
Впервые про TECO я прочитал в пародийной статье Real Programmers Don't Use Pascal, написанной незадолго до моего рождения. Там было написано, что настоящие программисты не используют новомодные редакторы EMACS и VI:
Нет, Настоящий Программист хочет редактор вида «Просил? Так получай!» — сложный, загадочный, мощный, не прощающий ошибок, опасный. TECO, если быть точным.
ОригиналNo, the Real Programmer wants a `you asked for it, you got it' text editor — complicated, cryptic, powerful, unforgiving, dangerous. TECO, to be precise.
Это меня заинтриговало. Что за зверь такой, можно ли его пощупать? Википедия рассказала, что TECO — это Text Editor & COrrector, создан он в 1962-м году в DEC и использовался на компьютерах семейства PDP, а позже на системах OpenVMS. Оказалось, что существует порт на Си, который поддерживается энтузиастами в актуальном состоянии и собирается под современными операционными системами. Вот я и решил почувствовать себя настоящим программистом хотя бы немножко.
Компиляция под Linux никаких сложностей не вызвала (надо только поставить libncurses-dev). И вот мы запускаем tecoc и видим мощный интерфейс редактора:
*Да, одна звёздочка. Это приглашение ко вводу команд. Похоже, без инструкции не обойтись. Хорошие новости — инструкция легко ищется в интернете. Это книжка почти на 300 страниц под названием «Standard TECO Text Editor and Corrector for the VAX, PDP-11, PDP-10, and PDP-8». Вот здесь можно почитать в PDF последнюю версию 1990-го года, в это время TECO уже практически был всеми забыт.
Для начала стоит выяснить, как же выйти из этого чуда. Оказывается, нужно ввести EX, а затем два раза нажать Escape. Вообще двойное нажатие Escape приводит к выполнению введённой команды. Клавиша Enter используется просто как перевод строки. Escape отображается на экране как доллар, но введя доллар, вы не получите эффекта Escape. Тем не менее далее если я пишу $, подразумевается, что надо нажать Escape. Так что выходим мы с помощью EX$$ (при этом файлы сохраняются). Отлично, входить и выходить научились — полдела сделано.
Вообще формат команд TECO примерно такой:
[[<число1>,] <число2>] [:] <команда> [<текст1> [ $ <текст2> ] $ ]Довольно непривычно, что аргументы могут идти и слева, и справа. Впрочем, лучше воспринимать это по-другому: числа слева — это не часть команды, а ещё одна команда, которая возвращает число (или пару чисел) в качестве результата. При этом последующая команда может использовать результат предыдущей.
С эскейпами неудобно, потому что если его скопируешь и вставишь, получится просто доллар, который не воспринимается как разделитель. К счастью, есть альтернативный синтаксис для команд с текстовым аргументом: @ <команда> <разделитель> <текст> <разделитель>, где разделитель — любой символ. Например, вставить текст 'Habr' в текущую позицию курсора можно с помощью IHabr$ (I, текст, Escape — ничего не напоминает?), а можно с помощью @I/Habr/. Чтобы упростить себе жизнь, я перешёл на второй синтаксис.
Прекрасно. Хорошо бы научиться вводить какой-нибудь текст в файл. Чтобы указать выходной файл, используется команда EW, а входной файл — команда ER. По-хорошему они не должны совпадать. Оказывается, в те времена было популярно многостраничное представление текстовых файлов с разделением на страницы с помощью символа <FF> или form-feed. Это символ с кодом 12 (0xC), который вводился через Ctrl+L (L — двенадцатая буква английского алфавита). Это не только инструктировало принтер выплюнуть страницу и начать новую, но и позволяло редактировать длинный файл при скромных объёмах оперативной памяти. TECO грузит в память только одну страницу входного файла (до символа <FF>) и позволяет отредактировать её, записать в выходной файл и перейти к следующей. Также есть операции склейки и разделения страниц. Если файл будет один и тот же, понятно, что ничего хорошего не выйдет. Ну ладно, мы со страницами играться не будем, в наши дни это совсем дикость. Наши файлы будут одностраничными. Итак, создадим файл с нуля:
*@EW/habr.txt/$$
*@I/Hello, Habrahabr!
This is TECO, the most powerful editor in the world.
Stop using your fancy IDEs, TECO for the win!
Bye.
/$$
*EX$$Это сработало, действительно появился файл habr.txt с нашим текстом. Я каждую команду завершал двумя Escape, но вообще-то это необязательно. Ну хорошо, а как же всё-таки редактировать существующий файл? Неохота каждый раз выдумывать новое имя. Для этого есть специальная команда EB, которая при первой записи переименует входной файл в *.bak, таким образом соблюдая то, что входной и выходной файл различны. После открытия файла надо не забыть перелистнуть на первую страницу (команда Y), а затем можно вывести всё содержимое файла командой HT:
*@EB/habr.txt/YHT$$
Hello, Habrahabr!
This is TECO, the most powerful editor in the world.
Stop using your fancy IDEs, TECO for the win!
Bye.
*Строго говоря, HT — это две команды. Команда H возвращает пару чисел — 0 и длину текстового буфера, то есть страницы, которая сейчас в памяти. А команда T печатает фрагмент файла в заданном диапазоне смещений:
*0,5T$$
Hello*7,17T$$
Habrahabr!*Да, перевод строки никто вам не добавит лишний раз, попросили пять символов — получайте. Зато всё чётко и ясно. Если команде T передать на вход только одно число, оно интерпретируется как количество строк, которое надо напечатать, считая от позиции курсора вперёд или назад. При этом если курсор в середине строки, то 0T печатает фрагмент от начала текущей строки до курсора, а просто T без параметров — от курсора до конца строки:
*5J$$
*0T$$
Hello*T$$
, Habrahabr!
*Команда J, которой мы воспользовались выше, перемещает курсор на заданное абсолютное смещение (курсор расположен всегда между символами). Ну так как-то некрасиво смотреть, хотелось бы увидеть этот самый курсор. Можно между 0T и T просто напечатать палочку? Да, можно. Команда печати — это ^A (можно ввести Ctrl+A, а можно прямо галочку и букву A по очереди):
*0T@^A/|/T$$
Hello|, Habrahabr!
*Ура, мы теперь умеем видеть позицию курсора. Хорошо бы записать эту команду и при необходимости выполнять её. Если сразу после выполнения команды набрать * и потом букву или цифру, то текст предыдущей команды запишется в соответствующий текстовый Q-регистр (я так и не выяснил, почему не просто регистр, а Q-регистр). Наберём, например, *Z. Теперь содержимое регистра Z можно выполнить как команду с помощью команды MZ:
*MZ$$
Hello|, Habrahabr!
*Отлично, мы записали первый TECO-макрос. Ну бегать по позициям скучно, хорошо бы уметь что-нибудь искать. Поищем, например, слово IDE. Справка говорит, что для этого есть команда S:
*@S/IDE/$$
*И что? Ничего не выдал. Нашёл или не нашёл? А если нашёл, то где? Да, интерактивные редакторы развращают. Раз ничего не выдал, значит, нашёл. TECO просто переставил курсор после найденного текста. Давайте повторим и сразу нарисуем строчку с курсором:
*@S/IDE/MZ$$
?SRH Search failure "IDE"Ой, а теперь-то что? Ага, ищет-то он с текущей позиции курсора, вот второго IDE и не нашлось. Надо сперва перейти к началу файла (можно просто J):
*J@S/IDE/MZ$$
Stop using your fancy IDE|s, TECO for the win!Во, красота. А как насчёт выделить найденный текст с обеих сторон? Тут пришлось изрядно порыть документацию. Пригодились такие штуки:
^S— возвращает длину результата последнего поиска или последней вставки (со знаком минус, чтобы веселее было).— точка возвращает текущую позицию курсора в буфере.C— перемещает курсор вправо на количество символов, возвращённое предыдущей командой (есть и противоположная команда, которая идёт влево, —R).
Соответственно с помощью ^SC можно перейти к началу найденной строки, потом знакомое 0T распечатает префикс, затем выведем [. Далее надо напечатать фрагмент от позиции . до .-^S (помните, что ^S — отрицательное число). Затем напечатать ], вернуть курсор на место с помощью -^SC и вывести остаток строки с помощью T. Вот вся программа:
*^SC0T@^A/[/.,.-^ST@^A/]/-^SCT$$
Stop using your fancy [IDE]s, TECO for the win!
*Отлично, мы уже начали уделывать Перл. Самое время для следующей цитаты из статьи про реальных программистов:
Замечено, что последовательность команд TECO скорее напоминает передачу шума, чем читаемый текст. Весёлое развлечение — набрать в TECO своё имя как команду и попытаться угадать, что произойдёт. Практически любая опечатка при разговоре с TECO может уничтожить вашу программу или, что ещё хуже, внести неуловимый и таинственный баг в когда-то рабочую процедуру.
ОригиналIt has been observed that a TECO command sequence more closely resembles transmission line noise than readable text. One of the more entertaining games to play with TECO is to type your name in as a command line and try to guess what it does. Just about any possible typing error while talking with TECO will probably destroy your program, or even worse — introduce subtle and mysterious bugs in a once working subroutine.
Кстати, некоторое подобие регулярных выражений в TECO тоже имеется. Например, аналогом [A-Z]\d+ будет ^EW^EM^ED. Если вы не любите обычные регулярные выражения, поработайте немного в TECO. После этого будете любить.
Теперь хотелось бы каких-нибудь управляющих структур. Скажем, такая задача: считая, что курсор стоит на начале строки, взять текст строки в красивую рамочку. Кстати, двигаться по строкам вниз — команда L, а вверх — -L. Также вы можете нажимать Ctrl+H и Ctrl+J для быстрого выполнения команд -LT и LT и бегать по тексту туда-сюда.
Для этой задачи нам потребуется вставить столько минусиков, сколько букв в текущей строке. Как это измерить? Можно вызвать . два раза, до и после L, и посчитать разность. Нам пригодится запись и чтение чисел в Q-регистры (число и текст хранятся в Q-регистре с одним и тем же именем независимо). UA записывает число в регистр A, а QA — считывает его. Простой цикл на n итераций — это n<...>. Например, если мы хотим вставить минусик A раз, мы напишем QA<@I/-/>. Весь макрос будет выглядеть так:
.UAL.-QA-2UA-L@I/+/QA<@I/-/>@I/+
|/L2R@I/|
+/QA<@I/-/>@I/+
/-LCВозможно, для кого-то самое непонятное в этом макросе — это -2. А ещё потом 2R. Всё очень просто: перевод строки в те времена всегда занимал два символа, '\r\n'. Никаких разногласий не было, это было прекрасно. Нам надо его вычесть из разности координат начал строк, а для отрисовки правой рамочки надо сходить на два символа влево.
Сохраним этот макрос его в регистр Y. Это, кстати, можно сделать не только через *Y после выполнения команды, а с помощью команды ^U записи строки в регистр: @^UY/текст макроса/. Выполним его, находясь в начале буфера, и получим:
*MY$$
*HT$$
+-----------------+
|Hello, Habrahabr!|
+-----------------+
This is TECO, the most powerful editor in the world.
Stop using your fancy IDEs, TECO for the win!
Bye.
*Супер! Переменные, циклы — это уже похоже на настоящее программирование. Можно идти на собеседование на должность Senior TECO Developer. Кстати, о собеседованиях. Давайте напишем макрос FizzBuzz на TECO. Не знаю, делал ли это кто-то до меня.
Тут пригодилось бы деление с остатком на 15, но операции деления с остатком, к сожалению, нет. Зато есть деление нацело, поэтому можно выразить через x-x/15*15. Правда приоритетов операций тоже нет, поэтому придётся писать -x/15*15+x. Далее в зависимости от остатка надо сделать разные вещи. Если остаток 0, напечатать FizzBuzz, если 3, 6, 9 или 12, то Fizz, если 5 или 10, то Buzz, а иначе — входное число. Для этого пригодится команда O. Без числового аргумента это безусловный прыжок (то есть GOTO), а с числовым аргументом — это вроде switch: nO прыгает на n-ную метку, перечисленную через запятую, если она есть. Метки выглядят как !метка! (так же пишут и комментарии — это просто метка, на которую никто не прыгает). Создадим метки !f! (для Fizz), !b! (для Buzz) и !fb! (для FizzBuzz), а также !e! — конец для выпрыгивания наружу, а-ля break. Вот весь макрос, включая команду его записи в Q-регистр F:
*^UF
UA-QA/15*15+QA@O/fb,,,f,,b,f,,,f,b,,f/QA=@O/e/!fb!@^A/Fizz/!b!@^A/Buzz
/@O/e/!f!@^A/Fizz
/!e!$$Заметьте, что в команду ^A я передаю перевод строки, чтобы вывести его на экран. Представляете, в Java до сих пор нет многострочных литералов, а в TECO они уже были больше полувека назад! Ещё я немного сэкономил, сделав "fallthrough" после ветки !fb! и напечатав "FizzBuzz" из двух половинок. Совсем как в обычном switch-case операторе.
Интересно, что макрос начинается с UA: записать в регистр A число. А какое число? Очень просто — аргумент этого самого макроса. Его надо указать просто перед вызовом. Проверяем:
*4MF$$
4
*5MF$$
Buzz
*105MF$$
FizzBuzz
*87MF$$
Fizz
*44MF$$
44
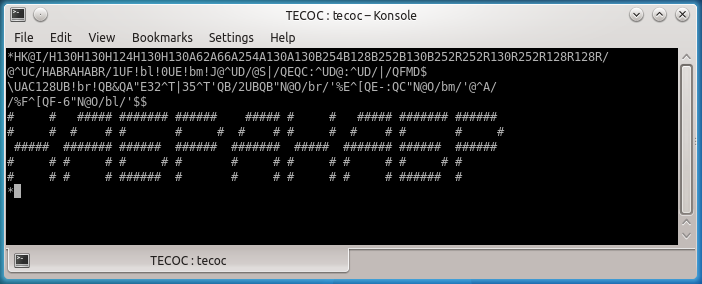
*Супер, мы прошли собеседование! Последний мой эксперимент потребовался, чтобы сделать КДПВ к этой статье. Как написать программу, которая выведет решётками нужные буквы? Похоже, что в языке нет никаких массивов и структур данных. Но зато есть текстовый буфер! Я загнал знакогенератор туда в виде <символ><первая строка битовой маски><символ><вторая строка битовой маски>... (Команда HK очистит текущее содержимое буфера):
*HK@I/H130H130H124H130H130A62A66A254A130A130B254B128B252B130B252R252R130R252R128R128R/$$Спозиционироваться на нужное число можно с помощью J<номер строки>@S/<символ>/, потому что числовой параметр S позволяет найти энное вхождение заданной строки. Я не нашёл как выполнить команду, параметризованную произвольным текстовым параметром, поэтому сформировал команду в Q-регистре D (:^UD дописывает в конец, а просто ^UD заменяет текст в Q-регистре) и выполнил её как макрос. Затем распарсить число можно с помощью команды обратный слэш \. Ещё нам потребуются условные операторы: "N<команда>' — выполнить, если числовой аргумент не ноль, а "E<команда>' — выполнить, если числовой аргумент ноль. Ветку «иначе» тоже можно создать, отделив её трубой. Таким образом, вывод пробела или решётки делается через "E32^T|35^T', где ^T печатает символ с соответствующим ASCII-кодом. Ещё полезная команда %<регистр>, увеличивающая численное значение в соответствующем Q-регистре на единицу.
Регистры я использовал так (чтобы не запутаться, каждый использовался только для числа или для строки):
- A — текущая строка текущей буквы в виде битовой маски
- B — 2^N, где N — текущий бит
- C — строчка, которую надо вывести, все символы должны быть в знакогенераторе
- D — автогенерируемый макрос для поиска битовой маски в знакогенераторе
- E — счётчик текущей буквы
- F — счётчик строк (1-6)
@^UC/HABRAHABR/1UF!bl!0UE!bm!J@^UD/@S|/QEQC:^UD@:^UD/|/QFMD$
\UAC128UB!br!QB&QA"E32^T|35^T'QB/2UBQB"N@O/br/'%E^[QE-:QC"N@O/bm/'@^A/
/%F^[QF-6"N@O/bl/'$$На TECO было написано множество макросов, причём довольно сложных. Разумеется, чтобы хоть что-то понять, хорошо бы структурировать макрос, вставлять переводы строки, отступы и комментарии. Однако выясняется, что это сильно замедляет обработку макроса. Поэтому придумали минимайзеры. Вот код такого минимайзера до минификации, вот он же после. Что-то похожее мы наблюдаем сегодня в мире JavaScript.
Интересно, что имеются команды чтения символа с клавиатуры, в связи с чем макрос можно сделать интерактивным. Используя возможности вывода терминалов через Escape-последовательности, легко позиционировать курсор на экране, обновлять текст фрагментами и переключать цвета. Таким образом с помощью макроса можно обработать каждый вводимый символ или специальную клавишу и сделать интерактивный режим редактирования. Примерно таким образом родился Emacs, который изначально действительно был макросом к TECO, и только потом был переписан как отдельное приложение.
Комментарии (9)

AlePil
19.03.2018 14:10ох ты ж…
и после этого кто-то еще будет говорить, что vi(m) это сложно-неудобно-примитивно…
А вообще, спасибо, очень залипательная древность…


GutenMorg
20.03.2018 03:17Спасибо, уважаемый Lany. Почитал… почему-то развеселило. Вспомнил про месье, который знал толк в извращениях :). В 1990 году начинал с замечательного редактора PE2.


mikelavr
20.03.2018 07:44+1Вот примерно в таких условиях студенты МЭИ вводили программы на Фортран-4 в СМ-4 (она же PDP11/40) в 1985 году с помощью редактора ED. Появление через год экранных редакторов (TED, MIM, micromir) с перемещением по тексту стрелочками выглядело как рывок в будущее. Правда дико тормозило центральный процессор.
И все это на зелёном алфавитно-цифровом мониторе 80*25 с интерфейсом с компьютером на скорости 9600 бит/сек. VT52, если не ошибаюсь.
Barafu
Почему всякий раз, когда кто-то откапывает доисторический софт, вокруг — KDE?
lany Автор
Как-то совершенно случайно получилось, что древняя виртуалка с Кубунтой была под рукой. Так-то я вообще виндузятник :D