
Реактивное программирование — один из самых актуальных трендов современности. Обучение ему — сложный процесс, особенно если нет подходящих материалов. В качестве своеобразного дайджеста может выступить эта статья. На конференции РИТ++ 2020 эксперт и тренер Luxoft Training Владимир Сонькин рассказал о фишках управления асинхронными потоками данных и подходах к ним, а также показал на примерах, в каких ситуациях нужна реактивность, и что она может дать.
В первой части статьи рассказывалось о том, что привело к появлению реактивного программирования, где оно применяется, и что нам может дать асинхронность. Пришло время рассказать о следующем шаге, позволяющем получить максимум преимуществ от асинхронности, и это — реактивное программирование.
Reactivity
Реактивное программирование — это асинхронность, соединенная с потоковой обработкой данных. То есть если в асинхронной обработке нет блокировок потоков, но данные обрабатываются все равно порциями, то реактивность добавляет возможность обрабатывать данные потоком. Помните тот пример, когда начальник поручает задачу Васе, тот должен передать результат Диме, а Дима вернуть начальнику? Но у нас задача — это некая порция, и пока она не будет сделана, дальше передать ее нельзя. Такой подход действительно разгружает начальника, но Дима и Вася периодически простаивают, ведь Диме надо дождаться результатов работы Васи, а Васе — дождаться нового задания.

А теперь представьте, что задачу разбили на множество подзадач. И теперь они плывут непрерывным потоком:

Говорят, когда Генри Форд придумал свой конвейер, он повысил производительность труда в четыре раза, благодаря чему ему удалось сделать автомобили доступными. Здесь мы видим то же самое: у нас небольшие порции данных, а конвейер с потоком данных, и каждый обработчик пропускает через себя эти данные, каким-то образом их преобразовывая. В качестве Васи и Димы у нас выступают потоки выполнения (threads), обеспечивая, таким образом, многопоточную обработку данных.

На этой схеме показаны разные технологии распараллеливания, добавлявшиеся в Java в разных версиях. Как мы видим, спецификация Reactive Streams на вершине — она не заменяет всего, что было до нее, но добавляет самый высокий уровень абстракции, а значит ее использование просто и эффективно. Попробуем в этом разобраться.
Идея реактивности построена на паттерне проектирования Observer.

Давайте вспомним, что это за паттерн. У нас есть подписчики и то, на что мы подписываемся. В качестве примера здесь рассмотрен Твиттер, но подписаться на какое-то сообщество или человека, а потом получать обновления можно в любой соцсети. После подписки, как только появляется новое сообщение, всем подписчикам приходит notify, то есть уведомление. Это базовый паттерн.
В данной схеме есть:
Publisher — тот, кто публикует новые сообщения;
Observer — тот, кто на них подписан. В реактивных потоках подписчик обычно называется Subscriber. Термины разные, но по сути это одно и то же. В большинстве сообществ более привычны термины Publisher/Subscriber.
Это базовая идея, на которой все строится.
Один из жизненных примеров реактивности — система оповещения при пожаре. Допустим, нам надо сделать систему, включающую тревогу в случае превышения задымленности и температуры.

У нас есть датчик дыма и градусник. Когда дыма становится много и/или температура растет, на соответствующих датчиках увеличивается значение. Когда значение и температура на датчике дыма оказываются выше пороговых, включается колокольчик и оповещает о тревоге.
Если бы у нас был традиционный, а не реактивный подход, мы бы писали код, который каждые пять минут опрашивает детектор дыма и датчик температуры, и включает или выключает колокольчик. Однако в реактивном подходе за нас это делает реактивный фреймворк, а мы только прописываем условия: колокольчик активен, когда детектор больше X, а температура больше Y. Это происходит каждый раз, когда приходит новое событие.
От детектора дыма идет поток данных: например, значение 10, потом 12, и т.д. Температура тоже меняется, это другой поток данных — 20, 25, 15. Каждый раз, когда появляется новое значение, результат пересчитывается, что приводит к включению или выключению системы оповещения. Нам достаточно сформулировать условие, при котором колокольчик должен включиться.
Если вернуться к паттерну Observer, у нас детектор дыма и термометр — это публикаторы сообщений, то есть источники данных (Publisher), а колокольчик на них подписан, то есть он Subscriber, или наблюдатель (Observer).

Немного разобравшись с идеей реактивности, давайте углубимся в реактивный подход. Мы поговорим об операторах реактивного программирования. Операторы позволяют каким-либо образом трансформировать потоки данных, меняя данные и создавая новые потоки. Для примера рассмотрим оператор distinctUntilChanged. Он убирает одинаковые значения, идущие друг за другом. Действительно, если значение на детекторе дыма не изменилось — зачем нам на него реагировать и что-то там пересчитывать:

Reactive approach
Рассмотрим еще один пример: допустим, мы разрабатываем UI, и нам нужно отслеживать двойные нажатия мышкой. Тройной клик будем считать как двойной.

Клики здесь — это поток щелчков мышкой (на схеме 1, 2, 1, 3). Нам нужно их сгруппировать. Для этого мы используем оператор throttle. Говорим, что если два события (два клика) произошли в течение 250 мс, их нужно сгруппировать. На второй схеме представлены сгруппированные значения (1, 2, 1, 3). Это поток данных, но уже обработанных — в данном случае сгрупированных.
Таким образом начальный поток преобразовался в другой. Дальше нужно получить длину списка ( 1, 2, 1, 3). Фильтруем, оставляя только те значения, которые больше или равны 2. На нижней схеме осталось только два элемента (2, 3) — это и были двойные клики. Таким образом, мы преобразовали начальный поток в поток двойных кликов.
Это и есть реактивное программирование: есть потоки на входе, каким-то образом мы пропускаем их через обработчики, и получаем поток на выходе. При этом вся обработка происходит асинхронно, то есть никто никого не ждет.
Еще одна хорошая метафора — это система водопровода: есть трубы, одна подключена к другой, есть какие-то вентили, может быть, стоят очистители, нагреватели или охладители (это операторы), трубы разделяются или объединяются. Система работает, вода льется. Так и в реактивном программировании, только в водопроводе течет вода, а у нас — данные.
Можно придумать потоковое приготовление супа. Например, есть задача максимально эффективно сварить много супа. Обычно берется кастрюля, в нее наливается порция воды, овощи нарезаются и т.д. Это не потоковый, а традиционный подход, когда мы варим суп порциями. Сварили эту кастрюлю, потом нужно ставить следующую, а после — еще одну. Соответственно, надо дождаться, пока в новой кастрюле снова закипит вода, растворится соль, специи и т.д. Все это занимает время.
Представьте себе такой вариант: в трубе нужного диаметра (достаточного, чтобы заполнялась кастрюля) вода сразу подогревается до нужной температуры, есть нарезанная свекла и другие овощи. На вход они поступают целыми, а выходят уже шинкованными. В какой-то момент все смешивается, вода подсаливается и т.д. Это максимально эффективное приготовление, супоконвейер. И именно в этом идея реактивного подхода.
Observable example
Теперь посмотрим на код, в котором мы публикуем события:

Observable.just позволяет положить в поток несколько значений, причем если обычные реактивные потоки содержат значения, растянутые во времени, то тут мы их кладем все сразу — то есть синхронно. В данном случае это названия городов, на которые в дальнейшем можно подписаться (тут для примера взяты города, в которых есть учебный центр Люксофт).
Девушка (Publisher) опубликовала эти значения, а Observers на них подписываются и печатают значения из потока.
Это похоже на потоки данных (Stream) в Java 8. И тут, и там синхронные потоки. И здесь, и в Java 8 список значений нам известен сразу. Но если бы использовался обычный для Java 8 поток, мы не могли бы туда что-то докладывать. В стрим ничего нельзя добавить: он синхронный. В нашем примере потоки асинхронные, то есть в любой момент времени в них могут появляться новые события — скажем, если через год откроется учебный центр в новой локации — она может добавиться в поток, и реактивные операторы правильно обработают эту ситуацию. Мы добавили события и сразу же на них подписались:
locations.subscribe(s -> System.out.println(s)))
Мы можем в любой момент добавить значение, которое через какое-то время выводится. Когда появляется новое значение, мы просим его напечатать, и на выходе получаем список значений:

При этом есть возможность не только указать, что должно происходить, когда появляются новые значения, но и дополнительно отработать такие сценарии, как возникновение ошибок в потоке данных или завершение потока данных. Да-да, хотя часто потоки данных не завершаются (например, показания термометра или датчика дыма), многие потоки могут завершаться: например, поток данных с сервера или с другого микросервиса. В какой-то момент сервер закрывает соединение, и появляется потребность на это как-то отреагировать.
Implementing and subscribing to an observer
В Java 9 нет реализации реактивных потоков — только спецификация. Но есть несколько библиотек — реализаций реактивного подхода. В этом примере используется библиотека RxJava. Мы подписываемся на поток данных, и определяем несколько обработчиков, то есть методы, которые будут запущены в начале обработки потока (onSubscribe), при получении каждого очередного сообщения (onNext), при возникновении ошибки (onError) и при завершении потока (onComplete):

Давайте посмотрим на последнюю строчку.
locations.map(String::length).filter(l -> l >= 5).subscribe(observer);
Мы используем операторы map и filter. Если вы работали со стримами Java 8, вам, конечно, знакомы map и filter. Здесь они работают точно так же. Разница в том, что в реактивном программировании эти значения могут появляться постепенно. Каждый раз, когда приходит новое значение, оно проходит через все преобразования. Так, String::length заменит строчки на длину в каждой из строк.
В данном случае получится 5 (Minsk), 6 (Krakow), 6 (Moscow), 4 (Kiev), 5 (Sofia). Фильтруем, оставляя только те, что больше 5. У нас получится список длин строк, которые больше 5 (Киев отсеется). Подписываемся на итоговый поток, после этого вызывается Observer и реагирует на значения в этом итоговом потоке. При каждом следующем значении он будет выводить длину:public void onNext(Integer value) {
System.out.println("Length: " + value);
То есть сначала появится Length 5, потом — Length 6. Когда наш поток завершится, будет вызван onComplete, а в конце появится надпись "Done.":
public void onComplete() {
System.out.println("Done.");
Не все потоки могут завершаться. Но некоторые способны на это. Например, если мы читали что-то из файла, поток завершится, когда файл закончится.
Если где-то произойдет ошибка, мы можем на нее отреагировать:
public void onError(Throwable e) {
e.printStackTrace();
Таким образом мы можем реагировать разными способами на разные события: на следующее значение, на завершение потока и на ошибочную ситуацию.
Reactive Streams spec
Реактивные потоки вошли в Java 9 как спецификация.
Если предыдущие технологии (Completable Future, Fork/Join framework) получили свою имплементацию в JDK, то реактивные потоки имплементации не имеют. Есть только очень короткая спецификация. Там всего 4 интерфейса:

Если рассматривать наш пример из картинки про Твиттер, мы можем сказать, что:
Publisher — девушка, которая постит твиты;
Subscriber — подписчик. Он определяет , что делать, если:
Начали слушать поток (onSubscribe). Когда мы успешно подписались, вызовется эта функция;
Появилось очередное значение в потоке (onNext);
Появилось ошибочное значение (onError);
Поток завершился (onComplete).
Subscription — у нас есть подписка, которую можно отменить (cancel) или запросить определенное количество значений (request(long n)). Мы можем определить поведение при каждом следующем значении, а можем забирать значения вручную.
Processor — обработчик — это два в одном: он одновременно и Subscriber, и Publisher. Он принимает какие-то значения и куда-то их кладет.
Если мы хотим на что-то подписаться, вызываем Subscribe, подписываемся, и потом каждый раз будем получать обновления. Можно запросить их вручную с помощью request. А можно определить поведение при приходе нового сообщения (onNext): что делать, если появилось новое сообщение, что делать, если пришла ошибка и что делать, если Publisher завершил поток. Мы можем определить эти callbacks, или отписаться (cancel).
PUSH / PULL модели
Существует две модели потоков:
Push-модель — когда идет «проталкивание» значений.
Например, вы подписались на кого-то в Telegram или Instagram и получаете оповещения (они так и называются — push-сообщения, вы их не запрашиваете, они приходят сами). Это может быть, например, всплывающее сообщение. Можно определить, как реагировать на каждое новое сообщение.
Pull-модель — когда мы сами делаем запрос.
Например, мы не хотим подписываться, т.к. информации и так слишком много, а хотим сами заходить на сайт и узнавать новости.
Для Push-модели мы определяем callbacks, то есть функции, которые будут вызваны, когда придет очередное сообщение, а для Pull-модели можно воспользоваться методом request, когда мы захотим узнать, что новенького.
Pull-модель очень важна для Backpressure — «напирания» сзади. Что же это такое?
Вы можете быть просто заспамленными своими подписками. В этом случае прочитать их все нереально, и есть шанс потерять действительно важные данные — они просто утонут в этом потоке сообщений. Когда подписчик из-за большого потока информации не справляется со всем, что публикует Publisher, получается Backpressure.
В этом случае можно использовать Pull-модель и делать request по одному сообщению, прежде всего из тех потоков данных, которые наиболее важны для вас.
Implementations
Давайте рассмотрим существующие реализации реактивных потоков:
RxJava. Эта библиотека реализована для разных языков. Помимо RxJava существует Rx для C#, JS, Kotlin, Scala и т.д.
Reactor Core. Был создан под эгидой Spring, и вошел в Spring 5.
Akka-стримы от создателя Scala Мартина Одерски. Они создали фреймворк Akka (подход с Actor), а Akka-стримы — это реализация реактивных потоков, которые дружат с этим фреймворком.
Во многом эти реализации похожи, и все они реализуют спецификацию реактивных потоков из Java 9.
Посмотрим подробнее на Spring’овский Reactor.
Function may return…
Давайте обобщим, что может возвращать функция:

Single/Synchronous;
Обычная функция возвращает одно значение, и делает это синхронно.
Multipple/Synchronous;
Если мы используем Java 8, можем возвращать из функции поток данных Stream. Когда вернулось много значений, их можно отправлять на обработку. Но мы не можем отправить на обработку данные до того, как все они получены — ведь Stream работают только синхронно.
Single/Asynchronous;
Здесь уже используется асинхронный подход, но функция возвращает только одно значение:
либо CompletableFuture (Java), и через какое-то время приходит асинхронный ответ;
либо Mono, возвращающая одно значение в библиотеке Spring Reactor.
Multiple/Asynchronous.
А вот тут как раз — реактивные потоки. Они асинхронные, то есть возвращают значение не сразу, а через какое-то время. И именно в этом варианте можно получить поток значений, причем эти значения будут растянуты во времени Таким образом, мы комбинируем преимущества потоков Stream, позволяющих вернуть цепочку значений, и асинхронности, позволяющей отложить возврат значения.
Например, вы читаете файл, а он меняется. В случае Single/Asynchronous вы через какое-то время получаете целиком весь файл. В случае Multiple/Asynchronous вы получаете поток данных из файла, который сразу же можно начинать обрабатывать. То есть можно одновременно читать данные, обрабатывать их, и, возможно, куда-то записывать. . Реактивные асинхронные потоки называются:
Publisher (в спецификации Java 9);
Observable (в RxJava);
Flux (в Spring Reactor).
Netty as a non-blocking server
Рассмотрим пример использования реактивных потоков Flux вместе со Spring Reactor. В основе Reactor лежит сервер Netty. Spring Reactor — это основа технологии, которую мы будем использовать. А сама технология называется WebFlux. Чтобы WebFlux работал, нужен асинхронный неблокирующий сервер.

Схема работы сервера Netty похожа на то, как работает Node.js. Есть Selector — входной поток, который принимает запросы от клиентов и отправляет их на выполнение в освободившиеся потоки. Если в качестве синхронного сервера (Servlet-контейнера) используется Tomcat, то в качестве асинхронного используется Netty.
Давайте посмотрим, сколько вычислительных ресурсов расходуют Netty и Tomcat на выполнение одного запроса:

Throughput — это общее количество обработанных данных. При небольшой нагрузке, до первых 300 пользователей у RxNetty и Tomcat оно одинаковое, а после Netty уходит в приличный отрыв — почти в 2 фраза.

Blocking vs Reactive
У нас есть два стека обработки запросов:
Традиционный блокирующий стек.
Неблокирующий стек — в нем все происходит асинхронно и реактивно.

В блокирующем стеке все строится на Servlet API, в реактивном неблокирующем стеке — на Netty.
Сравним реактивный стек и стек Servlet.
В Reactive Stack применяется технология Spring WebFlux. Например, вместо Servlet API используются реактивные стримы.

Чтобы мы получили ощутимое преимущество в производительности, весь стек должен быть реактивным. Поэтому чтение данных тоже должно происходить из реактивного источника.
Например, если у нас используется стандартный JDBC, он является не реактивным блокирующим источником, потому что JDBC не поддерживает неблокирующий ввод/вывод. Когда мы отправляем запрос в базу данных, приходится ждать, пока результат этого запроса придет. Соответственно, получить преимущество не удается.
В Reactive Stack мы получаем преимущество за счет реактивности. Netty работает с пользователем, Reactive Streams Adapters — со Spring WebFlux, а в конце находится реактивная база: то есть весь стек получается реактивным. Давайте посмотрим на него на схеме:
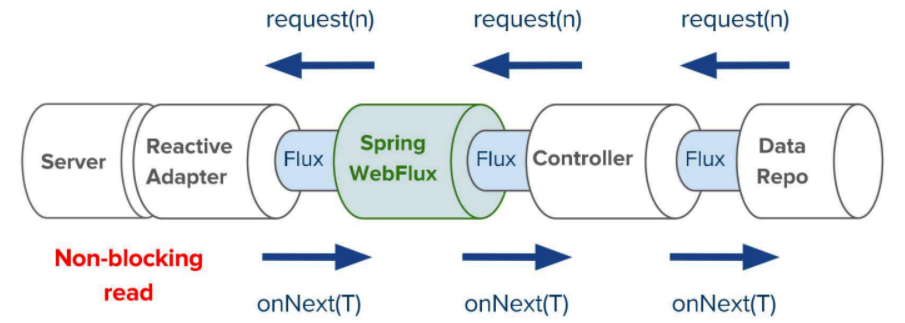
Data Repo — репозиторий, где хранятся данные. В случае, если есть запросы, допустим, от клиента или внешнего сервера, они через Flux поступают в контроллер, обрабатываются, добавляются в репозиторий, а потом ответ идет в обратную сторону.
При этом все это делается неблокирующим способом: мы можем использовать либо Push-подход, когда мы определяем, что делать при каждой следующей операции, либо Pull-подход, если есть вероятность Backpressure, и мы хотим сами контролировать скорость обработки данных, а не получать все данные разом.
Операторы
В реактивных потоках огромное количество операторов. Многие из них похожи на те, которые есть в обычных стримах Java. Мы рассмотрим только несколько самых распространенных операторов, которые понадобятся нам для практического примера применения реактивности.
Filter operator
Скорее всего, вы уже знакомы с фильтрами из интерфейса Stream.

По синтаксису этот фильтр точно такой же, как обычный. Но если в стриме Java 8 все данные есть сразу, здесь они могут появляться постепенно. Стрелки вправо — это временная шкала, а в кружочках находятся появляющиеся данные. Мы видим, что фильтр оставляет в итоговом потоке только значения, превышающие 10.

Take 2 означает, что нужно взять только первые два значения.
Map operator
Оператор Map тоже хорошо знаком:

Это действие, происходящее с каждым значением. Здесь — умножить на десять: было 3, стало 30; было 2, стало 20 и т.д.
Delay operator

Задержка: все операции сдвигаются. Этот оператор может понадобиться, когда значения уже генерируются, но подготовительные процессы еще происходят, поэтому приходится отложить обработку данных из потока.
Reduce operator
Еще один всем известный оператор:

Он дожидается конца работы потока (onComplete) — на схеме она представлена вертикальной чертой. После чего мы получаем результат — здесь это число 15. Оператор reduce сложил все значения, которые были в потоке.
Scan operator
Этот оператор отличается от предыдущего тем, что не дожидается конца работы потока.

Оператор scan рассчитывает текущее значение нарастающим итогом: сначала был 1, потом прибавил к предыдущему значению 2, стало 3, потом прибавил 3, стало 6, еще 4, стало 10 и т.д. На выходе получили 15. Дальше мы видим вертикальную черту — onComplete. Но, может быть, его никогда не произойдет: некоторые потоки не завершаются. Например, у термометра или датчика дыма нет завершения, но scan поможет рассчитать текущее суммарное значение, а при некоторой комбинации операторов — текущее среднее значение всех данных в потоке.
Merge operator
Объединяет значения двух потоков.

Например, есть два температурных датчика в разных местах, а нам нужно обрабатывать их единообразно, в общем потоке .
Combine latest
Получив новое значение, комбинирует его с последним значением из предыдущего потока.

Если в потоке возникает новое событие, мы его комбинируем с последним полученным значением из другого потока. Скажем, таким образом мы можем комбинировать значения от датчика дыма и термометра: при появлении нового значения температуры в потоке temperatureStream оно будет комбинироваться с последним полученным значением задымленности из smokeStream. И мы будем получать пару значений. А уже по этой паре можно выполнить итоговый расчет:
temperatureStream.combineLatest(smokeStream).map((x, y) -> x > X && y > Y)
В итоге на выходе у нас получается поток значений true или false — включить или выключить колокольчик. Он будет пересчитываться каждый раз, когда будет появляться новое значение в temperatureStream или в smokeStream.
FlatMap operator
Этот оператор вам, скорее всего, знаком по стримам Java 8. Элементами потока в данном случае являются другие потоки. Получается поток потоков. Работать с ними неудобно, и в этих случаях нам может понадобиться «уплостить» поток.

Можно представить такой поток как конвейер, на который ставят коробки с запчастями. До того, как мы начнем их применять, запчасти нужно достать из коробок. Именно это делает оператор flatMap.
Flatmap часто используется при обработке потока данных, полученных с сервера. Т.к. сервер возвращает поток, чтобы мы смогли обрабатывать отдельные данные, этот поток сначала надо «развернуть». Это и делает flatMap.
Buffer operator
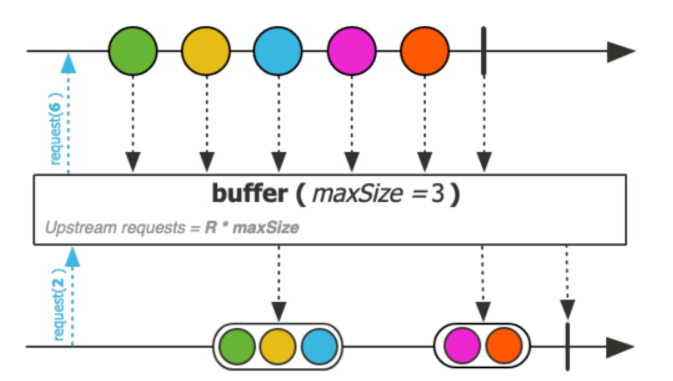
Это оператор, который помогает группировать данные. На выходе Buffer получается поток, элементами которого являются списки (List в Java). Он может пригодиться, когда мы хотим отправлять данные не по одному, а порциями.
Мы с самого начала говорили, что реактивные потоки позволяют разбить задачу на подзадачи, и обрабатывать их маленькими порциями. Но иногда лучше наоборот, собрать много маленьких частей в блоки. Скажем, продолжая пример с конвейером и запчастями, нам может понадобиться отправлять запчасти на другой завод (другой сервер). Но каждую отдельную запчасть отправлять неэффективно. Лучше их собрать в коробки, скажем по 100 штук, и отправлять более крупными партиями.
На схеме выше мы группируем отдельные значения по три элемента (так как всего их было пять, получилась «коробка» из трех, а потом из двух значений). То есть если flatMap распаковывает данные из коробок, buffer, наоборот, упаковывает их.
Всего существует более сотни операторов реактивного программирования. Здесь разобрана только небольшая часть.
Итого
Есть два подхода:
Spring MVC — традиционная модель, в которой используется JDBC, императивная логика и т.д.
Spring WebFlux, в котором используется реактивный подход и сервер Netty.

Есть кое-что, что их объединяет. Tomcat, Jetty, Undertow могут работать и со Spring MVC, и со Spring WebFlux. Однако дефолтным сервером в Spring для работы с реактивным подходом является именно Netty.
Конференция HighLoad++ Весна 2021 пройдет 20 и 21 мая 2021 года. Приобрести билеты можно уже сейчас.
А совсем скоро состоится еще одно интересное событие, на сей раз онлайн: 18 марта в 17:00 МСК пройдет митап «Как устроена самая современная платежная система в МИРе: архитектура и безопасность».
Вместе с разработчиками Mир Plat.Form будем разбираться, как обеспечить устойчивость работы всех сервисов уже на этапе проектирования и как сделать так, чтобы система могла развиваться, не затрагивая бизнес-процессы. Митап будет интересен разработчикам, архитекторам и специалистам по безопасности.Хотите бесплатно получить материалы конференции мини-конференции Saint HighLoad++ 2020? Подписывайтесь на нашу рассылку.
vba
По мне, так, Спринг следовало бы наказать и не упоминать об этой компании, каждый раз когда речь заходит о реактивном программировании в Java, несмотря на Reactor или WebFlux. В течение десяти лет это компания делала все что бы похоронить реактивное программирование в Java. Их больше интересовал выпуск поделок вроде Spring Roo, а не, к примеру, интеграция SpringMVC с Mina, а следом и Netty. Shame, Shame, Shame...