Однако, к сожалению, до сих пор я не встречал хорошего русскоязычного материала — да в общем и с англоязычными, чего уж тут греха таить, та же проблема, там тоже многих журналистов изнасиловали учёные — в котором внятно раскладывалось бы по полочкам, что именно произошло 3 января 2018 года, и как мы будем с этим жить дальше.
Попробую восполнить пробел, при этом и не слишком влезая в глубины работы процессоров (ассемблера не будет, тонких подробностей постараюсь избегать там, где они не нужны для понимания), и описывая проблему максимально полно.
Тезисно: в прошлом году нашли, а в этом опубликовали информацию о самой серьёзной ошибке в процессорах за все десятилетия их существования. В той или иной степени ей подвержены все процессоры, используемые в настоящее время в настольных компьютерах, серверах, планшетах, смартфонах, автомобилях, самолётах, поездах, почте, телефоне и телеграфе. То есть — вообще все процессоры, кроме микроконтроллеров.
К счастью, подвержены они ей в разной степени. К несчастью, самый серьёзный удар пришёлся на самые распространённые процессоры — Intel, причём затронул он абсолютно все выпускающиеся и практически все эксплуатируемые (единственным исключением являются старые Atom, выпущенные до 2013 года) процессоры этой компании.
До сих пор вся система обеспечения информационной безопасности на локальном компьютере в основе своей полагалась на одну предпосылку: центральный процессор способен гарантированно обеспечить полную изоляцию выполняющихся на нём программ друг от друга, поэтому при условии отсутствия ошибок в ПО различные процессы не имеют доступа к данным друга друга, если такой доступ не был предоставлен в явном виде.
Уберите эту предпосылку — и всё остальное рушится, как карточный домик.
Конкретно в архитектуре x86 защищённый режим был представлен в процессорах 80286 и доведён до ума в 80386. При работе в нём приложения вместо прямого доступа к физической памяти получают виртуальные адресные пространства, отображаемые на физическую память так, что пространства разных приложений не пересекаются. Контроль за адресными пространствами реализован аппаратно — блоком MMU, Memory Management Unit — поэтому, если при запуске нового процесса ОС корректно выделила ему память, попытка вылезти за пределы этой памяти будет немедленно пресечена процессором. Кроме того, участки памяти могут иметь разные уровни доступа, контроль за которыми также осуществляет MMU — в результате пользовательское приложение не сможет получить доступ к памяти, занимаемой ядром системы или драйверами, даже если соответствующие адреса формально ему доступны.
Всё было хорошо, пока не выяснилось, что сам процессор в ходе отработки своих внутренних алгоритмов может целенаправленно игнорировать MMU, а результаты работы этих алгоритмов могут быть косвенными путями получены программно.
Все современные процессоры — если мы говорим конкретно про Intel x86, то это модели начиная с Atom 2013-го года, Pentium Pro и Pentium II — имеют функции спекулятивного выполнения инструкций и предсказания ветвлений, а также кэши инструкций и данных.
Эти алгоритмы необходимы для обеспечения высокой производительности всей системы при условии, что все имеющиеся периферийные устройства, включая оперативную память, значительно медленнее центрального процессора. В случае, когда очередная выполняемая инструкция приводит к необходимости ожидания поступления данных снаружи, в течение периода ожидания процессор вместо простаивания начинает выполнять следующий за данной инструкцией код, исходя из ожиданий о том, какие именно данные с наибольшей вероятностью поступят.
Например:
if (x < array1_size)
{
y = array1[x]
}При последовательном выполнении этого кода процессор сначала проверяет, что переменная x находится в пределах массива array1, а потом выполняет вторую строку. При спекулятивном выполнении после какого-то количества if'ов, в которых действительно x < array1_size, процессор начинает считать, что данное условие с высокой вероятностью выполняется. поэтому начинает выполнение второй строки, не дожидаясь вычисления условия.
Что случается, если результат вычисления условия вдруг оказывается негативным? Процессор просто отбрасывает все предварительно вычисленные результаты и проводит вычисления заново, на этот раз уже последовательно. Одновременно модуль предсказания ветвлений снижает оценку вероятности того, что данное условие будет выполняться.
Что случается, если переменная x оказывается расположенной не просто за пределами конкретного массива, а вообще за пределами доступной данному процессу памяти? Процессор всё равно выполняет вторую строку кода. Дело в том, что на работу модуля MMU, в задачу которого входит определение, разрешено ли вообще данному процессу что-то читать по адресу x, также нужно время, поэтому механизм спекулятивного выполнения относится к MMU ровно тем же образом, как и к внешним шинам — он начинает выполнение до того, как из MMU поступит ответ о корректности этого кода.
Если MMU сообщает, что код некорректен, в эту память нельзя — процессор просто сбрасывает всё насчитанное.
Длина «забегания вперёд» у современных процессоров легко может составлять десятки инструкций.
На этой стадии всё пока ещё хорошо. Программа не знает о том, что происходит внутри процессора, если спекулятивное выполнение было самим процессором признано неудачным — его результаты ни одним из формальных путей в приложение не попадают (они не сохраняются ни в ОЗУ, ни в регистрах процессора). Всё, что можно зафиксировать снаружи — небольшую просадку темпа выполнения инструкций в момент, когда процессор понял, что кусок кода надо выполнить заново, и сбросил уже посчитанный результат и загруженные на конвейер команды (кто помнит дискуссии вокруг производительности Pentium 4, земля ему пухом, — там как раз был очень длинный конвейер, сброс которого обходился, соответственно, довольно дорого).
Но у процессора есть ещё один блок, и этот блок работает полностью самостоятельно — это кэш. В кэш ложатся все данные, прошедшие через процессор. Кэш, повторюсь, совершенно автономен — он не знает и не хочет знать, почему и как эти данные в него свалились, были ли они загружены в результате спекулятивного или последовательного выполнения, было ли спекулятивное выполнение признано корректным или нет. Данные пришли — данные легли в кэш.
То есть, если в рамках спекулятивного выполнения команд случится следующая последовательность:
- Прочитано значение по адресу в памяти N
- Получен ответ от MMU о невалидности данного адреса в контексте данного процесса
- Результаты чтения адреса сброшены из регистров процессора
То в кэше спокойно останется лежать значение, хранящее по адресу N.
Но и этого ещё мало, так как кэш — это внутреняя сущность процессора, ПО не может напрямую его читать. Однако, если ПО снова обратится по адресу N, то по скорости ответа процессора оно сможет определить, хранится ли соответствующее значение в кэше (быстрый ответ) или нет (медленный ответ).
И вот тут мы подбираемся к интересной части: ПО всё ещё не может напрямую прочитать некий адрес N, находящийся за пределами его доступа, но уже может определить, читался ли этот адрес кем-либо ранее.
Но ведь наше ПО по-прежнему не может в открытую читать адрес N, не так ли? Так. Но тут всё уже совсем просто: у современных процессоров есть процедуры косвенной адресации, указывающие, что процессор должен прочитать значение X, лежащее по адресу Y, а потом — значение Z, лежащее по только что прочитанному X. Ну да, работа с указателями.
Представьте, что у нас есть доступная приложению область памяти, поделённая на два куска с разными приоритетами — у одного приоритет собственно приложения, у другого приоритет ядра. Так
И, допустим, приложению в этом куске доступны адреса 0...9999, а ядру — 10000...20000, цифры тут неважны. И мы делаем конструкцию, расположенную в коде так, что процессор заведомо выполнит её в спекулятивном режиме (например, на тысячном повторении одного и того же цикла, 999 предыдущих повторений которого выполнялись корректно), и которая будет представлять собой косвенную адресацию по значению, лежащему по адресу 15000.
- Процессор в спекулятивном режиме читает значение по адресу 15000. Пусть там будет лежать, например, 98.
- Процессор читает значение, лежащее по адресу 98.
- От MMU приходит ответ о невалидности адреса 15000.
- Процессор сбрасывает конвейер и вместо значения, лежащего по адресу 98, выдаёт нам ошибку.
- Наше приложение начинает читать адреса от 0 и выше в собственном адресном пространстве (имеет полное право), замеряя время, требующееся на чтение каждого адреса, и читая их не по порядку, чтобы не натренировать тот же спекулятивный доступ
- На адресе 98 время доступа вдруг оказывается в несколько раз ниже, чем на других адресах
Таким образом мы понимаем, что кто-то уже недавно читал что-то по этому адресу, в результате чего он попал в кэш. Кто бы это мог быть? Ах, да, это наш дорогой процессор. По адресу 15000, соответственно, лежит значение 98.
Таким образом мы можем прочитать всю память ядра системы, на которую, в свою очередь, в современных ОС отображается вообще вся физическая память компьютера.
Это называется Meltdown (CVE-2017-5754), и эта уязвимость полностью перечёркивает все имеющиеся в процессоре защитные механизмы.
Кто подвержен Meltdown?
Как минимум все процессоры Intel линейки Core, все процессоры Intel линейки Xeon, все процессоры Intel линеек Celeron и Pentium на ядрах семейства Core.
Также подвержены уязвимости процессоры на ядрах ARM Cortex-A75, на которых, однако, пока что не выпущено каких-либо конечных устройств, а первый процессор — Qualcomm Snapdragon 845 на ядре Kryo 385, основанном на Cortex-A75 и Cortex-A53 — объявлен только месяц назад. Скорее всего, Kryo 385 также будет уязвим к Meltdown.
Согласно заявлению Apple, «все iOS-устройства» подвержены Meltdown. Это, очевидно, не может относиться к вообще всем когда-либо использовавшимся в iPhone/iPad процессорам (в конце концов, какой-нибудь iPhone 4 использует стандартное ядро Cortex-A8), но ARM-процессоры в современных моделях iPhone и iPad можно считать уязвимыми.
Кто не подвержен Meltdown?
Здесь чуть вопрос сложнее, поэтому сначала переформулируем его так: на данный момент не удалось — и, возможно, не удастся никогда — показать уязвимость Meltdown на процессорах AMD и ARM Cortex, отличных от перечисленных выше.
В оригинальной работе, публично открывающей подробности Meltdown, указывается, что на этих процессорах также были замечены изменения состояния кэша в результате спекулятивного выполнения инструкций, однако полезные данные получить не удалось.
Возможно, логика работы данных процессоров такова, что практическая реализация уязвимости на них невозможна вообще — например, MMU успевает прервать спекулятивное выполнение до того, как процессор прочитает вторую ячейку памяти; в этом случае в кэше окажется значение первой ячейки (лежащей в недоступной нам области), что не позволит эксплуатировать уязвимость.
Кроме того, ARM заявляет об уязвимости ядер Cortex-A15, Cortex-A57 и Cortex-A72 — формально компания относит эту уязвимости к Meltdown, называя оригинальный Meltdown «Variant 3», а обнаруженный в данных ядрах — «Variant 3a»
На этих ядрах сделано довольно много процессоров, например, Samsung Exynos 5 и Exynos 7 (смартфоны Galaxy S5, Galaxy S6, Galaxy Note с 3 по 7), Qualcomm Snapdragon 650, 652, 653, 808 и 810, Mediatek Helio X20.
К счастью, «Variant 3a», хотя и аналогичен «взрослому» Meltdown по причинам, сильно слабее по эффекту — он позволяет атакующему украсть содержимое не произвольных областей памяти, а лишь отдельных системных регистров процессора, пусть формально и недоступных на том уровне привилегий, который есть у атакующего.
Это позволяет облегчённо выдохнуть и считать данные три ядра и все сделанные на них смартфоны фактически атаке не подверженными.
Про кого мы не знаем, подвержен ли он Meltdown?
Есть масса процессоров, которые ещё толком никто не проверял — как минимум потому, что «оглушающий успех» Intel затмил всех остальных. С хорошей вероятностью не подвержен MIPS. Про более маргинальные архитектуры сказать ничего нельзя, и, вероятно, до них ещё долго никто не доберётся.
Если вас интересуют отечественные процессоры, то у Эльбруса своя архитектура, Байкал-Т1 построен на ядре MIPS P5600, Элвис — тоже на MIPS. С большой вероятностью они не подвержены Meltdown, хотя пока что в открытом виде информации об этом нет. Байкал-М построен на ядре Cortex-A57 и, соответственно, подвержен Meltdown.
Наконец, неизвестен статус кастомизированных ARM-ядер — это, например, Samsung Mongoose (серия процессоров Exynos 8, смартфоны Galaxy S7, Galaxy S8, Galaxy Note 8), Qualcomm Krait и Kryo 2xx, HiSilicon Kirin и прочих — но с большой вероятностью они в значительной степени похожи на своих ровесников из стандартной линейки.
Можно ли защититься от Meltdown программно?
Да. Meltdown эксплуатирует игнорирование процессором уровней доступа к памяти, но не позволяет читать память, находящуюся за пределами выделенного приложению виртуального блока.
Для всех распространённых ОС уже вышли или готовятся выйти патчи, переносящие область памяти ядра в другую облась, т.е. обеспечивающие защиту не только выставлением привилегий, но и контролем доступа по адресам — второе Meltdown обойти не может.
Проблема в том, что при такой архитектуре системные вызовы (syscalls) становятся крайне накладными — они замедляются в несколько раз. Соответственно, реальные приложения также теряют в производительности, в зависимости от доли системных вызовов в конкретном приложении падение может составить от 1-2 до нескольких десятков процентов. Например, на PostgreSQL продемонстрировано падение более 20 %, в то время как в игрушках разницы практически нет.
Кроме того, при подобном переключении страниц памяти принудительно сбрасывается TLB, Translation Lookaside Buffer — это кэш трансляций между виртуальной памятью и физической, когда меняется блок виртуальной памяти, он с очевидностью становится невалидным. В свежих процессорах Intel есть так называемый PCID, идентификатор процесса, который позволяет не сбрасывать весь TLB разом, а определить, к какому процессу какая запись имеет отношение. Использование PCID (он должен поддерживаться и ОС, и процессором) снижает потери на переключение между двумя кусками памяти, но не устраняет их полностью.
Меньше всего угроза для игр и иных пользовательских десктопных приложений, так как они мало используют системные вызовы — в абсолютном большинстве из них падение производительности не превысит 3 %, что можно считать погрешностью измерений. Впрочем, всегда могут быть исключения в лице отдельных приложений.
По этой причине данное поведение в ОС, скорее всего, будут включать только на процессорах, про которые известно, что они подвержены уязвимости. Тут тоже могут быть нюансы: например, в свежих патчах для ядра Linux есть не чёрный список уязвимых, а белый список неуязвимых, и в него пока входят только AMD.
Когда не нужно защищаться от Meltdown?
Meltdown относится к сугубо локальным атакам и подразумевает выполнение кода на вашем компьютере. Если никакой посторонний код, включая высокоуровневые языки, проникнуть на конкретный компьютер не может, Meltdown не опасен.
При этом не надо забывать, что Javascript в браузере — это тоже локально выполняющийся код. Разработчики браузеров сейчас предпринимают усилия (по состоянию на 4 января Firefox 57.0.4 уже вышел, соответствующая версия Chrome ожидается до конца месяца) по снижению эффективности использования JS для подобных атак, например, сознательно загрубляют доступные таймеры так, чтобы JS-код не смог достоверно измерить время доступа к памяти, но эти меры лишь снизят эффективность атак, но не исключат их полностью.
Если у вас стоит домашний сервер, который доступен только по сети, а софт на него вы устанавливаете исключительно из репозитария вашего любимого дистрибутива, то опасность для него будет заключаться только в сочетании Meltdown с каким-либо классическим эксплоитом, позволяющим подсадить вам «жучка» удалённо. Для атакующего удобство Meltdown будет заключаться в том, что с ним «жучку» не обязательно иметь какие-либо конкретные привилегии на атакуемой системе, достаточно запуститься на ней любым образом. С другой стороны, Meltdown позволяет только читать память, но не изменять её или выполнять какой-либо код. С третьей стороны, так как до недавних пор память считалась сравнительно безопасным местом временного хранения данных, то все ваши пароли и сертификаты лежат в ней в открытом виде.
Поэтому лучше поставьте патч сразу, как только он будет доступен для вашей ОС.
Несколько печальна может оказаться ситуация со смартфонами на Android, половина производителей которых известно в какого цвета тапочках видела все эти обновления — но, с другой стороны, у ARM подвержены Meltdown только новые старшие ядра, в то время как большинство неподдерживаемого ширпотреба сделано на старых и/или упрощённых ядрах.
Покажите мне, как вы с этим рутовый доступ получите!
Самое бессмысленное требование в дискуссиях о Meltdown. Уязвимости процессора не требуют обращения к верхнеуровневым абстракциям операционной системы — они даже не обходят их, они их просто не замечают.
В этом и есть самая большая опасность эксплоита Meltdown — он никак не взаимодействует с операционной системой, а значит, не только практически не зависит от неё, но и не оставляет в ней никаких следов.
Смогут ли антивирусы определять эксплуатирующее Meltdown ПО?
В общем случае — нет. В частном — они смогут определять ПО, про которое иными путями стало известно об эксплуатации им уязвимости, но в самом коде ничего однозначно нелегитимного нет, так что попытка эвристического определения может привести к большому количеству ложноположительных срабатываний.
Придумало ли Meltdown ЦРУ или KGB?
Нет, им не надо. Если они очень захотят заложить в ваш процессор закладку — они вежливо попросят производителя добавить какой-нибудь специализированный модуль, по типу JTAG, который спокойно позволит кому положено читать что ему надо напрямую. Сложность современных ядер такова, что этот модуль никто вообще никогда не заметит, а если и заметит, то у него прошивка всё едино будет в зашифрованном виде «для обеспечения безопасности наших пользователей».
Сделала ли Intel это специально, чтобы мы купили новые процессоры?
Разумеется, нет. Во-первых, глупо предполагать, что Intel запланировала это за двадцать лет до реального использования и в надежде, что никто раньше не обнаружит случайно. Во-вторых, цикл проектирования и выпуска нового процессора — не меньше пары лет (что неплохо видно по выпуску железа на лицензируемых ядрах, будь то ARM или MIPS; в случае AMD или Intel мы не знаем, когда реально было закончено проектирование ядра, а видим только работу маркетингового отдела, по которой создаётся впечатление, что там всех дел на полгодика — тут, как говорится, «хорошо вам, товарищ политрук, рот закрыл — рабочее место убрано»). В-третьих, кстати, про ARM, на примере которого видно, что уязвимость может появиться в ядрах процессоров в любой момент, в том числе в новейших топовых моделях — говоря проще, до сих пор никто не задумывался о функционировании связки из MMU, кэша и предсказания ветвлений как о потенциально уязвимой области, а выбирал их алгоритмы, исходя из иных предпосылок. В-четвёртых, трудно представить удара по Intel больнее, чем быстрый выпуск линейки исправленных процессоров: влияние этого на продажи моделей, которыми уже завалены склады, представляете?
Так что готовьтесь к тому, что 9-е поколение Intel Core будет иметь ту же уязвимость в полном объёме и полном составе.
Хотя многие действительно рано или поздно задумаются о новом процессоре. Подозреваю, в AMD сейчас по этому поводу второй раз за неделю фейерверки и шампанское.
Компания <Intel | AMD | ARM | Microsoft | Google | Amazon | etc.> заявила, что к обеду выпустит патч, который всё исправит
Коротко: вот когда выпустит — тогда и посмотрим.
В данный момент во всех компаниях, хоть как-то причастных к теме, из окон PR-отделов валит дым, а заявивших что-то кроме «к обеду мы всё исправим» просто молча выводят в коридор и расстреливают за углом. Последнее, что нужно всей индустрии, от производителей процессоров до владельцев датацентров — это паника среди их клиентов.
В результате абсолютное большинство заявлений всех компаний, последовавших после раскрытия подробностей Meltdown, отличаются предельной неконкретностью и отсутствием хотя бы минимальных деталей о том, что именно и как именно будет ими исправлено к обеду.
Смысла читать эти заявления, а тем более, фразы в стиле «это проблема легко исправляется внесением небольших программных изменений» в данный момент нет никакого, если в них далее не идёт перечень изменений с указанием, куда именно они вносятся. Просто вспоминайте старую истину про то, что хороший пиарщик никогда не врёт — он просто не говорит всей правды, а закавыченную фразу легко продолжить тезисом «… во все используемые на ваших компьютерах программы, драйверы и ОС», что несколько изменит её смысл.
TL:DR
Полная жопа, самая эпическая дыра за последние двадцать лет, но заплатка на ОС проблему устраняет полностью, пусть и ценой некоторой потери производительности. Владельцы AMD могут пока не волноваться.
А что там со Spectre?
Сейчас напишу отдельным текстом, ибо тема Spectre ещё обширнее.
Часть вторая: Spectre
Часть третья: хорошо ли мы себя вели
Комментарии (246)

Nekto_Habr
05.01.2018 15:34Кто-нибудь знает, как закрытие уязвимости повлияет на тот или иной конкретный софт?
Лично меня интересуют:
Браузеры (конкретно — Опера)
2д редакторы графики: Illustrator, InDesign, Photoshop
WinRAR

olartamonov Автор
05.01.2018 15:36+2На пользовательский десктопный софт в среднем по больнице повлияет мало, т.к. он в основном занимается своими делами, а ядро системы дёргает мало, ибо зачем оно ему.
Но, конечно, возможны исключения.Nekto_Habr
05.01.2018 21:26Но, конечно, возможны исключения.
Есть ли сайт, освещающий такие исключения? Или, быть может, стоит подписаться на вас — будете освещать? :)olartamonov Автор
05.01.2018 21:28Сайта пока точно нет, я точно не буду, мне эти все бенчармки уже много лет как малоинтересны.
На реддите где-нибудь будут коллекционировать результаты.

arheops
06.01.2018 01:11Исключения — работа с гигабитной сетью или nvme ssd
Nekto_Habr
06.01.2018 13:10nvme ssd
Ну-ка, ну-ка? Я как раз присматриваюсь к nvme ssd, хочу улучшить рабочую станцию. Есть подробности?
Danil1404
06.01.2018 13:56От патча для meltdown для интела страдают все системные вызовы без исключения. Обычно это не является большой проблемой, но к системным вызовам также относятся работа с дисками и с сетью.
Пострадали все без исключения приложения, работающие с дисками, но обычно это выражается просто в увеличении загрузки процессора. В случае с nvme ssd проц и так в некоторых ситуациях был бутылочным горлышком при работе с диском, поэтому у них просела производительность. Я встречал отзывы, что скорость линейных чтения/записи упала до двух раз в бенчмарках. Про случайных доступ не знаю, но думаю, что он (т.к. ограничителем все же до сих пор выступает диск) просел не настолько много.kagyr
07.01.2018 02:43Ну, в случае уже моего уже относительно старенького samsung 950 pro (2500/1500) бенчмарк показал данные, весьма близкие к заявленным (2447/1498). Насколько помню, когда замерял сразу после покупки (год назад), цифры были похожими.
arheops
06.01.2018 21:15Для большинства рабочих задач просто любой ссд — уже сильно улучшение. Просто данный патч отьедает кусочек от каждого запроса к диску. А когда у вас ssd, он их может ОЧЕНЬ много переварить. В результате у вас загружен проц там, где раньше не был.

samponet
08.01.2018 16:44Sprint Layout — до патча МС 0:58, после патча МС-время запуска 1:11,7. Это с библиотекой макросов, замеры на i5-4210
Я патч убрал в конце концов.

BogdanBorovik
05.01.2018 15:36Такой новогодний подарок принесли… что все ресурсы гудят уже как ульи с пчёлами обсуждая эту тему. Потому что такое не каждый день прилетает.
Ждём про Spectre, спасибо :)
TheOleg
05.01.2018 16:02+2Большинство ресурсов, кстати, те ещё мудаки. Все эти желтушные новости про потерю производительности в два раза после обновления приводят к тому, что люди отключают обновления, а потом происходит WannaCry и все ноют какой Windows плохой и дырявый.
TheOleg
05.01.2018 16:22+2Сам гугл так же выпустил статью про то, что много спекулятивных статей и на их серверах «незначительное» изменение производительности.
security.googleblog.com/2018/01/more-details-about-mitigations-for-cpu_4.html

BogdanBorovik
05.01.2018 16:29+1Большинство ресурсов написали статьи без разъяснения и с посылом «шеф, всё пропало!». А всё потому что там основном писатели, а не люди которые понимают что происходит. И это печально.
Сейчас пошли статьи о том, что топ-менеджмент знал и сливали акции. Опять эти все вбросы и желтизна. Толкового материала как здесь, просто единицы.
olartamonov Автор
05.01.2018 16:37+1На данном этапе я бы просто игнорировал все заявления причастных компаний, которые не сопровождаются конкретными цифрами.
Intel там вообще уже пообещал чуть ли не к обеду микрокод выпустить, который придёт и молча исправит всё. Неизвестно что конкретно, неизвестно как конкретно, но точно-точно всё исправит.willyd
05.01.2018 16:48Вроде как они написали, что еще выпьют валерьянки на выходных и начнут поставку микрокода на следующей неделе и он будет полноценно работать на системах выпущенных за последние 5 лет (PCID?).
olartamonov Автор
05.01.2018 16:58Вот как начнут — так и посмотрим, что он там делать будет.
Из описания уязвимостей никаким очевидным образом не следует, как это можно закрыть микрокодом без падения производительности, а заявление Интела — это просто образчик политкорректности и обтекаемости, PR-отдел такое должен в рамочку на стенку вешать и учиться.
Особенно если вспомнить их предыдущее заявление, выполненное в стиле «а чо сразу мы-то?».willyd
05.01.2018 17:03Да это все бизнес. Те, у кого есть голова на плечах, умеют читать между строк и играть между струн.
Мне без разницы как закроют. Нужно будет сегодня покопаться в коде примера спектра и пробовать заменить victim_function на что-то что сможет читать определенную область памяти. Сомневаюсь, что у меня получится, но попытка не пытка.tvi
05.01.2018 17:33PoC, лежащему на гистк можно скормить адрес и количетсво данных для чтения в аргументах. Так что жаэе не придется ничего менять
willyd
05.01.2018 17:42Я это и так понял, хоть моих знаний в С не так много, и хотелось бы получить что-то более пристойное для эксплуатации, ну к примеру самый простой пример прочитать, что сейчас загружено процессом, ну и память же будет выделена кусками для процесса.
willyd
05.01.2018 16:42Архитектура систем подразумевает, что вы разносите процессы по серверам в соответствии с требуемыми ресурсами.
На синтетических тестах у вас действительно могут быть просадки на 30%, но на реальной системе, даже на той, которая активно использует системные вызовы, у вас будет просадка меньше, есть еще сеть, память, и все это будет влиять. В масштабах датацентров класса GCP, AWS, FB доля таких сервером далеко не подавляющая, что и приводит к общей потери производительности измеряемой числами порядка единиц процентов. Под удар попадут клиенты, у которых основная масса серверов оказалась подвержена деградации производительности, но думаю, что таких довольно мало.arheops
06.01.2018 01:18+2Сеть и доступ к ссд как раз наибольшее падение и показывает.
Вы плохо понимаете, что происходит. ВСЕ нагруженные системы mysql, oracle, postgress паказывают 15% падение, а для многих 10% разницы это разница между живой и мертвой системой.
Просто никому не нужна паника.willyd
06.01.2018 05:38Вы можете показать это на падение на уровне всей инфраструктуры компании/проекта? Я еще понимаю, когда вся система закручена на ERP на SAP или Oracle и есть только пользовательские клиенты, но зачастую, сервера БД, хоть и критичны, но составляют далеко не большинство, даже внутри огромных компаний.
И я на это смотрю с опыта работы в очень большой компании.arheops
07.01.2018 23:59Я лично видел, как система падала от того, что ее поставили на процессор на 200мгц и 2мб кеша меньше, чем стояла до этого(и не падала).
В базах данных расстояние от «успевает нормально» до «пошла увеличиватся очередь» буквально проценты.

andy_p
05.01.2018 15:50Процессор сбрасывает конвейер и вместо значения, лежащего по адресу 98, выдаёт нам ошибку.
По моему процессор в этом случае не выдает ошибку, а процесс получает сигнал segmentation fault и аварийно завершается. Разве не так ?
olartamonov Автор
05.01.2018 15:59+1Ну, процесс же откуда-то получает этот Segmentation Fault?
У любого процессора есть набор прерываний, которыми он реагирует на подобные действия, ОС их обрабатывает и выдаёт по носу приложению (ну или предпринимает иные действия).
На примере Cortex-M в силу их простоты сравнительной хорошо видно, как это работает. Там у младших (M0) на все случаи жизни единственное прерывание — Hard Fault, у которого наивысший приоритет и которое нельзя замаскировать, а в M3 уже начинается разделение на BusFault (лезем по несуществующему адресу), MemFault (лезем по неразрешённом нам адресу, там зачатки управления памятью уже есть), UsageFault (пытаемся выполнить мусор вместо инструкции), которые ПО может отрабатывать по отдельности, решая, что ему с этим делать.
Собственно, даже пример вспомнил, как приложение лезет не в свою область памяти, но при этом корректно всё разруливает. Мы это используем, например, на Cortex-M3 для определения объёмов памяти, наличия всякой периферии и т.п. — просто маскируем прерывание BusFault, лезем по нужному адресу, если флажок BusFault встал, то там ничего нет, ставим отметку, что сюда не ходи, работаем дальше.andy_p
06.01.2018 00:23А разве в intel процессорах segmentation fault можно перехватить ?
olartamonov Автор
06.01.2018 00:38+2Segfault — это же на уровне системы почти обычное прерывание, 13-й номер, кто-то же его должен обработать? Может или нет пользовательский код отнять его обработку у ОС — это вопрос к ОС, не к процессору. Вот пишут, что и под линуксом с виндой вполне можно.
firk
06.01.2018 04:32По ссылке что-то слишком длинно расписано.
«Перехват» segfault делается через конструкцию __try __except (называется structured exception handler, SEH) в msvc и через sigaction(SIGSEGV) (посмотрите man sigaction) в unix-подобных системах. Из обработчика SIGSEGV, если не хотите завершать процесс, можно выпрыгнуть назад в основной код с помощью longjmp().

Halt
06.01.2018 07:48Когда вы видите окошко типа «программа упала, не хотите ли отправить отчет такой-то матери», это с большой вероятностью выполняется обработчик SIGSEGV.
Процесс прибивается принудительно, если он не выставил собственный обработчик.

3al
05.01.2018 22:48Достаточно обернуть всю работу с этим значением в, условно,
if (likely(false)) { }
Процессор послушно прогреет кэш если спровоцировать branch misprediction, даже если этот код никогда не выполнится.

av220
05.01.2018 16:18-6Я не понимаю мотивации людей, которые обнародовали эту дыру. На мой взгляд это их действия превратили поведение алгоритма в опасную уязвимость. Ну нашли вы уязвимость, быстро стало ясно что затрагивает она все современные процессоры и ее нельзя устранить, так зачем об этом кричать? Без этой огласки знали бы о ней единицы специально обученных людей и и уязвимость коснулась бы единиц. Теперь же в ближайшее время в открытом доступе появятся уже готовые жаваскрипты крадущие логины, пароли и бог знает что. Мотивация детей, «смотрите какие мы умные, мы такую дыру нашли». Здесь действия этих людей принесут принесут вред, а не сама эта уязвимость.
olartamonov Автор
05.01.2018 16:19+2уязвимость коснулась бы единиц
Или миллионов, если бы кто-то из специально обученных людей решил бы выпустить свежего симпатичного червячка. И на заделывание этой дыры тогда ушли бы не сутки, как в случае с типичными софтовыми дырками, а месяцы.

JTG
05.01.2018 16:34+3Security through obscurity не работает. Не сегодня — завтра кто-нибудь докопался бы. Вон покойный Касперски ещё в 2008 писал (PDF).
Mur81
05.01.2018 16:47+2Думать так — очень большая ошибка. Всё равно что скрывать симптомы и делать вид, что всё нормально. Вместо того что бы признать болезнь и заняться лечением.
Вообще это обычная практика у white hat. Нашли уязвимость -> уведомили ответственных -> подождали патча (или какое-то время)-> обнародовали. Если не обнародовать, то у ответственных пропадает стимул что-то исправлять.
И кстати есть инфа (достоверность правда не известна), что производители процессоров были уведомлены еще в июне.a5b
05.01.2018 17:08KAISER еще раньше начали делать: https://github.com/IAIK/KAISER (https://gruss.cc/files/kaiser.pdf JUNE 3, 2017), уже пару месяцев их патч адаптировали к включению в ядро. Были посты https://cyber.wtf/2017/07/28/negative-result-reading-kernel-memory-from-user-mode/ и http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table.
О баге подробно написал The Register, из-за информацию огласили раньше (на неделю?), чем планировали: https://www.theregister.co.uk/2018/01/02/intel_cpu_design_flaw/
There is presently an embargoed security bug impacting apparently all contemporary [Intel] CPU architectures
https://www.theregister.co.uk/2018/01/04/intel_meltdown_spectre_bugs_the_registers_annotations/
Intel and other vendors had planned to disclose this issue next week when more software and firmware updates will be available. However, Intel is making this statement today because of the current inaccurate media reports.
We were gonna say something next week, but those bastards at The Register blew the lid on it early so
The preferred phrase at present is "coordinated disclosure." "Responsible disclosure" suggests the media and security researchers have been irresponsible for reporting on this issue before Intel was ready to go public. Once we get into assigning blame, that invites terms like "responsible microarchitecture design" or "responsible sales of processors known to contain vulnerabilities" or "responsible handling of security disclosures made last June."
av220
05.01.2018 17:13Отличительная и ключевая особенность этой уязвимости — невозможность устранения, по-сути это не болезнь, ошибка или недоделка, это архитектурная особенность современного процессора. Програмный патч в этом случае, как я понял, будет в какой-то мере ограничивать функциональность, так что нет, это не тот случай, о котором вы говорите. Тут одни умные парни укололи других умных парней, а заплатят все остальные.
Mur81
05.01.2018 17:48+2Если проводить аналогии с болезнью, то да — это неизлечимая болезнь. Стоит ли её скрывать или всё таки надо признать и заняться лечением тем самым продлив пациенту жизнь?
Но аналогии фальшивы. А по факту уже написали — Security through obscurity не работает. Давно признанный в ИБ факт.
Есть ли тут какая-то доля тщеславия? Возможно. В конце концов «белые шляпы» очевидно зарабатывают меньше своих не столь отягощенных моралью коллег. Компенсируется это в том числе и так.
Но дело это не меняет всё равно — сокрытие ни к чему хорошему тоже не приводит.
Hardcoin
06.01.2018 19:50Поэтому давайте вирусописатели будут знать (им кто-то обязательно продал бы, не сейчас, так через пару лет), а остальные пусть знать не будут, что б спокойнее спалось? Верно понимаю вашу логику?
immaculate
05.01.2018 17:01+1Intel уведомили об ошибке в июне прошлого года. Было достаточно времени, чтобы предпринять хоть какие-то меры.
KivApple
05.01.2018 20:11Хорошие люди ничем от плохих в плане интеллекта принципиально не отличаются. Если до чего-то смог додуматься хороший человек, то и плохой человек додуматься сможет (а, возможно, даже кто-то плохой до этой уязвимости додумался уже давно, просто никто не знает). А это значит, что в один прекрасный момент Х, эпидемия всё равно случится (потому что плохой человек додумается до уязвимости, а также будет иметь мотивацию её применить на практике). Только вот сейчас пострадают только те, кто поленился поставить апдейты, ибо у софтовых компаний время на закрытие дыры было. А так пострадают вообще все.

EvgeniyNuAfanasievich
05.01.2018 16:24+1а может кто-то дать ссылку, на видео или статью где все вышеописанное на практике используют и тырят пароль или еще какой ключ в реале? Просто в статье упоминается перебор каких то там комбинаций и т.о. типа всю память физическую можно прочесть: ну ок, а за какое время?(может там уже мусор будет давно) и куда оно пишется после чтения? а сколько это займет времени и оперативки. чем/кем это все анализируется после считывания?

crea7or
05.01.2018 16:42-2Например вот, та же техника — переброс видео через кэш процессора на двух виртуалках в Amazon ec2.
EvgeniyNuAfanasievich
05.01.2018 17:17честно: не вижу более одной виртуалки/железной тачки) на видео. просто какое-то консольное нагромождение.
прошу простить, если с телефона не разглядел чего то.a5b
05.01.2018 17:54Это иллюстрация другой методики, когда на двух разных виртуальных машинах работает специальный код, пересылающий данные между ними по скрытому каналу через кэш-память
Black Hat Asia 2017: Hello From the Other Side
https://www.youtube.com/watch?v=a9sGk7FtnYk SSH Over Robust Cache Covert Channels in the Cloud (от тех же Daniel Gruss и ко)
https://gruss.cc/files/hello.pdf
Especially cache covert channels allow the transmission of several hundred kilobits
per second between unprivileged user programs in separate virtual machines… Our errorcorrecting and error-handling high-throughput covert channel can sustain transmission rates of more than 45 KBps on Amazon EC2, which is 3 orders of magnitude higher than previous covert channels demonstrated on Amazon EC2. Our robust and errorfree channel even allows us to build an SSH connection between two virtual machines, where all existing covert channels fail.
… Covert channels are unauthorized communication channels between two parties, a sender and a receiver.… At a high level, the sender transmits bits by evicting cache lines from the receiver. The receiver constantly probes a set in his L1 cache. These cache lines are also present in the lastlevel cache due to the inclusive property. To transmit a ‘0’, the
sender does nothing. The lines thus stay in the L1 cache of the receiver, which thus observes a short timing to probe its lines. To transmit a ‘1’, the sender accesses cache lines that are mapped to the same set in the last-level cache as the receiver’s.По Spectre для примера в статье заявлена скорость порядка килобайтов в сек https://spectreattack.com/spectre.pdf The unoptimized code in Appendix A reads approximately 10KB/second on an i7 Surface Pro 3.
Для meltdown быстрее — https://meltdownattack.com/meltdown.pdf we can dump kernel and physical memory with up to 503 KB/s… With exception handling, we achieved average reading speeds of 123 KB/s when leaking 12 MB of kernel memory
ZelAnton
05.01.2018 16:49EvgeniyNuAfanasievich
05.01.2018 17:15-1по первому видео: ну там адреса заранее известны. немного не жиза))
по второй ссылке: ну диспетчер паролей фф и какая то неведомая хня в hex. не ясно, какой вывод надо сделать то.olartamonov Автор
05.01.2018 17:21+2Да какая по большому счёту разница, известны они заранее или нет. Это только на время работы влияет.
На том же Heartbleed убедительно показывали, из какого сора растут цветы и добываются сертификаты.EvgeniyNuAfanasievich
05.01.2018 17:24разница есть. особенно в ентерпрайз, с сотнями гигов оперативы. так же можно сказать, что любой пароль можно подобрать, вопрос времени :-)
а хартблид чутка попроще и для понимания и для реализации имхо!kryvichh
05.01.2018 21:27Энтерпрайзу будет легче, если с его сервера утекут не пароли пользователей, а in-memory база данных, или открытые в терминалах офисные документы, или списки клиентов с контактными данными и номерами кредиток?
EvgeniyNuAfanasievich
09.01.2018 09:49вы читали мои изначальные вопросы(пост 05.01.18 в 16:24)?
Они по идее, должны бы увести беседу немного в другое русло (перейти от общего к частному, пруфам и т.п.). Понятно что дело серьезное, теперь осталось выяснить насколько срочно надо рвать волосы на *опе.

Solexid
05.01.2018 16:40Какую рускоязычную статью не читаю, везде пишут мол на амд тоже есть и причем вполне уверенно. Это очень смешно, учитывая тот факт что на амд так не смогли ее провернуть и что представители амд предупредили что у них совсем другой подход к работе процессора. Банально — у них даже шины не имеют ничего общего между собой- у амд звезда, у интел кольцо. Spectre на амд вообще работает только на системах с включеным BPF(линуксы и bsd), который по дефолту отрублен. Что это за мания пытаться за компанию и амд затянуть в это болото? У амд была проблема с райзенами до 25 недели, приводящая к сегфолту, но она решается отключением опкеша и эти процы амд меняет бесплатно по RMA. Как думаете, сколько процессоров поменяет интел? Мой вариант — 0.
olartamonov Автор
05.01.2018 16:52+1Spectre на амд вообще работает только на системах с включеным BPF(линуксы и bsd),
НЕТ.
Ёлки зелёные, из того, что гугль для простоты демонстрации дырки использовал eBPF, никак не следует, что без него эта дырка исчезает.interprise
05.01.2018 17:42-1www.amd.com/en/corporate/speculative-execution
Амд сделали патч, без падения производительности.olartamonov Автор
05.01.2018 17:46+2Какой патч, куда патч? AMD не подвержены Meltdown вообще.
interprise
05.01.2018 17:54-1я про spectre многие говорят, типо от нее вообще нельзя избавится у AMD судя по всем получилось. От Meltdown помогает программный патч. хоть и тормозной
olartamonov Автор
05.01.2018 17:57+1У AMD по ссылке написано, дословно, «проблему решат обновления ПО, которые вам предоставят производители».
Ровно по причине таких прекрасных, подробных пресс-релизов я специально добавил в текст абзац про пресс-релизы.interprise
05.01.2018 18:02насколько я понял имеется в виду обновление микрокода, а не обновления ядер ОС
kryvichh
05.01.2018 21:41Строго говоря, по ссылке написано: "(Уже) решено путем обновления программного обеспечения / ОС, которое должно быть доступно поставщикам и производителям систем. Ожидается незначительное влияние на производительность."
Но Вы правы, что надо подождать реальной поставки и независимой проверки готовых патчей на системах AMD, чтобы делать окончательные выводы.
september669
05.01.2018 18:32Проблема сегфолтов отключением опкеша не решается, а на на некоторых замененных процах сегфолт остаётся.
kryvichh
05.01.2018 21:32+1Для информации: подсистему eBPF в Linux рекомедовали отключить (для пользователей) ещё 23.12.2017, и по другому поводу.
UJIb9I4AnJIbIrUH
05.01.2018 16:45+1Нуб с мировым именем MODE ON.
Какой-то простой алгоритм. Я ни капли не программист, ну разве что самую малость, но это объяснение на пальцах мне показалось очень понятным, а сам алгоритм — лежащим на поверхности. Ну ладно, я всё таки Физтех закончил, благо, я могу попробовать объяснить это всё родственнику, который хоть и весьма толковый, но, как показала недавняя практика, даже не вполне умеет пользоваться гиперссылками на страницах в интернете. Так я даже ему смог это объяснить. Как тогда так получилось, что до этого додумались только сейчас?Mur81
05.01.2018 17:07+4Во-первых, думается мне, это просто когда тебе это на блюдечке преподнесли и рассказали как работает. А поди ты сам до такого хитроумного способа додумайся. Отличный пример высказывания «всё гениальное просто».
Во-вторых кто сказал, что додумались только сейчас? Это white hat додумались сейчас. А сколько до них додумались black hat? Сие не ведомо. Может и действительно никто.UJIb9I4AnJIbIrUH
05.01.2018 17:10Хороший вопрос. Я вроде в предыдущих постах видел, что все бьют себя пяткой в грудь и заявляют, что подобных атак не наблюдали. Отсюда вопрос: как они могли знать были атаки или нет, если сама уязвимость не была известна?
olartamonov Автор
05.01.2018 17:19+2«Если вы, откусив яблоко, обнаружили торчащую из него половину червяка, значит, вы только что съели червяка. Если же вы ничего не обнаружили, это ещё ничего не значит».
willyd
05.01.2018 17:56Лучше быть подготовленным.
В Amazon решили не доедать яблоко.
We will be updating the certificate authority (CA) for the certificates used by Amazon CloudWatch Logs domain(s), between 8 January 2018 and 22 January 2018. After the updates complete, the SSL/TLS certificates used by Amazon CloudWatch Logs will be issued by Amazon Trust Services (ATS), the same certificate authority (CA) used by AWS Certificate Manager. The update means that customers accessing AWS webpages via HTTPS (for example, the Amazon CloudWatch Console, customer portal, or homepage) or accessing Amazon CloudWatch Logs API endpoints, whether through browsers or programmatically, will need to update the trusted CA list on their client machines if they do not already support any of the following CAs:
— «Amazon Root CA 1»
— «Starfield Services Root Certificate Authority — G2»
— «Starfield Class 2 Certification Authority»
aram_pakhchanian
05.01.2018 20:53Ну если black hat не додумались, то они, наверное, от обиды уже съели свои black hats

0xd34df00d
09.01.2018 01:55При всём уважении, хитроумный способ — это вот это. Meltdown, на мой взгляд, по сравнению с ним — образец очевидности.

d-stream
05.01.2018 18:17Сейчас это выскочило на публику. А кто, когда додумался раньше, но не опубликовал — неизвестно.
Zarxonius
05.01.2018 17:14+1После чтения популярного изложения «на пальцах», у меня возник вопрос — как же до сих пор работала популярная в моем детстве программа ArtMoney, которая вполне себе работала с памятью других процессов?
Я понимаю, что в данном случае — вся беда в том, что доступ к чужим областям памяти может получить код запускаемый в средах, которые напрямую этого не позволяют, но все же — чем же занят MMU в случае с ArtMoney?olartamonov Автор
05.01.2018 17:18+3MMU — не сферический конь в вакууме, он не работает «сам по себе», ему ОС указывает, какие куски памяти кому положены. В частности, разрешённые области памяти у разных процессов могут вообще пересекаться.
Разрешила ОС данному приложению лазить в чужую память — значит, хорошее приложение, годное, ему можно.
Антивирусу, например, вон тоже много чего можно.
zikasak
05.01.2018 17:19+1Чтение: msdn.microsoft.com/en-us/library/ms680553(VS.85).aspx
Запись: msdn.microsoft.com/en-us/library/ms681674(VS.85).aspx

vvzvlad
05.01.2018 18:53+2А вы запустите на современной ОС ArtMoney не от администратора, откажитесь от всяких вопросов «процесс хочет доступ» и попробуйте прочитать память. Скорее всего ничего не получится. А тут даже JS в браузере может вытащить что-нибудь из памяти без всяких разрешений и прочего.
ARD8S
05.01.2018 21:53Я вот подумал, а Noscript может как-нибудь помочь в противодействии данной бяке, потенциально пытающейся эксплойтить через JS в браузере? (Intel, ессно).
vvzvlad
05.01.2018 22:09Я не в курсе, как работает noscript. Если он запрещает выполнение всего JS, то логично, что защитит. Но я вижу, что у меня на части сайтов не работает половина функционала, пока я в umatrix не разрешу загрузку пары скриптов с какого-нибудь CDN. Соотвественно, я от этой уязвимости не защищён — я рано или поздно запущу что-то ради функционала, либо скрипт будет лежать на доверенном домене.
А на практике, с JS скорее всего что-нибудь сделают производители браузеров — загрублением таймера или принудительным сбросом кеша, так что этого не очень стоит опасаться.
denisbasmanov
05.01.2018 22:52+1Pale Moon ещё в октябре 2016 «на всякий случай» решил огрубить таймер, как знали (ну, браузер для параноиков, решили упредить и не прогадали). Во всяком случае если верить записи разработчика на форуме.

stetzen
05.01.2018 18:16Спасибо за статью, на удивление понятно и доходчиво! По итогам вдумчивого прочтения возникли два вопроса:
1. Если я правильно понимаю, реализация всего этого дела опирается на то, что MMU работает настолько медленно, что процессор успевает минимум два раза сходить в медленную RAM, прежде чем получит ответ, что так нельзя — это действительно так?
2. После получения первого значения процессор начинает его использовать, не дожидаясь ответа, можно ли было его вообще получать. Если я правильно понимаю, примерно из-за ожидания ответа в таком случае Meltdown не реализуется на AMD. Но в каком именно случае процессор таки будет дожидаться ответа от MMU, прежде чем сделать очередную операцию? Кажется, что помимо косвенной адресации погут быть и другие разрешенные операции, которые могут привести к схожим атакам.olartamonov Автор
05.01.2018 18:311. Тут можно разрисовывать варианты работы MMU и думать, почему так. Например, в TLB — кэше таблицы трансляции адресов — хранятся только собственно адреса, но не права доступа, поэтому ALU быстро достаёт оттуда нужный физический адрес, пока MMU медленно собирается идти в ОЗУ за таблицей прав доступа к нему. Далее представляется логичным дать приоритет ALU, чтобы оно первым достало из памяти данные и поехало работать дальше, а MMU подождёт. В результате, когда MMU наконец пустили до памяти, ALU улетело вперёд уже на десятки операций.
Это я чисто спекулятивно, искать, как оно реально устроено в Интелах, сейчас лень — да и не уверен, что это есть в открытом доступе. У AMD в такой схеме могут быть или другие приоритеты (другой баланс между потребностями ALU и MMU), или в TLB уже лежат и права доступа тоже, например.
2. Могут быть и другие, но косвенной адресации более чем достаточно для счастья. Нет даже повода искать что-то ещё.a5b
05.01.2018 21:13TLB — это часть MMU, см http://www.cs.vu.nl/~giuffrida/papers/anc-ndss-2017.pdf "Fig. 2. Memory organization in a recent Intel processor.… The MMU performs the translation from the virtual address to the physical address using the TLB before accessing the data or the instruction since the caches that store the data are tagged with physical addresses (i.e., physically-tagged caches).".
Права доступа негде хранить, кроме как в TLB (их оригинал хранится в PT data structure, в PTE, но до настоящей pte далеко). Так как права должны быть проверены к моменту retire каждой инструкции, работающей с памятью, они не могут читаться из памяти или из обычных кэшей (всё чтение в L1 включая попадание в TLB и проверку прав занимает 4 такта). При этом права из TLB могут быть выдаваться в какие-то другие направления…
https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-140.html
https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-141.html
Each entry in a TLB… contains the… The access rights from the paging-structure entries…
https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-133.html
https://googleprojectzero.blogspot.ru/2018/01/reading-privileged-memory-with-side.html
The underlying idea is that the permission check for accessing an address might not be on the critical path for reading data from memory to a register, where the permission check could have significant performance impact. Instead, the memory read could make the result of the read available to following instructions immediately and only perform the permission check asynchronously, setting a flag in the reorder buffer that causes an exception to be raised if the permission check fails.olartamonov Автор
05.01.2018 21:21Так как права должны быть проверены к моменту retire каждой инструкции, работающей с памятью, они не могут читаться из памяти
Это не так. Даже сам адрес в ходе трансляции может читаться из ОЗУ, т.к. TLB — это кэш, он по определению не покрывает всех возможных адресов трансляции, не говоря уж о том, что он тупо сбрасывается в ноль при переключении контекста на большинстве процессоров.
Each entry in a TLB… contains the… The access rights from the paging-structure entries
where the permission check could have significant performance impact
Если оба утверждения корректны, то механизм возникновения significant performance impact, если и физический адрес, и права доступа достаются одновременного и из одного и того же места, остаётся неясен.a5b
05.01.2018 21:29TLB — это кэш, но все операции доступа к памяти (в нормальных режимах) проходят через него и не могут завершиться без выдачи физадреса из tlb. При промахе всех уровней tlb будет совершен (в MMU) pt walk, заполнение строки в tlb, трансляция физадреса + проверка прав. Т.е. инструкция работы с памятью не может завершиться, пока не ответил TLB.
1801BM1
05.01.2018 21:15+1Непонятно почему в TLB сохраняется только физический адрес, а не полностью аттрибуты доступа. TLB явно работает как CAM (content-addressable memory, идет сравнение тегов виртуального адреса с выставленным) поэтому странно. что физадрес из TLB извлечь успевают, а извлечь и проверить аттрибуты — нет. Я склоняюсь к тому что это именно архитектурный залет, технических же проблем реализовать проверку аттрибутов нет.
olartamonov Автор
05.01.2018 21:22Я не утверждаю, что права не хранятся в TLB, более того, выше есть ссылки, утверждающие, что это не так — и они там хранятся.
Но тогда вдвойне непонятно, откуда возникает такой performance impact на проверку прав доступа, что проще эту проверку отложить на потом.1801BM1
05.01.2018 21:29+1Про performance impact — это только предположение исследователей уязвимости. Время извлечения аттрибутов из TLB точно такого же порядка как и время извлечения физадреса. Возможно там есть сложности собственно проверки аттрибутов (многие биты режима работы процессора тоже конвееризуются), но решаемые, имхо, если задасться целью. Вероятнее всего, блок проверки прав сделан в уязвимых процессорах отдельно и работает асинхронно в целях упрощения структуры.
olartamonov Автор
05.01.2018 21:34В общем, там должна быть веская причина делать именно так — потому что логика откладывания проверки не выглядит самоочевидной, и не пережила бы двадцать лет и кучу поколений процессоров одного производителя, чтобы потом ещё и вылезти у другого.
Нам, впрочем, её всё равно вряд ли расскажут.
Упрощение структуры тут вряд ли является причиной — в современных процессорах наверчено уже столько, что на лишнюю сотню тысяч транзисторов в MMU посмотрят далеко не в первую очередь.1801BM1
05.01.2018 21:57>>логика откладывания проверки не выглядит самоочевидной
Пока оно выглядит так что аттрибуты доступа просто сохраняются рядом с полученными данными, и проверяются непосредственно в момент instruction retirement. Это позволяет иметь валидный контекст исключения на момент проверки. Гораздо сложнее «собрать» этот контекст при спекулятивном исполнении. В любом случае, нет оправдания почему не сделана хотя бы предварительная проверка прав в момент доступа к памяти и прекращение спекулятивного исполнения, если проверка не пройдена. Пенальти то тут никакого — ветка будет отброшена или из-за ложного предсказания исполнения, или таки из-за исключения.
>>что на лишнюю сотню тысяч транзисторов
Имелся ввиду не транзисторный бюджет, а именно сложность разработки архитектуры.ion2
06.01.2018 14:14В любом случае, нет оправдания почему не сделана хотя бы предварительная проверка прав в момент доступа к памяти и прекращение спекулятивного исполнения, если проверка не пройдена.
В некоторых случаях данные могут использоваться позже и есть смысл их загрузить заранее. Например запись в copy-on-write страницу вызовет исключение и последующее копирование в обработчике страничных ошибок. Я думаю, что Intel обнаружил небольшое увеличение производительности при таком спекулятивном кешировании.
a5b
05.01.2018 21:26Физадрес из tlb cam надо сразу выдавать в сторону кэш-памяти для параллельной сверки тэгов в VIPT L1 (приблизительно/условно так http://images.slideplayer.com/39/10978514/slides/slide_23.jpg http://images.slideplayer.com/23/6620421/slides/slide_16.jpg). Выдаются ли права доступа в сторону кэша — неясно (для них неважно, будет ли попадание в кэш), их надо проверить и выдать в какое-то устройство OOO-конвейера — ROB / MOB / retire...
1801BM1
05.01.2018 21:32+1Права доступа в сторону физкеша выдавать бессмысленно, кеш про них понятия не имеет. Наоборот, надо права проверить и результат проверки слать на блоки исполнения — пометить неправомерный доступ как токсичный и вызывающий исключение, на этом спекулятивное исполнение ветки прекратить.
olartamonov Автор
05.01.2018 21:36на этом спекулятивное исполнение ветки прекратить
Что характерно, вот это должно дать положительный импакт по сравнению с тем, что сейчас творится у интела и арма.

Sun-ami
05.01.2018 18:33Насколько я понял, перенос памяти ядра в другое адресное пространство — не единственный метод борьбы с этой уязвимостью. Можно, например, при попытке чтения памяти ядра сбрасывать весь кэш процессора. Возможно это в некоторых применениях будет эффективнее? Хотя, конечно если не изменить при этом алгоритмы таймменеджмента ОС — можно будет сильно затормозить систему используя этот механизм.

TheDeadOne
05.01.2018 18:38+1Вся соль в том, что в момент чтения процессор не знает относится ли читаемая память к ядру.
Sun-ami
05.01.2018 18:44А, до меня дошло — исключение в этом случае не генерится, потому что результаты отбрасываются, так что да, не получится.
olartamonov Автор
05.01.2018 19:12+1Оно внутри процессора генерируется, иначе бы он не знал, что результат надо отбросить. Но — в случае Intel и свежих ARM — только после того, как данные de facto прочитаны.
Sun-ami
05.01.2018 19:42Я имел в виду, что исключение по обращению к памяти, которое запрещено по уровню привилегий приложения, не вызывает прерывание, которое ядро могло бы обработать, и сбросить кэш. В принципе, на уровне микрокода, наверное, такое прерывание можно было бы добавить, но это, вероятно, приведёт к большому числу случайных срабатываний так что такой метод ещё больше затормозит процессор. А вот с точки зрения обнаружения атаки через эту уязвимость — думаю, было бы полезно.
olartamonov Автор
05.01.2018 20:15но это, вероятно, приведёт к большому числу случайных срабатываний так что такой метод ещё больше затормозит процессор
Вообще нет, при нормальной работе каких-то особо частых попаданий в чужую память быть не должно, если бы спекулятивное выполнение часто приводило к промахам — оно было бы тупо неэффективно, т.к. сброс конвейера дорого стоит.
Но это всё равно так себе решение, т.е. требует взаимодействия процессора и софта и при этом не даёт ничего, кроме зажигания лампочки «что-то тут не так».Sun-ami
05.01.2018 20:46Если сбросить весь кэш по попытке чтения памяти ядра — это полностью закроет уязвимость. Другое дело что это на порядки больший тормоз чем единичный кэш-промах, и неизвестно какая программа, написанная с точки зрения программной модели вполне корректно начнёт дико тормозить систему. Но если обрабатывать это прерывание антивирусом не всегда, а так, чтобы оно не тормозило систему, можно набрать статистику по подозрительным участкам кода, а потом посмотреть на них более детально и определить, пытается ли программа использовать уязвимость.

ns3230
05.01.2018 18:45Простите за возможно очень нубский вопрос, но в вопросах архитектурного устройства CPU и RAM у меня познания весьма невелики. Как я понял, суть дырки в том, что вредоносный код лезет туда, куда низзя, его за это посылают, но код определяет содержимое по интонации (задержке) отказа. И в итоге процессор может спалиться, как в анекдоте:
— Дед, люди говорят, у вас винтовка есть?
— Врут.
— Дед, люди говорят, у вас пулемет есть.
— Врут.
— Дед, люди говорят, у вас пушка есть.
— Врут.
— Дед, люди говорят, у вас танк есть.
— Врут.
— Дед, люди говорят, у вас атомная бомба есть.
— А вот чего нет, того нет.То есть, отличающийся от других ответ говорит, что значение ячейки памяти угадано, а дальше по цепочке как-то к другим ячейкам подбирает значения? Если нет, то где моя ошибка?
Ну и вопрос практического характера. Имею комп на i5-7600, включенный 24/7, с постоянно открытым браузером. ОС — Винда 7 (ну не люблю я десятку), с отключенными обновами. Никаких биткоин-кошельков на компе нет, к тому же счету вебмани или банк-клиенту авторизация все равно смартфоном прикрыта (двухфакторная авторизация), админок с правами, способными навредить какому-то ресурсу или стащить оттуда что-то ценное тоже нет. Я где попало не хожу обычно, и за всю жизнь ни одного серьезного виря не ловил (червячки максимум, лет 7 назад). Поэтому вопрос: мне бояться или выдыхать?stetzen
05.01.2018 18:57Насколько я понимаю, системам, у которых на процессоре работает один пользователь, бояться особо нечего, за исключением JavaScript-эксплойтов, которые должны более или менее прикрыть разработчики браузеров (если на винде работает какой-то левый код, то он может наворотить дел и без этой уязвимости). Большая проблема возникает, если на одном CPU выполняется код разных пользователей — тогда один из них получает доступ к памяти остальных.
vvzvlad
05.01.2018 19:00То есть, отличающийся от других ответ говорит, что значение ячейки памяти угадано, а дальше по цепочке как-то к другим ячейкам подбирает значения?
А дальше адрес увеличивается на единицу и подбирается значение дальше. В итоге получаем кусок памяти, в котором возможно что-то интересное.
к тому же счету вебмани или банк-клиенту авторизация все равно смартфоном прикрыта (двухфакторная авторизация)
Всегда можно вытащить токен/кукис, который позволит зайти без авторизации. Если не от банк-клиента, так хоть от почты/соцсети/итд. А «где попало не хожу» — плохая защита, не гарантирует того, что хороший сайт не сломают и не добавят туда маленький скрипт. Но вопрос с эксплуатацией уязвимости через браузерный JS остается открытым.
olartamonov Автор
05.01.2018 19:14Как я понял, суть дырки в том, что вредоносный код лезет туда, куда низзя, его за это посылают, но код определяет содержимое по интонации (задержке) отказа. И в итоге процессор может спалиться, как в анекдоте
Почти так. Если совсем строго — вредоносный код в явном виде даже никуда не лезет, он просто подстраивает ситуацию так, что процессор лезет туда сам, вперёд батьки в пекло. Поэтому формально код даже и не посылают.

hssergey
05.01.2018 19:23Ну подумаешь, комп станет частью ботнета и примется рассылать спам и майнить крипту) можно дышать спокойно…
ns3230
05.01.2018 20:11Ну подумаешь, комп станет частью ботнета и примется рассылать спам и майнить крипту)
Логика мне подсказывает, что если такое случится, то комп станет медленнее, что будет видно в диспетчере задач по уровню загрузки проца, горячее и шумнее. А уж шум кулера повышенный я сразу засеку, так как сейчас он на 300 об/мин постоянно лопатит, все тихо. И если я пойму, что это не термопаста, обнаружу какие-то мутные-непонятные процессы и т.д. — я в таких случаях просто нафиг переустановлю винду, на всяк пожарный проверю, все ли "лишние" порты залочены на роутере, плюс потом попрошу провайдера сменить мне айпишник.

shurshur
06.01.2018 01:38+1Данная уязвимость не позволяет запускать код, она позволяет только извлечь данные: пароли, куки, сертификаты, интимные фотки…
ARD8S
06.01.2018 13:45olartamonov, подскажите, реально ли извлечь ключи кошельков криптовалют. Например, насколько опасны сервисы, не закрывшие софт-заплаткой свои мощности, но которые сдают мощности майнерам или частные фермы/кластеры.
Или 2. Можно ли как-нибудь с помощью этой «архитектурной особенности» противостоять шифровальщикам (дешифровать данные), etc.olartamonov Автор
06.01.2018 13:55Теоретически реально извлечь всё перечисленное, а также всё остальное, не перечисленное.
В системах без специальных аппаратных криптопроцессоров любые ключи и пароли в тот или иной момент оказываются в памяти в полностью открытом виде, независимо от того, как они зашифрованы или иным образом защищены при хранении, потому что другого способа работы с ними нет.
olartamonov Автор
06.01.2018 13:58Но, кстати, конкретно шифровальщики используют несимметричное шифрование, поэтому ключа для дешифровки у вас на компьютере не будет ни в каком виде.
Если б там было симметричное, ключ можно было бы так или иначе достать из тушки шифровальщика и применить.
stetzen
05.01.2018 19:24+6Скорее, это работает так:
— Дед, люди говорят, у вас винтовка есть?
— Есть.
— Дед, люди говорят, у вас пулемет есть.
— Есть.
— Дед, люди говорят, у вас пушка есть.
— Есть.
— Дед, люди говорят, у вас танк есть.
— Есть.
— Дед, люди говорят, у вас атомная бомба есть?
—… не дожидаясь ответа, потому что ответ будет «не положено тебе про атомные бомбы знать»… Дед, а красные атомные бомбы бывают?
—… задумался… Бывают.
— Дед, а зеленые атомные бомбы бывают?
—… задумался… Бывают.
— Дед, а синие атомные бомбы бывают?
—… мгновенно, потому что уже вспомнил бомбу в сарае… Бывают.
interprise
05.01.2018 19:56+2Я уже сгораю от нетерпения, жду статью про spectre. Правда по описанию, мне показалась что в этом статье именно это и было описано.

Arxitektor
05.01.2018 20:01Спасибо за статью, на все понятно и доходчиво.
Ждем вторую часть.
Конечно то сколько лет назад была допущена данная аппаратная ошибка… крутовато.
Но обновами кое-как заткнут, подкрасят и OK.
Немного фантазии:
Виноваты Скайнет, Реплилоиды, путешественники во времени (Наиболее вероятны).
А так да заложенная в далёком прошлом архитектурная уязвимость.
Вот интересно вылезла только на современных CPU из-за их быстродействия?
На на каком нибудь 4 пне не будет столь эффективно работать?olartamonov Автор
05.01.2018 20:11+2Прекрасно работает на чём угодно, народ эксплоиты на Pentium M и каких-то промышленных SoC'ах AMD уже тестировал, не спрашивайте меня, где они их третьего января нашли вообще.
arheops
06.01.2018 02:09+1Ну у меня, например, лежит в коробке справа от стола один из первых атомов в micro-itx(причем уже в корпусе с RAM), штук 5 разных pentium, включая D, три ноута с разными ревизиями coreduo. И это обычный ит ящик, не рабочий, не имею отношения к ремонту компов или их сборке.
Найти дело нехитрое.
blbulyandavbulyan
05.01.2018 20:10Будет интересно посмотреть на то как тру хацкеры крадут ключи шифрования из моей оперативной памяти и достают с моего компа котов.
KivApple
05.01.2018 20:26По статье следует, что уязвимость позволяет чтение памяти по виртуальным адресам, чтение которых не было разрешено коду. Не запись и не чтение по произвольным физическим адресам.
В былые времена я пробовал писать свою игрушечную ОС, поэтому я знаю, что все пользовательские приложения на Intel всегда работают в 3-ем кольце защиты, а ядро в нулевом (1-ое и 2-ое кольцо существуют, но обычно не используются). Сами же по себе приложения по кольцам защиты никак не разделены (банально потому что колец защиты не хватит на всех), но имеют разные виртуальные адресные пространства. Таким образом, уязвимость открывает только доступ к структурам ядра, но не структурам других приложений.
Да, это плохо. Ведь в структурах ядра тоже могут содержаться данные, которые не стоило бы раскрывать. Например, ключи шифрования файловой системы (ведь этим занимается дравйвер из нулевого кольца). Плюс всякие буферы ввода-вывода (одно приложение туда запишет данные, а другое через уязвимость прочитает, хотя эта информация предназначалась вообще драйверу или третьему приложению). Но это значит, что есть немало информации, раскрытие которой не является уязвимостью. Например, сам исполняемый код ядра и драйверов. Это и так практически открытая информация — ведь весь этот софт находится в свободном или почти свободном доступе (в смысле платном, но от конечного пользователя не убудет, если кто-то сможет таким образом «спиратить» коммерческий драйвер или ОС, которые он купил).
Отсюда следует, что для закрытия уязвимости достаточно не полностью изолировать пространство ядра, а лишь вынести из него информацию, которая не имеет отношения к текущему процессу (например, чужие буферы ввода-вывода, чужие файловые дескрипторы и т. д.). Конечно, это тоже ударит по производительности, но в меньшей степени, ибо большинство системных вызовов работают с объектам, которые принадлежат самому процессу. От того, что процесс через уязвимость сможет прочитать кеш записи файла, в который он только что сам же записал данные, ничего страшного не случится.
Где я не прав?interprise
05.01.2018 20:30везде прав, только сложность реализации. Сейчас нужно «всего лишь» переключить адресное пространство во время системного вызова. А в вашем случае переписывать кэши и много чего еще.
KivApple
05.01.2018 20:40Полное скрытие всего — да, хорошее временное решение (потому что сейчас надо решать проблему максимально быстро, пока не начались массовые атаки). Но в перспективе надеюсь будут разработаны и варианты скрытия только того, что действительно нужно скрывать. Ради производительности можно и помучаться, не?
Но это уже никак не «найденная уязвимость может быть решена ТОЛЬКО снижением производительности на 30%». Это «найденная уязвимость может быть БЫСТРО решена только снижением производительности на 30%, в будущем можно решить её снижением производительности на 1%».
(цифры условные)olartamonov Автор
05.01.2018 21:11Да в общем и сейчас это не 30 %, а «от 1-2 до 30 %, в зависимости от приложений и их нагрузки».
wych-elm
05.01.2018 21:42Таким образом, уязвимость открывает только доступ к структурам ядра, но не структурам других приложений.
А вот для структур других приложений и предназначен Spectre.olartamonov Автор
05.01.2018 21:49Не-а, проще. Через память ядра обычно можно достать всю физическую память системы, то есть, если к ней есть доступ из пространства памяти приложения, то между ним и всем остальным на компьютере нет никаких барьеров, кроме прав доступа.
wych-elm
05.01.2018 22:50Насколько я понял, Meltdown позволяет обратится только к памяти ядра отображенной в пользовательский процесс, а не вообще к любой. А Spectre — к памяти любого пользовательского процесса, но не ядра. В Meltdown используется out-of-order исполнение и прерывание по доступу, а в Spectre — спекулятивное исполнение и переполнение буфера (или подобное). При этом в обоих случаях данные получаются через кэш, играя с процессором в «угадайку». Подобные техники называются side channel среди хакеров. Я назвал бы эту — «гадание по кэшу».
olartamonov Автор
06.01.2018 00:21А нет какого-то отдельного кусочка памяти ядра, который был бы отображён в память процесса, а всё остальное ядро не было бы.
Оно целиком там. А в нём — целиком физическая память, гуляй не хочу.
До сего момента никто даже не видел смысла заморачиваться с тем, чтобы сделать как-то иначе.
В Meltdown используется out-of-order исполнение и прерывание по доступу, а в Spectre — спекулятивное исполнение и переполнение буфера (или подобное)
Нет. В Meltdown не возникает прерывания, в Spectre — переполнения. Спекулятивное выполнение формально не порождает ни того, ни другого.wych-elm
06.01.2018 00:43Я читал доклад об этих уязвимостях, прерывание возникает когда выполняется попытка прочитать память ядра, но из-за out-of-order данные все же попадают в кэш. В Spectre, мы «заманиваем» предсказатель перехода в ветку с доступом за границы буфера в коде процесса-жертвы и таким образом также в кэш попадают данные недоступные иначе. Далее в обеих случаях происходит «угадывания» данных попавших в кэш. Как-то так, насколько я понял.
olartamonov Автор
06.01.2018 00:50Нет, прерывания не возникает.
Оно не может и не должно там возникать, т.к. данные читаются в ходе спекулятивного выполнения инструкций, о котором программа не знает и знать не может — так что внезапно, посреди совершенно корректного кода прилетевшее прерывание GPF ей будет немного как гром среди ясного неба.Danil1404
06.01.2018 01:39Ну, вообще говоря, в оригинальной meltdown.pdf рассматривается как раз случай с исключением. Другое дело, что если вместо него использовать branch prediction miss, то будет то же самое.
olartamonov Автор
06.01.2018 01:48Давайте не путать. Исключение — возникает, руководствуясь им, процессор считает результат спекулятивного выполнения невалидным и сбрасывает весь конвейер. Исключение — это внутренняя ошибка процессора, она наружу не всегда передаётся.
К генерации прерывания это исключение не приводит, так как любые прерывания при спекулятивном выполнении генерируются тогда и только тогда, когда оно будет признано успешным.
Вот если бы это было не спекулятивное выполнение, тогда да, исключение приводило бы к прерыванию, а атакующая программа получала бы от ОС в лоб segmentation fault.Danil1404
06.01.2018 11:35Именно это описано в работе о spectre, однако в meltdown.pdf на сайте meltdownattack.com, которые я воспринимаю изначальным источником информации, рассматривается случай, когда мы напрямую читаем память ядра и напрямую получаем segmentation fault. Потом мы его обрабатываем с помощью хендлеров или подавляем с помощью TSX, но мы его получаем.
olartamonov Автор
06.01.2018 12:16Это не является принципиальным условием эксплуатации дырки.
Достаточно любым способом убедить процессор провести спекулятивное чтение из недоступной нам области. Если при этом сами мы в данную область не сунемся — прерывания не будет, но данные из неё по-любому окажутся в кэше.
interprise
06.01.2018 11:42кстати согласен с вопросом. В оригинале там реально вроде ловили уже эксепшен.

rogoz
06.01.2018 13:32У вас неправильная терминология. Исключение (exception) — это подвид прерывания (interrupt). Оба вполне реальны.
wiki.osdev.org/Exceptions
ЕМНИП, именно так обстоят дела в доках Интела.
В нашем случае это неслучившееся исключение, кандидат на исключение или ещё как-то так.
wych-elm
06.01.2018 01:55+1А, то есть, операция с доступом к защищенной памяти находится в заведомо недосягаемой ветви программы, но из-за out-of-order она все равно попадает на исполнение и потом отбрасывается, но данные в кэше остаются?
KivApple
06.01.2018 01:58+1Это уже зависит от реализации ядра. Я не вижу веских причин маппить всю физическую память в пространство ядра.
olartamonov Автор
06.01.2018 02:09+1Так просто до сих пор не было никаких причин делать иначе.
Отобрази всё, а там уже процессор разберётся, кто свой, а кто чужой.
Lsh
08.01.2018 15:02Я правильно понимаю, как происходит в современных ОС вызов функции из ядра (syscall)?
1. Весь код ядра отображается в виртуальное пространство каждого процесса. Но на эти страницы права для процесса выставлены так, что код самого процесса может по адресам страниц ядра только execute, но не read и не write.
Код процесса делает вызов по некоторому адресу относящемуся к ядру, когда процессор переходит к выполнению кода с этого адреса, то виртуальное адресное пространство не меняется т.е. весь фарш процесса остаётся по тем же адресам. Только меняется кольцо исполнения на ring 0 и код из ядра может делать всё, что хочет. Всё верно?
2. Не очень понятно, с адресом вызова. Ведь процесс мог бы сделать вызов не на адрес начала функции, а в её середину, поломав всё. Но так не происходит. Значит и execute можно делать не для всего отображённого ядра, а только для небольшой части, видимо, некоторой таблицы jump-ов на сами функции. Или как оно работает?
3. Ядро отображается целиком в виртуальное адресное пространство процесса, для экономии времени, чтобы не нужно было переписывать таблички сопоставления адресов?
4. Раньше вызов функций ядра делался через определённое прерывание, но от этого отказались, т.к. медленно?
Где про всё это прочитать? Желательно на русском. Уровень знаний: лопух, делал лабораторные работы на ассемблере в пределах ста строчек. =)
P.S.: Надеюсь, не сочтёте нубские вопросы бестактными. Вас и так, видимо, завалили комментариями к статьям.olartamonov Автор
08.01.2018 16:23Почти так.
Передача управления от пользовательского кода к ядру происходит по прерыванию, в линуксе это 0x80, т.е. процессу не надо знать заранее адреса функций ядра и не надо иметь вообще никакого доступа к адресному пространству ядра.Lsh
08.01.2018 23:40Эм… А я думал, что теперь используется инструкция syscall, вместо int.
blog.rchapman.org/posts/Linux_System_Call_Table_for_x86_64
""«Note: 64-bit x86 uses syscall instead of interrupt 0x80.»""
Только я сам перемудрил, как оно используется. Полагал, что syscall выполняется в виде «syscall адрес», а оно просто «syscall». При этом выбор происходит через регистр. Или я опять ничего не понял?

Googolplex
05.01.2018 22:19Таким образом, уязвимость открывает только доступ к структурам ядра, но не структурам других приложений.
Не совсем так. Поскольку предполагалось, что хардварной проверки доступа достаточно для защиты, в целях производительности сисколлов и удобства в ядрах большинства систем, помимо собственно структур ядра, в адресное пространство ядра отображается также и физическая память целиком. В конце концов, на 64-битных системах виртуальное адресное пространство содержит 2^64 адресов, и пусть даже у компьютера десятки и сотни гигабайт оперативки, это все равно будет капля в море виртуальной памяти. Соответственно, возможность прочитать память ядра = возможности прочитать память любого процесса, работающего рядом. В этом суть фикса KAISER и его аналогов для других ОС — он убирает это отображение физической памяти и прочих структур ядра, кроме совершенно необходимых. Плата за это — необходимость восстанавливать маппинг памяти при системных вызовах, что приводит к просадке производительности.
mm7
05.01.2018 20:36> поэтому при условии отсутствия ошибок в ПО различные процессы не имеют доступа к данным друга друга, если такой доступ не был предоставлен в явном виде.
Вообще-то различные процессы не должны иметь доступа к данным друга друга, если такой доступ не был предоставлен в явном виде, даже
при условии ПРИСУТСТВИЯ ошибок в доступающемся процессе.
Т.е. процесс дающий доступ должен явно открыть разделяюмую область и назначить права доступа на нее. А процесс пытающийся получить доступ должен его получить только если у него есть права.
И уж тем более он не должен получить доступ к неразделяемой памяти другого процесса/ядра/гипервизора. И за это должен был отвечать ЦПУ, виртуализируя адресное пространство.
olartamonov Автор
05.01.2018 21:09при условии ПРИСУТСТВИЯ ошибок в доступающемся процессе
Процесс, дающий доступ доступающемуся процессу, также относится к категории «ПО». ;)mm7
05.01.2018 22:11Но в случае данного бага от дающего процесса вообще ничего не зависит.
Он может вообще ничего не давать. А «плохой» доступающийся процесс все равно будет читать.
Поэтому, есть-ли баги в дающем ПО или нет-ли, в данном контексте — пофиг.
Что, в общем-то, очень хорошо и доходчиво описано в статье.
vmchaz
05.01.2018 20:50Если я правильно помню организацию памяти в x86 (в x86_64-процах, по-моему, не слишком сильно отличается), то:
Есть используемые системой области данных. Они доступны только из ring0 и описываются в GDT
Есть используемые программой области данных. Они доступны из ring3 и описываются в LDT
ОС делает области памяти, описываемые в GDT и используемые в ring0, недоступными для кода ring3, но в то же время они проецируются на адресное пространство любого процесса.
И вот этот эксплоит как раз позволяет считывать эти данные из системных областей памяти. И из того, что можно там найти — например, буфер клавиатуры, пароль root или ещё что-нибудь важное.
Я правильно понимаю суть уязвимости?olartamonov Автор
05.01.2018 21:10+1Правильно.
KivApple
05.01.2018 21:13+1Не соглашусь с вами. Уязвимость описана в последнем абзаце верно, но сама структура управления доступном памяти на x86, используемая в современных ОС (то есть всё до последнего абзаца) — нет.
KivApple
05.01.2018 21:11+1В современных ОС за небольшим исключением сегментация для защиты памяти не используется. То есть тупо создаётся 4 сегмента с нулевой базой и максимальной длинной. ring0 код, ring0 данные, ring3 код, ring3 данные. А вся защита уже воротится на уровне таблиц страниц, которые задают преобразование виртуальных адресов на физические. При этом у каждой страницы есть флаг «доступно из ring3». Для кода из ring0 (в CS в настоящий момент находится селектор сегмента ring0 кода) этот бит игнорируется, для кода из ring3 при отсутствии этого бита происходит прерывание и ядро решает, что делать с провинившимся процессом.
vmchaz
05.01.2018 21:37Спасибо!
А как работает контроль доступа по адресам, на который возлагается надежда в патче?
Нужные страницы будут проецировать на виртуальное адресное пространство только внутри системных вызовов, а перед выходом — убирать проекцию?Googolplex
05.01.2018 22:23+1Что-то вроде этого, да. Почти все структуры ядра, кроме тех, которые необходимо маппить из-за архитектуры процессора, перестанут маппиться "по умолчанию", Цитата из статьи о Meltdown:
The KAISER patch by Gruss et al. [8] implements
a stronger isolation between kernel and user space.
KAISER does not map any kernel memory in the user
space, except for some parts required by the x86 archi-
tecture (e.g., interrupt handlers). Thus, there is no valid
mapping to either kernel memory or physical memory
(via the direct-physical map) in the user space, and such
addresses can therefore not be resolved. Consequently,
Meltdown cannot leak any kernel or physical memory
except for the few memory locations which have to be
mapped in user space.
We verified that KAISER indeed prevents Meltdown,
and there is no leakage of any kernel or physical memory.
Furthermore, if KASLR is active, and the few re-
maining memory locations are randomized, finding these
memory locations is not trivial due to their small size of
several kilobytes. Section 7.2 discusses the implications
of these mapped memory locations from a security per-
spective.
Karpion
05.01.2018 22:48Кроме того, участки памяти могут иметь разные уровни доступа, контроль за которыми также осуществляет MMU — в результате пользовательское приложение не сможет получить доступ к памяти, занимаемой ядром системы или драйверами, даже если соответствующие адреса формально ему доступны.
Вот тут я немного не понял: зачем надо делать какие-то куски памяти формально доступными процессу и при этом запрещать ему доступ через уровень доступа.
у современных процессоров есть процедуры косвенной адресации, указывающие, что процессор должен прочитать значение X, лежащее по адресу Y, а потом — значение Z, лежащее по только что прочитанному X
Хотелось бы примеры таких инструкций. Насколько я помню, это требует двух инструкций процессора; впрочем, при достаточно длинном конвейере это не помешает.
Представьте, что у нас есть доступная приложению область памяти, поделённая на два куска с разными приоритетами — у одного приоритет собственно приложения, у другого приоритет ядра {...} — дёрнуть что-то из того же куска виртуальной памяти намного быстрее, чем ходить каждый раз в другой кусок, а приоритеты решают проблему запрета приложению на прямой доступ к этому куску.
Ну, хорошо. А что лежит во втором куске памяти? Я надеюсь, там нет ничего такого, что не имеет отношения к этому приложению (например, список страниц памяти данного приложения или список открутых им файлов).
На адресе 98 время доступа вдруг оказывается в несколько раз ниже, чем на других адресах
Вообще-то, кэш загружает в себя данные большими кусками. Т.е. на процессора 386 и 486 с размером строки кэша в 16 байт быстрый доступ будет к адресам от 96 до 111; а на современных — даже трудно представить себе, сколько именно.
Наверно, надо как-то так: «Процессор в спекулятивном режиме читает значение по адресу 15000. Пусть там будет лежать, например, 98. Это число умножается на размер строки кэша (ну, там не умножение, а сдвиг) — и тогда уже делается следующее чтение.
Наше приложение начинает читать адреса от 0 и выше в собственном адресном пространстве (имеет полное право), замеряя время, требующееся на чтение каждого адреса
Простите, а каким таймером можно замерить это время? Ведь тут даже нельзя накапливать статистику, многократно читая одно и то же место памяти — ибо разница будет только на первом обращении, а потом содержимое памяти уже в кэше.
Таким образом мы можем прочитать всю память ядра системы, на которую, в свою очередь, в современных ОС отображается вообще вся физическая память компьютера.
Ну и какой неумный человек додумался отображать в память ядра „всю физическую память компьютера“???
И вообще, глупость какая-то получается:
Сначала нам говорят, что в адресном пространстве процесса/приложения есть его собственная память; а есть память ядра, защищённая от доступа уровнем доступа.
А потом оказывается, что в этом адресном пространстве (в области, защищённой уровнем доступа) есть вообще вся память компьютера. Что эта „вся память компьютера“ там делает, зачем она там нужна?
При этом не надо забывать, что Javascript в браузере — это тоже локально выполняющийся код.
Вообще-то, Javascript в браузере — это интерпретируемый код, а не код процессора. К тому же он не умеет обращаться напрямую к адресам. Или я отстал от жизни?
глупо предполагать, что Intel запланировала это за двадцать лет до реального использования и в надежде, что никто раньше не обнаружит случайно.
Сделали уязвимость — и спокойно ждали, что кто-то обнаружит уязвимость. Неважно, когда.olartamonov Автор
06.01.2018 00:18Вот тут я немного не понял: зачем надо делать какие-то куски памяти формально доступными процессу и при этом запрещать ему доступ через уровень доступа.
Потому что процесс иногда обращается к функциям ядра, а обращаться к тому же куску виртуальной памяти — сильно быстрее, чем к другому. При этом процесс не должен быть способным напрямую читать эту память.
А что лежит во втором куске памяти? Я надеюсь, там нет ничего такого, что не имеет отношения к этому приложению
Туда ядро отражено. Там лежат тонны всего, что не имеет никакого отношения к этому приложению.
Это число умножается на размер строки кэша
Излишнее усложнение объяснения, требующее уйти в рассуждения об организации кэша. Но да, на практике, при реальной атаке — умножается.
Простите, а каким таймером можно замерить это время?
Микросекундного на практике более чем достаточно.
А потом оказывается, что в этом адресном пространстве (в области, защищённой уровнем доступа) есть вообще вся память компьютера
Вы концепцию виртуальной памяти себе представляете? У процесса потенциально есть 64 бита адресного пространства, туда не то что всю память компьютера отобразить можно, а добрую половину галактики, и не заморачиваться по этому поводу.
Вообще-то, Javascript в браузере — это интерпретируемый код, а не код процессора
Интерпретируемый код в конечном итоге выполняется тем же процессором, а отнюдь не святым духом.
Неважно, когда
Также, видимо, неважно, кто из конкурентов на этом себе продажи поднимет.Karpion
06.01.2018 06:48Потому что процесс иногда обращается к функциям ядра, а обращаться к тому же куску виртуальной памяти — сильно быстрее, чем к другому.
Впервые слышу, что вирт.память делится на куски. Про страницы — знаю. Про сегменты (а также ппро проблемы от их использования) — знаю. А вот слово «кусок» в данном применении вижу впервые. Как оно в оригинало хоть звучит?
Туда ядро отражено. Там лежат тонны всего, что не имеет никакого отношения к этому приложению.
Я бы понял, если бы в адресное пространство процесса отображались только данные тех функций, которые этот процесс может вызвать. Но зачем передавать туда вообще всё, что имеется в распоряжении ядра?
Я вижу только одну причину: архитекторам системы было лень осуществлять изоляцию разных сущностей (тут часто говорят «уровней абстракции»; но термин неадекватен, ибо это не стек, не иерархия) друг-от-друга.
Кажется, старик Танненбаум с его идеей микроядра был прав: с микроядром такие фокусы не прокатили бы.
И кстати, интересно — способна ли подобная атака выйти за пределы вирт.машины.
Излишнее усложнение объяснения, требующее уйти в рассуждения об организации кэша.
А без этого объяснения — совершенно неясно, каким образом это работает. Да собственно, описанный алгоритм и не работает.
Микросекундного {таймера} на практике более чем достаточно.
Хм, а как его опрашивают? Не будет ли опрос таймера сбивать содержимое кэша?
Кстати, опрос таймера с высокой частотой — это характерный признак подобной атаки. Особенно вкупе с действиями по опустошению кэша.
У процесса потенциально есть 64 бита адресного пространства, туда не то что всю память компьютера отобразить можно, а добрую половину галактики, и не заморачиваться по этому поводу.
Мне кажется, Вы путаете «можно» и «нужно».
Интерпретируемый код в конечном итоге выполняется тем же процессором, а отнюдь не святым духом.
Я в курсе. Однако, интерпретатор может не содержать кода, который внутри условного оператора обращается к недоступной ему памяти!
Также, видимо, неважно, кто из конкурентов на этом себе продажи поднимет.
У Intel разве есть конкуренты? ;)olartamonov Автор
06.01.2018 11:55А вот слово «кусок» в данном применении вижу впервые. Как оно в оригинало хоть звучит?
«Блоки адресного пространства с различными уровнями доступа» вас устроит? Ну если да, то так дальше и пишите.
Но зачем передавать туда вообще всё, что имеется в распоряжении ядра?
Затем, что иначе вам надо целенаправленно писать процедуры, которые смогут разделить то, что нужно передавать, и то, что ненужно. Если вы на минуту задумаетесь об этом вопросе — вам станет понятно, почему ни один человек в здравом уме этого делать не будет.
То есть, например, с вашей точки зрения, как будет выглядеть механизм, определяющий, что именно в линуксовом ядре надо показать процессу для выполнения им конкретного сисколла?
Хм, а как его опрашивают? Не будет ли опрос таймера сбивать содержимое кэша?
Вы себе представляете кэширование значения, запрошенного у таймера?.. Во-первых, с какой целью вы себе это представляете, во-вторых, на x86 самый точный из таймеров — это одна команда, RDTSC, отдаёт 64-битный счётчик циклов процессора.
У Intel разве есть конкуренты? ;)
Ах, ну да, ещё Мур в семьдесят третьем писал, что нет и он может на пятьдесят лет гарантировать, что не будет.Karpion
06.01.2018 21:35-2
Т.е. сторонники микроядерной архитектуры — ненормальные? А мне после прочтения этой статьи показалось, что именно они оказались правы — хотя аргумент в их защиты приплыл с совершенно неожиданной стороны.Но зачем передавать туда вообще всё, что имеется в распоряжении ядра?
Затем, что иначе вам надо целенаправленно писать процедуры, которые смогут разделить то, что нужно передавать, и то, что ненужно. Если вы на минуту задумаетесь об этом вопросе — вам станет понятно, почему ни один человек в здравом уме этого делать не будет.
Впрочем, я сейчас размышляю над куда более интересной идеей — «надо отказаться от UMA и перейти к полностью раздельной памяти». В такой системе ядро операционки будет частично выполняться на пользовательских процессорах (их много), а частично будет вынесено на собственные процессоры (их тоже много). И у каждого процессора будет своя собственная память.
При такой схеме ситуация «в адресном пространстве ядра в числе прочего есть вся физическая память компьютера» становится физически невозможна.
То есть, например, с вашей точки зрения, как будет выглядеть механизм, определяющий, что именно в линуксовом ядре надо показать процессу для выполнения им конкретного сисколла?
Очевидно — данные, затрагиваемые этим сисколлом.
Вы себе представляете кэширование значения, запрошенного у таймера?
А кроме этого значения ничего более не используется?
Впрочем, ответ «RDTSC» снимает все вопросы — это действительно не сбивает кэш.

Waki
06.01.2018 00:20-1по поводу javascript, я думаю это кто-то ляпнул в одной из первых статей про уязвимость, а дальше начали копипастить
vvzvlad
06.01.2018 00:31Достаточно призрачной теоретической возможности, чтобы опасаться — с учетом того, что какой JS выполняется на компах, никто и никогда не контролирует, полагаясь на изоляцию от других сайтов и от других процессов.
olartamonov Автор
06.01.2018 00:53+1Ляпнули там примерно так, цитирую:
«Attacks using JavaScript. In addition to violating process isolation boundaries using native code, Spectre attacks can also be used to violate browser sandboxing, by mounting them via portable JavaScript code. We wrote a JavaScript program that successfully reads data from the address space of the browser process running it»

anshdo
07.01.2018 02:43Вообще-то, Javascript в браузере — это интерпретируемый код, а не код процессора. К тому же он не умеет обращаться напрямую к адресам. Или я отстал от жизни?
Гугловский V8, например, использует JIT-компиляцию. А напрямую обращаться к адресам не обязательно, можно сделать это косвено, например, запросив элемент массива с индексом, выходящим за его границы.
Karpion
07.01.2018 03:00Для этого надо, чтобы JIT-компилятор сгенерил код, реализующий соответствующую атаку. Ну, допустим, мы можем долго экспериментировать с JS-программой, анализируя, какой код получается.
Но дальше нам надо знать, какие адреса у нас свободны, а какие заняты. Как нам это сделать?
Ну и наконец, командой "RDTSC" (см.выше) воспользоваться явно не получится.

sumanai
07.01.2018 06:52Ну и наконец, командой «RDTSC» (см.выше) воспользоваться явно не получится.
В JS есть свои счётчики, и похоже их разрешения хватает. Патчи в браузеры как раз огрубляют их показания.
anarky92
06.01.2018 00:09Я правильно понял, что вычитать данные, лежащие в 15000, если там было записано 98, мы сможем, увидев изменение скорости на чтении по адресу 98? А если бы там лежало нечто такое, на что нам адресов не хватило бы?
olartamonov Автор
06.01.2018 00:10Правильно.
В остальных случаях надо придумывать, какую операцию произвести над лежащим по нужному адресу, чтобы для её результата всего хватило.

Barsuk
06.01.2018 00:412. Процессор читает значение, лежащее по адресу 98.
А что если этот адрес тоже не доступен? Может такое быть?olartamonov Автор
06.01.2018 00:55Так как эти адреса возникают в результате выполнения нашего собственного кода, в него можно просто загнать арифметику, которая отобразит результат на заведомо доступное нам адресное пространство.
Sizt
06.01.2018 02:09Статья об атаке на кэш из браузера за 2015 год (!!!)
arxiv.org/pdf/1502.07373.pdfolartamonov Автор
06.01.2018 02:25+1Ну это всё так было, звоночки, в подобных работах или скрытая намеренная передача данных между двумя софтинами, или генерализованное «отслеживание активности».
А так, чтобы напрямую чужие байты из памяти тырить — первый раз.

Alexeyslav
06.01.2018 02:34На самом деле, вопрос о реализации кеша именно в интеловских процессорах и возможность ПОДОБНОЙ уязвимости была озвучена как минимум лет 5 назад… просто тогда это было не так актуально и не резонансно, о Heartbleed ещё никто даже не подозревал… ну а сейчас просто выстрелило.
razielvamp
06.01.2018 08:20А что с виртуальными площадками (AWS, Azure, ...)?
Предположим, крутится у меня линух на одной из них. Поставил я на него заплатку. А злоумышленник запустил свою виртуалку, и, естественно без патча. В итоге делим мы с ним один проц, кэш общий, и он может из свой ОС читать все, что внутри моей, и даже патчи не помогут?firk
06.01.2018 08:28+1Нет, не сможет.
razielvamp
07.01.2018 19:31Окей.
Значит уязвимость даже в случае виртуальных площадок сугубо локальная, и если не запускать на сервере стороннего кода (и уж тем более страниц c JS через командную строку), то, формально, можно не беспокоиться?
И если все действительно так, то в данном случае большему риску подвергнуты скорее пользовательские машины, чем сервера (на которых локально установлен только необходимый софт)?razielvamp
07.01.2018 19:37Немного упустил из вида про патч в своем вопросе, поэтому уточню.
Информацию из соседней виртуалки не получится выкрасть в случае установленного патча или не получится даже и без патча, если, именно, локально не запустить?

DoctorMoriarty
06.01.2018 08:38Есть вопрос к компетентным товарищам: зашёл я на интеловский сайт с описанием действий при обсуждаемой проблеме — Intel Management Engine Critical Firmware Update (Intel-SA-00086) и забрал оттуда утилиту Intel-SA-00086 Detection Tool. Процессор у меня на основной рабочей станции Intel Core i5-3450, чипсет — H61, версия Intel ME — 11.0.0.1156. И утилита мне выдала занятное — «Эта система не является уязвимой.»
Значит ли это, что мне чудовищно повезло и мало того, что ME обновлять не надо, так еще и обновление KB4056892 на Windows 10 мне не нужно?oteuqpegop
06.01.2018 11:56По вашей ссылке другая уязвимость (которую товарищи из Positive Technologies летом нашли, а осенью опубликовали), никакого отношения к Meltdown/Spectre она не имеет.
acDev
06.01.2018 10:56+1Для винды уже появилась тестовая тулза, которая считывает байтики из ядра:
github.com/stormctf/Meltdown-PoC-Windows/tree/master/Meltdown/x64/Debug
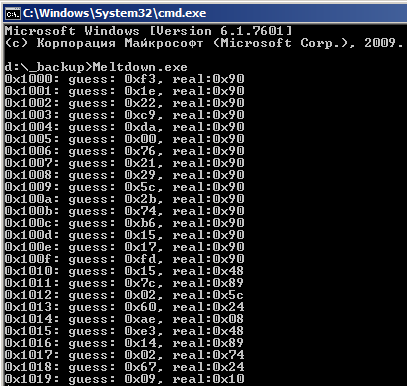
Эти байтики находятся в самом начале образа ntoskrnl.exe (см. на картинке ряд real).KivApple
06.01.2018 18:56Выглядит как-то так себе. Что, на мой взгляд, ожидаемо — современные ОС многозадачные и кеш забивают многие другие процессы.
z0mailbox
09.01.2018 01:08проверил на нескольких компах — ни байта не сходится
кстати екзешник там странный 212480 байтов
многовато
я перекомпилил сорцы получил 8704 :)
webhamster
06.01.2018 11:12> Кто бы это мог быть? Ах, да, это наш дорогой процессор. По адресу 15000, соответственно, лежит значение 98.
Из описания проблемы совершенно непонятно, откуда код приложения берет цифирь 15000, которое является адресом в пространстве ядра.olartamonov Автор
06.01.2018 11:57Из автора кода, который решил, что ему интересно будет почитать этот адрес.
N1ghtwish
06.01.2018 11:57Насколько теперь реально сбагрить интеловские процы по гарантии, и получить деньги по чеку?

Lord_Ahriman
06.01.2018 16:03Сразу предупреждаю: вопрос не ради спора, а исключительно
токмо ради пославшей мя женыради интереса. Насколько вообще реальна атака с применением Metldown in-the-wild? Ведь, в отличие от PoC, вредоносному коду/атакующему не известны базовые адреса загрузки прикладных программ в произвольно взятой системе, а, значит, например, добраться до памяти браузера и хешей/паролей будет довольно нетривиально (не перебирать же и тем более не дампить всю доступную память?). Ведь, насколько я помню, например, Windows гарантирует загрузку только компонентов ядра по определенным адресам, даже системные DLL грузятся динамически (могу ошибаться, интересовался этим очень давно).willyd
06.01.2018 16:18VPS сервис. к примеру. Если на хосте чувствительные данные есть в переменных окружения, то их можно будет получить сдампив кусок памяти.
olartamonov Автор
06.01.2018 16:28Так ядро знает, какой процесс у него где живёт, и если мы имеем доступ к памяти ядра, мы тоже можем это узнать.
Lord_Ahriman
06.01.2018 17:31+1Спасибо, слона-то я и не приметил. Ведь такой код сможет читать системные таблицы, так что вопрос отпадает.

evil_random
06.01.2018 17:27А что мешает сдампить всю, а потом регулярками номера кредиток найти? Уязвимости обычно всегда используются в паре или трио. Сам факт, что подобное возможно ставит безопасность компьютерных систем под большой вопрос.
Lord_Ahriman
06.01.2018 17:33Как вы себе это представляете? Незаметно сдампить, скажем, 16 ГБ памяти (при том, что чтение через Meltdown весьма небыстрая операция) и потом ее передать куда-то? Это, во-первых, слишком заметно и, во-вторых, абсолютно нецелесообразно. Эти же дампы потом еще надо будет где-то хранить и как-то обрабатывать.
evil_random
06.01.2018 17:37Ну что Вы в самом деле.
Петя вон сидел в системе и не шевелился до своего звёздного часа.
Что мешает в дуэте с другой уязвимостью дождаться пока юзер пойдет спать, а потом начать читать всё подряд или тыкать палочкой в процессы которые хранят ключи и кредитные карты, или банально делать те же дампы при живом юзере, только не загружая процессор так, что юзер заметит. Часто обычный пользователь наблюдает за тем, какой процесс сколько ресурсов использует? Да 99% пользователей даже не знает где это посмотреть.
sumanai
06.01.2018 17:41+1А зачем передавать? Можно регулярки локально применить и передать только номера карточек/пароли от банка/ssh.

perfect_genius
06.01.2018 17:02Насколько же человечество себя плохо вело в 2017м, раз такой подарочек от Санты?
Alexeyslav
07.01.2018 01:02Может наоборот хорошо, раз санта раскрыл такой подарочек, заложеный ещё 10 лет назад и способный пролежать незамеченным ещё с десяток, кабы не дотошные студенты.
evil_random
06.01.2018 17:33Правильно ли я понимаю, что в будущем появится два типа процессоров: «защищённые и быстрые» и «не защищённые и очень быстрые»? Скажем для кодирования видео не важно защищенный процессор или нет.
olartamonov Автор
06.01.2018 17:49Нет.
Во-первых, дыры такие, что для всех важно, защищённый это процессор или нет — кроме случая работы в строго контролируемом окружении, что для x86 некоторая редкость (поэтому, например, для Cortex-R наличие дырок не слишком принципиально, это процессоры для задач жёсткого реального времени, они в системах, где пользователь может какой-то код загрузить и исполнить, встречаются примерно никогда).
Во-вторых, Meltdown аппаратно можно закрыть без существенной потери производительности. Со Spectre сложнее, но вариант 2 тажке можно закрыть аппаратно без существенных потерь.
NB: существенными я считаю потери больше 2-3 %.
evil_random
06.01.2018 17:52По сути Intel обманул и сам себя и весь мир: я бы назвал это «незаконная производительность». Это как бизнес построенный только на «чёрные деньги». Невозможен в принципе если играть по правилам.
Reconstructor
07.01.2018 01:10Я что-то не понял: «адреса от 0 и выше в собственном адресном пространстве».
BYTE* p = 0; BYTE dest = *p;
Так, что ли? Если так, то это, очевидно, работать не будет. :)olartamonov Автор
07.01.2018 01:13Не будет работать где?
Reconstructor
07.01.2018 10:57Везде? Не существует ОС, в которой NULL — валидный адрес. Как и все в интервале 1-0xFF.
olartamonov Автор
07.01.2018 11:11+1А что, у нас NULL обязательно имеет значение 0? Во всех языках программирования?
Я даже не говорю о том, что вы придираетесь к числам, про которые прямо сказано, что они написаны для примера. Вам в этом примере сколько ещё упрощений показать, которые вы не заметили?Reconstructor
07.01.2018 12:01они написаны для примера
Я из тех людей, которым нужно полное и правильное объяснение, упрощенные примеры для меня малопродуктивны. Поэтому я и задал свой вопрос.olartamonov Автор
07.01.2018 12:08Для вас на Хабре есть пост с ассемблерными вставками.
К сожалению, под критерий полноты он подходит лишь частично, потому как не охватывает процессоры MIPS, ARM, SPARC, Power и некоторые другие.

bolk
07.01.2018 11:55С третьей стороны, так как до недавних пор память считалась сравнительно безопасным местом временного хранения данных, то все ваши пароли и сертификаты лежат в ней в открытом виде.
А как же «простукивание» DDR?
Я вот думаю — а нельзя ли частично отравлять кеш, иногда читая рандомные данные, чтобы внести некоторый процент шума в замеры времени доступа? Не будет ли вреда меньше?olartamonov Автор
07.01.2018 12:10Да и «простукивание кэша» уже демонстрировали.
Но это всё атаки, которые выполнялись либо в сугубо лабораторных условиях, либо демонстрировали передачу данных между двумя заранее подготовленными программами (например, через кэш процессора между двумя VM, не имеющими прямой связи друг с другом), либо демонстрировали лишь некие общие паттеры проходящей на компьютере активности.
Здесь же — в живой природе, без дополнительных условий, чтение чистых данных из ОЗУ.
Отравлять кэш довольно бессмысленно, его очень много у современных процессоров.
EvolViper
07.01.2018 12:07>По адресу 15000, соответственно, лежит значение 98.
Мне вот что непонятно: а что, если в участке памяти, который доступен приложению, нет значения 98?olartamonov Автор
07.01.2018 12:07Не играет вообще никакой роли, какое значение есть в участке памяти, легально доступном приложению.
heinza
08.01.2018 16:23Извините, если совсем нубский вопрос, но мне тоже непонятно.
То есть, прочитать содержимое защищённого адреса в памяти можно только в том случае, если это содержимое, в свою очередь, указывает на участок в памяти, доступный приложению? А если нет? Если по адресу 15000 находится не 98, а 16000? Или вообще не указатель, а что-то ещё?
Получается, читать можно не всю защищённую память, а только те фрагменты, которые содержат указатели на и так доступные приложению адреса?
olartamonov Автор
08.01.2018 16:36Если по адресу 15000 находится не 98, а 16000?
Замените в атаке array1[array2[x]] на array1[array2[x — 10000]]. На спекулятивное выполнение это никак не повлияет, с его точки зрения дополнительная арифметическая операция не стоит практически ничего.
NB: в настоящей атаке в индексах арифметика используется по-любому, чтобы обойти такие свойства процессора, как загрузка в кэш целыми блоками и опережающее чтение памяти.
Или вообще не указатель, а что-то ещё?
Указателей вообще не существует. Как той ложки. Это просто договорённость между программистами, что вот тут мы число считаем числом, а тут — указателем.
PavelNB
08.01.2018 16:24Кажется, что проблема раздута.
Программа запускается, ей выделяется виртуальное адресное пространство. Там есть область с куском памяти, доступной только ядру, или отображается часть рабочей памяти ядра?
Программа сможет прочитать эту область, и что там найдет?
К чему тут пароли и т.п. от других запущенных програм, они в другом адресном пространстве?
Выход простой — если программа вызвала ошибку-исключение доступа к памяти, то ОС убивает данную программу.
olartamonov Автор
08.01.2018 16:24Программа сможет прочитать эту область, и что там найдет?
Всё, что есть в физической памяти вашего компьютера.
К чему тут пароли и т.п. от других запущенных програм, они в другом адресном пространстве?
Нет. В том же.
tmf
08.01.2018 16:24Всё сошлось,
мир с его квантовыми приколами работает на процессорах с предсказанием.
Когда электрон летит через две щели, процессор просчитывает оба варианта, а когда мы его ловим — иные варианты отбрасываются…

seyko2
08.01.2018 16:24С целью ускорения при операции чтения проверка прав доступа и само чтение выполняются одновременно. Так что практически все процессоры должны быть уязвимы. Вряд ли до сего момента кто-то заботился очистить значение в кэш при нарушении прав. У AMD это тоже, как пишут, работает, только затирается чаще. Для записи такая оптимизация не возможна.
rRo
08.01.2018 16:24а нельзя добавить в процессор процедуру принудительного обнуления в кэше данных, «запрещённых» MMU, желательно, сразу после «запрещения»?
olartamonov Автор
08.01.2018 16:32Не поможет, для обхода достаточно будет инвертировать логику атаки — искать в кэше не строку, которую спекулятивное выполнение туда занесло, а строку, которую оно оттуда удалило.
ferreto
09.01.2018 08:29Так понимаю, что владельцам яблочной техники, в отличие от андроидов, нечего бояться. Пусть пооцессоры в теории и имеют уязвимость, но политика эйпл в плане проверок приложений перед отправкой в стор сводит возможность её использования на нет. Остаётся джэйл и левые приложения. Но для последних операционок джэйла нет.



{kind=link}
{kind=link}
{kind=link}
AlAnSa
Звучит так, как будто процессоры AMD не подвержены уязвимости из-за того, что они просто медленнее и успевают дождаться ответа mmu о некорректности вызова адреса памяти. Но вот сейчас замедлят Intel до их уровня — и будет ок.
Не холивара ради :)
olartamonov Автор
Или что MMU у них работает по другой логике и поэтому отрабатывает быстрее. Или что-то ещё, кто ж нам расскажет-то (нет, ну я знаю пару-тройку людей, которые наверное могли бы, но они ж мне расскажут только если я сначала в письменной форме пообещаю вам не рассказывать).
Причём на самом деле возможна и ситуация, что уязвимость у них столь же реальна, просто эксплоиту её надо отрабатывать быстрее или чуть иначе — но я в целом к этому отношусь как к маловероятному варианту.
AlAnSa
Вот это, кстати, самое интересное. Потому что не очень верится в столь большие различия в архитектуре процессоров у самых заклятых друзей.
Жаль, очень жаль.
olartamonov Автор
Ну почему, вот я вижу гипотетический сценарий, в котором процессор успевает прочитать первый адрес, но пока он читает второй (там же оба процесса медленные, он же их по первому разу читает из ОЗУ) — к нему прибегает MMU с воплями, и проц прерывает выполнение, в итоге не донося результат до кэша.
Это не какое-то грандиозное архитектурное отличие, это в общем-то нюансы реализации, на которые до сих пор никто мог даже не обращать особого внимания, а выбирать их исходя из длины конвейера, архитектуры MMU, архитектуры контроллера памяти и архитектуры чёрта в ступе.
kryvichh
Короч, либо архитекторам AMD несказанно повезло, или они что-то предполагали с самого начала, лет надцать назад.
Ждём про Spectre, там всё чудесатее, и непонятно вообще можно ли его эксплуатировать на реальных системах.
interprise
можно, но сложней. Для амд есть патч который убирает эту брешу, падение производительности на уровне погрешности.
olartamonov Автор
Да хватит бредить, нет этого патча.
См. вторую часть.
interprise
я конечно гляну, но получает амд врет?
olartamonov Автор
AMD нигде не говорит, что этот патч есть у AMD или у кого-либо ещё.
AMD говорит, что однажды нам его кто-нибудь сделает.
geisha
Ну AMD сообщает, что их процессоры как раз корректно отрабатывают это исключение поэтому и не подвержены meltdown. Т.е. атака по таймингу есть, а вот вылазки за адресное пространство — нет. В связи с этим вам, возможно, правильнее использовать "процессоры Intel" вместо "процессоры" — в статье и комментариях.
olartamonov Автор
Да там уже не только Intel, ARM тоже отметился.
geisha
Ну я просто за справедливость: если разность в производительности/энергоэффективности Intel vs AMD последние 15 лет была обусловлена тем, что Intel забивала на bounds check до последнего момента, то сейчас справедливо было бы уточнять, что не все процессоры выполняют вторую строку кода (а скоро никто не будет).
Alexeyslav
Я когда-то читал статью по устройству кешей в процессорах, из неё я точно помню что у INTEL и AMD работа кеша отличается довольно принципиально. Причем там же было предположение о возможности нынешней уязвимости на интеловских процессорах. Как-то они лихо срезали углы в ущерб безопасности но повысили быстродействие. Но это было достаточно давно, саму статью естественно не помню, читал её почти по диагонали — тогда это было просто интересно. Видимо тогда резонанс просто не получился ибо предполагали что уязвимость слишком сложная для реализации.
datacompboy
Если успели сходить только по первому (невалидному) адресу, то всё равно можно оценить, например — по изменению объёма наших закешированных данных.
насколько понял из пейпера, это и пытались сделать — просто вероятность паршивая
SandroSmith
Так а кто ж даст кэш взвесить?
datacompboy
Это отдельная задача. Оценка какая линейка сейчас в кеш упала тоже сложная штука, но решилась же.
wadeg
Если я все правильно понял, то за один раз возможно проверить байт по интересующему адресу на совпадение с одним значением (на 0 для простоты). Значит, реализуя тот же трюк второй раз, проверяем на 1. Итого, не более чем за 256 проверок будет получен результат. Где я налажал с рассуждениями?
a5b
В https://lkml.org/lkml/2017/12/27/2 представитель amd Tom Lendacky писал, что все операции доступа в память, в т.ч. спекулятивные у амд проверяют уровни доступа (и отключил kpti для amd — https://github.com/torvalds/linux/commit/694d99d40972f12e59a3696effee8a376b79d7c8):
olartamonov Автор
Да, вполне может быть и так. Тогда на AMD даже теоретической возможности эксплоита нет (а «игрушечный пример» в оригинальной работе по Meltdown, строго говоря, не демонстрирует доступ спекулятивного выполнения именно к закрытой от процесса памяти).