
С помощью всего пары скриптов, один из который необходимо положить на сервер, а второй раскидать по клиентам, можно сделать низкоуровневое авто-обнаружение nginx, mongod, rabbitmq, mysql, postgresql и любого другого сервиса.
Конечно мой вариант данной реализации не лишен недостатков и скорее всего гуру меня закидают помидорами! Буду крайне благодарен конструктивной критике и советам.
Ход действий, описание функционала и принцип работы
Навешиваем на хост шаблон авто/обнаружения «Template service auto discovery», в шаблоне или уже на хосте в макрос "{$SERVICES}" добавляем список сервисов (через пробел), которые необходимо обнаружить и поставить на мониторинг.
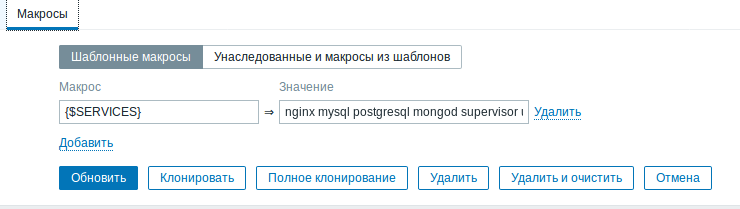
Если необходимый сервис установлен и запущен, например «nginx», то на хосте появляется элемент данных «SERVICE_AUTO_DISCOVERY: detected_and_run_nginx»

и триггер SERVICE_AUTO_DISCOVERY: trigger_detected_and_run_nginx,
через 30секунд срабатывает триггер, а на сработанный триггер запускается действие,
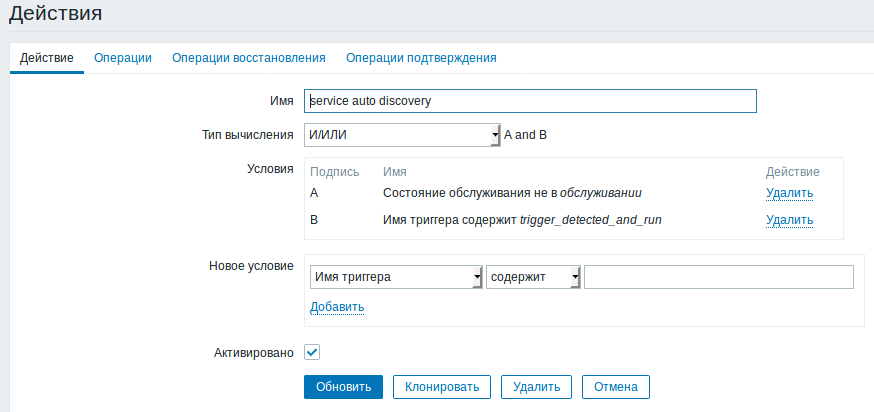
действие выполняет скрипт «auto-discovery.py» (не забудьте в скрипте поменять логин «zabbixapi_API_user» и пароль «password» на свои)на сервере zabbix.
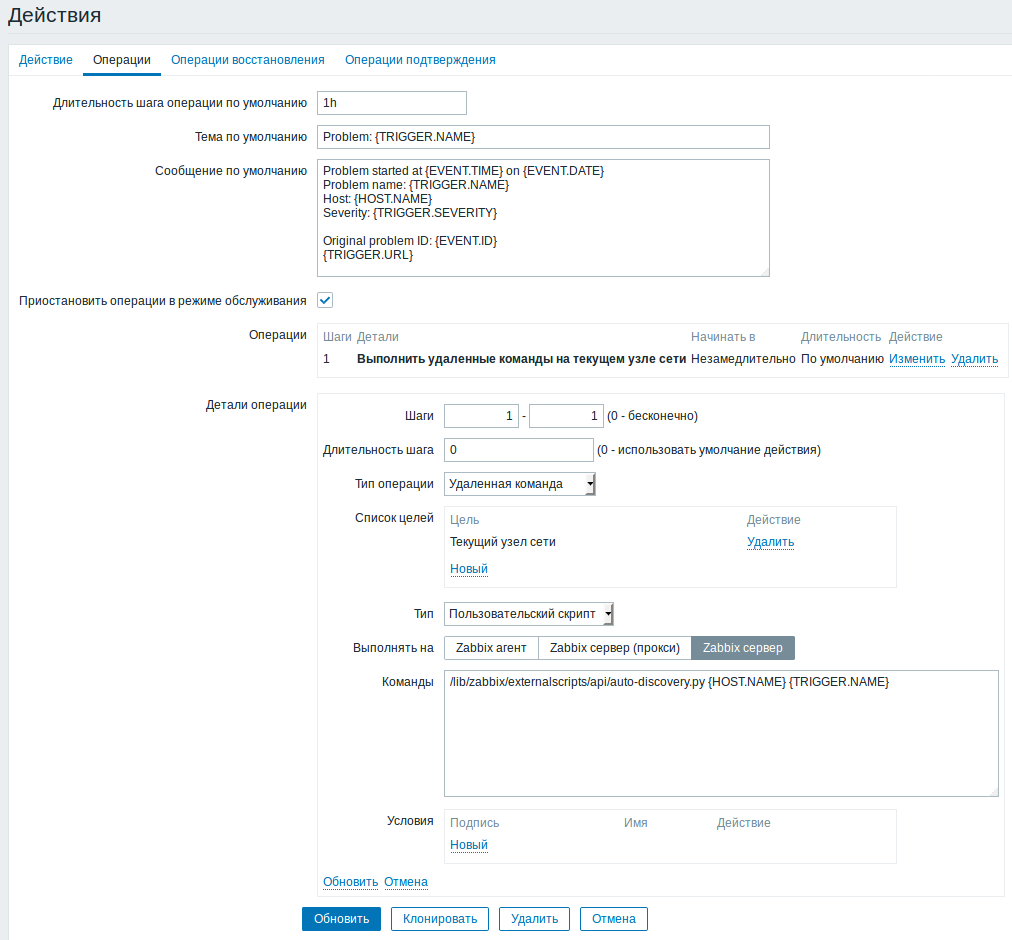
Скрипт в свою очередь через API-zabbix отключает соответствующий триггер и навешивает необходимы для этого сервиса шаблон.

Можно было бы сразу с клиента обращаться напрямую к API, но тогда придется на клиенте держать этот скрипт. Это не очень безопасно т.к. пароль от API придется держать на хосте т.е. в скрипте. Кстати сервер zabbix у нас за NAT.
Было решено, что обнаруживать будем запущенный софт, ведь нет никакого смысла ставить на мониторинг то, что не работает(куча алертов, паника, звонки и т.д.).
Подытожим:
Можно использовать абсолютно любой шаблон для мониторинга любого сервиса. Для этого необходимо переименовать шаблон дав ему имя вида:
«Template_<имя сервиса из макроса>».
То есть для мониторинга БД «mongo» необходимо в макрос "{$SERVICES}" добавить «mongod», а шаблон для мониторинга монги переименовать в «Template_mongod».
Сами скрипты и шаблоны лежат на гитхабе в папке autodiscovery.
Макрос называется {$SERVICE}, в именах сервисов можно опустить ".service", перечислять так-же через пробел.
Прошу обратить внимание, что никаких шаблонов тут не накидывается, а создаётся необходимый для мониторинга сервиса элемент данных и триггер.
Если сервис не обнаруживается, т.е. не создаются триггеры:
На хосте проверяем, как отрабатывает скрипт авто-обнаружения:
/etc/zabbix/scripts/run_service.sh mongo
{"data":[{"{#SERVICE}":"mongo"}]}root@bla_bla_bla:/tmp#
_______________________________________________________________________
/etc/zabbix/scripts/run_service.sh mongo nginx supervisor
{"data":[{"{#SERVICE}":"mongo"},{"{#SERVICE}":"nginx"},{"{#SERVICE}":"supervisor"}]}root@bla_bla_bla:/tmp#
_______________________________________________________________________
/etc/zabbix/scripts/run_service.sh mongodb
{"data":[]}root@bla_bla_bla:/tmp#
Тоесть если сервис не обнаружен, то скрипт вернет пустой JSON.
Если сервис обнаружился, но триггеры не отключаются:
Скорее всего скрипт не может подключиться к API zabbix. Проверяем что происходит:
Со стороны zabbix сервера запускаем скрипт и передаём ему два параметра? первый — имя хоста, а второй — имя триггера. Имя хоста как и имя триггера берем из «вэбморды» zabbixa, имя триггера берем из имени триггера в хосте.
/usr/bin/python3 /lib/zabbix/externalscripts/api/auto-discovery.py {HOST.NAME} {TRIGGER.NAME}Но тут возникает вопрос: Что должно быть первым zabbix или ansible?
Если zabbix, то ошибочные действия в системе мониторинга приведут к ненужной установке лишнего софта.
Если первым будет ansible, то его интеграция с zabbix излишня, ведь zabbix итак всё обнаружит и замониторит, а необходимые для zabbix-agent скрипты и конфиги накидывать во время разворачивания плейбука.
Остаётся третий вариант, когда накидывая шаблон с авто-обнаружением(в котором в макросе перечислены стандартные сервисы) на хост, zabbiz попутно запустит плейбук для разворачивания скриптов и конфигов для zabbix-agent. Но опять-же если сервисы стандартные то и на хосте как минимум при разворачивании этих стандартных сервисов необходимо разворачивать роль для мониторинга.
Комментарии (8)

kreicer
24.03.2018 04:44В целом, идея интересная (и, возможно, кому-то будет полезна), но пока выглядит не оптимально и не гибко. Скрипт на сервере, использование API, необходимая точность в названиях — я почти уверен, что это можно сделать проще. Как будет свободное время, попробую поколдовать на эту тему. А за поднятый вопрос спасибо.

Ash666 Автор
24.03.2018 04:57Вы правы, на первый взгляд выглядит не очень удобно, но на деле всё просто, уже больше полугода используем этот механизм.
На сервер скрипт положили один раз и забыли. Шаблоны которые подтягиваются, так-же переименованы один раз. Новый добавить нет никаких проблем.
На клиентов скрипт раскидывается с помощью Ansible вместе с остальными скриптами.
Будет отлично, если Вы сделаете более элегантное решение! С удовольствием примем его на вооружение.
hanzakkerman
26.03.2018 05:01У нас не разрешено выполнение на агентах произвольных команд со стороны сервера: учитывая тот факт, что даже с использованием tls-шифрования проверка агентом «аутентичности» сервера сводится всё равно к проверке IP-адреса — нам такие вещи не видятся безопасными. Ту же самую схему можно реализовать со стороны агента — и это будет куда более правильно ИМХО. У нас пока тоже реализован автоматический контроль только на уровне systemd (прописываешь в макросе на хосте список «полезных» systemd сервисов — и мониторишь), так что Ваша статья подтолкнула меня подумать над реализацией «автообнаружения с автонавешиванием».

past
25.03.2018 09:19Я делал подобное через https://github.com/cavaliercoder/zabbix-module-systemd помимо состояния сервиса еще мониторятся потребления
past
25.03.2018 09:27Я делал подобное через zabbix-module-systemd. Помимо состояния сервиса еще мониторится потребление памяти и CPU
Ash666 Автор
26.03.2018 05:03Так-то в статье речь идет не только о systemd, скорее наоборот не о нем.
Softer
Ash666 Автор
Исправил, была шибка в названии шаблона!
Спасибо, что заметили