В своей практике я достаточно много времени посвящаю проектированию и администрированию облачных инфраструктур различного назначения. В основном это Apache CloudStack. Данная система обладает отличными возможностями, но в части мониторинга, функциональности явно недостаточно (читайте — отсутствует), особенно, если на мониторинг смотреть шире чем мониторинг индивидуального объекта наблюдения (сервер, виртуальная машина).
В целом, в связи с более широкими требованиями к систем визуального анализа информации и потребностями в части интеграции с источниками данных стали распространяться специализированные решения для ad-hoc анализа данных, такие как Kibana, Grafana и иные. Данные системы могут интегрироваться со специализированными хранилищами временных рядов данных, одним из которых является InfluxDB. Статья расскажет о готовом решении, распространяемом в виде образа Docker, использующем LibVirt API, Grafana и InfluxDB, предназначенном для сбора и анализа параметров исполняющихся VM для гипервизора KVM.
Обзор решения
Решение представлено в форме Docker-контейнера, распространяемого по лицензии Apache License v2, поэтому оно может без ограничений применяться в любых организациях и изменяться, отражая потребности конкретной задачи. Контейнер размещается на выделенном сервере, python-утилита сбора данных удаленно подключается по протоколу TCP к LibVirt и отправляет данные в InfluxDB, откуда они могут быть запрошены с помощью Grafana для визуализации и анализа.
Контейнер доступен в виде исходных кодов на GitHub и в виде доступного для установки образа на DockerHub. Язык реализации — python.
Почему Docker-контейнер
Данное решение является конечным и удобным для внедрения, а так же не требует каких-либо дополнительных настроек и установки дополнительного ПО на серверах виртуализации, кроме разрешения доступа к API LibVirt по сети. Если доступ к API LibVirt снаружи не представляется возможным, то возможно установить Docker на хосте виртуализации и запускать контейнер локально.
В рамках решений, которые я применяю в своей практике, всегда существует защищенная сеть, доступ к которой ограничен для неавторизованных пользователей, соответственно, я не ограничиваю доступ к LibVirt паролем, и представленный контейнер не поддерживает аутентификацию. В том случае, если такая функция требуется, ее можно достаточно просто добавить.
Какие данные собираются
Сенсор собирает следующие данные о виртуальных машинах, доступные через LibVirt:
CPU:
{
"fields": {
"cpuTime": 1070.75,
"cpus": 4
},
"measurement": "cpuTime",
"tags": {
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}RAM:
{
"fields": {
"maxmem": 4194304,
"mem": 4194304,
"rss": 1443428
},
"measurement": "rss",
"tags": {
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}Статистика по каждому сетевому адаптеру с привязкой к MAC-адресу:
{
"fields": {
"readBytes": 111991494,
"readDrops": 0,
"readErrors": 0,
"readPackets": 1453303,
"writeBytes": 3067403974,
"writeDrops": 0,
"writeErrors": 0,
"writePackets": 588124
},
"measurement": "networkInterface",
"tags": {
"mac": "06:f2:64:00:01:54",
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}Статистика по каждому диску:
{
"fields": {
"allocatedSpace": 890,
"ioErrors": -1,
"onDiskSpace": 890,
"readBytes": 264512607744,
"readIOPS": 16538654,
"totalSpace": 1000,
"writeBytes": 930057794560,
"writeIOPS": 30476842
},
"measurement": "disk",
"tags": {
"image": "cc8121ef-2029-4f4f-826e-7c4f2c8a5563",
"pool": "b13cb3c0-c84d-334c-9fc3-4826ae58d984",
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system",
"vmId": "i-376-1733-VM",
"vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679"
}
}Общая статистика по хосту виртуализации, как ее "видит" LibVirt:
{
"fields": {
"freeMem": 80558,
"idle": 120492574,
"iowait": 39380,
"kernel": 1198652,
"totalMem": 128850,
"user": 6416940
},
"measurement": "nodeInfo",
"tags": {
"vmHost": "qemu+tcp://root@10.252.1.33:16509/system"
}
}Настройка LibVirt
В конфигурационном файле /etc/libvirt/libvirtd.conf необходимо установить:
listen_tls = 0
listen_tcp = 1
tcp_port = "16509"
auth_tcp = "none"
mdns_adv = 0Внимание! Вышеуказанные настройки позволят соединяться с API LibVirt по TCP, настройте корректно файрвол для ограничения доступа.
После выполнения данных настроек LibVirt необходимо перезапустить.
sudo service libvirt-bin restartInfluxDB
Установка (для Ubuntu)
Установка InfluxDB осуществляется по документации, например, для Ubuntu:
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
sudo apt-get update && sudo apt-get install influxdb
sudo service influxdb startНастройка аутентификации
Выполним команду influx для открытия сессии к СУБД:
$ influxСоздадим администратора (он нам понадобится когда мы активируем аутентификацию):
CREATE USER admin WITH PASSWORD '<password>' WITH ALL PRIVILEGESСоздадим базу данных pulsedb и обычного пользователя pulse с доступом к этой базе данных:
CREATE DATABASE pulsedb
CREATE USER pulse WITH PASSWORD '<password>'
GRANT ALL ON pulsedb TO pulseАктивируем аутентификацию в конфигурационном файле /etc/influxdb/influxdb.conf:
auth-enabled = trueПерезапустим InfluxDB:
service influxdb restartЕсли все сделано правильно, теперь при открытии сессии необходимо указывать имя пользователя и пароль:
influx -username pulse -password secretЗапуск контейнера для начала сбора данных
docker pull bwsw/cs-pulse-sensor
docker run --restart=always -d --name 10.252.1.11 -e PAUSE=10 -e INFLUX_HOST=influx -e INFLUX_PORT=8086 -e INFLUX_DB=pulsedb -e INFLUX_USER=pulse -e INFLUX_PASSWORD=secret -e GATHER_HOST_STATS=true
-e DEBUG=true -e KVM_HOST=qemu+tcp://root@10.252.1.11:16509/system bwsw/cs-pulse-sensorБольшинство параметров самоочевидны, поясню лишь два:
- PAUSE — интервал между запросом значений в секундах;
- GATHER_HOST_STATS — определяет собирать или нет дополнительно статистику по хосту;
После этого в журнале контейнера с помощью команды docker logs должна отражаться активность и не должны отражаться ошибки.
Если открыть сессию к InfluxDB, то в консоли можно выполнить команду и убедиться в наличии данных измерений:
influx -database pulsedb -username admin -password secret> select * from cpuTime limit 1
name: cpuTime
time cpuTime cpus vmHost vmId vmUuid
---- ------- ---- ------ ---- ------
1498262401173035067 1614.06 4 qemu+tcp://root@10.252.1.30:16509/system i-332-2954-VM 9c002f94-8d24-437e-8af3-a041523b916aНа этом основная часть статьи завершается, далее посмотрим каким образом с помощью Grafana можно работать с сохраняемыми временными рядами.
Установка и настройка Grafana (Ubuntu)
Устанавливаем, как описано в документации
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.4.1_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_4.4.1_amd64.deb
sudo service grafana-server start
sudo update-rc.d grafana-server defaultsЗапускаем web-браузер и открываем административный интерфейс Grafana http://influx.host.com:3000/.
Добавление источника данных в Grafana
Детальная инструкция по добавлению источника данных на сайте проекта. В нашем же случае добавляемый источник данных может выглядеть следующим образом:
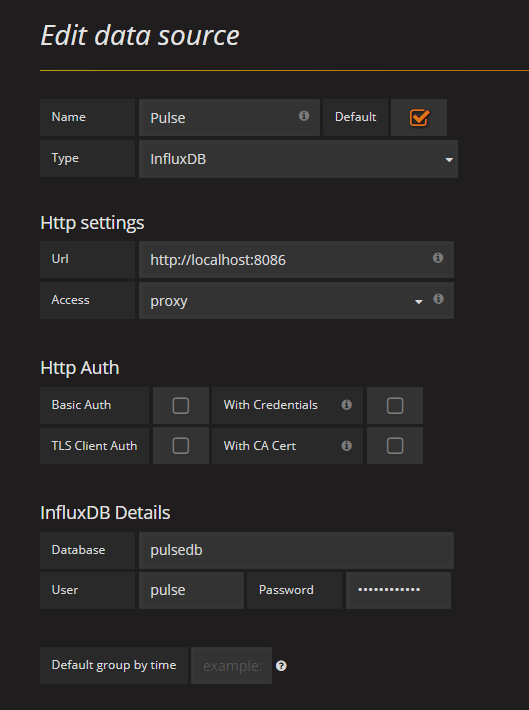
После сохранения источника данных, можно создать "дэшборды" и попробовать создавать запросы для графиков (поскольку данная инструкция не о том, как пользоваться Grafana, то привожу лишь выражения для запросов):
Загрузка CPU (минутки):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"), 1m) / LAST("cpus") / 60 * 100 from "cpuTime" where "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter group by time(1m)Загрузка CPU (пятиминутки):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"), 5m) / LAST("cpus") / 300 * 100 from "cpuTime" where "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter group by time(5m)Загрузка CPU (все VM):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"),1m) / LAST("cpus") / 60 * 100 as CPU from "cpuTime" WHERE $timeFilter group by time(1m), vmUuid
Память VM (пятиминутная агрегация):
SELECT MAX("rss") FROM "rss" WHERE "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter GROUP BY time(5m) fill(null)Статистика ReadBytes, WriteBytes для диска (пятиминутная агрегация):
select NON_NEGATIVE_DERIVATIVE(MAX("readBytes"),5m) / 300 from "disk" where "image" = '999a1942-3e14-4d04-8123-391494a28198' and $timeFilter group by time(5m)
select NON_NEGATIVE_DERIVATIVE(MAX("writeBytes"),5m) / 300 from "disk" where "image" = '999a1942-3e14-4d04-8123-391494a28198' and $timeFilter group by time(5m)Статистика ReadBits, WriteBits для NIC (пятиминутная агрегация):
select NON_NEGATIVE_DERIVATIVE(MAX("readBytes"), 5m) / 300 * 8 from "networkInterface" where "mac" = '06:07:70:00:01:10' and $timeFilter group by time(5m)
select NON_NEGATIVE_DERIVATIVE(MAX("writeBytes"), 5m) / 300 * 8 from "networkInterface" where "mac" ='06:07:70:00:01:10' and $timeFilter group by time(5m)Вся мощь языка запросов InfluxDB к вашим услугам, и Вы можете строить такие дэшборды, которые отвечают Вашим потребностям и позволяют производить наглядный анализ данных. Например, один из самых полезных для меня кейсов — это разбор инцидентов, бывает, что клиент жалуется на то, что "ваш код ****о" © и говорит, что его VM чудесно работала, а потом раз и все. Строим выражение, смотрим на картинку, видим как CPU его VM в течение часа уходил в пике и таки ушел. Скриншот — отличный аргумент при решении конфликта.
Еще можно анализировать самых интенсивно использующих различные ресурсы VM, чтобы мигрировать их на отдельные хосты. Да все, что угодно. В этом смысле Grafana, Kibana и подобные системы выгодно отличаются от традиционных систем мониторинга (например, Zabbix) тем, что позволяют делать анализ по требованию и строить комплексные аналитические наборы, а InfluxDB помогает обеспечить высокую производительность анализа даже на большом наборе данных.
Заключение
Код, получающий данные из LibVirt тестировался с VM, которые используют тома в QCOW2 формате. Я постарался учесть варианты LVM2 и RBD, но не тестировал. Если у кого-то получится протестировать код на других вариантах томов VM и прислать исправления для кода, буду признателен.
PS: При мониторинге сетевого трафика VM Вы можете обнаружить, что данные по PPS значительно меньше тех, которые Вы получаете посредством Sflow/Netflow на маршрутизаторе или tcpdump в VM. Это известное свойство KVM, сетевая подсистема которого не придерживается стандартного MTU в 1500 байт.
PPS: Документация по API LibVirt для python ужасна и мне пришлось продираться через разные версии, чтобы все же выяснить в каком виде возвращаются данные и что они означают.
PPS2: Если что, как говорят на Газорпазорпе, "Я рядом, если надо поговорить" ©
Комментарии (9)

SirEdvin
08.07.2017 22:27+1Зачем использовать influxdb, у которого есть определенные проблемы со стабильность и у которого платная кластеризация?
Почему не prometheus + libvirt_exporter?
ivankudryavtsev
09.07.2017 05:09+2Трудно сказать, зачем использовать продукт A, а не продукт B.
Наверное, моя мысль не так развивалась, когда я решил реализовать данный модуль. Я посмотрел что есть актуального среди TSDB, посмотрел бенчмарки и выбрал InfluxDB. Разработка заняла меньше двух дней, что вполне допустимо даже для неудачного PoC.
Если взять даже грубую оценку для сбора данных 1 раз в 30 секунд для 1000 хостов с 100 VM на каждом, то получается 100000 VM (~ 500000 точек). Скорее всего, данный масштаб еще нормально [обработается](https://www.influxdata.com/announcing-influxdb-v0-10-100000s-writes-per-second-better-compression/) одним сервером InfluxDB, а возможно, что и нет… Но, если вдуматься, то это уже задача иного масштаба, потому что 1000 серверов — это 30 стоек и это вполне приличные деньги, достаточные для применения подхода к решению задачи, который займет не два дня на реализацию. Возможно, что на данном этапе это уже будет какая-то другая технология, может быть платная кластеризация InfluxDB.
Что же до проблем со стабильностью, то я, к счастью, пока что их не наблюдаю. Вполне может быть, что они есть на масштабе, который я привожу выше, но за несколько месяцев использования пока что я существенных проблем не обнаружил.
В общем, хочу лишь сказать, что описанное мной решение работает и работает хорошо, а если будет хорошо работать и для других людей — волшебно.
Это, конечно, тред про администрирование, но для супермасштабных задач я бы попробовал Apache Kafka + Spark + RocksDB

timofei-durakov
09.07.2017 15:59Спасибо за статью.Только посмотрите еще в сторону аутентификации на libvirt.

raskal
09.07.2017 15:59В статистике по дискам есть такие поля:
«allocatedSpace»: 890,
«onDiskSpace»: 890,
«totalSpace»: 1000
Подскажите, что они значат в контексте libvirt?ivankudryavtsev
09.07.2017 16:05В зависимости от типа Storage, например файлы в формате qcow2, диск может иметь фактический размер не совпадающий с задекларированным в связи с «ленивым» выделением. TotalSpace — размер диска как его видит vm, а onDiskSpace — сколько на диске фактически занято, allocatedSpace не могу сказать значение, надо смотреть документацию libvirt.
Для raw файлов и блочных устройств все три должны совпадать.raskal
09.07.2017 16:41Вот интересно как раз понять, как onDiskSpace считается. Хотелось бы знать не только, сколько выделено диска (это можно и из бэкенда узнать, если там, например, OpenStack или просто Ceph), но и сколько его реально используется вмкой (потому что ни один бэкенд такой информации не даст, конечно же).
ivankudryavtsev
10.07.2017 05:49Для Qcow2 — сколько файл на диске занимает, столько и выдается. А вот сколько используется VM-кой (типа df -h) — на такой вопрос ответить не получится. Насколько я понимаю, qcow2 online trim не поддерживает.
denissa
Доброго времени суток! Понравились ваши статьи. После прочтения их у меня появилось к Вам несколько вопросов. Не оставите мне свой контактный e-mail для связи?
ivankudryavtsev
Добрый вечер. Ответил в личные сообщения.