

Привет! Меня зовут Андрей, я Head of Platform в финансовом маркетплейсе Banki.ru.
В числе множества сервисов наша команда поставляет площадки разработки и тестирования для коллег. Они появились у нас в 2010 году как «пет-проджект» одного из разработчиков, прижились и через несколько поколений перешли в ведение платформы.
Под катом – рассказ о нашем опыте: его можно назвать и историей успеха, и ошибкой выжившего:) Главное, что в итоге мы все-таки разобрались, какую пользу нам приносят площадки разработки и тестирования и почему они могут пригодиться в других компаниях.
Расскажу по порядку, как развивались наши площадки: как мы делали их со времен одного монолита, что делали, чтобы поддержать переход на сервисно ориентированную архитектуру, и как готовим это все в гибридной среде с виртуалками и кубером сегодня.
Пост получился в двух частях, в первой части расскажу о том, как начиналась эта работа.
Что такое площадка разработчика и тестовое окружение в контексте Банки.ру и зачем они нужны
Начну издалека — с названия площадок. С момента появления выделенной площадки для тестирования мы ее сразу же стали называть «Склянкой». Когда выбирали домен для внутреннего использования, просто решили, что это будет sklianki.ru. Ведь где banki, там и sklianki.
Итак, «Склянка» — это специально подготовленная копия сайта. Среды разработки «Склянкой» мы называем не всегда, иногда просто — «площадка». Каждому разработчику, которому нужно работать с монолитами, мы стараемся сделать свое изолированное окружение. Туда можно развернуть любые версии наших сервисов или даже какое-то их особое сочетание. А главное — в любой момент вернуть все «как было». А каждому тестировщику просто делаем несколько «Склянок», чтобы можно было проверять любой класс задач.
Пожалуй, первый вопрос, который возникает у любого IT-менеджера: зачем вообще нужна площадка для разработки и/или тестирования? Ресурсы тратим, поддержку выделяем, а оно еще иногда и ломается… Мы нашли несколько понятных причин.
Во-первых, на адаптацию в новой компании (а то и команде) разработчику требуется 3,5 месяца (усредненные цифры по опросам разных рекрутинговых компаний). Разработчики — это довольно дорогие сотрудники, при этом они задерживаются на одном месте работы порядка двух лет. Из них, получается, 15% времени уходит на адаптацию. А если речь идет о сложных приложениях и не очень хорошо поставленном процессе онбординга, то хорошая эффективность достигается через полгода. Поэтому все заинтересованы в более быстрой адаптации: и программист, который сразу начинает работать в понятном и предсказуемом окружении, и компания, которая быстрее начинает получать отдачу от своих инвестиций.
Во-вторых, наличие единого унифицированного рабочего окружения позволяет фокусироваться на продуктовых задачах. А тут и time2market поменьше, и качество выше, и выгорание дальше.
Этими целями мы сейчас и оправдываем существование и развитие «Склянок».
Как работала наша система управления разработкой на старте
В далеком 2010 году это выглядело так: приложение, база, кеш. Сверху был еще балансировщик — в целом довольно простая схема.
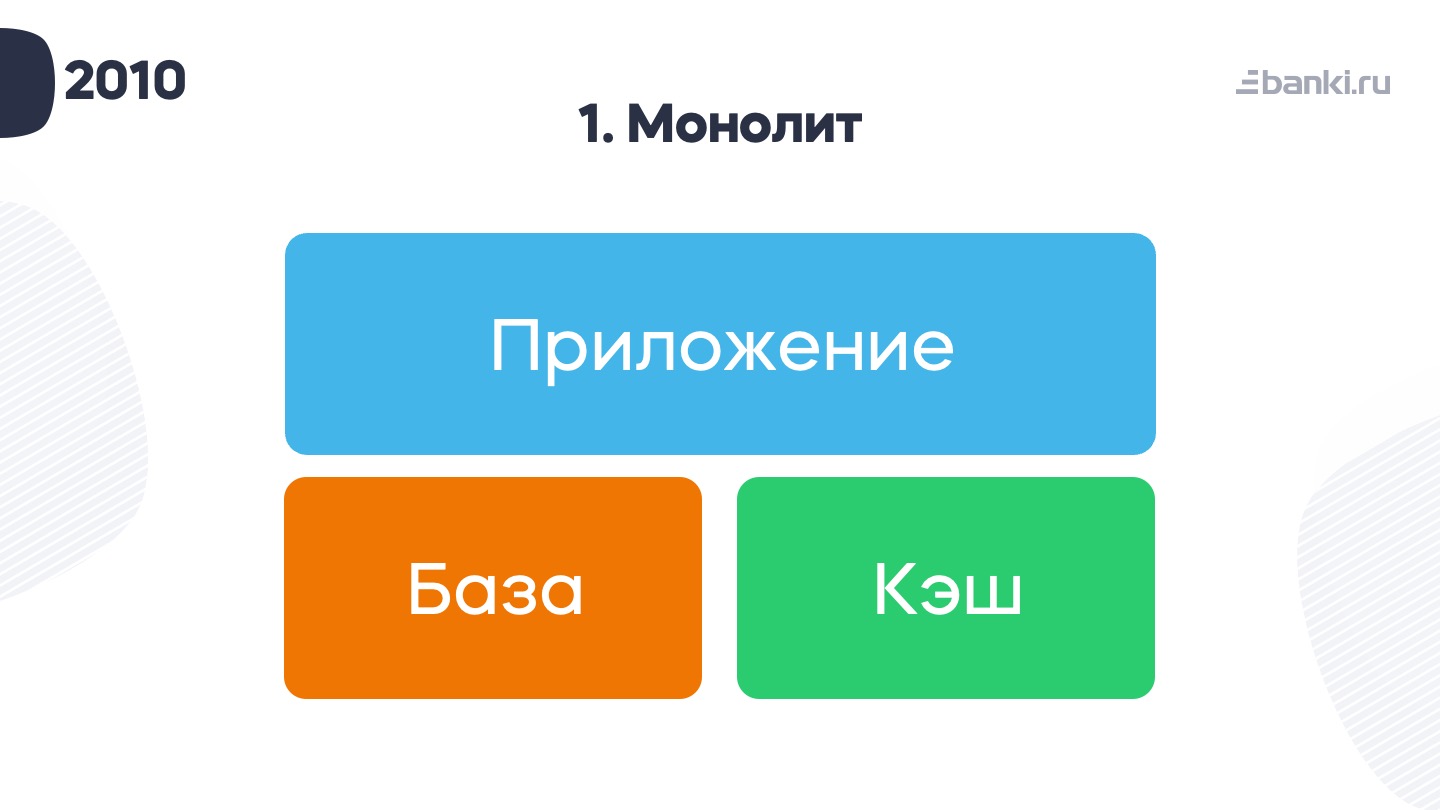
Называлась наша платформа «система управления разработкой 1.0». Это был дев-сервер — целый комплекс приложений. В то время у нас было два сервера для прода и один для test dev (такой еще Тауэр). Там находились Apache, база данных, кэш. Все это дело делилось в Apache vhost’ами (Dev-1, Dev-2, Dev-3…). База данных настраивалась с помощью портов. Mysql: 3306 — основная база (стейдж), 3307 — это база первого разработчика и так далее. Аналогично разбирали мемкэш.
Был отдельный vhost, на котором у нас находились репозиторий (веб-версия), панель управления (php, она же СУР) и база данных для хранения состояний.

Система была неплохая. Можно было кнопкой за час сделать новую площадку. Была даже веб-морда для SVN (олды здесь?). Также был доступ к несколько порезанному dump’у базы production. Хороший инструмент, который (по крайней мере для монолита) был довольно удобным. Использовался Bitrix, поэтому можно было внести в админке изменения, потом запустить инструмент сравнения схем (тоже самописный — очень интересный продукт, хотя и прожорливый с точки зрения ресурсов), и эти изменений выкатить миграцией куда нужно, чтобы не сломать прод.
Почему мы стали думать об изменениях
Система работала ужасно медленно. Когда все площадки находились на одном сервере, они влияли друг на друга. Один разработчик, запустив у себя что-нибудь тяжеленькое, мог отправить всех коллег пить кофе.
Главным же камнем преткновения была поддержка этого кода. Да, хороший объектно ориентированный код. Но, во-первых, это был самописный непростой фреймворк. Во-вторых, он был довольно опасный: под капотом php exeс(), далее шелл-команды. PHP управлял конфигами Apache, базы данных, кэша, у php на сервере был sudo (потом это ружье, конечно, выстрелит).

Наши первые тестовые среды
Когда в 2012 году у нас в Banki.ru появилось тестирование, тестовые среды решили делать примерно по той же схеме. Правда, к тому моменту стало понятно, что нам не хочется расширять СУР (и непонятно было, как это делать). Поэтому мы просто взяли наш монолит, скопировали схему с vhost-ами, написали пяток bash-скриптов, которые делали checkout из репозитория, добавили некоторое шаманство с конфигами.
Так у нас и получились «Склянки». Это четыре условно изолированные среды. На тот момент мы счастливо жили cо стеком из FreeBSD, Apache+PHP 5+Percona на Bare metal без виртуализации.
Но нам хотелось чего-то более расширяемого, поэтому мы начали движение в сторону сервисно ориентированной архитектуры. Монолитная система довольно плохо масштабируется и еще хуже держит нагрузку. А одного репозитория мало даже при четырех командах разработки. К тому же как раз в момент подготовки тестовых сред от нас уволился главный разработчик СУРа, оставив нам крутую, но сложную и капризную систему: она ломалась примерно пару раз в неделю, и обычно два-три часа уходило на ее ремонт.
Однажды один из наших тимлидов на «Склянках» случайно дропнул полностью все настройки вместе с кодом. Сами «Склянки» сломать не удалось, но пропали скрипты деплоя и все конфиги. Тогда же оказалось, что бэкапов тестовых сред у нас нет. Нашлась только версия двух-трех недельной давности у кого-то на рабочих машинах.
Версия «Склянок 2.0»
Так бесславно закончилась история первой версии «Склянок». Но мы решили сделать их заново. Тем более что наши приложения в 2013 году приобрели такой вид: балансировщик, два монолита бэкендов и пачка сервисов.
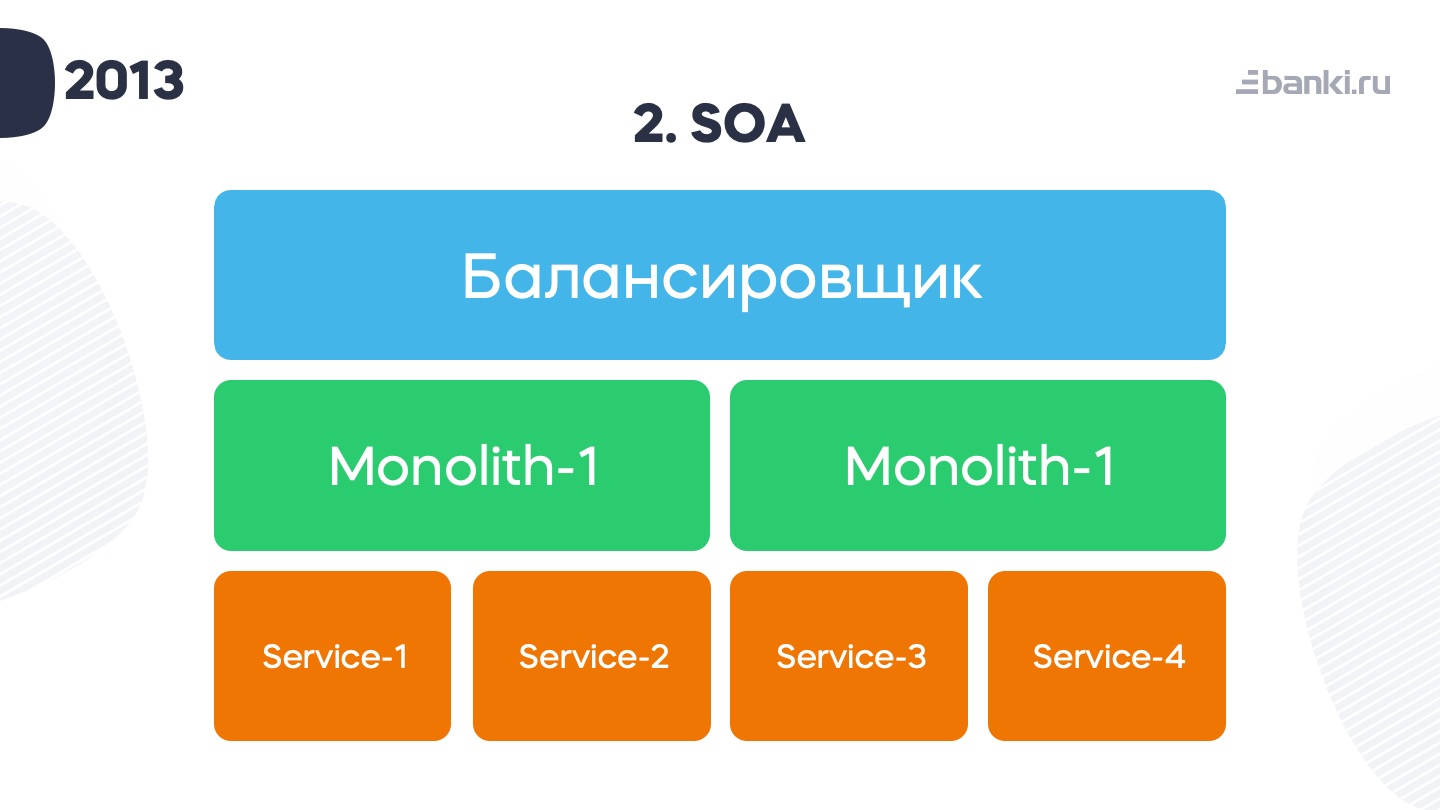
В тот момент мы собрались и решили, что хотим делать более быстрое масштабируемое приложение, а бизнес-логику выносить в сервисы. Одним словом, следовать лучшим на тот момент практикам. Для этого нам пришлось переработать наши тестовые среды. И у нас получилась вот такая картина:
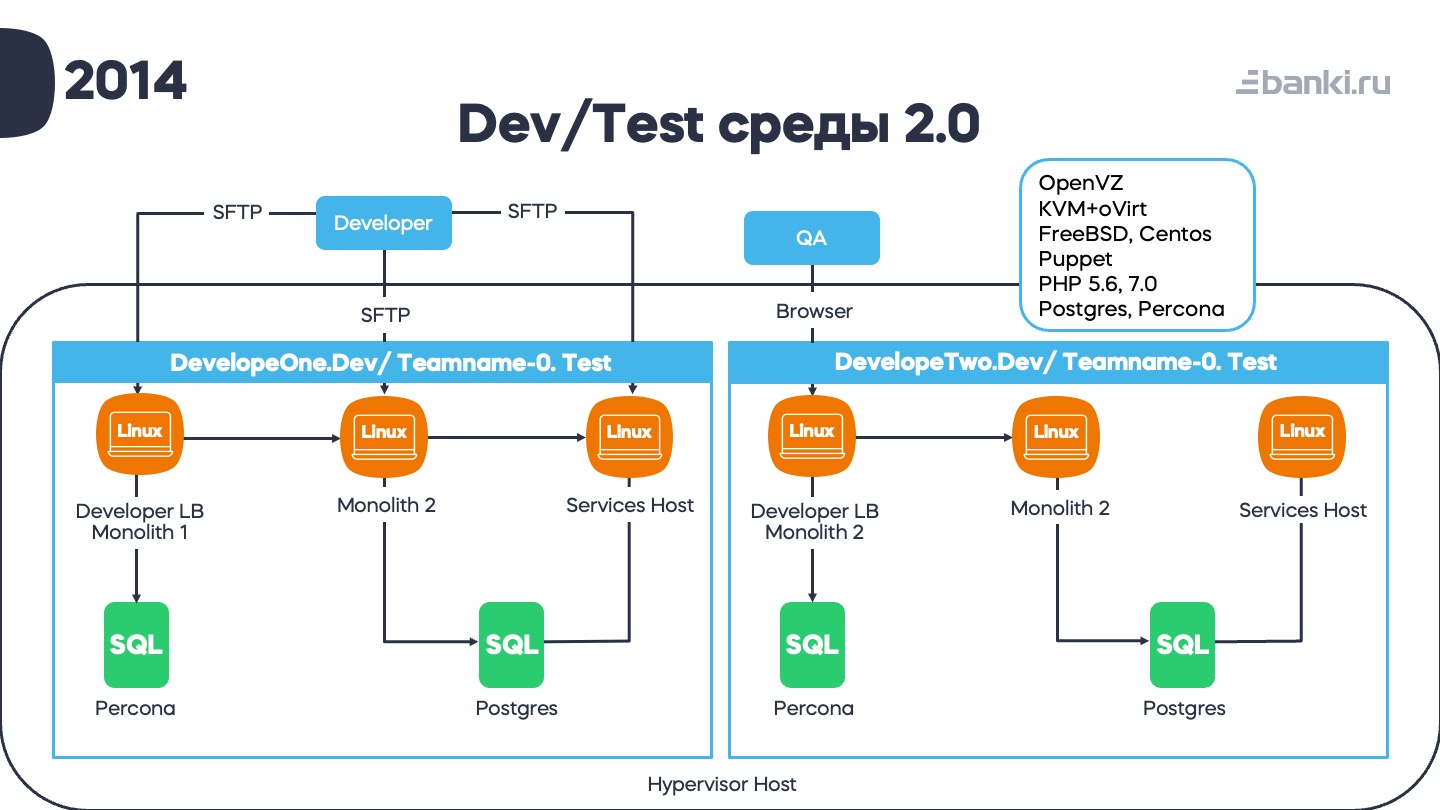
Свои среды для каждого разработчика, а также по одной-две среды для каждого QA-инженера. Разработчик со своими фичами работал с помощью SFTP. Тестирование было функциональное, юнит-тесты откручивались непосредственно на коде. Каждая тестовая среда стоила примерно пять виртуалок. Все это грело несколько достаточно толстых гипервизоров, списанных из продакшена. На каждом из них находилось много тестовых сред: хост для сервисов, хост для одного монолита, совмещенный с балансировщиками, хост для другого и пара баз данных. Так получились среды 2.0.
К стеку прибавились Postgres, php 7, сразу две системы виртуализации (OpenVZ / KVM+oVirt) и Puppet.
Тогда же, кстати, у нас появилась инфраструктура как код.
Puppet прекрасно держал свою конфигурацию в гите. И мы примерно знали, что у нас есть в инфраструктуре, только посмотрев репозиторий.
Но были нюансы. Сами виртуалки нужно было создавать вручную. А из-за одновременной работы CentOS и FreeBSD приходилось поддерживать две системы виртуализации. Сейчас понятно, что желание приблизиться к продакшену стоило довольно дорого и в конечном итоге нам это вышло боком.
CI/CD «склянок»
У нас была кнопка: «Deploy all». Она находилась в Atlassian Bamboo. Система появилась для автоматизации тестирования, а потом ее приспособили и для оркестрации деплоев. От ручного запуска bash-скриптов мы отказались.
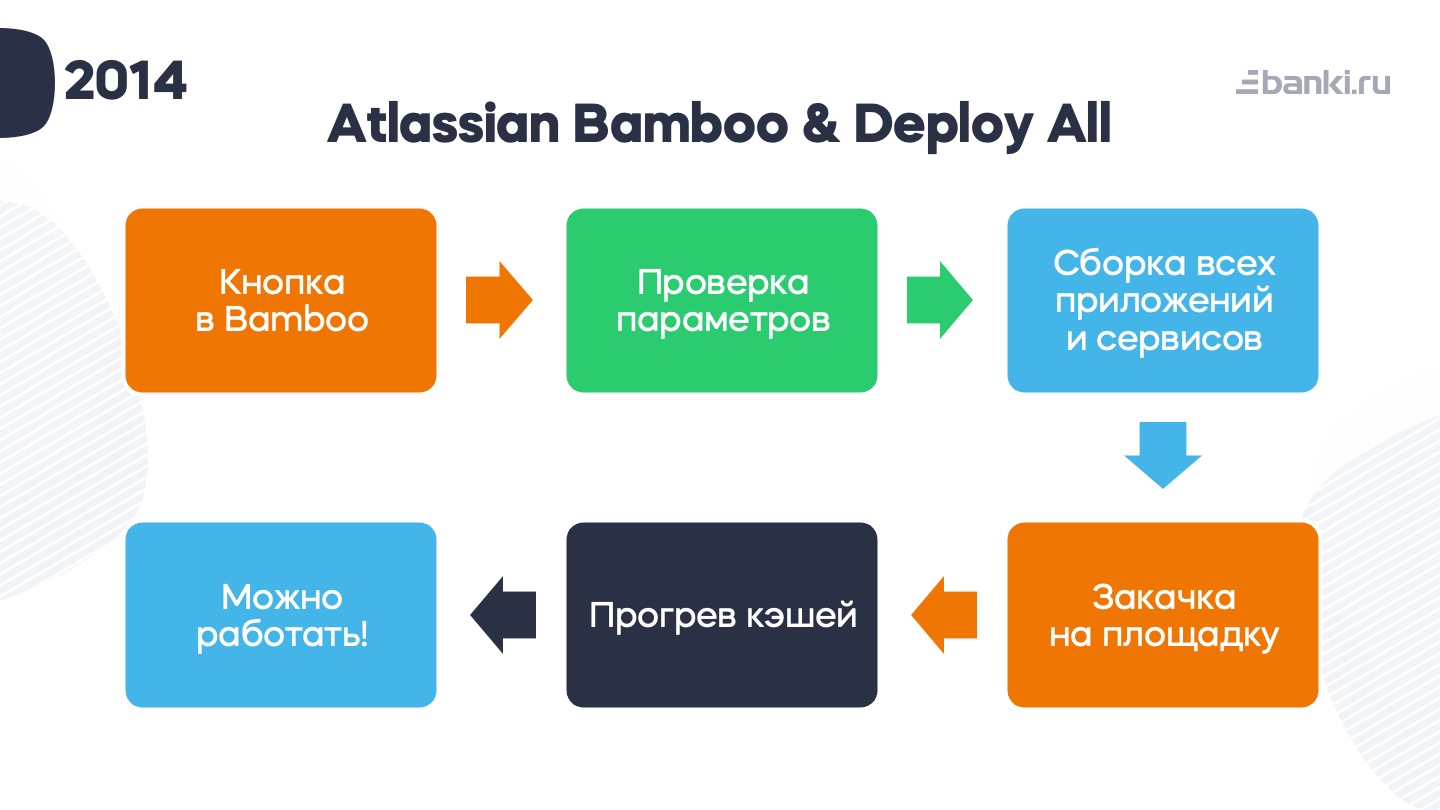
Изначально делали планы, используя плагин-шаблонизатор, от которого потом тоже пришлось отказаться, потому что его перестал поддерживать разработчик.
Пошагово это выглядело так: разработчик или тестировщик нажимал кнопку в Bamboo, вводил параметры (команда, номер площадки, имя разработчика). После этого запускалась сборка всех приложений и сервисов, результат сборки закачивался на площадку, где далее грелись кеши, и можно было приступать к работе.
Промежуточные итоги
За несколько лет техотдел вырос в несколько раз, а «Склянки» позволили этот рост поддержать. Кажется, мы неплохо регламентировали процессы разработки и тестирования, благодаря чему за несколько лет разработали и выкатили много сервисов для пользователей. Какие-то «взлетели», какие-то пришлось потом закрыть или радикально переделать — обычная жизнь. Счастливые лица, смех у кофе-машины и прочие атрибуты успешной технологической компании. Но…
Узкие и проблемные места при эксплуатации «Склянок 2.0»
Поначалу легкие сервисы и монолиты собирались быстро, а полная подготовка площадки занимала десять минут. Тесты крутились, польза приносилась.
Но очень быстро возникли новые проблемы.

Во-первых, система получилась довольно сложной. Много взаимодействий, они часто ломались. Поддерживал это все один девопс, который занимался собственно Puppet’ом. B какой-то момент все его время уходило на постоянный ремонт площадок, а на развитие и техдолг времени уже не оставалось.
Во-вторых, появилась проблема поиска разработчиков. Получается, на площадках мы зафиксировали технологический стек — сделали технологическую платформу, где сервис должен был выглядеть определенным образом, писаться на определенной версии кода. Но со временем многие технологии стали устаревать, стало сложно нанимать под наш текущий стек и развивать платформу не получалось.
В-третьих, каждому мы давали базу данных. Базы данных росли, нужно было писать скрипты деперсонализации и как-то подрезать данные. Постепенно деградировала и сама схема сборки и деплоя. Количество зависимостей росло в геометрической прогрессии, package.json файл уже перестал помещаться в экран монитора, а сборка фронтэнда требовала все больше ресурсов. Эти сборки производились на площадках и в течение рабочего дня безбожно тормозили. При этом быстро выдать ресурс площадкам было нельзя: гипервизоров-то больше не стало. Если один из гипервизоров падал, то падала и часть площадок. Если падал весь стек на Centos, то стек на FreeBSD тоже не работал из-за зависимостей.
В-четвертых, мы сами себе создали оверхед по процессам CI/CD. На каждом запуске выполнялась сборка приложения. Для часто изменяемых приложений это в принципе ок. Но на тот момент у нас восемь из десяти сервисов релизились раз в месяц. При этом собирались они каждый день, по 10–20 раз.
Короче говоря, проблем накопилось много, стало понятно, что пришло время все менять. О том, как мы вышли из положения и к чему это привело, расскажу в следующем посте.

DozenK
Хорошая практика. Спасибо за подробный рассказ.
Adeffeus Автор
Спасибо! скоро будет продолжение.