтропию от аппаратных источников) — нельзя. И это фундаментальная разница с которой никакой, самый модный, язык ничего поделать не сможет.
Одного взгляда на сигнатуру repeat
Не очень понятно как программа может бросить этот «один взгляд» получив объект. Хотя, может, через интроспекцию в каких-то реализациях?
В любом случае: либо вы можете предложить как это программно понять и тогда у списка естественным образом появится длина, либо не сможете — и тогда это не список.
mayorovp
24.05.2016 13:53+3@khim, Wesha, 0xd34df00d
Вы сейчас спорите об определениях, причем выдумывая их на ходу.
В контексте структур данных, список (более корректно, связный список) — это класс структур данных, основанных на идее хранения последовательности путем добавления к элементам указателей на соседей. Такие списки могут быть односвязными и многосвязными, плотными и разреженными, с заголовком и без него.
А еще они могут быть циклическими и обычными (и я ни разу до этого для не слышал чтобы обычный циклический список называли бесконечным). Разумеется, у циклических списков есть вполне определенная длина и алгоритмы ее нахождения.
В функциональном программировании, списком называется вполне конкретная структура данных, основанная на идее разбиения последовательности на голову и хвост. Эта структура данных чем-то напоминает обычный односвязный список — но все же отличается. К примеру, обычное и деструктивное получение первого элемента в односвязном списке — это две совершенно разные операции, но для списка в ФП это одно и то же.
Вот эти списки и правда бывают бесконечными — но и длина бесконечного списка также бесконечна. Точнее, она не определена — поскольку невозможно алгоритмически определить, является ли указанный список бесконечным (проблема останова).
В информатике вообще, списком называется любая структура данных, хранящая упорядоченные данные (упорядоченные — значит, что для двух элементов списка можно сказать какой идет первее другого).
Ну и в таких языках программирования как C# и Java, списком (List) называется упорядоченная коллекция, допускающая доступ по целочисленному индексу, причем в Java список — это только интерфейс, а в C# список — это и интерфейс, и его же реализация над массивом (IList<>/List<>).
Массив же — всегда был набором элементов одного типа, последовательно расположенных в адресном пространстве. Разумеется, в тех языках, в которых нет понятия адреса, требование непрерывного расположения элементов становится неактуальным, что приближает массив к списку.
Но массив всегда считался конкретной структурой данных, а не интерфейсом или классом структур данных. (Если кто-нибудь знает языки программирования где массивом считается что-то иное, пожалуйста расскажите о них).
Файл /dev/random, конечно же, не является ни массивом ни списком. Оба этих понятия подразумевают как минимум воспроизводимость результатов.
Наверное, про /dev/random можно сказать "последовательность" — но это понятие также зависит от контекста.
К примеру, многие алгоритмы нахождения наибольшей возрастающей подпоследовательности не смогут работать с /dev/random напрямую.
khim
24.05.2016 14:38Вы сейчас спорите об определениях, причем выдумывая их на ходу.
Вы действительно считаете, что спорящие тут этого не понимают? Да, разумеется, это спор об определениях. Для того он, в частности, и задаётся в такой формулировке — чтобы понять как кандидат будет на это реагировать.
Есть несколько вариантов:
- Кандидат офигивает от формулировки, но, подумав несколько минут, говорит: «вы имеете в виду циклический список и хотите, чтобы я две бегунка пустил?» — и пишет программу.
Вывод: хороший кандидат, скорее всего берём, но, конечно, это зависит от того, как он отвечает на другие вопросы тоже. - Кандидат долго пытается понять, чего от него хотят, через час, с горем пополам, пишет нечто слегка похожее на программу, которая, впрочем, не работает (самый популярный результат).
Вывод: отвратительный кандидат, не берём, говорить не о чем. - Кандидат уходит в спор об определениях, объясняет, что формулировка некорректа и вообще всячески показывает свою эрудированность. Кода в результате нет.
Вывод. Отличный кандат… для наших конкрентов. Не брать.
Всё просто: как я уже сказал: недоговорки и неточные определения — часть производственного процесса. Если кандидат «знает как с этим жить» и может, несмотря ни на что, выдать результат — то это «наш кандидат», с ним будет приятно работать и команда в 1000 человек не будет ждать его из-за того, что поля на техзадании оказались не по ГОСТу. Если кандидат либо не может, либо не хочет в таких условиях работать — нам он не подходит, будь он хоть трижды гений.
Вот и всё.
Это — разумеется, требования которые я применяю к кандидату. Вполне могу предствить себе компанию, где всё по другому и где люди, требующие чётких формурировок, но при этом не отличающие списка от массива будут востребованы. Но это — не у нас.
Если кто-нибудь знает языки программирования где массивом считается что-то иное, пожалуйста расскажите о них.
PHP. Как уже было написано: Этот тип данных ведёт себя как список, упорядоченный хэш, упорядоченный набор, разреженный список и время от времени как их странные комбинации. Какая его эффективность? Каков будет расход памяти?(пер. анализ расхода памяти для массивов) Кто знает? У меня всё равно нет других вариантов.
Ну уже даже JavaScript имеет отдельно массивы и объекты — и массивы ведут себя как массивы, а объекты — как объекты (хотя и используют при это одинаковый синтаксис). Одна есть огромное количество разработчиков, которые понятия не имеют в чём отличие этих структур данных и когда использовать одно, а когда другое. Их вопросы сложности и расхода памяти не заботят вовсе — и, опять-таки: возможно, что существуют компании, которым такие люди подходят.mayorovp
24.05.2016 17:33+2Вы действительно считаете, что спорящие тут этого не понимают? Да, разумеется, это спор об определениях. Для того он, в частности, и задаётся в такой формулировке — чтобы понять как кандидат будет на это реагировать.
Но в таком случае зачем вы тут спорите об определениях? Это ж не собеседование :)
Самых важных слов — о том, что выбранная формулировка является намеренно некорректной, вы и не сказали. Вместо этого вы почему-то начали объяснять что формулировка вполне корректна, на примере связного списка в Питоне. По крайней мере, я, прочитав все ваши комментарии, так и не понял что вы знаете разницу между бесконечным списком и циклическим. Потому-то эту разницу вам и начали объяснять.
Что же до самой идеи задать на собеседовании некорректное задание и посмотреть на реакцию — могу сказать следующее. При общении с заказчиком, ежели кто-нибудь меня до него допустит, я буду помнить, что он совсем не разбирается в программировании, и мне, возможно, придется еще "расшифровывать" его речь. Если я работаю с экспертом — мне надо вообще забыть про "свои" термины и подробно изучать предметную область. При общении с аналитиком я буду помнить, что знание структур данных для аналитика — необязательно, но буду ожидать от него наличие общих знаний по информатике. Но от своего коллеги, пусть даже начальника, я ожидаю корректного использования профессиональных терминов.
Я ожидаю слишком многого?
khim
24.05.2016 17:56Я ожидаю слишком многого?
Ну как вам сказать, чтобы не обидеть…
Senior Software Engineer; Software Archaeologist:
В наше время массив — это «структура данных, предоставляющая доступ к своим элементам по целочисленному индексу». Всё. Как оно хранится, как оно работает — это всё детали реализации. Это может быть обычный сишный массив — *(base + sizeof(element) * index), это может быть memory mapped file, это может быть sparse array, это может быть всё, что угодно; если возможен доступ arr[i] для любого i — то для целей дискуссии за пивом, каковую мы с Вами тут имеем, это «массив».
Такие дела.
А вы говорите «корректное использование профессиональных терминов»…mayorovp
24.05.2016 20:04Если "в наше время" понимать как "в языках программирования, достаточно абстрагированных от железа" — то я с ним даже согласен. Потому что в отсутствии в языке указателей и адресной арифметики само понятие "непрерывной области памяти" полностью теряет смысл.
Wesha
24.05.2016 22:03Я начинал ещё с (прости господи!) фортрана, потом был C, а последние 10 лет работаю на Ruby — который со всякими PHP и питонами начисто заабстрагировал железо чёрт-те куда. (Особенно с учётом того, что даже "железо", на котором мы работаем, на самом деле облачно-виртуальное.)
Wesha
24.05.2016 19:57При общении с заказчиком, ежели кто-нибудь меня до него допустит, я буду помнить, что он совсем не разбирается в программировании, и мне, возможно, придется еще "расшифровывать" его речь.
Вот и я тредстартеру пытаюсь объяснить это уже пятый раз: задача software developer — взять условие задачи и реализовать код, её рещающий. Причём если в условии полная хня — то и код будет такой же, либо не будет вообще: garbage in — garbage out. А "понять, что же там заказчик мямлит и корректно поставить задачу девелоперу" — это работа software consultant совсем за другие деньги.
"Поэтому я вам советую подождать специалиста, договориться с нянечкой и заплатить. Но можно этого и не делать. Если вас не интересует результат." ©
А тредстартер хочёт "два в одном флаконе" за ту же цену.
Wesha
24.05.2016 19:51Всё просто: как я уже сказал: недоговорки и неточные определения — часть производственного процесса.
Всё с Вами понятно: хочется иметь software consultant, а платить ему как software engineer. Плавали, знаем.
- Кандидат офигивает от формулировки, но, подумав несколько минут, говорит: «вы имеете в виду циклический список и хотите, чтобы я две бегунка пустил?» — и пишет программу.
Wesha
24.05.2016 19:48"Пятница. Пришёл лесник и выгнал из лесу всех — и нас, и белых." ©
Массив же — всегда был набором элементов одного типа, последовательно расположенных в адресном пространстве. Разумеется, в тех языках, в которых нет понятия адреса, требование непрерывного расположения элементов становится неактуальным
Вот и я про то же: в наше время массив — набор однотипных элементов, доступных по индексу (требование доступности по физическому адресу из-за
отсутствия таковойразмывания понятия всякими виртуализациями заменяется требованием доступности по индексу — "виртуальному адресу")mayorovp
24.05.2016 20:10Не совсем так. Если язык умеет работать с указателями и допускает арифметические операции над ними — то такие операции имеют смысл только в пределах некоторых непрерывных (в адресном пространстве процесса) блоков памяти. Такие блоки в этих языках и называют массивами.
В тех языках, где работа с памятью полностью спрятана, понятие массива "свободно" и может использоваться для любой структуры с индексатором.
Wesha
24.05.2016 22:09непрерывных (в адресном пространстве процесса)
Ключевая фраза! В реальной физической памяти оно может располагаться как угодно, хоть на винчестере.
Как я уже написал выше, я последние 10 лет работаю на Ruby, в котором, в самом деле, "понятие массива "свободно" и может использоваться для любой структуры с индексатором." (Arrays are ordered, integer-indexed collections of any object. ) Поэтому я и произнёс по привычке фразу, с которой и проистёк весь этот спор.
Scf
20.05.2016 17:13+14С позиции опытного разработчика:
Гуглить что?
Чаще всего я гуглю тексты ошибок и куски стектрейсов
Затем — тёмные или подзабытые места фреймворков типа "hibernate declare composite key". Если мне нужно начать использовать новый фреймворк, я предпочту потратить день и прочитать официальную документацию.
И никогда — чужой код. Чужой код при решении проблем нужен только для того, чтобы изучить те API, которыми он пользуется для решения проблемы.
Исключение — это реализация достаточно сложных алгоритмов типа BCrypt, но и там не стоит брать первый попавшийся кусок.
Вкратце: гуглить надо прежде всего чужой опыт и чужие впечатления. Знания лучше по-возможности получать из документации, а код — писать самому или брать известные библиотеки.
AllexIn
21.05.2016 13:23+2А по документации вы как ищите?
К примеру, я сейчас по работе часто обращаюсь к документации по Unreal Engine. В 99% случаев это вбитый в гугле запрос, который ведет на страницу документации. Оставшийся процент — перекрестные ссылки.Scf
21.05.2016 23:08Наверное, речь идет о С++ и документации к API? Я пишу на Java и там нет такой проблемы — документация к методу находится в исходниках непосредственно над методом и практически ко всем библиотекам есть исходники, которые автоматически подцепляются к проекту. Если же речь идет о крупном закрытом API — то я предпочитаю документацию, оформленную одним документом в html или pdf и ищу по ctrl+f. Если такой возможности нет — то да, только гугль. Почти всегда он ищет лучше, чем специализированные "поиски по онлайн документации".
khim
22.05.2016 00:31Я пишу на Java и там нет такой проблемы — документация к методу находится в исходниках непосредственно над методом
Так и в C++ бывает, но непонятно как это поможет писать код. Читать — да, но писать…
Как вы без поиска понимаете как должен называться метод, который «делает X»? Одно и то же действие можно называть сотней разных способой (если это не какая-нибудь базовая бибоитека, оперирующая уже давным-давно устоявшейся терминологией).

maxru
20.05.2016 17:46+5Раньше читали тот же MSDN, теперь гуглят, потому что к формальному описанию добавляется практический опыт.
Лучше прочитать про чужие грабли, чем наступить на свои.
Так что не вижу ничего плохого (тем более, что решение проблемы, по которой не удалось нагуглить решение, поднимает ЧСВ ещё примерно на over 9000)
amaksr
20.05.2016 17:54+1Я уже забыл, когда последний раз читал книгу по программированию. Гугль все заменяет. Правда последние несколько лет он слишком умничает, и основываясь на своих каких-то своих предположениях корректирует выдачу к моим запросам. Например выдает, ссылки, где нет требуемого мне ключевого слова. Поэтому если появится поисковик, который будет работать как гугль 10 лет назад, я сразу на него переключусь.
dvor
20.05.2016 17:57+6amaksr
20.05.2016 18:07Возможно когда-нибудь дорастет. Пока их индекс во много раз меньше гугловского, и обновляется не так быстро.
dvor
20.05.2016 18:27+3Возможно уже дорос? Я щупал ddg года 2 назад, тогда были проблемы с поиском на русском языке, да и на английском поисковая выдача была не очень. Однако с тех пор многое изменилось. Уже полгода как перешел на ddg, все устраивает.
обновляется не так быстро
Рандомный вопрос со stackoverflow, опубликованный час назад, уже проиндексировался.
тыц тыц.amaksr
20.05.2016 18:38+1Ок, проверяю статью с хабра Strelki.js — еще одна библиотека для работы с массивами, опубликованную сегодня:
Ищу по названию StrelkiJS — ничего (хотя слово в статье есть)
Ищу по названию Strelki.js — показывает кучу ссылок
Видимо кое-что уже занеслось в индекс, но не все. Ну а Гугль, как обычно, сразу все загрузил.dvor
20.05.2016 18:45Хм, у меня все находит. https://duckduckgo.com/?q=Strelki.js&ia=web
Скриншот
flying_hawaiian
24.05.2016 18:12На русском они сейчас, ЕМНИП, просто редиректят запрос Яндексу, так что качество выдачи по соответствующим запросам должно быть более-менее достойным.
Кого не устраивает выдача DDG, может использовать startpage.com — этакий прокси-поисковик, анонимно передающий запросы в Google. Поисковой линзы нет, много раз проверял, Столлман одобряет (https://stallman.org/stallman-computing.html, ищем «ixquick», это то же самое).
Scf
20.05.2016 18:00+2Вот, почитайте: https://support.google.com/websearch/answer/2466433?hl=ru
amaksr
20.05.2016 18:08+1Да, я этими возможностями постоянно пользуюсь. Но гугль все равно корректирует.

Athari
20.05.2016 18:23+4К сожалению, они выкинули оператор "+" — обязательное включение в запрос, в любой форме, не синоним. Какое-то время эту задачу кое-как выполняли кавычки (без стемминга, очевидно), но сейчас даже слова в кавычках игнорирует, правда пока хотя бы указывает, что выкинул. Скоро и это уберут наверняка.

silvansky
20.05.2016 20:41+2Угу, и вообще временами он и сейчас выкидывает почти всё, что без кавычек, а про кавычки говорит «не нашёл, вот тебе про другое». Так скоро вообще можно будет поле ввода убирать из гугла, оставить только кнопку «найти». =)

sshikov
20.05.2016 20:47+8А еще выкинули оператор "-". Кстати, плюс не выкинули — он ищет страницы в Google+. За это кстати отдельно следовало бы кое-кому вломить.
Athari
20.05.2016 22:51Их можно понять, это часть неудавшейся рекламной компании. Они впихивали гугл-плюс во все сервисы, пытаясь использовать для рекламы все сайты в их власти. Но фейсбук не сломить.
Carburn
24.05.2016 18:13Оператор дефис не выкинули. support.google.com/websearch/answer/2466433?hl=ru
grossws
24.05.2016 19:25Он просто не работает в некоторых случаях (может просто является недостаточной пессимизацией).
RomanArzumanyan
20.05.2016 17:59+2Гугл для мелких или сугубо прикладных задач.
Книга для research'а. Ну или научная статья. Которую нагуглил.

GreenBee
20.05.2016 18:10+3Читать книги/статьи хорошо, когда нужно научиться чему-то большому, а именно: изучить новую технологию/методологию/язык.
Для решения насущных проблем книга не подходит. Невозможно держать в голове все, что ты когда либо прочитал. Да что там прочитал — собственноручно написанный код начисто забывается через год. Я несколько раз слышал о случаях, когда человек гуглил свою проблему и находил свой же ответ на каком-то сайте, оставленный несколько лет назад.
daiver19
20.05.2016 18:10Иронично, что при работе в Google обычно гуглить особо смысла нет. Ну и в целом, если бОльшая часть работы не связана с какими-то стандартными фрэймворками, то объем релевантной информации в интернете весьма ограничен.

leventov
21.05.2016 13:08+2Работа почти любого программиста связана с какой-то стандартной платформой. Уж точно 99% программистов в том же гугле. Если вы не используете фреймворк — вы все равно используете язык программирования и стандартную библиотеку, x86/arm, сетевые протоколы, и т. д.
daiver19
21.05.2016 15:54К счастью, базовых знаний языка и стандартной библиотеки достаточно в 99 процентах случаев, ну а всякие низкоуровневые штуки мало кому нужны. Обычно проблемы возникают именно в специфичных местах, которых в интернете нет и быть не может.
leventov
21.05.2016 18:50+3Ну я по 100 раз на дню гуглю вещи которые 100 раз уже видел, например, методы классов String и Map (для Java — базовее не придумаешь). Всякие сниппеты, например, как сконвертировать строку из одной кодировки в другую, как прочитать содержимое из архива, и т. д. Если нет интернета (например в самолете) — конечно могу написать такие вещи сам, основываясь на API стандартной библиотеки, которое доступно в оффлайне (и по которому есть навигация в IDE). Но если есть гугл — никогда так не делаю, потому что 1) нагуглить быстрее 2) меньше вероятность что упустишь какой-то момент и сделаешь ошибку в мини-велосипеде. Сниппеты со StackOverflow обычно отполированы опытом.
leventov
21.05.2016 18:54100 раз это не преувеличение — вообще в определенные периоды я в среднем делал по 100-150 поисков в день, хотя не использовал никакие фреймворки. Сейчас в среднем 30-50 поисков в день.

Darka
20.05.2016 18:20+2Кстати DDG ищет техническую информацию гораздо лучше чем гугл. Плюс офромление поисковый выдачи, это нечто — иногда даже по ссылкам ходить не нужно!

stavinsky
20.05.2016 18:21+4В отсутствии системных знаний, никакой Google не поможет качественно решить задачу. Равно как и наоборот обладая системными знаниями, можно не решить задачу не расширив кругозор возможными вариантами решения. Как-то так. Но без системных знаний все же никуда. А без гугла еще в теории можно…

vaniaPooh
20.05.2016 18:27+5Пользование поиском программиста — это то же самое, что умение пользоваться справочником у любого инженера. Опытный программист часто знает что он ищет, поэтому способен отсеивать лишнее. Начинающий программист ищет хотя бы какое-то решение, поэтому часто берет первое попавшееся.

amarao
20.05.2016 18:48+4Гуглить стыдно, а ходить в в библиотеку за консультациями в профессиональной литературе и периодике — почётно и является признаком профессионала высокого уровня.
Так?

vlreshet
20.05.2016 18:50+15Старый анекдот:
Физику, математику и инженеру дали задание найти объём красного мячика.
Физик погрузил мяч в стакан с водой и измерилл объём вытесненной жидкости.
Математик измерил диаметр мяча и рассчитал тройной интеграл.
Инженер достал из стола свою «Таблицу объёмов красных резиновых мячиков» и нашёл нужное значение.
Вот так и у программистов. Хороший программист всегда сначала попытается нагуглить объём красного резинового мячика, вместо долгого и тернистого пути по поиску объёма самостоятельно. Зачастую нет смысла рыться в документации если тебе нужен чёткий ответ всего на один вопрос — проще нагуглить этот ответ, и работать дальше.degs
20.05.2016 22:40+6Хороший программист прежде всего помнит что существует формула для обьема, во вторых понимает что обьем красного резинового мячика равен обьему синего, а так же не резинового и не мячика. Он понимает что единственный значимый параметр — диаметр, а вот потом уже со спокойной совестью гуглит, если данную конкретную формулу он не помнит.
bobzer
25.05.2016 10:52+1Напомнило:
Идеальный мужчина не пьёт, не курит, не играет на скачках, никогда не спорит и не существует.
Oxoron
21.05.2016 13:31+1Вопрос без сарказма: как математик измерил диаметр?
Для металлического мячика — зафиксировал параллельно 2 плоскости, загнал между ними мячик, сближаешь поверхности пока мячик позволяет.
Но резиновый мячик будет сплющиваться во что-то эллипсоидное.
Подвесить мяч на резинке к потолку, под него источник света, и замерять освещенную площадь? Так проще в стакан с водой кинуть…dendron
22.05.2016 17:55+1Математик просто тыкнул в формулу и сказал «решение существует, что вы ко мне со всякими глупостями пристаете».

copist
22.05.2016 22:54+21. если на мяче есть центральный шов или нарисовано кольцо — погрузить мяч в сыпучее вещество (песок, мука, крупа) до середины, затем посчитать диаметр отверстия
2. померить диаметр тени от солнца или другого источника прямых лучей, если тень эллиптическая — в самой узкой части тени
3. посыпать мячик сверху псевдослучайным потоком мелких дробинок, потом посчитать сколько из них не отскочили, а упали на поверхность (например, плотный клей), посчитать площадь методом Монте-Карло, вычислить диаметр

limon_spb
20.05.2016 19:28+6CPP = Copy Paste Programming :-)

mnv
20.05.2016 22:29+5Тогда Go и вовсе Google-oriented

gag_fenix
20.05.2016 20:00+1Программисту нормально гуглить, а вот какому-нибудь выездному инженеру не стоит рассчитывать, что на объекте будет интернет и можно будет скачать софт, доки, прошивки…
khanid
21.05.2016 01:16Тут надо делать скидку на то, что у них примерно известна область случая.
Если я иду по поводу рассыпавшегося рейда, то мне вряд ли придётся гуглить информацию о том, как разные его варианты устроены. Иначе я бы не шёл.
Так и с инженером. Может — решает. Не может — по таким кейсам, думаю, процедура у них описана.

Dywar
20.05.2016 21:19+2Некоторая подмена понятий в комментариях.
В книге есть содержание и возможно предметный указатель, что является ссылкой на источник.
Google поисковик информации, интернет можно представить себе как подобие большой книги, а книгу можно представить как некоторый объем информации которая имеет определенный формат. Поисковик анализируя страницы в сети, строит свое содержание и предметный указатель.
Дело в свойствах этой информации — объективность, достоверность, полнота…
Бумажное издание часто проходит модерацию, в сети это проделать невозможно и не нужно. Но это не определяет гарантии качества по обе стороны.
Нужно и читать и гуглить, смотреть и слушать, все способы хороши, в любом случае вы получаете одно и тоже — информацию.
Wesha
21.05.2016 00:31+2Напомнило:
Решили провести тест на интеллектуальное развитие студентов, подошли поочередно к студентам 1-го, 2-го, 3-го, 4-го и 5-го курсов и спросили: «Сколько будет дважды два?»
1-й курс (быстро): «4!»
2-й курс (быстро посмотрев в шпору): «4!»
3-й курс (достав калькулятор, быстро): «4!»
4-й курс (торопясь, полистав справочник): «4!»
5-й курс (с возмущением!): «Что я, все константы должен помнить?»Lodary
27.05.2016 16:34Но 2х2 != 24 :)
Wesha
27.05.2016 18:32Простите, у Вас туннельное зрение? Я уже осветил этот вопрос.
Lodary
27.05.2016 18:49+1Вежливый вы человек, сразу видно :) Поскольку я неполноценный участник, мои комментарии проходят премодерацию автором статьи. В этот раз он был, вероятно, занят и утвердил написанное мною только через пять дней. За этот срок, другой комментатор успел пошутить схожим образом, а вы осветить.
khanid
21.05.2016 01:14Мы выяснили: гуглят все. Разница в том, как.
Касается, в общем-то, не только программистов.
Здравствуйте, я админ. И я гуглю.
Вот только гуглить как я в моём окружении может 2 или 3 человека. Остальные десятки будут искать то же самое решение долго и мучительно.
Это хороший универсальный навык. Потому что занимаясь своим хобби (а это уже как раз программирование) я ищу на примерно том же уровне, что и в области моей профессиональной деятельности.
Моё личное мнение — если ты не гуглишь, то, скорее всего, ты останавливаешься в развитии. Или уступаешь другим, если не умеешь искать.
mib
21.05.2016 15:30Я никогда не задавался таким вопросом, корректно ли гуглить. Я сейчас держу в уме контуры: что где использовать, какие функции, а подробности уже гуглю, например параметры функций, я не буду это всё учить наизусть. Ну и авто-дополнение тоже помогает. И как уже писали выше — ошибки, трейсы и тд — гугль знает все ответы.
Единственное, о чем я беспокоюсь — рано или позддно гугль возьмёт нас в «оборот» и заставит заплатить за все прошлые и будущие ответы.
Mixim333
21.05.2016 15:50Сам также использую именно Google для поиска методики решения возникшей проблемы, но именно «методики решения», а не «решения». Еще для себя выработал правило: никогда не задавать Google'у «вопрос» по разработке на русском языке — только английский, т.к. ответы более релевантные
questor
23.05.2016 00:32Я обычно пользуюсь поиском яндекса, но вопросы по программированию задаю сразу в гугле, долгое время сравнивал, у кого лучше (тупо задавая вопрос в яндексе и нажимая найти это же в гугле — внизу есть такая сслыка «поискать в других поисковых системах»). Бывало, что оба поисковика понимали, что нужно мой вопрос немного перефразировать — и почему-то на мой взгляд гугл с этим лучше справляется.
Не могу судить, дело в объёме проиндексированной сети, в том, что для гугл нативный язык — английский или у меня самого корявость английского лучше подходит под гугл, чем под яндекс.
vsb
21.05.2016 17:31+1Раньше гугл не был так хорош, да и в интернете не было SO и подобных сайтов. Поиск решения приводил к длинным мануалам, сложным книжкам. Их чтение помимо решения проблемы приносило множество дополнительных знаний. В последние годы возникла проблема: вбил в гугл, получил решение, реализовал, двинулся дальше. В голове в лучшем случае конкретно решение этой проблемы останется, а порой даже и это забывается, через год опять то же самое гуглишь. Для себя считаю это проблемой, поэтому стал пользоваться гуглом, как самым последним средством. Сначала пересматриваю книги, руководства, изучаю исходный код, пытаюсь экспериментируя сам найти решение, даже если этот путь отнимает время. И только в самом крайнем случае иду на SO и если там ничего не нашлось — в гугл. Кстати помимо прочего зависимость от гугла мне тоже не нравится и хотя он вряд ли куда-нибудь исчезнет, всё равно стараюсь сначала использовать другие варианты вроде поиска по SO, DDG и тд.

seregamorph
21.05.2016 23:36Решая задачу, лезу сразу в гугл (как правило попадая на stackoverflow) в случаях:
1) я уже знаю ответ на вопрос, просто не помню точной формулировки (например, название параметра/класса/метода)
2) я вообще не знаю, в какую сторону искать, но есть за что зацепиться (например, сообщение об ошибке в слабо знакомой технологии)
3) необходимая срочность решения
В остальных случаях хотя бы полчаса-час решаю задачу самостоятельно (анализ сорцов либы, эксперименты, спеки). Даже получив ответ, иногда все же захожу в гугл — посмотреть чужой опыт и найти нехватающие нюансы. Полученный таким способом ответ намного лучше оседает в памяти, да и ачивка за решение — всегда приятно.

Shablonarium
22.05.2016 03:41+1Если человек не гуглит, а использует только старый опыт, как он может давать современные актуальные решения?
dendron
22.05.2016 18:02+1Главное отличие профессионала от халтурщика — понимает ли человек то решение, которое берет, пропустил ли его через свой мезушный узел.
Если программист копипастит код без понимания как он работает — это халтурщик и гнать его в шею.
Это в принципе любых профессий касается.

bodqhrohro
22.05.2016 20:40Важная проблема GOP в том, что оно не совместимо с радикальным методом борьбы с прокрастинацией — уходом в оффлайн. Конечно, во многих сферах программные решения уже и без того завязаны на постоянном интернет-подключении, да и в оффлайне можно прокрастинировать ещё как…

lxsmkv
27.05.2016 16:35По тому какие человек делает запросы и сколько запросов ему понадобится для ответа, видно, насколько он владеет предметной областью.
Владение профессиональными терминами и правильное их употребление в контексте, с моей т.з. достаточный тест на профпригодность. Человек не знакомый с типографией будет говорить «расстояние между строк» а знакомый — «интерлиньяж», и найдет более качественную информацию. Кроме того сразу видно как человек владеет языком. Сравните: «как сделать интервал между строк другим» и «как изменить межстрочный пробел».
Гуглить почему-то считается моветоном, хотя он экономит время а значит и деньги. Думаю Гуглу надо просто открыть новый сервис: Google Pro — все то же самое, но с обязательной регистрацией, за деньги, и без рекламы. (Для тех кому для имиджа нужно пользоваться только самыми профессиональными инструментами :)
3v1lcore
27.05.2016 16:35Не виду ничего плохого в использовании поисковика для решения задачи.
Одна конечная цель и не столь важно каким способом ее достигать, а если я могу тратить меньше времени на поиск решения, а выполнять больший объем работы, то нет смысла противиться прогрессу.
Еще один немаловажный факт заключается в самооценке, многие себя переоценивают или напротив, недооценивают, но даже отличный программист может оказаться профаном в чуждой ему области или плохой программист может дать отличные советы по частному вопросу.
В самом начале своего пути приходилось изобретать сортировки, какие то списки, а сейчас нет нужды тратить часы жизни на придумывание давно созданного и отлаженного.
shaytan69
27.05.2016 16:35А ведь есть и языковая проблема поиска. Не всегда можно найти нужную информацию вбивая в поиск русские слова и наоборот английские. Ровно как и в случае с другими языками. Иногда очень полезно владеть несколькими языками.
Stroy71
27.05.2016 16:35Все сказано до нас. «Сформулировать проблему, значит наполовину найти решение». Google, лично мне, помогает сформулировать проблему.

AnatoliD
27.05.2016 16:35Мне приходиться решать задачи в основном на стыке нескольких дисциплин — организации и автоматизации производства, экономики и программирования… и хотя в разработке программно — аппаратных систем я с 1973, тем не менее времени на очень глубокое изучение программирования не очень много…
Тем не менее, на практике получается так, что наработки кем — то сделанные и публикуемые на Интернет использую нечасто, чаще использую свои систематизированные наработки — это и быстрее и надежнее, в части ожидаемого результата






koceg
khim
Тут вопрос даже не в какую сторону копать, а скорее в какую сторону НЕ копать. Как известно для любой волнующей человека проблемы всегда легко найти решение — простое, достижимое и ошибочное (there is always a well-known solution to every human problem — neat, plausible, and wrong).
Главное для чего нужно читать книжки — это не чтобы найти правильное решение (его вам выдаст Google), а для того, чтобы отсеять кучу неправильных (их тоже будет в выдаче поисковика в достатке).
Temirkhan
Вы говорите о бОльшем кольце поиска. Такой метод больше подходит начинающим — не наступать на самые распространенные грабли. А тот, о котором говорит koceg, подразумевает, что разработчик опытный и ему необходимо «качественное» решение.
koceg
В моём случае, скорее нет. Я просто не в состоянии запомнить все нюансы, связанные с выбором конкретного инструмента (он, выбор, ведь должен быть аргументированным). Важнее знать, что такой инструмент есть и как раз уметь найти его сильные и слабые стороны уже непосредственно в нужный момент. Lazy loading, проще говоря. Например, книга "7 languages in 7 weeks" ничего мне не расскажет о недостатках этих языков, не убережёт от стандартных для них граблей, но когда придёт время я хотя бы буду знать, что такие языки есть и в каких областях используются.