
Введение
Недавно открыл для себя платформу Streamlit и был впечатлен простотой интеграции в питоновский проект. По детски, очень радовался тому что контроллеры на дашборде напрямую меняют питоновские переменные. И вот для тестирования решил поиграть с одной из тем которая мне очень интересна – климат. Начал с самого простого параметра который можно проанализировать – температуру воздуха с метеостанции города в котором я живу - Алматы (Казахстан). Интересно было посмотреть эффект глобального изменения климата на отдельно взятый город.
Для анализа скачал данные за 100 лет (1922-2022). Для начала использовал только месяцы с ноября по апрель включительно, во-первых, потому что в несвободное от работы время я работаю с морским льдом и зимний климат мне понятней, а во-вторых потому что в данных была пропущена неделя наблюдений в августе, в одном из годов.
Один из плюсов Streamlit, то что дашборды можно бесплатно публиковать в Streamlit Cloud, что я и сделал:
https://share.streamlit.io/yevkad/alaclim/main/app.py
Пройдя по этой ссылке, можно поиграть с интерактивными графиками. А в этом посте я поподробней покажу что и как я делал (с кодом) и опишу некоторые свои наблюдения.
Инструменты
Все было сделано на Python и следующими библиотеками:
Streamlit - платформа для быстрого создания DS/ML веб-приложений
Pandas - манипуляции с таблицами
Numpy - использовал некоторые вспомогательные функции
Plotly - Все интерактивные графики были построены с помощью этой библиотеки
SciPy - для подбора распределения вероятностей
pyMannKendall - для Теста Манна-Кендалла, который оценивает статистическую значимость тренда
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.figure_factory as ff
import plotly.graph_objects as go
import scipy
import pymannkendall as mk
from datetime import datetimeДанные
Основная часть данных была взята с NOAA Climate Data Center, к слову - один из любимых источников открытых данных, наравне с европейским Copernicus.
Почему-то было много пропусков после 2006го года, заполнил их данными rp5 - там трехчасовые данные с метеостанций доступны для большинства локаций с 2005го года. На rp5 данные в местном времени, предварительно перевел время в UTC и усреднил подневно.
Данные подготавливаются функцией представленной ниже. Декоратор st.cahce для того чтобы данные не обрабатывались каждый раз при обновлении контроллеров.
@st.cache
def get_winter_data(fl):
#initial columns: date, at - daily mean air temperature
df_winter=pd.read_csv(fl,parse_dates=['date'])
df_winter['fd']=np.abs(np.minimum(0,df_winter['at'])) #freezing days
df_winter['month']=df_winter['date'].dt.strftime('%b')
#relative date for timeseries.
df_winter['date_rel']=pd.to_datetime(df_winter['date'].dt.strftime('2016-%m-%d'),
format='%Y-%m-%d')
df_winter.loc[df_winter['mon']>8,
'date_rel']=df_winter['date_rel'] - pd.DateOffset(years=1)
df_winter.loc[df_winter['date']<datetime(1972,6,1), 'period']='1922-1972'
df_winter.loc[df_winter['date']>datetime(1972,6,1), 'period']='1972-2022'
df_winter['dt']=df_winter['date'].dt.strftime('%Y%m').astype(int)
df_fdd=df_winter.groupby(['seas'])['fd'].sum().reset_index(name='fdd')
return df_winter,df_fddВ результате получаем два датафрейма df_winter и df_fdd. У df_winter следующие колонки:
date - дата
at - среднедневная температура воздуха
seas - сезон, строка в виде начального и конечного года (1922-1923)
month - месяц в формате строчном формате (Nov, Dec, etc). От нее можно было бы избавиться и оптимизировать обработку, но руки пока не дошли
mon - месяц в числовом формате (11, 12 и тд.)
period - фиксированный период по 50 лет с 1922 по 1972 и 1972 по 2022
fd - freezing days, градусы ниже нуля в абсолюте
dt - полукостыль, год-месяц в виде целого числа в формате YYYYMM, для группирования нескольких сезонов в одну группу функцией
np.digitize(пример будет в следующих секциях)rel_date - дата с заменой года для всех дней на 2015 до января и 2016 с января, для того что бы можно было агрегировать 100 лет за каждый день.
У df_fdd всего 100 рядов, по ряду за каждый сезон и следующие колонки:
seas - сезон
fdd - Freezing Degree Days - аккумулированные градусы ниже нуля в абсолюте. Более подробное описание будет ниже.
Временной ряд
Временной ряд был составлен выведением на график агрегированных за каждый день с ноября по апрель столетних температур (максимум, минимум, среднее) и возможностью сравнивать эти параметры с выбранными периодами.
Если визуально сравнить первую половину периода со второй, то видно, что в основном средние температуры с 1922 по 1972 ниже столетнего среднего значения, а с 1972 по 2022 выше.

Распределения
Далее были построены гистограммы с подбором распределения вероятностей для двух периодов по 50 лет: 1922-1972 и 1972-2022. В падающем меню можно выбрать тип распределения - Нормальное или Гамма. В данном случае визуально понятно, что Нормальное больше подходит, но в будущем добавлю метрику "goodness of fit".
Левая часть распределения 1972-2022 "сужается" в право, по сравнению с периодом 1922-1972. Это показывает, что за последние 50 лет количество наблюдений экстремально холодных температур уменьшилось. Это не противоречит выведенными параметрами распределения - среднее (Mean) увеличилось на 0.6 градуса, а среднеквадратическое отклонение (SD) уменьшилось по сравнению с начальным периодом.

Усатые Ящики
Помимо сравнения двух фиксированных периодов в виде гистограмм и распределений описанных в предыдущей секции, также была добавлена возможность сравнения распределения выбранных групп периодов (1 год, 5 лет, 10 лет и тд). Наиболее подходящей визуализацией для этого, по моему мнению, являются графики, которые я называл всегда боксплотами, и только сегодня выяснил что русское называние для них - "ящик с усами".
Для тех кто не сталкивался с такими графиками, подробное описание "ящика с усами" можно почитать, например, здесь, но грубо и приближенно, вот как можно его интерпретировать:
"Ящик" содержит 50% наблюдений
Линия внутри ящика - медиана, или 2-й квартиль - выше и ниже по 50% наблюдений
Нижний и верхний "ус" - 25% нижних и верхних наблюдений соответственно
Точки - выбросы (наблюдения вне 2.7 среднеквадратических отклонений)
Нижняя граница "ящика" - 1-й квартиль - ниже него 25% наблюдений, выше 75%
Верхняя граница "ящика" - 3-й квартиль - выше него 25% наблюдений, ниже 75%
Сгруппировав по длительным периодам, например 20 лет, как на примере ниже, видно что, медиана и 1-й квартиль стабильно возрастает с периода который включает в себя 1970е, а 3-й квартиль в последнем периоде. Также как на распределениях описанных выше, изменение зим по большей части выражается в уменьшении "холодов", а в более поздние периоды еще и в увеличении "тепла".

Вот часть кода, где группируются температуры по годам и выводятся в график:
# Years grouping:
nmax=df_fdd.shape[0]
yr_start=df_winter['year'].min()
# list of only divisible groups
group_lst=[i for i in range(1,nmax+1,1) if nmax % i==0]
step=st.selectbox('Group years ', group_lst, index=group_lst.index(10))
date_range=np.array([datetime(yr_start+i,6,1).strftime('%Y%m')
for i in range(step,nmax+1,step)
]).astype(int)
date_bin_n=np.array([f'{yr_start+i}-{yr_start+step+i}' for i in range(0,nmax,step)])
df_winter_g=df_winter.copy()
#assigning bin name to date range
df_winter_g['date_bin']=date_bin_n[np.digitize(df_winter_g['dt'], date_range)]
#month filtering
mon_lst=df_winter['month'].unique()
st_mon_lst = st.multiselect("Months Used", mon_lst, default=mon_lst)
df_mon=df_winter_g[df_winter_g['month'].isin(st_mon_lst)]
fig_box = px.box(df_mon, x="date_bin", y="at",
labels={'seas':'Winter Season',
'at':'Air Temperature (\u00B0C)',
'date_bin':'Date Range'},)
st.write(fig_box)Суровость зим по FDD
Сумма градусодней мороза (Freezing Degree Days - FDD) рассчитывается как абсолютная сумма всех отрицательных температур воздуха за период – обычно за зимний сезон. На всякий случай формула FDD:
Где at - среднедневная температура воздуха, N - число дней в сезоне.
FDD часто используется для примерного определения прироста толщины льда, уровня промерзания почвы, и может служить индексом суровости зим: чем меньше FDD тем мягче зима.
Отобразив на графике FDD за каждый сезон и положив линию тренда, то можно увидеть тенденцию снижения суровости зим, особенно с 1970х годов.

Тренд был посчитан в NumPy как полиномиальная кривая (с возможностью управлять порядком).
poly_deg=st.slider('Degree of a Polynomial Trend',
min_value=1, max_value=20, value=1, step=1)
trend_x = np.arange(df_fdd.shape[0])
trend_fit = np.polyfit(trend_x, df_fdd['fdd'], poly_deg)
trend_fit_fn = np.poly1d(trend_fit)Помимо визуальной оценки, тренд и его статистическая значимость была оценена тестом Манна-Кенадалла при помощи библиотеки pyMannKendall вот так:
mk_res=mk.original_test(df_fdd['fdd']) # results of Mann-Kendall TestИ вывести результат..
trend_mk=mk_res.trend # Trend: Increasing, Decreasing or No Trend
pval_mk=mk_res.p # P-Value of MK Test
if pval_mk<0.05: # alpha=0.05
p_str='**statistically significant**'
alpha_compr='smaller'
else:
p_str='**not statistically significant**'
alpha_compr='greater'
#Markdown string generated to present MK Test results of FDD Trend
mk_str=f'''Mann-Kendall Test shows that FDD trend is **{trend_mk}**.
\n\n**P-value** is **{pval_mk:.3e}**, which is **{alpha_compr}**
than **0.05**, meaning that the trend in the data is {p_str}'''И в таком виде результаты теста выводятся на страницу:

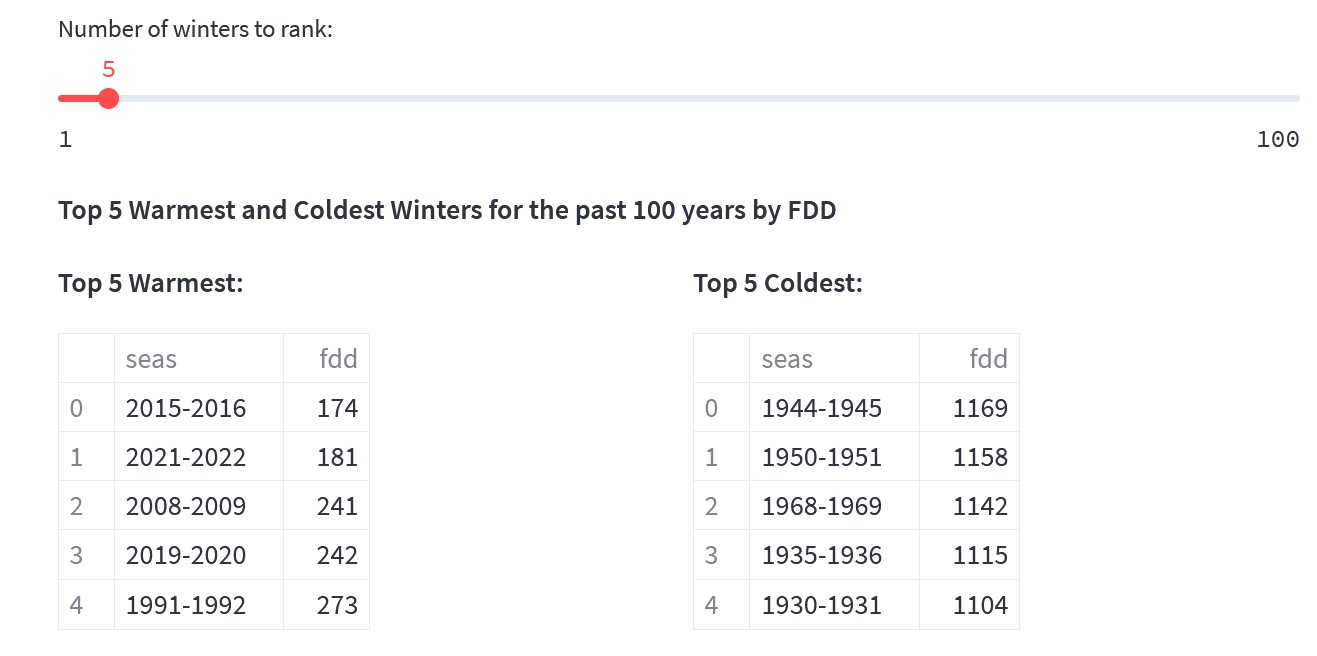
Ну и напоследок можно посмотреть указанное число наиболее мягких и наиболее суровых зим ранжированных по FDD. В пятерку наиболее мягких попали сезоны последних 30 лет. В пятерку наиболее суровых попали зимы не позже 1970х.
Заключение
Анализ столетних наблюдений температуры воздуха, показал что зимы в Алматы становятся мягче.
Весь дашборд уложился в менее чем 300 строк питоновского файла, значительную часть из которых занимает пояснительный текст. На составление основной части веб-приложения ушло несколько часов, ну и потом периодически что-то добавлял. Для сравнения, до знакомства со Streamlit я делал визуализацию с Bokeh+Flask, и на составление одного графика, когда я только начал изучать Bokeh, ушло полдня.
В будущем буду расширять дашборд новыми элементами и локациями. Добавлю сравнение средних максимумов и минимумов за период. Еще планирую добавить другие параметры, такие как ветер и осадки. Ну и если руки дойдут, может и моделирование какое-нибудь.
Maga2030
Хорошая работа