Зачем это нужно программистам? Ведь электронике учат на (гораздо менее массовых) факультетах электроники, где студент сначала изучает физику электричества, аналоговые схемы, делает пару лаб с мультиплексорами, после чего все это забывает и идет работать программистом.
Одна из причин, зачем цифровая схемотехника программисту — в последнее время происходит бум нейросетей. Если вы хотите чтобы обучение сложной сети занимало не недели / дни / часы, а часы / минуты / секунды, без аппаратных ускорителей не обойтись. Только специализированный хардвер выполнит параллельно большое количество умножений малой точности с одновременными транзакциями к океану памяти. В будущем нас ждут специализированные ASIC (application-specific integrated circuits) для AI, причем повсюду. В них будет как традиционный процессор, так и большие AI блоки на борту, с возможностью частичной реконфигурации.
От Гугла и Микрософта до Сколково и Иннополиса растет понимание, что нужны специалисты, которые могут строить такие сопроцессоры. Они должны владеть хардверной микроархитектурой, одновременно с пониманием софтверной экосистемы и алгоритмов. А владение микроархитектурой стоит на понимании уровня регистровых передач. Как это реализуется сейчас в Иннополисе:

Курс компьютерной архитектуры в Иннополисе разрабатывает его ректор Александр Тормасов, вместе с приглашенными им в Казань иностранными специалистами: итальянским профессором Giancarlo Succi, который работает в Иннополисе деканом, и Muhammad Fahim, который до Иннополиса работал в университетах Южной Кореи и Пакистана.
Сам ректор Тормасов до Иннополиса работал завкфедрой информатики МФТИ и возглавлял отдел перспективных разработок SWsoft (позже Parallels), где занимался виртуализацией. Paralells является одной из немногих российских компаний, широко известных в Америке — как минимум пара американских инженеров были удивлены, когда я сказал им, что Parallels является российской компанией, они думали что это американская компания. Кроме этого Тормасов возглавляет российское отделение IEEE Computer Society.
Тормасов любил вводить всякие новомодные штучки еще 30 лет назад — тогда он обучал студентов МФТИ использовать Unix, shell, awk итд. Линукса тогда еще не было, а Unix был на австралийских компьютерах Labtam с процессором National Semicondustor NS32000. До Тормасова студенты работали на БЭСМ-6 с Фортраном и перфокартами.
Итак, недавно Тормасов попросил меня прочитать по скайпу пару лекций про HDL, RTL и FPGA для его курса компьютерной архитектуры. На эти лекции у него ходит более 200 студентов, так что у эксперимента неплохая выборка. Лекции Тормасов попросил прочитать на английском, по-видимому потому что 1) в Иннополисе есть иностранные студенты 2) Giancarlo Succi и Muhammad Fahim тоже читают на английском и 3) студентам нужно тренировать comprehension, в том числе на мой тяжелый украинский акцент.
Целью первой лекции было дать студентам достаточно информации, чтобы они могли симулировать простейшую схему на программном симуляторе, а также синтезировать эту схему и сконфигурировать ею ПЛИС. Также нужно было наглядно показать, что схема — это не программа:
Слайды первой лекции в формате PDF.
Целью второй лекции было дать обзор того, что их ожидает, если они захотят копать тему цифровой логики глубже. Им нужно понять концепцию D-триггера, последовательностной логики, конечного автомата и конвейера. Тогда они смогут делать интересные схемы, которые повторяют действия, передают информацию с датчиков и т.д. — вплоть до процессорных ядер и дальше.
Слайды второй лекции в формате PDF.
Несколько ключевых слайдов. Разница между схемами и программами. Языки программирования (например Си) компилируются в цепочки инструкция, которые процессор выбирает з памяти. Языки описания аппаратуры (например Verilog) синтезируется в граф из логических элементов, которые в конечном итоге превращаются в транзисторы и дорожки на микросхеме, которая выпекается на фабрике:
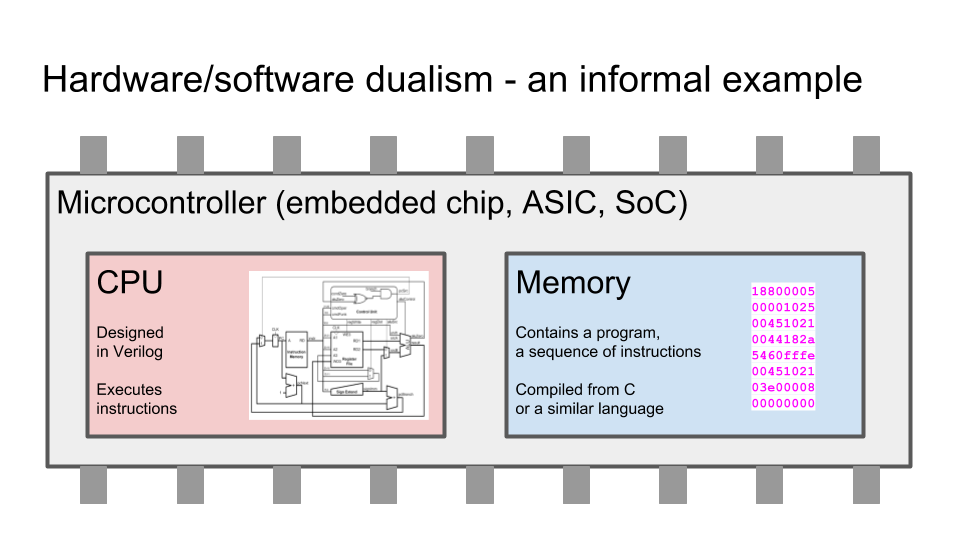
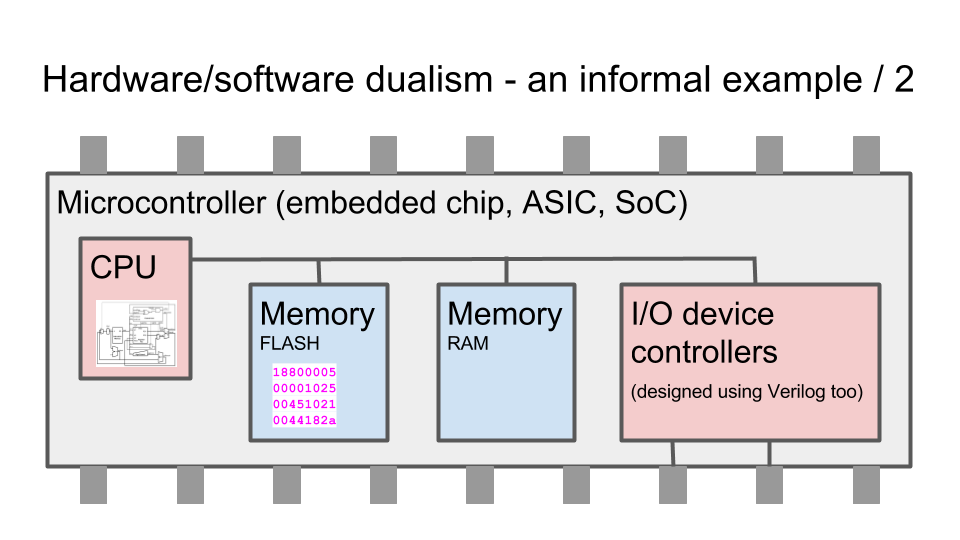
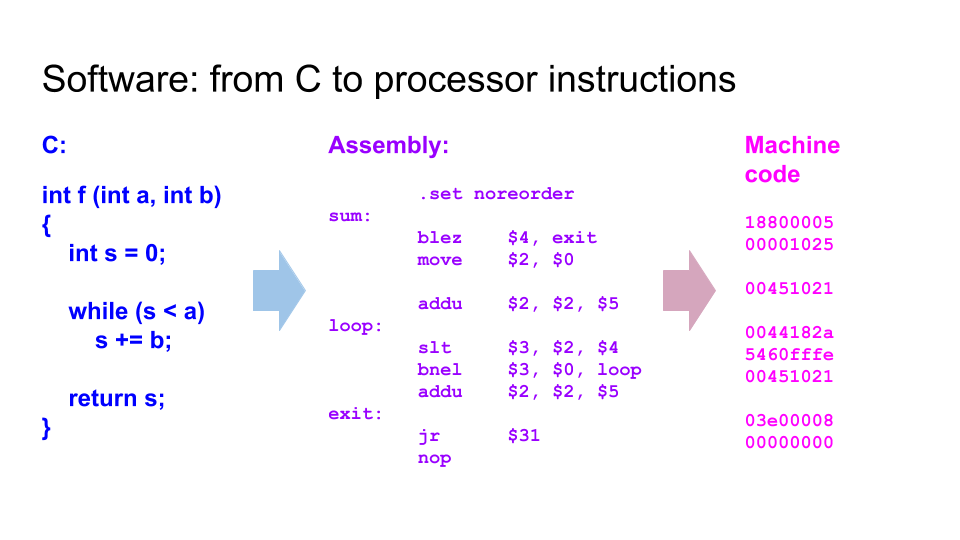
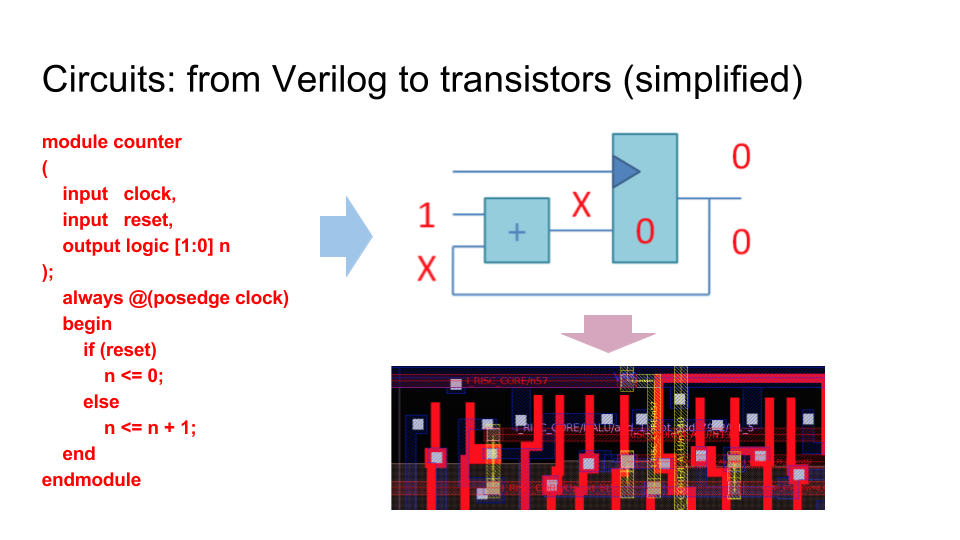
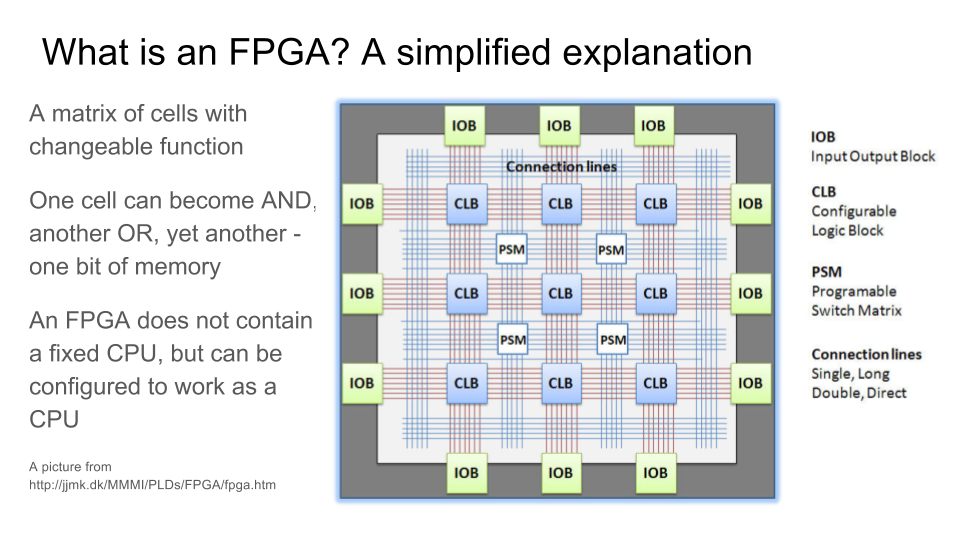
Как работает ПЛИС / FPGA — матрица из логических элементов, функцию которых можно менять с помощью мультиплексоров, подсоединенных к битам конфигурационной памяти:
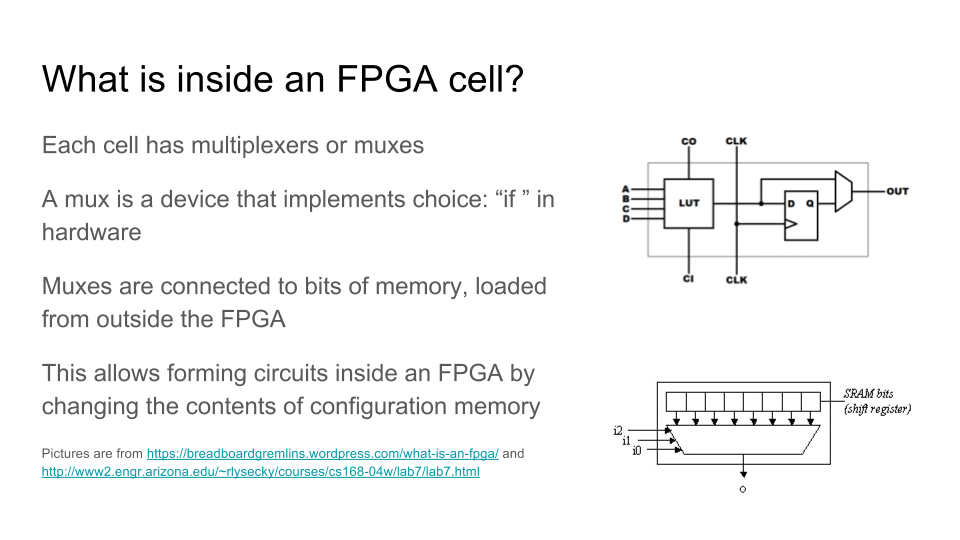
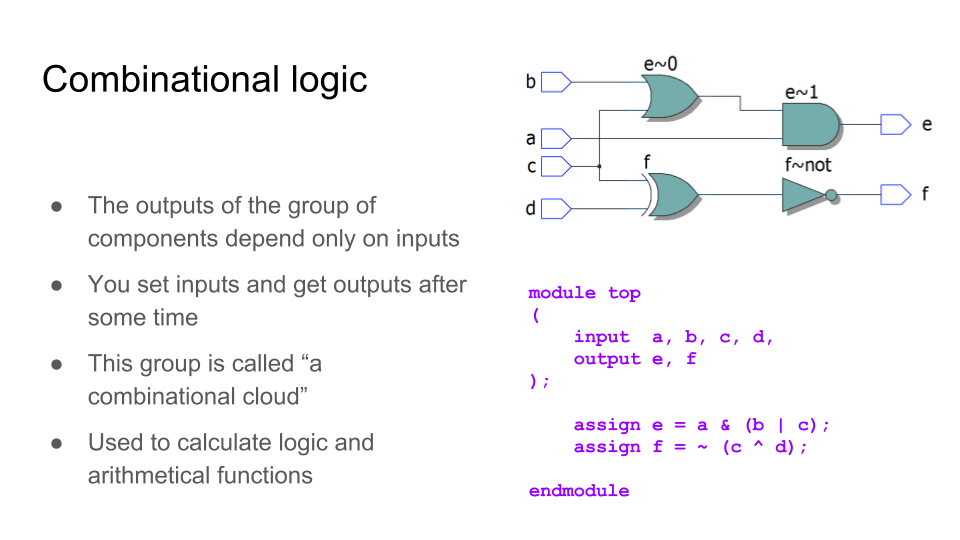
Простейшая схема. Комбинационная логика — кладем на вход некие данные, через некоторое время (с задержкой распространения) получаем на выходе ответ.
Модель Хаффмана — удобна для введения последовательностной логики. Комбинационная логика соединяется с регистрами — запоминающими элементами.
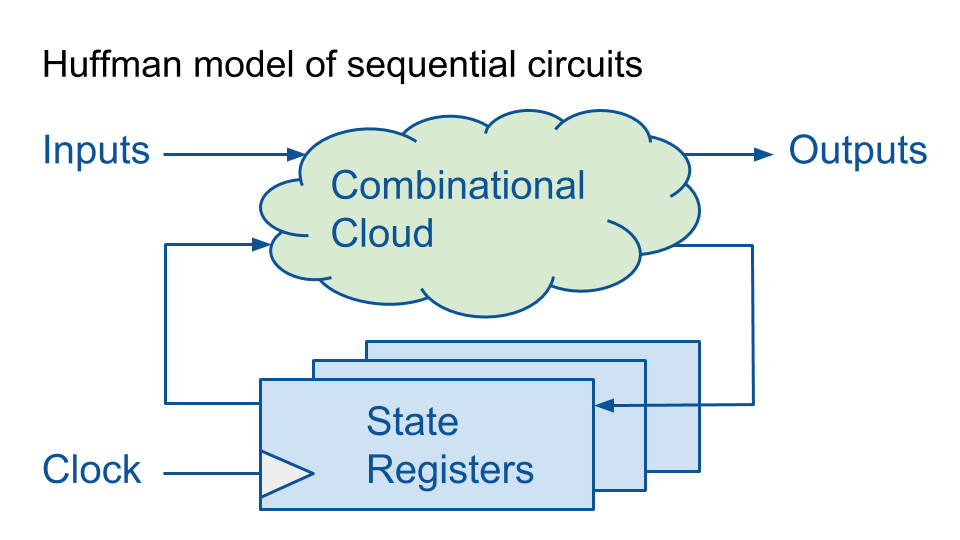
Последовательностная логика позволяет вычислительным устройствам делать нетривиальные вещи. Без нее, только на комбинационной логике, мы могли бы только вычислять таблицы функций, значения которых однозначно определяются из аргументами. Последовательностная логика добавляет к схеме текущее состояние, в результате чего мы может считать, ожидать события, повторять операции на основе старых и новых данных и т.д. Здесь я ссылаюсь на «китайскую комнату» — популярный парадокс, который всплывает при обсуждении темы «может ли машина мыслить?» Китайская комната — это по-сути одна из реализаций модели Хаффмана, обобщения конечного автомата:
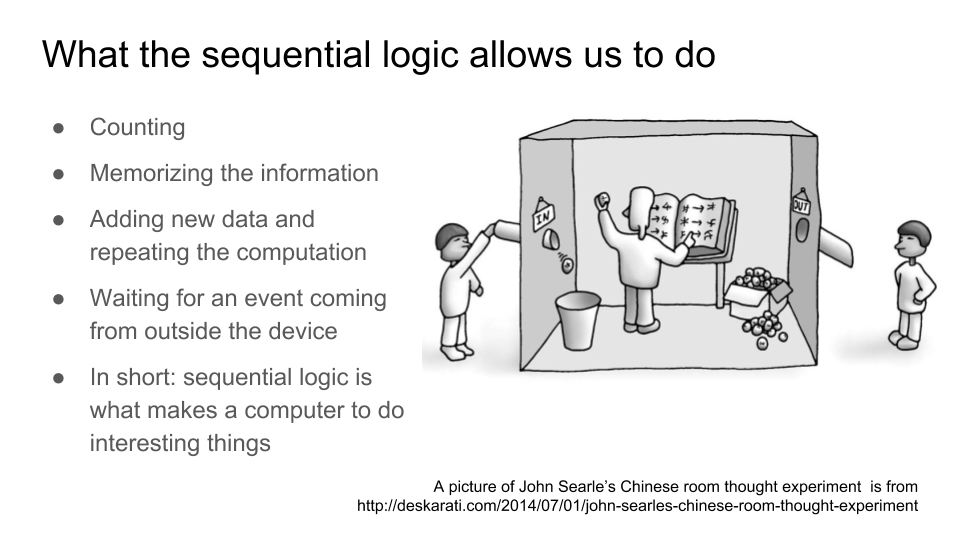
Главная концепция, которую нужно понять в вводном курсе цифровой схемотехники — это функция D-триггера, базового элемента состояния. Если логические элементы И-ИЛИ-НЕ можно в принципе объяснить даже детям в детском саду, то с D-триггерами у школьников есть ментальный барьер. И не только у школьников, но и у программистов с опытом, которым мешает понять цифровую логику намертво вросшая в их мозг ментальная модель выполнения программ как цепочек инструкций. Вместо этого нужно использовать ментальную модель, в которой много событий просходит одновременно, например одновременная запись в тысячи или миллионы D-триггеров.
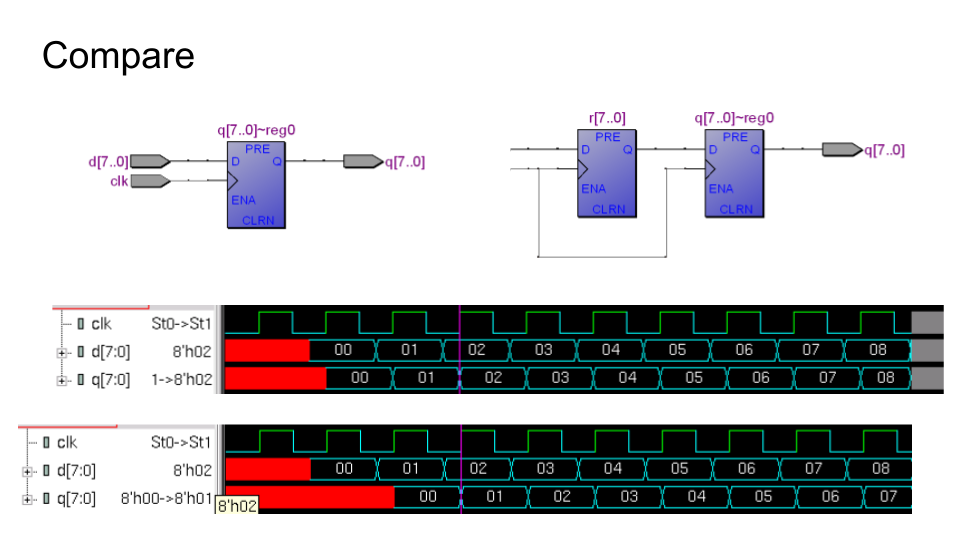
D-триггер — это устройство, которое хранит 1 бит информации в течение одного цикла тактового сигнала. У него есть три главных внешних сигнала — тактовый сигнал (clock, CLK), вход для записи (D) и выход для чтения (Q). На выходе Q выводится хранимое состояние D-триггера, а вход D в течении практически всего цикла D-триггер игнорирует. Вход D записывается в текущее состояние в течение короткого мига апертуры (aperture), когда синхронизирующий тактовый сигнал CLK меняется из нуля в единицу. К моменту апертуры, при правильно выбранной частоте тактового сигнала, на входе D-триггера находится устаканившийся результат вычислений комбинационной логики. А до этого момента на входе может находится всякий мусор, так как вычисления в аппаратуре не происходят мгновенно.
Из D-триггеров строятся регистры, хранилища для наборов в нескольких бит. На выходе регистра целый цикл находится значение, записанное в него в предыдущем цикле. Если поставить регистры один за другим, на выводе из этой комбинации будет значение из пред-предыдущего цикла:
Если соединить комбинационный сумматор и регистр, то получится счетчик. На этой анимации X означает «неустаканившееся значение». Частота тактового сигнала подобрана так, чтобы запись в регистр происходила тогда, когда сложение с единицей гарантированно закончилось, и нужно записать сумму в регистр. Эта сумма будет использована как одно из слагаемых в следующем цикле:
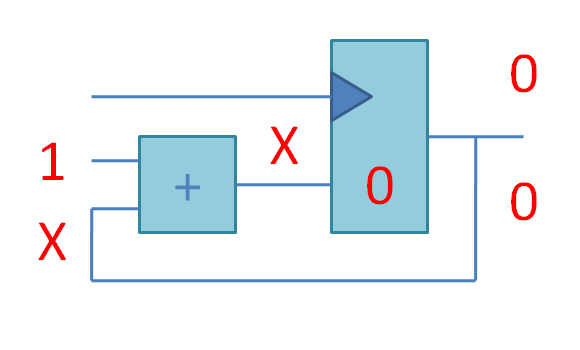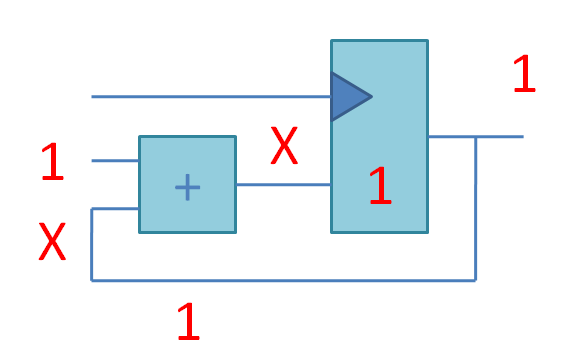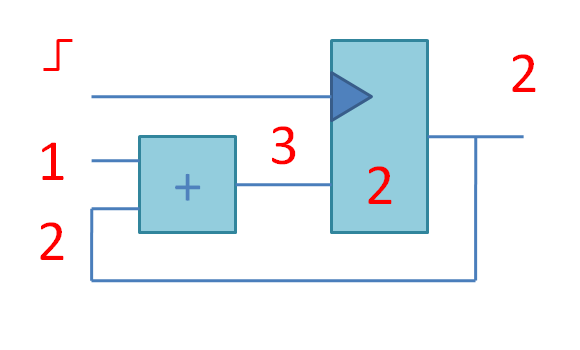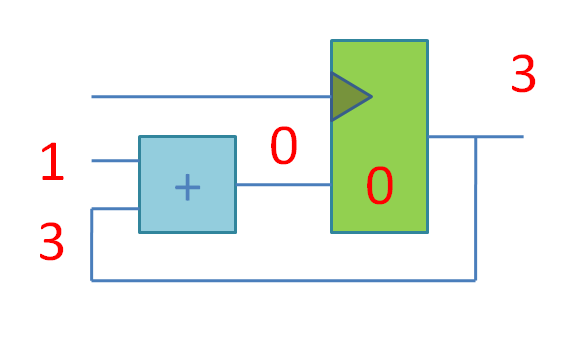
Потом идут слайды про конечные автоматы, которые я сделал на основе книжки Цифровая схемотехника и архитектура компьютера. Дэвид М. Харрис, Сара Л. Харрис. А затем несколько слайдов про принцип конвейерной обработки.
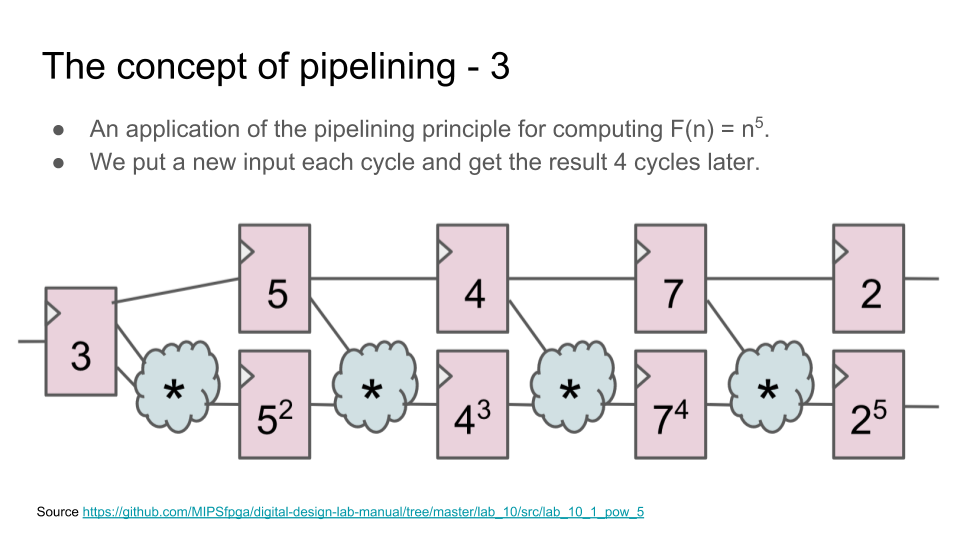
Конвейер — это одна из ключевых концепций современной разработки цифровой электроники. Конвейер возникает не только в дизайне процессора (execution pipe), но и в чем угодно: в дизайне арифметического блока, в блоке для транзакций к памяти, в обработке пакетов внутри роутерного чипа, и в шейдерах для трехмерной графики. Проще всего объяснить базовую идею конвейера на примере арифметического блока, например блока для возведения в степень.
Возмем какую-нибудь операцию, которую можно разделить на несколько последовательных шагов. Теперь вместо того, чтобы выполнять все шаги за один цикл, поставим между шагами регистры. Хотя теперь операция выполняется не за один цикл, а за несколько, но:
1) схема может работать на более высокой тактовой частоте;
2) при этом операнды для нового вычисления можно подавать на вход сразу после первого цикла предыдущего вычисления, не дожидаясь окончания всех циклов предыдущего вычисления;
3) поэтому общая пропускная способность блока будет выше, чем у блока, в котором вычисления выполняются за один цикл:
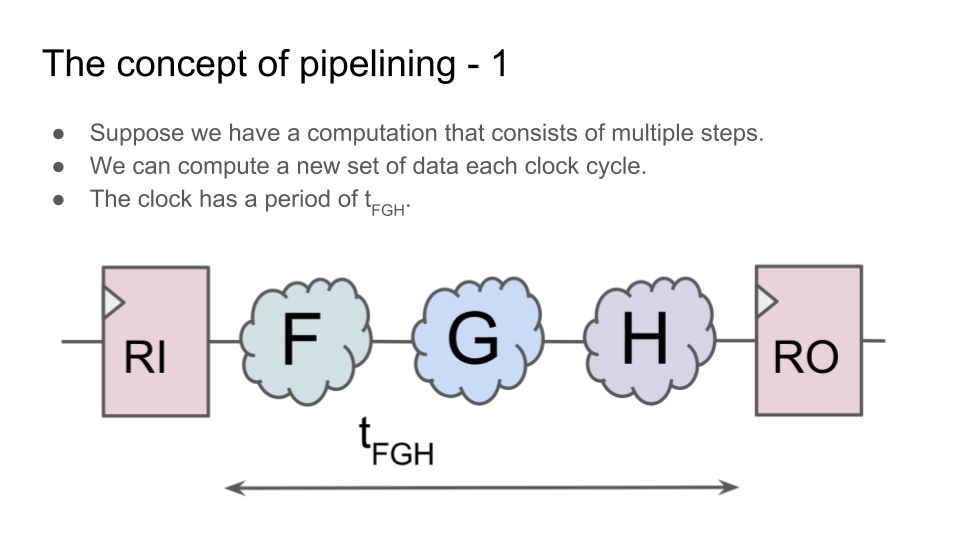
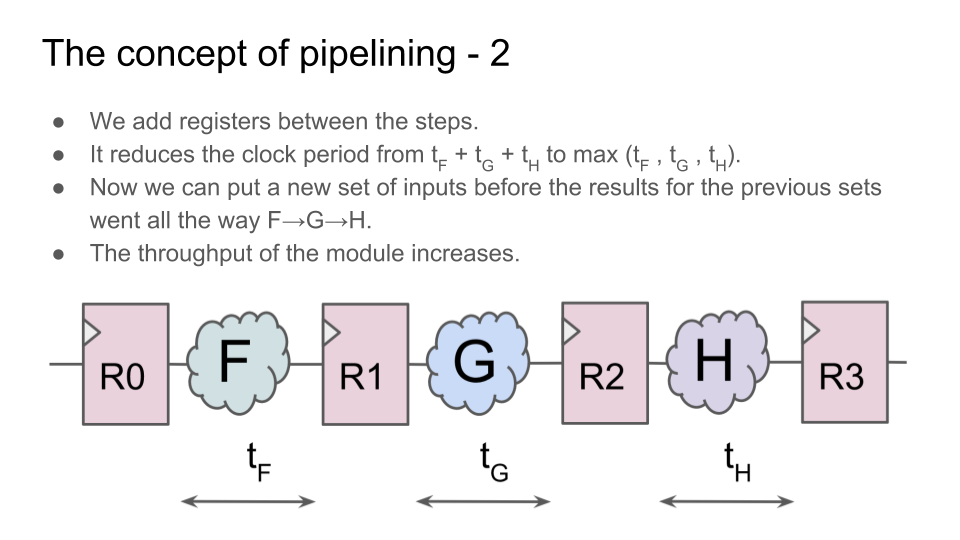
Видео второй лекции:
Теперь о платах для лабораторных работ. Так как курс только ввели в порядке эксперимента, бюджета на FPGA платы в Иннополисе не выделили. Я одолжил Иннополису 10 плат, которые я купил на свои деньги, но плат катастрофически не хватает (на курсе 210 студентов). «Дайте больше плат!» — самый частый отзыв студентов на лабы с FPGA.
В принципе, преподавателям раздает платы Intel / Altera, реже Xilinx, но в небольшом количестве. Университеты покупают платы у Xilinx и Altera и на свои деньги, но довольно часто это связано с бюрократией и волокитой. Киевский Политехнический Институт в лице Евгения Короткого недавно купил FPGA платы на грант от киевского муниципалитета, для обучения FPGA школьников. Зеленоградское предприятие Элвис-НеоТек, московская компания НауТех, питерский Макро Груп и калифорнийский MIPS выделяли FPGA платы университетам для образовательных нужд (МГУ, МИЭТ, ИТМО, МЭИ, КПИ, и другие). Но для того, чтобы обновить все программы в центральных и региональных университетах и сделать понимание RTL частью общего образования в хайтеке (как это сделано в американских вузах и как это быстро делают китайцы в КНР), нужно на два порядка больше плат. Это с одной стороны проблема, но с другой стороны — возможность региональным компаниям и частным лицам занятся благотворительностью по отношению к своим местным университетам и физматшколам. Массовое владение этими технологиями может иметь далеко идущие последствия для России и других стран региона — примерно как введение информатики в советских школах в 1985 году привело к Яндексам и другим развитым российским софтверным компаниям в 21 веке.
Для базовых упражнений в разработке цифровой логики на уровне регистровых передач подходят практически любые платы (Xilinx, Altera, Lattice и т.д.) В Иннополисе мы сейчас используем плату Terasic DE10-Lite. Она недорогая и годится даже для синтеза небольших промышленных процессорных ядер (если вам хочется с этим поэкспериментировать — это следущий уровень):

Но если закупать платы сотнями в условиях нехватки денег, то одно из решений — брать платы с али экспресс с не самыми последними FPGA. Правда для некоторых из них прийдется использовать и не самую свежую версию софтвера для синтеза, но по большому счету это неважно. Также на них не самые удобные переключатели и их мало, но зато стоят в районе двадцати долларов (тысячи рублей). К платам c Intel / Altera FPGA нужен адаптер USB Blaster, и его лучше покупать отдельно — некоторые USB Blaster на AliExpress работают с последним софтвером Intel Quartus, версии 17.1, но другие совместимы только с версией 13.0sp1 2013 года.

Еще дешевле — покупать FPGA платы без периферийных устройств. Это может быть интересным для руководителей кружков школьников, особенно если у них есть завалы всяких сенсоров, дальномерок, светодиодных матриц, динамиков и других устройств, которые можно подключить к FPGA плате и сделать на ней привлекательные проекты. Для школьников может быть интересно сделать один и тот же проект сначала с микросхемами малой степени интеграции, потом с ПЛИС, потом с микроконтроллером.

Наконец, помимо Terasic, Digilent и других азиатских, американских и европейских производителей плат есть и российские: Марсоход и завод по изготовлению ПЛИС в Воронеже. На сайте Марсохода есть неплохие инструкции для образовательных проектов. Они могут развиться в один из центров российского коммьюнити в этой области. ПЛИС-ы из Воронежа дорогие, но если воронежский завод будет их раздавать университетам, то на них тоже можно делать все эти упражнения.

Комментарии (73)
ukt
22.02.2018 21:56От Гугла и Микрософта до Сколково и Иннополиса растет понимание, что нужны специалисты, которые могут строить такие сопроцессоры.
На сайте hh, вакансии:
fpga — 82 штуки, от 60 т.р. до 115 т.р.
java — 1982 штуки, от 80 т.р. до 185 т.р.
YuriPanchul Автор
22.02.2018 23:27Это вопрос курицы и яйца. Вы посмотрите на вакансии в Санта-Кларе в Intel, NVidia, в Apple в Купертино и т.д.

AntiLL
22.02.2018 23:38Все равно в том же вебе вакансий будет больше. Другое дело, что хороший спец везде ценится.
YuriPanchul Автор
23.02.2018 00:51Одним людям интересно одно, другим людям — другое. Если все поля засеять кукурузой, то вакансий комбайнеров будет больше, чем вакансий животноводов, а если построить везде свинофермы — то наоборот.

olartamonov
23.02.2018 11:30«Менеджер по продажам» — 11 524 штуки, до 300 т.р.
Я правильно понимаю, что, согласно вашей логике, из этого следует, что программировать на яве учить тоже не надо?Falstaff
24.02.2018 13:03Мне просто любопытно стало — ukt просто цифры привёл, как вы его мысли прочитали и вывели, что его логика именно про зарплату а не, к примеру, про количество вакансий? Или про комбинацию того и другого? :)
Falstaff
24.02.2018 13:09Но неважно. Вообще же — да, логика такая, что (увы) в продажники идти ещё перспективнее. Жизнь такая. Если же сужать и искать именно вакансии разработчика (что скорее всего и имелось в виду), то Java всё ещё выигрывает, и руководствоваться одним только "растущим пониманием" всё ещё преждевременно. Скорее уж надо чтобы просто нравилось в FPGA разбираться.
olartamonov
24.02.2018 13:44и руководствоваться одним только «растущим пониманием» всё ещё преждевременно
Руководствоваться для чего?
Для получения конкретных трудовых навыков, необходимых для устройства на работу в краткосрочной перспективе? В посте идёт речь о вузовском образовании, а вузовское образование не даёт и не должно давать таких навыков, его задача — не организация быстрого трудоустройства, вузы вообще на краткосрочную перспективу не работают по определению.
Трудовые навыки даёт ПТУ, а в наше время — ещё и многочисленные курсы. Если вам надо быстренько трудоустроиться, то тратить на это пять лет обучения в вузе — глубоко бессмысленная идея, вон у меня фейсбук по пять раз в день рекламу трёхмесячных курсов по питону показывает.Falstaff
24.02.2018 15:43Ну вот тренд навскидку — зарплата эмбеддера в UK в последние шесть-семь лет практически не менялась. Понятно что рынок меняется, но он не настолько быстро меняется. Я не могу сказать за ukt, но я просто считаю, что надо полегче с "растущим пониманием", потому что уж очень маркетингово смотрится. В реальности же через пять лет выпускник придёт на более или менее тот же рынок (да, если не случится уж очень большого прорыва), а когда он спросит, но как жe так, был же тренд на нейросети, ему ответят — да, есть такой, гугл нанимал двадцать человек спроектировать им TPU, теперь он в смартфонах стоит, все под него программируют. Теперь эти двадцать человек проектируют следующую версию (чтобы конкурировать с другими двадцатью из MS и ещё двадцатью из Qualcomm), и больше рынку специалистов не надо.
Я не против того чтобы народ шёл туда учиться, ей-ей. Но если судить по нынешней ситуации, то, если они туда пойдут за обещанным длинным рублём а не потому что им интересно, то они рискуют через пять лет разочароваться в выборе. Поэтому я за то, чтобы поменьше "ого-го, смотрите как нейросети бойко пошли, поступайте к нам, выпуститесь как раз когда вас с руками отрывать будут" и побольше "поступайте к нам, у нас клёво и необычно и мы делаем интересные штуки".
olartamonov
24.02.2018 16:07+1Ещё раз: если вам надо получить рабочую специальность, по которой вы можете быстро трудоустроиться на пристойную зарплату, для вас есть масса прекрасных курсов длительностью от 3 до 6 месяцев.
Делать с этим желанием 4-6 лет в вузе вам абсолютно нечего.
Задача вуза — дать студентам актуальную и максимально полную информацию об определённой области знаний, а заодно привить способности к самостоятельному поиску и анализу информации, самостоятельной работе и т.п.
Так вот, тема «программирование FPGA» представляет собой вполне конкретный, специфический и актуальный подраздел информатики. Поэтому без программирования FPGA вузовская программа будет неполной.
Поэтому у вас оба посыла неправильные. Университет — это не «вас оторвут с руками», но и не «мы тут всякие клёвые штуки делаем». Хотя оба слогана используются в рекламе университетов по всему миру, на самом деле высшее образование — не про это. Высшее образование — это «после нас вы будете понимать, как устроен этот кусок мира».
Сможете ли вы этим пониманием воспользоваться, чтобы научиться делать что-то, за что деньги платят — это уже ваша проблема.
P.S. Примеряю это прекрасную дискуссию на себя и хохочу, представляя, как бы выглядела ситуация, в которой мне в вузе дисциплины бы убирали или добавляли исходя из их востребованности на рынке труда. «В свете текущей ситуации с трудоустройством квантовая хромодинамика заменена на физику твёрдого тела».Falstaff
24.02.2018 16:21В таком случае ukt совершенно прав, когда возразил на
От Гугла и Микрософта до Сколково и Иннополиса растет понимание, что нужны специалисты, которые могут строить такие сопроцессоры.
— поскольку реклама, не имеющая отношения к функциям ВУЗа. И ответ на ваше "программировать на яве учить тоже не надо?" вы опять же дали сами — нет, не надо, а надо прививать способности и всё такое прочее. (И да, кто сказал, что вузовская программа неполна без FPGA? Казанская программа — это эксперимент, статья об этом прямо и говорит. А без лиспа полна? А без схемотехники?)
olartamonov
24.02.2018 16:39И да, кто сказал, что вузовская программа неполна без FPGA
Чтобы обосновать полноту вузовской программы без FPGA, вам надо сделать одно из двух:
1) обосновать, что специфика «аппаратных языков» является неактуальной в современном мире и потому может рассматриваться только в контексте истории дисциплины
либо
2) указать, как именно студентам может быть продемонстрирована специфика «аппаратных языков» без использования в курсе FPGAFalstaff
24.02.2018 17:17Ну, это вы утверждаете, что неполна — вам и доказывать, что актуальна (как мы, кстати, перескочили от "вузовская программа информатики" к "в современном мире"? в современном мире много что актуально, давайте специфику аппаратных языков филологам читать?) для данной специальности, и что надо аппаратные языки, и обязательно с FPGA. Иначе получается что вы один из этих, которые что-то выпячивают и на которых забавно смотреть.
olartamonov
24.02.2018 17:24И тут Остапа понесло (с)
Ок, в вашем мире аппаратных языков нет, айфоны растут на деревьях, программистам надо уметь только тетрис для них на яве писать.
В моём мире программирование на Verilog/VHDL существует, используется и является, натурально, программированием. И потому должно преподаваться в вузе, готовящем программистов, если этот вуз претендует на что-то значимое (также, кстати, как должны преподаваться и функциональые языки — это к вопросу об упомянутом вами лиспе).
olartamonov
24.02.2018 13:41+2Во-первых, у него не логика, а пустая демагогия.
Во-вторых, я вроде бы и число вакансий, и размер зарплаты менеджера по продажам привёл? Можно комбинировать как угодно, результат от этого осмысленнее не станет — просто потому, что концепция «текущая статистика Хедхантера даёт представление о рынке труда через пять лет» глупа сама по себе, а наложение её на тематику образования глупо в квадрате.
P.S. Отдельно мне каждый раз забавно смотреть, как программисты на Хабре (электронщики на electronix.ru и т.п.) выпячивают спрос на свои любимые профессии, забывая про существование остальных, а потом у них немножко бомбит от сравнения со спросом на бухгалтеров и продажников.Falstaff
24.02.2018 15:58Я посмотрел выше — оказывается, неправильно прочитал данные у ukt, так что прошу прощения. Но в целом, пять лет — не такой большой срок, выше ссылка на первый попавшийся тренд эмбеддерских зарплат. Если не будет прорывов, то тренд сохранится, а объявлять нейросети таким прорывом (именно таким, который обеспечит новые рабочие места), как мне кажется, рановато.
Ну и, судя по цитате, которую комментировал ukt, это как раз не выпячивание Java, это ответ на выпячивание FPGA. (И опять же, я не против выпячивания, но лучше чем-нибудь объективным, а не обещанием, что будет спрос на специалистов. Я эмбеддер, и до сих пор не перекочевал в продажники, несмотря на то что зарплаты там больше, а ответственность меньше.)
olartamonov
24.02.2018 16:15+11) Работа с FPGA представляет собой весьма специфический подвид программирования, поэтому для получения цельной картинки окружающего мира она должна изучаться в вузе.
2) Java концептуально ничего особенного собой не представляет. Изучается она в вузе или нет — второстепенный вопрос.
3) Вуз не даёт и не должен давать навыки, нужные для быстрого трудоустройства на приличную зарплату, потому что «4-6 лет обучения» и «быстрое трудоустройство» — это два круга на диаграмме Венна, расположенные в противоположных концах Местной группы. Начать можно с того, что за пять лет меняется даже не индустрия, а личные предпочтения конкретного человека.
4) Если вам надо быстро трудоустроиться — есть много прекрасных 3-месячных курсов программирования.Falstaff
24.02.2018 16:25… должна изучаться в вузе.
Вот даже Казанский не уверен, что должна — для них это эксперимент — а вы прямо-таки уверены.
Ну и на остальное — отлично, тогда давайте уж не апеллировать к тому, что гуглу нужны нейросети и поэтому айда к нам в ВУЗ, мы FPGA преподаём. Раз уж трудоустройство вообще к ВУЗу никакого отношения не имеет. Иначе как-то на передёргивание смахивает.
olartamonov
24.02.2018 16:36+1Вот даже Казанский не уверен, что должна — для них это эксперимент — а вы прямо-таки уверены.
(пожав плечами) А выпускники трех четвертей расплодившихся в девяностые «экономических факультетов» из знаний обладают разве что смутным представлением о ведении бухгалтерии. И что, должны ли мы ориентироваться на мнение выпустивших их вузов?
Если вуз не уверен, стоит ли студентам рассказывать о существующей, актуальной и касающейся их области знаний теме — это проблема данного конкретного вуза, а не области знаний.
Ну и на остальное — отлично, тогда давайте уж не апеллировать к тому, что гуглу нужны нейросети
Просто Юра добрый, он пытается разговаривать с оппонентами на их языке. Я, например, не такой добрый — на «вуз должен готовить к профессии» просто нервно реагирую, а если ещё и к «востребованными профессиям будущего», то могу сразу к оскорблениям перейти.
поэтому айда к нам в ВУЗ, мы FPGA преподаём
Вы в третий или четвертый раз не поняли мои слова о том, что преподаёт вуз.Falstaff
24.02.2018 17:29Должны ли мы ориентироваться на ваше личное мнение, которое вы противопоставляете мнению вуза? Тоже, если что, без особой аргументации, просто подавая как аксиому. И, извините, "айда к нам в ВУЗ..." — это перифраз слов ВУЗа из статьи, не ваших. Я уже понял, что вы с ВУЗом расходитесь в понимании, без чего можно обойти и что они вообще должны преподавать. :)
Намёк на оскорбления понял, благодарю. Оставлю ваши нервы в покое...
olartamonov
24.02.2018 17:45Вы согласились ориентироваться на личные мнения самим фактом оставления тут вами комментариев, в которых содержится ваше личное мнение, если что.
YuriPanchul Автор
24.02.2018 18:09+1Лабы на FPGA еще в 1990 годы стали такой же стандартной частью университетской программы в штатах как лабы по химии. Они есть не только в Беркли, Стенфорде и MIT, но в провинциальных университетах типа Монтаны. В странах СНГ был некоторый провал в этом деле, так как введение HDL, синтеза и FPGA в мейнстрим совпало по времени с коллапсом СССР.
См. например курс в MIT — web.mit.edu/6.111
Все, о чем я говорю, в очень массовом масштабе вводилось последние годы в Китае (КНР, в Тайванях-Гонконгах это ввели еще в 1990-е). То, что в России это распостранено меньше — это перекос, который нужно устранить. Тогда в России будет легче строить свои компании типа Qualcomm, Samsung или AMD.
golf2109
22.02.2018 21:56а почему такие «отстойные» development board с 7-сегментными индикаторами до сих пор выпускаются, неужели нельзя вставить какой нибудь графический LCD?
nerudo
22.02.2018 22:48Это ведь плата для начинающих и семисегментник довольно прост и интуитивен для начального освоения. Ну а на сложных платах ставят hdmi и все дела. А lcd никому особо не нужен. Кому и правда нужен — могут через разъем расширения подключить ;)
crazyblu
22.02.2018 23:25А чему Вы хотите научиться с графическим LCD? Отдельные сегменты это, считай, светодиодики. А если LCD — либо рисуешь сам, а точечная графика — задача на порядок сложнее управления светодиодами, либо — пользуешься «шаманским черным ящиком», который как работает ты не знаешь, но вот все ритуалы по вызову нужных реакций уже выучил…
Чем такой разработчик отличается от «разработчика роботов» на Лего?? Хочется же научить именно делать эти самые блоки, а не пользоваться ими…
Ну и по цене — это приблизительно треть стоимости платы будет. За странное преимущество LCD платить в полтора раза больше? Когда и на это то денег нет…olartamonov
23.02.2018 11:33Тем более, графические ЖК — и часть семисегментных тоже — ныне со своими контроллерами на борту, там разве что реализации I2C или SPI учиться остаётся.
Lisiy
24.02.2018 00:37В 2008 учась в Технионе, делал лабы на DE2 от Altera, такую же девушка держит на последнем слайде второго pdf'а. Они тогда уже казались устаревшими, но есть нюанс. Для начального обучения в полне подходит. Чего только стоило прописать контролёр VGA. Так что не надо наговаривать на эти платы.
YuriPanchul Автор
24.02.2018 00:38Девушка держит не DE2, а DE2-115, это гораздо более новая плата, типа 2013 или 2014 года
Lisiy
24.02.2018 12:36Имел ввиду, что даже на старой плате есть чему поучиться. Кстати не заметил в ваших лекциях объяснений касающихся setup & hold time. Не отрицаю что мог и сам пропустить.
YuriPanchul Автор
24.02.2018 18:17Если бы лекции были не две, а три, я бы вставил setup и hold, но в данном формате у студентов бы мозги сварились, поэтому я представил огрубленную картину с propagation delay комбинационной логики и максимальным периодом clock-а. При этом я порекомендовал вставить слайд с setup/hold в их собственные слайды в Иннополисе. Мои две лекции для них просто разогреться, у них полный курс компьютерной архитектуры на семестр. То есть когда они будут проходить то же по второй итерации, там setup/hold возникнет.
reversecode
22.02.2018 22:20А куда дели девочку которую обычно в статьях пиарили?
YuriPanchul Автор
22.02.2018 23:28Как куда? На первой фотке она есть справа. Или вы про другую девочку? У меня их несколько.
reversecode
22.02.2018 23:46-1Присмотрелся… вроде она, только как то она сейчас не ахти
вы их кормите и любите, а то увянут


kovserg
23.02.2018 09:11Это как для написания програм вместо изучения алгоритмов изучать ассемблер и писать свой компилятор. Дело благородное, но бесполезное.
www.imgtec.com/powervr-2nx-neural-network-accelerator
community.imgtec.com/developers/powervr/neural-network-sdk
developer.nvidia.com/gpu-accelerated-libraries
Всё уже есть. Зачем велосипеды строить?YuriPanchul Автор
23.02.2018 09:54Я подозреваю, что вы меня троллируете. В вашей первой ссылке стоит Imagination Technologies. Я проработал в этой компании с 2012 до 2017 года, правда не в отделении PowerVR, а в отделении MIPS.
Если же вы меня не троллируете, то вы возможно думаете, что весь хардвер растет на деревьях где-то в параллельной вселенной. Или что люди больше не будут проектировать микросхемы.
В данном посте ускорители нейронных сетей (история которых отнюдь не закончена) приведены как только одна из причин, почему полезно понимать проектирование на уровне регистровых передач. На самом деле это гораздо более общая технология, которая, как я написал выше, является мейнстримной технологией проектирования разнообразных чипов (CPU, GPU, NPU, теперь AI) за последние 25 лет. Даже если через пару лет волна AI чипов пройдет, будет что-нибудь еще.
Это как владеть программированием. Циклы, if-then-else, массивы, подпрограммы придумали в 1950-е года, но их до сих пор полезно знать. Так же и с принципами методологии проектирования на уровне регистровых передач — комбинационная и последовательностная логика, конечные автоматы и конвейер. Это столь же базовая вещь, как циклы и подпрограммы в программировании.kovserg
23.02.2018 13:23Я просто хотел сказать что первый шаг к аппаратным ускорителям нейронных сетей уже давно сделан. Воину искусно владеющему мечом совершенно не обязательно знать как кузнец сделал этот меч. Так для тех кто занимается нейросетями плисы очень далеки. Для загрузки монетизации вычислительных мощностей есть уже готовые инструменты в том числе и deeplearning. FPGA уж очень для узко специализированных задач подходят. Для поиграться есть aws.amazon.com/ru/ec2/instance-types/f1
YuriPanchul Автор
23.02.2018 20:26+1*** Я просто хотел сказать что первый шаг к аппаратным ускорителям нейронных сетей уже давно сделан. ***
Вы хотите сказать, что уже повсеместно в каждом смартфоне, микроконтроллере и сенсоре для интернета вещей стоит аппаратный ускоритель нейросетей? Рынок находится на довольно ранней стадии, хотя софтверные интерфейсы частично устаканились (TensorFlow и подобные).
*** Воину искусно владеющему мечом совершенно не обязательно знать как кузнец сделал этот меч. ***
Вы предлагаете всем идти в воины, а не в кузнецы? А если кому-нравится кузнечное дело?
*** Так для тех кто занимается нейросетями плисы очень далеки ***
В Микрософте с вами не согласятся — azure.microsoft.com/en-us/resources/videos/build-2017-inside-the-microsoft-fpga-based-configurable-cloud
(меня звали работать в ту группу год назад)
*** FPGA уж очень для узко специализированных задач подходят ***
В данном курсе FPGA используется как удобный инструмент для обучения основам RTL. А конечная цель — это не относительно нишевые FPGA, а разработчики массовых ASIC (application specific integrated circuits) которые стоят везде. Просто на FPGA вы можете сделать что-то сразу на плате за $100, а чтобы сделать коммерческий ASIC, вам заплатить фабрике миллион доларов (для исследовательского шаттла — десятки тысяч долларов).kovserg
23.02.2018 21:36> Вы предлагаете всем идти в воины, а не в кузнецы? А если кому-нравится кузнечное дело?
Некоторые еще химией занимаются и геологией и еще куча других специальностей которые очень важны. Но от нейросетей они очень далеки. Тут пиар, маркетиг и искуство впарить будут куда важнее.

lain8dono
23.02.2018 10:14Всё уже есть. Зачем велосипеды строить?
Но ведь кто-то это сделал? Даже в случае если ничего нового не делать, то всё равно кому-то надо поддерживать.
lvss_nn
23.02.2018 20:26+1Всё равно предметы по типу Аппаратные средства никуда не ушли из университетского курса и остаются базовыми для понимания работы схем, работающих с цифровыми данными. В случае RTL круто самому поработать с триггерами/буферами и попробовать собрать сумматор тот же — это даёт больше наглядности.
А так, в случае аппаратного программирования давно уже есть ещё один уровень абстракций, когда ты собираешь систему из готовых IP ядер и лишь добавляешь свои кастомные, написанные на veriloge.
И да, разработку и как минимум поддержку — никто не отменял. Ведь те же компиляторы тоже кто-то поддерживает и разрабатывает, верно? Просто это не такая большая ниша как веб.
В случае с FPGA всё интереснее, т.к. они получили массовое развитие и с точки зрения технологий, и с точки зрения работы на них — поэтому в данный момент, они уже могут использоваться не только как средство для прототипирования, но и в качестве компонента для конечного продукта: т.к. исправить косяк/добавить фичу в уже готовой и проданной микросхеме — невозможно, а здесь требуется просто обновить битстрим.
YuriPanchul Автор
25.02.2018 02:15А вот в Electronic Engineering Times месяц назад написали статью, что куча стартапов только готовит чипы с AI и все еще в ранней стадии. Кому верить — вашему «все уже есть» или EE Times?
https://www.eetimes.com/document.asp?doc_id=1332877


AntiLL
23.02.2018 12:02Но для того, чтобы обновить все программы в центральных и региональных университетах и сделать понимание RTL частью общего образования в хайтеке (как это сделано в американских вузах и как это быстро делают китайцы в КНР)
А можно на этом месте поподробнее? Действительно в США и Китае делают ставку на уровень RTL в образовании, и как следствие FPGA? А зачем? И каким образом вы это заметили?
У нас в ВлГУ преподавали ПЛИС и VHDL, но все всегда упиралось в простое, а какую задачу то решать на ПЛИС? Для большинства лабораторных поделок достаточно микроконтроллерного уровня. Тут надо отметить, что повторяется история с суперЭВМ, когда они есть. но чем их загружать непонятно (особенно эффективно, ведь мы знаем, что у них загрузка крайне невысокая по ядрам в силу закона Амдала), а мощность персоналок растет и все больше задач можно решать на них. Тоже самое и с ПЛИС, возможности микроконтроллеров растут, и все больше задач можно решать на них, та же ЦОС (DSP), сейчас вполне эффектно решается на микроконтроллерах. Нужно больше примеров реальных задач на FPGA, в этом плане спасибо вам за наводку по нейронным сетям.San_tit
23.02.2018 16:12Нормальный ЦОС (раалтайм и широкая полоса) на микроконтроллерах не решается в принципе, иногда можно решить на GPU. В итоге FPGA банально удобнее в силу того, что обычно уже все есть на борту (и интерфейсы и АЦП/ЦАП) плюс занимает мало места и можно сделать достаточно компактное решение.

Mirn
23.02.2018 17:52Полностью согласен и хотел бы доказать цифрами на паре примеров:
1. Предположим хотим сделать автомобильный ДСП процессор. Например о котором я писал ранее, цель — чтоб музыка в салоне не накладывалась абы как а играла качественно.
входные данные 44кГц, 8 каналов (а люди часто спрашивают больше каналов и качество 192кгц+).
Предположим что реализуем на ПК это — закинем его в багажник, проц ПК 3гигагерца, но из за того что ПК не предназначен для реалтайма соовсем, то придётся сделать буфера и КИХ фильтр на целых 100мс.
Итог:
(3*10^9) / (8*48000*48000*0.1) = 1.627604166667 (такта на семпло-тап)
в контроллер не влезет соовсем, современный ПК будет загружен свыше 50%. На малинке не подымешь.
Ок, делаем на FPGA — проблем с реалтаймом нет, ОС нет, всё можно сделать до 10мс.
укладываемся спокойно в 200 мегагерц
(2*10^8) / (8*48000*48000*0.01) = 1.085069444444,
потянет любая число дробилка с 8 умножителями, по цене STM32F4.
2. Всего-навсего FullHD 60fps видео камера и требуется простейшая обработка видеопотока реалтайм.
Давайте просто подсчитаем сколько у нас тактов на пиксель на том же ПК?
(3*10^9) / (1920*1080*60) = 24
что за это время можно сделать? особенно микроконтроллером? ладно на GPU, ну например подсчитать 8 матриц SADом и определить одно из 8 направлений если они есть. Чего не хватит чтобы просто например RAW поток цветового светофильтра байера превратить в RGB. Т.е. мы не сможем даже на GPU выполнить качественную цветовую интерполяцию без артефактов типа цветного и яркостного муара, «лабиринтов» и тд, т.е. не достигнем качества даже простых мыльниц в реалтайме.
О каких нейронных сетях вообще может идти речь? До нейронных сетей нам надо из монохрома хотябы цвета получить а не мозайку вырви-глаз.
И желательно без задержки в 2 секунды и более — с такой задержкой даже ИИ для роботизированной инвалидной коляски не сделать.
А задержки в процессинге и это бичь современного ИТ. Вспомните тот же meltdown — всё базируется на времени и зарежке скорости срабатывания, на том на что всё современное ИТ просто забило и игнорирует.lain8dono
24.02.2018 05:07На малинке не подымешь.
На самом деле можно заморочиться. Никто не запрещает пилить bare metal код на малинке. Есть neon. Если не хватит, то есть VideoCore. Не думаю, что сильно сложнее в сравнении с FPGA. Но смысла в этом мало на самом деле.
(3*10^9) / (8*48000*48000*0.1) = 1.627604166667 (такта на семпло-тап)
(2*10^8) / (8*48000*48000*0.01) = 1.085069444444
(3*10^9) / (1920*1080*60) = 24А можно это расписать? Что за такты на семпло-тапы? Откуда константы
3*10^9и2*10^8?Mirn
24.02.2018 06:16А можно это расписать? Что за такты на семпло-тапы? Откуда константы 3*10^9 и 2*10^8?
это частоты среднего пк в 3ггц и бюджетных плис в 200Мгц.
Звук лучше и проще всего обрабатывать КИХ фильтрами, их глубина задаётся в тапах — в количестве выборок, в задаче обработки звука количество выборок лучше пересчитывать в миллисекунды т.к. у аппаратуры и ОС есть задержки и у среды есть задержки распространения выраженные в миллисекундах.
КИХ фильтры это просто умножения на коэфициенты с сложением:
X0*A0 + X1*A1 + X2*A2 +… + Xn*An = Y
и семпло-тапы это и есть умножение с накоплением, т.е. количество семплов в секунду умноженое на глубину фильтра в тапах и количество фильтров.
расписываю пример
(3*10^9) / (8*48000*48000*0.1)
комп 3 гигагерца (3*10^9)
8 каналов
48кгц
глубина фильтра 100мс или 0.1 секунда при частоте 48кгц это 4800 тапов.
итого (8*48000*48000*0.1) = 1.843 миллиардов умножений с накоплениями в секунду.
Очевидно что невозможно сделать более нескольких операций за такт даже на NEON и SSE — немало времени потребуют пересылки, нормализации результатов и прочие мелочи.
В случае FPGA грубо говоря достаточно 1 такта на семпло-тап и одного умножителя на каждый экземпляр КИХ фильтра.
Что ещё очень плохо в малинке и во всех дешовых АРМ процах что они не могут перешагнуть планку в 2-4 операции за такт.
Есть интересное наблюдение что один и тот же Core i3 одного и того же покаления и одинаковым размером кеша, но ондин на ноуте тормозит в 4 раза сильнее чем стационарный в ПК.
Что уже говорить про разницу в производительности между Core i3 и ARM A9 например.
Поэтому по ряду причин проще и надёжнее реализовать урезанный вариант на STM32F7H например — там есть отличная ARM DSP библиотека. Я пытался сделать лучше неё свою либу и никогда выигрыш не превышал 10-20%. А производительности у этого МК столько же как и у Кортексов А серии. Но кодить под него мне лично проще. Поэтому следующая версия авто проца на ней сделана. Да и МК гораздо лучше предназначены для встраиваемых систем и дешевле и меньше места занимают чем малинка.lain8dono
24.02.2018 17:12Понятнее не стало. Проблема больше в том, что эти семпло-тапы не гуглятся от слова совсем. Какой-то профессиональный жаргон судя по всему. Я достаточно далёк от этой темы, потому и спрашиваю.
Что ещё очень плохо в малинке и во всех дешовых АРМ процах что они не могут перешагнуть планку в 2-4 операции за такт.
Не понимаю, в чём проблема. С одной стороны 2-4 операции за такт, а с другой стороны количество тактов в секунду. Кроме того ядро можно взять не одно, а 2 или 4. Тем более, что задача вроде как неплохо поддаётся распараллеливанию.
Если грубо: не вникая в сущность задачи, сколько она требует 32-битных операций с плавающей запятой в секунду? Актуальная малинка судя по всему может предоставить до
5*10^9таких операций в секунду. Или (теоретически) до25*10^9при содействии QPU.Mirn
24.02.2018 17:51я привёл способ оценки Ферма сложности, очевидно что если требуется простейших операций существенно меньше чем тактовая частота то всё ок, а если наоборот то всё очень плохо и плис просто позарез нужна. Не более.
«семпло-тапы» это просто мой способ оценки когда каждый семпл проходит N филтров по M тапов внутри, т.е. грубо говоря N*M операций умножения с накоплением на семпл. Но в реальности другие операции — пересылки данных, загрузки коэффициентов, их подстройка на лету методом наименьших квадратов (ща модно это называть нейросетью), и много чего интересного что упущено дабы не усложнять и поставить перед фактом что просто восемь сферических в ваккууме КИХ фильтров не потянет.
А насчёт малинки — ради бога делайте, не спорю что можно, малинка хорошая штука. Но судя по отзывам, стек оверфулу и нашему опыту что на малинке кое как распознование номеров взлетело даже на прямоугольнике 200х300 быстродействие у неё очень низкое, где-то в 10-100 раз ниже чем у десктопного ПК (на десктопном пк 8 каналов фул скрин тянет).
беглый поиск показал цифру в среднем ~700 MFLOPS, оценка ферма дсп проца дала 1500 MFLOPS. Заниматься реализацией алгоритма имеет смысл только когда запас в 2 раза есть а не наоборот.Mirn
24.02.2018 18:39добавлено
700 MFLOPS — это именно на КИХ фильтре измеренное быстродействие при помощи NEON инстриктов и глубокой оптимизации на небольшой длине фильтра, если фильтр длинной 4к и выше то это существенно хуже — в регистры коэф. не загрузить, могут и в кеш не влезть. Как выход есть либа для малинки которая заменяет Ких на FFT что для нашей задачи уже немного не то… но 99% клиентов не услышат. Но эта либа даёт быстродейтвие 32к… 64к тапов на семпл что впритык но позволяет реализовать задачу «в лоб».
YuriPanchul Автор
23.02.2018 20:36Лабы на FPGA еще в 1990 годы стали такой же стандартной частью университетской программы в штатах как лабы по химии. В странах СНГ был некоторый провал в этом деле, так как введение HDL, синтеза и FPGA в мейнстрим совпало по времени с коллапсом СССР.
Насчет задач вы можете посмотреть например MIT — web.mit.edu/6.111/www/f2017/previousterms.html
r6l-025
23.02.2018 20:37Например, обработка потоков данных от фазированных антенных решеток. Суммарный поток данных от все приемников может составлять десятки а то и сотни гигабит. При этом этот данные от всех приемников дублируют друг друга, от них нужна только информация о фазе и амплитуде сигнала. Я слабо себе представляю процессор который мог бы эффективно справится с такой задачей. А вот FPGA весьма неплохо для этого подходит. Из всех потоков извлекается информация о фазе и амплитуде, которая занимает в десятки раз меньший поток. А этот поток уже можно эффективно обрабатывать дальше на ЭВМ.
lingvo
23.02.2018 18:28Первый шаг к аппаратным ускорителям нейронных сетей для программистов лежит через изучение основ HDL, RTL и лаб на FPGA
Я бы сказал, что с этим не согласен. Первый шаг к аппаратному решению какой-либо математической задачи лежит через модель и принципы моделирования. Второй шаг — изучение Xilinx System Generator, куда входит часть первого шага.
После этого уложить любые алгоритмы на FPGA сможет любой программист без знаний RTL и HDL и даже не-программист. Проверено на опыте десятков людей.nerudo
23.02.2018 19:54Я с вами согласен в целом, но вот уверен, что в качестве бэкграунда без HDL никак. Пока вы реализуете абстрактную вычислительную модель гоняющуюся в hardware-in-the-loop — пожалуйста. Но вот когда нужно собрать окончательное устройство, то без HDL не обойдется…
lingvo
23.02.2018 20:14Готов поспорить…
Приведите примеры, где без HDL никак. В качестве своих примеров могу сказать, что у нас есть окончательные устройства, где ввод-вывод был сделан и c использованием АЦП и PCIe и 1/10GB Ethernet. И все это и без использования HDL, и с включением сторонних IP ядер напрямую в моделях. Софт-процессоры, ессно, тоже есть.nerudo
23.02.2018 21:24Наверное можно в ряде случаев впихнуть все в модель. Но вот эффективно ли? Ладно, я понимаю можно готовые ip-ядра втянуть в модель или блок-дизайн. Но если нужно написать свой интерфейс с АЦП или взять готовое HDL-решение и модифицировать под свои нужды (там AD936* какой-нибудь)?
lingvo
23.02.2018 22:10Но вот эффективно ли?
С точки зрения затраченного времени на разработку — очень.
YuriPanchul Автор
24.02.2018 00:37Вы сделали свой ASIC без использования HDL? Что вы имеете в виду под окончательным устойством? Использование готовых чипов? Вы считаете, что в России вообще не стоит проектировать чипы и все брать из Калифорнии?
lingvo
24.02.2018 10:35Вы сделали свой ASIC без использования HDL?
Цикл разработки на ПЛИС далеко не всегда заканчивается изготовлением ASIC.
Что вы имеете в виду под окончательным устойством? Использование готовых чипов?
Да. Xilinx, Intel. Готовые устройства — это платы, контроллеры, системы управления, в основе которых используется либо ПЛИС самостоятельно, либо в сочетании с к каким-либо процессором.
Вы считаете, что в России вообще не стоит проектировать чипы и все брать из Калифорнии?
Нет.
YuriPanchul Автор
23.02.2018 20:40В данном курсе FPGA используется как удобный инструмент для обучения основам RTL. А конечная цель — это не относительно нишевые FPGA, а разработчики массовых ASIC (application specific integrated circuits) которые стоят везде. Крупный FPGA в смартфон или устройство для IoT не запихнете (цена, Fmax, энергопотребление, физический размер), а задачи типа «Smart IoT» доползут и в такие массовые устройства.
lingvo
24.02.2018 11:01А конечная цель — это не относительно нишевые FPGA, а разработчики массовых ASIC (application specific integrated circuits) которые стоят везде.
Вы немножечко не понимаете о том, что такое ASIC в современном смартфоне, и лекция касается этого только в одном вступительном слайде. ASIC в современном смарте — это не что иное, как ARM процессор, обвернутый нужной периферией, чтобы решить определенную проблему. Т.е. это не триггеры, не нейросети, не DSP алгоритмы, а тупо процессоры, которые делают то же самое, что и настольный компьютер, только немножечко экономнее, немножечко медленнее, но при этом сами немножечко меньше. И подход к разработке таких ASIC лежит не через RTL, и даже не через HDL, а через кропотливую разводку данного чипа, как платы, многочисленное моделирование и оптимизацию расположения. Они там пытаются выжать гигагерцы и милливатты из того, что и так уже работает, понимаете? И все, что можно было сделать на HDL — уже было сделано разработчиками ядер.
Поэтому такой ASIC — это совершенно иная степь и она программисту не нужна. Есть смысл именно остановиться на ПЛИС, рассказать, как определенные алгоритмы решаются на ПЛИС быстрее и лучше. Средние ПЛИС сейчас не такие уж большие и дорогие, мало того, как было описано выше, Cloud сервисы уже предоставляют массивы из ПЛИС, а следовательно смартфону или IoT устройству не нужно нести ПЛИС на борту, а нужен только нормальный интернет-канал.flatscode
24.02.2018 12:36+1Вы немножечко не понимаете о том, что такое ASIC в современном смартфоне...
По-моему, вы слишком много на себя берете.olartamonov
24.02.2018 13:47Ну откуда Юре это знать-то, вот вы когда последний раз смартфон на MIPS видели? А? Шах и мат, фпгашники!
YuriPanchul Автор
24.02.2018 18:40*** Вы немножечко не понимаете о том, что такое ASIC в современном смартфоне ***
Э-э-э, я вообще-то в текущий момент работаю над процессором, который лицензировал MediaTek для своего ASIC-а для LTE:
www.electronicsweekly.com/news/imagination-secures-big-smartphone-design-mediatek-2017-08
*** ASIC в современном смарте — это не что иное, как ARM процессор, обвернутый нужной периферией, чтобы решить определенную проблему. ***
В современнои смартфоне помимо ядра ARM есть еще несколько ядер:

*** Т.е. это не триггеры, ***
Вы хотите сказать, что внутри ARM процессора нет триггеров?
*** не нейросети ***
Это текущая маркетинговая фишка в электронных компания — что везде (в том числе в смартфонах) будут стоять ускорители нейросетей. Мнение Дадо Банатао, ветерана индустрии, основателя Chips & Technologies, чипсета для первых PC — en.wikipedia.org/wiki/Dado_Banatao
*** не DSP алгоритмы ***
Смартфон без DSP алгоритмов — это как брачная ночь без невесты. Texas Instruments вырос с 1990-х за счет DSP процессоров для мобильных телефонов.
***, а тупо процессоры, которые делают то же самое, что и настольный компьютер, только немножечко экономнее, немножечко медленнее, но при этом сами немножечко меньше. ***
А процессор в настольном компьютере спроектирован без использования HDL? Может вы еще скажете, что инженеры в Intel и AMD не используют FPGA-base эмуляторы типа ZeBu?
*** И подход к разработке таких ASIC лежит не через RTL, и даже не через HDL, а через кропотливую разводку данного чипа, как платы, многочисленное моделирование и оптимизацию расположения. ***
Физический дизайн на backend (floorplanning, clock synthesis, placement, routing, DRC, LVS) — это все очень хорошо, но как вы себе это представляете без HDL/RTL? Нарисовать мышкой на экране граф из миллиарда ASIC library cells?
*** И все, что можно было сделать на HDL — уже было сделано разработчиками ядер. ***
В России не нужно иметь разработчиков ядер? Брать все из США, UK, Израиля, КНР, Японии и Южной Кореи?lingvo
24.02.2018 21:54В России не нужно иметь разработчиков ядер? Брать все из США, UK, Израиля, КНР, Японии и Южной Кореи?
Вот с этого и нужно было начинать. Кому в России нужны разработчики ядер? Кому в России нужны разработчики ASICов и сами ASICи вообще? У вас есть фирма, которая производит смартфоны миллионами и которой нужен специализированный ASIC чип, который не может сделать или уже не выпускает какой-нибудь Broadcom? Или Вы лицензировали технологии Zwave, Zigbee, BLE, WiFi и прочие, чтобы делать свои ASIC для IoT?
ASIC — это очень нишевый рынок, весьма дорогой для вхождения и это лишь малюсенькая область применений ПЛИС. Настолько малая, что не вижу смысла забивать этим голову студентам — получится очень узкий специалист.
YuriPanchul Автор
24.02.2018 22:04+1*** У вас есть фирма, которая производит смартфоны миллионами и которой нужен специализированный ASIC чип, ***
К кому вы обращаетесь под «у вас»? Я работаю инженером в Santa Clara, California. Пишу верилог. MediaTek, Broadcom, Qualcomm — наши клиенты. Сотни миллионов, миллиарды.
*** Кому в России нужны разработчики ядер? Кому в России нужны разработчики ASICов и сами ASICи вообще? ***
Когда я работал в 1989 году программистом в советском совместном предприятии, которое писало софтвер для Windows, то тоже говорили «кому это нужно в СССР? Все программы уже написаны в Микрософте. Нужно только научиться пользоваться Page Maker и Word».lingvo
25.02.2018 02:12Разговор зашел в тупик…
Так вы согласны, что программистов не стоит учить проектировать ASIC, а стоит учить только программированию ПЛИСов? Этого будет достаточно для решения поставленной в статье задачи — получение аппаратного ускорения нейросетей?YuriPanchul Автор
25.02.2018 02:22Моя позиция: программистам стоит показать базовые элементы цифровой логики и методологии проектирования на уровне регистровых передач. Потому что это им поможет иметь понимание, какую часть задачи стоит реализовать в хардвере, а какую часть — в софтвере. Независимо от того, является ли хардвер FPGA или ASIC (я предполагаю, что в будущем в России будет больше групп разработчиков ASIC и IP-блоков). FPGA стоит использовать, чтобы это пощупать. При этом учить программистов конкретно Xilinx System Designer лично я бы не стал. Хотя если кто-нибудь собирается их учить маршруту от MathLab через Xilinx System Designer — я не против, пусть цветут все цветы.
lingvo
25.02.2018 11:17Ну не нравится Xilinx System Generator, можно взять родной матлабовский HDL Coder.
Смысл того, что вы написали выше — когда встает вопрос, где реализовать ту или иную функцию — в железе или софте, во первых необязательно знать HDL, а важно знать как тот или иной алгоритм ложится на параллельную архитектуру ПЛИС. Как его можно распараллелить, поставить в конвеер, чтобы получить высокое быстродействие, есть ли там конечные автоматы, которые тоже хорошо ложатся на железо и т.д.
А для этого нужно представлять как выглядит алгоритм в математической, независящей от реализации форме. И тут на помощь приходит Матлаб с Симулинком. С его помощью и помощью его тулбоксов (нейронные сети там тоже есть) программист (мало того даже не-программист) может создать и промоделировать свой алгоритм, выяснить его структуру, решить какой из вариантов физической реализации выбрать и автоматически сгенерировать HDL или С код. Т.е вся разработка может быть сделана в одном пакете.
YuriPanchul Автор
25.02.2018 02:28Что касается нейросетей, то для их ускорения только FPGA недостаточно. Месяц назад в EE Times была статья про стартапы в области ускорения AI с помощью custom silicon, то бишь массовых ASIC-ов:
www.eetimes.com/document.asp?doc_id=1332877
flatscode
Интересно еще для криптографии. А то аппаратный AES уже в каждом утюге, а с ГОСТами все намного хуже.
YuriPanchul Автор
Да, это хороший пример