

В 2014-м году я присоединился к небольшой команде в Schibsted Media Group в качестве 6-го специалиста по Data Science в этой компании. С тех пор я поработал над многими начинаниями в области Data Science в организации, в которой теперь таких уже 40 с лишним человек. В этом посте я расскажу о некоторых вещах, о которых узнал за последние четыре года, сперва как специалист, а затем как менеджер Data Science.
Этот пост следует примеру Robert Chang и его отличной статьи «Doing Data Science in Twitter», которую я нашел очень ценной, когда впервые прочитал ее в 2015-м году. Цель моего собственного вклада ? поведать настолько же полезные мысли специалистам и менеджерам Data Science по всему миру.
Я поделил пост на две части:
- Часть I: Data Science в реальной жизни
- Часть II: Управление командой Data Science
В части I я сфокусировался на той работе, которую в реальности выполняют специалисты по Data Science, в то время как в части II обсуждается, как максимально эффективно управлять командой Data Science. Я бы сказал, что обе части важны и для специалистов, и для менеджеров.
Я не буду тратить много времени на описание того, кем является и кем не является специалист по Data Science, ? на эту тему достаточно статей по всему Интернету.
Коротко о Schibsted: медиа и маркетплейсы в 20 с лишним странах по всему миру. Я работаю в основном над нашим бизнесом маркетплейсов, где миллионы людей покупают и продают товары каждый день. Если вы хотите взглянуть на несколько реальных примеров работ в области Data Science в Schibsted, вот небольшая подборка:
- Выставление цен на автомобили
- Предсказание потенциальных подписчиков новостей
- Вывод пользовательских атрибутов
С учетом вышесказанного, давайте погружаться!
Часть I: Data Science в реальной жизни
Начинать специалистом по Data Science в новой компании с большими амбициями ? это действительно потрясающе, но также может показаться страшным. Чего ожидают от меня люди вокруг? Каким уровнем квалификации будут обладать мои коллеги? Как мне работать, чтобы быть полезным компании? На позиции, вокруг которой столько шумихи, временами сложно не почувствовать себя самозванцем.
Страх показаться простаком часто побуждает специалиста по Data Science сосредоточиться в первую очередь на сложности. Это приводит нас к первому выводу.
1.1. Сложность увеличивает стоимость, начинайте с простого
Они наняли специалиста по Data Science, так что эта проблема наверняка должна быть действительно сложной, не так ли?

Это предположение очень часто будет вводить вас в заблуждение как специалиста по Data Science. Прежде всего, проблемы, с которыми вы встречаетесь в бизнесе, очень часто решаются с помощью довольно простых методов. Во-вторых, важно помнить, что сложность увеличивает стоимость. Сложная модель, скорее всего, повлечет за собой больше работы по ее внедрению, более высокий риск ошибок и больше сложностей с ее объяснением заказчикам. Следовательно, вы должны всегда сначала искать самый простой подход.
Но как понять, достаточно ли самого простого подход?
1.2. Всегда имейте базовую модель
Оценки качества вашей модели, скорее всего, не имеют смысла сами по себе без сравнения с базовой моделью. Сравнения с точностью при случайном выборе, в большинстве случаев, просто недостаточно.

В какой-то момент мы построили модель для прогнозирования вероятности того, что пользователь вернется на наш сайт ? модель возвращаемости. В нашей модели использовалось около 15 признаков, основанных на поведении пользователей, и мы достигли точности около ~0.8 ROC-AUC. Сравнивая с точностью случайного предсказания (0.5), мы были вполне довольны этим результатом. Но когда мы выкинули из модели всё, кроме двух самых важных признаков: недавность (число дней с последнего посещения) и частота (число дней посещений в прошлом), мы обнаружили, что простая логистическая регрессия по этим двум переменным дала нам 78% ROC-AUC! Другими словами, мы могли бы достичь более 97% производительности, выбросив более 85% признаков.
Я столько раз видел, как специалисты по Data Science показывают результаты офлайн-экспериментов над сложными моделями без какой-либо простой базовой модели для сравнения. Когда вы видите такое, вы всегда должны спрашивать: могли ли мы добиться того же результата с помощью гораздо более простой модели?
1.3. Используйте данные, которые у вас есть
Однажды я обедал с инженером данных и другим специалистом по Data Science. У последнего загорались глаза, когда он говорил обо всех удивительных вещах, которые он мог бы сделать «если бы только у него были данные об X, Y или Z». В какой-то момент во время разговора инженер рассмеялся: «Вы, специалисты по Data Science, всегда рассказываете о том, что могли бы сделать с данными, которых у вас нет. Как насчет сделать что-нибудь с данными, которые у вас есть?».

Это прозвучало грубо, но инженер выразил важную истину. У вас никогда не будет идеального набора данных и всегда будут данные, которые вы могли бы использовать. В большинстве случаев вы сможете сделать что-нибудь с тем, что у вас есть.
1.4 Возьмите на себя ответственность за данные
Как было сказано выше, качество и полнота данных почти всегда являются проблемой. Но вместо того, чтобы сидеть и ждать, когда кто-то преподнесет вам данные на блюдечке, вам нужно выступить и взять на себя ответственность за данные, которые вам нужны.

Я не говорю о формальном владении в смысле модели управления данными. Я говорю о том, чтобы расширить свою роль и помочь там, где это возможно, чтобы получить нужные вам данные.
Это может означать участие в создании схем и форматов сбора данных. Это может означать просмотр кода Javascript, выполняющегося в интерфейсе веб-приложения, чтобы убедиться, что события запускаются, когда следует. Или это может означать построение конвейеров данных, не дожидаясь, что инженеры данных сделают все за вас.
1.5. Забудьте про данные
Очевидно, что это противоречит всему, что я сказал выше, но очень важно не слишком зацикливаться на данных, которые у вас есть.

Когда появляется новая проблема, вы должны сначала попытаться забыть имеющиеся данные. Почему же? Да потому что существующие у вас данные могут ограничивать пространство решений, и это может отвлечь вас от поиска наилучшего подхода. Вы застрянете в локальном оптимуме, где вы пытаетесь натянуть решение любой проблемы на тот набор данных, который вам доступен (использование превыше изучения). Как следствие, у вас никогда не будет новых наборов данных.
1.6. Выработайте детальное представление о причинности
Мы все знаем, что корреляция не предполагает причинно-следственной связи. Проблема в том, что многие специалисты по Data Science на этом останавливаются и боятся связать причину со следствием.

Почему это проблема? Потому что менеджеров по продукту, маркетинговую команду, вашего CEO или с кем вы там работаете, совершенно не волнует корреляция. Их волнует причинно-следственная связь.
Менеджер по продукту хочет быть уверенным, что, когда он решит выпустить эту новую функцию, он вызовет 10%-ный рост вовлеченности в продукт. Маркетинговая команда хочет знать, что увеличение количества писем от 2 в неделю до 4 не заставит людей отписаться от рассылки. А генеральный директор хочет знать, что инвестирование в лучшие настройки таргетирования приведет к увеличению доходов от рекламы.
Ну так и есть ли компромиссное решение? Оказывается, их два.
Наиболее известны онлайн-эксперименты. По сути, вы запускаете рандомизированные испытания, среди них наиболее популярны A/B-тесты. Идея проста: поскольку мы случайно выбирали, кто будет в целевой группе, а кто в контрольной, то, если мы обнаружили статистически значимое различие между группами, примененное нами «лечение» можно считать причиной. Не вдаваясь в философские рассуждения, на практике это разумное предположение.
Менее известный подход к поиску причинно-следственных связей ? это каузальное моделирование. Идея здесь в том, что вы делаете предположения о причинно-следственной структуре мира, а затем используете данные наблюдений (неэкспериментальные), чтобы проверить, согласуются ли эти предположения с данными, или оценить силу различных причинно-следственных связей. Adam Kelleher написал замечательную серию статей «Causal Data Science», которую я советую прочитать. Помимо этого, библия причинности ? это книга «Causality» Judea Pearl.
По моему опыту, большинство специалистов по Data Science имеют большой опыт создания моделей машинного обучения и их офлайн-оценивания. Гораздо меньше тех, кто имеет опыт онлайн-оценивания и экспериментов. Объяснение простое: вы можете скачать набор данных из Kaggle, обучить модель и оценить ее офлайн за считанные минуты. Чтобы оценить эту модель онлайн, с другой стороны, нужен доступ к реальному миру. Даже если вы работаете в интернет-компании с миллионами пользователей, вам часто приходится преодолевать много преград, чтобы выставить вашу модель машинного обучения перед пользователями.
Теперь, если немногие специалисты по Data Science имеют большой опыт онлайн-оценивания, то очень немногие имеют опыт работы с каузальным моделированием. Я думаю, на то есть много веских причин. Одна из причин заключается в том, что большая часть книг по причинности довольно теоретические, среди них мало практических руководств о том, как начинать каузальное моделирование в реальном мире. Я предсказываю, что в ближайшие несколько лет мы увидим более практические руководства по каузальному моделированию.
Выработка детального представления о причинности позволит вам давать практические рекомендации своим заказчикам и при этом поддержит вашу целостность как специалиста по Data Science.
Часть II: Управление командой Data Science
В Schibsted, как и во многих других компаниях, есть два пути карьерного роста: в качестве самостоятельного работника и в качестве руководителя. В контексте Data Science первый предназначен для тех, кто действительно хочет приумножить свои знания в области Data Science и внести свой вклад в компанию благодаря практической работе и техническому лидерству. Путь руководителя предназначен для тех, кто более увлечен развитием людей и управлением командой.
Я вовсе не был уверен, какой путь подходит мне, но в конечном итоге решил попробовать путь руководителя. Не прошло много времени, когда я понял, что это действительно правильный путь для меня, но я, конечно, столкнулся с множеством проблем (и я до сих пор это делаю!).
Первый вызов, с которым вы столкнетесь, ? это то, что в мире очень мало других менеджеров Data Science. Если вы думали, что опытные специалистов по Data Science редки, то опытных менеджеров Data Science в разы меньше. Таким образом, вы в той или иной степени оказываетесь предоставлены сами себе.
Но правда ли, что управление командой Data Science настолько отличается от управления другими типами команд? И да, и нет.
Если вы никогда не управляли командой раньше, наверняка вам поможет классическое чтиво по менеджменту вроде «High Output Management» Andrew Grove. Кроме того, проактивное обращение за советом к старшим руководителям (из других дисциплин) также имеет решающее значение.
Однако команды Data Science имеют несколько ключевых отличий, поэтому сейчас мы сосредоточимся на выводах, в особенности имеющих отношение к командам Data Science.
2.1. Команда Data Science на самом деле не команда
Когда большинство людей думает о командах, они думают о чем-то вроде этого:

Каковы некоторые характеристики футбольной команды, такой как FC Barcelona? По крайней мере три вещи:
- Общая цель
- Различные роли в команде, каждая из которых имеет разные обязанности
- Независимость в достижении своей цели
Если вы управляете командой, состоящей только из специалистов по Data Science, скорее всего, ни одна из этих характеристик не выполняется. Вместо этого у вашей команды будут:
- Множественные, изменяющиеся цели
- Специалисты, и они хороши в одном и том же: Data Science
- Другие команды, с которыми можно работать, чтобы в конечном итоге оказать влияние на пользователей и доходы
Более подходящая аналогия, чем футбольная команда, для команды специалистов по Data Science, выглядит так:
Спрос на услуги Малдера и Скалли меняется со временем. Их привлекают, когда требуется их опыт. И они никогда не разрешат дело, не разговаривая с людьми за пределами ФБР.
Почему это различие важно?
Потому что, если у вас есть команда специалистов по Data Science, и вы управляете ими как «классической» командой с общей целью, различными ролями и полной автономией, вы очень быстро получите фрустрированную команду.
Я видел команды Data Science, управляемые как любая другая команда продукта или разработки, и неизбежным следствием этого является то, что специалисты по Data Science начинают делать все что угодно, кроме Data Science. Вместо этого они в итоге занимаются разработкой, декомпозицией или управлением продуктом.
Так что специалисты по Data Science отличаются. Но как вы тогда гарантируете, что ваша Data Science не будет жить в башне из слоновой кости?
2.2. Встраивайте специалистов по Data Science в другие команды
Магия происходит, когда вы ставите специалистов по Data Science рядом с менеджерами продукта, программистами, исследователями интерфейса, маркетологами и прочими.
Попросту целевая функция, которую вы хотите максимизировать, заключается в следующем: плодотворное взаимодействие между специалистами по Data Science в вашей команде и людьми в других командах.
Мне нравится думать об этом, используя концепцию широкого канала. Давайте проиллюстрируем это с помощью менеджера продукта в паре со специалистом по Data Science.
Хуже всего, когда между ними нет никакого канала:

Это означает, что между DS и PM не происходит коммуникация. Другими словами, DS не будет знать о каких-либо проблемах с продуктом, с которыми сталкивается PM, что делает невозможным анализ или решение этих проблем.
Немного лучше, когда у нас узкий канал между ними:
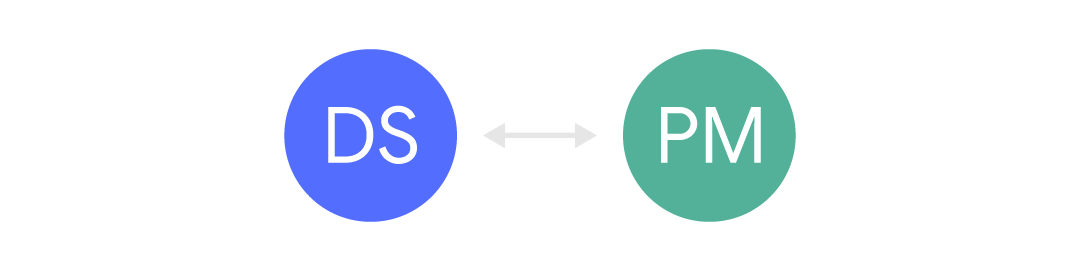
В этом случае информация приходит, но обычно ограниченно и часто асинхронно. Информация приходит через других людей (например, другого менеджера) либо через формы запроса и т. д. Этот тип общения распространен, когда ожидается, что специалисты по Data Science будут обслуживать множество разных заказчиков. Но это может фрустрировать, потому что бизнес-контекст часто отсутствует, и это может привести к недоразумениям и бестолковой возне.
Наиболее эффективное состояние ? это когда у нас есть широкий канал:

В самом буквальном смысле, широкий канал ? это когда специалист по Data Science сидит рядом с менеджером продукта. Это, естественно, позволяет им общаться гораздо эффективнее. Располагать людей физически близко не всегда бывает удобным или даже возможным (мы в Schibsted разбросаны по 22 разным странам!), но есть виртуальные версии этого принципа: от Slack до удаленного парного программирования и Hangouts.
Естественно, у вас не получится каждому менеджеру продукта в компании организовать широкий канал с каждым специалистом по Data Science в вашей команде, это не масштабируется. Ваша задача как менеджера Data Science определить, когда какие широкие каналы организовать. А потом убраться с дороги!
Одним из случаев в Schibsted, когда мы активно работали над созданием широкого канала, была разработка нашего инструмента оценки автомобилей, который помогает вам установить цену при продаже вашего автомобиля (попробуйте его на нашем норвежском маркетплейсе Finn). Первоначально у нас был довольно тонкий канал, вроде такого: «Попробуйте построить самую точную модель ценообразования, какую сможете». Мы обнаружили, что это довольно неэффективно, поскольку было много продуктовых вопросов, на которые мы не могли ответить, не поэкспериментировав с пользователями на ранних стадиях.
Однако спустя некоторое время всё закончилось тем, что мы встроили одного из наших специалистов по Data Science в продуктовую команду, и получили результаты намного лучше. Вы можете прочитать о некоторых из наших ранних работ по инструменту оценки автомобилей в этом посте.
Пример того, когда у нас был широкий канал с самого начала, ? это модель прогноза новых цифровых подписок. Модель помогла увеличить конверсию продаж на 540% и была вознаграждена премией INMA «Лучшее использование анализа данных» в 2017-м году.
2.3. Возьмите на себя ответственность за производительность аналитики
В книге «High Output Management» Andrew Grove заявляет, что вам как менеджеру принадлежат результаты работы вашей команды. Это означает, что менеджер Data Science должен инвестировать средства в создание наилучшей возможной среды для своих специалистов по Data Science, чтобы они были продуктивными.

Это во многих отношениях противоречит модели встраивания, описанной выше. Если все время всех встраивать, есть большая вероятность, что вы в результате получите склады данных и неоптимальную инфраструктуру, продублированную несколько раз.
Некоторые менеджеры разработки утверждают, что когда вы станете руководителем, вы должны полностью перестать кодить. Я думаю, что как менеджер Data Science вы должны тратить до 10% своего времени на самостоятельную работу: обучение моделей, визуализацию данных и т. д. Это ставит вас на место специалиста по Data Science.
«Я должен потратить 15 минут, ожидая, когда этот кластер загрузится, каждый раз, когда я захочу сделать ad-hoc анализ?! Разумеется, должен быть более быстрый способ сделать это».
«Эта документация по нашим форматам схем кажется устаревшей ? как я буду измерять клики на этом типе кнопок на разных сайтах?»
И так далее и тому подобное.
Конечно, такая работа руками не должна заменять проактивное получение обратной связи от вашей команды. Но это, безусловно, поможет вам обнаружить ключевые области, где можно упростить жизнь вашим специалистам по Data Science.
Вы также можете быть более методичным и использовать фреймворки, такие как Lean Management, чтобы стремиться к ликвидации потерь в различных процессах Data Science. Этот пост от всегда блестящих XKCD послужит отправной точкой:
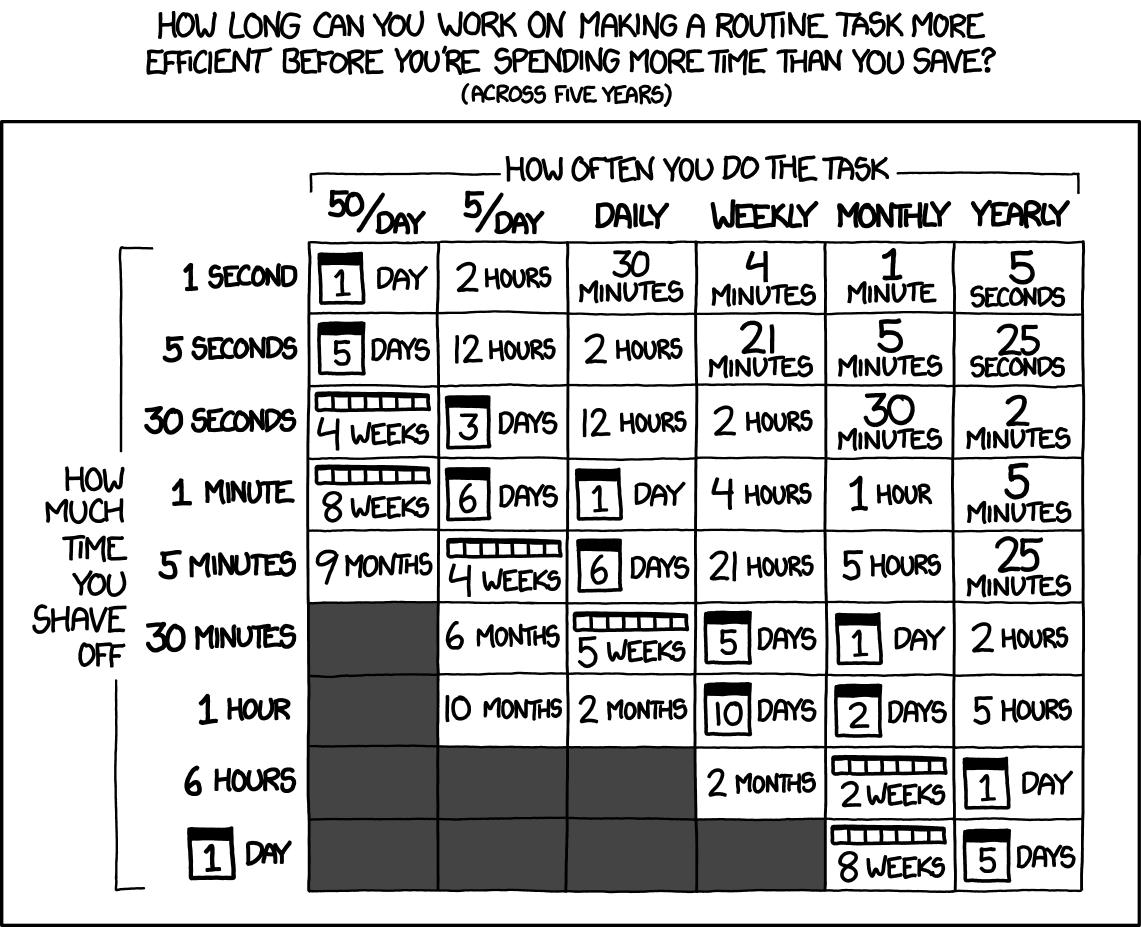
Просто помните, что в работе специалиста по Data Science должно быть довольно много гибкости и возможности для исследований. Вы не фабрикой управляете!
2.4. Данные -> Власть -> Политика
Важно знать «политический» контекст, в котором вы работаете как менеджер Data Science, особенно в крупной и сложной организации. Управлять командой Data Science означает управлять скудными и востребованными ресурсами. Это, в свою очередь, означает, что вам обязательно придется иногда заниматься политикой.

Некоторые гипотетические примеры:
Вице-президент намерена предложить новую стратегическую инициативу. У нее на 98% готова презентация, но она хочет помощи от вашей команды, чтобы подкрепить свое предложение данными (… после того, как выводы уже сделаны).
Бизнес-юнит отказывается делиться данными с вашей командой, опасаясь, что вы обнаружите что-то в данных, о чем они не знают.
Отдел настаивает на том, что им нужен Data Science, но когда вы копаете глубже, оказывается, что там нет реальной необходимости, только мотивация увеличить штат.
Другая команда с частично перекрывающейся областью ответственности неохотно делится методологией, опасаясь, что вы украдете их работу.
Количество времени, которое вам нужно потратить на подобные ситуации, во многом зависит от культуры вашей компании и того, какие стимулы существуют для людей, которые ведут себя таким образом. Но всегда хорошо осознавать, что это происходит.
Моя собственная наивная вера состоит в том, что прозрачность ? самое сильное лекарство. На практике это означает руководить, подавая пример. Все записи со встреч открыты для всех в компании. Все каналы Slack являются общедоступными. Цели команды (и индивидуальные тоже!) открыты для всех в компании, кто захочет их проверить.
Прозрачности самой по себе недостаточно. Вы должны активно работать над укреплением доверия со своими заказчиками. Для укрепления доверия требуется много времени, но он его можно очень быстро разрушить!
Теперь, до какой степени вы должны погружать людей в вашей команде в политику? Я бы сказал, настолько, насколько абсолютно необходимо для понимания контекста их работы. Это не означает, что вы держите своих людей в неведении, но это означает, что они могут сосредоточиться на делании отличной Data Science.
Не позволяйте политике занимать слишком много вашего внимания. Но имейте в виду, что, когда у вас есть доступ к данным и ресурсы, чтобы получить от этого ценность, вы сразу же получаете власть. И политика всегда будет окружать власть.
2.5. Используйте свои ресурсы, стремитесь к высокой окупаемости инвестиций
Столько компаний сейчас нанимают специалистов по Data Science. Во многих случаях эти компании в принципе понятия не имеют, для чего они будут их использовать. Но, конечно же, они смогут создать какую-то магию, правда?
Если вы купили Ferrari, не бросайте его в гараже.

Кроме того, не используйте его только лишь для покупки продуктов.

Используйте свой Ferrari для того, для чего он был построен.

Специалисты по Data Science ? это амбициозные, умные, деловые люди. Это значит, что вы должны убедиться, что они работают над проблемами, которые не просто сложны, но имеют высокую окупаемость инвестиций (ROI).
Здесь важную роль играет менеджер Data Science. Вы должны последовательно сочетать правильный набор бизнес-задач с людьми в вашей команде, которые помогают их решить.
Возвращаясь к нашему первому пункту, возникает соблазн сосредоточиться сначала на проблемах, которые связаны с наибольшей сложностью. По моему опыту, вы должны, прежде всего, думать о ценности при рассмотрении того, куда инвестировать ресурсы ? то есть, где использовать людей из вашей команды. Как упоминалось ранее, сложность увеличивает стоимость, и вы тоже должны это учитывать.
В то же самое время, специалистов по Data Science привлекают сложные задачки. Таким образом, нужно помнить о балансе. Но ценность, которую можно дать бизнесу, по моему опыту гораздо более мотивирует, чем сама по себе сложность.
2.6. OKR для фокусировки и выравнивания
Одинаково важно иметь хорошие инструменты как менеджеру, так и специалисту по Data Science. И самым мощным инструментом менеджера являются Objectives and Key Results (OKR). Вкратце, OKR ? это создание нескольких амбициозных, качественных целей и сопоставление количественных ключевых результатов с этими целями. Как правило, вы делаете это ежеквартально. В OKR есть ещё много всего, но суть в этом.
OKR очень мощные, потому что простым способом они гарантируют, что каждый знает точно, в каком направлении мы идем, и чего мы пытаемся достичь.
Они также увлекательны с точки зрения менеджера, потому что методологию OKR легко выучить, но на удивление трудно освоить. Обычно это занимает несколько кварталов, прежде чем вы действительно поймете ее правильно: как их устанавливать, отслеживать и проверять.
Есть две вещи, которые я нахожу особенно полезными как менеджер, когда дело доходит до OKR.
Во-первых: поощряйте всех в вашей команде создавать личные OKR. Ваши личные OKR должны учитывать в совокупности то, что вы, как человек, хотите достичь в этом квартале. Когда я говорю «в совокупности», я имею в виду ваши личные цели роста и ваш вклад в организацию и команду вокруг вас. Я не могу выразить, насколько важно держать эти две вещи в одном и том же месте. Это такая простая вещь, но это действительно помогает вам согласовать свои личные цели с целями компании.
Хочешь узнать больше об LSTM? Отлично, давай ты поучаствуешь в этом NLP-проекте, где мы знаем, что LSTM будут использоваться. Стремишься улучшить свои навыки презентации? Ты можешь поработать над этим проектом анализа удержания с маркетингом. Хочешь попробовать путь руководителя? Попробуй возглавить эту команду, работающую над сегментированием пользователей для монетизации.
После выравнивания индивидуальных целей и целей компании все члены вашей команды будут иметь одну страничку с OKR, которую они смогут буквально распечатать и повесить рядом со своим монитором.
В идеале, все личные OKR видны всем в компании. Это создает культуру, в которой люди сосредотачиваются на росте и помогают друг другу достичь своих целей.
Во-вторых: помогите членам вашей команды интегрировать OKR в свою ежедневную и еженедельную рутину. Я начал использовать простую таблицу, которую члены моей команды адаптировали для собственных нужд. Это некрасиво, но зато работает:
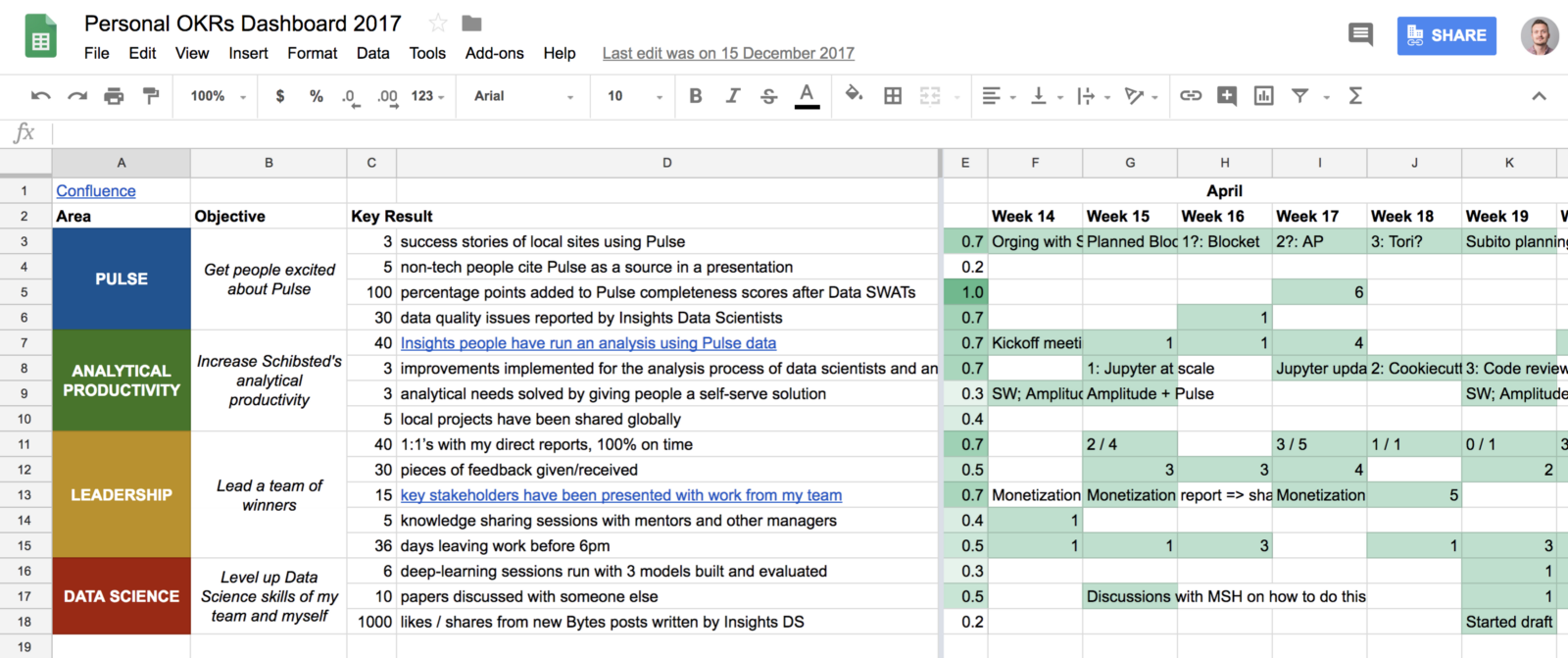
Каждую пятницу перед тем, как отправиться домой, мы проводим 10 минут, заполняя колонку этой недели. То, что вы пишете, не так важно ? ценность исходит от самого ритуала. Это поможет вам узнать о ваших главных приоритетах в этом квартале. Персональные OKR также неоценимы в беседах один на один с членами команды.
Не существует единственно верного способа, работающего для всех, когда дело доходит до выполнения OKRs ? ключевым моментом является помочь членам вашей команды найти способ естественным образом встроить их в ежедневную и еженедельную рутину.
2.7. Прежде всего психологическая безопасность
И под конец самый важный момент.
Когда Google изучал свои команды в течение двух лет, чтобы узнать, что заставляет одни команды работать хорошо, а другие ? недорабатывать, была одна вещь, которая выделялась. Это психологическая безопасность.
Вкратце, психологическая безопасность может быть обобщена как убеждение, что вы не будете наказаны, когда совершите ошибку.
Теперь подумайте об этом в контексте введения в часть I. Синдром самозванца очень велик в Data Science. А чего вы боитесь, когда чувствуете себя самозванцем? Делать ошибки.
На протяжении многих лет я обнаружил, что люди из разных областей приходят в Data Science. В нашей команде в Schibsted нам повезло, что у нас есть фантастические люди с очень широким спектром опыта. Люди с опытом работы в области финансов, научных исследований, образования, консалтинга, разработки программного обеспечения и т. д.
Было бы глупо предположить, что все эти люди знают одно и то же. Напротив, ценность такого разнообразного опыта заключается в том, что каждый привносит в команду что-то новое.
Представление о «единороге» Data Science ? яд для психологической безопасности.
Есть ли быстрое решение повысить психологическую безопасность? Я так не думаю. Но я считаю, что она должен быть наверху списка приоритетов у вас в качестве менеджера ? особенно когда вы создаете новую команду или когда к вам присоединяются новые члены. Хоть и нет быстрого решения, но есть четкие меры, которые вы можете предпринять для повышения психологической безопасности. Вот некоторые из тех, что хорошо сработали для нас:
- Создайте культуру обратной связи. Дайте понять, что члены вашей команды обязаны сообщать друг другу «плюсы и что можно улучшить» после презентаций, спринтов и т. д. Кстати, вы как менеджер тоже должны это делать! И обучите людей тому, как правильно дать конструктивную обратную связь ? это не для всех естественная вещь.
- Увеличьте время работы лицом к лицу. Парное программирование, решение проблем на доске… Это особенно важно для удаленных команд. Этот авиабилет почти наверняка стоит своих денег.
- Создавайте пары или команды вместо индивидуальной работы. Вы можете в конечном итоге сделать меньше вещей в команде, но вы сделаете это лучше. И те, кто работает вместе, будут строить доверие друг к другу.
- Поощряйте открытые и честные дискуссии на встречах. Работайте активно над тем, чтобы сбалансировать время в эфире всех участников ? некоторых людей, возможно, придется попросить выступить.
- Помните о культурных различиях. Вы можете происходить из эгалитарной, явной и прямой культуры. Есть большая вероятность, что вы пропустите сигналы от члена команды, происходящего из иерархической, неявной и косвенной культуры.
- Проводите групповые эксперименты для постоянного совершенствования. Вовлечение всей команды в проблему «как вам успешно управлять командой» дает каждому чувство ответственности за благосостояние команды.
- Измеряйте счастье и психологическую безопасность. Найдите простой способ регулярно задавать вопросы, касающиеся счастья и психологической безопасности. Если у вас нет модной системы HR для этих целей, просто начните с Typeform и итерируйте, пока вы и команда не найдете, что это полезно. Поделитесь (анонимными) средними оценками или выводами с командой и включите их в то, как улучшить ситуацию.
…
Поздравляю, вы дошли до конца! Надеюсь, этот пост был немного полезен для вас как специалиста или менеджера Data Science.
Мы прошли довольно много, вот краткий список:
Часть I: Data Science в реальной жизни
1.1. Сложность увеличивает стоимость, начните с простого
1.2. Всегда имейте базовую модель
1.3. Используйте данные, которые у вас есть
1.4. Возьмите на себя ответственность за данные
1.5. Забудьте про данные
1.6. Выработайте детальное представление о причинности
Часть II: Управление командой Data Science
2.1. Команда Data Science на самом деле не команда
2.2. Встраивайте специалистов по Data Science в другие команды
2.3. Возьмите на себя ответственность за производительность аналитики
2.4. Данные -> Власть -> Политика
2.5. Используйте свои ресурсы, стремитесь к высокой окупаемости инвестиций
2.6. OKR для фокусировки и выравнивания
2.7. Прежде всего психологическая безопасность
…
Спасибо за прочтение! Если это было полезно, подумайте о том, чтобы поделиться этим постом с другими. Надеюсь когда-нибудь увидеть ваши собственные мысли о работе в качестве специалиста или менеджера Data Science
grt_pretender
Хорошая статья.
А вот это вообще актуальная ловушка в любом исследовательском процессе: