
Задача была следующей: есть определенный набор скриптов для развертывания сервисов, которые нужно запускать на каждом сервере каждого дата-центра. Скрипты выполняют серию операций: проверка статуса, вывод из-под load balancer’а, выпуск версии, развертывание, проверка статуса, отправка уведомлений через email и Slack и т.д. Это просто и удобно, но с ростом числа дата-центров и сервисов процесс выкатки новой версии может занять целый день. Кроме того, за некоторые действия отвечают отдельные команды, например, настройка load balancer’а. Также хотелось, чтобы управляющий процессом код хранился в общедоступном репозитории, дабы каждый член команды мог его поддерживать.
Решить задачу удалось с помощью Jenkins Pipeline Shared Libraries: этапы процесса разделились визуально на логические части, код хранится в репозитории, а осуществить доставку на 20 серверов стало возможно в один клик. Ниже приведен пример подобного тестового проекта:
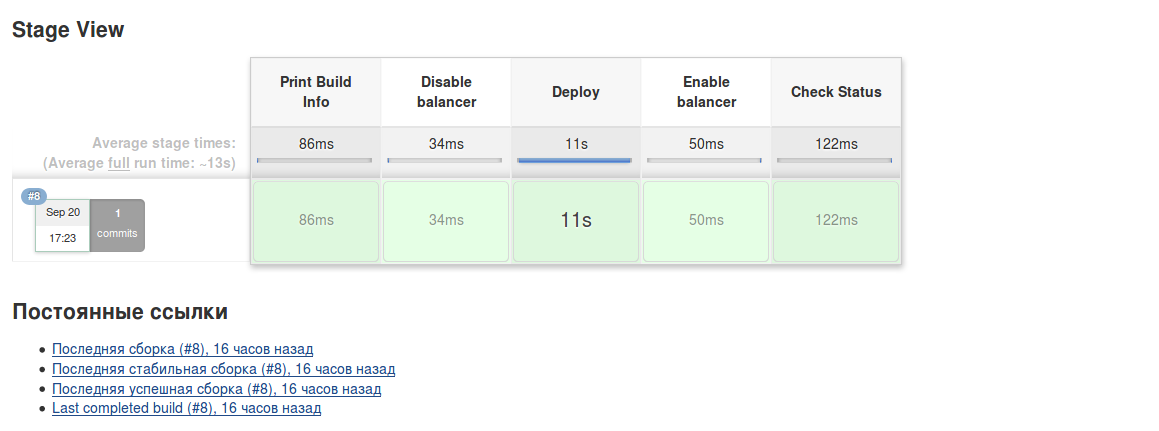
Сейчас я расскажу и покажу примеры как этого достичь. Надеюсь эта статья поможет сохранить время другим разработчикам, а также буду рад дельным комментариям.
Создание библиотеки
Первое что необходимо сделать, создать собственную библиотеку, в которой будут храниться наши функции.
Создаем новый репозиторий, который должен иметь следующую структуру:
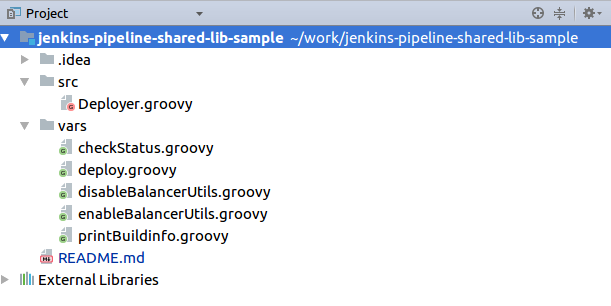
Директория src используется для Groovy классов, которые добавляются в classpath при выполнении Pipeline.
Директория vars используется в скриптах, которые определяют глобальные переменные, доступные из Pipeline.
Ниже приведен пример Groovy класса
@Grab(group = 'org.apache.commons', module = 'commons-lang3', version = '3.6')
import org.apache.commons.lang3.StringUtils
class Deployer {
int tries = 0
Script script
def run() {
while (tries < 10) {
Thread.sleep(1000)
tries++
script.echo("tries is numeric: " + StringUtils.isAlphanumeric("" + tries))
}
}
}
В классах можно использовать любые возможности языка: создавать потоки, соединяться по FTP и т.д.
Важно:
— чтобы выводить в лог консоли из Pipeline, нужно передавать Script;
— для импорта библиотек просто используем
@Grab.Ниже пример скрипта:
#!/usr/bin/env groovy
def call(body) {
echo "Start Deploy"
new Deployer(script:this).run()
echo "Deployed"
currentBuild.result = 'SUCCESS' //FAILURE to fail
return this
}
В скриптах можно использовать любые возможности языка и также получить переменные сборки и параметры Jenkins.
Важно:
— Чтобы остановить выполнение достаточно установить значение
currentBuild.result = 'FAILURE';— Получить параметры параметризованной сборки можно через переменную
env. Например, env.param1.Вот пример репозитория с другими примерами.
Подключение репозитория
Следующий шаг — добавить наш репозиторий как глобальную библиотеку Pipeline.
Для этого в Jenkins нужно перейти: Manage Jenkins > Configure System (Настроить Jenkins > Конфигурирование системы). В блоке Global Pipeline Libraries, добавить наш репозиторий, как на картинке ниже:

Создание Pipeline
Последний шаг — создать Pipeline.
Наш Pipeline будет выглядеть следующим образом:
@Library('jenkins-pipeline-shared-lib-sample')_
stage('Print Build Info') {
printBuildinfo {
name = "Sample Name"
}
} stage('Disable balancer') {
disableBalancerUtils()
} stage('Deploy') {
deploy()
} stage('Enable balancer') {
enableBalancerUtils()
} stage('Check Status') {
checkStatus()
}
Т.е. мы просто добавляем
@Library('jenkins-pipeline-shared-lib-sample')_ (не забываем добавить _ в конце) и вызываем наши функции по имени скриптов, например deploy.Наш Pipeline готов.
В следующий раз я покажу, как я настраивал параметризованную сборку, чтобы элегантно получить зависимые параметры из REST сервиса.
Спасибо за внимание!
Комментарии (17)
Hixon10
21.09.2017 23:02Спасибо за статью, Андрей!
1) Скажите, пожалуйста, у вас получилось как-то подружить Идею с скриптами для Дженкинса?
У меня разразработка для Дженкинса в Идеи выглядит, как написание кода в IDE, в которой данный язык не поддерживается. Всё красное, никаких подсказок по классам. Оно и понятно, я не добавлял в класпас каких-либо jar-ников (которые я сходу не смог найти).
2) Вы пишите, что можно и Джаву использовать. У вас есть опыт? Ведь в дженкинсе вроде бы только на груви можно писать пайплайны?
Andrey_V_Markelov Автор
22.09.2017 09:31Привет,
1. Я импортирую проект как новый модуль и добавляю groovy sdk. Мне этого достаточно
2. Спасибо за замечание — исправил. Более правильно добавить, что можно использовать любые библиотеки с помощью Grabmarxfreedom
22.09.2017 14:44C аннотацией grab тоже не все так просто. Например я пробовал подключить таким образом google guava и при обращении к классам библиотеки получил исключение MethodNotFoundException. Было несложно догадаться и проверить, что код pipeline-а загружается в classloader-е наследнике какого-то classloader-а в Jenkins куда уже загружены библиотеки самого Jenkins. Это может вести к очень неприятным последствиям.

debose
22.09.2017 11:29Подсветка синтаксиса и автокомплит в Idea появляются после подключения библиотек Groovy Sdk И jenkins pipeline gdsl. Вот например: https://gist.github.com/arehmandev/736daba40a3e1ef1fbe939c6674d7da8

dburmistrov
22.09.2017 09:32В скриптах можно использовать любые возможности языка
Oчень смелое заявление. Важно понимать, что это не groovy, а jenkins dsl. Со своим кастомным интерпретатором и своими багами. И с учётом их фишки CPS это даёт незабываемые ощущения при разработке. Так, что тут чем проще, тем меньше шансов наступить на грабли.Andrey_V_Markelov Автор
22.09.2017 09:32Добрый день. Можете привести пример конструкции groovy, которую нельзя использовать внутри функции в модуле
vars?
kefiiir
22.09.2017 09:59+1(1..3).each
и надо еще не забывать, что в дженкинсе по умолчанию запрещено выполнение половины встроенных методов, и их надо разрешать отдельно.Andrey_V_Markelov Автор
22.09.2017 10:06Я обновил пример
И вот мой аутпут:
Enable balancer
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (Check Status)
[Pipeline] echo
Check status
[Pipeline] echo
Number: 1
[Pipeline] echo
Number: 2
[Pipeline] echo
Number: 3
[Pipeline] }
[Pipeline] // stage
[Pipeline] End of Pipeline
Finished: SUCCESS
Можете привести другой пример?kefiiir
22.09.2017 10:59я удивлен, но сейчас это действительно работает, когда пайплайн в дженкинсе только появился подобное работать отказывалсоь, и у меня до сих пор все старые библиотеки пестят конструкциями типа:
for (int i = 0; i < changeLogSets.size(); i++) {
или
@NonCPS
надо будет это переосмыслитьmarxfreedom
22.09.2017 12:54Это буквально недавно в новостях появилось. См. jenkins.io/blog/2017/09/08/enumerators-in-pipeline
Я правда пока не спешу обновлять сервера, есть недоверие что опять заработает только часть конструкций :)kefiiir
22.09.2017 14:53это да, сначала пишешь все на груви, а потом еще день портируешь с груви на груви и без такой-то матери ниогда не обходится.
dburmistrov
22.09.2017 11:48def collection = ['One Two Three'].collect{ it.split(' ') } println "collection: " + collection def result = '' collection.each{ result += it } println "result: " + result
Результат из Script Console:
collection: [[One, Two, Three]]
result: [One, Two, Three]
Результат из пайплайна:
[Pipeline] echo
collection: [[One, Two, Three]]
[Pipeline] echo
result: One
GamePad64
У Pipeline Shared Libraries в таком исполнении есть один существенный недостаток — они ломают концепцию Pipeline-as-Code, когда код хранится и версионируется вместе с пайплайном.
Andrey_V_Markelov Автор
Согласен, но все же зависит от решаемой задачи. В нашем случае используется именно библиотека, потому что очень много команд. Поддерживать очень большой один файл было бы слишком сложно.
ggo
Следует все таки различать декларацию, что хотим получить, и имплементацию декларации.
Куча jenkins-плагинов, это как раз имплементация. Shared Library, из той же оперы.