Несмотря на всю мощь уязвимости Meltdown, принесённое этим Новым годом счастье не было бы полным, если бы не вторая часть открытия, не ограничивающаяся процессорами Intel — Spectre.
Если говорить очень-очень коротко, то Spectre — принципиально схожая с Meltdown уязвимость процессоров в том смысле, что она тоже представляет собой аппаратную особенность и эксплуатирует непрямые каналы утечки данных. Spectre сложнее в практической реализации, но зато она не ограничивается процессорами Intel, а распространяется — хоть и с нюансами — на все современные процессоры, имеющие кэш и механизм предсказания переходов. То есть, на все современные процессоры.
Строго говоря, Spectre не является одной уязвимостью — уже на старте заявлены два различных механизма (CVE-2017-5753 и CVE-2017-5715), а авторы отмечают, что может быть ещё и много менее очевидных вариантов.
В основе своей Spectre похожа на Meltdown, так как также базируется на том факте, что в ходе спекулятивного выполнения кода процессор может выполнить инструкции, которые он не стал бы выполнять при условии строго последовательного (неспекулятивного) вычисления, и, хотя в дальнейшем результат их выполнения отбрасывается, его отпечаток остаётся в процессорном кэше и может быть использован.
Любой современный процессор в целях даже не улучшения эффективности, а обеспечения самой возможности спекулятивного выполнения команд имеет Branch Prediction Unit, блок предсказания ветвлений, в задачу которого входит оценка вероятности, с которой выполнение пойдёт по тому или иному пути после какого-либо условия, без предварительного расчёта этого условия. Блок предсказания работает статистически, то есть накапливает данные о выполненных на данный момент похожих ветвлениях, и на их основе прогнозирует исход каждого следующего ветвления.
То есть, например, если код if (a < b), для расчёта которого надо долго и печально загружать a и b, тысячу раз подряд выдал true, то на тысяча первый раз можно с большой уверенность решить, что и сейчас будет true, ещё до того, как из памяти загрузились a и b и собственно произошла проверка.
Что ещё интереснее, процессоры не делают различий между тем, в каких процессах вычисляется это условие. Поэтому, если в процессе malware.exe тысячу раз подряд такой if выдавал true, то процессор будет считать, что первый же похожий if в процессе word.exe также вернёт true.
Это довольно логично, так как в разных программах может встречаться масса очень похожих конструкций, поэтому тренировать блок предсказания на всём потоке данных — эффективнее, чем на одном конкретном процессе.
По сути, только что я описал механизм, с помощью которого программа malware.exe может управлять ходом выполнения программы word.exe, не имея на то ровным счётом никаких формально утверждённых прав.
До 3 января сего года было принято считать, что в этом нет никакой опасности — в конце концов, если что-то пойдёт не так, как ожидает word.exe, процессор в конечном итоге признает ветку спекулятивных вычислений недействительной, сбросит конвейер к исходному состоянию и пересчитает всё заново, на этот раз уже последовательно. Word.exe даже ничего не заметит, кроме небольшой неравномерности в темпе исполнения инструкций процессором.
На этом месте ещё похоже на Meltdown, но дальше начинаются различия. Как мы помним, Meltdown не работает на процессорах, которые вовремя — раньше фактического окончания выполнения последовательности команд — проверяют условия доступа процесса к чужой памяти даже в случае спекулятивного выполнения.
У Spectre такой проблемы не возникает, потому что Spectre не подразумевает прямого доступа к чужой памяти ни в каком виде, даже при спекулятивном исполнении. Вместо этого Spectre делает так, чтобы атакуемый процесс (это может быть как ядро системы, так и другая пользовательская программа) сам выдал сведения о содержании собственной памяти.
Представьте в коде атакуемого процесса такую конструкцию, причём переменная x является следствием какого-то пользовательского ввода, на который мы можем влиять:
if (x < array1_size)
{
y = array2[array1[x]];
}Теперь мы берём и пишем в своёй программе, эксплуатирующей уязвимость, максимально похожую конструкцию, и выполняем её много-много раз, причём каждый раз честно вычисленное условие выдаёт true, индексы массива совершенно валидны, и вообще всё хорошо. Блок предсказания ветвлений таким образом набирает статистику, говорящую, что эта конструкция всегда вычисляется в true, поэтому, встретив её, можно не ждать окончания вычисления условия, а сразу переходить к содержимому.
А теперь мы передаём в атакуемую программу такие данные, что x вдруг выскакивает куда-то далеко за пределы массива array1. Если бы спекулятивного выполнения не было бы, процессор посчитал бы условие x < array1_size, нашёл его невалидным и перепрыгнул бы дальше. Но оно есть, и блок предсказания выдаёт ему, что x < array1_size почти наверняка будет выполнено, поэтому, пока откуда-то из памяти медленно и печально подсасывается значение array1_size, чтобы действительно выполнить сравнение, процессор начинает выполнять тело этого куска кода.
Важным моментом в атаке, кстати, является пункт «медленно и печально» — если array1_size лежит готовый где-то в кэше, процессор может не заморачиваться со спекулятивным вычислением, а просто быстро посчитать условие. Поэтому array1_size должен быть в ОЗУ, откуда его придётся долго доставать.
Значение x мы выбираем таким, чтобы оно указывало на адрес в области памяти атакуемой программы, который мы хотим прочитать. Допустим, по нему хранится значение k, при этом нам также потребуется, чтобы данное значение уже было загружено в кэш ранее.
Последнего добиться часто не очень сложно — если, например, мы хотим стащить приватный ключ у программы шифрования данных, достаточно предыдущим действием просто совершенно легально попросить программу нам что-нибудь зашифровать, тогда она сама обратится к этому ключу, а процессор, соответственно, затащит его в кэш. Напомню, что ещё одним условием было отсутствие других участвующих в процессе переменных в кэше, но это может быть реализовано простым забиванием кэша всяким мусором от имени атакующего процесса, а то и просто инструкцией принудительного сброса кэша, если такая есть на атакуемом процессоре.
Итак, всё подстроено так, чтобы процессор прочитал array1[x], который будет равен k, что он и делает. Так как k находится в кэше, процессор получает его практически мгновенно, подставляет в качестве индекса в array2 и запрашивает из ОЗУ значение, соответствующее array2[k].
После этой замысловатой цепочки наконец прибывает значение array1_size, процессор вычисляет условие, признаёт его негодным и выбрасывает результаты всех описанных выше вычислений. Исчислил царство и положил ему конец. Везде, кроме кэша.
Что особенно цинично, базовую возможность проведения атаки нам обеспечила проверка индекса массива, необходимая для обеспечения безопасности кода.
Дальше сильно проще не становится, так как нам надо теперь выяснить, что лежит в кэше — и положено оно туда от имени стороннего процесса, то есть, в отличие от Meltdown, напрямую пощупать память мы не можем.
Тем не менее, и тут могут найтись свои методы. Например, если array2 имеет достаточно валидных индексов (не менее k штук), а мы можем снаружи более-менее прямым способом побудить атакуемую программу его почитать, то на индексе k операция чтения выполнится быстрее, чем на других индексах, так как он уже закэширован.
Как нетрудно заметить, способ не отличается простотой и прямотой реализации — однако, при условии атаки на конкретное ПО, известное атакующему и по возможности доступное в исходных кодах в той же версии и на той же системе, на какой предполагается атака, он может быть реализован.
В отличие от Meltdown, этот способ может оставить следы в системы, если атакуемая программа, например, сообщает о входных данных, вызывающих переполнение индекса используемого в атаке массива.
Так же, как и в случае с Meltdown, атакующая программа не требует для себя никаких особенных привилегий, кроме самой возможности запуститься на атакуемой системе. Теоретически, атака может быть произведена даже из JS-скрипта в браузере и других интерпретируемых языков, в которых есть возможности организовать таймер с точностью, пригодной для различения скорости получения переменной из кэша и из ОЗУ.
Это был первый вариант Spectre, который я затрудняюсь как-то коротко назвать. Ко второму же так и просится простое, хорошо знакомое русскому уху название: Гаджеты.
Нет, гаджет в данном случае — это не ваш айфон. Гаджет — это то, что можно использовать для вытаскивания из вашего айфона ваших паролей без вашего ведома.
Гаджет — это последовательность команд в адресном пространстве атакуемой программы, которая может быть использована для атаки. Задачей такой последовательности является организация утечки данных если не напрямую, то через кэш по описанному выше механизму, поэтому последовательность может быть достаточно короткой, а также никак вообще не связанной с какими-либо программными уязвимостями — прямой утечки данных за пределы контролируемой атакуемой программой области памяти, напомню, не происходит.
Важный момент: эта последовательность не создаётся и не вносится атакующим, то есть, опять же, de jure вторжения в атакуемую программу не происходит. Атакующий просто находит нужный ему кусочек кода в теле атакуемой программы или какой-либо из загруженных ей библиотек; более того, в некоторых случаях ему не требуется даже предварительный анализ ПО — непосредственно на атакуемой системе можно попробовать найти нужную последовательность в общеупотребимых системных библиотеках in situ, логично предполагая, что атакуемая программа также эти библиотеки использует.
Исследователи из Google и вовсе использовали функцию BPF — это механизм, существующий в Linux и FreeBSD и позволяющий пользовательскому приложений подцепить к ядру системы свой фильтр, например, для отслеживания I/O-потоков. В данном случае, понятно, совершенно неважно, что этот фильтр будет делать — важно, чтобы в каком-то его месте была нужная нам последовательность команд.
Nota bene: из этого родилась версия, что уязвимость Spectre неприменима при выключенном BPF. Это не так.
Чтобы перевести выполнение атакуемой программы на нужную последовательность, используется подход, похожий на описанную выше тренировку блока предсказания ветвлений — в процессоре есть аналогичный блок предсказания переходов, который пытается угадать, по какому адресу будет совершён переход очередной инструкцией косвенного перехода (мы все помним эти инструкции по Meltdown, но тут они играют другую роль).
Для упрощения работы этот блок не выполняет трансляцию между виртуальными и реальными адресами, а значит, может быть натренирован в адресном пространстве атакующего на определённые действия в адресном пространстве атакуемого.
То есть, если мы знаем, что нужная нам инструкция в атакуемой программе лежит по адресу 123456, а также в этой программе есть регулярно исполняемый косвенный переход. В атакующей программе мы пишем конструкцию, максимально похожую на переход в атакуемой, но при этом всегда выполняющую переход по адресу 123456. В нашем адресном пространстве, конечно, абсолютно валидный и легальный переход. Что именно у нас лежит по адресу 123456, никакого значения не имеет.
Через некоторое время блок предсказания переходов абсолютно уверен, что все переходы такого вида ведут на адрес 123456, поэтому, когда атакуемая программа — с нашей подачи или по своей инициативе — доходит до аналогичного перехода, процессор радостно начинает спекулятивное исполнение инструкций с адреса 123456. Уже в адресном пространстве атакуемой программы.
Через некоторое время настоящий адрес перехода будет вычислен, процессор осознает ошибку и отбросит результаты спекулятивного выполнения, однако, как и во всех прочих случаях применения Meltdown и Spectre, от него останутся следы в кэше.
А что делать со следами в кэше, вы уже знаете.
В целом, по описанию всей этой головоломной процедуры достаточно очевидно, что эксплуатировать Spectre сильно сложнее, чем Meltdown — но, с другой стороны, в той или иной степени ему подвержены если не все, то большинство существующих процессоров.
Кто подвержен?
Можно считать, что все процессоры новее, чем Pentium MMX, однако есть нюансы.
- Процессоры Intel подвержены все
- Новые ядра ARM подвержены все. Последними ядрами без спекулятивного выполнения кода были Cortex-A7 и Cortex-A53. Cortex-A7 в живой природе ещё встречаются во встраиваемых системах, от Raspberry Pi 3 до систем-на-модуле на iMX6UL и iMX6ULL, а вот на Cortex-A53 построены многие смартфоны среднего уровня — там он извествен как Snapdragon 625, Snapdragon 410, Mediatek MT6752 и т.п.
- Процессоры AMD, по заявлению компании, «практически не подвержены» атаке через гаджеты, официально называющейся Branch Target Injection или Indirect Branch Poisoning
- Про другие ядра информации нет, но, скорее всего, первому варианту Spectre (Bounds Check Bypass) подвержены все, а второй зависит от реализации в конкретной архитектуре предсказания переходов
Почему именно AMD «практически не подвержены» атаке через перенаправление косвенных переходов, компания не раскрывает. MMU здесь замешан быть не может, так как все запросы осуществляются строго в пределах адресного пространства атакуемой программы. Можно предположить, что у AMD другой механизм предсказания переходов, возможно, отслеживающий, скептически относящийся к идее переноса таких предсказаний между разными процессами. Что характерно, AMD не говорит о полной невозможности атаки, лишь о «почти нулевой вероятности».
При этом AMD точно так же, как Intel и ARM, подвержены первому типу атак Spectre, через обучение блока предсказания ветвлений.
Правда ли, что AMD подвержены атаке Spectre второго типа только на Linux и только при включённом BPF?
Нет.
На Linux с включённым BPF атака была показана в документе Google Project Zero, там же было отмечено, что её не удалось провести на процессоре AMD без BPF — однако, судя по всему, это было вызывано лишь тем, что исследователям не удалось найти в скомпилированном ядре последовательности команд, выбранной ими для атаки. На практике, во-первых, атаки могут проводиться не только против ядра системы, но и против любых исполняющихся в системе программ и используемых ими библиотек, а во-вторых, необходимые последовательности команд могут быть различными. Поэтому, хотя одна конкретная атака могла быть проведена в конкретном случае только через BPF, к общему вопросу уязвимости перед атаками типа Spectre это отношения не имеет.
Производители процессоров обещают простой и быстрый фикс
Во-первых, см. замечание в первой части про отношение к текущим заявлениям производителей.
Во-вторых, Spectre, в отличие от Meltdown, не является какой-то конкретной атакой — это лишь две наиболее очевидные из целого спектра (я в курсе, что «spectre» переводится не так, но уж больно просится) изощрённых атак, использующих возможность целенаправленного обучения процессорных блоков предсказания выполнения программы.
Что мы будем дальше делать, как мы будем дальше жить?
Пока не очень понятно.
Во-первых, вероятно, производители процессоров будут дополнительно тюнинговать их архитектуру с целью исключения или затруднения известных атак. Но результат мы увидим только через два-три года, а кроме того, имеющаяся вольность в алгоритмах процессоров обусловлена стремлением к увеличению их производительности — в обоих случаях со Spectre мы имеем дело с тем, что процессор учится быстрее выполнять один процесс на примере выполнения другого процесса, тем самым фактически позволяя второму процессу контролировать ход выполнения первого.
Глобально решило бы все проблемы более аккуратное обращение с кэшем, например, обнуление результатов спекулятивного выполнения в случае сброса конвейера или сохранение таких результатов в отдельный кэш с переносом их в основной только при успешном выполнении — но оба варианта также влекут за собой дополнительные накладные расходы.
В данный момент разрабатываются также патчи к компиляторам, обеспечивающие защиту от второй из атак Spectre — на данный момент уже представлены варианты для gcc и llvm, базирующиеся на предложениях Google.
Основываются они на довольно простой вещи: подмене косвенного перехода на возврат из функции. Возврат из функции работает немного иначе, чем косвенный переход, блок предсказания переходов на него не влияет. Фактически, это обман обманщика. Было бы двойным удовольствием, но, как обычно, есть нюансы.
Во-первых, исправление никак не влияет на Spectre первого типа.
Во-вторых, every magic comes with a price. Хотя Google в официльном сообщении аккуратно обходит стороной вопрос о количественном измерении оверхеда, на практике один «защищённый» косвенный переход в среднем утяжеляется в десять раз. Эффект для конкретного приложения зависит от его структуры, языка и компилятора — для ядра Linux он составляет в пределах 2 %, для других приложений может быть значительно больше.
В связи с этим на данный момент «официально считается», что для обеспечения «приемлемого» уровня защиты достаточно пересобрать ядро и единичные критичные приложения, а всё остальное и так вряд ли будут атаковать.
В-третьих, никакой общесистемной заплатки для Spectre на данный момент нет и не предвидится — ни от одного из вариантов. Минимальная защита от второго варианта требует полной перекомпиляции ядра системы и, вероятно, в большинстве ОС будет реализована не раньше выхода следующей мажорной версии. Защита от первого варианта пока что представлена исключительно в виде поиска и убирания из кода линуксового ядра последовательности, использованной в демонстрации Google Project Zero на интелах.
Производители процессоров начали потихоньку обновлять их микрокод, но эффективность и потери в производительности в результате этих обновлений пока что никто толком не оценил. Intel выпустил два обновления — IBRS, Indirect Branch Restricted Speculation, и IBPB, Indirect Branch Prediction Barriers; как нетрудно заметить по названию, оба относятся ко второму типу атаки Spectre.
TL:DR
Глобальная ошибка, присутствующая примерно во всех существующих процессорах. Была бы полной жопой, если бы не высокая сложность практической реализации, из-за которой хакеры на неё забьют.
AMD, похоже, наполовину безопаснее прочих, хотя и непонятно, почему.
TL:DR — разница с Meltdown
Meltdown использует ошибку в процессорах Intel и ARM, из-за которой при спекулятивном выполнении инструкций процессор игнорирует права доступа к памяти.
Spectre использует особенность работы алгоритмов предсказания ветвлений и переходов в современных процессорах, из-за которой один процесс может влиять на вероятность спекулятивного исполнения инструкций в другом процессе.
Часть третья: хорошо ли мы себя вели
Комментарии (129)
vassabi
05.01.2018 21:23AMD, похоже, наполовину безопаснее прочих, хотя и непонятно, почему.
вангую, что у них какая-нибудь случайно оказавшаяся ошибка с отбросом «не пригодившихся данных» (например — порча какого-нить бита), поэтому он не дает признака нахождения в кеше. И если раньше они грустили (типа «а могли бы работать на полтора процента быстрее»), то теперь радуются по этому поводу.
ximaera
05.01.2018 23:07У AMD предсказатель ветвлений совсем иначе сделан. AFAIK они строят его на перцептронах, в то время как Intel использует какую-то модификацию TAGE. Считается (были где-то измерения), что TAGE существенно быстрее, однако возможно при этом, что перцептрон сложнее натренировать.
Буду рад, если автор статьи меня поправит.ximaera
05.01.2018 23:10+3Вот это исследование: hal.inria.fr/hal-01100647/document. Поведение предсказателя ветвлений в Haswell больше всего похоже на ITTAGE. Использование перцептронов в продукции AMD заявлялось ранее самим производителем (они, правда, как-то более пафосно это называли).

olartamonov Автор
05.01.2018 23:49+2Здесь вопрос, скорее всего, не в верхнем уровне предсказателя, а в нижнем. Как минимум, предсказатель работает с упрощённой схемой адресации, а как максимум, его ещё и кормят только виртуальными адресами, не различая, от какого они процесса.

interprise
05.01.2018 21:30Меня смущает необходимость передавать параметр в атакуемый процесс. Это сильно усложняет такую хрупкую атаку. А так очень интересно написано.
olartamonov Автор
05.01.2018 21:30Там всё очень хрупко, что и позволяет, приняв рюмку коньяка, забить.
interprise
05.01.2018 21:37Как ни крути АМД получается в выигрыше. Первая атака намного опасней и ее решение съедает производительность. Описанная в этой статье какая-то через чур теоретическая. В живую бы эту атаку пощупать. Подождем, выкатят ли нам патчи.

rogoz
06.01.2018 00:45+1В живую бы эту атаку пощупать.
gist.github.com/ErikAugust/724d4a969fb2c6ae1bbd7b2a9e3d4bb6
olartamonov это оно?olartamonov Автор
06.01.2018 01:08+1Kind of. Ну то есть оно какого-то чужого кода не читает, но чтение через следы в кэше демонстрирует.
Оно же с комментарием: github.com/Eugnis/spectre-attack
interprise
05.01.2018 21:50хотя если есть возможность читать из расшаренной памяти, это может помочь. Верней это уберет пункт с необходимостью читать через атакуемый процесс, а можно будет читать в своем процессе. Правда это требует еще более конкретного кода для проведения атаки.

Arxitektor
05.01.2018 21:41Спасибо за 2 часть.
если бы не высокая сложность практической реализации,
Думаю для направленных атак банков, крупных компаний и прочее могут и сделать троян или еще что.
Главное чтобы на основании этих уязвимостей не нашли чего похлеще…
arheops
06.01.2018 01:59Там такая сложность, что это реально может только сильный ИИ, похоже, сделать. Вам же надо 100500 проходов и еще запуск приложения на каждый бит информации сделать.
zikasak
05.01.2018 21:42на всякий случай. Правильно понимаю, что и к заявлениям RedHat о том, что уже исправили Spectre (2 случая из трех) access.redhat.com/articles/3311301 стоит относится с настороженностью?


yleo
05.01.2018 22:06У кого горит CVE-2017-5715, aka #Spectre branch target injection.
Есть unstable microcode от Intel, можно пробовать лечиться и баловаться.
Changelog:
2018-01-04 — Henrique de Moraes Holschuh hmh@debian.org
intel-microcode (3.20171215.1) unstable; urgency=high
- Add supplementary-ucode-CVE-2017-5715.d/: (closes: #886367)
New upstream microcodes to partially address CVE-2017-5715 - Updated Microcodes:
sig 0x000306c3, pf_mask 0x32, 2017-11-20, rev 0x0023, size 23552
sig 0x000306d4, pf_mask 0xc0, 2017-11-17, rev 0x0028, size 18432
sig 0x000306f2, pf_mask 0x6f, 2017-11-17, rev 0x003b, size 33792
sig 0x00040651, pf_mask 0x72, 2017-11-20, rev 0x0021, size 22528
sig 0x000406e3, pf_mask 0xc0, 2017-11-16, rev 0x00c2, size 99328
sig 0x000406f1, pf_mask 0xef, 2017-11-18, rev 0xb000025, size 27648
sig 0x00050654, pf_mask 0xb7, 2017-11-21, rev 0x200003a, size 27648
sig 0x000506c9, pf_mask 0x03, 2017-11-22, rev 0x002e, size 16384
sig 0x000806e9, pf_mask 0xc0, 2017-12-03, rev 0x007c, size 98304
sig 0x000906e9, pf_mask 0x2a, 2017-12-03, rev 0x007c, size 98304 - Implements IBRS and IBPB support via new MSR (Spectre variant 2
mitigation, indirect branches). Support is exposed through cpuid(7).EDX. - LFENCE terminates all previous instructions (Spectre variant 2
mitigation, conditional branches).
https://debian.pkgs.org/sid/debian-nonfree-amd64/intel-microcode_3.20171215.1_amd64.deb.html
a5b
06.01.2018 02:59https://newsroom.intel.com/wp-content/uploads/sites/11/2018/01/Intel-Analysis-of-Speculative-Execution-Side-Channels.pdf
3.2 Branch Target Injection Mitigation
This mitigation strategy requires both updated system software as well as a microcode update to be loaded to support the new interface for many existing processors.
In particular, the capabilities are:
? Indirect Branch Restricted Speculation (IBRS): Restricts speculation of indirect branches.
? Single Thread Indirect Branch Predictors (STIBP): Prevents indirect branch predictions from
being controlled by the sibling Hyperthread.
? Indirect Branch Predictor Barrier (IBPB): Ensures that earlier code’s behavior does not control
later indirect branch predictions.(в статье не упоминали, что lfence требует каких-либо обновлений микрокода, называя метод "mitigation strategy is focused on software modifications.")
https://access.redhat.com/articles/3311301 — правки ядра (еще не принято в github.com/torvalds/linux), после которых появляются /sys/kernel/debug/x86/pti_enabled, /sys/kernel/debug/x86/ibpb_enabled, /sys/kernel/debug/x86/ibrs_enabledyleo
06.01.2018 16:12Упоминания о
LFENCEв Changelog не моего авторства, поэтому пока могу только предполагать.
Тем не менее, стоит обратить внимание, что
LFENCEв Changelog упоминается в контексте "Spectre variant #2". Тогда как в публикации Intel в контексте "Bounds Check Bypass Mitigation", т.е. "Spectre variant #1".
Поэтому напрашивается предположения:
- либо в Changelog очепятка (2 вместо 1) и на разных моделях было отличие в поведении
LFENCE, которое исправлено в этом микрокоде; - либо поведение
LFENCEвсё-таки имеет какой-то эффект на "Spectre variant #2", но в публикации Intel это упустили в спешке.
- либо в Changelog очепятка (2 вместо 1) и на разных моделях было отличие в поведении

Andy_U
08.01.2018 00:01А вот, кстати способ, как можно поменять микрокоды в Windows c помощью драйвера от VMware: How to update microcode from Windows..
P.S. А как микрокоды из deb-файла извлечь?olartamonov Автор
08.01.2018 00:11А как микрокоды из deb-файла извлечь?
DEB — это обычный tar-архив. 7-Zip тот же под виндой спокойно открывает.Andy_U
08.01.2018 00:15Спасибо, сам не догадался попробовать. Распаковал, но вот беда, утилита от VMware использует ASCI вариант, а тут только binary. Ищем/ждем дальше.
- Add supplementary-ucode-CVE-2017-5715.d/: (closes: #886367)
zx80
05.01.2018 22:15теперь без вариантов прийдется весной апгрейдиться на Ryzen 2000, intel давай досвидос

Skaurus
05.01.2018 22:38Переделать что-то в Ryzen 2000 без откладывания выпуска этак на год (полгода, если очень оптимистично) никто не успеет.
olartamonov Автор
05.01.2018 22:42Ну Meltdown он не подвержен, Spectre v2 вроде тоже (и точно без экспериментального микрокода и падения производительности), а Spectre v1 по-любому подвержены все.


Mairon
05.01.2018 22:43+1Я, конечно, понимаю, что это почти неактуально для рынка, но как дела с этими дырками у NV Denver? Судя по вайтпаперам об архитектуре ядра, он не подвержен Meltdown, а что со Spectre?
qbertych
05.01.2018 23:00Напомню, что ещё одним условием было отсутствие других участвующих в процессе переменных в кэше
Вот этот момент не совсем понятен. Речь о переменных, которые проверяются в условии if (как array_size), или о чем-то еще?
olartamonov Автор
05.01.2018 23:34Там и array1_size, и array2 должны быть вне кэша. Первый — чтобы спекулятивное выполнение запустилось, второй — чтобы потом можно было понять, какой индекс мы дёрнули.
willyd
06.01.2018 04:40мне кажется, что в этом и есть секрет амд… что они предиктивно подтягивают в кеш весь массив.
ну так, диванная теория, основанная на комментариях к toy example с gist'a
ps скорее всего — это глупостьwillyd
06.01.2018 05:02Я немного распишу, чтобы совсем не заминусовали. И мне интересно, возможно ли такое с точки зрения, тех, кто разбирается в работе процессоров.
Это такой себе side-channel инжениринг.
У AMD уже давно кеши больше чем Intel, при этом в производительности на ватт они проигрывают, это показывает серверный сегмент, где считается каждая копейка. Первым делом напрашивается ответ, что это из-за маркетинга «игра в бизнес сегменте проиграна, а пользователям — главное цифры в даташите». Но производство процессоров — вещь недешевая, и если уже, даже ради маркетинга, в процессоре добавлен лишний кеш, — его грех не задействовать. Массив — это указатель на указатели, и в принципе, вытягивание значения из кеша, это операция, которую тоже можно распараллелить, И коль у нас много кеша, то мы можем без потери ресурсов грузить избыточную информацию в кеш, не обязательно первого уровня. Предсказатель встречая выгрузку из массива может жестко загружать весь массив в кеш верхнего уровня, с доставкой нужного значения в кеш первого уровня — это может съекономить такты в будущем, поскольку работа с массивами в большинстве случаев производится в цикле с одним массивом, а лишнего кеша у нас дофига.
Ну и еще пару моментов есть, которые меня подталкивают к этой теории, но как я уже объяснил, все это на грани интуиции и информации из тестов toy example.
Для проверки, я бы попробовал все ри уязвимости, но с более структурами данных чем массивы, мне знаний C и ассемблера на хватит, а более высокоуровневые языки могут все поломать.aamonster
06.01.2018 11:15Довод против: CPU не знает размер массива.
Deosis
06.01.2018 11:42Не обязательно грузить весь массив, достаточно заполнять 16 линий и атакующий сможет узнать из байта только ниббл.
aamonster
06.01.2018 12:41+1- Фактически вы просто предлагаете увеличить линию кэша в 16 раз.
1.1. Чего это будет стОить? (Увеличится требуемый объём кэша — точно проц станет допоже; увеличится поток данных из DRAM — возможно, проц станет медленней). - Увеличиваем в 16 раз размер элемента массива — и по прежнему узнаём весь байт.
- Допустим, мы можем за раз узнать только нибл. Вот проблема-то — атака замедлилась в два раза.
Но вот если добавить поддержку в компилятор (дать CPU hint — размер массива) — загрузка в кэш всего массива может оказаться выгодной...
- Фактически вы просто предлагаете увеличить линию кэша в 16 раз.
livemotion
05.01.2018 23:33+1я вот понимаю, что эти уязвимости моим серверам ну никак не навредят. Но как простыми словами объяснить это директору, который из всех новостных каналов слышит «жопа», «всё пропало»?

gnomeby
05.01.2018 23:44+1Если он очень хочет потратить денег, то можно воспользоваться как поводом для апгрейда.
ximaera
05.01.2018 23:46+1… на что? На Эльбрус?
В статье подробно описано: неуязвимых моделей Intel не будет ещё год или два, а с Intel на AMD это (во всех смыслах, кроме безопасности) так себе апгрейд.

agat000
06.01.2018 09:11Гасите его переживания умными словами типа «информационная безопасность» и «IT-шники лучше знают». Ну и похвалите, что он такой умный, взял на работу нормальных специалистов.

shurshur
06.01.2018 18:10+1Строго говоря, для эксплуатации уязвимости на целевой системе нужно что-то запустить. Яваскрипт в браузере или php на сайт подсунуть — не столь важно — но всё же подсунуть надо. Так что если сценарий открытого подсовывания кода невозможен (например, компания не предоставляет хостинговые услуги), то и риски непонятно откуда возьмутся. Разве что найдутся какие-то другие уязвимости, позволяющие запускать код — но с такими уязвимостями и без процессорных багов можно огрести спам-бота или майнера.

phantom-code
06.01.2018 00:02-1AMD вроде говорили, что у них какой-то особенный branch predictor, основанный на нейросетях. Возможно в этом и кроется причина их неуязвимости к некоторым типам атак.
olartamonov Автор
06.01.2018 00:24Нет, скорее эти предсказатели просто кормят разными данными. Если интел в него передаёт виртуальные адреса, не заморачиваясь с их преобразованием в реальные, то предсказатель и не будет два разных процесса друг от друга отличать, нейросети там или нет.
closegl
06.01.2018 00:56а разве в строке таблиц TLB не указывается адрес инструкции где находится «if()» про который строится предсказание? тогда повлиять на соседний процесс было бы сложнее…
olartamonov Автор
06.01.2018 00:57+1Видимо, не TLB, а предсказателя? TLB тут особо ни при чём.
Указывается. Вопрос только в том, какой это адрес. Как минимум, от него для упрощения жизни могут остаться только сколько-то младших бит, как максимум — он вообще может быть виртуальным, а не физическим.
janatem
06.01.2018 02:09+1Не смог распарсить вот этот кусочек:
Как мы помним, Meltdown не работает на процессорах, вовремя — до окончания выполнения — проверяющих условия доступа процесса к чужой памяти даже в случае спекулятивного выполнения.
Там где-то опечатка или ошибка в тексте, но не соображу, где именно.Temtaime
06.01.2018 02:44+1Нет там ошибки.
Если процессор в режиме спекулятивного выполнения сразу проверяет флаги доступа к страницам памяти, то он не подвержен meltdown.

lonelymyp
06.01.2018 03:01+2Свежеиспечённые апдэйты kb4056894 KB4056898 и KB4056897(которые вроде как должны фиксить ситуацию) на многих процессорах AMD вызывают синий экран скоро после перезагрузки или сразу.
www.reddit.com/r/windows/comments/7oap39/patch_windows_7_kb4056894
answers.microsoft.com/en-us/windows/forum/windows_7-update/stop-0x000000c4-after-installing-kb4056894-2018-01/f09a8be3-5313-40bb-9cef-727fcdd4cd56?auth=1
Видимо чтобы подгорало не только у обладателей процессоров intel.
KruFFT
06.01.2018 14:57+1Именно так. Вчера принесли ноутбук, довольно старый, на AMD Turion 64 X2 TL-56. При попытке загрузки, Windows 7 падает в синий экран, который не содержит почти никакой дополнительной информации:
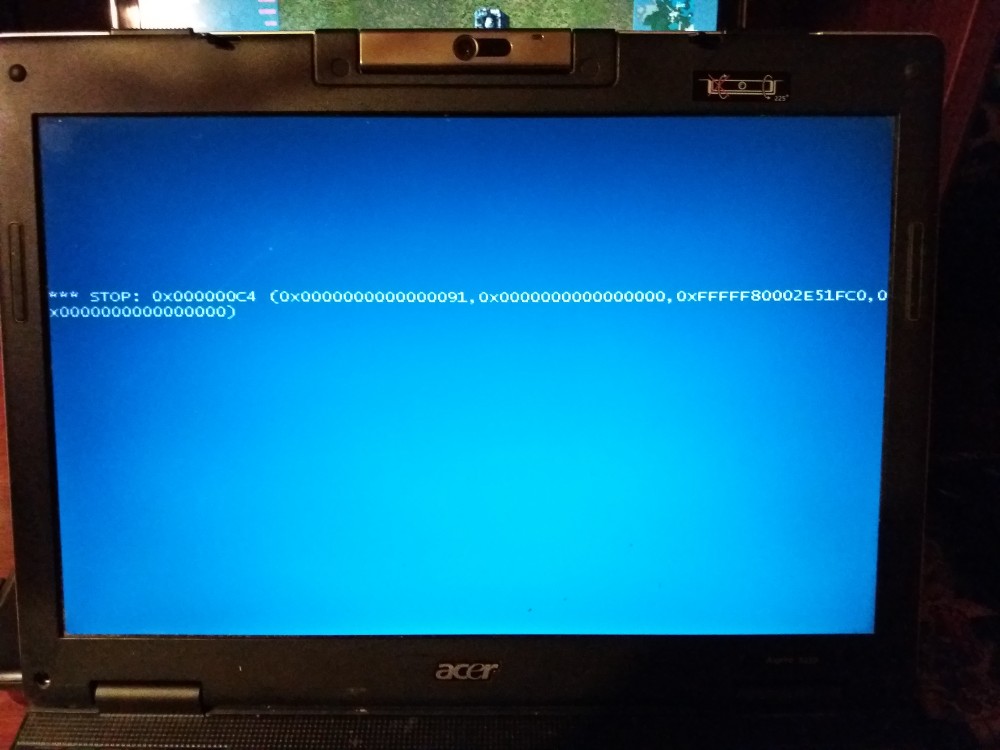
Автоматически система не смогла восстановить свою загрузку. Вручную удалось откатить на точку восстановления, которая создалась перед установкой обновления. Потом запретил установку обновления KB4056894.

firk
06.01.2018 03:08Важным моментом в атаке, кстати, является пункт «медленно и печально» — если array1_size лежит готовый где-то в кэше, процессор может не заморачиваться со спекулятивным вычислением, а просто быстро посчитать условие. Поэтому array1_size должен быть в ОЗУ, откуда его придётся долго доставать.
Только что проверял у себя на AMD. Видел инвалидацию кеша в примере из статьи — не понимал зачем она там нужна. Сам запускал не пример, а свою реализацию, там размер массива был вообще не в переменной а захардкожен. Аналог переменной x гарантировано был в кеше т.к. её только недавно записали. Всё работало.
На другом проце (тоже AMD) — не работало. Сейчас прочёл эту статью, дописал переменную с размером массива и её инвалидацию — заработало. Так что это не жёсткое требование, где-то работает, где-то нет.
Что особенно цинично, базовую возможность проведения атаки нам обеспечила проверка индекса массива, необходимая для обеспечения безопасности кода.
Нет, если бы там не было этой проверки, то её не пришлось бы взламывать, а программа бы неспекулятивно сделала тоже самое что тут получается только спекулятивно.

delvin-fil
06.01.2018 07:56На Linux с включённым BPF
Про FreeBSD тоже было.
А как насчет других BSD?shurshur
06.01.2018 17:36+2Проблема не в BPF как таковом, просто именно на BPF продемонстрирована успешная атака.
Cobolorum
06.01.2018 10:42-1Для понимания почему на AMD «все так плохо» надо читать спеки NUMA, MOESI, MOESI.

unwrecker
06.01.2018 12:09Печально когда только что закупился пачкой Xeon Scalable :(
ЗЫ. Ну хоть майнить на них вариант остаётся :)
PashaPash
06.01.2018 13:39«Еденичные уязвимые приложения» и прочите «гаджеты» — это, прежде всего, браузеры. Spectre позволяет читать память браузера из Javascript. Авторы атаки предоставили POC для Chrome. И именно из-за этого вся движуха со срочными фиксами для браузеров, включением Site Isolation и отключением SharedArrayBuffer — для использования атаки достаточно просто заманить пользователя на сайт. Т.е. это не какая-то теоретическая атака, в которой
всё очень хрупко, что и позволяет, приняв рюмку коньяка, забить.
… а вполне конкретная дырка, как минимум в Chrome.olartamonov Автор
06.01.2018 13:51+1Эта дырка существует в любой программе, где присутствует выполнение произвольного пользовательского кода в «песочнице», обеспечивающей изоляцию кода от внешнего мира одновременно с выполнением его с правами доступа родительской программы, но не контролирующей возможность создания при компиляции кода последовательностей команд, пригодных для атаки.
Говоря русским языком, позволяет все нужные нам структуры создать своими руками и при этом сразу внутри атакуемого процесса.
Другое дело, что таких мало, я в пользовательском окружении сходу кроме браузера с JS ничего и не назову. В серверном — вон, ядро линукса или BSD с BPF. То есть в общем величина дырки имеет более-менее разумный размер, позволяющий её закрыть.willyd
06.01.2018 14:20Другое дело, что таких мало, я в пользовательском окружении сходу кроме браузера с JS ничего и не назову.
А приложение на смартфоне с уязвимым arm может заглянуть дальше песочницы?olartamonov Автор
06.01.2018 14:42Надо специалистов по потрохам Dalvik и ART спрашивать, как там изоляция приложений реализована.
В ART (Android 5.0 и новее) — почти наверняка не может, там приложение при установке компилируется в нативный код, а не в байткод для выполнения в виртуалке, соответственно, методы изоляции должны быть такие же, как для обычного приложения. А через них Spectre ходить не умеет, если заранее не найдёт снаружи готовый подходящий код, на выполнение которого сможет повлиять.willyd
06.01.2018 15:05То есть, нужна функция процесса, который работает, с привилегиями выше песочницы, при это произведет чтение нужных данных и еще и положит в доступную нам из песочницы память?
olartamonov Автор
06.01.2018 15:49Не обязательно выше, но если мы хотим атаковать не сами себя, а сторонний процесс, то нам нужна определённая последовательность команд, находящаяся либо непосредственно в атакуемом процессе, либо в процессе, который имеет свободный доступ к атакуемому (в ядре, например).
artskep
06.01.2018 18:34Насколько я помню, во всех андроидах (что до ART, что после) каждое приложение это отдельный пользователь. Т.е. каждое приложение запускается под своим «пользователем», что и обеспечивает песочницу.
Но тут может быть интересный вопрос по поводу того какая часть ядра и/или критичных андроидных сервисов действительно находится за пределами маппинга памяти, а какая просто защищена доступом (а значит потенциально уязвима для Meltdown). Потому что все процессы являются форками «зиготы», которая много фреймворков содержит. Это неплохо для производительности, но сколько интересного в действительности попадает в адресное пространство процесса… Тут сложно сказатьolartamonov Автор
06.01.2018 18:49Т.е. каждое приложение запускается под своим «пользователем», что и обеспечивает песочницу
Нет, если у нас есть какая-то виртуальная машина, в которой крутится нескомпилированный код, то этот код будет работать в адресном пространстве и с привилегиями виртуальной машины, как JS в браузерах или BPF в ядрах, а значит, может использовать Spectre напрямую. От того, чтобы он куда не положено не лазил, его сама VM и ограничивает. И «пользователи» — это высокоуровневая сущность VM, к разделению на уровне процессов она не имеет отношения; с точки зрения CPU тут процесс один — сама VM.
А вот ART один раз собирает готовый нативный бинарник, который уже можно выплюнуть в отдельный самостоятельный процесс.
а значит потенциально уязвима для Meltdown
Meltdown на ARM есть только на самых свежих ядрах.
Основная масса неподдерживаемого барахла на рынке — либо на ядрах, умеющих только Spectre, либо не умеющих вообще ничего.artskep
06.01.2018 19:40Нет, если у нас есть какая-то виртуальная машина, в которой крутится нескомпилированный код, то этот код будет работать в адресном пространстве и с привилегиями виртуальной машины, как JS в браузерах ...
Я как раз говорю о том, что каждое приложение в Андроиде (даже до ART) это отдельный процесс под отдельным пользователем (UID связан с приложением) с точки зрения Линукса, который его крутит. Именно так гарантируется песочница (в другой каталог файл не запишешь/не прочитаешь, потому что у процесса, который твою VM крутит нет правов кроме как на запись в свои каталоги, ядро ограничивает ресурсы «на пользователя» и прочее).
Естественно, если не рутить телефон, но это отдельная тема.
Но в каждой этой копии VM есть куча шареной памяти от изначальной зиготы (которая содержит кучу фреймворков). И в каждом телефоне ХЗ чего интересного в этой памяти можно найти, если суметь до нее добраться.
И тут уже интереснее можно ли использовать Spectre и/или Meltdown.
Хотя, очевидно, это все пока что из области ковыряния в носу — реальный хак на этом сделать навряд ли выйдет в обозримое будущее…olartamonov Автор
06.01.2018 20:03+1Нет, если там целиком форкается VM, и в этом форке крутится ровно одно приложение, со Spectre никаким простым способом оно ничего не добьётся.
Расшаренная память (библиотеки, сам форк и т.п.) никак не поможет, на Spectre нельзя через общую библиотеку перебраться из одного процесса в другой. Любое изменение в этой памяти со стороны процесса вызовет copy-on-write и будет видно только самому процессу.
Meltdown при этом будет работать совершенно спокойно, но Meltdown подвержены только три ядра — A15, A57, A72. На этих ядрах массовость имели самсунговские Galaxy Note и Galaxy S (Exynos), потом MTK Helio X20, потом Snapdragon 650/652/653.
Самсунг с большой вероятностью выпустит патчи, если ещё нет. На Снапдрагоне смартфонов не так много, на MTK на глазок побольше, но это всё уже тонет в массе бюджетных моделей, которые выгоднее делать на сборках дешёвых ядер, без всякого этого вашего big.LITTLE. Так что, если Самсунг из списка вычеркнуть, для атакующих становится уже не особо интересно.
olartamonov Автор
06.01.2018 20:48Впрочем, я посмотрел ARM'овскую white paper — зря они ошибку в своих ядрах отнесли к Meltdown, надо было ей отдельный номер давать.
Причина там та же, но их «Variant 3a» позволяет читать не память, а лишь отдельные системные регистры, de jure недоступные непривилегированному процессу.
Тоже неприятно, но не смертельно.
PashaPash
06.01.2018 18:36+1Вы немного не правильно восприняли мой комментарий. Я знаю как работает Spectre и знаю ограничения на его применимость. Я скорее о том, что «забить» не получится — всем придется как минимум пообновлять браузеры. Т.е. почти у всех сейчас установлен дырявый хром, в котором эта уязвимость есть в эксплуатируемом виде. А фикс, по планам, выйдет 23-го января. Вопрос не в величине дырки, вопрос в распространенности. Т.е. да, куча народу прочитала статью. Сколько из них пошло и отключило у себя SharedArrayBuffer?
olartamonov Автор
06.01.2018 18:44+1Т.е. да, куча народу прочитала статью. Сколько из них пошло и отключило у себя SharedArrayBuffer?
Примерно ни один.
Но это локальная проблема, она будет устранена до конца января — как раз с обновлением браузеров проблем никаких нет, они это сами делают.PashaPash
06.01.2018 18:57+1Все, кроме IE. И кроме энтерпрайзных LTSB, где обновлениями заправляет админ. И кроме тех, кто сидит на хроме под Vista / XP. И кроме браузеров, вшитых в необновляемые бюджетные андроиды.
Да и лично мне от ощущения, что у меня в браузере есть дырка, которая будет там еще пару недель, как-то не по себе.firk
07.01.2018 18:34У меня для вас плохие новости: в вашем браузере (если это конечно не lynx или что-то подобное) этих дырок десятки, и будут они там не несколько недель, а годы. Хуже того, они будут и новые добавляться с новыми версиями.
PashaPash
08.01.2018 03:42Под "этих дырок" вы подразумеваете "легко эксплуатируемых дырок известных широкой общественности и разработчикам браузера, которые не торопятся чинить"? — выше же именно это обсуждается. А не просто наличие "каких то дырок". Известных дыр точно десятки? Назовите хотя бы три.
PashaPash
06.01.2018 18:50+1В качестве подтверджения, что размер дырки не имеет никакого отношения к вероятности быстрого ее закрытия — bugs.chromium.org/p/chromium/issues/detail?id=508166
Security: Chrome provides high-res timers which allow cache side channel attacks
Reported by mseaborn@chromium.org, Jul 8 2015
и там же
Jul 15 2015, I have a PoC of the «Spy in the Sandbox» attack that works based on Shared Array Buffers instead of via high-resolution timing.
Конкретную проблему в конретном Chrome зарепортили два года назад. Но PoC на то время позволял всего лишь следить за движениями мышки вне браузера и обнаруживать сетевую активность. Сейчас появился PoC который позволяет через нее читать память процесса, и только после этого производители бразуеров зашевелились и выпустили «патч». Точнее, выпустят через две недели. В виде отключения Shared Array Buffers. В остальных приложениях никто ничего проверять и закрывать не собирается.
jazbit
06.01.2018 16:13Кстати про предсказание. На Stackoverflow САМЫЙ популярный вопрос за всю историю сайта как раз про это (про предсказание ветвлений). Довольно интересно почитать, рекомендую.
stackoverflow.com/questions/11227809/why-is-it-faster-to-process-a-sorted-array-than-an-unsorted-arraykryvichh
07.01.2018 20:27Интересно, придумали ли уже процессоростроители какую-нибудь команду, чтобы программно пометить предпочтительную ветку исполнения? Чтобы процессор не использовал разные методы предсказания, а точно знал, что если это цикл — то скорее всего исполнение пойдёт на второй круг. а не на выход.

pesh1983
06.01.2018 16:32Я не совсем понял, проясните пожалуйста. В статье написано, что при замере времени доступа к каждому элементу массива можно понять, получен ли элемент из кэша, либо вытянут из RAM. Узнать, это одно, а получить данные из кэша от другого процесса — не одно и то же. Правильно ли я понимаю, что при доступе к элементу массива в атакующем процессе он будет в итоге содержать данные из кэша от другого процесса?
olartamonov Автор
06.01.2018 16:46+1Данные из кэша напрямую получить нельзя в принципе.
Однако можно понять, закэшировано ли значение, хранящееся в памяти по определённому адресу, или нет.
Поэтому изобретаются всякие косвенные методы передачи нужного значения через кэш, наиболее понятный из которых — проведение атаки так, чтобы интересующее нас значение в момент атаки подставилось в индекс какого-либо массива, который мы можем дальше перебрать легальным образом. При этом нас даже не волнует, в каком виде мы получим собственно значения этого массива, нам достаточно, что на нужном индексе мы увидим более быстрый возврат из него (он закэширован в ходе атаки), а этот индекс и есть искомая величина.
Meltdown работает именно так. В Spectre есть сложности, связанные с тем, что всю эту схему надо организовать внутри атакуемого процесса, поэтому там могут и более сложные схемы косвенного анализа кэша применяться.
tot418
06.01.2018 16:37Надеюсь что с новогодними подарками, будет как с продолжением Half — Life (третьей части не будет).
leggiermente
06.01.2018 18:36-1Совсем не разбираюсь в процессорных архитектурах (так что ниже может быть написана глупость), но сразу по прочтении появилась следующая идея: подмешивать (путём сдвига адресации) в каждом цикле записи в кэш величину, связанную с идентификатором соответствующей операции MMU. При соответствующем извлечении данных из кэша, выполнять обратную операцию. Таким образом, значения в кэше, соответствующие одному процессу, будут распределены с большей энтропией. Мне кажется, здесь будет минимальная потеря операций за такт. Среди минусов — уменьшение эффективного размера кэша.
Я не знаю, реализуемо ли это путём нового микрокода, или необходимы аппаратные модификации.olartamonov Автор
06.01.2018 18:55+3Энтропия тут вообще ни при чём. Кэш не знает, от имени какого процесса в него свалились данные, и при этом и сейчас раскидывает их по своему объёму непоследовательно — у него есть алгоритмы, определяющие, какие старые данные уже можно перезаписать новыми, а какие лучше пока придержать. Так что новые данные будут каким-то странным образом по кэшу раскиданы по определению, и этот образ может зависеть от совокупной активности всех работающих в системе процессов, т.е. снаружи он труднопредсказуем.
Если сделать так, что закэшированные одним процессом данные не смогут быть доступны другому (ввести в кэш аналог PCID), то это очень сильно ударит по производительности.
kryvichh
07.01.2018 20:33Надо просто вовремя проверять права доступа на запрошенный участок памяти, как это делает AMD. То есть изменить архитектуру процессора таким образом, чтобы эта проверка была не дороже получения самого запрошенного значения из памяти.
McAaron
06.01.2018 23:32Не видно причин, препятствующих безусловному сбросу кеша при переключении процессов. Даже если это происходит аппаратно, например, при входе/возвращении из системного вызова или прерывания, можно устроить так, что в этот момент будет генерироваться исключение, обработчик которого сбросит кеш. Собственно, на производительность это никак не повлияет, поскольку переключение между режимами происходят не слишком часто, а время преключения настолько мало, что даже если его и увеличить в десять раз, то системное время не вырастет даже на сотую процента. В таких приложениях, где тысячи процессов постоянно дергают ввод/вывод, можно все порешать поместив все, что выше аппаратного драйвера, которому действительно требуется режим ядра, в пространство пользователя статической линковкой с библиотеками ввода вывода.
olartamonov Автор
06.01.2018 23:50Собственно, на производительность это никак не повлияет, поскольку переключение между режимами происходят не слишком часто
Да, примерно каждые две-три миллисекунды на средне нагруженной системе.
На сколько у вас там предполагается обрушить производительность обнулением кэша каждые 2 мс, процентов на сорок?
Hardcoin
07.01.2018 00:38можно все порешать поместив все
В смысле, исправить приложение? Каждое? Классное решение, ага.
kryvichh
07.01.2018 20:39Если говорить о будущих процессорах, надо дорабатывать логику работы кэша, а не ухудшать его характеристики (внедряя рандомные задержки, внезапные сбросы и т.п.).

kuraga333
06.01.2018 23:38Я не совсем понимаю отличие Meltdown и Spectre… То есть, я не понимаю, почему одна из них не является уязвимостью, а вторая (и всё производное) — лишь способом эксплуатации…
Если коротко, то — начнем с этого — само по себе оседание значения в кеше и неочистка его после «отката» — само по себе это не уязвимость?..olartamonov Автор
06.01.2018 23:39+1Само по себе это незначительная уязвимость.
А вот возможность целенаправленно осадить в кэше значение из закрытой для данного процесса памяти — значительная. Не должно быть у процесса доступа к чужой памяти, ни в каком виде, ни в явном, ни в неявном.kuraga333
07.01.2018 11:43Спасибо!
Просто есть ощущение, что Meltdown — это «Spectre, который проявляется не только в данном процессе, но и в памяти ядра». Я не прав?
Ну правда, у меня ощущение, что есть «основная уязвимость», которая позволяет проанализировать память. Происходит это благодаря механизмам: спекулятивного выполнения, косвенной адресации и измерения таймингов. Для атаки необходимо вынудить нужный процесс сделать нужные действия. Это «как бы Spectre».
А есть вторая уязвимость («как бы Meltdown»), которая позволяет применить этот процесс прямо, из атакующего процесса, т.к. вторая уязвимость — это первая, но косвенная адресация может произойти и в память другого процесса.
Где я не прав? Это не копательство в терминологии, я пытаюсь понять, где я не прав. Спасибо!olartamonov Автор
07.01.2018 12:14Нет, механика у Meltdown и Spectre совершенно разная.
Meltdown достаточно легко устраняется в железе, как устранить первый вариант Spectre, не обрушая производительность процессора, вообще не очень понятно.kuraga333
07.01.2018 12:45Так я наоборот говорю, что Meltdown — «дополнение» к Spectre.
Ну если бы все, что обнаружилось в Spectre, было бы строго неверно (т.е. НЕ работало), то Meltdown был бы возможен?olartamonov Автор
07.01.2018 12:57Да, был бы. Meltdown можно реализовать без тренировки предсказателя ветвлений, чисто на одном только спекулятивном выполнении. Атакуемый процесс никаких вообще действий при эксплуатации Meltdown не выполняет.
Единственное критичное для него условие, помимо наличия спекулятивного выполнения — это запоздалая генерация процессором исключения, в результате чего при спекулятивном выполении не ограничиваются права доступа к памяти.
Прочие меры относятся к «а давайте уберём из процессора кэш» или «а давайте выключим спекулятивное выполнение», это из того же разряда, что и «а давайте лечить головную боль гильотиной».kuraga333
07.01.2018 13:10Прочие меры относятся к «а давайте уберём из процессора кэш» или «а давайте выключим спекулятивное выполнение», это из того же разряда, что и «а давайте лечить головную боль гильотиной».
Да, именно такое ощущение у меня и сложилось. Что основное даже не в спекулятивном выполнении, а в связке
- оседание в кеше (не важно, из-за чего),
- косвенная адресация (!),
- возможность (прямого или косвенного) измерения таймингов косвенной адресации
Но, видимо, этих трех вещей недостаточно, и тут я, наверное, и не понимаю…olartamonov Автор
07.01.2018 14:44Не пытайтесь найти общую причину Meltdown и двух версий Spectre, её нет, это три разные уязвимости. Оседание в кэше — не причина, а следствие их.
1) Meltdown: проверка прав доступа после выполнения спекулятивной инструкции. Достаточно легко устраняется в железе процессора.
2) Spectre №1: тренировка предсказателя ветвлений, позволяющая одному процессу влиять на другой. Устранить без потери эффективности очень сложно.
3) Spectre №2: тренировка предсказателя переходов, позволяющая одному процессу влиять на другой. Устранить с несущественной потерей эффективности можно.firk
07.01.2018 19:37Не верно. Общая причина есть — отпечатки в кеше от спекулятивного исполнения. kuraga333 всё верно пишет — суть тут одна и та же, просто разные методы эксплуатации. В том, что называется spectre, спекулятивное исполнение происходит в нереализуемой ветке if, а в том, что называется meltdown — в нереализуемой ветке «после исключения» (по сути тоже if, но не в коде программы, а в микрокоде/схеме проца, который проверяет права доступа). Первое обходит проверку уровня приложения, второе — проверку уровня архитектуры проца. Сам по себе «обход проверок» (и тренировка предсказателя ветвлений — тоже) — не уязвимость, а суть спекулятивного исполнения. Уязвимость в том что от этого исполнения остаются следы.
olartamonov Автор
07.01.2018 20:39А причина головной боли — наличие головы.
Вы не можете отключить спекулятивное выполнение от кэша, оно в этом случае просто потеряет смысл. Разве что сделать для него свой кэш, который будет синхронизироваться с основным.kuraga333
07.01.2018 21:04Я, кажется, понял. Я почему-то думал, что получить осажденным в кеше значение по нужному адресу в предсказуемый момент времени (и на достаточно долго) — легко. Вот если бы это было бы так, то, судя по всему, в сочетании с косвенной адресацией и таймингами, нам бы больше ничего и не нужно было.
НоОседание в кэше — не причина, а следствие их [уязвимостей].
, и без Spectre/Meltdown вышеуказанное не легко/невозможно.
firk
08.01.2018 13:21А причина головной боли — наличие головы.
Не надо ложных аналогий.
Вы не можете отключить спекулятивное выполнение от кэша, оно в этом случае просто потеряет смысл.
И? это как-то опровергает то что я написал выше? Да, нельзя отключить, а это значит что базовая суть уязвимости принципиально неисправима в данной архитектуре. Можно только затыкать её частные дыро-проявления.
Разве что сделать для него свой кэш, который будет синхронизироваться с основным.
Интересная идея, но не поможет. Во-первых, у меня есть подозрение что заметная часть кеша заполняется именно спекулятивными операциями (и без этого эффективность кеша резко упадёт), а, во-вторых, читать задержки можно тоже спекулятивно, хоть и чуть сложнее, таким образом получив доступ и к спекулятивному кешу.

anshdo
09.01.2018 09:19А насколько сложно было бы просто чистить кэш от следов "несыгравшего" спекулятивного выполнения?
olartamonov Автор
09.01.2018 09:19Несложно, но бессмысленно. Не поможет от данного типа аттак после минимального изменения их логики.
apro
07.01.2018 00:36>если array2 имеет достаточно валидных индексов (не менее k штук), а мы можем снаружи >более-менее прямым способом побудить атакуемую программу его почитать, то на индексе >k операция чтения выполнится быстрее, чем на других индексах, так как он уже закэширован.
Вот это непонятно, ну да в другой программе что-то закэшировано и будет выполняется быстрее.
А как мы измерим время работы другой программы с точностью необходимой для отличия незакэшированных данных от кэешированный?olartamonov Автор
07.01.2018 01:00Нам нужен любой способ более-менее прямого доступа к интересующему нас массиву, без излишней обёртки с непрогнозируемым временем выполнения (т.е. если там ещё по пути будет сотня-другая инструкций, из которых ни одна не лезет в память — это плохо, но не смертельно).
apro
07.01.2018 03:32То есть нам нужен способ вызывать функции другой «программы» почти напрямую, кроме syscall'ов кто-нибудь подпадает под требуемые критерии?
Ведь явно даже программа предоставляющая COM/dbus интерфейс не подходит так как там «оверхед» в виде инструкций работающих с памятью там присутсвует.olartamonov Автор
07.01.2018 11:15Сходу подходит любая программа, исполняющая чужой код в песочнице, не выделяя его в отдельный процесс — тогда мы просто сами сформируем код, который сделает что надо уже в её адресном пространстве. JS в браузерах и BPF в ядрах как пример.
В остальных случаях могут подойти более изощрённые способы атаки, их есть ещё несколько, помимо попыток найти читающийся напрямую массив.
ololowl
07.01.2018 11:12А как узнать что на индексе >k операция чтения выполнится быстрее? Эту же операцию проделывает атакуемая программа. Как мы из вне увидим какой элемент читается быстрее?
olartamonov Автор
07.01.2018 11:15Если в программе есть доступная снаружи функция, про которую мы знаем, что она более-менее напрямую запрашивает значения из искомого массива и отдаёт их нам с минимальной, предсказуемой по времени обработкой, то мы просто её запросим.
Supercoban
07.01.2018 20:39Спасибо большое за подробное объяснение. Как заставиить атакуемое приложение положить нужные данные в кэш — совсем все понятно. Но хуже всего у атакующего, как я понял с чтением из кэша. Все сводится к угадыванию значения, причем маркером того что угадал правильно является время отклика. Поправьте меня пожалуйста если я не прав.
Собственно вопроса 2:
- каким образом злоумышленник анализирует время с нужной точностью и не влияя на исследуемый процесс.
- Как убедиться что в кэше есть только нужное значение и ничего больше (про очищение кэша понятно, но ведь в это время в него пишут сотни запущенных и продолжающих работать процессов, + само атакуемое приложение может писать много чего)
olartamonov Автор
07.01.2018 20:421. У x86 попросту есть доступный из кода таймер, считающий такты процессора, доступный по единственной ассемблерной команде. Точнее и быстрее измерять время особо уже некуда.
2. Маловероятно, что кто-то будет случайно в то же время — а оно очень небольшое, это доли микросекунды — читать тот же или близкий участок памяти. На практике error rate получается 0,02-0,03 % на сканировании десятков мегабайт памяти на живой системе.
GerrAlt
07.01.2018 20:53Если я правильно понял то если, к примеру, я буду сам собирать программы из исходников, и мой компилятор будет немного необычен (возможно будет добавлять немного «магии» к конкретным используемым адресам памяти) то вся эти история с Meltdown, Spectre и т.д. для меня будет выглядеть давольно прохладно (код с конкретными адресами есть только у меня, а без конкретных адресов атака неосуществима).
Т.е. open-source получает преимущество)olartamonov Автор
07.01.2018 21:03Meltdown'у ваши программы вообще не нужны для работы. Адрес процесса он достанет из ядра, адрес паролей внутри процесса — уж найдёт как-нибудь.
GerrAlt
07.01.2018 21:13А в ядро он как залезет?
Я не очень хорошо понимаю как выделяется память под ядро, там какие-то предопределенные адреса? А если я сам своим компилятором ядро собрал?olartamonov Автор
07.01.2018 21:29Да чем бы ни собирали, у вас есть системные вызовы функций из ядра, программа как-то по ним попасть должна — значит, адреса знает.
GerrAlt
07.01.2018 21:37т.е. преимущество у open-source, собранного самостоятельно из исходников «персонофицированным» компилятором и работающем на AMD (или еще чем-то не подверженном Meltdown)
blackswanny
08.01.2018 21:00-1Судя по описанию уязвимости все тесты синтетические. Для каждого отдельного атакуемого куска кода нужно писать отдельную реализацию. И реализация может занять много времени, так как чтобы довести вероятность перехвата до 100%, нужно тестировать на конкретном процессоре и конкретном ПО. Т.е. на другом процессоре все может пойти не так, верно?
В общем эта атака видиться на вполне конкретные важные цели, а не на обычного массового пользователя и ее нельзя использовать в ботнетах.
NickViz
09.01.2018 12:42правильно ли я понимаю, что предиктор переходов для каждого ядра свой? и атакующий процесс должен работать на том же ядре, что и атакуемый?
d-stream
olartamonov Автор
А это вообще не по сложности зловреда определяется в первую очередь, а по тому, центрифуги какой страны он сломал, ггг.
d-stream
Журналистами??
hokum13
Это определяется журналисты какой страны определяют что центрифуги взломали, а не забыли смазать…
Ну и как бы практика показывает, что всегда может появиться какой-нибудь Перельман, который из вредности проработает «сложную в практической реализации» задачу, просто «потому что может».