
Автор: Николай Хабаров, Embedded Expert DataArt, евангелист технологий умного дома.
Результаты тестов, приведенные в статье о сравнении производительности плат Raspberry Pi3 и DragonBoard при работе с приложениями на Python, вызвали сомнения у некоторых коллег.
В частности, под материалом появились такие комментарии:
«… я делал бенчмарки между 32х битными ARM'ами, между 64х битными и между Intel x86_64 и все цифры были сопоставимы. как минимум между 32 битными и 64 битными ARM'ами разница была в десятки процентов, а не в разы. ну или вы просто разное чисто --cpu-max-prime указали».
«Удивительные результаты обычно означают ошибку эксперимента».
«есть подозрение, что в тесте CPU какая-то ошибка. я лично тестил разные ARMы sysbench'ом, но разницы в 25 раз и близко не было. в принципе хороший медиа ARM в CPU тесте может быть в несколько раз эффективней чем BCM2837, но ни как не в 25 раз. подозреваю, что тест для pi был сделан в один поток, а для DragonBoard в 4 потока(4 ядра)».
Речь идет о тесте cpu из пакета тестов sysbench. Ответ на эти предположения получился настолько объемным, что я решил опубликовать его отдельным постом, заодно рассказав о том, почему в некоторых задачах разница может быть настолько колоссальной.
Начнем с того, что команды со всеми аргументами для теста были указаны в таблице оригинальной статьи. Разумеется, никакого аргумента --cpu-max-prime или других аргументов, заставляющих использовать несколько ядер процессора, там нет. В части о 10-20%-ной разнице, возможно, имелся ввиду тест общей производительности системы, который на реальных приложениях (не всегда, конечно, но, скорее всего) как раз и покажет 10-20 % разницы между 32-битным и 64-битным режимами одного и того же процессора.
В принципе, почитать, как реализуются математические операции с разрядностью большей разрядности машинного слова, можно, например, вот здесь. Переписывать алгоритмы смысла нет. Скажем, умножение займет примерно в 4 раза больше тактов процессора (три умножения + операции сложения). Естественно это величина может варьироваться от процессора к процессору и в зависимости от оптимизации компилятора Например, для обыкновенного x86 процессора разницы может и не быть, т. к. еще с появлением набора инструкций MMX появилась возможность использовать 64-битные регистры и 64-битные вычисления на 32-битном процессоре. А с появлением SSE появились 128-битные регистры. Если программа скомпилирована с использованием таких инструкций, то она может выполняться даже быстрее, чем 32-битные вычисления, разница в 10-20 % и даже более может наблюдаться уже в другую сторону, т. к. тот же набор инструкции MMX может выполнять несколько операций одновременно.
Но речь все же о синтетическом тесте, который явно использует 64-битные числа (исходные коды доступны тут), и так как пакет взят из официального репозитория, не факт, что при сборке пакета были включены все возможные оптимизации (все из-за той же совместимости с другими ARM-процессорами). Например, процессоры ARM начиная с v6 поддерживает SIMD, который, как MMX/SSE на x86, может работать с 64-битной и 128-битной арифметикой. Мы не задавались целью выжать как можно больше «попугаев» из тестов, нам интересно реальное положение дел при установке приложений «из коробки», т. к. мы не хотим майнтейнить еще половину операционной системы.
Все еще не верите, что даже «из коробки» скорость на одном и том же процессоре не может отличаться в десять раз в зависимости от режима процессора?
Ну хорошо, давайте возьмем ту же DragonBoard.
sysbench --test=cpu runНа этот раз со скриншотами:
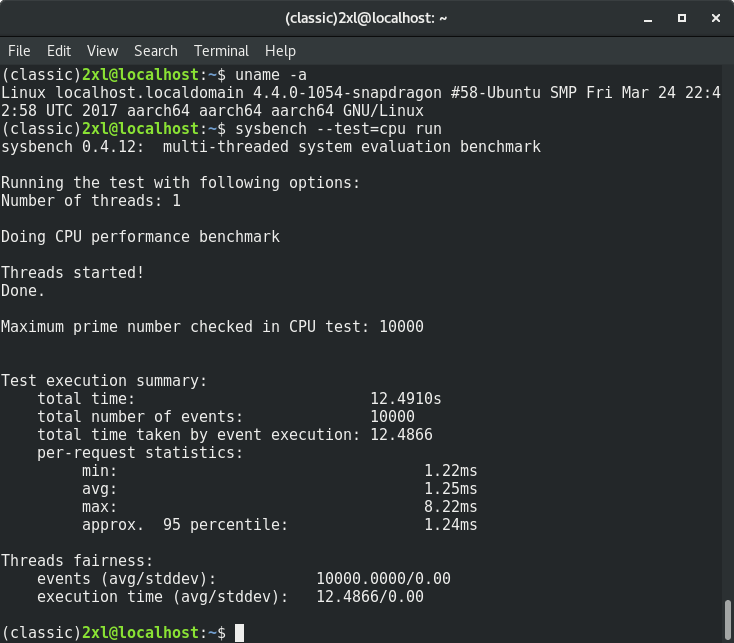
12.4910 секунды. Хорошо, теперь на этой же плате:
sudo dpkg --add-architecture armhf
sudo apt update
sudo apt install sysbench:armhfЭтим командами мы установили 32-битную версию пакета sysbench на ту же плату DragonBoard.
И снова:
sysbench --test=cpu runИ вот он скриншот (наверху виден вывод apt install):

156.4920 секунды. Разница более 10 раз. Раз уж заговорили о подобных случаях, давайте разберемся подробнее почему. Напишем вот такую простенькую программу на С:
#include <stdint.h>
#include <stdio.h>
int main(int argc, char **argv) {
volatile uint64_t a = 0x123;
volatile uint64_t b = 0x456;
volatile uint64_t c = a * b;
printf("%lu\n", c);
return 0;
}Ключевое слово volatile мы используем для того чтобы компилятор не посчитал все заранее, а именно присвоил бы переменные и сделал честное умножение двух произвольных 64-битных чисел. Соберем программу для обеих архитектур:
arm-linux-gnueabihf-gcc -O2 -g main.c -o main-armhf
aarch64-linux-gnu-gcc -O2 -g main.c -o main-arm64А теперь посмотрим дизассемблер для arm64:
$ aarch64-linux-gnu-objdump -d main-arm64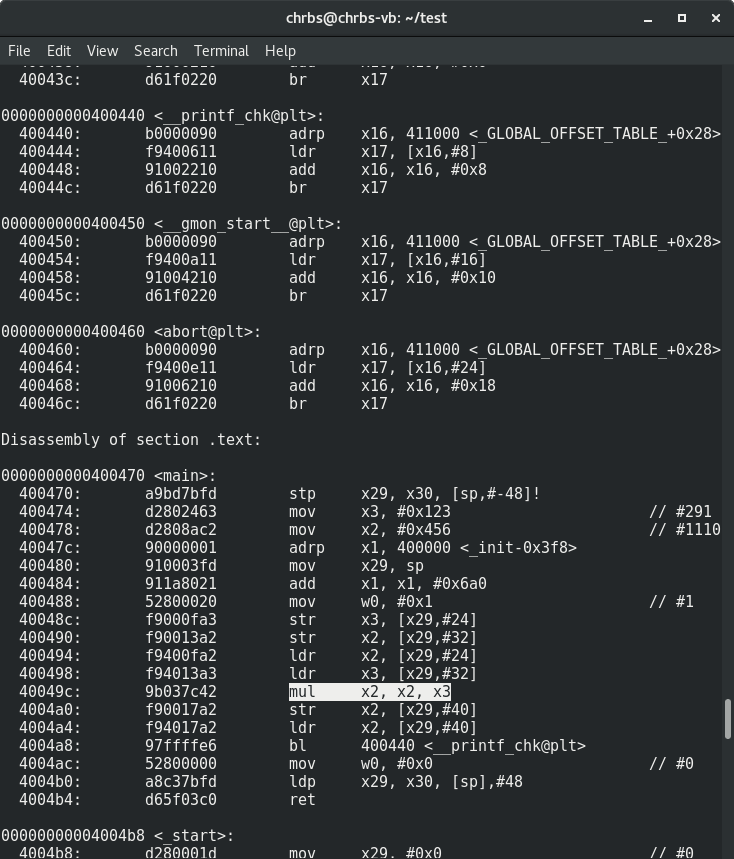
Довольно предсказуемо использована инструкцию mul. А теперь для armhf:
$ arm-linux-gnueabihf-objdump -d main-armhf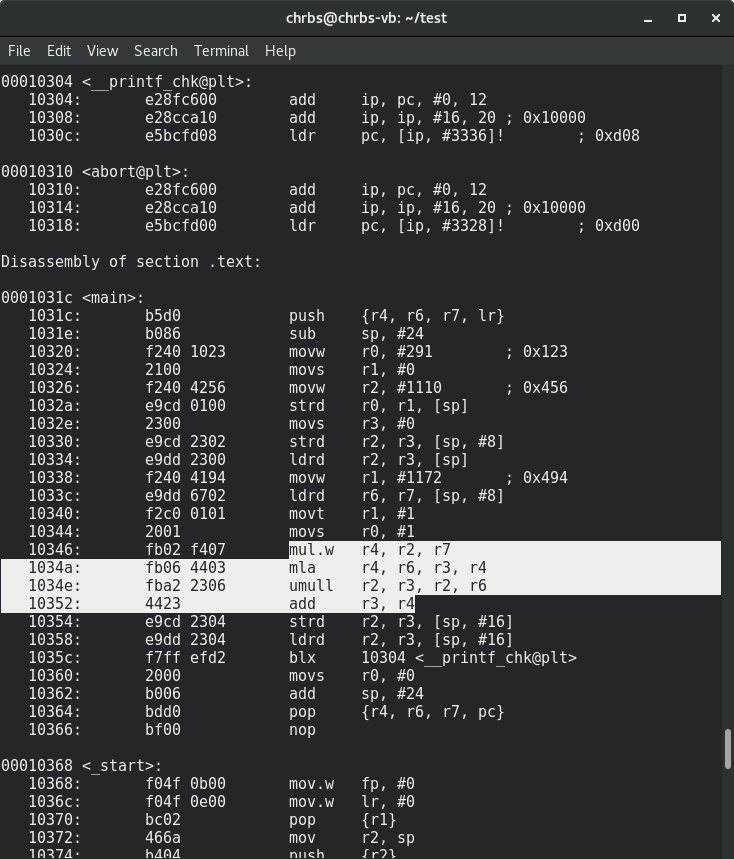
Как видите, компилятор применил один из методов длинной арифметики. И как следствие мы наблюдаем целую портянку, которая использует в том числе довольно тяжеловесные инструкции mul, mla, umull. Отсюда и многократная разница в производительности.
Да, можно еще попробовать скомпилировать, включив какой-либо набор инструкций, но тогда мы, возможно, потеряем совместимость с каким-нибудь процессором. Опять же повторимся, нас интересовала реальная скорость работы всей платы с реальными двоичными пакетами. Надеемся, этого обоснования, почему на конкретном тесте cpu была получена такая разница, достаточно. И вас не будут смущать такие разрывы в некоторых тестах и, возможно, некоторых прикладных программах.
Комментарии (10)

abstracto
18.07.2017 19:56+4нет, ну вот вы странные люди если честно. окей, молодцы, вы знаете ассемблер. окей, значит я на своём rk3368 имел armhf, а не arm64 (что мой косяк в критике вас).
но блин, в любом случае получается, что вы вставили в свою прошлую статью тест совершенно не показательный, который говорит лишь о том, что 64 битные числа этот arm дробит в 25 раз лучше, чем raspberi pi
Но если тестить общую эффективность, то ваша табличка должна быть такой:
Raspberry Pi3: 318.1229s
DragonBoard 410c: 156.492s
и мы видим, что разница в 2 раза и мы — этому верим. и без пафосных постов о том какие вы умные на самом деле (ведь этого никто не оспаривал).
Anyway, спасибо, что не поленились сделать ещё тесты и поделится результатами. это в любом случае правильно и хорошо.
Dmitri-D
19.07.2017 04:44+1секундочку. На Raspberry Pi3 стоити BCM2837, который ARM Cortex A53 (ARMv8), т.е. 64битные инструкции ему не чужды
izzholtik
19.07.2017 10:27Разве уже выпустили живую 64-битную ось?
Dmitri-D
20.07.2017 06:48Разве уже выпустили живую 64-битную ось?
живая ось собирается примерно за час, при наличии знаний. Знания собираются дольше.
Готовых примеров сборки ядра линукс для Pi3 — уже немало. Вот пример тут https://devsidestory.com/build-a-64-bit-kernel-for-your-raspberry-pi-3. И я использую, кстати, тоже Debian на DragonBoard 410C.
А вот для ARMv7 платках использую Ubuntu. Так исторически сложилось.
ValdikSS
22.07.2017 19:10Это вообще беда современных ARM'ов и бинарных дистрибутивов. Один SoC поддерживает одно, другой — другое, и хоть с приходом AArch ситуация стала лучше, в плане начальной поддержки фич, все равно все не идеально, многие технологии конкретных процессоров не используются.
Я об этом еще в 2012 писал: https://habrahabr.ru/post/146877/Dmitri-D
23.07.2017 04:45так дело в том, что АРМ — это не процессор и не фирма-изготовитель. Это лицензируемый набор спецификаций. А изготовителей уже воз и маленькая тележка. Каждый поверх армовских спецификаций прилепливает своё.
Что касается qualcomm по сравнению с broadcom — тут немного другое. Первый позиционируется как hi-end, и вылизывает свои изделия. А broadcom — более дешевый ширпотреб, он, соответственно, медленнее, но и доступнее. В тестах запускался один и тот же код, поэтому сравнивались одни и те же фичи, входящие в базовый набор.
bazil
Вы верно все написали, но ваши тесты похожи на манипуляцию — запускать операции которые на одном девайсе заведомо выполняются быстрее и назвать это тестом — имхо, странно.
romxx
Это настолько, к сожалению, распространено, что для этого даже есть специальное слово: «benchmarketing»