В этот раз я хочу поделиться с вами одной проблемой, с которой столкнулся, когда решил сравнить итерационные и рекурсивные функции в C++. Между рекурсией и итерацией есть несколько отличий: о них подробно рассказано в этой стать. В языках общего назначения вроде Java, C или Python рекурсия довольно затратна по сравнению с итерацией из-за необходимости каждый раз выделять новый стековый фрэйм. В C/C++ эти затраты можно легко устранить, указав оптимизирующему компилятору использовать хвостовую рекурсию, при которой определенные типы рекурсии (а точнее, определенные виды хвостовых вызовов) преобразуются в команды безусловного перехода. Для осуществления такого преобразования необходимо, чтобы самым последним действием функции перед возвратом значения был вызов еще одной функции (в данном случае себя самой). При таком сценарии безусловный переход к началу второй подпрограммы безопасен. Главный недостаток рекурсивных алгоритмов в императивных языках заключается в том, что в них не всегда возможно иметь хвостовые вызовы, т.е. выделение места для адреса функции (и связанных с ней переменных, например, структур) на стеке при каждом вызове. При слишком большой глубине рекурсии это может привести к переполнению стека из-за ограничения на его максимальный размер, который обычно на порядки меньше объема оперативной памяти.
В качестве теста для изучения хвостовой рекурсии я написал в Visual Studio простую функцию Фибоначчи на C++. Давайте посмотрим, как она работает:
Чтобы перед возвратом значения получился хвостовой вызов, функция fib_tail в качестве последнего действия вызывает саму себя. Давайте теперь взглянем на сгенерированный ассемблерный код. Для этого я скомпилировал программу в релиз-режиме с использованием ключа оптимизации /O2. Вот как выглядит этот код:
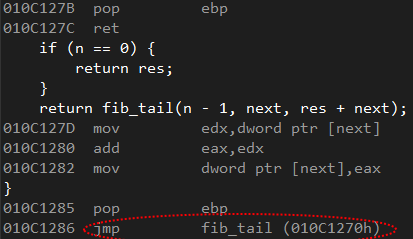
Есть! Обратите внимание на последнюю строку: в ней вместо инструкции CALL используется JMP. В данном случае хвостовая рекурсия сработала, и у нашей функции не возникнет никаких проблем с переполнением стека, поскольку на уровне ассемблера она превратилась в итерационную функцию.
Этого мне было мало, и я решил поэкспериментировать с производительностью, увеличив входную переменную n. Затем я изменил тип переменных, используемых в функции, с int на unsigned long long. Запустив программу повторно, я внезапно получил переполнение стека! Вот как выглядит этот вариант нашей функции:
Давайте снова взглянем на сгенерированный ассемблерный код:
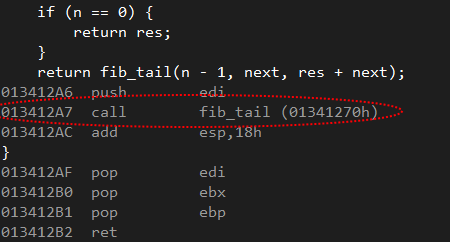
Как я и ожидал, хвостовой рекурсии тут не оказалось! Теперь вместо ожидаемой JMP используется CALL. Между тем, единственное различие между двумя вариантами нашей функции заключается в том, что во втором случае я использовал 64-битную переменную вместо 32-битной. В связи с чем возникает вопрос: почему компилятор не задействует хвостовую рекурсию при использовании 64-битных переменных?
Я решил скомпилировать программу в 64-битном режиме и посмотреть, как она себя поведет. Сгенерированный ассемблерный код:
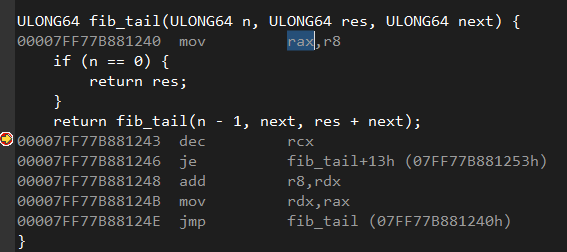
Здесь хвостовая рекурсия снова появилась! Благодаря 64-битным регистрам (rax, r8, rcx, rdx) вызывающая и вызываемая функции имеют общий стек, а вызываемая функция возвращает результат непосредственно в точку вызова внутри вызывающей функции.
Я задал свой вопрос на сайте StackOverflow – похоже, что проблема в самом компиляторе Microsoft C++. Автор одного из комментариев сообщил, что в остальных C++-компиляторах эта проблема не наблюдается, но я должен убедиться в этом сам.
Я выложил пример кода на GitHub – можете скопировать его и попробовать запустить у себя. На Reddit и Stackoverflow мне также сказали, что в издании VS2013 Community Edition описанная проблема не возникает. Я попробовал поработать в VS2013 Ultimate, но столкнулся с ней и там. В течение ближайших дней попробую потестировать код под GCC и сравню результаты.
См. проект Example на GitHub.
Надеюсь, что мое расследование окажется полезным и для вас, если вам вдруг тоже доведется разбираться, почему в определенных случаях компилятор не реализует хвостовую рекурсию.
До скорой встречи!
Продолжение: habrahabr.ru/company/pvs-studio/blog/261029
В качестве теста для изучения хвостовой рекурсии я написал в Visual Studio простую функцию Фибоначчи на C++. Давайте посмотрим, как она работает:
int fib_tail(int n, int res, int next)
{
if (n == 0)
{
return res;
}
return fib_tail(n - 1, next, res + next);
}Чтобы перед возвратом значения получился хвостовой вызов, функция fib_tail в качестве последнего действия вызывает саму себя. Давайте теперь взглянем на сгенерированный ассемблерный код. Для этого я скомпилировал программу в релиз-режиме с использованием ключа оптимизации /O2. Вот как выглядит этот код:
Есть! Обратите внимание на последнюю строку: в ней вместо инструкции CALL используется JMP. В данном случае хвостовая рекурсия сработала, и у нашей функции не возникнет никаких проблем с переполнением стека, поскольку на уровне ассемблера она превратилась в итерационную функцию.
Этого мне было мало, и я решил поэкспериментировать с производительностью, увеличив входную переменную n. Затем я изменил тип переменных, используемых в функции, с int на unsigned long long. Запустив программу повторно, я внезапно получил переполнение стека! Вот как выглядит этот вариант нашей функции:
typedef unsigned long long ULONG64;
ULONG64 fib_tail(ULONG64 n, ULONG64 res, ULONG64 next)
{
if (n == 0)
{
return res;
}
return fib_tail(n - 1, next, res + next);
}Давайте снова взглянем на сгенерированный ассемблерный код:
Как я и ожидал, хвостовой рекурсии тут не оказалось! Теперь вместо ожидаемой JMP используется CALL. Между тем, единственное различие между двумя вариантами нашей функции заключается в том, что во втором случае я использовал 64-битную переменную вместо 32-битной. В связи с чем возникает вопрос: почему компилятор не задействует хвостовую рекурсию при использовании 64-битных переменных?
Я решил скомпилировать программу в 64-битном режиме и посмотреть, как она себя поведет. Сгенерированный ассемблерный код:
Здесь хвостовая рекурсия снова появилась! Благодаря 64-битным регистрам (rax, r8, rcx, rdx) вызывающая и вызываемая функции имеют общий стек, а вызываемая функция возвращает результат непосредственно в точку вызова внутри вызывающей функции.
Я задал свой вопрос на сайте StackOverflow – похоже, что проблема в самом компиляторе Microsoft C++. Автор одного из комментариев сообщил, что в остальных C++-компиляторах эта проблема не наблюдается, но я должен убедиться в этом сам.
Я выложил пример кода на GitHub – можете скопировать его и попробовать запустить у себя. На Reddit и Stackoverflow мне также сказали, что в издании VS2013 Community Edition описанная проблема не возникает. Я попробовал поработать в VS2013 Ultimate, но столкнулся с ней и там. В течение ближайших дней попробую потестировать код под GCC и сравню результаты.
См. проект Example на GitHub.
Надеюсь, что мое расследование окажется полезным и для вас, если вам вдруг тоже доведется разбираться, почему в определенных случаях компилятор не реализует хвостовую рекурсию.
До скорой встречи!
Продолжение: habrahabr.ru/company/pvs-studio/blog/261029
Комментарии (4)

dyadyaSerezha
24.06.2015 14:42+11. «выделение адреса функции (и связанных с ней переменных, например, структур) на стеке при каждом вызове» — корявый перевод. Не выделение, а размещение. Или выделение места для. Пока не прочитал оригинал, не мог понять, о чем речь.
Оригинал: www.viva64.com/en/b/0332
2. «не всегда возможна реализация хвостовых вызовов» — не всегда возможно иметь хвостовые вызовы. Слово «реализация» только запутывает и отсылает куда--то к особенностям компилятора.
Andrey2008 Автор
24.06.2015 15:02Согласен. Спасибо. Прошу отписывать про неточности личными сообщениями.
potan
Я эксперементировал с TCO (хвостовые вызовы, а не просто рекурсия) в чистом gcc.
Мне удалось заставить его оптимизировать вызов функции по указателю с передачей параметров через стек и непосредственный вызов с передачей через регистры. Но вызов по указателю с передачей в регистрах не получилось. Почему так и не разобрался.
Писал небольшой интерпретатор байт-кода, в котором каждая команда была функцией на C, а состояние жило в аргументах.