
Миграция ИТ-систем — задача непростая. Но особую сложность представляет ситуация, когда нужно не просто перейти со старого железа на новое, а переехать на новую операционную систему на существующем оборудовании, причём без миграции продуктивных данных. Один подобный переезд длился около года, причём большую часть времени заняла подготовка.
У клиента две площадки в разных городах, и на каждой по две связанные между собой системы хранения данных. Информация с одной СХД с помощью встроенных средств репликации отправляется на вторую. Управление выполняется с помощью внешней системы резервного копирования. В одном городе установлены две системы NetApp 3250, в другом — основная NetApp 6220 и резервная NetApp 3250. Клиент планирует в будущем расширять этот комплекс, добавлять диски, модернизировать контроллеры.
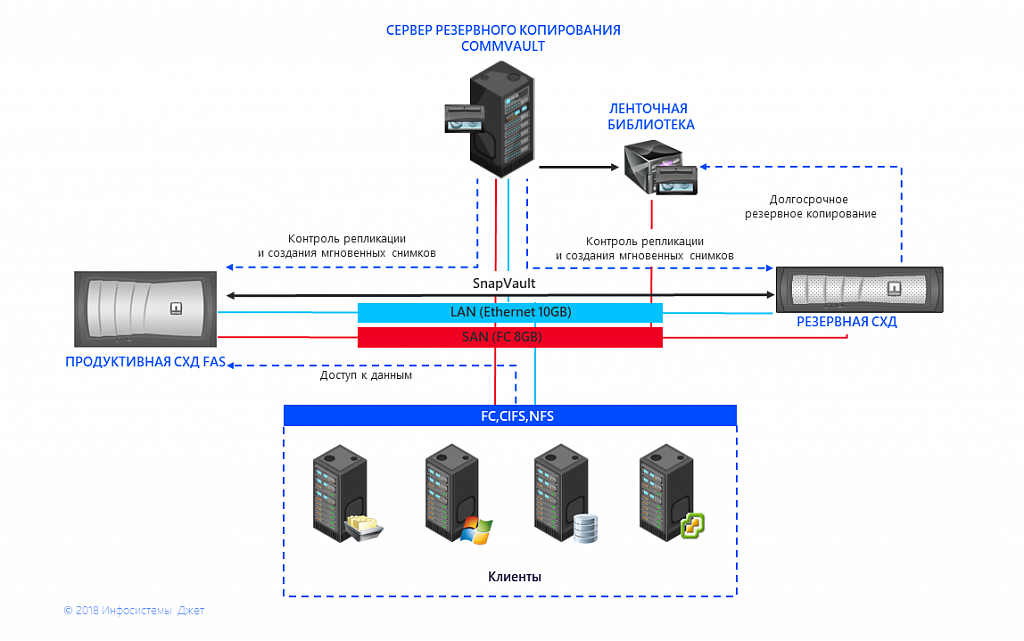
Рис. 1 Схема взаимодействия СХД и СРК
И с этим связана основная проблема — окончание поддержки. Для установленной на СХД операционной системы Data ONTAP 8.2 7-Mode мажорных обновлений не было уже пару лет, а выпуск исправлений критических ошибок прекратится в 2021 году. Новые диски и контроллеры не совместимы с устаревшей операционной системой.
Решение — переход на кластерную систему ONTAP 9.1 как последнюю поддерживаемую для данных контроллеров СХД. Её основными преимуществами являются:
- Горизонтальное масштабирование путём объединения в единый отказоустойчивый кластер, что позволит создать единую систему на базе продуктивной СХД и СРК.
- Распределение нагрузки между контроллерами, дисками, а также перемещение данных внутри СХД без прерывания сервиса и остановки доступа к приложениям.
- Обслуживание аппаратного и программного обеспечения систем хранения данных без остановки их работы и прерывания сервиса.
- Возможность создания гетерогенных кластерных конфигураций, включающих в себя контролеры и диски различных типов, в том числе СХД сторонних производителей при условии использования лицензий на виртуализацию их дисковой емкости.
- Возможность использования SSD как кэширующего слоя для агрегатов.
- Оптимизированная работа механизмов Data Compaction (компрессия и дедупликация).
Для миграции с 7 mode на Cluster Mode есть 3 варианта:
- Миграция с репликацией данных с помощью утилиты Netapp 7-Mode Transition Tool (7MTT) и режима copy-based transition (CBT). Для этого необходима вторая СХД с дисковым пространством неменьшего объёма и поэтапная репликация на базе SnapMirror. Для каждого сервиса переключения согласовываются и выполняются в заданное время.
У одного из наших заказчиков мы уже делали данную процедуру на метрокластере. В связи с большим числом томов, LUN’ов (>400) и долгим согласованием деталей, даунтаймов и т.д. миграция заняла около 3 месяцев без учёта подготовки. - Миграция без перемещения данных с помощью утилиты Netapp 7-Mode Transition Tool (7MTT) и режима copy-free transition (CFT). Для этого необходима вторая СХД с минимальным количеством дисков, на которую после предварительной подготовки будет переключаться продуктивная дисковая подсистема. Для всех сервисов согласовывается один большой даунтайм.
- Миграция с копированием данных средствами хоста. Это традиционный путь миграции между СХД любых производителей.
Поскольку существующие СХД были ещё на вендорской поддержке, а производительности контроллеров в ближайшей перспективе хватало, то бюджет на закупку новых контроллеров не выделили. В связи с этим было принято решение провести миграцию контроллеров на Cluster Mode с помощью 7MTT CFT. Одним из ключевых требований являлось отсутствие заметных перерывов в работе СХД: большая часть систем должна работать бесперебойно по будним дням. Поэтому основные работы по миграции на продуктивной СХД были назначены на выходные.
Этап подготовки начался со сбора информации с СХД и проведения предварительных проверок. Специализированное ПО NetApp 7MTT формирует список предупреждений, которые могут помешать выполнить миграцию или завершить её с ошибками. Например, для одной из систем этот список состоял из более 200 пунктов. Потребовалось обновить все системы до наиболее свежих поддерживаемых версий ОС, обновить прошивки контроллеров, дисковых полок и самих дисков. Также у новой операционной системы другая логика работы, требующая дополнительных IP-адресов и подключений между СХД.
Достаточно быстро обнаружился стоп-фактор — у клиента использовалась технология, которая основывалась не на репликации томов целиком, а на репликации qtree (подраздел, к которому применяются ограничения по доступу, объёму и т.д.) А в новую ОС такие отношения SnapVault мигрировать невозможно. В результате перед началом работ было бы необходимо полностью удалить все репликационные копии. Чтобы клиент после переезда не остался без резервных копий, перед миграцией было запущено резервное копирование на базе репликации томов целиком. С помощью SnapMirror создавались новые резервные копии рядом со старыми, в процессе четырёх недель накапливался лог изменений. И если на одной из площадок для этого было достаточно места, то на второй пространство было ограничено, пришлось постепенно делать копии одного из томов. По прошествии четырёх недель старые отношения удалялись и создавались новые. Достаточно длительный, поэтапный процесс, который занял в случае одной площадки около 1,5 месяцев, а у второй более 3-х. Дополнительно хочу отметить, что процедура остановки отношения Snapvault сопровождается удалением целевого qtree и скорость её выполнения сильно зависит от количества файлов и в меньшей степени от его объёма. Например, qtree с 4 миллионами файлов и размером в 500GB удалялся в течение 24 часов.
В процессе возникали разные сложности. Забюрократизированность процессов внесения изменений на системах клиента увеличивала сроки согласования работ. К счастью, удалось договориться решать технические вопросы напрямую, обсуждая на более высоком уровне только важные, «идеологические» моменты, такие как согласование плана работ и выбор конкретных дат для миграции.
Трудностей доставило использование временной СХД. Под руководством 7MTT настроили обе СХД согласно требованиям и предпроверкам. Затем выключили старую СХД и подключили дисковые полки к новой. Снова всё проверили. С точки зрения ПО NetApp, процесс миграции завершён и все расходятся
Для работ на второй площадке заложили дополнительное время, надеясь избежать хотя бы части проблем, но это не помогло — операционная система вела себя непредсказуемо. График дважды сдвигался. В первом случае, когда вели работы с FAS3250, не получалось мигрировать боевые системы, работающие в режиме 24/7, из-за ошибки в недавно изменённых настройках сетевой инфраструктуры заказчика (хотя при тестировании миграции за неделю до начала работ всё летало). vMotion на удалённую СХД копировал виртуалки со скоростью меньше 1 Мбит/с.
В процессе миграции у клиента частично изменилась архитектура. Тома, которые отдавались в их инфраструктуру VMware vSphere, раньше выдавались по NFS Ethernet. Клиент их переделал, и они переехали на Fibre Channel. В процессе миграции выяснилось, что у LUNа полностью меняется ID и, соответственно, VMware видела новые LUNы, которые ей адресовали со старыми данными, и отказывалась их подключать на постоянной основе. В итоге, благодаря помощи специалистов VMware удалось через консоль подключить эти LUNы на постоянной основе, указав, что это снэпшот старых датасторов. Затем пришлось перезагрузить VMware-хосты. В итоге, на них удалось увидеть виртуальные машины и поднять виртуальную инфраструктуру. А если бы клиент продолжил использовать NFS, то такой проблемы не возникло бы — IP адрес и DNS имя остались теми же самыми, что и раньше.
План работ непосредственно в дни миграции:
Пятница: работы с СХД и СРК
- Остановили все отношения SnapVault и SnapMirror, скоммутировали временную СХД и проверили готовность систем к миграции. Запустили процедуры миграции СХД в 7MTT по методу Copy Free Transition. Переподключили боевые дисковые полки к временному контроллеру.
- Мигрировали в 7MTT, мигрировали root vol подменных контроллеров на дисковые полки СХД СРК. Установили новые Ethernet-адаптеры, запустили СХД СРК, стёрли конфигурацию и загрузили образ ОС по сети с HTTP-сервера. Установили новые версии прошивки и ОС (на этом этапе возникли необъяснимые проблемы с загрузкой образа по сети. В конце концов загрузили напрямую с ноутбука).
- Заменили контроллеры в кластере на старые и подключили боевые дисковые полки к СХД по процедуре upgrading by moving storage. Восстановили работу кластера, перенастроили сетевые интерфейсы (пришлось решать проблемы, связанные с некорректной работой кластера) и установили лицензионные ключи.
Суббота: работы с основной СХД
- Подключили временные дисковые полки к временной СХД и снова её настроили.
- Мигрировали важные виртуальные машины на СХД в удалённый ЦОД средствами VMware vMotion.
- Мигрировали основную СХД в 7MTT по методу CFT. Выключили основную боевую СХД, подключили её дисковые полки к контроллеру и конвертировали метаданные ОС в 7MTT. Мигрировали root vol подменных контроллеров на дисковые полки СХД СРК.
- Установили новые Ethernet адаптеры и запустили боевую СХД в бездисковой конфигурации, стёрли настройки, а потом загрузили по сети с HTTP-сервера. Установили новые версии прошивки и ОС. Заменили контроллеры в кластере, подключили боевые дисковых полки к СХД по процедуре upgrading by moving storage.
- Восстановили работу кластера, перенастроили сетевые интерфейсы (повозились с некорректной работой кластера из-за подключенных боевых сетевых интерфейсов). Установили лицензионные ключи.
- Восстановили подключения СХД к серверам VMware, изменили зонирования в SAN-сети, настроили маппинг LUNов, переместили тома в отдельный SVM для работы с FC-доступом. Подключили LUN к ESXi. В связи с тем, что LUN ID изменился, датасторы не появлялись в автоматическом режиме, пришлось последовательно перезагрузить серверы ESXi и подключить LUN командами через esxcli.
- Перенастроили боевые интерфейсы, переименовали CIFS-серверы и восстановили доступ к CIFS-шарам и NFS-экспортам.
Воскресенье: решение проблем и настройка ПО СРК
- Обратно мигрировали виртуальные машины с СХД СРК на боевую СХД.
- Решили проблему с доступом к папке в режиме записи с Linux-хоста. Развернули последнюю версию ПО мониторинга Netapp onCommand Unified Manager 7.3 и подключили к ней обе СХД.
- Проанализировали данные по текущей нагрузке на агрегаты c помощью ПО Unified Manager, с помощью SSD подключили кэширующий слой к существующим дисковым агрегатам (Flash/Storage Pool).
- Выключили подменную СХД, создали связи между кластерами (Cluster peering, SVM peering), чтобы можно было использовать репликацию. Создали новые отношений SnapMirror между основной СХД и СХД СРК на базе существующих томов (которые использовались в отношениях SnapMirror 7 mode) с ресинхронизацией изменившихся данных, а затем переконвертировали отношения SnapMirror в отношения SnapVault (SnapMirror XDP).
- Подключили обе СХД к ПО СРК Commvault в режиме NetApp Open Replication с помощью техподдержки Commvault, по-другому не получалось, хотя всё делали по инструкции. Настроили отправку логов Autosupport с боевой СХД и СХД СРК.
Понедельник: шлифовка
- Проверка работы основной продуктивной СХД и СХД СРК. Решение возможных проблем и неполадок.
- Отключение и демонтаж временного оборудования.
Непосредственно миграция заняла всего два дня. Переезд прошёл успешно, все данные заказчика в целости и сохранности. Также сохранилась система управления резервным копированием и интеграция с существующим ПО СРК. Если ранее использовалась связка Commvault c OnCommand Unified Manager, то после перехода на Cluster Mode от неё было решено отказаться в пользу Netapp Open Replication для подключения Commvault напрямую к контроллерам СХД.
Основные рекомендации, которые я могу дать по результатам этой миграции: переходить с 7 mode на Cluster Mode вместе с заменой контроллеров. Если всё-таки планируется переезд на вторые контроллеры, как в описанном выше случае, то необходимо заложить в план достаточно времени на решение различных проблем, которые обязательно возникнут при переезде обратно на старые контроллеры. Использование миграции без перемещения данных с помощью 7MTT CFT вполне безопасная процедура, если её доверить профессионалам.
Полезные руководства, которые использовались в ходе данной миграции:
- Портал Netapp с документацией по ОС ONTAP 9 и ПО 7MTT
- Портал Netapp с документацией по СХД FAS и AFF, раздел про модернизацию контроллеров
- Портал Hardware Universe для определения совместимости оборудования Netapp
- Руководство по Netapp Open Replication, для Commvault
Дмитрий Кострюков, Ведущий инженер-проектировщик систем хранения данных
Центра проектирования вычислительных комплексов «Инфосистемы Джет»
Комментарии (2)

sub31
01.09.2018 22:57Хороший пост. Описан процесс в одном из городов. По второму городу работал другой специалист. Мигрировали профессионально.
Smasher
Хороший пост.
Я бы для осознания масштабов ещё добавил информацию о том, что FAS3250 была снята с продажи в 2014 году, FAS6220 — в 2015, а миграция происходила на версию ONTAP, которая появилась в конце 2016 года. И после 3250, 6220 вышло уже два поколения новых контроллеров.
Переход на ONTAP 9.1 теоретически уберегает заказчика от таких процедур миграций в будущем. Но главное не затягивать с покупкой новых контроллеров. А то может получится так, что не окажется общей поддерживаемой версии ONTAP. Хотя и в таких ситуациях есть не совсем официальные способы расширить кластер. Вот кусок познавательного треда, где люди мигрировали с 3250 на 8200, объединили их в единый кластер, причем 3250 была на 9.1, а 8200 на 9.2, потому что захотели ADP. Кластер из разных версий собрался, данные без даунтайма утекли на 8200.