Еще в начале ноября 2017 года компания Qualcomm Datacenter Technologies (QDT) завершила работу над своим новым детищем — процессором на базе 10-нм технологии — Centriq 2400. Какое будущее ждет индустрию по мнению создателей сего новшества? Какие преимущества получать серверы и чем так уникален Centriq 2400? Об этом и не только читайте далее.
8 ноября в Сан-Хосе (Калифорния) прошла пресс-конференция компании QDT, на которой и было официально анонсировано начало поставок нового процессора. Старший вице-президент и главный менеджер компании Ананд Чандрасехер по этому поводу заявил:
Сегодняшняя презентация является важным достижением и кульминацией более 4 лет усердного проектирования, разработки и поддержки системы… Мы создали самый продвинутый серверный процессор в мире, который предоставляет высокую производительность в совокупности с высоким уровнем энергоэффективности, позволяющий нашим клиентам значительно уменьшить свои затраты.
Помимо неприкрытой гордости за свой продукт, представители компании не стесняются заявлять, что их процессор Centriq 2400 значительно превосходит продукты-конкуренты, к примеру Intel Xeon Platinum 8180. По их подсчетам, на каждый потраченный доллар (а стоимость процессора составляет $1995) пользователь получит производительность в 4 раза. А при перерасчете в производительность на 1 ватт — на 45% больше. Смелые заявления, однако многие из представителей различных компаний, заинтересованных в новинке, более чем рады их услышать.
Технические данные Qualcomm Centriq 2400
Архитектура CPU:
- до 48 64-битных ядер с пиковой частотой в 2.6 ГГц;
- Armv8-совместимость;
- только AArch64;
- Armv8 FP/SIMD;
- Расширение CRC и Armv8 Crypto;
Кэш CPU:
- 64 Кб кэша команд (инструкций) L1 и 24 Кб одноциклового кеша L0;
- 32 Кб кэша данных L1;
- 512 Кб общего кэша L2 на каждые 2 ядра;
- 60 Мб общего кэша L3;
- фильтрация межпроцессорных запросов L2;
- QoS;
где, L (L1, L2, L3, L0) — уровень, т.е. L0 — нулевой уровень.
Технология:
- 10-нм технологии FinFET от Samsung;
Пропускная способность памяти:
- 6 каналов подключения модулей памяти DDR4;
- до 2667 МТ/с на одно подключение;
- 128 ГБ/с — максимальная общая пропускная способность;
- Встроенное сжатие полосы пропускания;
Объем памяти:
- 768 ГБ = 128 ГБ х 6 подключений;
Тип памяти:
- 64-битные DDR4 подключения с 8-битным ECC;
- RDIMM и LRDIMM;
Поддерживаемый интерфейс:
- GPIO;
- I?C;
- SPI;
- 8-полосный SATA Gen 3;
- 32 PCIe Gen3 с возможностью подключения до 6 контроллеров PCIe;
Помимо вышеуказанных характеристик стоит отметить, что данный процессор имеет по 18 миллиардов транзисторов на каждом чипе. А все его ядра связаны двунаправленной кольцевой шиной. При максимальной нагрузке Centriq 2400 потребляет всего 120 Вт.
Основной направленностью нового процессора все же остаться облачные решения. По словам представителей компании, Centriq 2400 позволит создать серверные системе, которые будут отличаться высокой производительностью, эффективностью и масштабируемостью.
Это не могло не привлечь множество компаний, облачные технологии для которых являются чуть ли не основой их деятельности. На презентации побывали: Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Cadence Design Systems, Canonical, Chelsio Communications, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Synopsys, Uber, Xilinx. Список довольно внушительный, что говорит о повышенном внимании к данному продукту.
На данный момент процессор Qualcomm Centriq 2400 только набирает обороты, как в распространенности, так и в популярности. Что, естественно, приведет к появлению чего-то нового, подобного или даже более производительного, со стороны конкурентов компании QDT.
Но далеко не все слепо верят в крутость новинки. Если и те, кто считает, что проведение тестов и сравнительного анализа нескольких процессоров позволит увидеть куда более показательные результаты, нежели слова промоутеров Centriq 2400.
Компания Cloudflare провела сравнительный анализ трех платформ: Grantley (Intel), Purley (Intel) и Centriq (Qualcomm).
Ниже будут представлены графики данного анализа и выводы их автора — Влада Краснова. (Оригинал данного анализа в блоге компании Cloudflare)
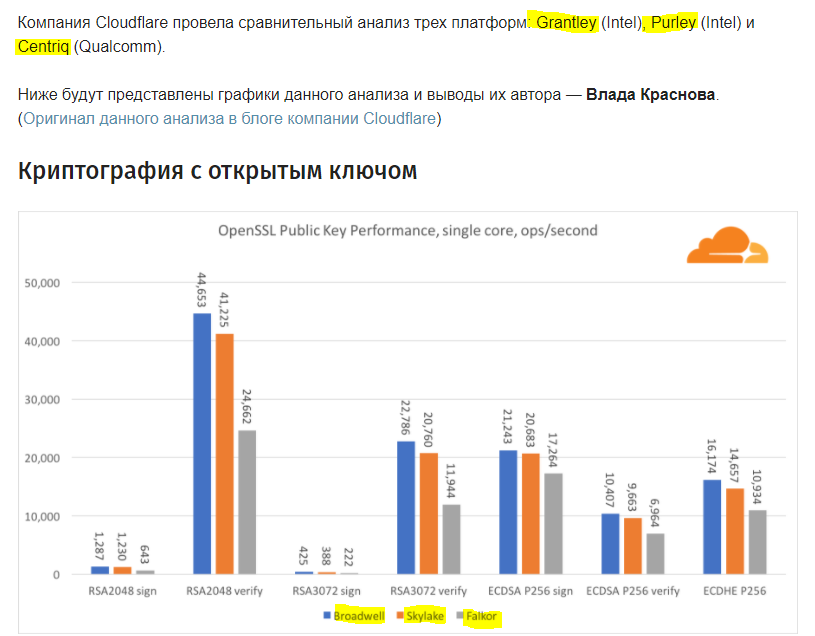
Криптография с открытым ключом
Криптография с открытым ключом — это чистой воды производительность АЛУ (арифметико-логическое устройство). Интересно, но не удивительно, что в одном базовом бенчмарке ядро Broadwell быстрее Skylake, и оба они в свою очередь быстрее, чем Falkor. Это потому, что Broadwell работает на более высокой частоте, хотя в архитектурном плане он не намного уступает Skylake.
Falkor уступает остальным в данном тесте. Во-первых, в одном из базовых бенчмарков был включен режим turbo, означающий, что процессоры Intel работают на более высокой частоте. К тому же в Broadwell Intel представила две специальные инструкции для ускорения обработки больших чисел: ADCX и ADOX. Они выполняют две независимые операции add-with-carry за цикл, тогда как ARM может выполнять только одну. Аналогично, набор инструкций ARMv8 не имеет единой команды для выполнения 64-битного умножения, вместо этого используется пара инструкций MUL и UMULH.
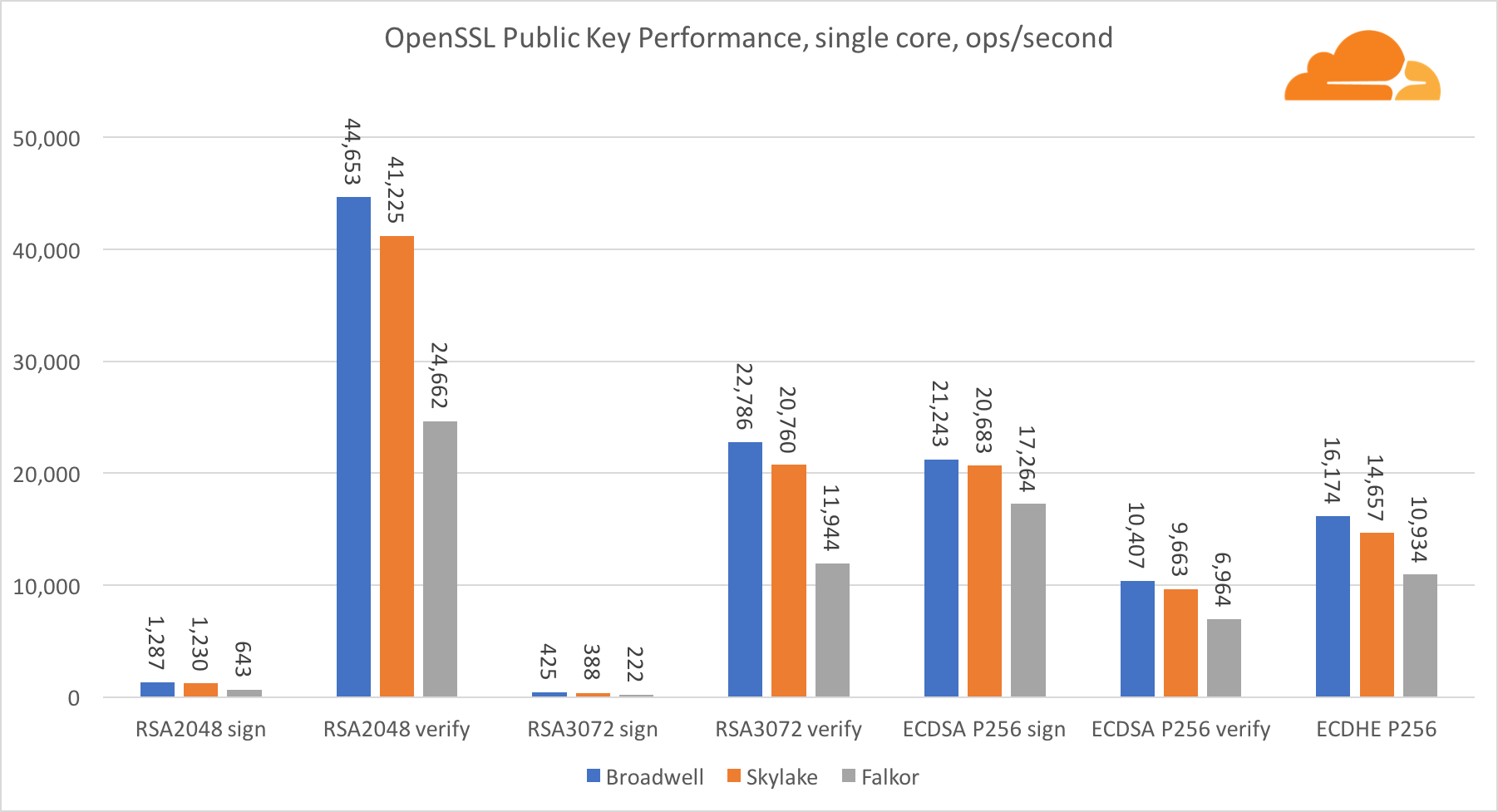
Тем не менее, на уровне SoC, Falkor выигрывает. Он незначительно медленнее, чем Skylake по показателям RSA2048, и только потому, что RSA2048 не имеет оптимизированной реализации для ARM. Производительность ECDSA смехотворно высока. Один чип Centriq может удовлетворить потребности ECDSA практически любой компании в мире.
Также очень интересно видеть, что Skylake превосходит Broadwell на 30%, несмотря на то, что уступил ему в тесте по одному ядру и обладает всего на 20% больше ядер чем Broadwell. Это можно объяснить более эффективным turbo режимом и улучшенной гиперпоточностью.
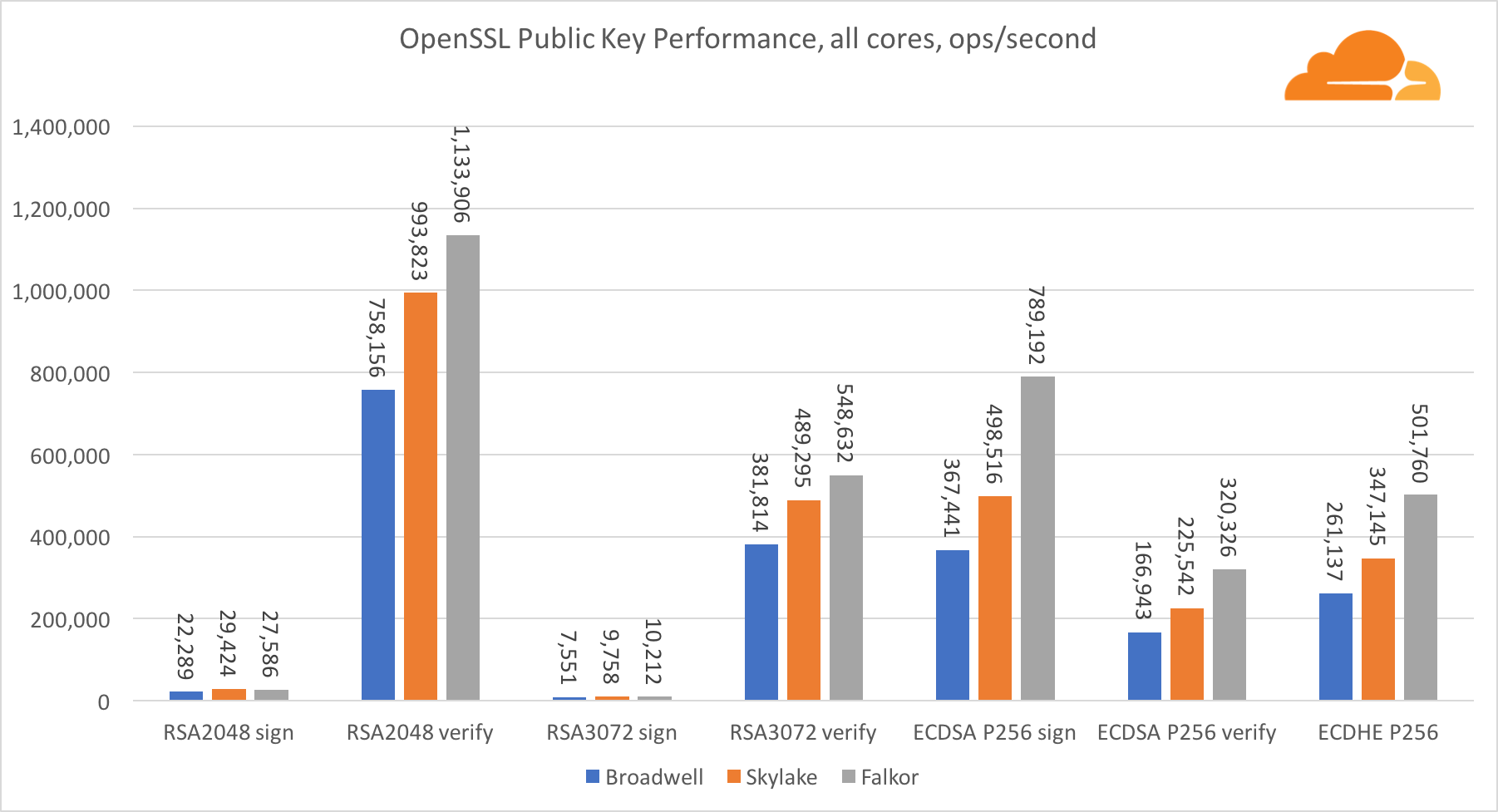
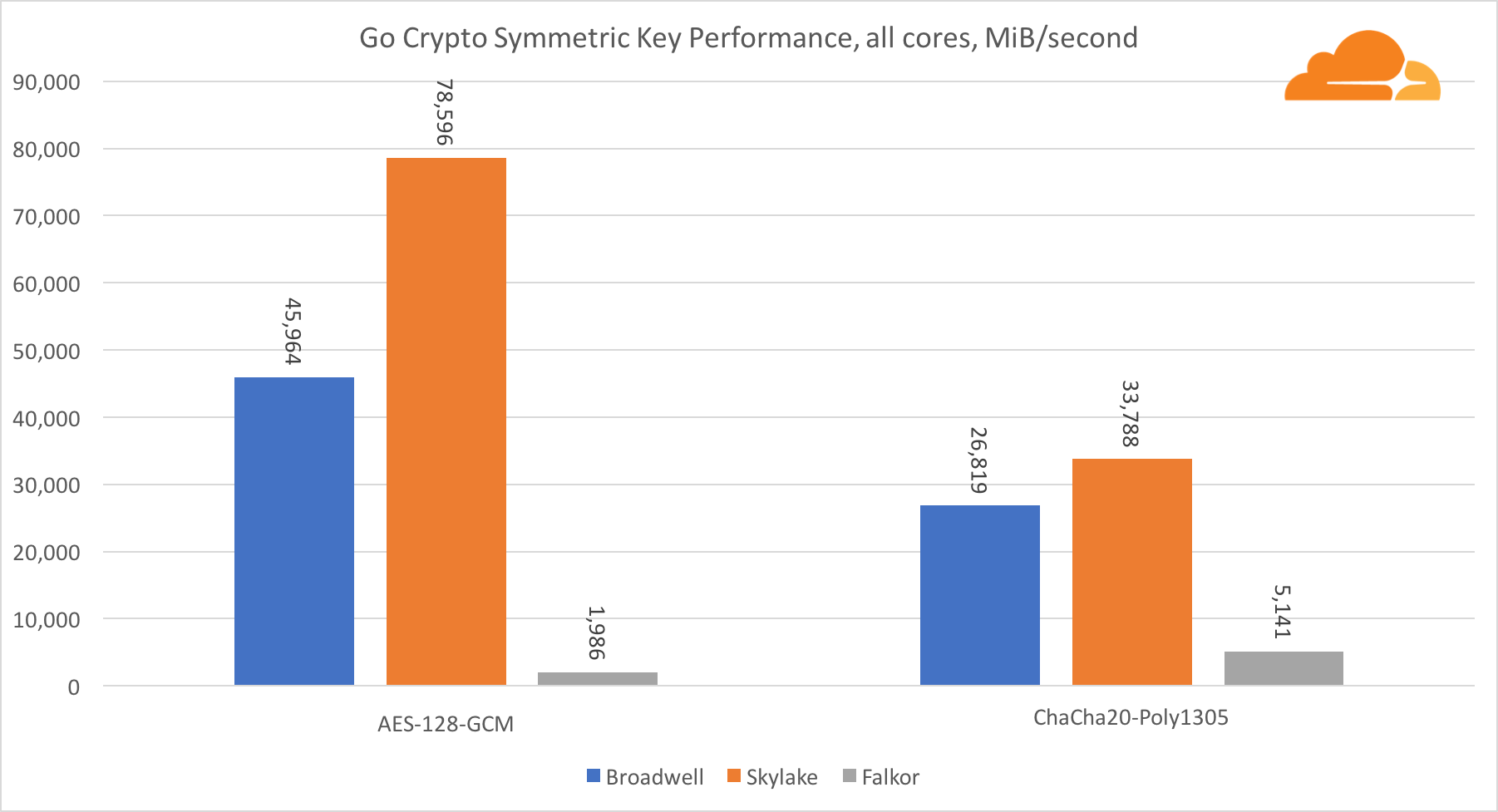
Симметричная криптография
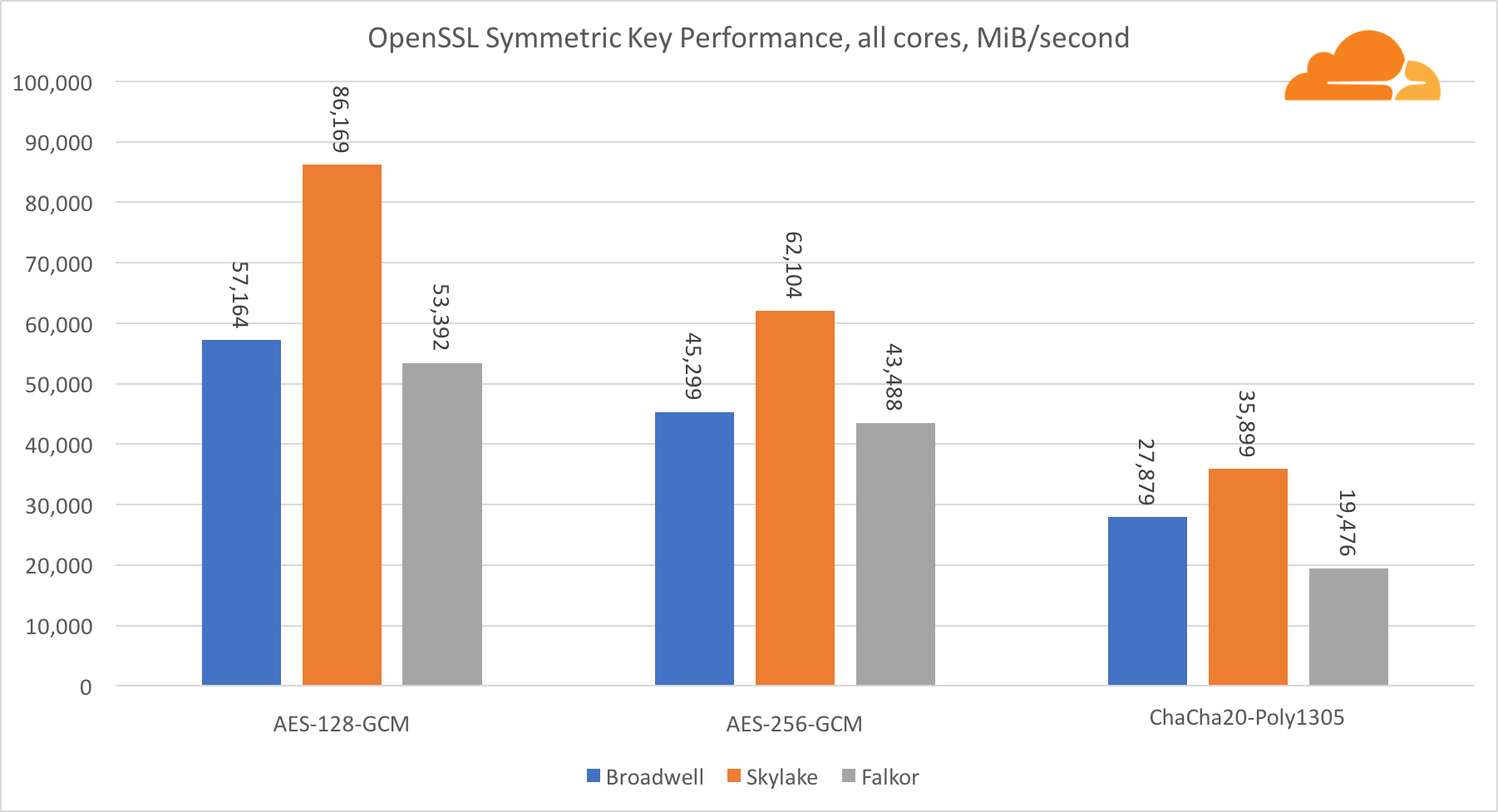
Производительность ядер Intel в симметричной криптографии просто великолепна.
AES-GCM использует комбинацию специальных аппаратных инструкций для ускорения AES и CLMUL. Intel впервые представила эти инструкции еще в 2010 году, с их процессором Westmere и с каждым поколением они улучшали их производительность. Недавно ARM представила набор подобных инструкций с их 64-битным набором команд в качестве необязательного дополнения. К счастью, каждый поставщик оборудования, которого я знаю, реализовал их. Весьма вероятно, что Qualcomm улучшит производительность криптографических инструкций в будущих поколениях.
ChaCha20-Poly1305 — более общий алгоритм, разработанный таким образом, чтобы лучше использовать широкие SIMD-модули. Процессор Qualcomm имеет только 128-битный NEON SIMD, а Broadwell — 256-битный AVX2, а Skylake — 512-битный AVX-512. Это объясняет, почему Skylake с таким отрывом ушел в лидеры по оценке работы с одним ядром. В тесте всех ядер одновременно отрыв Skylake от остальных сократился, поскольку он должен снизить тактовую частоту при выполнении рабочих нагрузок AVX-512. При выполнении AVX-512 на всех ядрах базовая частота уменьшается до 1,4 ГГц. Помните об этом, если вы смешиваете AVX-512 и другой код.
Выводом касательно симметричной криптографии является то, что хоть Skylake и лидирует, Broadwell и Falkor показали очень неплохие результаты, имея достаточно высокую производительность для реальных случаев, учитывая тот факт, что на нашей стороне RSA потребляет больше процессорного времени, чем все другие криптоалгоритмы, вместе взятые.
Компрессия (сжатие)
Следующий тест, который я хотел провести, это компрессия. По двум причинам. Во-первых, это важная рабочая нагрузка, поскольку чем лучше компрессия, тем меньше нужно пропусков способности, а это позволяет быстрее доставлять контент клиенту. Во-вторых, это очень требовательная рабочая нагрузка с высокой частотой Branch misprediction.
Очевидно, что первым тестом будет популярная библиотека zlib. В Cloudflare мы используем улучшенную версию библиотеки, оптимизированную для 64-разрядных процессоров Intel, и хотя она написана в основном на языке C, она использует некоторые специфические для Intel встроенные функции. Сравнивать эту оптимизированную версию с оригинальной zlib было бы несправедливо. Но не волнуйтесь, немного усилий и я адаптировал библиотеку так, чтобы она работала на ARMv8 архитектуре, с использованием свойств NEON и CRC32. При этом скорость ее в 2 раза больше чем у оригинальной, для некоторых файлов.
Второй тест — это новая библиотека brotli, написанная на языке С и позволяющая использовать равные условия для всех платформ.
Все тесты проведены на HTML blog.cloudflare.com, в памяти, подобно тому, как NGINX производит потоковое сжатие. Разве конкретной версии HTML файла 29329 байта, что является хорошим показателем, поскольку соответствует размер большинству файлов, которые мы сжимаем. Тест параллельного сжатия — это параллельное сжатие нескольких файлов одновременно, одиночного — сжатие одного файла в несколько потоков, аналогично тому, как работает NGINX.
gzip
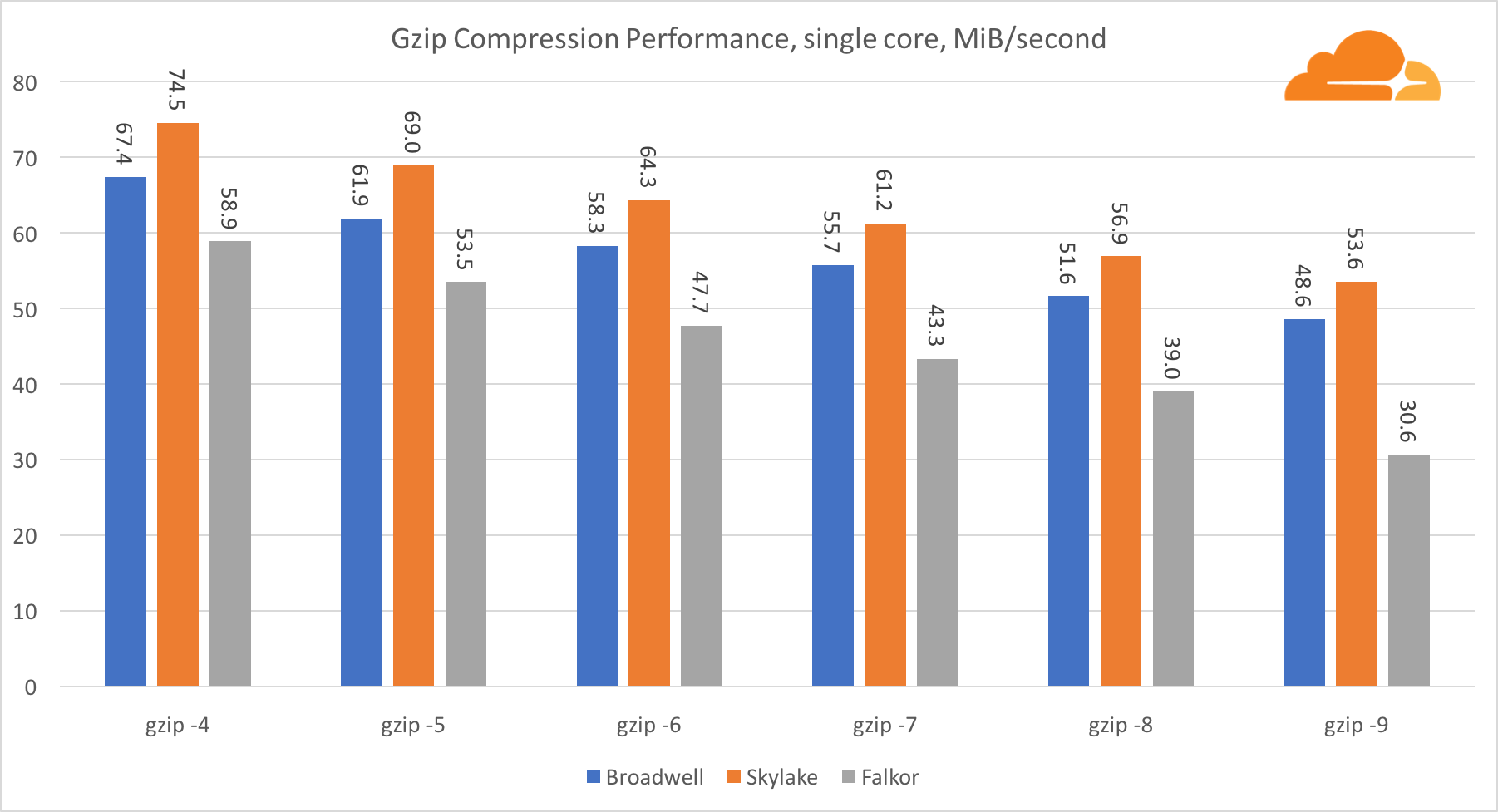
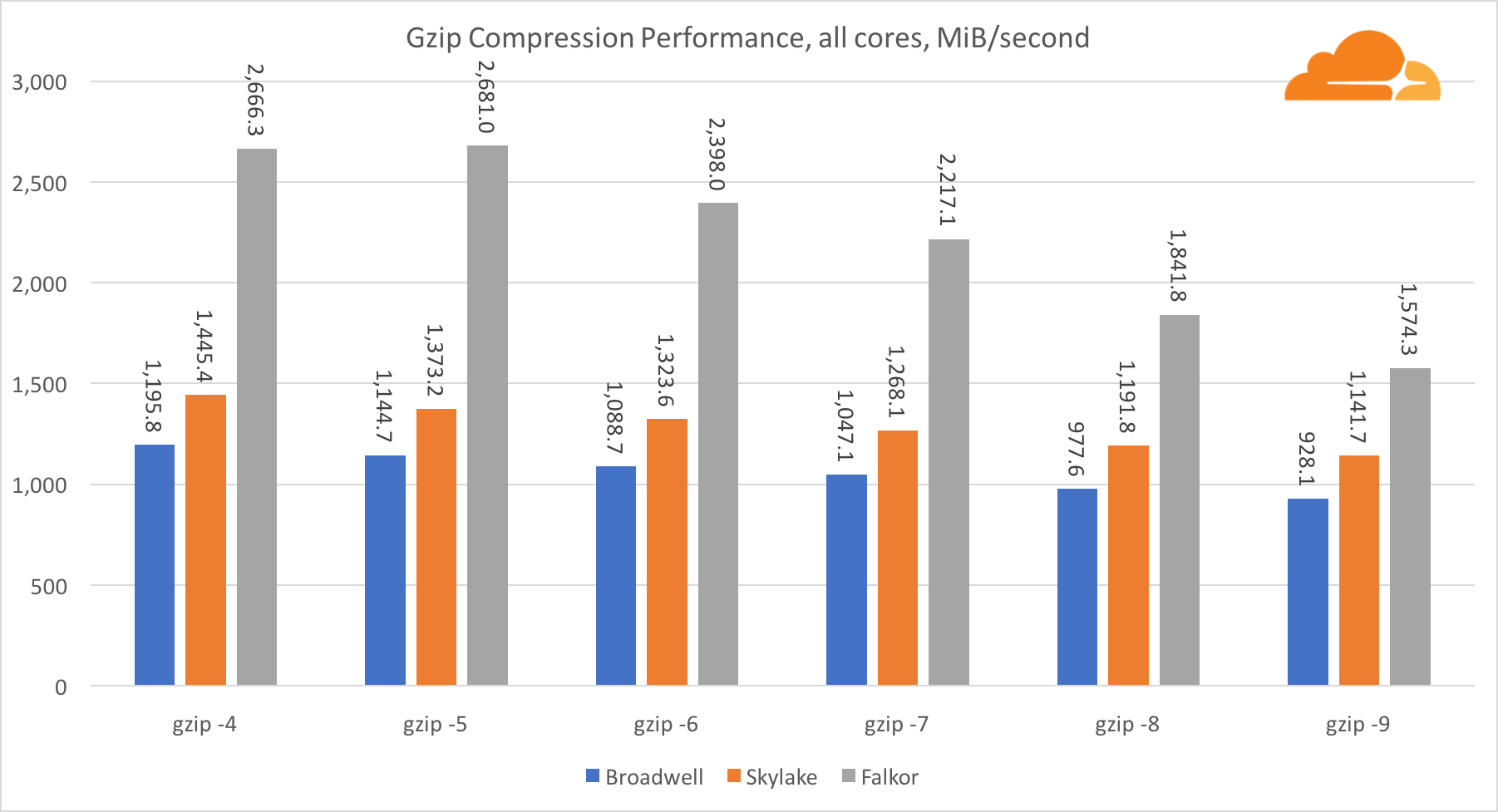
Используя gzip на уровне одного ядра, Skylake бесспорно побеждает. Имея более низкую частоту, чем Broadwell, Skylake выигрывает за счет более низкого уровня воздействия branch misprediction. Ядро Falkor не сильно отстает. На системном уровне Falkor показывает себя намного лучше, за счет большего числа ядер. Обратите внимание, насколько gzip хорошо масштабируется на нескольких ядрах.
Brotli
С brotli на одном ядре ситуация схожа с предыдущей. Skylake является самым быстрым, но Falkor не очень отстает. А на стандарте 9, Falkor даже быстрее. Brotli со стандартом 4 очень похож на gzip уровня 5, в то время как фактическая компрессия все же лучше (8010B против 8187B).
Пр компрессии на нескольких ядрах, ситуация становится немного запутанной. Для уровней 4, 5 и 6 brotli скейлится очень хорошо. На уровне 7 и 8 производительно на ядро начинает падать, опускаясь до дна на уровне 9, где мы получаем в 3 раза меньше производительность работы всех ядер в сравнении с одним.
По моему представлению, это связано с тем что с каждым уровнем brotli начинает потреблять больше памяти и рушит кэш. Показатели начинают восстанавливаться уже на уровне 10 и 11.
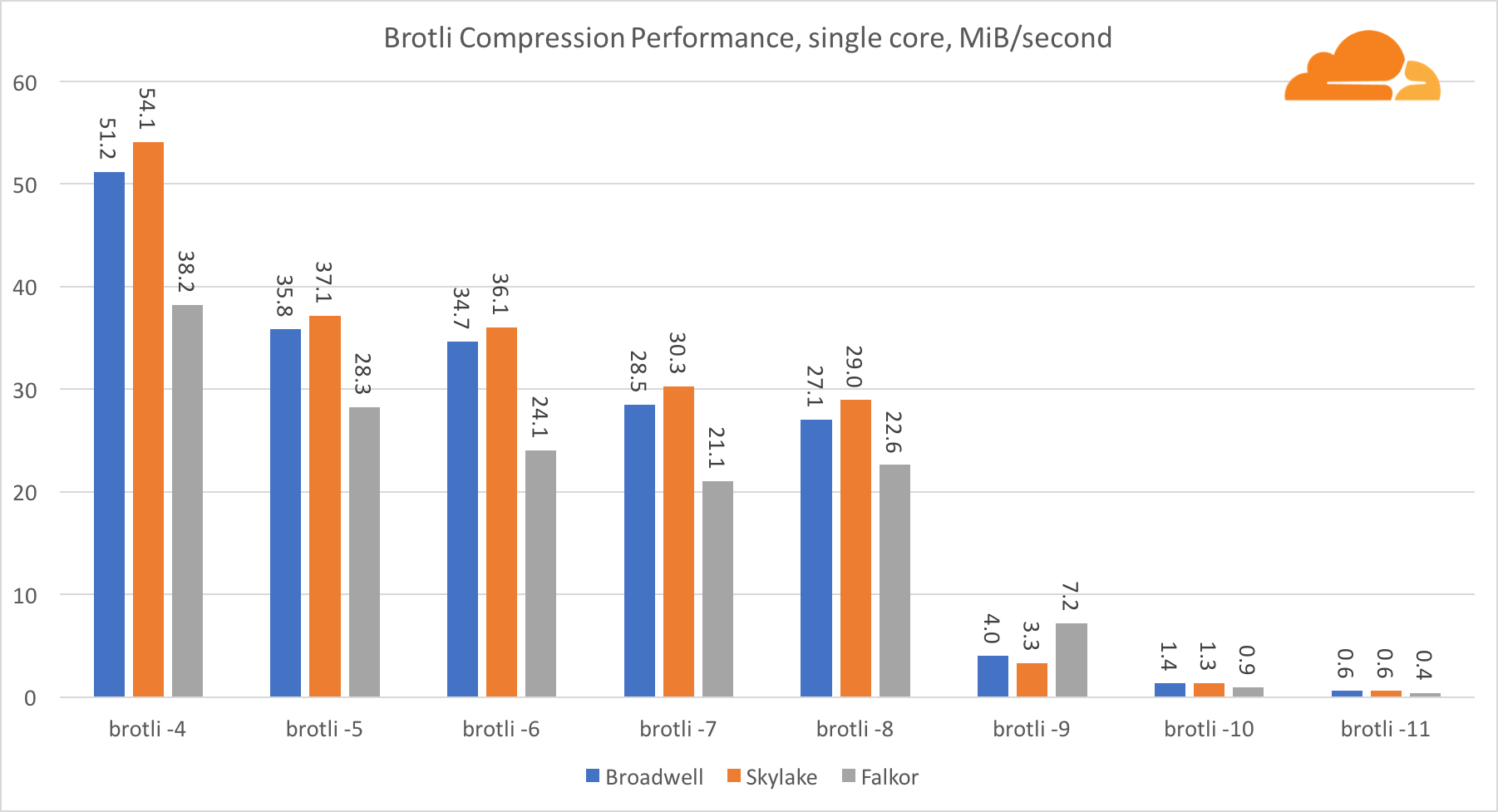
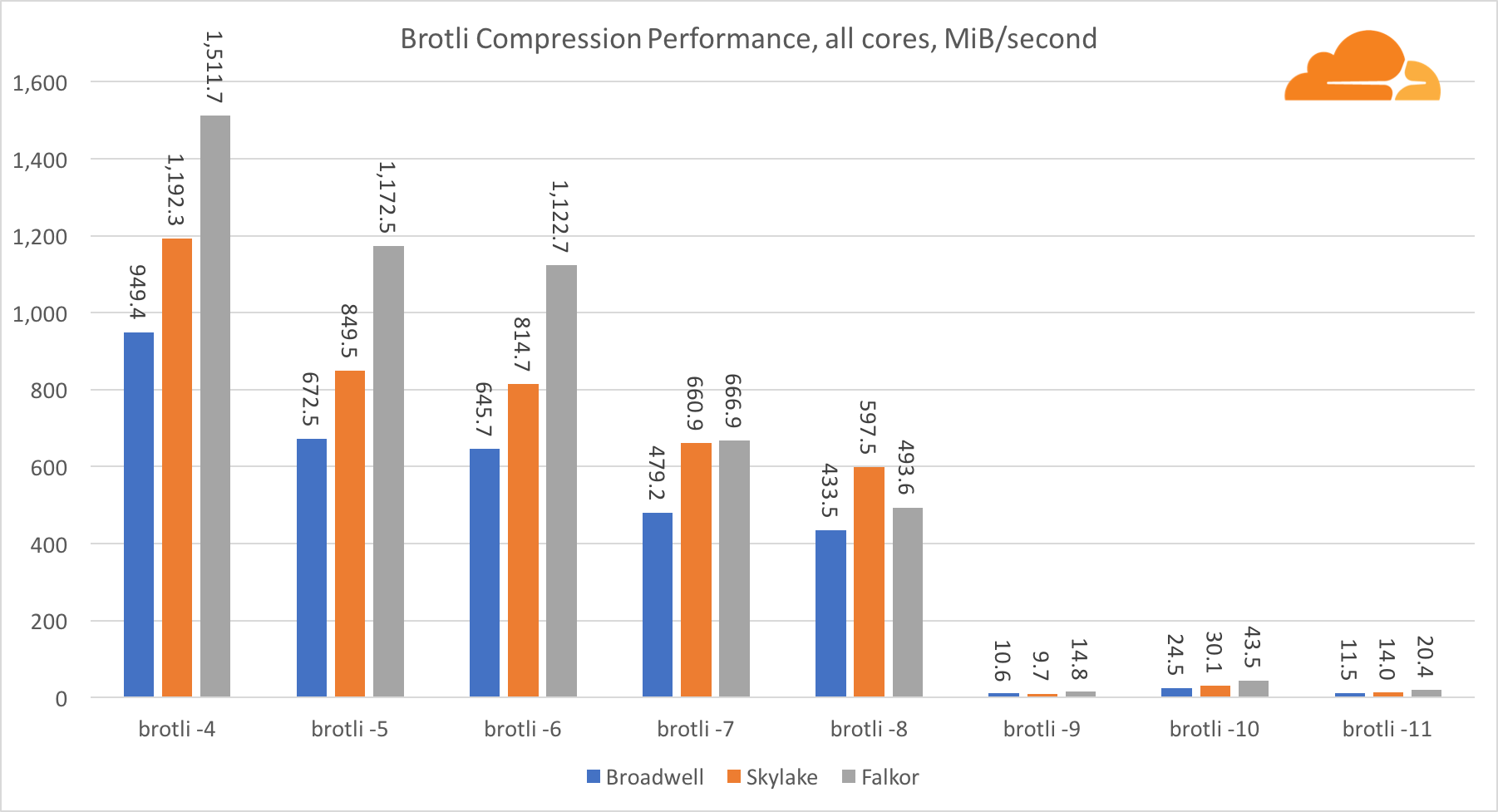
Как вывод — победу одержал Falkor, учитывая что динамическое сжатие не перейдет выше 7 уровня.
Golang
Golang это еще один очень важный язык для Cloudflare. Это также один из первых языков поддерживающий ARMv8, поэтому можно ожидать хорошей производительности. Я использовал некоторые встроенные тесты, но модифицировал их под множественные goroutines.
Go crypto
Я бы хотел начать с тестов производительности шифрования. Благорадя OpenSSL у нас есть отличные исходные данные, и будет весьма интересно увидеть насколько хороша библиотека Go.
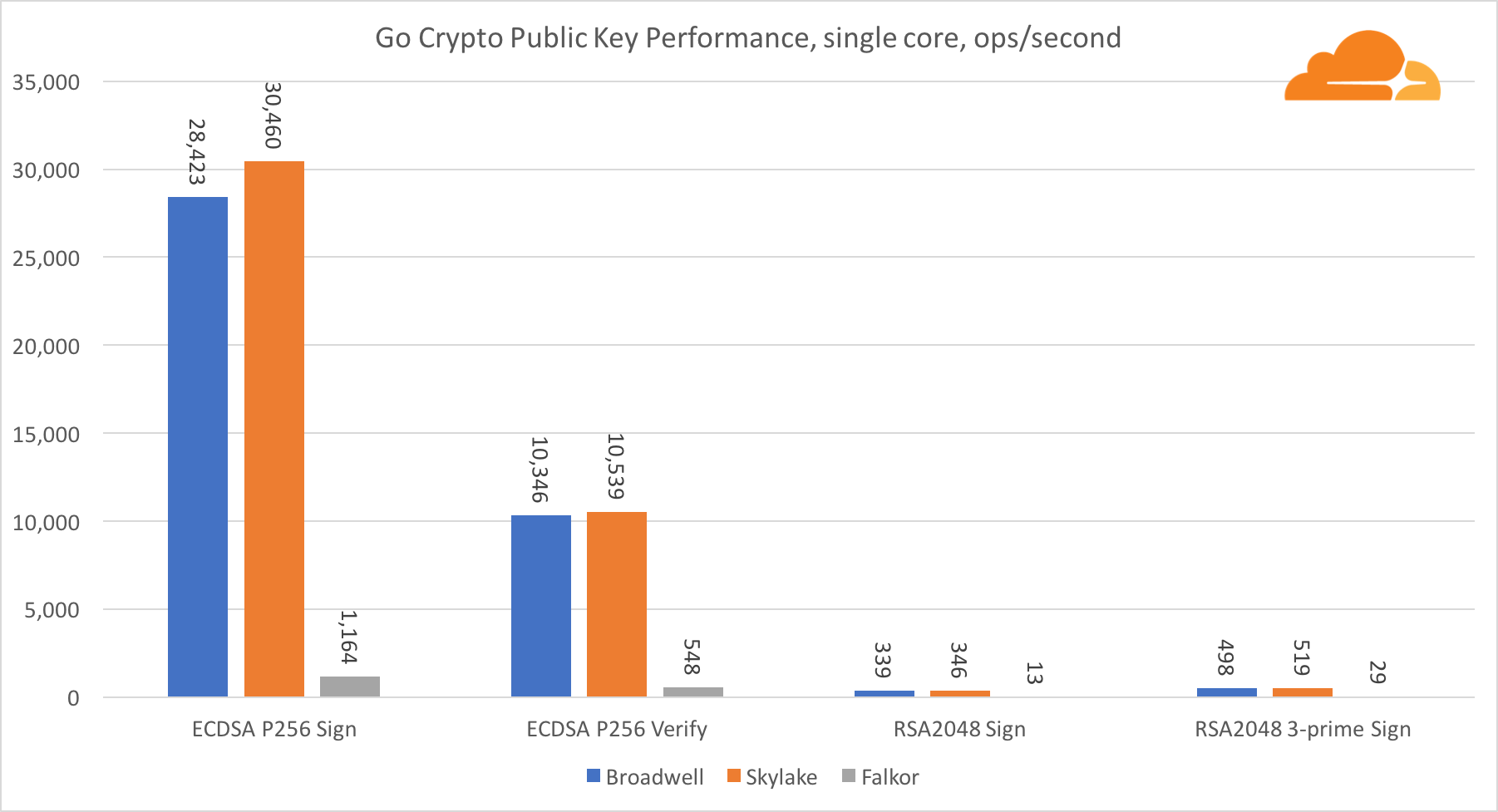
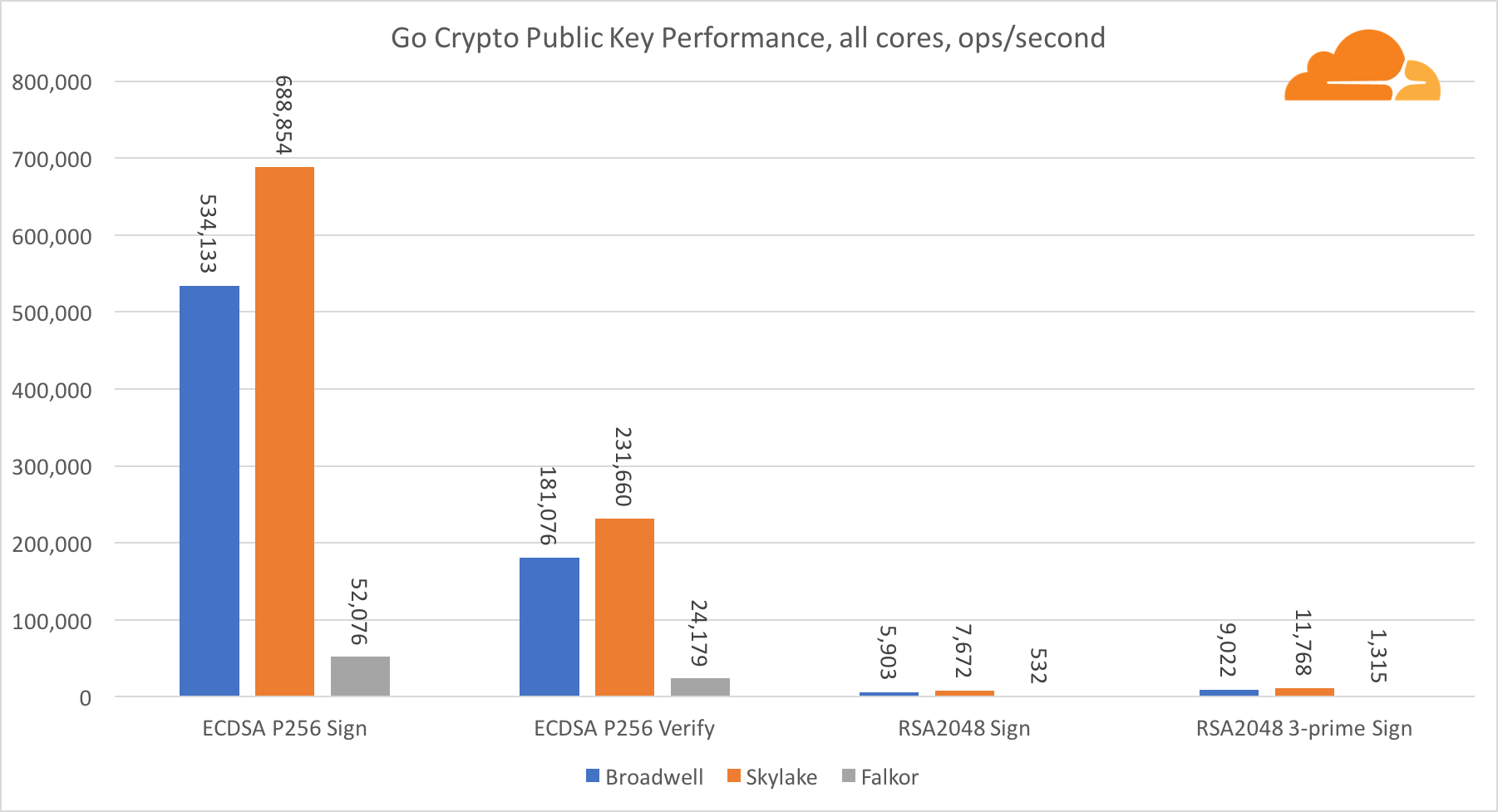
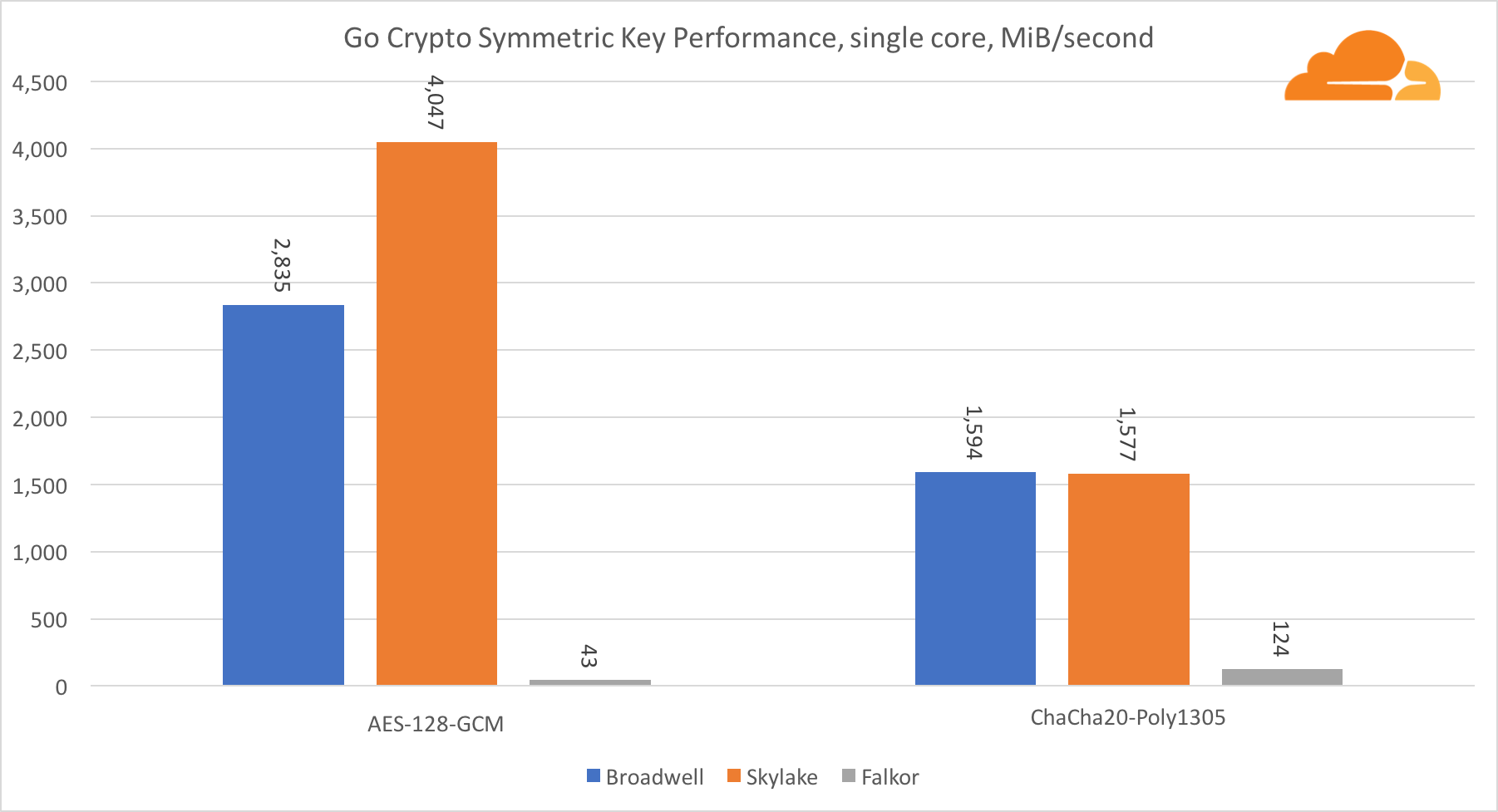
Касательно Go crypto, то ARM и Intel находятся даже не в одной весовой категории. У Go есть отлично оптимизированный ассемблерный код для ECDSA, AES-GCM и Chacha20-Poly1305 на Intel. Также есть оптимизированные математические функции, используемые в вычислениях RSA. У ARMv8 всего этого нет, что ставит его в очень невыгодное положение.
Тем не менее, разрыв можно сократить относительно небольшими усилиями, и мы знаем, что при правильной оптимизации производительность может быть на одном уровне с OpenSSL. Даже очень незначительные изменения, такие как реализация функции addMulVVW в сборке, приводят к более чем десятикратному увеличению производительности RSA, помещая Falkor (с показателем в 8009) выше как Broadwell, так и Skylake.
Стоит отметить еще одну интересную штуку — на Skylake код Go Chacha20-Poly1305, который использует AVX2, работает примерно так же как и код OpenSSL AVX512. Опять же это связано с тем, что AVX2 работает на более высоких тактовых частотах.
Go gzip
Теперь рассмотрим производительность Go со стороны gzip. Тут также есть отличный ориентир на довольно хорошо оптимизированный код, и мы можем сравнить его с Go. В случае библиотеки gzip, специфических оптимизаций для Intel нет.
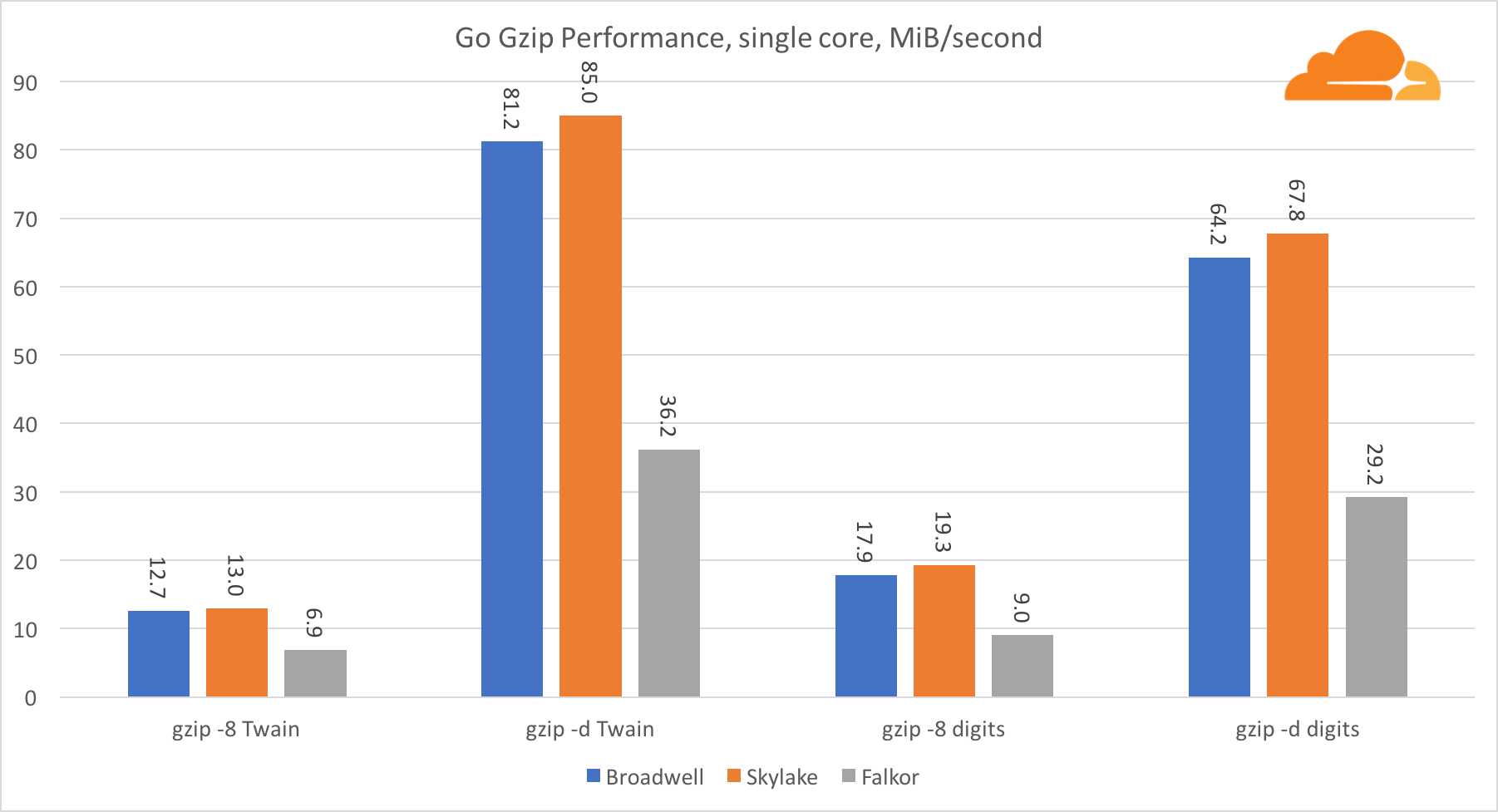

Производительность gzip довольно хороша. Производительность по одному ядру Falkor значительно отстает от обоих процессоров Intel, но на системном уровне ему удалось превзойти Broadwell и расположиться ниже Skylake. Поскольку мы уже знаем, что Falkor превосходит другие два процессора, когда работает С. Это может означать только одно — бэкенд Go для ARMv8 все еще не доработан по сравнению с gcc.
Go regexp
Regexp широко используется в самых разных задачах, потому его производительность также крайне важна. Я запустил встроенные тесты на 32 Кб потоках.
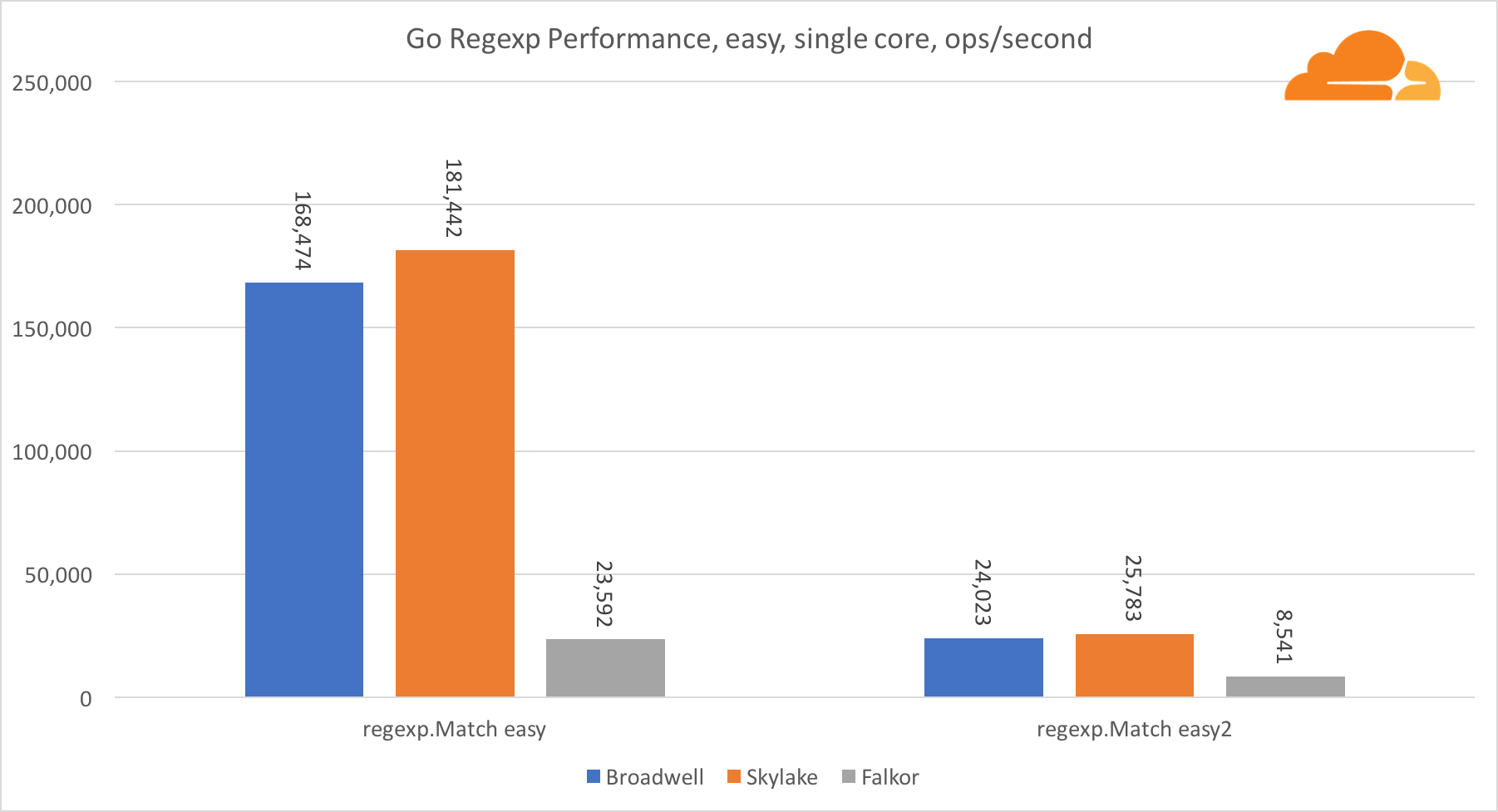
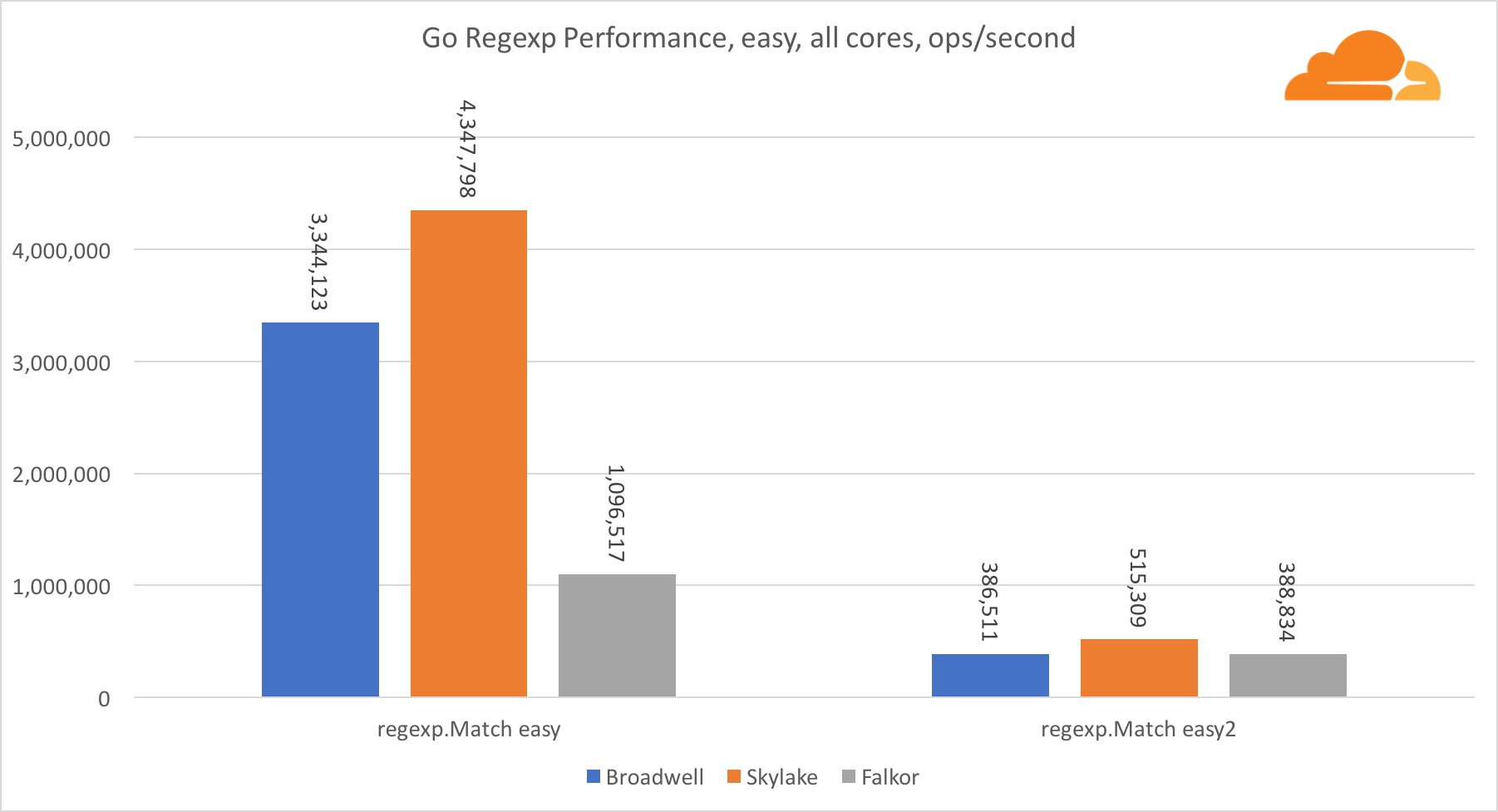
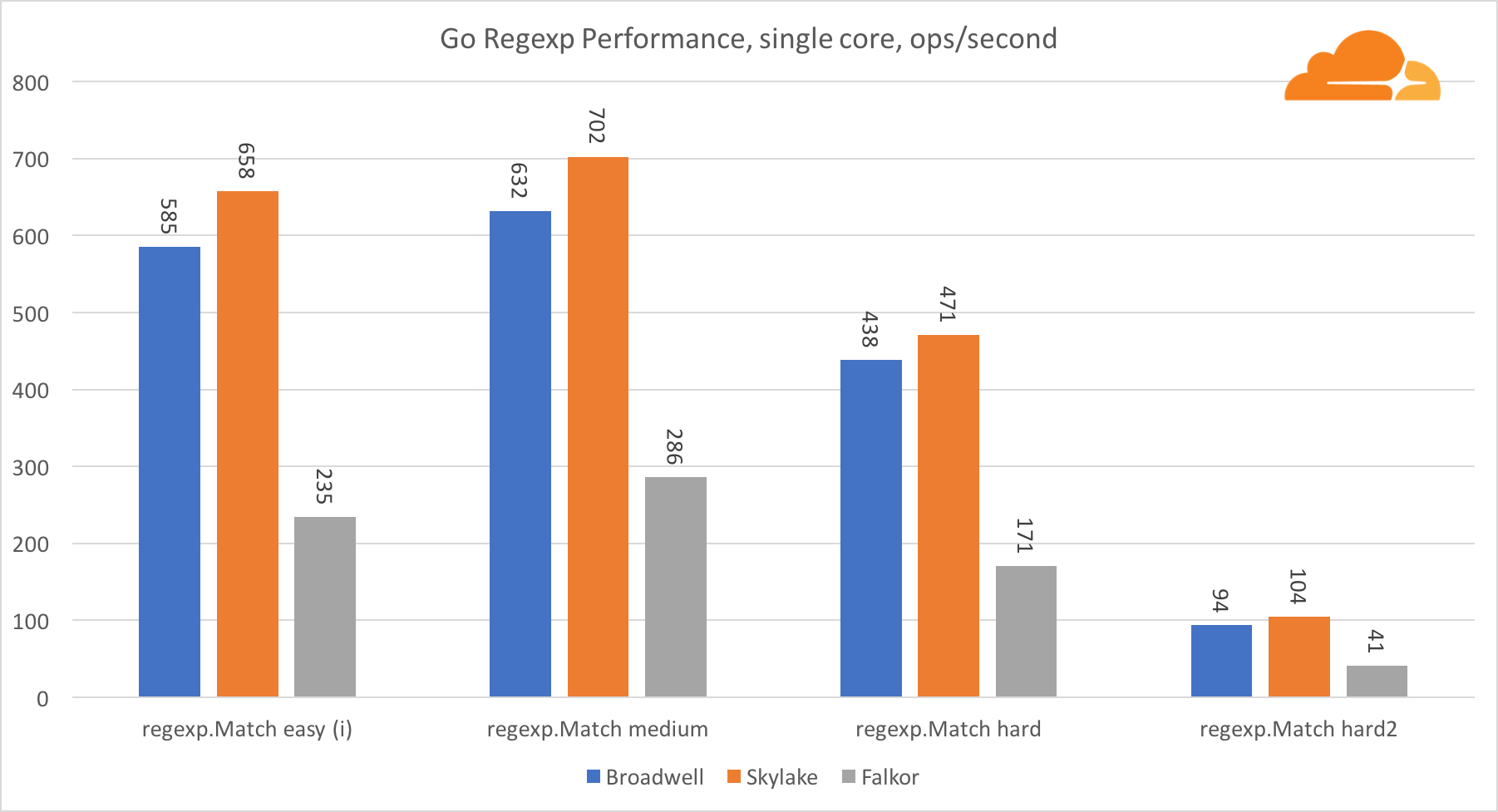
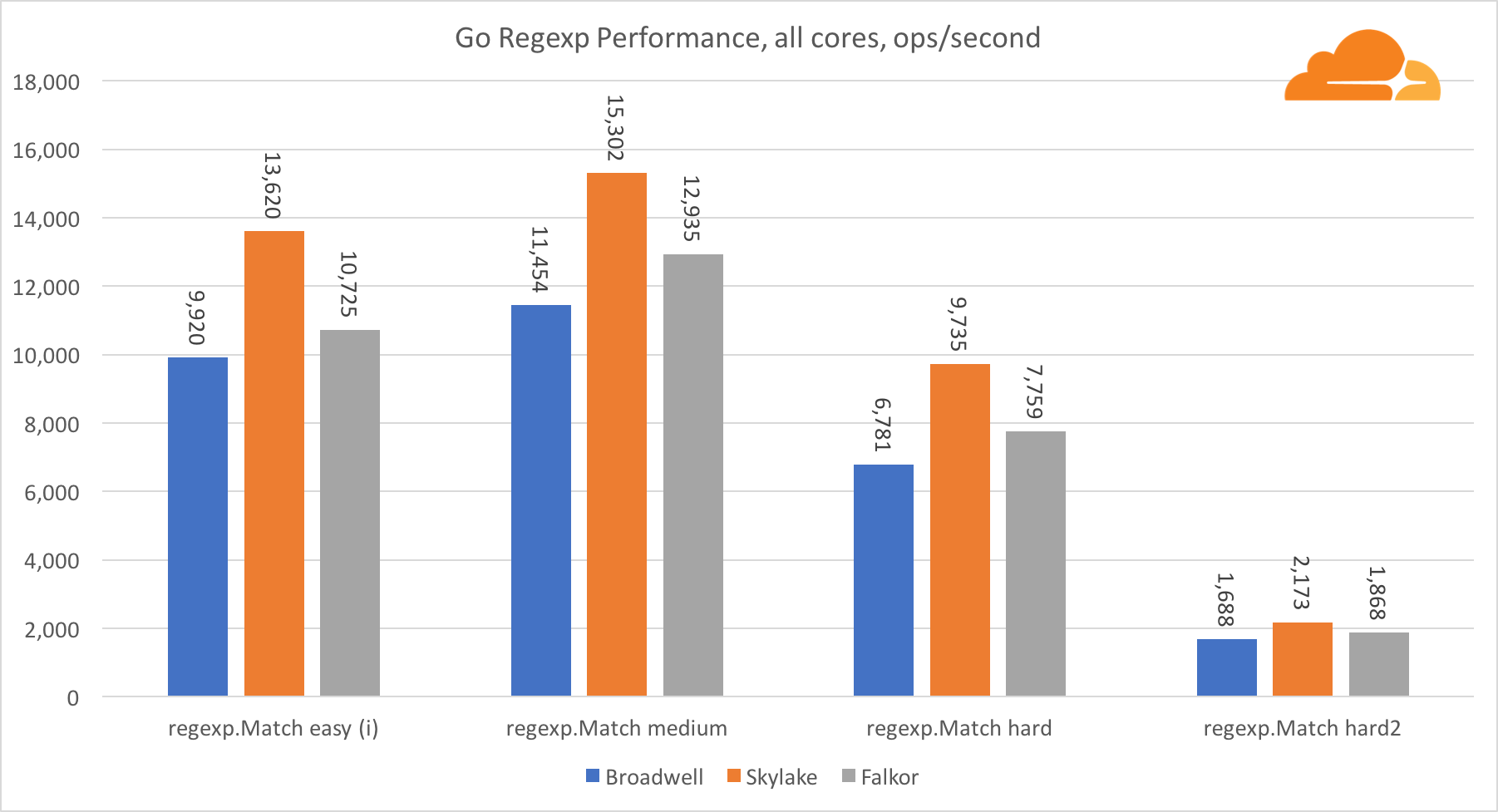
На Falkor производительность Go regexp не очень хороша. На средних и сложных тестах он занимает второе место, благодаря большему числу ядер, но, все же, Skylake значительно быстрее.
Более подробное рассмотрение процесса показывает, что много времени тратится на функцию bytes.IndexByte. Эта функция обладает ассемблер реализацией для amd64 (runtime.indexbytebody), но основная реализация для Go. Во время легких тестов regexp еще больше времени проводилось в этой функции, что объясняет еще больший разрыв.
Go strings
Еще одна важная для веб-сервера библиотека это Go strings. Я тестировал только основной Replacer class.
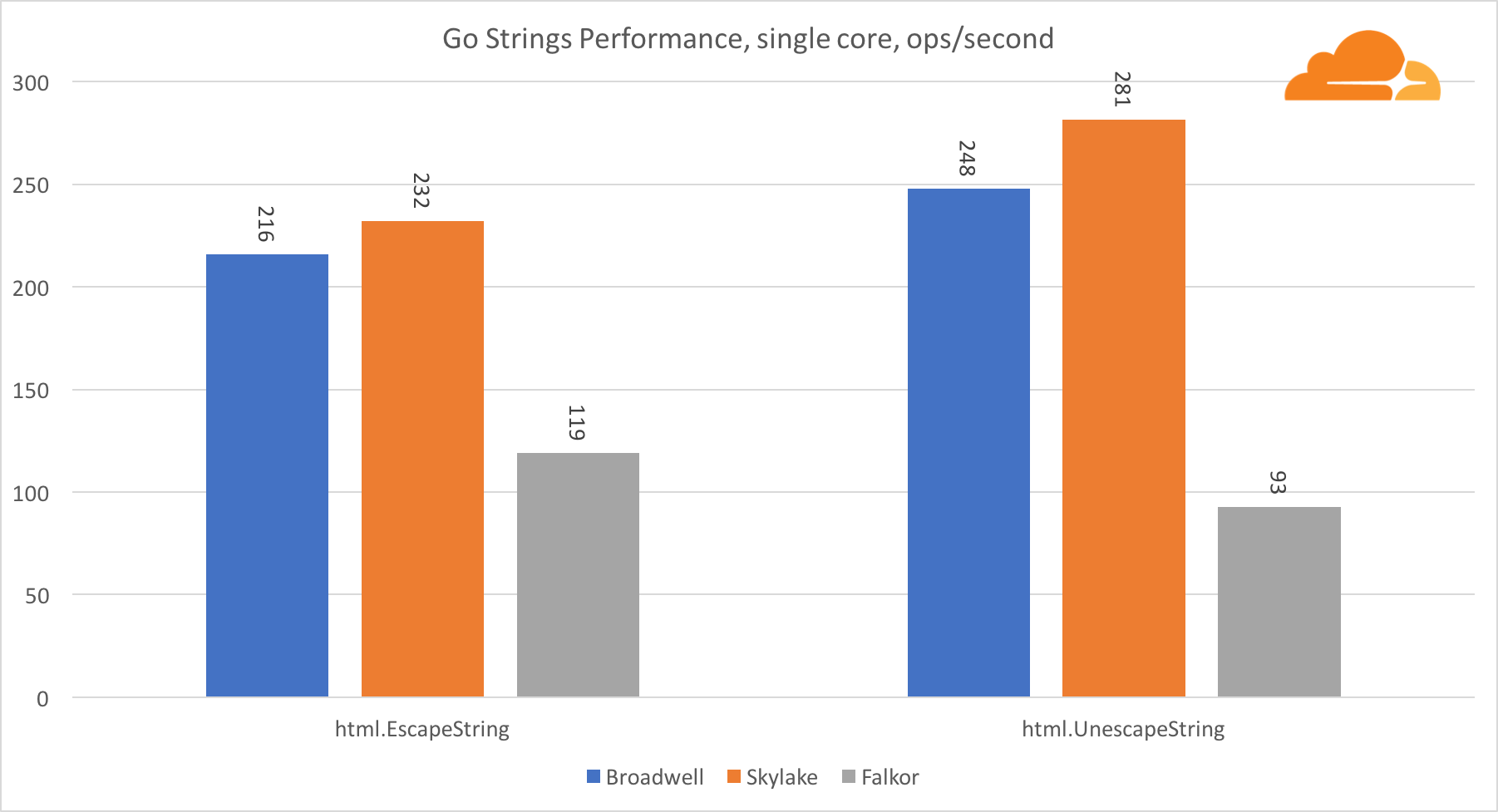
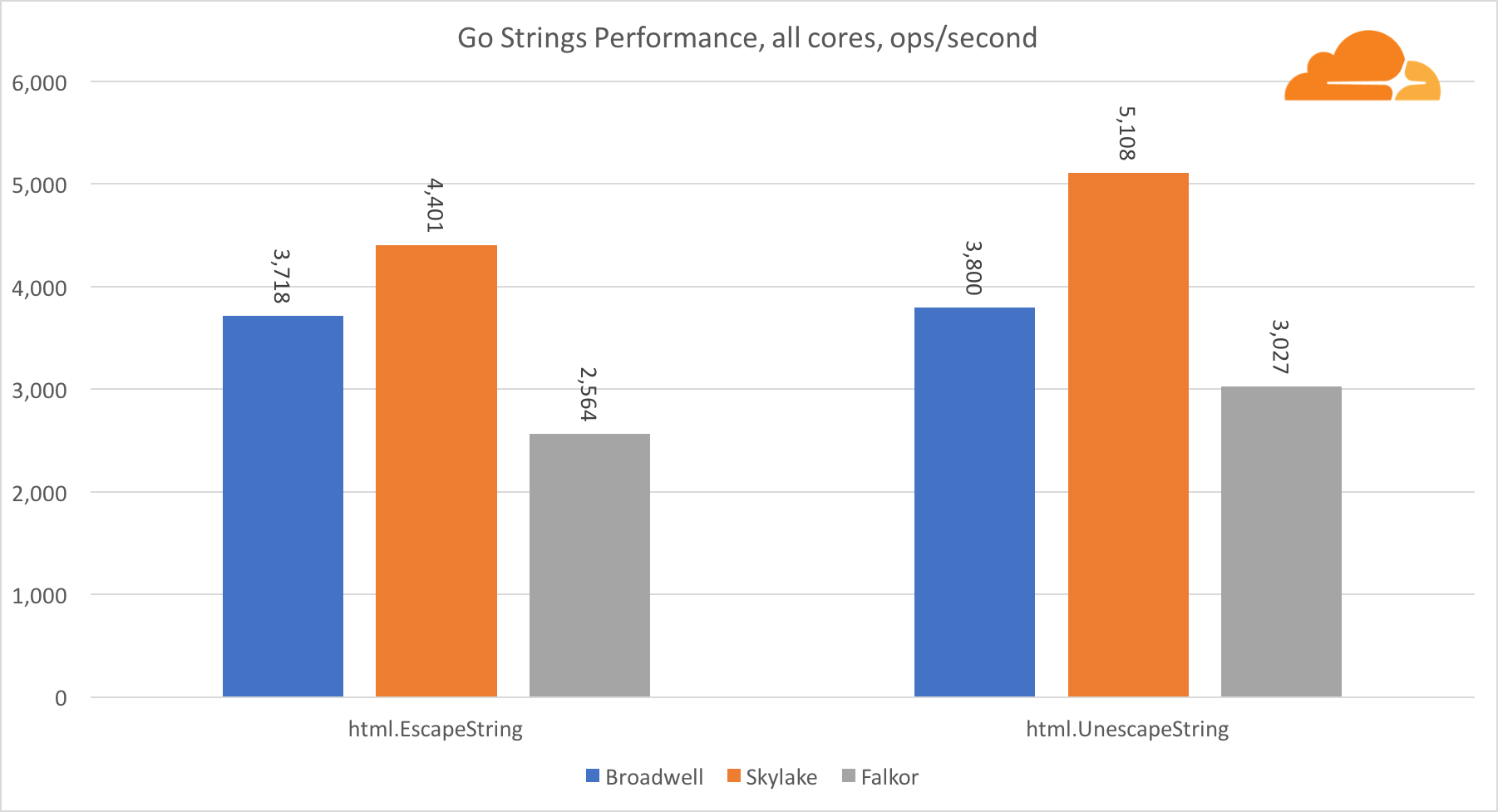
В этом тесте Falkor опять отстает, уступая даже Broadwell. Подробное рассмотрение показывает долгое пребывание в функции runtime.memmove. Знаете что? У нее есть отлично оптимизированный код ассемблера для amd64, который использует AVX2, но только самый простой ассемблер, который копирует 8 байт за один раз. Изменив 3 строчки в этом коде и использовав инструкции LDP/STP (загрузка пары / хранение пары) можно копировать единовременно 16 байт, что увеличило производительность memmove на 30%, что, в свою очередь, на 20% ускоряет работу EscapeString и UnescapeString. И это только верхушка айсберга.
Вывод по Go
Поддержка Go на aarch64 довольно разочаровывающая. Я с радостью заявляю, что все компилировалось и работало безукоризненно, но со стороны производительности могло быть и лучше. Складывается впечатление, что большая часть усилий была потрачена на бэкэнд компилятора, а библиотека была практически нетронута. Существует множество низкоуровневых оптимизаций, к примеру мое исправление addMulVVW, которое заняло 20 минут. Qualcomm и другие поставщики ARMv8 намерены потратить значительные технические ресурсы на исправление ситуации, но любой, на самом деле, может внести свой вклад в Go. Поэтому, если вы хотите оставить свой след в истории, сейчас самое время.
LuaJIT
Lua это клей, который скрепляет воедино Cloudflare.
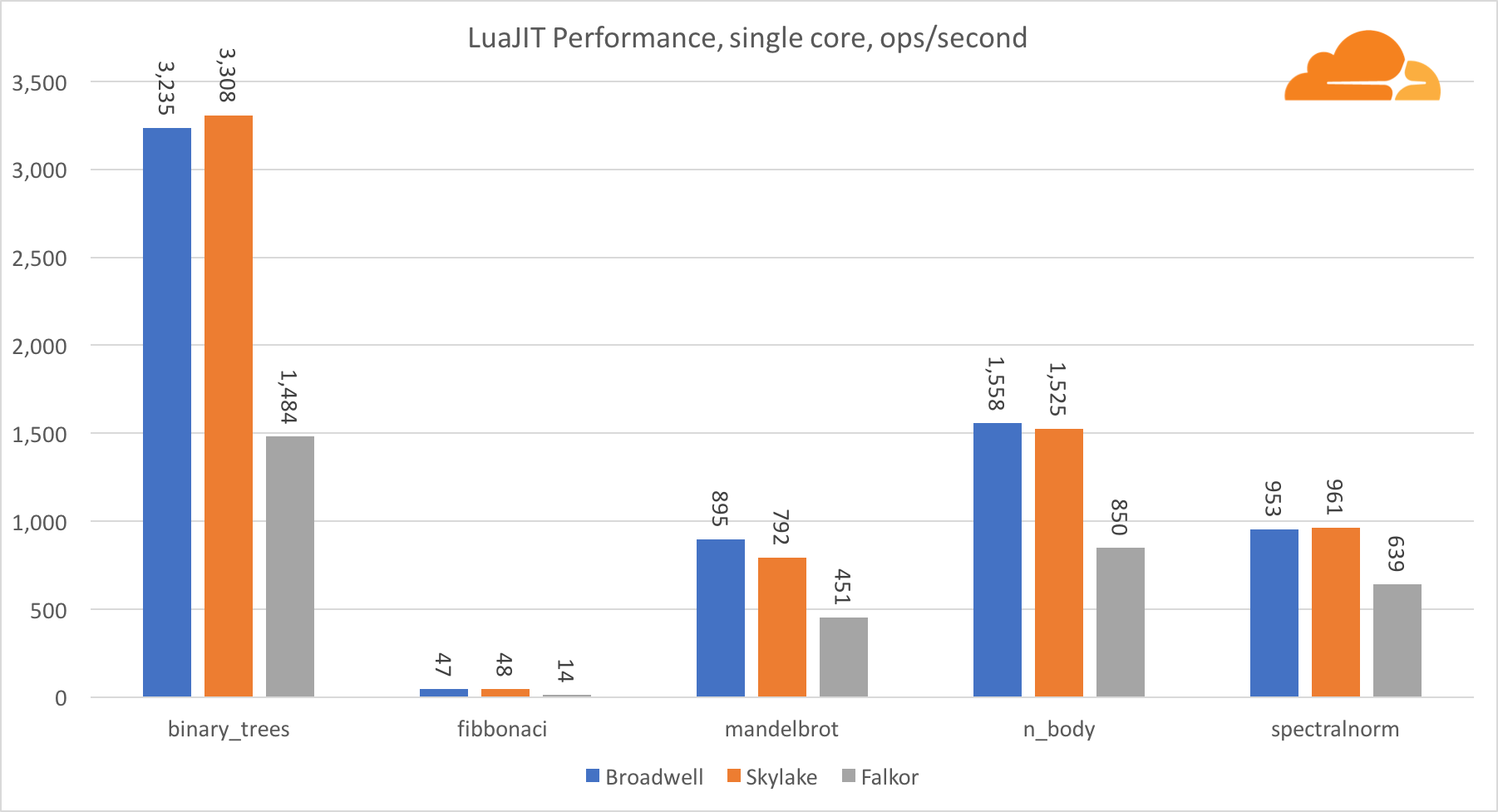
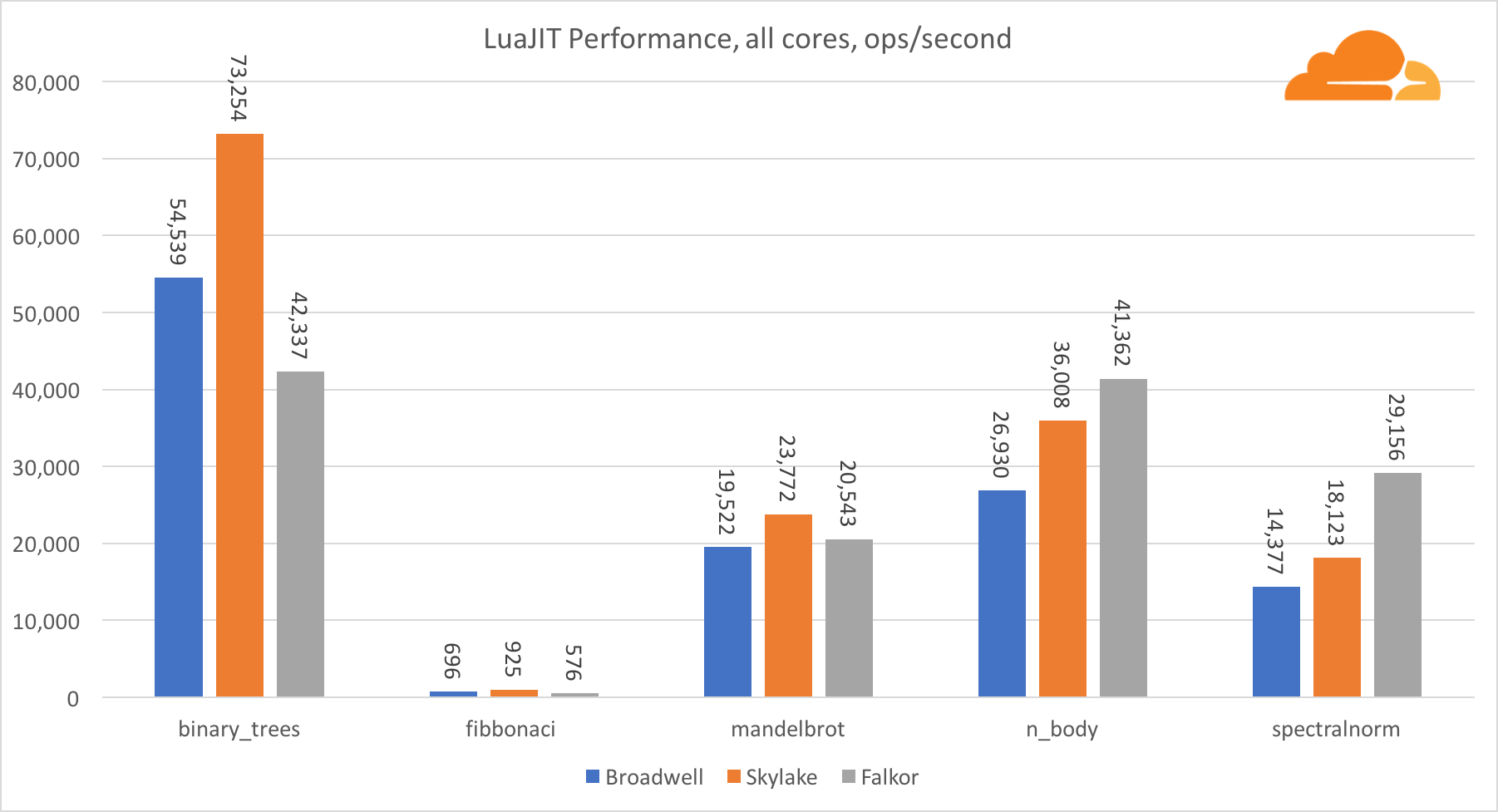
За исключением теста binary_trees, производительность LuaJIT на ARM очень конкурентоспособна. Два теста он выигрывает, а на третьем идет нос в нос с конкурентами.
Стоит заметить, что тест binary_trees крайне важен, поскольку в нем задействовано множество циклов распределения памяти и сбора мусора. Он требует более дотошного рассмотрения в будущем.
NGINX
В качестве рабочей нагрузки NGINX я решил создать таковую, которая будет напоминать фактический сервер.
Я настроил сервер, который обслуживает HTML-файл, используемый в тесте gzip, поверх https, с помощью набора шифров ECDHE-ECDSA-AES128-GCM-SHA256.
Он также использует LuaJIT для перенаправления входящего запроса, удаления всех разрывов строк и дополнительных пробелов из файла HTML при добавлении метки времени. Затем HTML сжимается с использованием brotli 5.
Каждый сервер был настроен для работы с таким количеством пользователей, как у виртуальных процессоров. 40 для Broadwell, 48 для Skylake и 46 для Falkor.
В качестве клиента для этого теста я использовал программу hey, работающую от 3 серверов Broadwell.
Одновременно с тестом мы взяли показания мощности из соответствующих блоков BMC каждого сервера.
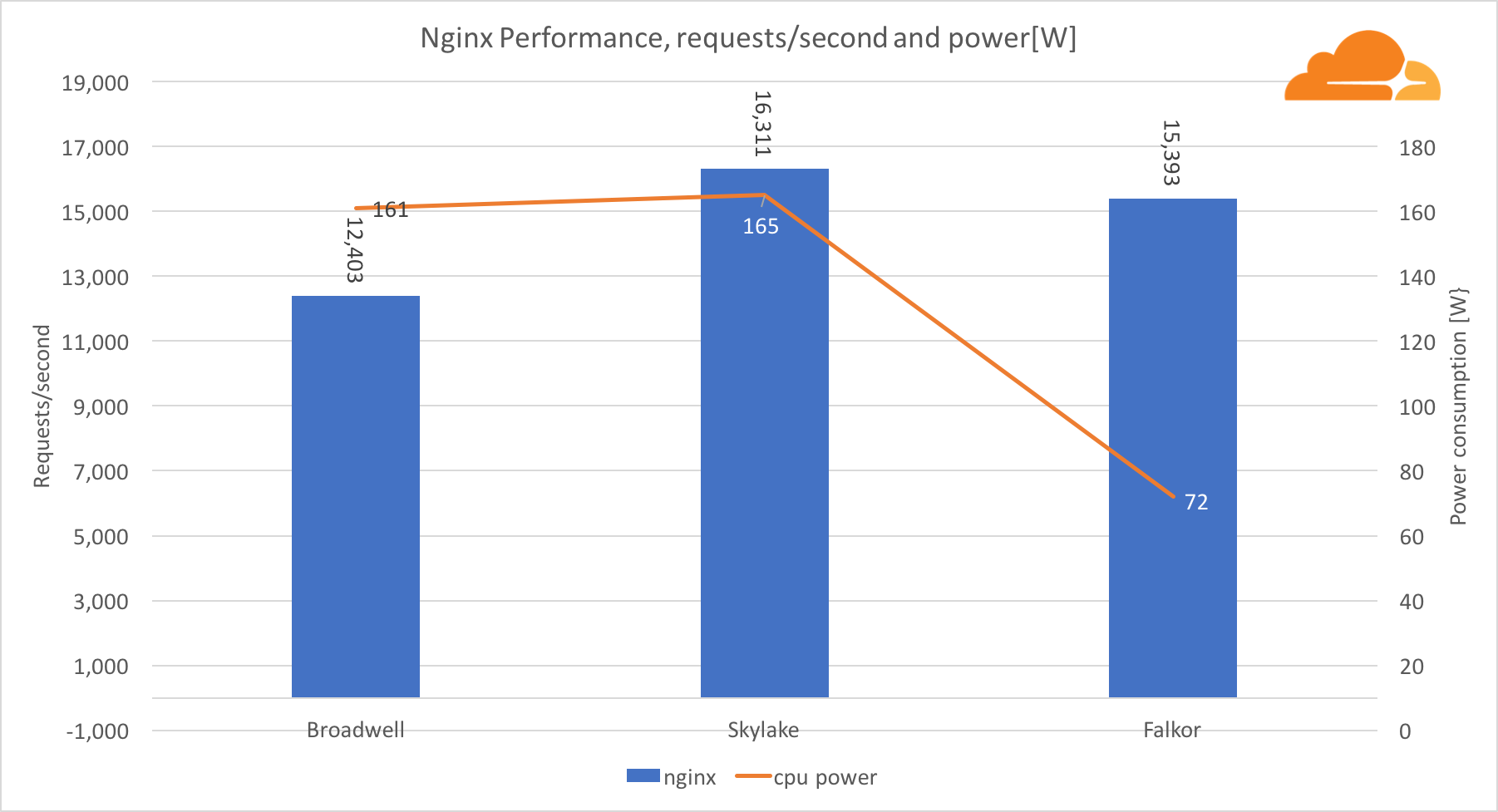
С рабочей нагрузкой NGINX Falkor обрабатывал почти то же количество запросов, что и сервер Skylake, и оба они значительно опережают Broadwell. Показания мощности, взятые из BMC, показывают, что это происходило при потреблении мощности в половину меньше, чем другие процессоры. Это означает, что Falkor удалось получить 214 запросов/Вт, Skylake — 99 запросов/Вт и Broadwell — 77 запросов/Вт.
Я был удивлен тем, что Skylake и Broadwell потребляют примерно одинаковый объем энергии, при учете того, что производятся они одинаково, а у Skylake больше ядер.
Низкое потребление энергии у Falkor не удивляет, так как процессоры от Qualcomm известны своей высокой энергоэффективностью, что позволило им занять доминирующее положение на рынке процессоров для мобильных устройств.
Заключение
Образец Falkor, который мы получили, меня действительно поразил. Это огромный шаг вперед, по сравнению с предыдущими попытками в серверах на базе ARM. Конечно сравнивая ядро с ядром, Intel Skylake значительно лучше, но если рассматривать системный уровень, производительность становится весьма привлекательной.
Производственная версия Centriq SoC будет содержать 48 Falkor ядер, работающих на частоте до 2.6 Ггц, что дает потенциальный рост производительности в 8%.
Очевидно, что тестируемый нами Skylake не является флагманом, как Platinum с его 28 ядрами, но эти 28 ядер стоят много и потребляют 200W, в то время как мы стараемся оптимизировать наши затраты и увеличить производительность на 1 ватт.
На данный момент меня больше всего беспокоит плохая производительность языка Go, но это измениться как только сервера на базе ARM займут свою нишу на рынке.
Производительность С и LuaJIT очень конкурентоспособна, и во многих случаях превосходит Skylake. Практически во всех тестах Falkor показал себя как достойная замена Broadwell.
Самым большим плюсом для Falkor на данный момент остается низкий уровень энергопотребления. Хотя TDP и составляет 120W, во время моих тестов этот показатель никогда не превышал 89W (для тестов go). Для сравнения, Skylake и Broadwell превысили отметку в 160W, тогда как их TDP составляет 170W.
На правах рекламы.Это не просто виртуальные серверы! Это VPS (KVM) с выделенными накопителями, которые могут быть не хуже выделенных серверов, а в большинстве случаев — лучше! Мы сделали VPS (KVM) c выделенными накопителями в Нидерландах и США (конфигурации от VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD или 4TB HDD / 1Gbps 10TB доступными по уникально низкой цене — от $29 / месяц, доступны варианты с RAID1 и RAID10), не упустите шанс оформить заказ на новый тип виртуального сервера, где все ресурсы принадлежат Вам, как на выделенном, а цена значительно ниже, при гораздо более производительном «железе»!
Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки? Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США!
Комментарии (56)

Atractor
10.01.2018 11:38+5Не осилил. Текст изобилует ошибками. Ощущение, что это не правленый он-лайн перевод.
justhabrauser
11.01.2018 06:21Потерпите, человеки — скайнет скоро пойдет в школу и начнет учить русика изыг очин трудни.


BogdanBorovik
10.01.2018 11:46+1Хорошая попытка. Но для того чтобы убедить перейти с Xeon`a к примеру, то Qualcomm`у нужно предоставить какую-то более убедительную информацию, чем «немного быстрее и экономичнее».
Пока что выглядит не очень, если честно. Даже на графиках (которые тоже не очень понятны, где там быстрее всех и лучше).zipo
10.01.2018 13:06Думаю для многих ДЦ весьма важный фактор энергопотребления. Т.к. это сильно увеличивает стоимость как самого ДЦ (система кондиционирования) так и обслуживание (расзоды на электрику как самого чипа так и системы кондиционирования).
Думаю тут все будет упираться в цену продукта и потом ДЦ посчитают каждый для себя, что ему выгоднее ставить.
Если производительность будет даже просто на том же уровне при той же цене, то уже за счет меньшего энергопотребления и соответственно меньшие расходы обсулживание, то уже имеет смысл.BogdanBorovik
10.01.2018 13:28Да, возможно. Но смотря какие будут расходы на переход от постоянных решений на новые.
Если реально проще и дешевле будет платить за электричество хотя бы, то никто этим заниматься не будет. И не забываем про контракты, которые предусматривают всякие вот такие вот моменты. Нельзя так просто взять и перейти к новому поставщику железа, потому что так захотелось.
Без вопросов. Когда есть выбор и новый игрок на рынке железа, это приведёт к переставновке сил и цены поползут вниз. Но для того чтобы это случилось, то что показали в прессрелизе, маловато будет для революции на таком уже устоявшемся рынке. :)zipo
10.01.2018 14:03Для революции безусловно маловато, и заголовок статьи желтоват. Qualcommу предстоит большая работа пиаром, ибо люди привыкли думать ксеонами при аренде серверов или виртуальных машин. Все упрется в цену, но конкуренция это всегда здорово.

DisM
11.01.2018 00:25Это не стиральный порошок, тут пиар не особо нужен. Нужны рабочие системы, сертифицированные, и с ясными преимуществами. Нужны люди сами все найдут, оценят и купят.


proton17
10.01.2018 11:48Сначала все о Centriq 2400, а потом лихо появляется какой-то Фалкор)
vikarti
10.01.2018 12:48+1Производственная версия Centriq SoC будет содержать 48 Falkor ядер,
— в самом конце мы узнаем что это так микроархитектура ядер(?) называется (вроде как есть Pentium 4 а есть ядра NetBurst)
Со слов про Влада Краснова начинается blog.cloudflare.com/arm-takes-wing. Причем пропущено начало поста Влада где объяснение терминов.proton17
10.01.2018 15:31Видимо надо было поставить иконку "сарказм" в своем комменте. Это пинок в сторону автора статьи, он должен был сразу пояснить что Centriq это SoC, а Falkor название архитектуры ядра. Но так как статья из разряда "давай быстро че-ть переведем не вникая и запилим пост в ГТ" то это норма)
kentaskis
10.01.2018 11:49+1А с уязвимостями-то что?

prohitec
10.01.2018 12:42На сайте ARM нет информации об уязвимости ядер Falkor и все, что нам удалось нагуглить — это одну заметку на networkworld. Автор считает, что так как процессор активно использует инструменты спекулятивного исполнения инструкций, проц почти наверняка в той или иной мере подвержен Spectre/Meltdown.

Sensimilla
10.01.2018 13:02Кольцевая внутренняя шина — признак примитивности конструкции. При числе ядер больше 4-6 необходима уже сетевая топология

beeruser
10.01.2018 22:05+1Смотрите какой 22-ядерный примитив:
www.anandtech.com/show/10158/the-intel-xeon-e5-v4-review/2
Ой, это же Интел породил. Ну тогда это гениальное произведение инженерного исскуства!
К слову задержки межядерного обмена при grid-топологии у Skylake-X выше, хотя и равномернее.
forum.ixbt.com/topic.cgi?id=8:25158:4965#4965
Sensimilla
11.01.2018 10:05на больших ксеонах уже две кольцевые шины, потом, 22 ядра — это не то же, что 48
ustas33
10.01.2018 13:54Qualcomm Centriq 2400 работает только в одиночку.
Cavium Thunderx2 можно использовать в двухпроцессорных нодах, плюс он поддерживает больше памяти.
Но как бы не приключилась та же история, как с Cavuim… Объявили год назад, внятного плана отгрузки до сих пор нет.
У нас уже почти год готовы серверы по Cavium Thunderx2:
2U 4x нодовый сервер,
1U двухпроцессорный сервер.
OpenPower9 тоже выглядит неплохо. В феврале приедет пара нод, будем тестить.
firk
10.01.2018 14:55Неужели лицензионная политика Intel довела ситуацию до того, что ARM уже всерьёз рассматривают для серверов? Или тут в другом причины? Мне вот казалось, что всё что не x86 — это либо какие-то промышленные/энтерпрайзные мейнфреймы, либо контроллеры для всяких телефонов/планшетов и прочего embedded.
vasimv
10.01.2018 16:06С разморозкой в новом веке! ARM уже давно пытается занять свое место в этой нише, пока не очень, но надеюсь у них получится. Устали уже от этого мусора 8086, который упорно тащат десятилетиями.
DmitryBabokin
10.01.2018 16:42А как там в ARM с мусором в наборе инструкций, не интересовались?

john316
11.01.2018 09:39В ARM64 очень много чего переделали, так что там «мусора» я бы сказал даже не хватает как-то.
prohitec
10.01.2018 16:54Можно поинтересоваться, почему конкретно вы считаете x86 «мусорной архитектурой», то есть, вот ваша личная практика, гипотетический полный переход на ARM — что бы парк вашей компании выиграл от него?

Goodkat
10.01.2018 21:19Минус 40% трат на электричество.
Плюс 9000% трат на замену оборудования, адаптацию существующего и написание нового софта под него, поддержку нестандартного решения.
Вот когда они все свои сервера на свои процессоры переведут, тогда и поговорим :)
prohitec
10.01.2018 22:49Вообще, в случае с Centriq нельзя забывать, что это 10-нм процессоры, а в бенчмарках они сравниваются с 14-нм зионами, которые вскоре могут быть заменены новыми моделями. Было бы странно, если бы соотношение производительности к энергоэффективности у них было бы идентичным. На сегодня 10-нм конкурентов на x86 у Centriq, конечно же, нет, но они будут. И вопрос вот в чем, когда будут представлены x86-процессоры с 10-нм техпроцессом для серверов, насколько они будут отставать от Centriq по соотношению производительности к энергоэффективности, и будут ли отставать, вообще? Сиюминутная выгода от перехода на ARM вроде как понятна при условии готовности софта. Но готов ли софт, который актуален для вашего конкретного предприятия? Идентичен ли он про производительности его версиями под x86? И сколько времени и средств уйдет на подготовку софта и инфраструктуры для перехода — не проще ли дождаться новых серверников на x86? Отсюда и остается первоначальный вопрос — «а вам оно зачем», если производительность и энергоэффективность решений на x86 и arm будут условно идентичными? И почему именно ARM, а не какая-нибудь другая не менее замечательная, прогрессивная и «не мусорная», как выразился предыдущий оратор, архитектура?
beeruser
10.01.2018 23:06У ARM нет _своих_ серверных процессоров. К тому же они чипы в принципе не выпускают.

Alexeyslav
11.01.2018 11:44x86 тянет за собой обратную совместимость со старыми процессорами, что очень мешает оптимизации такого важного параметра как производительность на ватт. Выкинуть бы оттуда кучу лишних инструкций и процессор станет быстрее, энергоэффективней и т.д. но это поломает обратную совместимость и тогда ARM-ы точно выиграют. Хотя чем тогда новый процессор будет отличаться от ARM-ов? На принципиальном уровне — ничем.
prohitec
11.01.2018 14:13То есть, вы считаете, что отключение возможности исполнения инструкций, потерявших актуальность, при исполнении современных адекватно составленных приложений, может значительно повлиять на производительность или энергоэффективность процессоров, которые уже давно исполняют x86-инструкции лишь на уровне МОДИФИЦИРУЕМОГО микрокода, а фактически преобразуют их в более простые инструкции при исполнении? Ваше предположение подкреплено каким-то исследованиями, тестами?
Alexeyslav
11.01.2018 15:05+1Одно отключение не поможет. Просто само наличие инструкций не позволяет оптимизировать работу конвеера, например. А это за собой тянет проблемы с энергоэффективностью. Когда-то давно была статья, когда ещё появились процессоры на ARM-ядре, там было достаточно интересное исследование по их энергоэффективности и сделан вывод о том что сама архитектура x86 не позволяет делать энергоэффективные процессоры из-за наличия некоторого процента малоиспользуемых команд, в которых уже нет никакой насущной необходимости но обратная совместимость не позволяет их убрать с чистой совестью.
prohitec
11.01.2018 16:36Еще раз хочу обратить ваше внимание на то, что в СОВРЕМЕННЫЕ x86 процессоры микрокод с набором инструкций x86 не вшит физически. Сложные инструкции преобразуются в более простые инструкции через конвертер микроопераций и вот уже они физически исполняются процессором, таким образом производителям x86-процессоров удалось сохранить совместимость со старыми приложениями, получив при этом набор преимуществ, характерный для RISC-процессоров, что впервые было представлено еще в Pentium Pro, и развивалось с каждым последующим поколением процессоров. Если ваша точка зрения подкреплена «давнишним», как вы выразились материалом, о противостоянии CISC и RISC образца 95 года и ранее, то данная информация устарела. Из более «современных» материалов можете загуглить заметку 2009 года — «Intel x86 Processors – CISC or RISC? Or both??». Также рекомендую тестовый материал, который доступен на сайте ARM — «The final ISA showdown: Is ARM, x86, or MIPS intrinsically more power efficient?». Если же я неправильно вас понял, пожалуйста, разверните вашу точку зрения подробнее и дайте названия статей и тестовых материалов, которые рекомендуете изучить, на которые ссылаетесь, чтобы обосновать ее.

Chamie
12.01.2018 19:18У х86 сложнее блок декодирования инструкций, неравномерная и непредсказуемая плотность их (не помню по памяти, но, вроде, инструкция вместе с аргументами занимает от 1 до 16 байт?), что затрудняет упреждающее чтение/выполнение. Кроме того, инструкций банально много, а рантайм-трансляция инструкций по умолчанию не может не занимать времени/отнимать производительности/расходовать энергию.
a5b
14.01.2018 14:55Модифицируемость микрокода обновлениями серьезно ограничена.
Есть описание AMD K8 — основной микрокод зашит в ROM, обновления попадают в небольшую RAM. Патчи микрокода могут изменить лишь 8 адресов ROM (т.е. пропатчить микрокод/"отбросить ненужные" можно только для очень ограниченного числа команд): https://www.usenix.org/system/files/conference/usenixsecurity17/sec17-koppe.pdf стр 6 Figure 1
По интелу — обновления микрокода имеют размер до 16 КБ https://www.dcddcc.com/docs/2014_paper_microcode.pdf (стр 16) и, вероятно, также являются лишь частичными патчами для ROM-микрокода.
Также следует помнить, что большинство простых операций декодируются без микрокода, аппаратными декодерами (3-4 шт), т.е. "конвертер" вшит физически. (https://www.dcddcc.com/docs/2014_paper_microcode.pdf — Simple instructions are directly decoded into a short sequence of fixed-length RISC-like operations… by hardware, whereas complex instructions are decoded by microcode ROM. Examples of the former include ADD, XOR, and JMP, while the latter include MOVS, REP, and CPUID.; http://www.agner.org/optimize/ http://www.agner.org/optimize/instruction_tables.pdf ops<=3, ?ops<=3 вероятно directly decoded аппаратурой)

worldmind
10.01.2018 19:36Где-то мелькала новость, что сервера на ARM выгоднее из-за энергоэффективности.
DaylightIsBurning
10.01.2018 20:02Всего на 45%, судя по заявлениям Qualcomm. Результаты тестов в обзоре тоже похожий результат показывают. Учитывая то, на сколько Intel и AMD продвинулись в последнее время в снижении энергопотребления, возможно отставание ещё сократится. А сложности с переходом на новый тип оборудования останутся в любом случае. Однопоточная производительность Falkor тоже не впечатляет.

DaylightIsBurning
10.01.2018 19:55Неплохо, но если сравнивать с каким-нибудь AMD EPYC 7501/7401 — выходит уже не так интересно по цене ЦПУ. Transistor count тоже близок. При этом EPYC вероятно быстрее в single-threaded.
AllexIn
10.01.2018 20:14Раз уж тут про процессоры — объясните мне пожалуйста, почему предсказение перетащили на уровень процессора вместо того, чтобы делать его на уровне компилятора и ключевых слов указывающих какой код вероятно будет исполняться чаще, а какой реже?
Ведь тогда и никакого случайного исполнения критического кода бы не было и производительность была бы выше, т.к. процессор не пытался бы угадать что исполнять тратя на это ресурсы и угадывая криво, а исполнял бы заранее заданные ветки.
Да и сложность программирования бы не выросла. Статический анализатор вполне способ понять, каокй код будет выполняться чаще и расставить соответствующие метки.
Плюс и сейчас программист пищущий важный код должен учитывать особенности работа кэша и спекулятивного исполнения, вместо того, чтобы просто указать что исполнять чаще.
gxcreator
10.01.2018 20:37То, что вы описали называется VLIW. Не взлетел, потому что пришлось долго пилить компиляторы под каждый проц + динамическое предсказание все же даёт некоторые преимущества, а статическое и так все популярные компиляторы делают (-march, вот это всё)
Cenzo
11.01.2018 01:57Вроде бы достаточно всего одного дополнительного бита в инструкции перехода? Как «if (likely(x))» в ядре линукс. Возможно как раз процессоры без legacy смогут себе такое позволить.

rogoz
11.01.2018 09:49Такое было в x86, но выпилили.
stackoverflow.com/questions/14332848/intel-x86-0x2e-0x3e-prefix-branch-prediction-actually-used?lq=1
lexore
11.01.2018 01:03Ну, если очень диванно, будь вы процессором, вы бы в какой кеш хотели бы чаще попадать?
Который подальше, или который поближе?
Gryphon88
11.01.2018 09:37Добавить manual prefetch и управление кэшем, вроде в Эльбрусе оно даже есть. Программирование станет сложнее, компиляция дольше, но теоретически программы станут шустрее.
erwins22
12.01.2018 09:400F 18 / 01 PREFETCHT0 m8 Move data from m8 closer to processor using T0 hint
0F 18 / 81 RETIRET0 m8 Mark data from m8 as evictable from T0 to T1,T2,RAM
0F 18 / 02 PREFETCHT1 m8 Move data from m8 closer to processor using T1 hint
0F 18 / 82 RETIRET1 m8 Mark data from m8 as evictable from T0,T1 to T2,RAM
0F 18 / 03 PREFETCHT1 m8 Move data from m8 closer to processor using T2 hint
0F 18 / 83 RETIRET1 m8 Mark data from m8 as evictable from T0,T1,T2 to RAM

arheops
11.01.2018 21:45Вопрос в том, насколько усложняется компилятор(а это еще ж баги) и насколько лучше он предсказывает, по сравнению с динамическим предсказанием.
Пока соотношение — не очень. Не взлетает.
Hellsy22
11.01.2018 08:55Мм… а как на счет сравнения с Xeon Phi и его 72 ядрами? Да, там 14нм, но все же интересно…
huankun
Бессмыслица какая-то.
Кроме того, на графиках интеловские процессоры сравниваются в неким Falkor. Какое он имеет отношение к рассматриваемому Qualcomm Centriq 2400 вообще не понятно.
prohitec
Falkor — микроархитектура ядер CPU, Centriq — название процессора. Аналогично у Intel — Skylake и Xeon или у AMD Zen и EPYC.
zipo
Перейдите по ссылке на оригинал статьи там есть таблица характеристик сравниваемых процессоров, почти в самом вверху.
blog.cloudflare.com/arm-takes-wing
Centriq это название процессора — Falkor это архитектура или название версии. Так же как и Skylake у интела. Автор почему-то про это не написал. Тоесть Falkor на графиках это и есть Centriq.
Chamie
Да там вообще выглядит, как будто обрывки 2 статей случайно склеили: