 Инструкторы курсов «Введение в программирование» знают, что студенты находят любые причины для ошибок своих программ. Процедура сортировки отбраковала половину данных? «Это может быть вирус в Windows!» Двоичный поиск ни разу не сработал? «Компилятор Java сегодня странно себя ведёт!» Опытные программисты очень хорошо знают, что баг обычно в их собственном коде, иногда в сторонних библиотеках, очень редко в системных библиотеках, крайне редко в компиляторе и никогда — в процессоре. Я тоже так думал до недавнего времени. Пока не столкнулся с багом в процессорах Intel Skylake, когда занимался отладкой таинственных сбоев OCaml.
Инструкторы курсов «Введение в программирование» знают, что студенты находят любые причины для ошибок своих программ. Процедура сортировки отбраковала половину данных? «Это может быть вирус в Windows!» Двоичный поиск ни разу не сработал? «Компилятор Java сегодня странно себя ведёт!» Опытные программисты очень хорошо знают, что баг обычно в их собственном коде, иногда в сторонних библиотеках, очень редко в системных библиотеках, крайне редко в компиляторе и никогда — в процессоре. Я тоже так думал до недавнего времени. Пока не столкнулся с багом в процессорах Intel Skylake, когда занимался отладкой таинственных сбоев OCaml.Первое проявление
В конце апреля 2016 года вскоре после выпуска OCaml 4.03.0 один Очень Серьёзный Индустриальный Пользователь OCaml (ОСИП) обратился ко мне в частном порядке с плохими новостями: одно из наших приложений, написанное на OCaml и скомпилированное в OCaml 4.03.0, падало случайным образом. Не при каждом запуске, но иногда вылетал segfault, в разных местах кода. Более того, сбои наблюдались только на их самых новых компьютерах, которые работали на процессорах Intel Skylake (Skylake — это кодовое название последнего на тот момент поколения процессоров Intel. Сейчас последним поколением является Kaby Lake).
За последние 25 лет мне сообщали о многих багах OCaml, но это сообщение вызывало особенное беспокойство. Почему только процессоры Skylake? В конце концов, я даже не мог воспроизвести сбои в бинарниках ОСИПа на компьютерах в моей компании Inria, потому что все они работали на более старых процессорах Intel. Почему сбои не воспроизводятся? Однопоточное приложение ОСИПа делает сетевые и дисковые операции I/O, так что его выполнение должно быть строго детерминировано, и любой баг, который вызвал segfault, должен проявлять себя при каждом запуске в том же месте кода.
Моим первым предположением было то, что у ОСИПа глючит железо: плохая микросхема памяти? перегрев? По моему опыту, из-за таких неисправностей компьютер может нормально загружаться и работать в GUI, но падает под нагрузкой. Итак, я посоветовал ОСИПу запустить проверку памяти, снизить тактовую частоту процессора и отключить Hyper-Threading. Предположение насчёт HT появилось в связи с недавним сообщением о баге в Skylake с векторной арифметикой AVX, который проявлялся только при включенном HT (см. описание).
ОСИПу не понравились мои советы. Он возразил (логично), что они запускали другие требовательные к CPU и памяти задачи/тесты, но падают только программы, написанные на OCaml. Очевидно, они решили, что их железо в порядке, а баг в моей программе. Ну отлично. Я всё-таки уговорил их запустить тест памяти, который не выявил ошибок, но мою просьбу выключить HT они проигнорировали. (Очень плохо, потому что это сэкономило бы нам кучу времени).
Одновременно ОСИП провёл впечатляющее расследование с использованием разных версий OCaml, разных компиляторов C, которые используются для компиляции системы поддержки выполнения OCaml, и разных операционных систем. Вердикт был следующий. Глючит OCaml 4.03, включая ранние беты, но не 4.02.3. Из компиляторов глючит GCC, но не Clang. Из операционных систем — Linux и Windows, но не MacOS. Поскольку в MacOS используется Clang и там работает порт с Windows-версии на GCC, то причиной чётко назвали OCaml 4.03 и GCC.
Конечно, ОСИП рассуждал логично: мол, в системе поддержки выполнения OCaml 4.03 был фрагмент плохого кода С — с неопределённым поведением, как мы говорим в бизнесе — из-за которого GCC генерировал сбойный машинный код, поскольку компиляторам C позволено работать при наличии неопределённого поведения. Это не первый раз, когда GCC максимально некорректно обрабатывает неопределённое поведение. Например, см. эту уязвимость в безопасности или этот сломанный бенчмарк.
Такое объяснение казалось вполне правдоподобным, но оно не объясняло случайный характер сбоев. GCC генерирует причудливый код из-за неопределённого поведения, но это по-прежнему детерминистический код. Единственной причиной случайности, которую я смог придумать, могла быть Address Space Layout Randomization (ASLR) — функция ОС для рандомизации адресного пространства, которая изменяет абсолютные адреса в памяти при каждом запуске. Система поддержки выполнения OCaml кое-где использует абсолютные адреса, в том числе для индексации страниц памяти в хеш-таблицу. Но сбои оставались случайными даже после отключения ASLR, в частности, во время работы отладчика GDB.
Наступил май 2016 года, и пришла моя очередь замарать руки, когда ОСИП прислал тонкий намёк — дал доступ в шелл к своей знаменитой машине Skylake. Первым делом я собрал отладочную версию OCaml 4.03 (к которой позже планировал добавить больше отладочного инструментария) и собрал заново приложение ОСИПа с этой версией OCaml. К сожалению, эта отладочная версия не вызывала сбой. Вместо этого я начал работать с исполняемым файлом от ОСИПа, сначала интерактивно вручную под GDB (но это сводило меня с ума, потому что иногда приходилось ждать сбоя целый час), а затем с небольшим скриптом OCaml, который запускал программу 1000 раз и сохранял дампы памяти на каждом сбое.
Отладка системы поддержки выполнения OCaml — не самое весёлое занятие, но посмертная отладка из дампов памяти вообще ужасна. Анализ 30 дампов памяти показал ошибки segfault в семи разных местах, два места в OCaml GC, а ещё пять в приложении. Самым популярным местом с 50% сбоев была функция
mark_slice в сборщике мусора OCaml. Во всех случаях у OCaml была повреждена куча: в хорошо сформированной структуре данных находился плохой указатель, то есть указатель, который указывал не на первое поле блока Caml, а на заголовок или на середину блока Caml, или даже на недействительный адрес памяти (уже освобождённой). Все 15 сбоев mark_slice были вызваны указателем на два слова впереди блока размером 4.Все эти симптомы согласовались со знакомыми ошибками, вроде той, что компилятор
mark_slice забывал зарегистрировать объект памяти в сборщике мусора. Однако такие ошибки привели бы к воспроизводимым сбоям, которые зависят только от распределения памяти и действий сборщика мусора. Я совершенно не понимал, какой тип ошибки управления памятью OCaml мог вызвать случайные сбои!За неимением лучших идей, я опять прислушался к внутреннему голосу, который шептал: «аппаратный баг!». У меня было неясное ощущение, что сбои чаще случаются, если машина находится под большей нагрузкой, как будто это просто перегрев. Для проверки этой теории я изменил свой скрипт OCaml для параллельного запуска N копий программы ОСИПа. Для некоторых прогонов я также отключал уплотнитель памяти OCaml, что вызывало большее потреблением памяти и большую активность сборщика мусора. Результаты оказались не такими, как я ожидал, но всё равно поразительными:
| N | Загрузка системы | С настройками по умолчанию | С отключенным уплотнителем |
|---|---|---|---|
| 1 | 3+epsilon | 0 сбоев | 0 сбоев |
| 2 | 4+epsilon | 1 сбой | 3 сбоя |
| 4 | 6+epsilon | 12 сбоев | 19 сбоев |
| 8 | 10+epsilon | 17 сбоев | 23 сбоя |
| 16 | 18+epsilon | 16 сбоев |
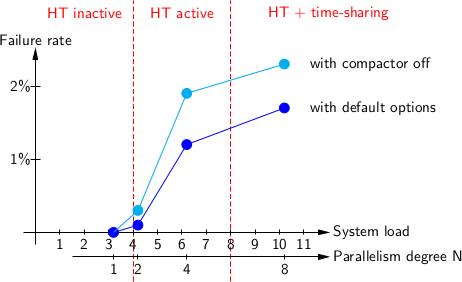
Здесь показано количество сбоев на 1000 запусков тестовой программы. Видите скачок между и ? И плато между более высокими значениями ? Чтоб объяснить эти цифры, нужно более подробно рассказать о тестовой машине Skylake. У неё 4 физических ядра и 8 логических ядер, поскольку включен HT. Два ядра были заняты в фоне двумя долговременными тестами (не моими), но в остальном машина была свободна. Следовательно, загрузка системы равнялась , где — это количество тестов, запущенных параллельно.
Когда одновременно работает не более четырёх процессов, планировщик ОС поровну распределяет их между четырьмя ядрами машины и упорно старается не направлять два процесса на два логических ядра одного физического ядра, потому что это приведёт к недостаточному использованию других физических ядер. Такое происходит в случае с , а также большую часть времени в случае с . Если количество активных процессов превышает 4, то ОС начинает применять HT, назначая процессы двум логическим ядрам на одном и том же физическом ядре. Это случай . Только если все 8 логических ядер на машине заняты, ОС осуществляет традиционное разделение времени между процессами. В нашем эксперименте это случаи и .
Теперь стало видно, что сбои начинаются только при включении Hyper-Threading, точнее, тогда, когда программа OCaml работала рядом с другим потоком (логическим ядром) на том же физическом ядре процессора.
Я отправил ОСИПу результаты экспериментов, умоляя его принять мою теорию о том, что во всём виновата многопоточность. В этот раз он послушал и отключил HT на своей машине. После этого сбои полностью исчезли: двое суток непрерывного тестирования не выявили вообще ни одной проблемы.
Проблема решена? Да! Счастливый конец? Не совсем. Ни я, ни ОСИП не пытались сообщить о проблеме в Intel или кому-то ещё, потому что ОСИП был удовлетворён тем, что можно компилировать OCaml c Clang, а ещё потому что он не хотел неприятной огласки в духе «продукты ОСИПа падают случайным образом!». Я же совсем устал от этой проблемы, да и не знал, как сообщать о таких вещах (в Intel нет публичного баг-трекера, как у обычных людей), а ещё я подозревал, что это баг конкретных машин ОСИПа (например, партия сбойных микросхем, которая случайно попала не в ту корзину на фабрике).
Второе проявление
2016-й год прошёл спокойно, больше никто не сообщал, что небо (sky, точнее, Skylake — каламбур) падает из-за OCaml 4.03, так что я с радостью забыл об этом маленьком эпизоде с ОСИПом (и продолжил сочинять ужасные каламбуры).
Затем, 6 января 2017 года Ангерран Декорн и Джорис Джованнанджели из Ahrefs (ещё один Очень Серьёзный Индустриальный Пользователь OCaml, член Консорциума Caml в придачу) сообщили о загадочных случайных сбоях с OCaml 4.03.0: это PR#7452 в баг-трекере Caml.
В их примере повторяемого сбоя сам компилятор ocamlopt.opt иногда падал или выдавал бессмысленный результат, когда компилировал большой исходный файл. Это не слишком удивительно, потому что ocamlopt.opt сам по себе является программой OCaml, скомпилированной компилятором ocamlopt.byte, но так было проще обсуждать и воспроизвести проблему.
Публично открытые комментарии к багу PR#7452 довольно хорошо показывают, что произошло дальше, а сотрудники Ahrefs подробно описали свою охоту за багом в этой статье. Так что я выделю только ключевые моменты этой истории.
- Через 12 часов после открытия тикета, когда в обсуждении было уже 19 комментариев, Ангерран Декорн сообщил, что «все машины, которые смогли воспроизвести баг, работают на процессорах семейства Intel Skylake».
- На следующий день я упомянул о случайных сбоях у ОСИПа и предложил отключить многопоточность (Hyper-Threading).
- Ещё через день Джорис Джованнанджели подтвердил, что баг не воспроизводится при отключенном Hyper-Threading.
- Параллельно Джорис обнаружил, что сбой происходит только если система поддержки выполнения OCaml собрана с параметром
gcc -O2, но неgcc -O1. Оглядываясь назад, это объясняет отсутствие сбоев с отладочной версией окружения OCaml и с OCaml 4.02, поскольку они обе по умолчанию собираются с параметромgcc -O1. - Я выхожу на сцену и публикую следующий комментарий:
Будет ли безумием предположить, что настройка
gcc -O2на окружении OCaml 4.03 выдаёт специфическую последовательность инструкций, которая вызывает аппаратный сбой (какие-то степпинги) в процессорах Skylake с Hyper-Threading? Возможно, это и безумие. С другой стороны, уже есть одна задокументированная аппаратная проблема с Hyper-Threading и Skylake (ссылка) - Марк Шинвелл связался с коллегами в Intel и сумел протолкнуть отчёт через отдел поддержки пользователей.
Затем ничего не происходило 5 месяцев, пока…
Открытие
26 мая 2017 года пользователь "ygrek" опубликовал ссылку на следующий журнал изменений из пакета с «микрокодом» от Debian:
* New upstream microcode datafile 20170511 [...]
* Likely fix nightmare-level Skylake erratum SKL150. Fortunately,
either this erratum is very-low-hitting, or gcc/clang/icc/msvc
won't usually issue the affected opcode pattern and it ends up
being rare.
SKL150 - Short loops using both the AH/BH/CH/DH registers and
the corresponding wide register *may* result in unpredictable
system behavior. Requires both logical processors of the same
core (i.e. sibling hyperthreads) to be active to trigger, as
well as a "complex set of micro-architectural conditions" Эррата SKL150 была задокументирована компанией Intel в апреле 2017 года и описана на странице 65 в Обновлении спецификаций семейства процессоров Intel 6-го поколения. Похожая эррата упоминается под номерами SKW144, SKX150, SKZ7 для разновидностей архитектуры Skylake и KBL095, KBW095 для более новой архитектуры Kaby Lake. Слова «полный кошмар» не упоминаются в документации Intel, но приблизительно описывают ситуацию.
Несмотря на довольно расплывчатое описание («сложный набор микроархитектурных условий», и не говорите!) эта эррата бьёт прямо в цель: включенный Hyper-Threading? Есть такое! Проявляется псевдослучайно? Есть! Не имеет отношения ни к плавающей запятой, ни к векторным инструкциям? Есть! К тому же, готово обновление микрокода, которое устраняет эту ошибку, оно мило упаковано в Debian и готово к загрузке в наши тестовые машины. Через несколько часов Джорис Джованнанджели подтвердил, что сбой исчез после обновления микрокода. Я запустил ещё больше тестов на своей новёхонькой рабочей станции с процессором Skylake (спасибо отделу снабжения Inria) и пришёл к тому же выводу, поскольку тест, который обваливался быстрее чем за 10 минут на старом микрокоде, проработал 2,5 суток без проблем на новом микрокоде.
Есть ещё одна причина считать, что SKL150 — виновник наших проблем. Дело в том, что проблемный код, описанный в этой эррате, как раз и генерирует GCC при компиляции системы поддержки выполнения OCaml. Например, в файле
byterun/major_gc.c для функции sweep_slice получается такой код C:hd = Hd_hp (hp);
/*...*/
Hd_hp (hp) = Whitehd_hd (hd);После макрорасширения это выглядит так:
hd = *hp;
/*...*/
*hp = hd & ~0x300;Clang компилирует этот код банальным способом, используя только регистры полной ширины:
movq (%rbx), %rax
[...]
andq $-769, %rax # imm = 0xFFFFFFFFFFFFFCFF
movq %rax, (%rbx)Однако GCC предпочитает использовать 8-битный регистр
%ah для работы с битами от 8 до 15 из полного регистра %rax, оставляя остальные биты без изменений:movq (%rdi), %rax
[...]
andb $252, %ah
movq %rax, (%rdi)Эти два кода функционально эквиваленты. Одной возможной причиной выбора GCC может быть то, что его код более компактный: 8-битная константа
$252 помещается в один байт кода, в то время как 32-битной, расширенной до 64 бит, константе $-769 нужно 4 байта. Во всяком случае, сгенерированный GCC код использует и %rax, и %ah и, в зависимости от уровня оптимизации и неудачного стечения обстоятельств, такой код может окончиться циклом, достаточно маленьким, чтобы вызвать баг SKL150.Так что, в итоге, это всё-таки аппаратный баг. Говорил же!
Эпилог
Intel выпустила обновления микрокода для процессоров Skylake и Kaby Lake, которые исправляют или обходят проблему. Debian опубликовала подробные инструкции для проверки, подвержен ли багу ваш процессор и как получить и применить обновления микрокода.
Публикация о баге и выпуск микрокода оказались очень своевременными, потому что у нескольких проектов на OCaml начали происходить таинственные сбои. Например, у Lwt, Coq и Coccinelle.
Об аппаратном баге написал ряд технических сайтов, например, Ars Technica, HotHardware, Tom's Hardware и Hacker's News [и GeekTimes — прим. пер.].
Комментарии (27)

apro
06.07.2017 16:36-1Странно он себя повел:
потому что мы были удовлетворены тем, что можно компилировать OCaml c Clang
clang развивается, как и прочие популярные компиляторы,
процессоры на нового поколения появлялись бы на все большем количестве
машин,
соответственно в следующий раз уже у 100500 ОСИПов такое могло произойти.
encyclopedist
06.07.2017 17:08+2В оригинале:
because they were satisfied with the workaround consisting in compiling OCaml with Clang
То есть на самом деле это заказчик был удовлетворён, а не автор.

Salabar
06.07.2017 17:06+4В будущих процессорах такой ад будет встречаться еще чаще. И они будут использоваться еще шире, чем сейчас. Приятных всем снов.
glowingsword
06.07.2017 17:15+6Верно, с ростом их сложности и ростом количества разных наборов инструкций ошибок будет всё больше. И это печально. Забагованное железо — это куда хуже, чем баги в ПО.

teleavtomatika
07.07.2017 06:28-1Нет никаких оснований полагать, что с ростом сложности системы пропорционально растет и количество ошибок в этой системе.
glowingsword
07.07.2017 06:41+2В теории вроде бы нет, вы правы. Вот только практика иногда преподности сюрьпризы. Судя по глюкам в различных прошивках EFI(во времена более примитивного BIOS их столько не было), а также всё более глючном железе(одни только видеокарты современные чего стоят). Производители не очень тщательно тестируют то, что производят. И чем больше функциоанала нужно каждый раз тестить, тем меньше вероятность что его протестируют более-менее тщательно. Мне кажется, им некогда тестить своё железо, они торопятся денег заработать.

kekekeks
07.07.2017 09:28+5во времена более примитивного BIOS их столько не было
Было-было. Просто в момент массового перехода на EFI биосы за два с лишним десятилетия уже успели стабилизироваться, а тут всё переписывать пришлось.

saboteur_kiev
07.07.2017 12:45+1Уйдет на пенсию/в другую компанию тот, кто разрабатывал конкретную фичу, и новый человек будет только примерно представлять как она работает. А любой незадокументированный нюанс может стать причиной проблемы в будущем.
С ростом сложности системы, в ней появляется все больше и больше подобных мест.
С ростом сложности системы, она становится целиком неподдающаяся освоению одним человеком.
То есть это прямая и логичная закономерность потенциальных проблем.
glowingsword
06.07.2017 17:14+10Был бы это единственный баг у процов Intel… Мне приходится компилировать OpenVPN без поддержки AES-NI для ноутбука Acer с Pentium N4200 из-за того, что OpenVPN с AES-NI не работает(ни в Windows, ни в Linux) с одним ключом, в то время как на других ноутах/ПК c более старыми интеловскими процами с AES-NI это же подключение работает корректно с той же версией OpenVPN и OpenSSL. С другими ключами OpenVPN с AES-NI на этом же ноуте работает. Пришлось просто отказаться от поддержки AES-NI на данном девайсе, так как проще не юзать забагованный AES-NI на Pentium N4200, чем пытаться достучаться до ТП компании, которая рьяно скрывает любую информацию о контактах их службы технической поддержки. Соответственно, в Intel наверно и не знают о проблемах с AES-NI в их N4200, а потому и фиксов этой проблемы ожидать не приходится.
kindacute
06.07.2017 17:55А я ведь знаю этого пользователя ygrek, он активно когда-то коммитил в mldonkey

Jef239
07.07.2017 00:36+3Насчет «никогда — в процессоре»… На моей памяти — два бага в процессорах. Один приводил к прерыванию по нереализованной операции при делении ненормализованного плавающего числа на ненормализованное (СМ-2М). Второй — сравнение двух вещественных чисел только по мантисе, без сравнения ординат (ЕС-1033).
Carburn
12.07.2017 06:41Все же знают про замену процессоров из-за некорректного деления (Ошибка Pentium FDIV).

eugenk
07.07.2017 06:19+3Нда… На моей памяти такое было только в одном проекте. Но не на интеле конечно. Был в конце 90-х начале 2000-х некий камень под названием NUON. Довольно симпатичный. Дешёвый, 4 ядра, vliw-инструкции, низкое потребление. Жаль так и не взлетел. У Тошибы был на нём проект DVD-плеера. Не знаю выпустили ли его в конце концов в серию. Тогда мы портировали под него игру The Next Tetris (хит 98-го года кстати). Сама игра тогда была только под PlayStation 1, причем написана была не то что с привязкой к архитектуре, а даже к конкретному компилятору gcc! И такие подарки были равномерно разбросаны по всему коду. Так что игру фактически не портировали, а писали с нуля. Вот тогда пришлось этого дела и хлебнуть. Глюки были и в версии OpenGL (она там тоже была довольно нетривиальной, например сидела на двух ядрах), и в самом процессоре. Вобщем интересные были времена. Есть что вспомнить…
mike_y_k
07.07.2017 09:37-1Спасибо за статью.
Правда первое промельк нувшее в голове было из другой области:
«Всем свойственно ошибаться — мрачно бормотал ёжик, слезая с кактуса».
Как результат:
— радует возможность в настоящий момент изменения ситуации патчем микрокода. В былые времена пришлось бы допиливать компилятор для обхода проблемы;
— печальна закрытость поддержки Intel от пользователей, только избранные имеют возможность робко постучаться к небожителям и без гарантии результата.
Mercury13
07.07.2017 11:41-1Хорошо. Как определить, есть ли этот баг, и где найти патч против него?

HEKOT
07.07.2017 12:06+21. Прочитать предыдущее сообщение
2. Стать «немного опытным» программистом в соответствии с терминолонгией предыдущего сообщения
3. google.com
4. напечатать что-то типа «intel errata list»
5. нажать клавишу «Ввод» («Return», «Enter», etc.)
6. Получить ссылку на документ типа:
7. Найти на последней старнице раздел Errata
Carburn
12.07.2017 06:53В статье написано
Debian опубликовала подробные инструкции для проверки, подвержен ли багу ваш процессор и как получить и применить обновления микрокода.
weiser
07.07.2017 11:48-1Ну всё, теперь я знаю ещё одну причину «для заказчика» при обнаружении плавающих багов на фронтенде :)
Labunsky
Интересно, Intel несет какую-нибудь ответственность, связанную с последствиями от таких косяков?
inoyakaigor
Навряд ли. Наверняка у них есть какая-нибудь лицензия, которая снимает с них всю ответственность (что, в общем-то, логично).
Chugumoto
а Майкрософт и прочие софтверные компании несут? вроде нет. только обновления для исправления ошибок выпускают… так и тут… микрокодом исправили и всё…
Labunsky
Все-таки, процессоры — не софт. Но да, бегло пробежался по их сайту и соглашению: готовы только менять, чинить и возвращать деньги