Публикации с тегом Spark
SPARK для «малышей»

Python streaming (spark+kafka)
Оптимизируем параметры запуска приложения Spark. Часть первая

3 способа запуска Spark в Kubernetes из Airflow
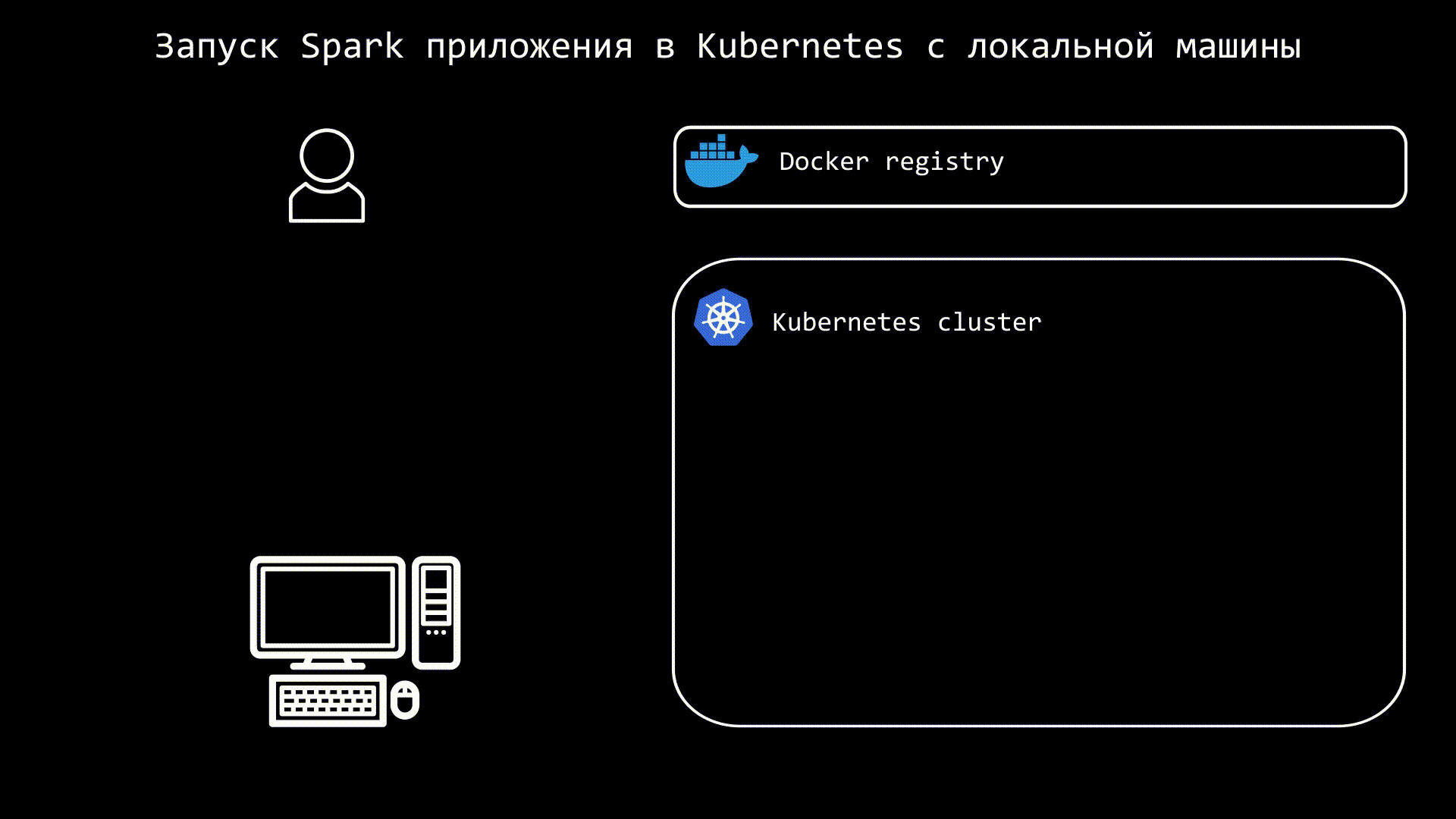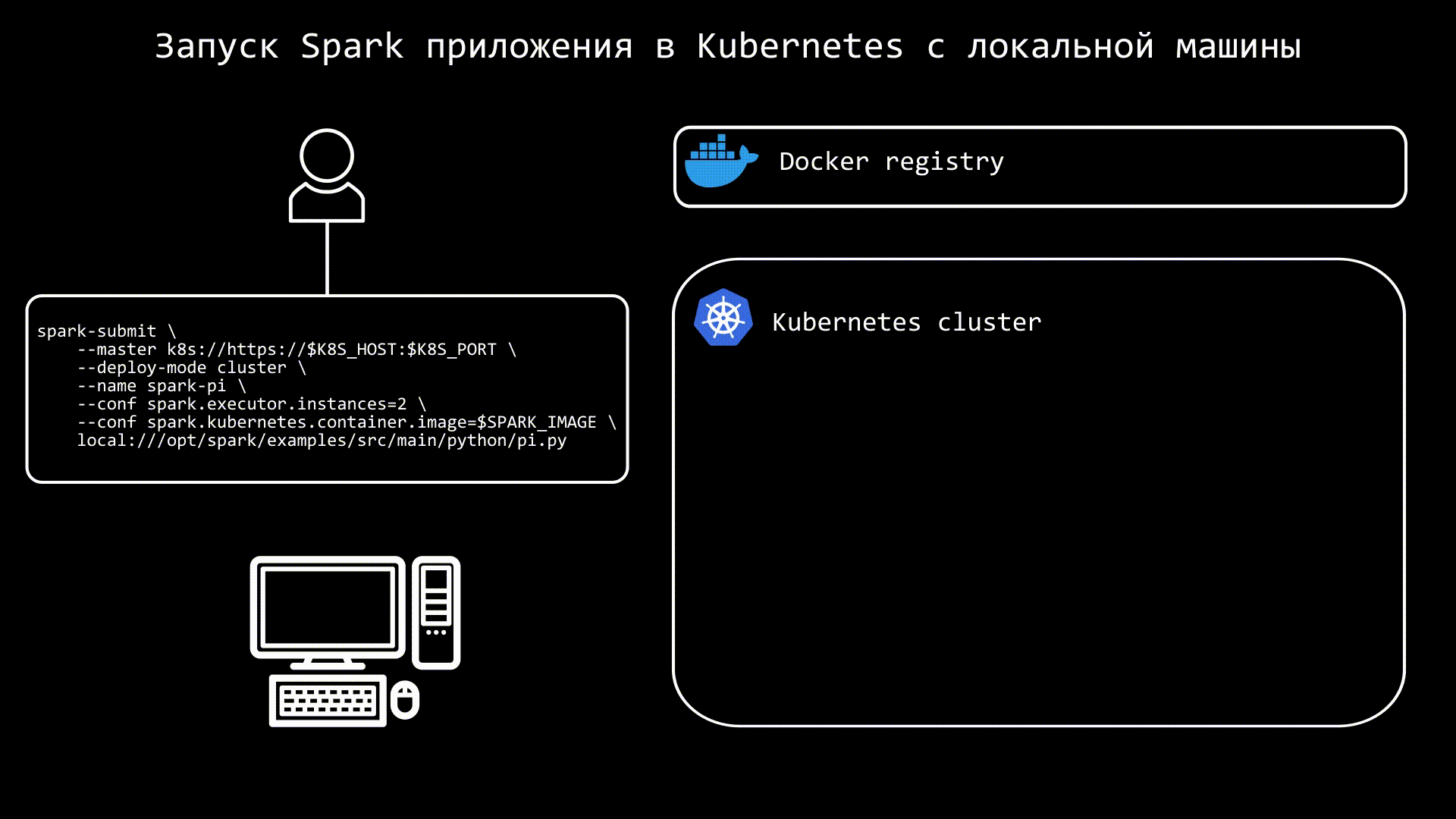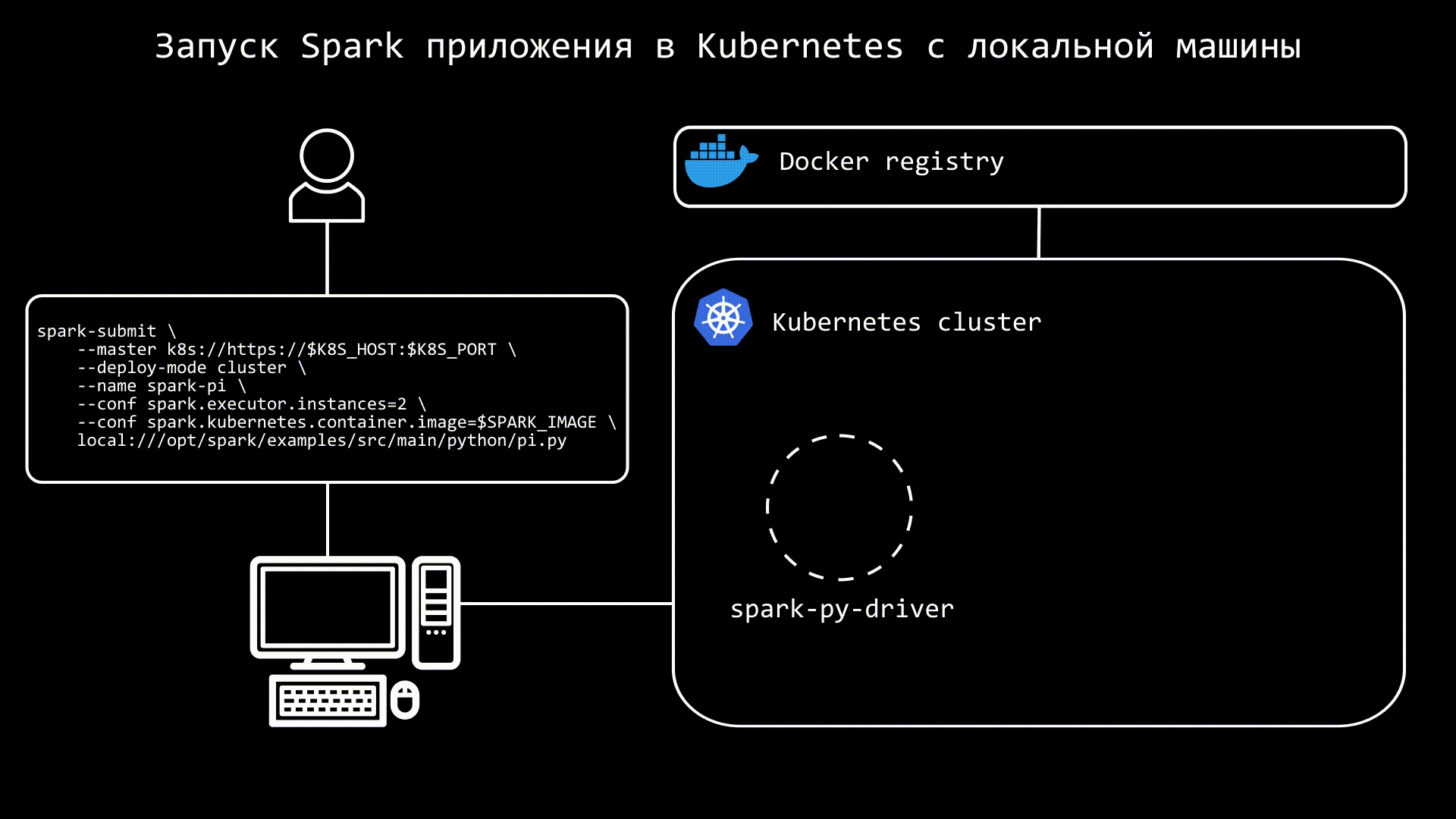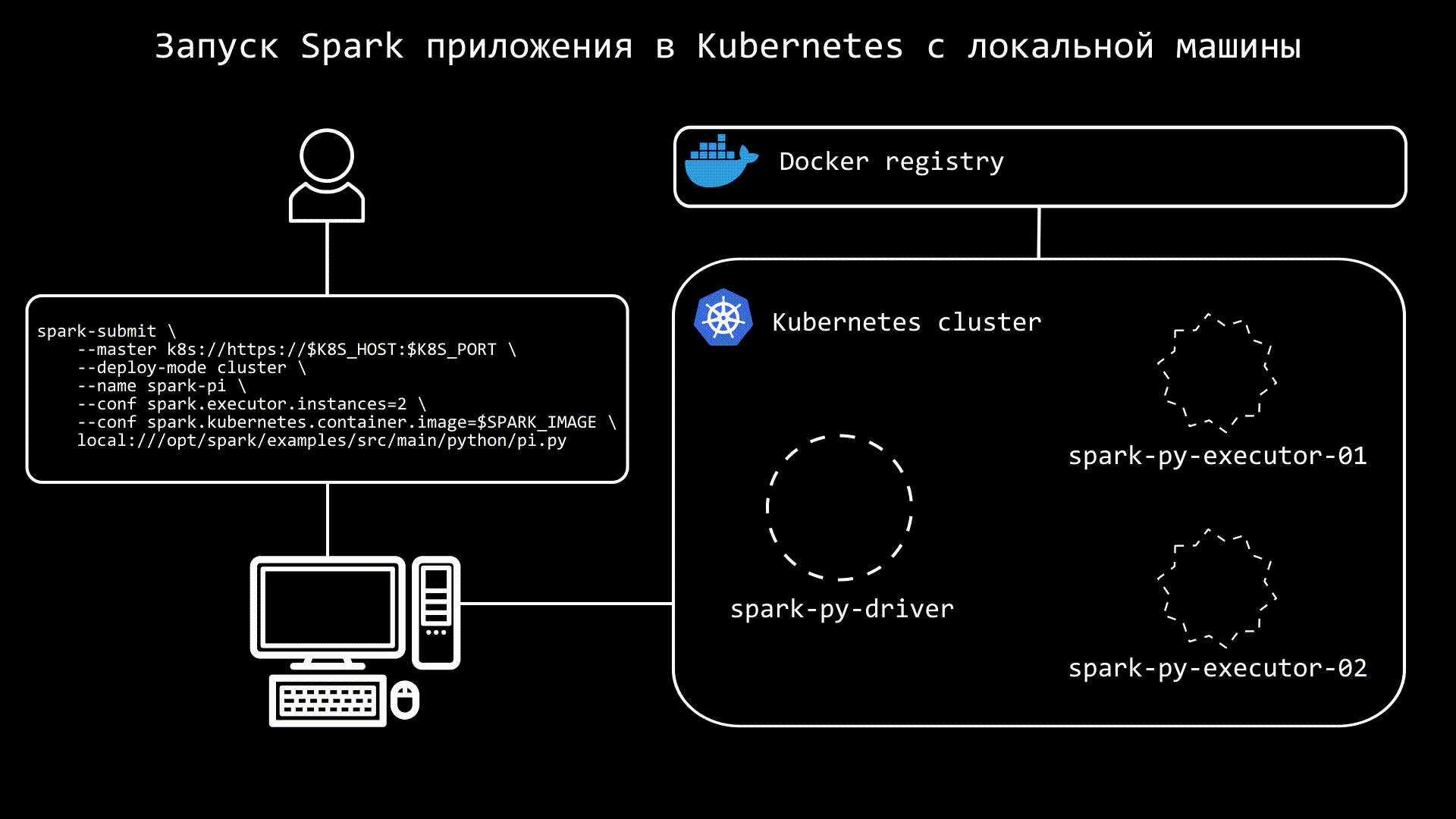
Что такое MLOps и как мы внедряли каскады моделей

Как сделать Spark в Kubernetes простым в использовании: опыт команды VK Cloud

Spark не для чайников: где?

Apache Spark… Это база +1

Дежурный data-инженер: рабочие хроники +9

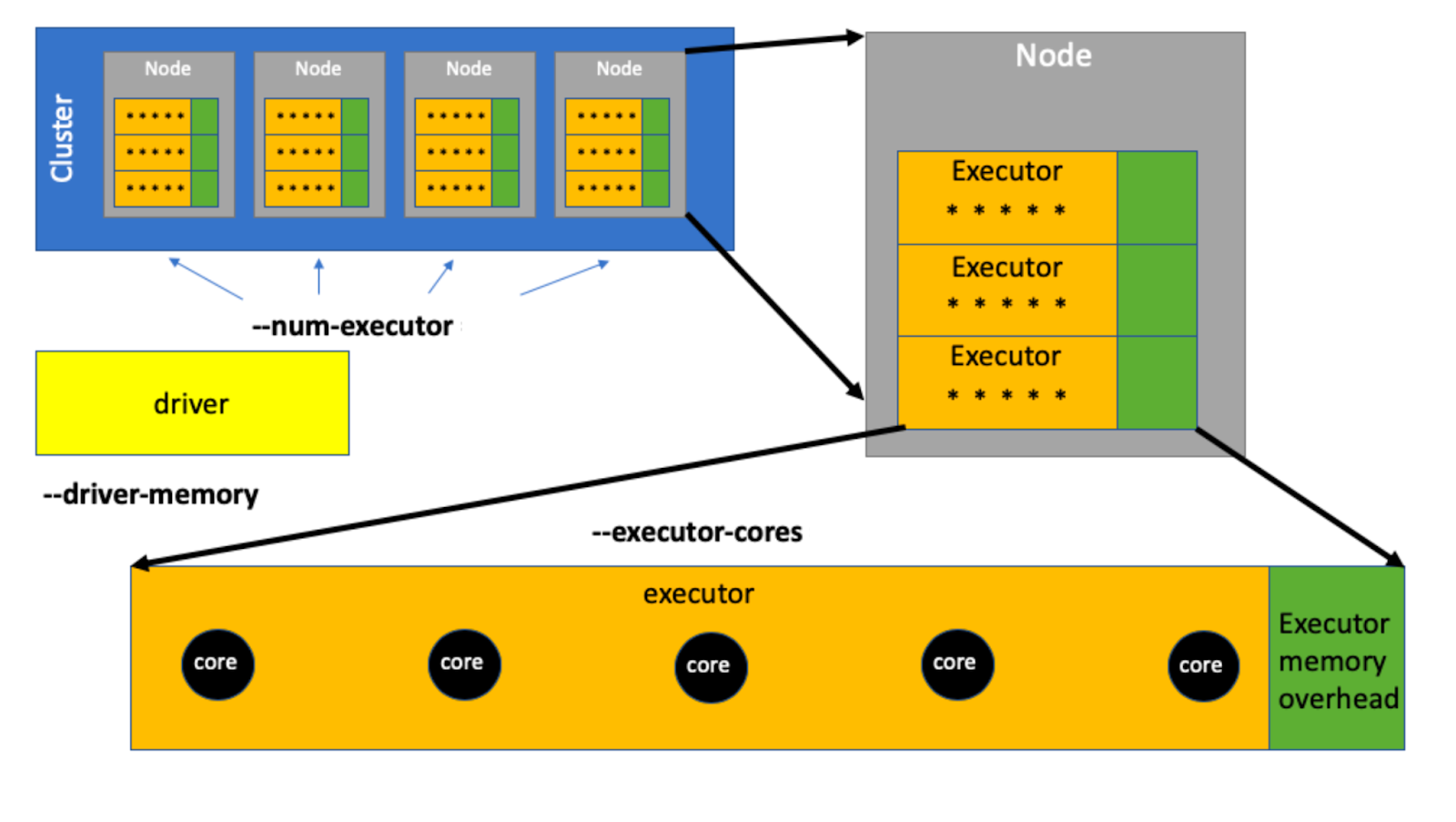
Подбираем параметры сессии в Apache Spark, чтобы не стоять в очереди +12
Руководство для начинающих по Spark UI: Как отслеживать и анализировать задания Spark +4

Apache Spark и PySpark для аналитика. Учимся читать и понимать план запроса в SparkUI +8

Пять подходов к созданию ad-hoc-датафреймов в PySpark +10

Стайлгайд PySpark: как сделать код элегантным +10
