
У нас есть два подхода к Disaster Recovery: «растянутый» кластер (active-active-инсталляция) и площадка с выключенными виртуальными машинами (репликами). Они имеют несколько точек сохранения снэпшотов.
Запрос на катастрофоустойчивость есть, и многим нашим клиентам это реально нужно. Поэтому мы начали прорабатывать обе схемы в рамках нашего продакшна.
У методов есть плюсы и минусы, сейчас про них расскажу.
«Растянутый» кластер
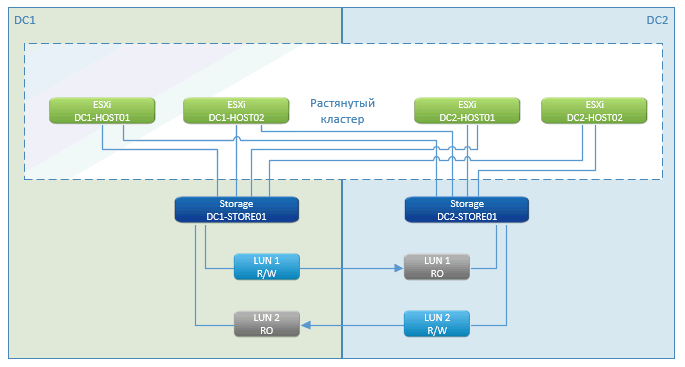
Как видите, это стандартная история метрокластера. В плюсах — практически нулевой простой, пауза только на время запуска виртуальных машин. Отрабатывает такая фича — VMware High Availability (HA). Она видит, что хосты потерялись, и сразу же перезапускает ВМ на удалённой площадке.
Запуск делается сразу с СХД, которая находится в кластере.
СХД с геораспределённым кластером — это маркетинговая фича NetApp. У других производителей есть нечто с похожим названием. По сути, это продуманная асинхронная репликация с одной стороны на другую. Пишем на одну ноду в локальной сети и синхронизируем через специализированные каналы связи с другой.
В случае отказа одной из СХД оставшаяся (на другой площадке) презентует пути к дискам оставшимся же хостам. На них перезапускаются ВМ, которые погибли. Всё происходит автоматически — ЦОД грохнулся, всё перезагрузилось, СХД отработали, VMware отработала. Клиент увидел, что всё моргнуло и перезапустилось.
Единственное, кэш из оперативной памяти ВМ может потеряться. Но если база данных его скинула, то потеря нулевая по времени.
Если у нас теряется связь между площадками, то всё продолжает работать на своих местах и, как только связь восстанавливается, начинает синхронизироваться.
Минус — высокая цена. Потому что нужна фактически двойная СХД (причём аналогичная по типам, скорости и объёму дисков первой СХД на основной площадке), которую нельзя как-то использовать, кроме как под резерв. Плюс обвязка к СХД для метрокластера, это FC-бриджи, FC-сеть и прочее.
У нас два ЦОДа, между ними FC-связка по двум лучам (четыре линии тёмной оптики и DWDM). Это две железки, каждая обеспечивает по 200 Гбит пропускной способности для FC и Ethernet.
Альтернатива с DR

Есть софт с интуитивно запоминающимся названием — VMware vCloud Availability for Cloud-to-Cloud DR.
Это система создания идентичной ВМ на удалённой площадке раз, условно говоря, в 15 минут. К ней на изоленте примотана система презентации всего этого правильным образом в механизмы управления облаком.
То есть в бэкенде находится технология VMware Replication. В случае отказа мы вручную запускаем DR-план на второй площадке, он автоматически прекращает попытки реплицировать, затем регистрирует ВМ в vCloud Director, кастомизирует IP-адреса (чтобы не пришлось менять их на ВМ) и запускает ВМ в нужном порядке. В нашем решении менять адресацию не нужно, мы растягиваем сети на оба ЦОДа.
Машины реплицируются постоянно, но не весь ЦОД, а только выбранные — критичные процессы. Реплицируется раз в какое-то время, минимальный интервал — 15 минут (это идеальный случай, когда всё летает и есть выделенный сервер репликации и минимум изменений на ВМ). На практике у вас есть копия на полчаса или час назад. Если что-то пошло не так, то данные, которые попали в интервал, потерялись. 15 минут — это вопрос агента, который собирает новую репликацию. Veeam говорят, что могут меньше 15 минут, но по факту тоже на практике дольше, если не используют фичи СХД. Я не видел на промышленной машине (не на тесте), чтобы было иначе.
Уже давно у NetApp, как и у многих других производителей СХД, есть технология SnapMirror, которая позволяет переложить работу по репликации с гипервизоров на СХД, и VMware Replication умеет этим пользоваться.
Пока сервис репликации пробежит, поезд уходит далеко. Но зато это дёшево.
Почему ещё дёшево — потому что можно использовать любую СХД с любой стороны (от разных производителей, разного класса), не надо выделять заранее большой объём дисков.
Не надо выделять большую дисковую группу, внутри которой нарезаются луны. Просто берётся место на локальной СХД и применяется по факту наличия записи от виртуальной машины. За счёт этого оптимальнее занимается место на СХД, если она используется под другие задачи. А она используется, так как мы не всем клиентам даём такую услугу.
Минус — надо настраивать репликацию на уровне ВМ, то есть контролировать, что всё верно настроено, что это та машина, следить за тем, что репликация проходит, что ошибок нет. Создавать DR-планы для каждого клиента, проводить их испытания.
В первом случае СХД берётся, условно, инфраструктурно, чуть ли не по секторам (точнее, по объектам). А тут одна машина может отвалиться по причине отваливания задачи из-за каких-то софтверных причин, связанных с багом на высоких уровнях, или из-за проблем с доступностью. Это случается чуть чаще, чем если брать именно низкие уровни.
В плюсе — DR хранит несколько точек. Можно откатиться на несколько снепшотов назад.
Снаружи от гостевых ОС нужен дополнительный софт.
Чтобы до Vcloud Director прокинуть все нужные сети, нужна работа нашего администратора. Вообще, вся сетевая связность в этом варианте остаётся на нашем администраторе. Для клиента облака это означает заявку, что тоже занимает время.
Репликация настраивается тоже через заявку. Добавил ВМ — надо отправить заявку, что необходимо её реплицировать. Автоматом она в задачи по репликации не попадёт. Нужно уделять внимание админу.
Разница
В итоге цена может отличаться больше чем в два раза. Репликация будет умножать стоимость дискового пространства на два и больше (две полные копии + история изменений), плюс что-то за сервис и резервацию вычислительных ресурсов. В случае с метрокластером стоимость пространства будет умножаться на два, но само пространство будет стоить значительно дороже, плюс надо жёстко резервировать узлы на удалённой площадке. То есть и вычислительные ресурсы должны умножаться на два, мы их не можем утилизировать под что-то ещё.
В случае с метрокластером мы можем использовать только одинаковые типы дисков, чтобы было полное зеркало. Если на основном ЦОДе часть дисков быстрые, часть медленные на 10 тысяч оборотов в минуту, то нужна идентичная конфигурация. В случае реплики возможны более медленные диски на резервной площадке, а это дешевле за счёт хранения. Но при переключении на резерв он окажется по производительности меньше. То есть если он что-то хранит на SSD в основном кластере, а реплицируется на обычные диски, то хранение будет значительно дешевле ценой замедления инфраструктуры резерва.
Прямо сейчас мы выбираем то, что войдёт в более ранний релиз, поэтому хотим посоветоваться: можете коротко рассказать, как вы организуете свои DR-площадки и что бы от них хотели вообще в целом?
Комментарии (11)

Loxmatiymamont
23.08.2018 11:26Всё же кластер и репликация призваны защищать разные вещи. Кластер обеспечивает, что сбойная машина будет быстро загружена в другом месте, в то время как реплика защищает информацию внутри машины.
Грубо говоря, слови вы криптор, кластер радостно отзеркалирует все изменения и у вас будет очень стабильная, но очень зашифрованная машина. В то время как с репликой такого риска нет.dklm
23.08.2018 11:47С репликой эта проблема также актуальна, если только вы не храните несколько реплик.
Реплика защитит ваши данные в случаи физической потери или не доступности ваших серверов.
Для защиты от криптовирусов нужны резервные копии…Loxmatiymamont
23.08.2018 11:55Не вижу каким образом это может быть актуально, кроме как запустить репликацию после атаки. Но для этого надо обладать совсем уж буйной фантазией. А даже если это произошло автоматически, то хранение реплики с одной точкой отката, это… кхм… странное решение…
По сути это тот же бкап, но лежащий не в сторонке, а на какой-то схд и готовый стартануть несколько быстрее, чем машина в бекапе.dklm
23.08.2018 12:01реплика это не бэкап ;-) снепшот это также не бэкап ;-)
Loxmatiymamont
23.08.2018 12:18+1и рейд не бекап, и кластер не бекап, и ничто кроме бекапа не бекап, иначе не назывался бы он так ;)
behek Автор
23.08.2018 12:16Репликация срабатывает по расписанию раз в несколько минут, и каждая дельта занимает место на СХД и является снепшотом на резервной машине. Хранить бесконечное количество реплик не получится.
Момент атаки можно легко пропустить и установить время её начала не всегда быстро и легко.
Так что, от крипторов только резервное копирование на удалённую площадку.Loxmatiymamont
23.08.2018 12:22Это всё верно, хотя можно долго спорить про размер дельт, про разницу реплик на уровне схд и гипервизора, про количество хранимых реплик и т.д. Но мой изначальный посыл был про то, что сравнивать реплику и кластер совершенно некорректно. Они дополняют друг-друга, защищая от разных типов угроз и никак не взаимозаменимы.
behek Автор
23.08.2018 12:48-1Не согласен, от проблем с СХД и отказа вычислительного кластера защищают оба решения.
И выбирать из них стоит отталкиваясь от стоимости вашего RTO\RPO.
NoOne
25.08.2018 06:32VMware Site Recovery Manager 6 с vSphere Replication каждые 15 минут для серверов приложений, СУБД — Oracle DataGuard.
Потому как данные терять нельзя, а сервера приложений меняются не так часто, и этого достаточно
Karroplan
мне кажется, что автор путает понятия fault tolerance и disaster recovery. «Растянутый кластер», реплики СХД и т.д. — это fault-tolerance.
FT — это набор технических мероприятий минимизирующий влияние технических неполадок.
DR — это уже комплекс как технических так и организационных мероприятий, который позволяет продолжать работу при событии нарушающем работу мер FT.
то есть, FT — это два ЦОДа, репликация СХД, растянутые кластеры и т.д. И если выйдет из строя сеть питания всего региона и оба ЦОДа прикажут долго жить или изолируются — все ваши кластеры были ни к чему. DR — это как раз меры, чтоб избежать в том числе и этого. Например, третий ЦОД в 2000км от пары основных с 5мин отставанием в данных, ну или без отставания — зависит от глубины кармана.
behek Автор
Говоря про DR-план, я не имею ввиду общий план для всего ЦОДа, а только про рассматриваемый продукт. И сокращение DR употребляю — как короткое название продукта, о котором пишу. Видимо небольшой путаницы не удалось избежать.