
Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- TResNet: High Performance GPU-Dedicated Architecture (DAMO Academy, Alibaba Group, 2020)
- Controllable Person Image Synthesis with Attribute-Decomposed GAN (China, 2020)
- Learning to See Through Obstructions (Taiwan, USA, 2020)
- Tracking Objects as Points (UT Austin, Intel Labs, 2020)
- CookGAN: Meal Image Synthesis from Ingredients (USA, UK, 2020)
- Designing Network Design Spaces (FAIR, 2020)
- Gradient Centralization: A New Optimization Technique for Deep Neural Networks (Hong Kong, Alibaba, 2020)
- When Does Unsupervised Machine Translation Work? (Johns Hopkins University, USA, 2020)
- 2020 год: Январь — Февраль, Март ч1, ч2
- 2019 год: Январь — Июнь, Июль — Сентябрь, Октябрь — Декабрь
- Декабрь 2017 — Январь 2018, Февраль — Март 2018
- 2017 год: Август, Сентябрь, Октябрь — Ноябрь
1. TResNet: High Performance GPU-Dedicated Architecture
Авторы статьи: Tal Ridnik, Hussam Lawen, Asaf Noy, Itamar Friedman (DAMO Academy, Alibaba Group, 2020)
Оригинал статьи :: GitHub project :: Претренированные модели
Автор обзора: Андрей Лукьяненко (в слэке artgor, на habr artgor)
Чисто инженерная статья как с помощью модификаций архитектуры и оптимизаций производительности достичь высокого качества, не теряя в скорости. На текущий момент версия модели под названием TResNet-XL имеет top-1 accuracy 84.3% на imagenet. Если использовать версию, которая сравнима с Resnet50 по gpu throughput, то top-1 accuracy 80.7%
Мысли о том, почему более продвинутые архитектуры работают медленнее:
- Многие архитектуры используют depthwise и 1х1 convolutions. Это уменьшает FLOPS, но обычно GPU ограничены не количеством вычислений, а затратами на доступ к памяти. Поэтому итоговое улучшение скорости работы не слишком большое.
- Многие архитектуры используют Multi-path, что создаем много карт активаций, которые должны храниться для backpropagation, а это уменьшает максимально возможный размер батча. А ещё из-за этого ограничена возможность делать inplace операции.
Особенности дизайна
Есть 3 варианта архитектуры: TResNet-M, TResNet-L and TResNet-XL. Разница только в глубине и количестве каналов. Авторы сделали следующие улучшения: SpaceToDepth stem, Anti-Alias downsampling, In-Place Activated BatchNorm, Blocks selection and SE layers.
Stem Design
У большинства архитектур в самом начале стоит Stem Block — для быстрого уменьшения размера изображения. Например, в Resnet50 это conv 7x7, stride 2 + maxpooling, это уменьшает 224 до 56. Авторы предлагают слой SpaceToDepth, который по факту делает большую глубину, а после этого накладывают conv 1x1, чтобы получить нужное количество каналов.

Anti-Alias Downsampling
Заменяют все downscaling слой на этот новый слой. Говорят, то увеличивает shift-equivariance и дает лучше трейдофф точности-скорости.

Inplace-ABN
Inplace-ABN заменяет все BatchNorm+ReLU слои. Это уменьшает потребление памяти. Ещё вместо ReLU используют Leaky-ReLU. На практике почти удваивает возможный размер батча, а замена активации повышает качество без увеличения требований по памяти или вычислений.
Blocks Selection
В ResNet34 используются BasicBlocks с conv 3x3, в ResNet50 Bottleneck состоит из двух блоков conv 1x1 и одного conv 3x3 — выше точность, но больше затраты GPU. Здесь решили комбинировать: в самом начале 2 BasicBlock, в самом конце 2 Bottleneck.
SE Layers
Вставляют оптимизированные SE слои на первые 3 stage архитектуры. Оптимизация:
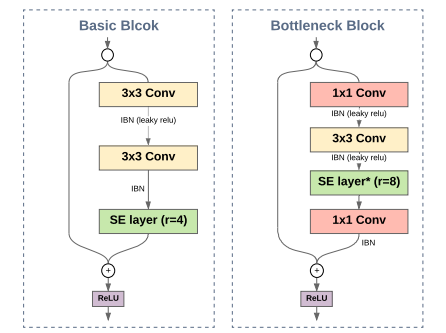
JIT Compilation для слоев, где нет обучаемых параметров — для AA blur filter and the SpaceToDepth. Уменьшает GPU cost этих слоёв в 2 раза.
Ускорение Global Average Pooling
Тупо используют view и mean из Pytorch вместо AvgPool2d и получают ускорение до 5 раз
Inplace Operations
Используют их везде, где возможно: Inplace-ABN, residual connections, SE blocks, activations и так далее. Это сильно увеличивает максимально возможный размер батча.
Эксперименты:
Изображения 224х224, 300 эпох, SGD и 1-cycle policy. Регуляризация: Auto-augment, Cutout, Label-smooth and Trueweight-decay. Ещё нормализация изображений не по статистикам ImageNet, а просто чтобы значения были от 0 до 1. Так тренировали Resnet50 и разнообразные вариации TResNet.

Ablation Study
Больше всего качества докинули SE слои и AA. Скорость докинули остальные три изменения.
2. Controllable Person Image Synthesis with Attribute-Decomposed GAN
Авторы статьи: Yifang Men, Yiming Mao, Yuning Jiang, Wei-Ying Ma, Zhouhui Lian (China, 2020)
Оригинал статьи :: GitHub project :: Blog :: Video
Автор обзора: Евгений Кашин (в слэке digitman, на habr digitman)
Генерация людей, закондишенная на позу и "части тел" других людей. На вход одна фотография человека, целевая поза и референсные фотографии других людей, от которых хотим взять одежду. На выходе — исходный человек в целевой позе и с одеждой (футболка, штаны, обувь) выбранных людей. Дополнительно к этой фиче получили еще и буст по качеству генерации тел.
Модель из двух энкодеров, первый кодирует позу, второй — текстуры целевых частей тела. В генераторе это соединяется. Для обучения нужно две фотографии одного человека в одной одежде, но разных позах.

Берут 2 фото человека, пытаются из одной (сорс картинки I_s) сделать вторую(таргет I_t). На вход текстурному энкодеру подается исходная фотография человека и семантическая сегментация тела, полученная с претрейн сегментатора. На вход поуз энкодеру подается 18 кейпоинтов целевой позы P_t для этого же человека (из претрейн поуз детектора). Pose encoder состоит просто из 2х downsampling блоков.
Для каждой части тела (всего 8, берется ее маска, выделяется по ней кусок изображения и подается по отдельности в текстурный энкодер. Энкодер одинаковый для всех частей тела. Полученные эмбеддинги для разных кусков человека конкатенируются, получается style code. Если просто его использовать дальше, получалось плохо, поэтому сверху обмазали еще тремя полносвязными слоями.
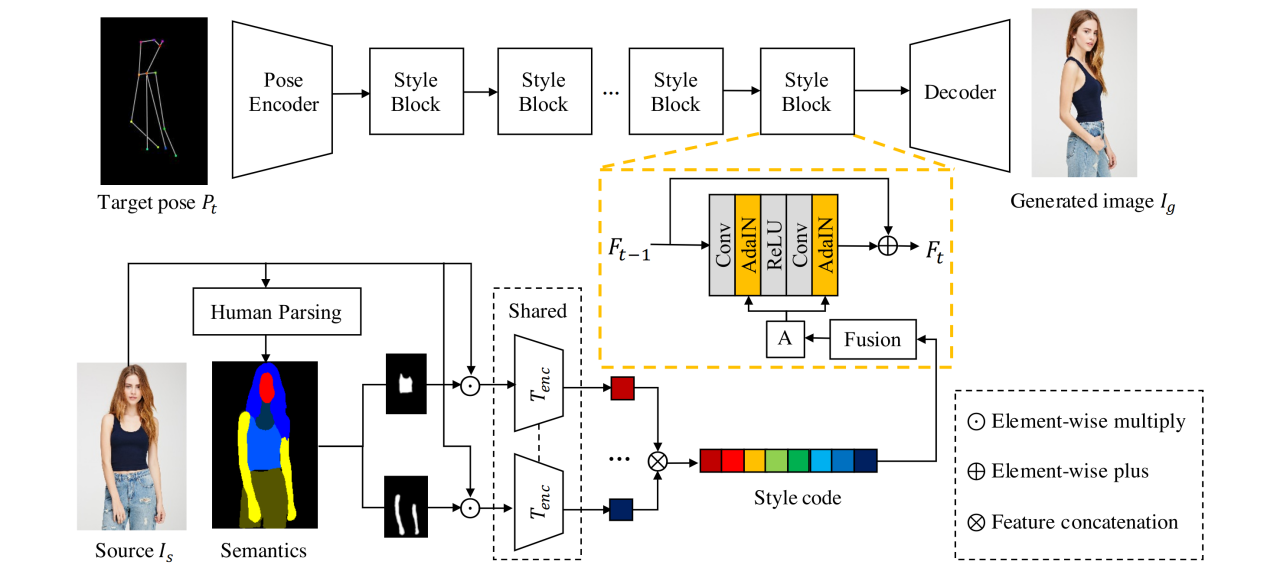
Архитектура texture encoder хитрая: половина — это обучаемый энкодер, вторая половина — замороженный vgg, на каждом слое к активации обучаемого энкодера конкатятся активации vgg.
Получив style code от текстур и какое-то представление для целевой позы, нужно это соединить. Соединяют уже ставшим классикой методом — StyleBlock с AdaIN (как в StyleGAN). Всего 8 таких блоков. После это несколько апсемплинг блоков — и получается сгенерированная картинка I_g.
Два дискриминатора. Один проверяет соответствие сгенерированной картинки и таргет позы. Второй — сгенерированной картинки и исходной картинки(чек на текстуры). И тот и тот — PatchGAN дискриминаторы, которым на вход подается конкат двух картинок.
Лоссы. Adversarial loss-ы от двух дискриминаторов. Reconstruction loss — l1 между выходом и таргет картинкой. Perceptual loss — l2 между Грамм матрицами vgg фичей выхода и таргета. Contextual loss (CX) — измеряет похожесть двух даже не выровненных изображений(считается по хитрому через VGG фичи, не учитывая их пространственную составляющую).
Датасет — DeepFashion. Проверялись как по вычисляемым метрикам, так и по юзер стади, всех побили по реалистичности картинки.

Что интересно, их подход позволяет интерполировать отдельные атрибуты. Линейно меняя значение от одной футболки до другой, получается достаточно плавное перетекание. На странице проекта классная гифка. Там же есть гифка по анимации человека по движению скелета, выглядит не топ, но они и не решали специально задачу для видео, статика выглядит красиво.
3. Learning to See Through Obstructions
Авторы статьи: Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang (Taiwan, USA, 2020)
Оригинал статьи :: GitHub project :: Blog
Автор обзора: Александр Бельских (в слэке belskikh)
Новый подход к удалению препятствий (отражений, мелких преград, бликов и т.п.) с фона, используя последовательность кадров с перемещением относительно фона. Предобучается на синтетике, файнтюнится на реальных данных, результаты — сота. Сочетает в себе классические подходы, основанные на optical flow, и нейронные сети.
Алгоритм представляет собой coarse to fine multi stage подход, когда модели постепенно обучаются на изображениях всё большего и большего качества, а инпутом следующих стадий служат аутпуты предыдущих. В основе алгоритма лежит предсказание optical flow фона и препятствий из последовательности кадров с перемещением фона, который подаётся в сеть, генерирующую очищенное изображение.
Весь алгоритм делится на три основные части:
Initial Flow Decompositon
Здесь предсказывается OF для фона и препятствий на самом грубом уровне изображений. Сеть тут состоит из двух сабмодулей: экстрактор фичей и flow estimator. Экстрактор сначала генерирует для всех инпут фреймов фичемапы, а затем создает cost volume (работа Cnns for optical flow using pyramid, warping, and cost volume), используя специальный корреляционный слой, который выдаёт представление локальных корреляций между фичемапами разных кадров. Flow Estimator глобал пулит из этих фичей и подаёт в FC слой, чтобы сгенерить два вектора движения, из который получается initial flow, который будет использоваться в следующем модуле, а также грубые реконструкции фона и препятствий.
Background/Reflection Layer Reconstruction
Тут обучаются две независимые сети одинаковой архитектуры, одна на предсказание фона, а другая на предсказание препятствий. На вход поступают восстановленные изображения фона и препятствий с предыдущей стадии, optical flow, набор кадров, а также ключевой кадр. Они комбинируются и подаются в сеть генератор, которая предсказывает уже очищенное изображение.
Optical Flow Refinement
Чтобы получить optical flow на этом этапе используется предобученная PWC-Net.
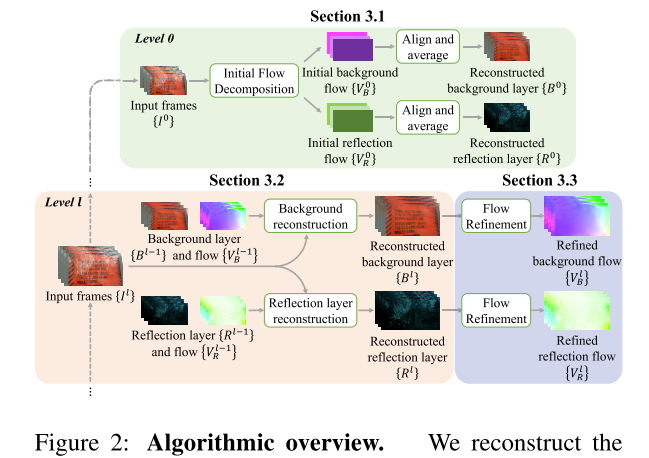

Обучение происходит в две стадии — сначала обучается первая часть про initial flow, накидывается L1 лосс на аутпут, за таргет берётся предикт PWC-Net.
Затем первая часть замораживается, и обучаются остальные сети, лоссами служат L1 reconstruction loss и gradient loss (L1 между градиентами изображения-предикта и изображения-таргета. НЕ градиенты сеток). Эта часть проходит на синтетике, так как только тут можно получить много данных с разделением слоёв фона и препятствий. Дообучение на реальных происходит в unsupervised режиме.
Накидывается L1 лосс на разность между исходным изображением и суммой фона и препятствий, предсказанных обученной моделью (в идеале это должен быть 0). Также докидывается total variation loss.

4. Tracking Objects as Points
Авторы статьи: Xingyi Zhou, Vladlen Koltun, Philipp Krahenbuhl (UT Austin, Intel Labs, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Использование немного подхаченного CenterNet с постпроцессингом и сильными аугментациями позволило создать легковесный трекер, показавший соту на нескольких датасетах в почти риалтайме.
Авторы взяли за основу статью Objects as Points, где был представлен CenterNet — anchorbox free object detector, показавший на время выхода соту по детекции. Его суть в том, что объекты моделируются как точки на хитмапах, а размеры — это регрессия ширины и высоты в этих точках.
Авторы проделали несколько простых модификаций, чтоб сделать из детектора трекер:
- добавили в инпут предыдущий фрейм;
- добавили в инпут class-agnostic хитмапу детекций всех предыдущих кадров (получена рендером через Гаусс, по аналогии с тем, как генерятся предикты центров в CenterNet);
- добавили на каждый класс аутпут оффсета точки — предсказывают смещение между двумя кадрами; из этих аутпутов и набирается инпут из предыдущего пункта.
Ассоциация между кадров происходит в очень простом жадном режиме — если в некоем пространстве вокруг точки уже был такой же класс, то считаем, что это тот же самый объект (если классов несколько, то выбираем самый уверенный).
Также авторы использовали очень жёсткие аугментации, чтобы получать хорошие карты оффсетов:
- локально смещали точку-центр из ground truth, добавляя гауссовый шум
- случайно добавляли false positives рядом с ground truth объектами
- случайно добавляли false negatives, удаляя детекции.
Так как в основе всего — детектор CenterNet, то они не учили сеть с нуля, а взяли предобученный детектор, рандомно инициализировав веса добавленных тензоров.

Процесс обучения с жёсткими аугами оказался настолько хорош, что позволяет учить трекер на датасете статических изображений, симулируя движение между кадрами через ауги со смещением и скалированием изображения.
Результаты — 67.3% MOTA on the MOT17 challenge at 22 FPS and 89.4% MOTA on the KITTI tracking benchmark at 15 FPS.

Так как CenterNet может и в monocular 3D detection, авторы заимплементили и 3D tracking в похожем сетапе, получив и там сильный прирост относительно бейзлайна.
Сравнив с другими моделями движения (Kalman, Optical Flow), авторы обнаружили, что они почти все перформят практически одинаково, даже если вообще не применять никакую модель.
Но их подход с добавлением оффсетов немного докидывает на некоторых задачах, так что они делают вывод, что они таким образом энкодят не только движение, но и что-то ещё.
Похоже, эра anchor box детекторов потихоньку кончается.
5. CookGAN: Meal Image Synthesis from Ingredients
Авторы статьи: Fangda Han, Ricardo Guerrero, Vladimir Pavlovic (USA, UK, 2020)
Оригинал статьи
Автор обзора: Евгений Кашин (в слэке digitman, на habr digitman)
Генерация еды по списку ингредиентов. Хитрая фильтрация текстового датасета, атеншн после лстм, сайкл консистенси, мультискейл генератор.

Сначала отдельно предобучают текстовый и картиночный энкодеры. Текстовый энкодер — bidirectional LSTM, на вход word2vec эмбединги слов, после LSTM агрегация через attention. Картиночный энкодер — ResNet50, претрейн Imagenet, файнтюн на UPMC-Food-101. Эти энкодеры обучаются мапить в "FoodSpace" на триплетах ["ингридиенты", "фото подходящего блюда", "фото рандомного блюда"]. Дальше эти энкодеры замораживают.

Дальше берут ингредиенты, получают эмбединг от текстового энкодера p+. Его подают в отдельный полносвязный слой, который предсказывает параметры для Гауссовского распределения. На распределение регуляризатор, чтобы было ближе к стандартному Гауссовскому. Как я понял, этот костыль нужен от оверфита, иначе бы дальнейшая часть пайплайна оверфитилась под конкретные вектора, а теперь они немного случайные.

После того, как из предсказанного Гауссовского распределения засемплили вектор 'c', его подают в трехуровневый генератор, который на каждом уровне генерирует скрытый вектор из предыдущего вектора и вектора 'c' и на каждом уровне генерирует картинку (64, 128, 256).Соответственно для каждого уровня свой дискриминатор. У каждого дискриминатора три задачи:
- классифицировать вектор ингредиентов и соответствующую ему реальную картинку как "реальное";
- классифицировать вектор ингредиентов и НЕ соответствующую ему реальную картинку как "фейк";
- классифицировать сгенерированную по вектору картинку как "фейк".
Используются conditional лоссы, т.к. для всех учитывался вектор 'c'. Еще костыль — добавили unconditional лоссов (реальные картинки как "реальный", сгенерированные как "фейк").
Чтобы заставить генерироваться все входные ингредиенты, они добавили cycle-consistency (похоже просто адвесериал лосса не хватило). Берут реальную картинку v+, получают ее эмбединг q+, т.к. знают ингредиенты, то могут сгенерировать фейковое изображение(на разных скейлах) v~+ и получить его эмбединг q~+. Ну а дальше нужно максимизировать косинусное расстояние между реальным и сгенерированными эмбедингами: L_ci = cos(q+, q~+).
Финальный лосс генератора:
16к уникальных ингредиентов они фильтровали до топ 4к, и потом еще мерджили похожие всякими эвристиками и даже людьми. В итоге словарь сократили до 1989 ингредиентов, что вроде как существенно повлияло на качество.
Для измерения качество помимо FID и IS использовали метрики ранжирования — по сгенерированному блюду ранжировали рецепты и смотрели, где исходный рецепт.
Аттеншн хоть и выдает разумные значения для ингредиентов, но скор не улучшает. Но они все равно оставили его для вязкости.
Пример интерполяции между рецептами ниже:

6. Designing Network Design Spaces
Авторы статьи: Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollar (FAIR, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Новая работа по поиску архитектур сетей, которая выходит на один мета-уровень выше — теперь происходит поиск не самой удачной архитектуры, а самого удачного пространства поиска. Процесс поиска выполнен в ручном режиме путём последовательного упрощения большего пространства и накладывания ограничений.
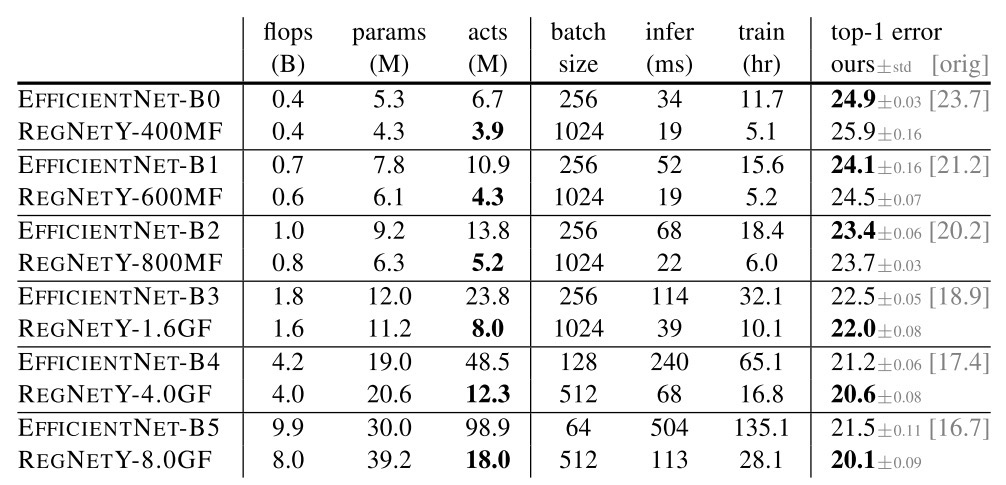
В процессе были подтверждены некоторые существующие паттерны дизайна архитектур и найдены новые контринтуитивные. Полученные архитектуры RegNets перформят лучше аналогичных по FLOPs EffNet сетям, но при этом до х5 раз быстрее инферятся.

Суть подхода в том, чтобы искать не лучшую модельку в определенном пространстве поиска, а найти такое пространство поиска, в котором будет как можно больше хорошо работающих архитектур.
Уже были работы, показывающие, что рандомно насэмплированные архитектуры из хорошего пространства перформят примерно так же, как и те, которые сложным RL доставали из этого пространства.Этим же способом и пользуются авторы — сэмплируют из пространства поиска архитектуры, обучают их и рассматривают это как статистическое распределения, такие распределения можно сравнивать между собой и делать выводы о пространствах поиска. За основную метрику авторы взяли empirical distribution function, которая показывает, сколько процентов сеток из выборки имеют ошибку ниже определенного трешхолда.
Построив такую кривую для всех трешхолдов, по площади оценивается качество пространства (аналог ROC AUC). Сам процесс оптимизации пространств поиска авторы проводили вручную путем поэтапного вдумчивого анализа и упрощения, начиная с очень богатого пространства поиска.
Для начала определили обширное пространство поиска (10^18 вариантов архитектур), названное AnyNet.
У него простая структура:
- у сети есть части stem, body и head;
- у body есть 4 stage;
- каждый stage состоит из нескольких block. Блоки основаны на обычных резнет блоках, состоят из 1х1, 3х3, 1х1 блоков с residual коннектом, внутри групп конволюции, батчнорм и релу.
Это всё добро запараметризировано следующими параметрами в каждом stage:
- количество блоков (d);
- ширина блоков (w);
- bottleneck ratio (b);
- ширина группы в group convolution (g).

Дальше, анализируя графики EDF (empirical distributionfunction), а также различные внутренние распределения параметров сети, авторы последовательно урезают пространство поиска, пытаясь получить там всё более и более устойчивые архитектуры.
Итеративный список упрощений:
- Общий размер ботлнека для всех блоков.
- Общий размер групп для всех блоков.
- Обнаружили, что у лучших сеток в каждом следующем stage ширина слоя увеличивается, так что наложили и такое ограничение — ширина следующего слоя больше или равно предыдущему.
- То же самое проделали и для глубины стейджей.
После всех этих улучшений обнаружили, что усреднение скорости роста ширины слоёв от глубины ложится на некоторую линейную модель, зафитив коэффициенты которой авторы наложили ещё одно ограничение на рост ширины по стейджам. Эти-то изменения и легли в основу упрощенного пространства RegNet
Дальше они провели ещё более подробный анализ уже RegNet пространства и обучили оттуда лучшие модели. Они специально не применяли разные трюки обучения вроде DropPath, AutoAugment и т.п., только weight decay.
В результате были получены архитектуры, которые, имея то же количество флопсов, что и Efficient Nets, перформят лучше по точности (Efficient Nets обучались здесь с нуля в том же сетапе, то есть результаты их хуже, чем в статье, так как трюки обучения не юзали), и быстрее по времени инференса и обучения
От автора обзора: Пейпер очень рекомендую к прочтению, так как там подробно описан весь процесс ресерча и читается как детективный роман. Думаю, на базе этой работы будет много новых NAS архитектур.
7. Gradient Centralization: A New Optimization Technique for Deep Neural Networks
Авторы статьи: Hongwei Yong, Jianqiang Huang, Xiansheng Hua, Lei Zhang (Hong Kong, Alibaba, 2020)
Оригинал статьи :: GitHub project
Автор обзора: Александр Бельских (в слэке belskikh)
Метод «улучшения» градиентов, заключающийся в их центрировании (среднее = 0), имплементится в одну строчку, почти ничего не стоит вычислительно, даёт стабильный прирост на множестве картиночных датасетов на задачах классификации и детекции/инст сегментации.
Суть подхода очень простая — берётся матрица (тензор) градиентов слоя (кернела), для каждого столбца (слайса) считается среднее, вычитается из каждого значения столбца, т.е. столбец центрируется, чтоб иметь нулевое среднее. Отдельной заметкой есть замечание, что полная нормализация не даёт хорошего результата, только центрирование.
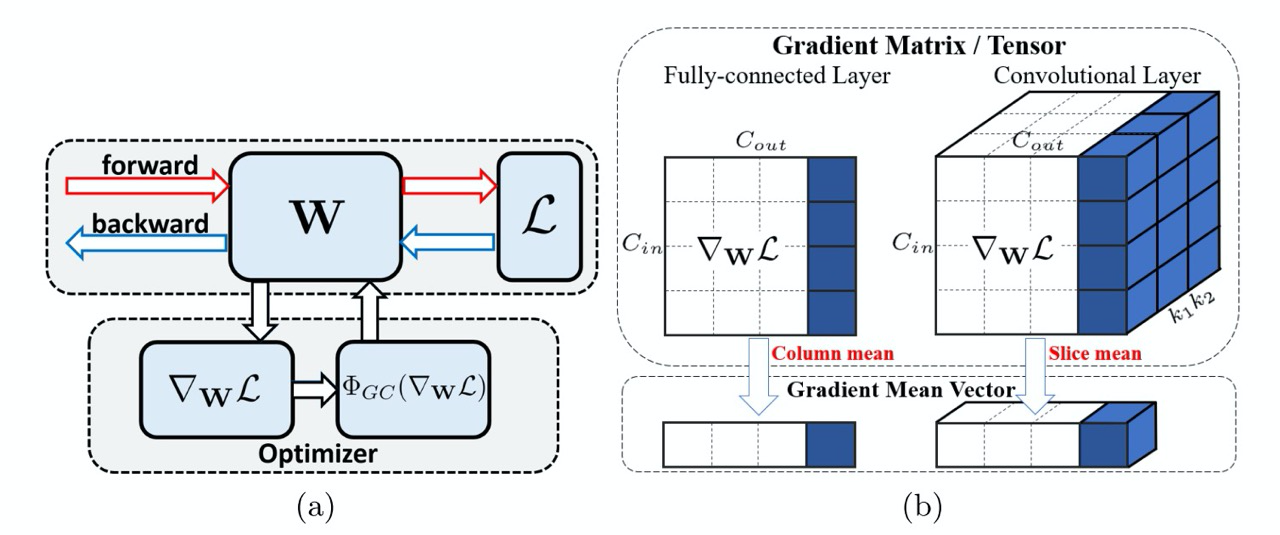
Авторы приводят ряд теоретических обоснований, почему этот подход работает и улучшает стабильность обучения:
Регуляризация пространства весов. Приводится геометрическая иллюстрация, где показано, что шагая в пространстве центрированных градиентов, мы накладываем регулязиционный эффект на пространство весов, уменьшая возможность оверфита.

Регуляризация пространства выходных признаков. Авторы показывают, что если использовать предложенный метод, то инициализированные одним из современных методов веса (например — Kaiming, или просто взятые претреном), имеющие по дефолту нулевое среднее, в процессе обучения будут также сохранять среднее в районе нуля, что делает сеть менее чувствительной к разбросу входных фичей.
Математически доказывают, что предложенный метод приводит к лучшей Липшицности, так что гиперплоскость лосса становится ещё более гладкой (как с батчнормом и weight standartization). Есть теорема с доказательством в Аппендиксе.
Снижение вероятности взрыва градиентов. В доказательство приводят графики L2 и макс значения градиентов с и без предложенного метода. С их методом оба значения в среднем ниже, так что взрываться должно пореже.

Метод показал стабильный прирост на датасетах Mini-Imagenet, CIFAR100, ImageNet, ВАСМб Cars, Dogs, CUB-200-2011, COCO.

8. When Does Unsupervised Machine Translation Work?
Авторы статьи: Kelly Marchisio, Kevin Duh, Philipp Koehn (Johns Hopkins University, USA, 2020)
Оригинал статьи
Автор обзора: Евгений Желтоножский (в слэке evgeniyzh, на habr Randl)
Авторы изучают проблему Unsupervised Machine Translation (UMT). За последние несколько лет, начиная с работы Lample et al. 2018 такие подходы добились неплохих результатов (Bai et al. 2020 получает 30+ BLEU — метрика которая считает взвешенную долю совпадающих n-грам). Но все это методы используют похожие языки (английский, немецкий, французский), корпуса с общим domain и большим объемом высококачественных данных. Авторы проверяют важность каждого из этих компонентов.
Базовая идея UMT довольно элегантна и показана на картинке ниже. Мы тренируем encoder-decoder для каждого из языков и пытаемся получить общий latent space используя обе модели: с помощью модели из предыдущей эпохи переводим предложение, а потом пытаемся перевести его назад.
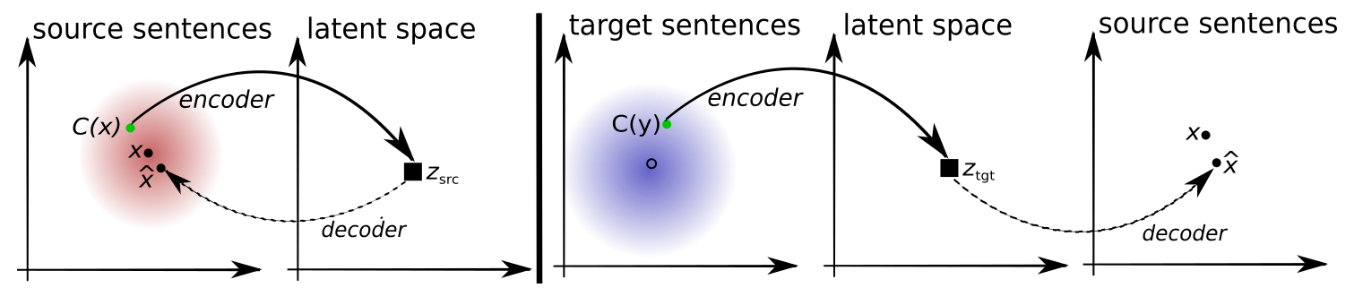
Авторы используют несколько корпусов из разных domains (UN =United Nations, CC = Common Crawl, News = Newscrawl) и на разных языках (русский, английский, французский, сингальский и непальский).
Для начала авторы воспроизводят результаты предыдущих работ, в частности, Artetxe et al. 2019 с небольшими модификациями.
Следующий этап — сравнение двух пар языков (французский-английский и русский-английский) с разными датасетами. При использовании параллельных корпусов разница с supervised training всего несколько пунктов. При использовании непересекающихся частей параллельных корпусов (то есть половина данных на одном языке, а вторая — на другом), качество падает еще на несколько пунктов, причем для русского падение почти вдвое больше чем для французского. Наконец, использование корпусов из разных domains практически полностью ломает всю систему.

Наконец, при попытке обучаться на действительно редких языках, сильно отличающихся от английского (сингальский и непальский), где мы действительно хотели бы использовать UMT, авторы получили очень плохие результаты (падение с 10-20% до 1%).
Кроме того, авторы проводят сравнение точности перевода отдельных слов и замечают что в случае разных domains для французского и СС для русского, стабильность обучения довольно низкая (в половине случаев просто ничего не сходится, а в половине получается приличный скор).
Также продемонстрировано наличие корреляции между точностью перевода отдельных слов и конечной метрикой (BLEU).