
Во многих своих фронтендовых проектах я в какой-то момент сталкивался со снижением производительности — обычно такое случается, когда возрастает сложность приложения, и это нормально. Тем не менее, разработчики всё же ответственны за производительность, поэтому в своей статье я дам пять советов по оптимизации приложений, которые применяю сам: какие-то могут показаться очевидными, какие-то затрагивают основные принципы программирования — но, думаю, освежить память лишним не будет. Каждый совет подкреплен тестами: можно запустить их самостоятельно и проверить производительность.
Переведено в Alconost
Предисловие
Запомните: если коду оптимизация не нужна, не лезьте в него. Безусловно, код, который вы пишете, должен работать быстро, и всегда можно придумать более быстрый алгоритм — но написанное должно оставаться понятным для других разработчиков. В лекции «Программирование как искусство» Дональд Кнут высказал очень важную мысль об оптимизации кода:
Настоящая проблема заключалась в том, что программисты тратили слишком много времени в заботах об эффективности в неподходящих местах и в неуместное время. Преждевременная оптимизация — это корень всех ошибок в программировании (или, по крайней мере, большинства).
1. Поиск: вместо обычных массивов — объекты и ассоциативные массивы
При работе с данными часто возникают ситуации, когда нужно, например, найти объект, сделать что-то с ним, затем найти другой объект, и так далее. Наиболее распространенной структурой данных в JS является массив, поэтому хранение данных в них — нормальная практика. Однако всякий раз, когда в массиве нужно что-то найти, приходится использовать такие методы, как «find», «indexOf», «filter», или выполнять итерации с циклами — то есть, нужно перебирать элементы от начала до конца. Таким образом мы выполняем линейный поиск, сложность которого — 0(n) (в худшем случае нам понадобится выполнить столько сравнений, сколько есть элементов в массиве). Если делать такую операцию пару раз на небольших массивах, влияние на производительность будет невелико. Однако если элементов у нас немало, и операция выполняется много раз, производительность обязательно просядет.
В таком случае хорошим решением будет преобразовать обычный массив в объект или ассоциативный массив и выполнять поиск по ключам: в этих структурах доступ к элементам можно получать со сложностью O(1) — у нас будет один вызов памяти, независимо от размера. Повышение скорости работы достигается за счет использования структуры данных, называемой хэш-таблицей.
Протестировать производительность можно здесь: https://jsperf.com/finding-element-object-vs-map-vs-array/1. Ниже приведены мои результаты:
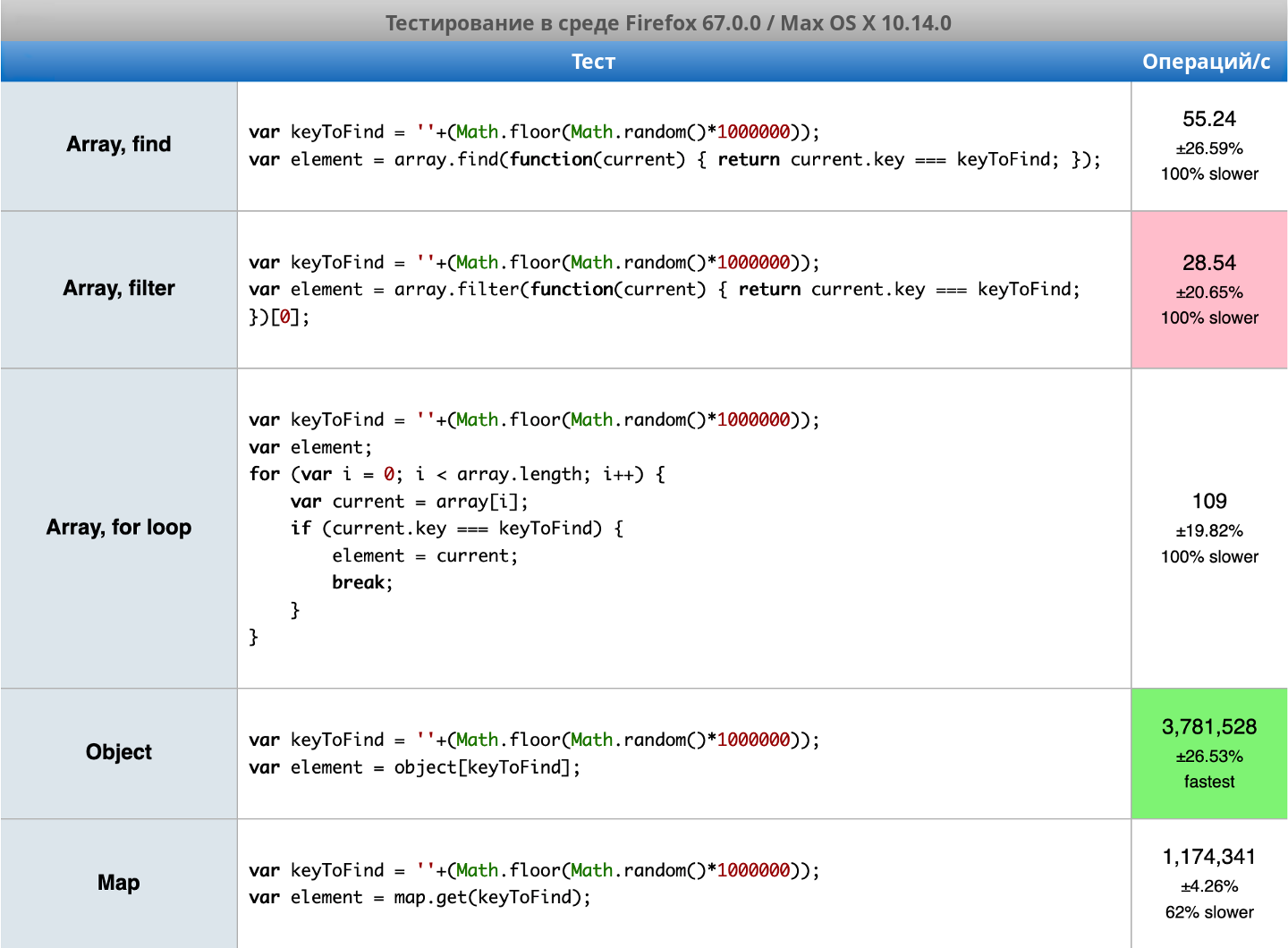
Разница весьма значительна: для ассоциативного массива и объекта у меня получились миллионы операций в секунду, тогда как для массива лучший результат — чуть более сотни операций. Безусловно, здесь не учитывается преобразование данных, но даже с учетом его операция будет выполняться намного быстрее.
2. Вместо исключений — условный оператор «if»
Иногда кажется, что легче пропустить проверку на «null» и просто перехватывать соответствующие исключения. Это, понятно, плохая привычка — так делать не надо, и если у вас в коде такое есть, просто перепишите соответствующие участки. Но чтобы вас окончательно убедить, я подкреплю эту рекомендацию тестами. Я решил проверить три способа выполнения проверок: выражение «try-catch», условие «if» и вычисление «короткого замыкания».
Тест: https://jsperf.com/try-catch-vs-conditions/1. Ниже приведены мои результаты:

Думаю, отсюда очевидно, что выполнять проверку на «null» нужно обязательно. Кроме того, как можно видеть, между условием «if» и вычислением «короткого замыкания» разницы почти нет — к чему душа лежит, то и применяйте.
3. Чем меньше циклов, тем лучше
Еще одно очевидное, но, возможно, небесспорное соображение. Для массивов есть много удобных функций: «map», «filter», «reduce», — поэтому их использование выглядит заманчиво, да и код с ними выглядит аккуратнее и читается проще. Но когда встает вопрос повышения производительности, можно попытаться сократить число вызываемых функций. Я решил разобрать два случая: 1) «filter», затем «map», и 2) «filter», затем «reduce», — и сравнить их с функциональной цепочкой, «forEach» и традиционным циклом «for». Почему именно эти два случая? Из тестов будет видно, что получаемые преимущества могут быть не очень значительными. Кроме того, во втором случае я попробовал также использовать «filter» при вызове «reduce».
Тест производительности для «filter» и «map»: https://jsperf.com/array-function-chains-vs-single-loop-filter-map/1. Мои результаты:

Видно, что один цикл быстрее, но разница невелика. Причина такого небольшого отрыва — операция «push», которая при использовании «map» не требуется. Поэтому в этом случае можно задуматься, действительно ли так уж необходимо переходить к одному циклу.
Теперь давайте проверим «filter» + «reduce»: https://jsperf.com/array-function-chains-vs-single-loop-filter-reduce/1. Мои результаты:

Здесь разница уже значительнее: объединение двух функций в одну ускорило выполнение почти вдвое. Тем не менее, переход на традиционный цикл «for» дает намного более существенный прирост скорости.
4. Используйте обычные циклы «for»
Этот совет тоже может показаться спорным, ведь разработчики любят функциональные циклы: они хорошо читаются и могут упрощать работу. Однако они менее эффективны, чем традиционные циклы. Думаю, вы уже могли заметить разницу в использовании циклов «for», но давайте взглянем на нее в отдельном тесте: https://jsperf.com/for-loops-in-few-different-ways/. Как можно видеть, кроме встроенных механизмов я также проверил «forEach» из библиотеки «Lodash» и «each» из «jQuery». Результаты:

И мы снова видим, что самый простой цикл «for» работает гораздо быстрее остальных. Правда, эти циклы хороши только для массивов — в случае других итерируемых объектов следует использовать «forEach», «for…of» или непосредственно итератор. А вот «for…in» нужно применять, только если других способов нет вообще. Кроме того, помните, что «for…in» принимает все свойства объекта (а в массиве свойства — это индексы), что может привести к непредсказуемым результатам. Удивительно, но методы из Lodash и jQuery оказались не так уж плохи с точки зрения производительности, поэтому в некоторых случаях ими можно спокойно пользоваться вместо встроенного «forEach» (интересно, что в тесте цикл из Lodash сработал быстрее встроенного).
5. Для работы с DOM используйте встроенные функции
Иногда смотришь на чужой код и видишь, что разработчик импортировал jQuery только для манипуляций с DOM — уверен, вам тоже такое встречалось, ведь это одна из популярнейших библиотек JavaScript. Понятно, что в использовании библиотек для управления DOM нет ничего плохого: сегодня мы применяем React и Angular, а они делают то же самое. Однако некоторым иногда кажется, что jQuery нужно использовать даже для простых операций по извлечению элемента из DOM и внесению в него незначительных изменений.
Вот сравнение встроенных функций для DOM и аналогичных операций JQuery в трех различных случаях: https://jsperf.com/native-dom-functions-vs-jquery/1. Мои результаты:
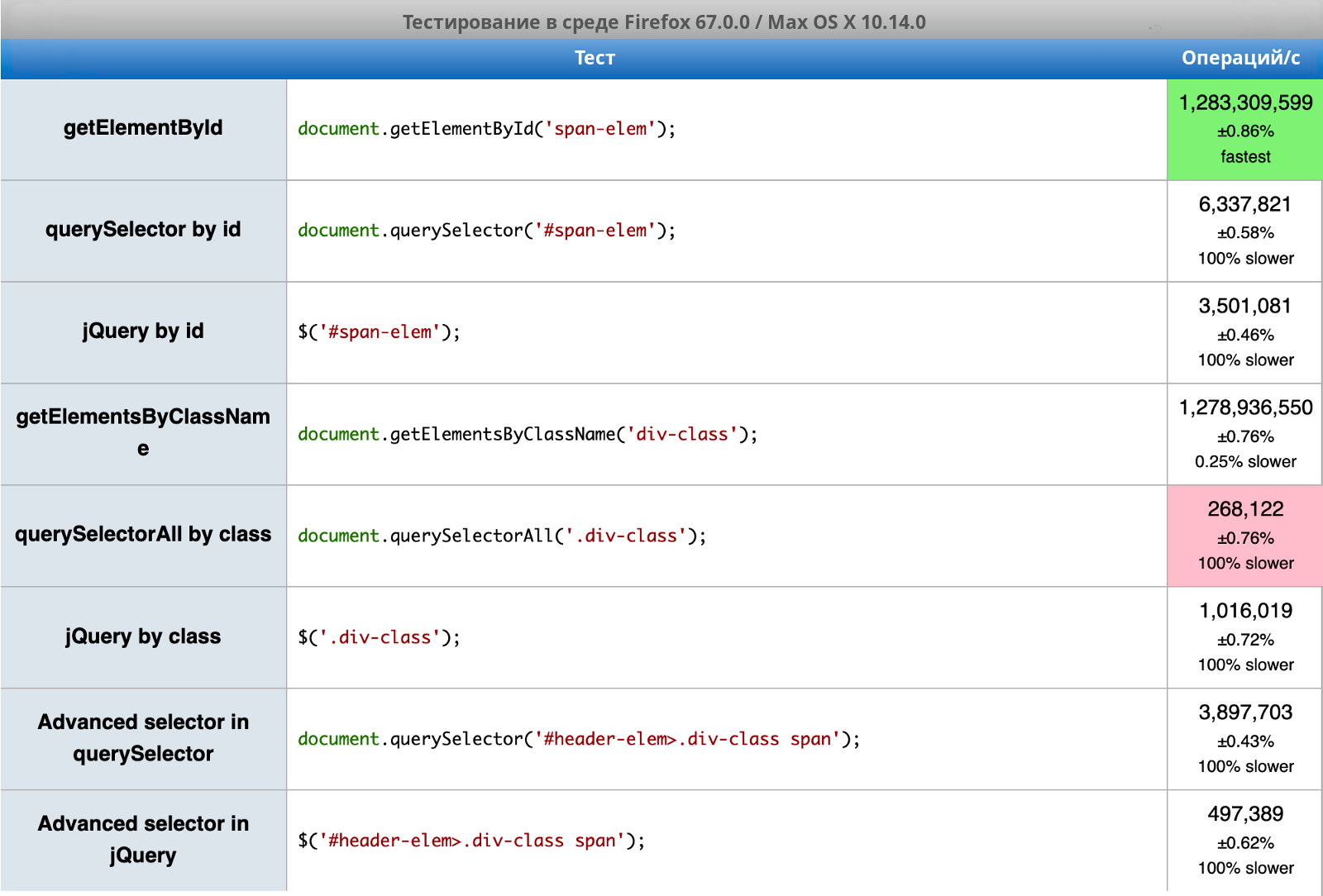
И снова самые базовые функции — «getElementById» и «getElementsByClassName» — при просмотре DOM оказались самыми быстрыми. В случае идентификаторов и расширенных селекторов «querySelector» тоже быстрее, чем jQuery. И только в одном случае «querySelectorAll» медленнее, чем jQuery (получение элементов по имени класса). Подробнее о том, чем и как можно заменить jQuery, смотрите здесь: http://youmightnotneedjquery.com.
Понятно, что если вы уже используете библиотеку для управления DOM, настоятельно рекомендуется придерживаться ее — однако для простых случаев достаточно и встроенных инструментов.
Дополнительные материалы
Приведенные пять советов помогут писать более «быстрый» код на JavaScript. Но если вам интересно почитать об оптимизации производительности подробнее, вот несколько рекомендаций:
1. Оптимизация бандлов JavaScript с помощью Webpack: это очень обширная тема, но если всё сделать правильно, загрузка приложений может значительно ускориться.
2. Структуры данных, основные алгоритмы и их сложность: многие считают, что это «просто теория», однако мы в первом же пункте увидели, как эта теория работает на практике.
3. Тесты на странице jsPerf: здесь можно ознакомиться со сравнением различных способов выполнения одной и той же задачи в JavaScript и при этом увидеть важный на практике показатель — разницу в скорости.
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 70 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
> Подробнее
Комментарии (10)

tuxi
20.06.2019 09:51+1По моему скромному мнению, высокая производительность фронта, частично зависит от грамотности подготовки данных на бекенде. И профилировать бекенд на жту тему гораздо эффективней зачастую. Зачем отдавать списки из тысяч элементов, если контекст уже говорит нам о том, что достаточно отдать 10..20 и уже среди них искать на фронте, хоть по id, хоть перебором.
yarick123
20.06.2019 18:53Полностью с Вами согласен, производительность фронтенда зависит также от бекенда. В то же время, читая заголовок статьи и саму статью, я склоняюсь к мнению, что автор поставил перед собой цель, описать изменения именно во фронтенде, которые позволяют повысить его производительность.
Опять же, даже при вылизанном бекенде, во фронтенде «развернуться» можно о-го-го как. Так что весьма полезно знать, что же делать стоит, а что нет. Из памяти не выходит случай, когда на фронтенде по разным критериям самостоятельно сортировалась таблица идентификаторов за O(n**2). Данные при этом «кэшировались» в неотсортированом массиве. Сложность операции O(n**3) начинала достаточно быстро ощущаться при увеличении n. Вишенка на торте: в таблице могло оказаться больше элементов, чем допускал кэш.
Ещё нам часто приходится писать фронтенд, используя бекенд сторонних фирм, которые вообще никак не реагируют на просьбы оптимизировать его в конкретных местах. Так что нам остаётся ограничиваться только оптимизацией фронтенда, хотя мы и представляем себе, насколько удобнее и зачастую эффективнее профилировать бекенд.
ilya_1986
20.06.2019 11:43Никогда бы не подумал что
вот прям ну настооолько (в 350 с лишним раз) быстрее jQuery-вскогоdocument.getElementById('id');$('#id');
Marwin
20.06.2019 15:53ну справедливости ради… скорость $('#id') всё равно достаточная, если это не миллион вызовов в цикле. Хотя, я, пожалуй, всё же откажусь от $('#id') хотя бы в циклах. Что-то и правда жесть.

CoolCmd
20.06.2019 17:19по поводу 1 200 000 000 операций в секунду… по своему опыту скажу, что когда это число сравнимо с частотой процессора, то с тестом что-то не так. я говорю не о банальном сложении двух чисел, а о вызове DOM функций, которые что-то ищут. например,
getElementByIdможет кэшировать результат последнего вызова. или шибко умный JIT может выкинуть что-то "лишнее". или, как отмечали выше, в DOM дереве всего два идентификатора и основное время занимает проверка параметров (перевод в строку и т.д.).
dom1n1k
22.06.2019 01:50Хотел написать то же самое. Когда jsperf показывает результаты в десятки-сотни миллионов (не говоря уже о миллиардах) операций в секунду — почти наверняка это означает, что тест некорректный.
Spunreal
Иногда лучше пропустить проверку на null и просто перехватить исключение. Есть то, что мы ожидаем и то, чего мы не ожидаем в нормальной работе приложения. Если мы ожидаем null, например, пользователь не включил чекбокс или это значение по умолчанию, то естественно это не исключение.
А если в длинной цепочке вызовов закралась ошибка и вдруг пришел null вместо ID пользователя, хотя тут явно должен был быть ID? Это как раз исключение. Мы выкидываем исключение и ловим его там, где нам надо обработать его (залогировать, сообщить пользователю об этом, откатить транзакцию и т.п.).
Исключения в нормальной ситуации должны происходить довольно редко по отношению к другим событиям. Из-за этого выигрыш будет минимальным.
Можно и микроскопом забивать гвозди, но зачем?