Более ста лет назад немецкий психолог Уильям Штерн (William Stern) предложил тест оценки интеллекта человека, который получил название теста IQ. С тех пор тест IQ получил довольно широкое распространение как стандартная методика для оценки интеллекта детей при поступлении в школу, а также для оценки взрослых кандидатов на работу.
Тесты IQ обычно содержат три типа вопросов: 1) вопросы на логику, где нужно распознать шаблон в последовательности изображений; 2) математические вопросы, где нужно определить шаблон в последовательности чисел; 3) словесные задачи, основанные на аналогиях и классификациях, как синонимы и антонимы.
Исследователи из подразделения Microsoft Research в Пекине совместно с коллегами из университета науки и технологий Китая разработали технологию ИИ, способную решать третий тип задач из перечисленных выше (научная статья).
Компьютеры никогда не могли хорошо разбираться и решать задачи, сформулированные в словесном виде. По крайней мере, они делали это гораздо хуже людей. Разработка Microsoft Research меняет положение вещей. Их программа, основанная на системе глубинного обучения (deep learning), впервые превзошла средний результат, показанный людьми, при решении вербальных задач из теста на IQ.
В прежние годы учёные использовали технику дата-майнинга для анализа больших объёмов текстов, чтобы найти определённые связи между словами. В частности, эта техника позволяет составить словарь со статистическими показателями, как часто те или иные слова располагаются рядом. Это позволяет определить взаимоотношения слов друг с другом.
В результате, каждое слово в такой системе воспринимается как вектор в многомерном пространстве параметров. Подобную систему векторов можно обрабатывать математическими методами: сравнивать их, складывать, вычитать друг из друга, как обычные векторы. Например, становится возможным подобное уравнение: «король — мужчина + женщина = королева».
Такой подход доказал свою эффективность. Например, Google использует дата-майнинг в системе автоматического перевода текстов, сравнивая векторы слов на разных языках.
Но в случае вербальных тестов IQ задача усложняется, потому что здесь у одного слова может быть несколько значений. Составители тестов специально делают так, чтобы усложнить задачу.
Группа исследователей из подразделения Microsoft Research нашли решение для этой проблемы с помощью того же дата-майнинга: их программа определяет, с какими словами чаще всего встречается каждое слово в массиве текстов, а затем определяет возможные значения этого слова, на основе полученной информации. Это делается путём вычисления векторов из полученных предложений. Для программы сначала составляется матрица частоты встречаемости слов, а затем на базе корпуса текстов (статьи Википедии) для каждого слова указывается вектор встречаемости вместе с ним других слов.
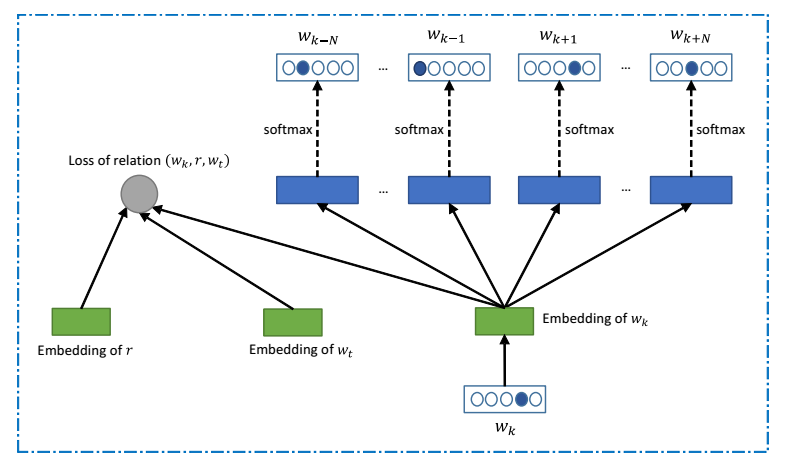
Учёные заявляют, что программа показывает лучший результат, чем у большинства людей. Опрос людей проводился на сайте Mechanical Turk.
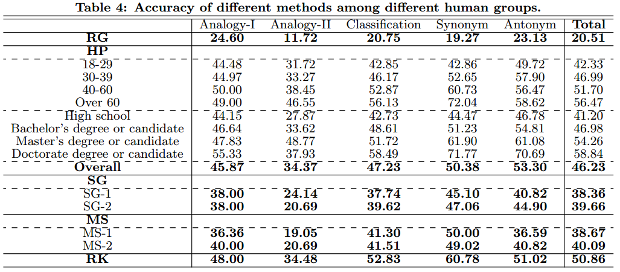
Согласно таблице, её результат находится примерно посередине между результатами, которые показывают средними результатами бакалавры и обладатели магистерской степени.
Тесты IQ обычно содержат три типа вопросов: 1) вопросы на логику, где нужно распознать шаблон в последовательности изображений; 2) математические вопросы, где нужно определить шаблон в последовательности чисел; 3) словесные задачи, основанные на аналогиях и классификациях, как синонимы и антонимы.
Исследователи из подразделения Microsoft Research в Пекине совместно с коллегами из университета науки и технологий Китая разработали технологию ИИ, способную решать третий тип задач из перечисленных выше (научная статья).
Компьютеры никогда не могли хорошо разбираться и решать задачи, сформулированные в словесном виде. По крайней мере, они делали это гораздо хуже людей. Разработка Microsoft Research меняет положение вещей. Их программа, основанная на системе глубинного обучения (deep learning), впервые превзошла средний результат, показанный людьми, при решении вербальных задач из теста на IQ.
В прежние годы учёные использовали технику дата-майнинга для анализа больших объёмов текстов, чтобы найти определённые связи между словами. В частности, эта техника позволяет составить словарь со статистическими показателями, как часто те или иные слова располагаются рядом. Это позволяет определить взаимоотношения слов друг с другом.
В результате, каждое слово в такой системе воспринимается как вектор в многомерном пространстве параметров. Подобную систему векторов можно обрабатывать математическими методами: сравнивать их, складывать, вычитать друг из друга, как обычные векторы. Например, становится возможным подобное уравнение: «король — мужчина + женщина = королева».
Такой подход доказал свою эффективность. Например, Google использует дата-майнинг в системе автоматического перевода текстов, сравнивая векторы слов на разных языках.
Но в случае вербальных тестов IQ задача усложняется, потому что здесь у одного слова может быть несколько значений. Составители тестов специально делают так, чтобы усложнить задачу.
Группа исследователей из подразделения Microsoft Research нашли решение для этой проблемы с помощью того же дата-майнинга: их программа определяет, с какими словами чаще всего встречается каждое слово в массиве текстов, а затем определяет возможные значения этого слова, на основе полученной информации. Это делается путём вычисления векторов из полученных предложений. Для программы сначала составляется матрица частоты встречаемости слов, а затем на базе корпуса текстов (статьи Википедии) для каждого слова указывается вектор встречаемости вместе с ним других слов.
Учёные заявляют, что программа показывает лучший результат, чем у большинства людей. Опрос людей проводился на сайте Mechanical Turk.
Согласно таблице, её результат находится примерно посередине между результатами, которые показывают средними результатами бакалавры и обладатели магистерской степени.
ServPonomarev
Вот отечественный подход к получению для одного слова нескольких векторных репрезентаций. По одной репрезентации на каждый из смыслов этого слова:
bayesgroup.ru/adagram
Кстати, для русского языка такая задача решалась на последнем Диалоге, с точностью ассоциаций в 98+ процентов. russe.nlpub.ru/results