
В последние дни старого, 2016 года, компания поднапряглась и выпустила давно ожидаемый «мажорный» релиз 5.0 нашей Acropolis OS. Это, напомню, то, что стоит внутри нашей CVM, Controller VM, и в которой содержится практически вся богатая функциональность Nutanix как системы.
Новинок в ней появилось множество, только простое перечисление займет, пожалуй, страницу. Поэтому я решил остановиться в этой статье только на самых интересных и важных с точки зрения развития Nutanix как продукта, или полезных практическому сисадмину, работающему с такой системой.
Итак, AOS 5.0, третий большой софтверный релиз в 2016 году, и интересный старт для нового, 2017 года в компании, вышедшей в сентябре на IPO, и ставшей одним из самых успешных «единорогов» 2016 года на NASDAQ (компаний, оцененных в миллиард долларов и выше).
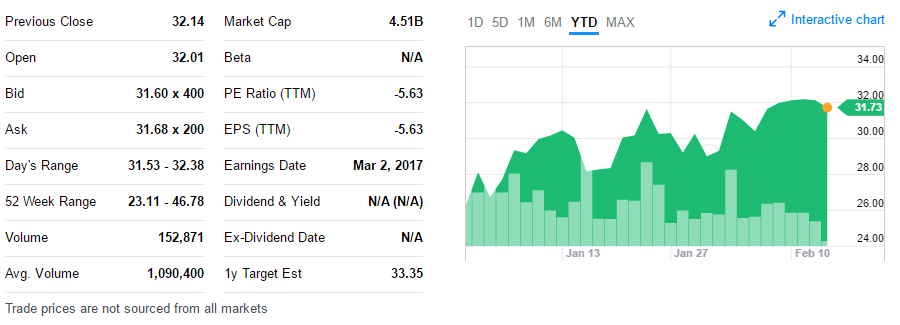
Прежде всего, я бы хотел рассказать и показать фичу, о которой давно просили наши пользователи. И вот, наконец, Nutanix сделал SSP, Self-Service Portal, наш собственный инструмент для создания пользователям «облачного портала», наш «vCloud Director», интерфейса, который позволяет пользователям определенной группы LDAP/AD создавать и разворачивать из утвержденных сисадмином шаблонов их собственных VM на платформе Nutanix AHV. Группа пользователей (например: Test dept, developers, techsupport) получает некие лимиты ресурсов (к примеру 100Ghz CPU power, 12TB RAM, 1800GB storage), и в пределах этих лимитов разворачивает из своего собственного веб-интерфейса свои VM, не беспокоя этими заявками сисадминов.
Для компании, в которой VM разворачивается сотни, или в которой структурных подразделений десятки, или же для компании, которая хочет сделать у себя (или для определенных внешних пользователей) private cloud, это отличная новая возможность. И раньше такой портал можно было написать с помощью нашего RESTful API, но сейчас не просто пользователь получает готовый, бесплатный, «из коробки» готовый инструмент для того, чтобы его использовать, но и сам API был существенно расширен, и дорос до «v3.0».
Так что постепенно становится понятно, что совершенно не просто «для красоты» Nutanix в прошлом году официально стал именовать себя An Enterprise Cloud Company. Появление SSP показало направление движения Nutanix в этом году. Мы уже не просто компания-стартап, которая ставит на ODM Supermicro свой Virtual Appliance, берите выше. И в этом году вы увидите много интересного в этом направлении.
Сразу скажу, что вышедшая первая версия SSP не идеальна, и в следующем релизе, уже совсем скоро, его возможности будут существенно расширены, так, например, появится возможность работать с несколькими AD, а, значит появится гораздо более богатая multi-tenancy, но, также будет поддерживаться не только AHV, наш собственный бесплатный гипервизор, но и кое-какой еще.
Но уже сейчас вы можете посмотреть работу SSP. Причем, обратите внимание, SSP появился не только на «коммерческом» Nutanix, он есть и на Nutanix CE!
Если вам интересно подробно разобраться как поставить и использовать SSP, рекомендую серию постов нашего сотрудника Magnus Andersson: http://vcdx56.com/category/ssp/
Не покажется удивительным, что в первую очередь Nutanix теперь выкатывает фичи на наш собственный гипервизор. Он для нас наиболее нативный и родной, а число пользователей AHV на наших системах превысило 30% инсталлированных систем, видимых саппорту (а еще есть системы, которые саппорт не видит).
Мы продолжаем расширять его функциональность, так, например, в этой версии гипервизора добавился наша версия DRS, Dynamic Resource Scheduler (напомню, в ESXi эта функциональность доступна только в Enterprise лицензии), а также тесно связанные с ним Affinity и Anti-Affinity Rules. Это, в двух словах, возможность задать правила, на соответствие которым будет проверяться процедура миграции VM, пользователем, или при HA. Например, можно задать правила, при котором данные VM всегда будут мигрировать только на определенные хосты, например, на которых есть специальные ресурсы для их работы, а принадлежащие этой группе — всегда будут располагаться на разных хостах, например — они являются HA-парой какого-то сервиса и для отказоустойчивости всегда должны работать на разных хостах виртуализации.
Кроме того, теперь, для развертывания новой VM на кластере, будет выбираться с помощью того же DRS, наименее физически загруженный хост.
Еще в прошлом году Nutanix начал процесс разделения функций в нашем собственном интерфейсе управления системой — Prism GUI. Напомню, что в каждую систему Nutanix встроен веб-интерфейс управления всем кластером, написанный на чистом HTML5, без использования Java или Flash. Вся функциональность, которая в Prism была — осталась, но теперь мы называем «просто» Prism, встроенный в узлы Nutanix — Prism Elements. Он как и раньше встроенный и бесплатный, и из него ничего не «вырезали». А вот некоторые новые «тяжелые» фичи, интересные Ъ-энтерпрайзу, добавляются теперь в продукт, который называется Prism Pro, и он базируется на нашем отдельном VM-апплаенсе — Prism Central. Изначально Prism Central был VA с множеством возможностей по управлению множественными кластерами, централизованным сбором алертов с разных кластеров, интегральным интерфейсом управления. Поэтому, когда встал вопрос, как сохранить относительно легковесный встроенный Prism, и, одновременно, добавить новые фичи в интерфейс, было приято решение часть «тяжелых» фич для энтерпрайза, называемых Prism Pro, поместить в интерфейс Prism Central.
Prism Pro это набор дополнительных функций, интересных «тяжелым» энтерпрайз-инсталляциям, и идет за допденьги, при этом оригинальный Elements остался легким и простым, и, что важно, бесплатным.
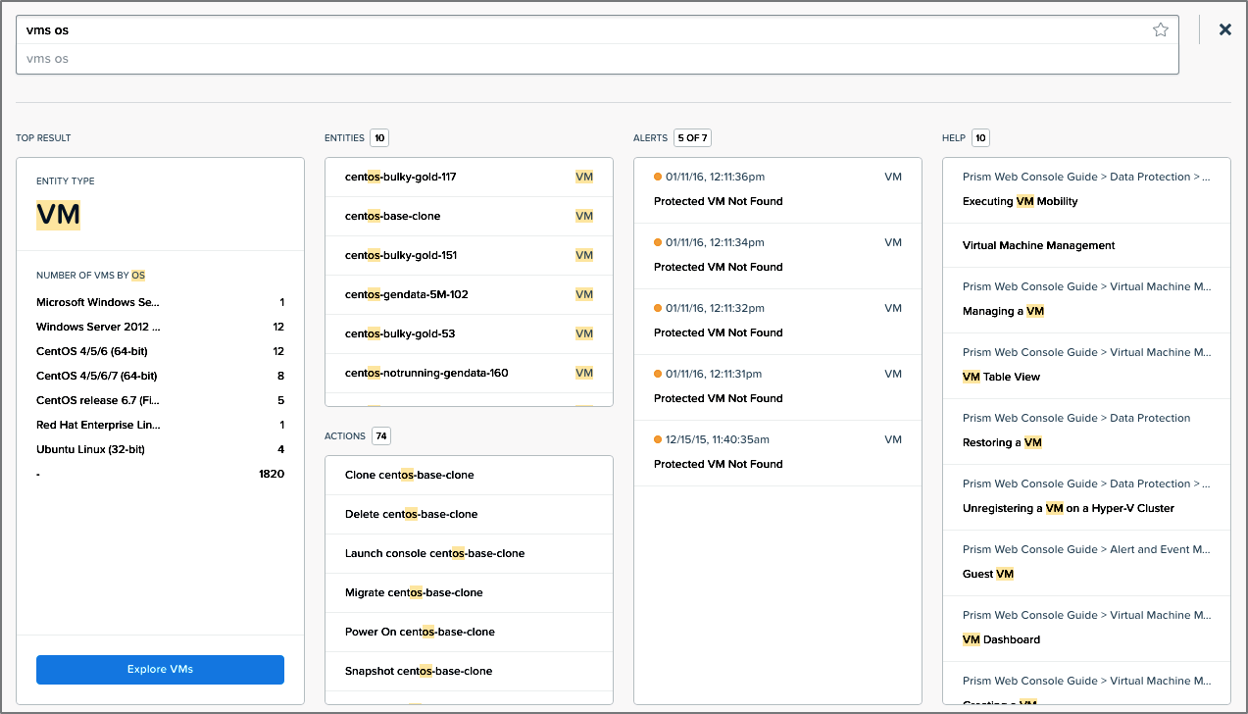
Из новых интересных возможностей можно упомянуть интересную новую возможность искать прямо в пользовательском интерфейсе. Теперь «погуглить» можно прямо в Prism. Напишите запрос, и, вероятно, в результатах поиска вы сразу получите искомое. Теперь поддерживается привычный язык запросов, переменные, булевы операции.
Например, админ захотел посмотреть какие OS используются в его VM. Запрос «vms os» в строке поиска в интерфейсе, и, как видите, в поле Top Results слева уже показана табличка результата. Хотите получить список VM, которые показывают производительность выше 1000 IOPS — снова не проблема «vms IOPS > 1000» покажет вам их.
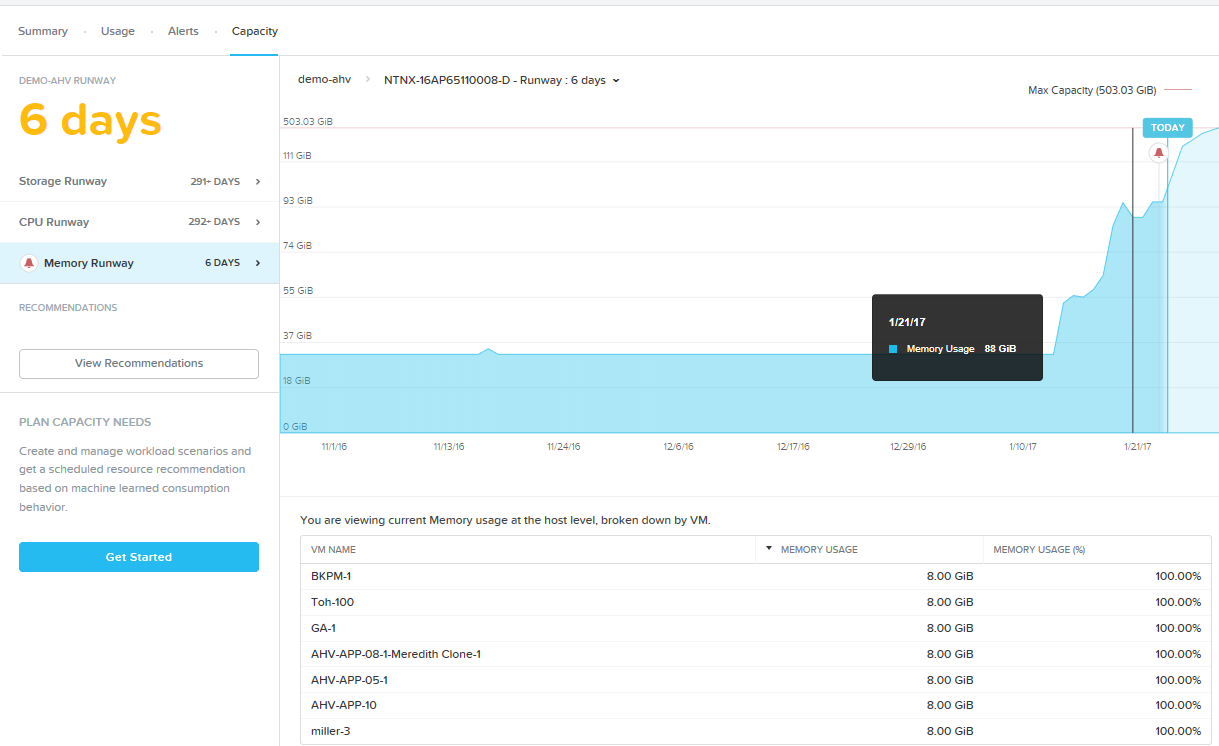
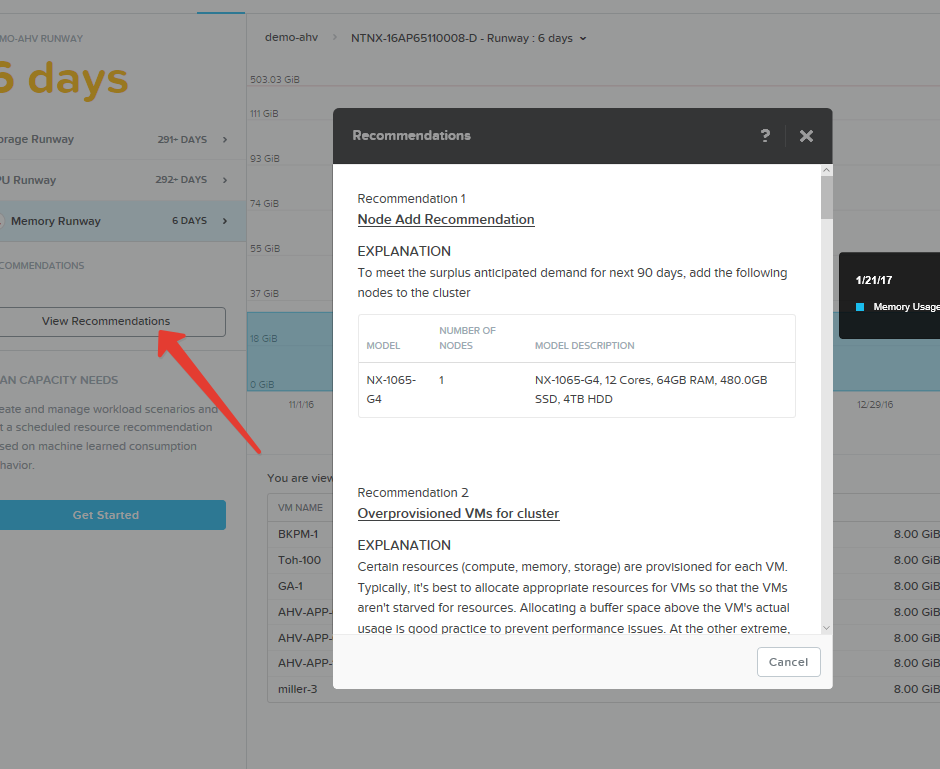
Там же, в Prism Pro появилась очень нужная для больших систем функция Predictive Analysis и What-If.
Как скоро у меня кончится память на хостах кластера, если все будет идти, как у меня идет сейчас? Что будет, если мне понадобится развернуть еще 10 VM с нагрузкой SQL Server таких вот параметров? Какие хосты Nutanix мне нужно будет купить для них и когда?
На все такие вопросы можно получить ответы в Prism Pro и новых функциях интерфейса.
Но не только в Prism Pro появились новинки. Развивается и Prism Elements.
Например, в нем появилась визуализация виртуальной сетевой инфраструктуры кластера. Когда VM в кластере десятки и сотни, когда они разбросаны по множеству хостов кластера, иногда бывает сложно разобраться, к какому хосту, VLAN и интерфейсу относится та или иная VM. Теперь, в панели Network, вы можете быстро посмотреть и проанализировать всю сеть.
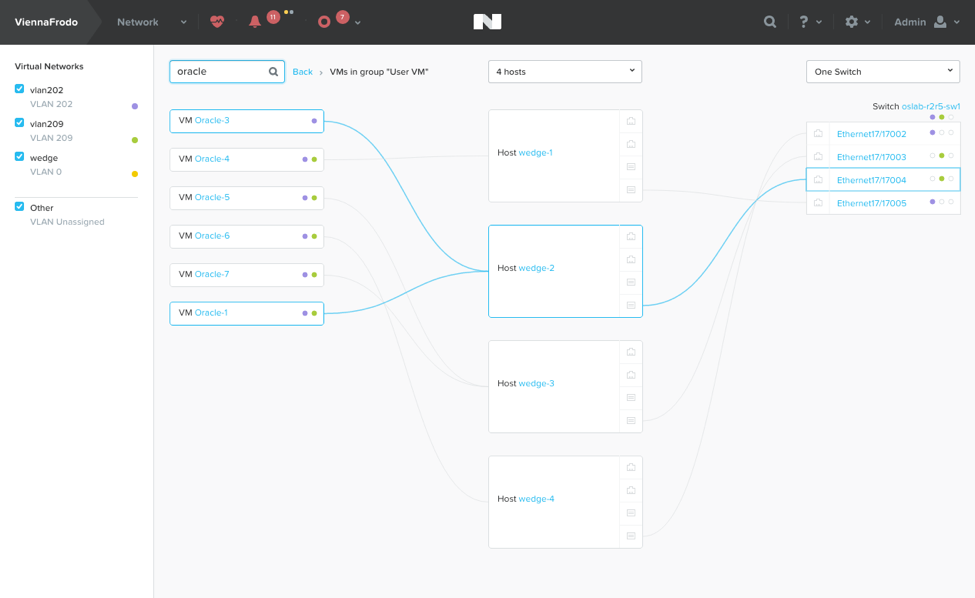
Там же можно посмотреть и статистику по портам, физическим, хоста, и виртуальным, VM. Кроме того, если ваш коммутатор поддерживает протокол LLDP, то данные о конфигурации с физического коммутатора также можно получить и проанализировать.
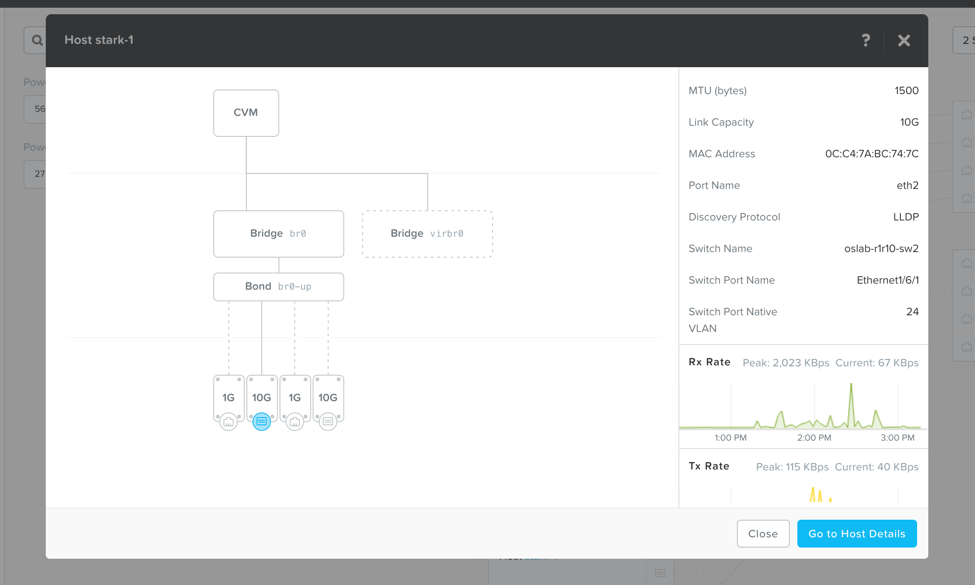
Наш встроенный скрипт контроля NCC, Nutanix Cluster Check, который раньше был доступен только из консоли CVM, теперь можно запустить и изучит его вывод в интерфейсе Prism. Все ли настройки сделаны правильно, разрешается ли FQDN на DNS, отвечает ли NTP, нет ли проблем в сетевом бридже? Все эти проверки теперь можно вызвать из Prism Elements, встроенного в каждый хост Nutanix.
Ну и что же мы все про Acropolis? Что там с ESXi? Для него тоже есть новинка. Prism так удобен, а Web Console порой так страшна, что сложно упрекать админов в том, что они часто просили нас сделать возможность управления некоторыми фичами vSphere из Prism. Теперь у нас есть возможность из Prism управлять некоторыми рутинными операциями администрирования не из vCenter, а из Prism. Остановить и запустить VM, мигрировать ее с хоста на хост, получить доступ к ее консоли — теперь можно не из Web Client vCenter, а из Prism. vCenter тут, правда, все равно нужен, мы просто дергаем его API з Prism для этих задач. Но для кого-то из админов vSphere это может показаться полезным и удобным, как кажется мне.
Acrоpolis File Service — наш собственный NAS по файловому протоколу SMB 2.0/2.1, распределенный, децентрализованный, многопоточный, single namespace, способный хранить десятки миллионов файлов в кластере, дорос до GA, General Available. Это значит, что он готов в продакшн уже окончательно. И не значит, что новые фичи не появятся в самое ближайшее время. В планах добавить SMB 3.0 и NFS, и еще кое-что.
Но уже сейчас у нас получился неплохой конкурент кластерным и unified-хранилкам NAS.
В Acropolis Block Service добавилась поддержка нескольких новых OS, среди них, что интересно, ESXi 5.5 и 6.0. Это означает, что кластер Nutanix c ABS может работать как внешняя SDS-хранилище по 10G iSCSI не только для baremetal-серверов, например, для не-x86 серверов Oracle или иного софта, который невозможно или нецелесообразно по каким-то причинам тащить на Nutanix. С поддержкой ESXi теперь добавилась возможность использовать Nutanix как хранилище для датасторов ESXi. Однако надо понимать, что использовать Nutanix как SDS не есть правильная цель, и Nutanix не стремится к такому использованию, HCI (HyperConverged Infrastructure), на наш взгляд, гораздо более умная и прогрессивная штука. Именно по этой причине, например, мы не будем реализовывать в ABS технологию VAAI. Поддержка ESXi рассматривается как вспомогательная, для целей миграции, например, или как временное решение. Плюсов и плюшек HCI гораздо больше.
Кроме расширения числа поддерживаемых OS добавилась поддержка CHAP, IP Whitelist, Online Resizing для LUN, а также возможность закрепить LUN на уровне SSD.
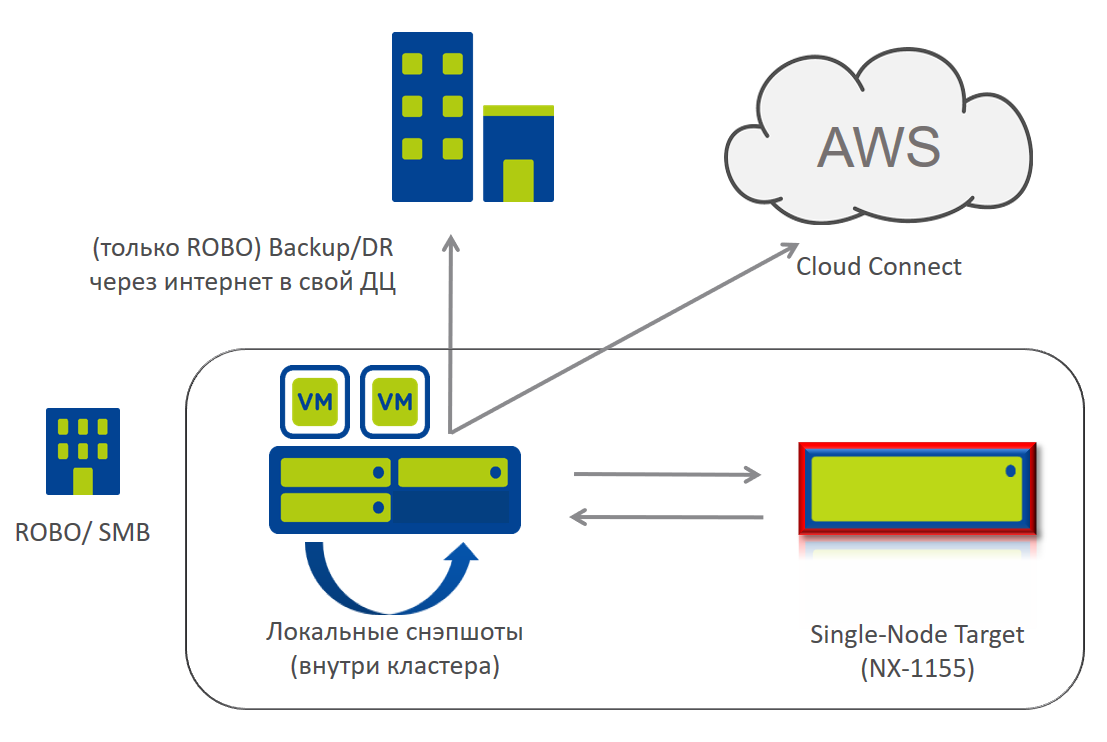
Наконец, появилась новая интересная возможность для наших SMB/SME и ROBO клиентов.
Для таких небольших офисов часто остро стоит вопрос хранения резервных копий. В Nutanix встроен механизм снэпшотов, но хотелось бы эти снэпшоты, в определенных случаях, хранить вне защищаемого кластера. В принципе, существует несколько вариантов. Можно отправлять их в центральный офис, если канал передачи данных это позволяет, можно хранить их в «виртуальном Nutanix» в среде публичного облачного провайдера, например AWS или Azure. Но идеально было бы это делать на локальный, но другой, отличный от боевого кластер.
Как вы уже знаете, минимальная конфигурация кластера Nutanix насчитывает 3 ноды. И в ситуации, когда небольшой офис вынужден покупать только для хранения бэкапа еще три ноды, это выглядит избыточно. Но для игравшихся с Nutanix CE не секрет, что, в принципе, если поступиться отказоусточивостью (а для хранения бэкапов это, в принципе, допустимо), то можно поднять Nutanix даже на одном хосте.
И вот теперь у нас есть Single-node backup target, специальная конфигурация для хранения снэпшотов основного кластера, однонодовый «псевдокластер». На нем нельзя развертывать VM, он не работает со сторонними бэкап-приложениями, но если цель его хранения снэпшотов на отдельной системе, то это — интересный вариант.
На рисунке поясняется эта схема.
Остались нерассмотренными и нерассказанными еще около 25 различных новых фич, там и поддержка NVMe (у нас в линейке еще нет моделей с NVMe, но софт это уже поддерживает), и поддержка до 60TB емкости хранения на ноду, поддержка XenServer для VDI-инфраструктур с 3D-GPU NVIDIA Tesla M60/M10, реализация CBT (Change Block Tracking) API для сторонних приложений резервного копирования, Metro Witness для нашего механизма Metro Availability позволит лучше обрабатывать ситуацию Split Brain, механизм Self-service restore, который позволяет пользователю VM самостоятельно монтировать и восстанавливать содержимое VM из снэпшотов, без привлечения админа. Мы перешли на новый, улучшенный алгоритм компрессии, поменяв внутри системы Snappy, который был до версии 5.0 на LZ4HC, один из самых эффективных на сегодня алгоритмов компресии данных на дисках, и он так хорошо работает, что мы приняли решение оставить его включенным по умолчанию на AllFlash системах.
Наконец, Nutanix с Acropolis Hypervisor официально признан совместимым для систем SAP Netweaver. Учитывая потрясающую консервативность SAP в отношении виртуализации и технологических новинок, это — прорыв. Признание совместимости со стороны SAP означает, что системы SAP на платформе Netweaver официально можно развертывать на HCI Nutanix на нашем гипервизоре Acropolis. Впереди — SAP HANA, но насколько впереди поддержка HANA пока сказать я вам не могу. Мы все ждем выхода в релиз поддержки NUMA в Acropolis Hypervisor, и после этого мы будем «пробивать» SAP про HANA. Оптимистично — это может случиться уже в этом году. С учетом того, что сегодня SAP не рассматривает вообще никакую виртуализацию для систем HANA, и поддерживает только baremetal, это будет «маленький шаг для компании, но огромный скачок для человечества».
Итак, новый мажорный релиз вышел, и, согласно отчетам нашей техподдержки, уже в первый месяц около 5% наших пользователей в своих системах перешли на него только в январе.
Ничего удивительного, ведь кроме перечисленных фич нам удалось еще немного оптимизировать код и поднять производительность на чтении и записи в IOPS примерно на 20% (AOS 4.7.3, AOS 5.0), просто софтверным бесплатным обновлением, на том же физическом железе. И это еще одно очевидное преимущество Software-defined решений.
{kind=link}
{kind=link}
Поделиться с друзьями
Комментарии (11)

krids
16.02.2017 23:47Про виртуализацию хАны это вы сами придумали? Или кто «подсказал»?

shapa
16.02.2017 23:50Я думаю лучше сначала изучать реально вопрос, затем писать на публику.
Реально виртуализация HANA поддерживается только для очень ограниченного круга сценариев (фактически test&dev и небольшие инстансы)
Вообще забавно читать комментарии такого плана — неужели вы думаете что мы не работаем с SAP напрямую и не в курсе всех деталей? :)
ast-pm-105
Есть вопрос — планирует ли Nutanix расширение физического функционала своих серверов NX серии? Конкретно интересует энергонезависимый cache для записти (не SSD как сейчас, а RAM+BBU как в обычных СХД)?
shapa
В данном случае это не «расширение функционала», а возврат к старинным граблям на которые наступили практически все остальные вендоры.
Можно ли уточнить — зачем вводить:
Дополнительную точку отказа (SPOF),
Cложные аппаратные контроллеры (особенно — для 100% SDS системы),
Если у нас одна из лучших (если не лучшая) скорость работы подсистемы ввода / вывода, без применения устаревших и опасных технологий (такие как кэширование на контроллере и применение батареек)?
Перефразируя — чего вы хотите добиться, добавив RAM+BBU?
ast-pm-105
Скорость обработки random write операций при использовании маленьких блоков.
nutanix
Вы считаете, что сейчас она маленькая, и будет больше?
233675 IOPS random read 4K blocks и 170937 random write с latency в пределах 3ms на 4-нодовом кластере среднего уровня — это мало?
shapa
Это еще слабое железо :) На 4x узлах All Flash будет более полумиллиона IOPS (3000 и выше серия)
nutanix
Погодите. Тут какое-то непонимание с первых слов вижу я.
> своих серверов NX серии?
Ну, сначала стоит сказать, что все же не «сервер», это система особого класса, гиперконвергентная система, включающая в себя и сервер-хост виртуализации, и (часть) хранилища данных, способная масштабироваться scale-out объединением в кластер.
> Конкретно интересует энергонезависимый cache для записти (не SSD как сейчас, а RAM+BBU как в обычных СХД)?
А зачем, в чем смысл такого, что это, с вашей точки зрения даст хорошего, и почему вам кажется, что нынешняя архитектура хуже?
ast-pm-105
>А зачем, в чем смысл такого, что это, с вашей точки зрения даст хорошего, и почему вам кажется, что нынешняя архитектура хуже?
Думается мне, что это одна из сторон архитектуры которую было бы неплохо (при возможности) улучшить.
При сравнении с традиционными СХД это первое что приходит в голову, когда начинаешь задумываться о цепочке записи данных на распределенный массив Nutanix: «что будет, если на массив придет 1GB random write»? В случае СХД с каким-то объемом cache, операции быстро-быстро уйдут в него, а потом постепенно убегут на следующий Tier (SSD или SAS). В случае с Nutanix они уйдут на SSD ноды, а потом по сети на другие ноды кластера и только потом на следующий Tier.
shapa
Еще раз. Что конкретно улучшить?
1) Скорость записи random 4k блоков у нас одна из лучших на рынке
2) Если у вас на традиционной СХД придет не 1GB, а 100GB — вы «убьете» кэш контроллера и получите коллосальную просадку по скорости I/O.
На Нутаникс — все абсолютно предсказуемо, ввиду того что идет на SSD сразу запись (который минимум — сотни гигабайт).
Cуммаризируя, все что вы пишете — ровно с точностью до наоборот, подход традиционных СХД с использованием кэша (у нас вообще нет RAM кэша на запись — все идет сразу на hot уровень) — крайне устаревший и опасный.
Архитектура Нутаникс работает намного быстрее и стабильнее, в том числе под Tier-1 и Tier-0 нагрузками, всвязи с чем даже сверх-критичные системы / организации / структуры переводят на Нутаникс.
Недавний пример — DJC2
https://en.wikipedia.org/wiki/Deployable_Joint_Command_and_Control
https://www.nutanix.com/press-releases/2017/01/24/nutanix-selected-help-modernize-deployable-joint-command-control-djc2-program/
Одна из ключевых причин того что платформу выбирают для ультра-критичных нагрузок и применений — архитектура Нутаникс намного более надежна и предсказуема чем традиционные СХД (с применением кэшей и батареек), плюс лидирующие показатели производительности.
nutanix
Вы пытаетесь натянуть сову на глобус :) Вернее приспособить решение, которое принадлежит к совсем иной архитектуре. RAM-кэш с BBU это устройство, которое придумано (и неплохо работало) для медленных HDD в RAID. Мы не используем для записи поступающих данных HDD (за рядом известных исключений, например чисто секвентальной записи), и не используем RAID. То есть для случая, когда у нас есть ооооочень медленное устройство persistent memory на «том конце».
Мы используем SSD типа Intel S3610, как отдельное физическое устройство. А если вы посмотрите на его производительность, например в спеке тут: http://www.intel.com/content/dam/www/public/us/en/documents/product-specifications/ssd-dc-s3610-spec.pdf
то увидите его реальный потенциал быстродействия.
Мы сейчас даже имеющийся физический потенциал устройства не исчерпываем (хотя идем к этой границе постепенно, но скорее в отрасль придут NVMe и 3D Xpoint). Например, в приведенных выше показателях на каждой из 4 нод кластера стояло по 2 таких SSD (и операции по ним раскидываются), то есть производительность одного SSD на тесте была в районе 29 тысяч IOPS чтения и 21 тысячи записи, а потенциально эти SSD могли бы дать 84 и 28K соответственно.