После перехода от Perl к JavaScript много лет тому назад, я всё испытывал за свой новый язык некоторый комплекс неполноценности из-за недостаточной поддержки Юникода. За всё то время, пока JavaScript совершал в этом направлении свой большой скачок (при переходе от ES5 к ES6), у меня в закладках осталось несколько хороших статей.
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
JavaScript has a Unicode problem
Unicode-aware regular expressions in ECMAScript 6
ES6 Strings (and Unicode, ) in Depth
В последней из них предлагался рецепт разбиения строки на символы с учётом Юникода при помощи нового оператора
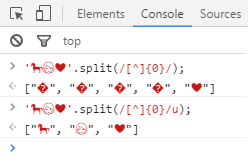
... Например (хабровский парсер не даёт почему-то ввести этот пример кодом, скрывая символы выше BMP):
И вот я вчера задумался, можно ли реализовать то же самое при помощи новых регулярных выражений. В голову пришла простая идея, которая на поверку оказалась верна:
Сегодня я внезапно понял, что вчера как раз был день рождения Далай-ламы. Поэтому мне показалось, что завершить эту заметку можно небольшой шуткой на JavaScript в честь виновника торжества.
const nothingness = /[^]{0}/;
const nothing = '';
console.log(nothing.search(nothingness));
// 0
console.log(nothing.match(nothingness));
// [ '', index: 0, input: '' ]
console.log(nothing.split(nothingness));
// []
console.log(nothing.replace(nothingness, nothing));
// ''
console.log(nothingness.test(nothing));
// true

P.S. Попробовал сравнить по скорости оба метода:
/******************************************************************************/
'use strict';
/******************************************************************************/
const str = '\ud83d\udc0e'.repeat(1000);
const re = /[^]{0}/u;
let symbols;
let hrStart;
let hrEnd;
let i;
/******************************************************************************/
hrStart = process.hrtime();
i = 100000;
while (i-- > 0) symbols = [...str];
hrEnd = process.hrtime(hrStart);
console.log(
`${symbols.length} symbols via spread: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s`
);
/******************************************************************************/
hrStart = process.hrtime();
i = 100000;
while (i-- > 0) symbols = str.split(re);
hrEnd = process.hrtime(hrStart);
console.log(
`${symbols.length} symbols via regexp: ${(hrEnd[0] * 1e9 + hrEnd[1]) / 1e9} s`
);
/******************************************************************************/
/******************************************************************************/
'use strict';
/******************************************************************************/
const str = '\ud83d\udc0e'.repeat(1000);
const re = /[^]{0}/u;
let symbols;
let pStart;
let i;
/******************************************************************************/
pStart = performance.now();
i = 100000;
while (i-- > 0) symbols = [...str];
console.log(
`${symbols.length} symbols via spread: ${(performance.now() - pStart) / 1e3} s`
);
/******************************************************************************/
pStart = performance.now();
i = 100000;
while (i-- > 0) symbols = str.split(re);
console.log(
`${symbols.length} symbols via regexp: ${(performance.now() - pStart) / 1e3} s`
);
/******************************************************************************/
Node.js 6.3.0
1000 symbols via spread: 28.284130503 s
1000 symbols via regexp: 14.887705856 sGoogle Chrome Canary 54.0.2790.0
1000 symbols via spread: 36.575210000000006 s
1000 symbols via regexp: 15.550919999999998 sFirefox Nightly 50.0a1
1000 symbols via spread: 20.392635000000002 s
1000 symbols via regexp: 26.935885000000003 sВ V8 выигрывает регулярное выражение (быстрее в два раза и более), в SpiderMonkey выигрывает оператор spread (ненамного).
Комментарии (14)

tumikosha
07.07.2016 18:53лучше бы сделать это без регулярных выражений

vmb
07.07.2016 20:02+1Если вы имеете в виду, что лучше при помощи
..., то я добавил в конец сравнение в скорости. Если же вы предлагаете создавать специальную функцию, то я не спорю, что можно найти более быстрые решения, но я имел в виду короткие идиомы из коробки.
ReinRaus
07.07.2016 22:30+1Попробуйте
/(?:)/uпо моим замерам оно быстрее Вашего на 5% в среднем.
Если же вы предлагаете создавать специальную функцию, то я не спорю, что можно найти более быстрые решения
Нельзя найти такие решения. В данной задаче регулярное выражение всегда будет быстрее «чистой» реализации, если не использовать оператор
...vmb
07.07.2016 23:09Попробовал. В Node.js всегда чуть быстрее, в Firefox то чуть быстрее, то чуть медленнее, в Chrome по большей части чуть медленнее. Видимо, если очень важно быстродействие, этот вариант стоит иметь в виду, но одновременно подстраиваться под реализацию.
lockywolf
Unicode — это нечто просто.
Достоинство у него единственное — он таки действительно содержит всё. Дальше остаются только недостатки. Доступ по индексу за O(n) — пожалуй, самый видный невооружённым взглядом, хотя вообще говоря их сильно больше.
vmb
Ну, пока ещё не всё. Но Emoji — значительный шаг ко всему)
lockywolf
Ну, как бы, этих самых эмодзи было не избежать, они же есть в какой-то японской кодировке, придуманной NTT.
senia
Строго говоря доступ по индексу к юникоду не имеет прямого отношения.
Полагаю вы подразумевали конкретный способ представления — utf-8.
Ничто не мешает вам использовать UTF-32. Получите константный доступ по индексу.
lockywolf
>>Ничто не мешает вам использовать UTF-32
И кто его поддерживает? Никто его не поддерживает.
Да и в UTF32 можно забодяжить линейный доступ если злоупотреблять «безногими» конструкциями.
mwizard
Что такое «безногие конструкции»?
lockywolf
1???)? ?Н?Е???? ???????П????????Ы?Т???А???Й??Т???????ЕС????????Б??????? ????Ч???????Т??????ОТ??0????? ??????N???3????М?Е???????Н??????И?????Т?Ь???!???? ?????2????)??????? ??????Д????У?М?А?????N?????T????????3??????? ??????Т????О???Л???????Ь????К??О????? ????О?? ?????СЕБ??Е!???? ????????3??)??? ??Р??????У?????К??????И????? 4??)??? ??Д??О???С????М?????О??????Т???????? ??????л????ю???????д???е?й ??п?????р?о??с??м????о??????т??р??????е???в?????ши??????х?? ??с??о?????й????д???у?????т?? ??с??????? ????у????м?????а????? ?????Б???Е???З?Н???????О????Г??N??????М??
Per_Ardua
А если выделить, то вполне можно прочитать :)
akzhan
Что такое "не поддерживает"? Сохраните в UTF-32 и делайте что угодно. Потом обратно.
Конвертор — такой сложный...
lockywolf
Я же не в вакууме живу и сам себе компиляторы не пишу.