

Сразу ответим на возможный вопрос. Отношение положительных отзывов к отрицательным оказалось никак связано с инцидентами, поэтому нужны были более хитрые методы. К тому же, мы хотели определить темы инцидентов.
Для выявления аномалий выбрали модель авторегрессионного интегрированного скользящего среднего Arima.
ARIMA(p,d,q) для нестационарного временного ряда Xt имеет вид:

Где ?t — стационарный временной ряд; c,ai,bj — параметры модели; ?d — оператор разности временного ряда порядка d (последовательное взятие d раз разностей первого порядка — сначала от временного ряда, затем от полученных разностей первого порядка, затем от второго порядка и т.д.).
Обучали модель на всей выборке. Для прогноза нормального уровня отрицательных отзывов на выбранную дату использовали интервал в три месяца до нее. Предсказание строили на неделю вперед от выбранной даты, с дискретизацией в одни сутки.
Далее сформировали доверительный уровень. Для этого к значению функции прогнозирования на каждую дату прибавили расчетное значение доверительного интервала. За него приняли третий квантиль распределения всех отклонений функции предсказания от фактического количества отрицательных отзывов за трехмесячный интервал, на котором строится предсказание нормального уровня.
Аномалия фиксировалась при превышении фактического количества отрицательных отзывов выше доверительного уровня (прогнозное значение + доверительный интервал). Вот как это выглядит на графике:

Красный цвет – фактическое количество отзывов. Желтый цвет – прогнозное значение нормального уровня с доверительным интервалом
Для дальнейшего анализа отобрали 5 явно выраженных пиков, которые приходились на 27.02.2017, 15.03.2017, 14.09.2017, 18.09.2017, 20.09.2017.
Выявление тем инцидентов проводили путем кластеризации текстов отзывов двумя моделями на основе BIGARTM и Word2Vec со встроенным кластеризатором Kmeans.
Библиотека BIGARTM (тематическая модель)
Тематическая модель — это представление наблюдаемого условного распределения p(w|d) терминов (слов или словосочетаний) w в документах d коллекции D:
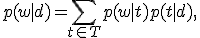
где T — множество тем;
 — неизвестное распределение терминов в теме t;
— неизвестное распределение терминов в теме t;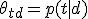 — неизвестное распределение тем в документе d.
— неизвестное распределение тем в документе d.Параметры тематической модели — матрицы
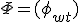 и
и  — находятся путем решения задачи максимизации правдоподобия:
— находятся путем решения задачи максимизации правдоподобия:
Основное преимущество перед другими вероятностными моделями — наличие регуляризаторов для сглаживания, разреживания, декоррелирования.
Модель с Word2Vec
Модель, использующая Word2Vec, основана на тензорной алгебре. Под нее был составлен словарь всех слов в отзывах. Векторное представление слов Word2Vec стало базисным пространством для кластеров.
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:

k — число кластеров, Si — полученные кластеры, i=1,2…к, а ?i — центры масс всех векторов x из кластера Si. Теперь посмотрим результаты работы моделей на конкретных примерах.
Аномальный период с пиком 15.03.2017
BIGARTM:
| № кластера |
Теги |
Примеры отзывов кластера (исходная лексика) |
| 1 |
обновление версия операция счет работать ошибка не_мочь устанавливать удалять перевод вернуть |
«Старая версия не работает. Обновление мне не нужно. Места на телефоне нет! Верните возможность пользования старой версией!!!» «Не могу вообще установить приложение, памяти на телефоне предостаточно, более 50%, но приложение упорно пишет что нет возможности установить, ошибка 24! Исправте ошибку, до этого пользовалась, очень нравилось!!!» «После обновления перестало работать! Появляется окно с сообщением: "«В приложении „“ Сбербанк „“ произошла ошибка»" и до свидания. Дёрнул чёрт обновиться! До обновления всё работало нормально, полностью устраивало. И по ходу не у меня одного такая хрень!» |
| 2 |
соединение зайти писать работать не_мочь память невозможно вылетать постоянно ужасно удалять проблема |
«Не могу зайти в Приложение, ввожу код, пишет, не удается восстановить защищенное соединение! что за дела!? Или вы так принуждаете обновляться! Меня старое обновление устраивало! Решите проблему!» «Что Вы сделали с отличной программой? Обнавила и пожалела. Каждые 2 минуты всплывает окно с текстом "«соединение со сбербанком прервано»". Решила удалить и заново установить. Теперь вообще не открывается. Сразу же выкидывает из программы. Ребят верните старую версию» |
| 3 |
смс не_приходить входить код карта нужно спасибо не_работать вход не_мочь вылетать |
«Не приходит на телефон Смс с паролем» «Не регистрирует, пишет что придёт смс с кодом и ничего ....» «После обновления приходит смс о входе, но порога вылетает через 4 секунды. Как быть?» |
Word2Vec + Kmeans:
| № кластера |
Теги |
Примеры отзывов кластера (исходная лексика) |
| 1 |
обновление соединение зайти пользоваться обновить |
«Не могу зайти в Приложение, ввожу код, пишет, не удается восстановить защищенное соединение! что за дела!? Или вы так принуждаете обновляться! Меня старое обновление устраивало! Решите проблему!» «Соединение разорвано, подключитесь к другой сети — вот что я чаще всего вижу, когда хочу зайти в приложение. Обновления всегда ставлю сразу, когда они выходят. Если зайти удаётся, все работает нормально» |
| 2 |
смс приходить вход телефон зайти |
«После обновления приходит смс о входе, но порога вылетает через 4 секунды. Как быть?» «Не приходит на телефон Смс с паролем» «При регистрации не приходит смс с кодом...» «Не возможно войти.код по смс не приходит.исправте все по скорее.» |
| BIGARTM |
Word2Vec + Kmeans |
 |
 |
Проблемы, выявленные при кластеризации:
|
Проблемы, выявленные при кластеризации:
|
Как видно из результатов, BIGARTM более четко выделяет темы по сравнению с Word2Vec + Kmeans. Для модели Word2Vec + Kmeans не учитывались короткие неинформативные отзывы со словами, не имевшими векторного представления (слова с ошибками, ненормативная лексика и пр.).
Интересно, что в этот период во внутренней системе ServiceDesk инциденты не классифицировались по проблеме обновления версии и обрабатывались отдельно. Это означает, что в данном случае модель справилась с задачей лучше человека.
Распознавание на ранней стадии
А вот пример, демонстрирующий способность нашей модели работать на упреждение. 18.09.2017 в ServiceDesk была зарегистрирована массовая проблема, связанная с невозможностью входа в приложение и проведения платежей у части пользователей. На графике Arima мы видим сильный всплеск негативных отзывов в эту дату, а также незначительный выброс четырьмя днями ранее.

Мы проанализировали оба этих выброса.
14 сентября 2017 г.:
| BIGARTM |
Word2Vec + Kmeans |
 |
 |
Проблемы, выявленные при кластеризации:
|
Проблема, выявленная при кластеризации:
|
18 сентября 2017 г.:
| BIGARTM |
Word2Vec + Kmeans |
 |
 |
Проблемы, выявленные при кластеризации:
|
Проблема, выявленная при кластеризации:
|
А вот как эти результаты соотносятся с данными из ServiceDesk.
| Дата выявления аномалии |
Зарегистрированная проблема в SM |
Определение сути проблемы с использованием BIGARTM |
Определение сути проблемы с использованием Word2Vec + Kmeans |
| 2017-09-14 00:00 – 24:00 |
После обновления приложения образовался повышенный фон обращений от обновленных приложений. |
Проблема с переводом денежных средств. Проблема с интерфейсом. Проблема с входом в приложение после обновления. Проблема с входом в приложение. Пользователь не доволен политикой конфиденциальности. |
Проблема работы в приложении после обновления. Пользователь не доволен политикой конфиденциальности, также есть проблема с переводом денежных средств. |
| 2017-09-18 00:00 – 24:00 |
В период с 09:23 по 15:20 мск для части клиентов Банка зафиксировано увеличение времени входа и проведения операций в Сбербанк Онлайн. Инциденты практически не оказали влияния на работу клиентов, использующих IOS. Повышенное количество обращений клиентов в контактный центр Банка (до 1369 дополнительных звонков за 15 мин.). |
Проблема с входом в приложение после обновления версии. Приложение выдает пользователю сообщение об устаревшей версии. Проблема с входом в приложение. Пользователь несколько раз вводит пароль, приложение виснет. Проблема работы приложения, связанная со встроенным антивирусом. |
Проблема с вводом пароля и входом в приложение. Ошибка обновления версии. |
Очевидно, что 18 сентября большой поток негативных отзывов клиентов и обращений в контактный центр вызван отсутствием должной реакции на инцидент повышенного фона 14 сентября. Данный пример наглядно демонстрирует, что модель могла бы помочь избежать массовой проблемы, распознав ее на ранней стадии.
Также интересно, что в это же время модель обнаружила другую проблему (со встроенным антивирусом), которая не была выделена на фоне основной проблемы. По ней регистрация в ServiceDesk отсутствует.
Подведем итоги
Машинное обучение хорошо справляется с анализом отзывов пользователей. Иногда даже точнее ручной обработки. Это поможет сократить время устранения инцидентов мобильного приложения и сделать его лучше.
Возможно, подобные методы подойдут не только для выявления инцидентов, но также для анализа нейтральных и положительных отзывов с целью выделения приоритетных пользовательских кейсов. Это поможет развивать функциональность приложения на базе предпочтений клиентов без дополнительных затрат по их сбору и анализу. Но эту идею нужно еще проверять…
Комментарии (7)

WizardryIB
12.07.2018 14:53Напишите нам, куда вас послали с предложением по использованию ваших наработок из службы сопровождения компании!?
DSBTeam Автор
14.07.2018 01:03Andriljo спасибо за интересное предложение!
В принципе да, так тоже можно. Но мы решили, что предсказание непрерывной величины (значения нормы на дату) больше подходит для наших данных, чем бинарная классификация. Дело в том, что однозначно разметить аномалии можно только по явным пикам, которых значительно меньше условной «нормы». Т.о. мы получаем высокую несбалансированность обучающей выборки, где классу 1 соответствует на порядок меньше примеров, чем классу 0. Есть риск, что незначительные выбросы при таком обучении xgboost тоже загонит в 0, а они как раз очень ценны с т.з. раннего прогнозирования (как показано во втором примере).

Andriljo
14.07.2018 01:03А не пробовали предсказывать аномалии, как дисперсия в прогнозируемом окне. Например при прогнозе на 7 суток, берем окно в 7 дней вперед и считаем в нем дисперсию -> ставим как целевой признак. Если комментарии «нормальны» по числу, то дисперсия будет мала, если аномальный уровень появится, будет пик. Пики можно нумеровать как 1-есть аномалия, все что ниже порога (обычно около 0) — ставим 0-нет аномалии. Далее классификатор из xgboost и уаля детектор без АРИМА и т.п.
DSBTeam Автор
14.07.2018 01:09Andriljo спасибо за интересное предложение!
В принципе да, так тоже можно. Но мы решили, что предсказание непрерывной величины (значения нормы на дату) больше подходит для наших данных, чем бинарная классификация. Дело в том, что однозначно разметить аномалии можно только по явным пикам, которых значительно меньше условной «нормы». Т.о. мы получаем высокую несбалансированность обучающей выборки, где классу 1 соответствует на порядок меньше примеров, чем классу 0. Есть риск, что незначительные выбросы при таком обучении xgboost тоже загонит в 0, а они как раз очень ценны с т.з. раннего прогнозирования (как показано во втором примере).
smind
Я снес сберонлайн после того как оно запросило достут к фото.
до этого сбер выкачал себе телефонные книги пользователей, а учитывая их клиентскую базу это огромнейший граф который непонятно как и кто будет использовать.
DSBTeam Автор
Ну почему же, как раз понятно :)
Спецпроекты в Сбербанк-Технологиях: как в банках готовят Hadoop, Spark, Kafka и прочую Big Data