
Введение
Библиотека Unified и экосистема плагинов для работы с Markdown и HTML позволит очень просто создать конвертер и подключить компоненты React. Unified преобразует контент в синтаксическое дерево, и имеет набор утилит для работы с деревом, но даже без набора утилит это простая задача, достаточно уметь перебирать свойства объекта javascript. Все это будет продемонстрировано и объяснено.
В статье есть пример создания плагина и демо проект.
Причины выбора библиотеки Unified
Во-первых, интеграция с React плагины для компиляции HTML/Markdown в компоненты React:
rehype-react - для компиляции HTML
remark-react - для компиляции Markdown
Во-вторых мне понравилось наличие большого количества плагинов, среди которых есть компонент React react-markdown который я уже использовал в своих проектах, react-markdown под капотом использует библиотеку Unified и плагины rehype-react + remark-react.
Еще одной причиной является понятная и небольшая документация библиотеки Unified.
Оставлю ссылку на хорошую статью Как я Markdown парсер выбирал в которой можно найти несколько альтернативных решений включая, библиотека Unified тоже упоминается, но не так подробно.
Термины и определения
Markdown - облегчённый язык разметки, созданный с целью обозначения форматирования в простом тексте, с максимальным сохранением его читаемости человеком, и пригодный для машинного преобразования в языки для продвинутых публикаций. Ссылки для ознакомления markdownguide.org и Wiki
HTML - стандартизированный язык гипертекстовой разметки документов для просмотра веб-страниц в браузере. Ссылки для ознакомления Wiki и HTML Living Standard
AST(Abstract syntax tree) - это древовидное представление абстрактной синтаксической структуры текста, в нашем случае написанного на языке javascript. Далее в тексте буду писать AST для краткости. Ссылки для ознакомления Wiki
Unified - библиотека предоставляет интерфейс (смотри раздел processor API) для обработки контента с помощью AST. Экосистемы содержат плагины, работают с AST.
-
Экосистема плагинов - каждая экосистема добавляет поддержку какого-то типа контента. В этой статье будут использоваться экосистемы плагинов:
Процессор / Processor - создается с помощью вызова конструктора unified(), remark(), rehype() под капотом вызывается метод processor(). Создается процессор готовый к конфигурированию с последовательного подключения плагинов с помощью метода processor().use(). Контент обрабатывается с помощью подключенных плагинов.
Спецификация синтаксического дерева
Синтаксические деревья - это представления исходного кода или естественного языка. Эти деревья являются абстракциями, которые позволяют анализировать, преобразовывать и генерировать код.
В этом документе описан интерфейс синтаксического дерева: specification syntax tree
Набор утилит для работы с синтаксическими деревьями
hast - HTML abstract syntax tree
mdast - Markdown abstract syntax tree
nlcst - Natural language syntax tree
xast - XML abstract syntax tree
Node - узлы синтаксического дерева
Описание интерфейса Node можно найти в документации
в отладчике мы получим такую структуру, которая описана в документации
export type Node = Partial<{
type: string; // for example 'element'
tagName: string; // for example "p"
properties: { [key: string]: any }; //
children: Array<Node>;
value: string;
position: { // положение этого узла в исходном документа
start: { line: number; column: number; offset: number }; // { line: 1, column: 1, offset: 0 }
end: { line: number; column: number; offset: number };
};
}>;
Краткое описание свойств:
-
type - из моего опыта отладки может иметь три значения:
root - корень дерева
text например для представления текстового блока
element - html элемент
tagName есть только у типа element, строковое значение наименование элемента.
value есть только у text
properties есть у type element это атрибуты html элемента
children это дочерние элементы
position содержит информацию о положении узла в исходном контенте до трансформаций. Например, чтобы узнать сколько строчек занимает контент просто выполним position.end.line - position.start.line.
Пример AST
Создаем процессор для преобразования markdown в html
result = unified()
.use(remarkParse)
.use(remarkRehype)
.use(parseElements)
.processSync("## Netlify");
Мы получим такое дерево
[
{
type: "element",
tagName: "h2",
properties: {
},
children: [
{
type: "text",
value: "Netlify",
position: {
start: {
line: 1,
column: 4,
offset: 3,
},
end: {
line: 1,
column: 11,
offset: 10,
},
},
},
],
position: {
start: {
line: 1,
column: 1,
offset: 0,
},
end: {
line: 1,
column: 11,
offset: 10,
},
},
},
]
Библиотека unified и экосистема
unified - библиотека, которая преобразует контент с помощью AST и предоставляет возможность промежуточной обработки деревьев с помощью экосистемы плагинов. Сайт проекта
Обработка контента проходит три обязательные стадии:
преобразование контента html или markdown в AST - используется плагин Parser
трансформации в AST - используется плагин Transformer
компиляция AST в контент html или markdown - используется плагин Compiler
Плагины подключаются с помощью универсального интерфейса Processor API, рассмотрим далее.
Экосистема rehype для работы с html
rehype - добавляет поддержку работы с html.
Плагины parser и compiler:
rehype-parse - разбирает строку HTML в AST
rehype-stringify - компилирует AST в строку HTML
rehype-react - компилирует AST HTML в компоненты React
Плагины Transformers, используемые в статье:
@mapbox/rehype-prism - подсветка синтаксиса с использованием PrismJS
rehype-sanitize - делает AST более безопасным для использования другими плагинами, в демо приложении будем использовать для безопасного компилирования html в компоненты React
Список всех плагинов экосистемы rehype
Экосистема remark для работы с markdown
remark - добавляет поддержку работы с markdown.
Плагины parser и compiler:
remark-parse - разбирает строку markdown в AST
remark-stringify- компилирует AST в строку markdown
Плагины Transformers, несколько часто используемых:
remark-rehype - трансформирует AST Markdown в AST HTML, после этой трансформации нужно использовать плагины для rehype
Список всех плагинов экосистемы remark
Основной разработчик
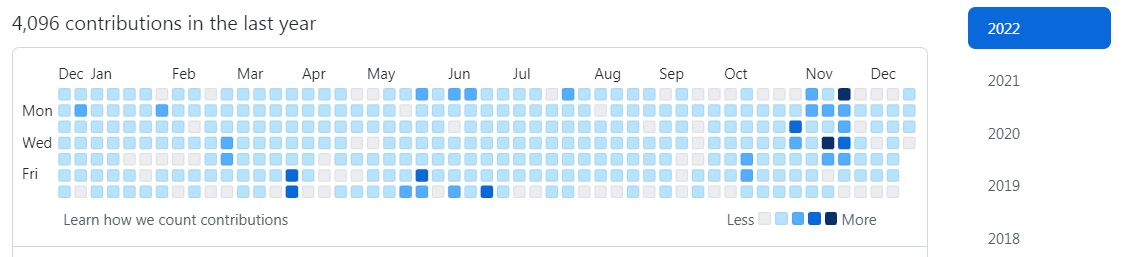
Titus (wroom) - основной разработчик спецификации синтаксических деревьев unist, библиотеки Unified и экосистемы плагинов remark и rehype, сделал 4100 вклада (не знаю как еще перевести contribution) на github за 2022 год, но удивительно не столько само число, а стабильность если смотреть на график почти нет дней без вкладов. Это объясняет как он успевает поддерживать столько разработок.
Processor API - интерфейс Unified
Процессоры используется для подключения и настройки плагинов, запуска процесса обработки контента. Который напомню состоит из трех фаз преобразование контента в AST, трансформации в AST и компиляции обратно контент.
Описание использованных в примерах методов процессора:
processor() - создает новый процессор, готовый к конфигурации с помощью подключения плагинов.
processor.use(plugin[, options]) - подключают плагин, чтобы сделать его частью сконфигурированного процессора
processor.parse(file) - используется с плагином parser, для того чтобы преобразовать контент в AST
processor.stringify(tree[, file]) - используется с плагином compiler, для того чтобы преобразовать AST в контент
processor.run(tree[, file][, done]) - асинхронный метод обработки AST с помощью плагинов трансформации
processor.runSync(tree[, file]) - синхронный метод обработки AST с помощью плагинов трансформации
processor.process(file[, done]) - асинхронный метод обработки контента с помощью плагинов: преобразование контента в AST > трансформация AST > компилятор AST в контент
processor.processSync(file) - синхронный метод обработки контента с помощью плагинов: преобразование контента в AST > трансформация AST > компилятор AST в контент
Типичный пример сконфигурированного процессора:
import {unified} from 'unified'
import remarkParse from 'remark-parse'
import remarkRehype from 'remark-rehype'
import rehypeDocument from 'rehype-document'
import rehypeFormat from 'rehype-format'
import rehypeStringify from 'rehype-stringify'
const file = await unified()
.use(remarkParse)
.use(remarkRehype)
.use(rehypeDocument, {title: '????????'})
.use(rehypeFormat)
.use(rehypeStringify)
.process('# Hello world!')
console.log(String(file))
Входные данные
# Hello world!
Выходные
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>????????</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
<h1>Hello world!</h1>
</body>
</html>
Рассмотрим несколько примеров создания процессоров.
Пример описывающий способы подключения плагинов с помощью метода use
unified()
// Plugin with options:
.use(pluginA, {x: true, y: true})
// Passing the same plugin again merges
// configuration (to `{x: true, y: false, z: true}`):
.use(pluginA, {y: false, z: true})
// Plugins:
.use([pluginB, pluginC])
// Two plugins, the second with options:
.use([pluginD, [pluginE, {}]])
// Preset with plugins and settings:
.use({plugins: [pluginF, [pluginG, {}]], settings: {position: false}})
// Settings only:
.use({settings: {position: false}})
Пример обработки синтаксического дерева с помощью метода run
import {unified} from 'unified'
import remarkReferenceLinks from 'remark-reference-links'
import {u} from 'unist-builder'
const tree = u('root', [
u('paragraph', [
u('link', {href: 'https://example.com'}, [u('text', 'Example Domain')])
])
])
const changedTree = await unified().use(remarkReferenceLinks).run(tree)
Пример обработки контента markdown с преобразованием в html c трансформациями
const processor = unified()
// markdown преобразуем в AST
.use(remarkParse)
// markdown AST преобразуем в HTML AST и далее нужно
// подключать плагины экосистемы Rehype
.use(remarkRehype)
// делаем трансформации в HTML AST добавляем
// или меняем html тег title с контентом ????
.use(rehypeDocument, {title: '????'})
// добавляем поддержку преобразования в строку для процессора
.use(rehypeStringify)
// Для того чтобы использовать процессор и получить результат
// нужно вызвать метод process или processSync
Создание своего плагина
Из прочитанного ранее должно стать понятно: как создавать и сконфигурировать процессор, подключать плагины, какая структура узла дерева и представление о дереве в целом.
Теперь пришло время написать свой плагин. Мы будем писать Tranformer плагин, который обрабатывает AST дерево, а точнее вносит небольшие изменения в html тег "a" добавляет пару свойств target="_blank" и rel="noreferrer" в случае если href не начинается с "#". На сайте unifiedjs.com есть документация в которой описано создание плагина экосистемы retext для работы с естественным языком. Они очень похожи на rehype плагины, которые я использовал в статье, отличие названиях типов в узлах. также там демонстрируется утилита visit из пакета unist-util-visit, которая помогает искать узлы дерева по шаблону.
Шаблон плагина
export default function retextSentenceSpacing(options) {
return (tree, file) => {
}
}
options - в документации не написали этот параметр, но его можно использовать для передачи настроек
tree это корневой узел дерева в rehype экосистеме будет иметь type root
рассмотрим работу на примере создания плагина работты с сcылками a[href], если это внешняя ссылка будем добавлять свойства target="_blank" rel="noreferrer"
import type { Node } from "../unified.types";
import { visit, Node as NodeVisitor } from "unist-util-visit";
export const rehypeAhref = () => {
return (tree: NodeVisitor) => {
try {
visit(tree, { tagName: "a" }, (node: Node) => {
if(!node?.properties){
node.properties = {}
}
const props = node.properties
if(props.href[0] !== "#"){
props.target = "_blank";
props.rel = "noreferrer";
}
});
} catch (err) {}
};
};
и подключение к процессору
unified()
.use(remarkParse)
.use(remarkRehype)
.use(rehypeAhref)
.use(rehypeStringify)
.processSync("[Google](https://google.ru)")
.toString()
результат должен быть
<a href="https://google.ru" target="_blank" rel="noreferrer">Google</a>
Демо приложение
Демо приложение клиент-серверное. На клиенте редактор Markdown, код markdown отправляется на сервер где будет выполнена трансформация Markdown в HTML, код HTML возвращается на клиент, для компиляции html в компоненты React.
Стек компонентов:
React - одна из самых популярных библиотек для создания Frontend-приложений, которую в настоящий момент я очень интенсивно использую.
NextJS - фреймворк для React, его возможности описаны в документации, в демо приложении NextJS используется только как сервер, который может предоставить api для выполнения запросов на сервер с клиента, NextJS разработан специально для React. Так что для меня выбор этого стека был очевидным.
Vercel - площадка на которой развернуто демо приложение
SimpleMDE - простой редактор markdown. В этом демо приложении установлен адаптированный для React пакет react-simplemde-editor. Библиотека unified, экосистема плагинов rehype и remark Для подсветки синтаксиса использовались библиотеки refractor + prismjs
Приложение не обязательно должно быть клиент серверным. Библиотека unified не привязана к React, их можно использовать в среде NodeJS или браузерном js, так как я в последнее время использую React то для меня NextJS это удобный выбор для создания приложения.
Плагины, разработанные для демо приложения:
Плагин, который добавляет к html элементу a[href] атрибут target="_blank" и rel="noreferrer" при условии, что ссылка не ссылает на id этой же страницы. Ссылка на github
Плагин подсветки синтаксиса использует PismJS и refractor, это адаптированный плагин rehype-prismjs. Ссылка на github
Плагин создания блока кода с нумерацией строк и кнопкой копировать код Ссылка на github
Компиляция AST HTML в React компоненты
Предварительно используем плагин rehype-sanitize для того чтобы компилируемое AST html было более безопасным. Например, если мы случайно забудем обернуть строку
<button
className="codecopy"
onClick={handlerCopy}
ref={refBtnCopy}
>
{textBthCopy}
</button>
в Fenced Code Block то плагин трансформации rehype-react будет воспринимать этот код, как JSX и скомпилирует компонент button у которого будет props ref как строка и получим Unhandled Runtime Error
Error: Function components cannot have string refs. We recommend using useRef() instead. Learn more about using refs safely here: reactjs.org/link/strict-mode-string-ref
я использовал rehype-sanitize чтобы компилировались только разрешенные html теги и только с разрешенным списком атрибутов. Плагин rehype-sanitize превратит небезопасную строку в безопасную изменив начальный символ < на escape символ html <, результат будет таким:
<p><button
className="codecopy"
onClick={handlerCopy}
ref={refBtnCopy}</p>
потеряли часть строки, но визуально мы это заметим и исправил, это лучше, чем получить ошибку.
Теперь можно без проблем использовать плагин rehype-react для компиляции html в React компоненты. В демо приложении он используется для копирования кода по клику на кнопку Copy.

Компонент React
const CodeSection = ({
className,
children,
}: JSX.IntrinsicElements["section"]) => {
const refCodeBlock = React.useRef<HTMLElement | null>(null);
const refCodeBox = React.useRef<HTMLElement | null>(null);
const refBtnCopy = React.useRef<HTMLButtonElement | null>(null);
const [copyBtn, setCopyBtn] = React.useState(false);
const [textBthCopy, setTextBtnCopy] = React.useState("Copy");
const handlerCopy = () => {
const range = document.createRange();
range.selectNodeContents(refCodeBox.current as Node);
const buffer = range.valueOf().toString();
navigator.clipboard
.writeText(buffer)
.then(() => {
setTextBtnCopy("Copied");
refBtnCopy.current?.classList.add("copied");
setTimeout(() => {
refBtnCopy.current?.classList.remove("copied");
setTextBtnCopy("Copy");
}, 2000);
})
.catch(() => {
setTextBtnCopy("Copy error");
refBtnCopy.current?.classList.add("error");
setTimeout(() => {
refBtnCopy.current?.classList.remove("error");
setTextBtnCopy("Copy");
}, 2000);
});
};
return (
<section
className={className}
ref={(node: HTMLElement) => {
if (node && refCodeBlock.current === null) {
refCodeBlock.current = node;
refCodeBox.current = node.querySelector(".codebox");
if (refCodeBox.current) {
setCopyBtn(true);
}
}
}}
>
{copyBtn && (
<button
className="codecopy"
onClick={handlerCopy}
ref={refBtnCopy}
>
{textBthCopy}
</button>
)}
{children}
</section>
);
};
Подключение компонента
.use(rehypeReact, {
createElement: React.createElement,
Fragment: React.Fragment,
components: {
section: CodeSection,
},
})
Заключение
В этой статье я изложил свой опыт использования библиотеки Unified для работы с контентом markdown и html, показал насколько просто работать с синтаксическим деревом, сконфигурировать плагины для выполнения изменения контента и разработать и подключить свой плагины. По моему мнению библиотека Unified обладает большим потенциалом и большим набором возможностей. Мне очень интересно ваше мнение и критика. Спасибо.
Оригинал статьи на моем сайте, я открыт для предложений по работе.
Aquahawk
Вопрос не совсем по статье, но вообще про markdown. Есть огромный markdown документ(около 100 страниц) c большим количеством внутренних ссылок по заголовкам, и нужно его распечатать (сконвертировать в pdf) и сделать ссылки с конвертировать в номера страниц, чтобы можно было по нему перемещаться в бумаге. Поверхностный гуглёж ничего внятного не показал.
BogdanPetrov
Могу предложить не самое универсальное, но в целом рабочее решение
Исходный md и результат в pdf
Секция 3 начинается на 4 странице в печатном варианте, поэтому в скобках "4"