
На пути от наблюдаемой системы до пользователя DataDog (здесь и далее - DD) метрические данные неизбежно проходят несколько этапов агрегации. Это означает, что в момент чтения метрик пользователь DD оперирует не конкретными значениями, а их агрегатами. Теоретически возможно записать в DD метрики таким образом, чтобы они в итоге не были подвержены агрегации, но это не имеет смысла и противоречит самой концепции DD.

Восприятие агрегатов DD за точные значения метрик в точный момент времени – это распространенная ошибка, которая может привести к неправильной трактовке метрик, а следовательно – к ложным выводам о состоянии системы. Поэтому важно понимать, как именно и на каких этапах происходят агрегации полученных от системы данных.
Агрегации на стороне агента
Для доставки метрик DD использует протокол DogStatsD (сервер DogStatsD встроен в агент DD), который является расширенной реализацией протокола StatsD от Etsy (https://github.com/statsd/statsd). Как и StatsD, DogStatsD подразумевает накопление полученных метрик в течении заданного интервала времени с последующей их агрегацией и пересылкой. Агрегация необходима для повышения производительности системы сбора метрик и снижения нагрузки на нее.
Например, агент получил 1000 инкрементов некоей метрики типа COUNT за интервал времени. Вместо того, чтобы производить 1000 вызовов API, по одному на инкремент, агент DD суммирует их значения по ключу ИМЯ+МЕТКИ, и производит пересылку только полученных агрегатов. Количество вызовов API таким образом многократно снижается: если метки всех инкрементов из примера совпадают, то агент произведет пересылку только одного агрегата (https://docs.datadoghq.com/developers/dogstatsd/data_aggregation/#how-is-aggregation-performed-with-the-dogstatsd-server).
Длина интервала накопления может меняться в зависимости от источника метрик. Для частных метрик она составляет 10 секунд, после чего происходит агрегация. Агрегату присваивается отметка времени, соответствующая началу интервала. Таким образом, из частных метрик, полученных с 12:00:00 до 12:00:10, создается агрегат с отметкой времени 12:00:00. В терминологии DD агрегаты, созданные на стороне агента, называются точками данных (datapoint).
Способы, которыми DogStatsD агрегирует полученные за интервал накопления данные, зависят от типа метрик:
GAUGE: пересылается последнее полученное значение метрики;
COUNT: пересылается сумма полученных значений;
HISTOGRAM: пересылается набор агрегатов, заданных в конфигурации агента: количество полученных значений, минимальное и максимальное значения, их сумма, среднее, медиана и набор перцентилей;
SET: пересылается набор уникальных полученных значений;
DISTRIBUTION: значения агрегируются и пересылаются, как глобальное распределение.
Агрегации на стороне приложения DataDog
Из агента агрегаты в итоге попадают в бэк-энд DD, который осуществляет их хранение, поиск, визуализацию и автоматический анализ. Они хранятся в своем первоначальном виде и со временем не меняются. Несмотря на это, на стороне DD агрегация производится при обработке запроса данных метрик для их визуализации.
Можно выделить два типа агрегаций, автоматически выполняемых на стороне DD: пространственная и по времени. Так же к метрикам в DD можно вручную применить свертку по времени, что позволит полнее контролировать агрегации.
Пространственная агрегация
Пространственная агрегация производится при выполнении запроса с фильтром по набору меток, для которого отсутствует готовый агрегат.
Например, за интервал накопления метрик агент получил 5 инкрементов метрики «act..app.start» типа COUNT, показывающей количество запусков приложения:
3 инкремента с метками «host:75ab75c0b32b;success:true»;
1 инкремента с метками «host:75ab75c0b32b;success:false»;
1 инкремент с метками «host:9503fdc385a3;success:true».
То есть, на хосте «75ab75c0b32b» приложение запускалось 4 раза. Из них 3 раза успешно, а 1 - нет. На хосте «9503fdc385a3» приложение запускалось 1 раз, успешно.
По истечении интервала агент построит 3 агрегата (по одному на каждый набор меток) и отправит их в бэк-энд DD, который сохранит их в таком же виде.
Пусть требуется построить временной ряд в виде столбцов для неуспешных запусков приложения независимо от хоста. В этой ситуации у DD не будет агрегата, который подошел бы для построения отсчета на графике, поэтому он выполнит дополнительную агрегацию: просуммирует значения тех агрегатов, среди меток которых есть «success:false», либо вычислит по ним среднее.
Агрегация по времени
Как уже упоминалось, DD хранит агрегаты метрик в неизменном виде. Соответственно, каждый из них вычислен на достаточно коротком интервале времени. Например, для частных метрик это интервал длиной в 10 секунд.
При построении временных рядов DD автоматически выбирает размер одного отсчета на горизонтальной оси, пытаясь найти баланс между точностью графика, и его читаемостью. Как правило, выбранный размер отсчета превышает размер интервала агрегата. В этом случае для построения графика DD так же выполнит дополнительную агрегацию.
Управление автоматической агрегацией на стороне DataDog
JSON-описание временного ряда в DD выглядит примерно так:
{
"viz": "timeseries",
"requests": [
{
"queries": [
{
"data_source": "metrics",
"name": "query1",
"query": "sum:act..app.start{success:false}.as_count()"
}
],
"response_format": "timeseries",
"type": "bars"
}
]
}
}Выделенное поле query содержит запрос данных, который DD должен выполнить для построения графика.
«sum» в начале строки запроса указывает DD, что как для пространственной, так и для временной агрегации необходимо выполнить суммирование значений агрегатов, доступных для построения одного отсчета графика.
Кроме суммирования, DD так же может вычислять из доступных для отсчета агрегатов среднее. В этом случае строка запроса начиналась бы с «avg» и выглядела бы так:
"query": "avg:act..app.start{success:false}.as_count()"Важно отметить, что для вычисления среднего могут быть использованы
Ручная свертка по времени
Ручная свертка позволяет пользователю самостоятельно задать размер отсчета временного ряда, а также предоставляет больше типов агрегации для его построения.
Свертка доступна, как функция «.rollup()», применяемая к метрике. Принимает два параметра: <AGGREGATOR> – тип агрегации, который будет применяться к данным отсчета (count, min, max, sum, avg), и <INTERVAL> – размер интервала, на котором будет производится свертка (необязательный).
Строка запроса для свертки суммированием на интервале 1 минута будет иметь вид:
"query": "sum:act..app.start{success:false}.as_count().rollup(sum, 60)"При построении временного ряда DD определяет минимальный размер отсчета. Передача параметра <INTERVAL> при вызове .rollup() задаст размер отсчета на графике только в том случае, если его значение не превышает минимум, определенный DD. В противном случае, а также в случае, когда параметр <INTERVAL> не передан, как размер отсчета будет использован интервал, определенный DD, и .rollup() будет выполнен на нем. О том, какой минимальный размер отсчета в разных ситуациях выбирает DD, можно узнать из таблицы по ссылке (https://docs.datadoghq.com/dashboards/functions/rollup/#rollup-interval-enforced-vs-custom).
Интерполяция
Хотя это и не относится к агрегации данных, хотелось бы также вкратце упомянуть про интерполяцию в DD, так как некоторые ее особенности могут привести к тем же проблемам, что и особенности агрегации.
Важно помнить, что к метрикам типа GAUGE DD автоматически применяет линейную интерполяцию, заполняя таким образом отсчеты, данные для которых отсутствуют. Обычно это не мешает, так как графики становятся более плавными, и, соответственно, более читаемыми. Но из-за того, что полученные с помощью интерполяции отсчеты никак не выделены на графике, он может ввести пользователя в заблуждение.
Для примера рассмотрим метрику «rabbitmq.queue.messages_ready» из интеграции DD с rabbitmq. Метрика показывает, сколько сообщений в rmq находятся в состоянии «ready», что можно условно принять за размер очередей. Построенный по этой метрике временной ряд будет выглядеть следующим образом:

По графику можно сделать вывод, что за период размер очередей плавно нарастал, достиг плато, а затем начал плавно снижаться.
Если отключить интерполяцию, то картина изменится:
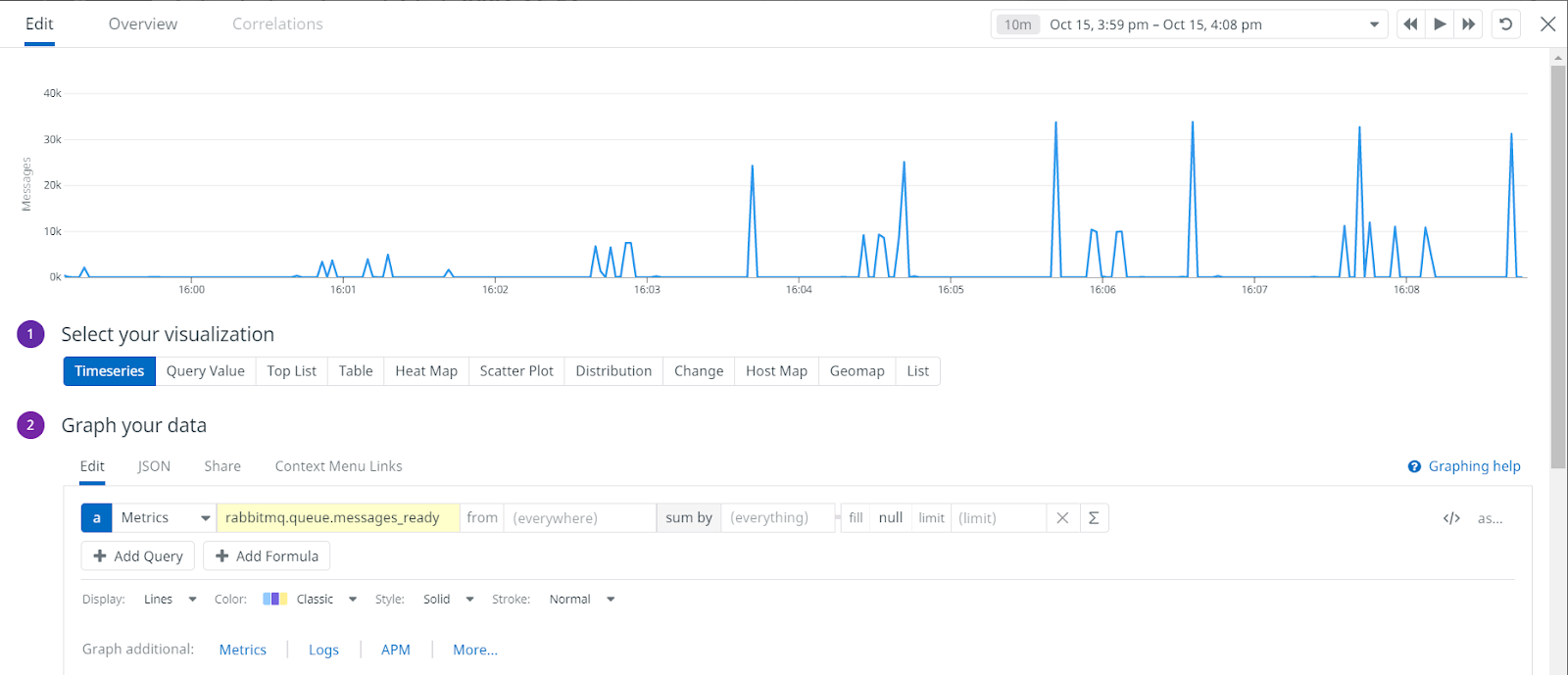

По графику без интерполяции можно понять, для каких отчетов у DD есть данные (пики), а для каких – нет. Также стало видно, что между 16:01 и 16:02 происходило кратковременное уменьшение размера очередей, после чего начался их более резкий рост. Подобная информация может быть крайне важной в процессе диагностики. Поэтому хорошей практикой при работе с метриками GAUGE является построение как графиков с интерполяцией, так и графиков без нее.
Отключить или изменить интерполяцию можно с помощью функции «.fill()», принимающей параметры <METHOD> и <LIMIT>.
Developer в Social Discovery Ventures