
Конечно, в данном случае речь идет о скорости «сырого тома». В реальной жизни к нему добавляется файловая система, операционная система, приложения и все такое. Так что на самом деле не все так плохо. Однако есть и программно-аппаратные способы увеличения производительности, независимые от указанных подсистем. Речь идет о технологиях кэширования, когда к массиву из жестких дисков добавляется существенно более быстрый накопитель на базе флэшпамяти.
В частности в RAID- контроллерах Adaptec эта технология называется maxCache и ее версия 3.0 реализована в моделях ASR-8885Q и ASR-81605ZQ. При ее использовании необходимо учитывать несколько особенностей: допускается наличие только одного тома maxCache на контроллер, максимальный объем тома maxCache составляет 1 ТБ, для работы кэширования записи необходимо иметь отказоустойчивую конфигурацию самого тома maxCache (например, зеркало). При этом пользователь может самостоятельно указывать для каждого логического тома как конкретно он будет работать с maxCache – на чтение и/или на запись и в каком режиме.
Для тестирования использовался сервер на базе материнской платы Supermicro X10SLM-F, процессора Intel Xeon E3-1225 v3 (4C/8T, 3,2 ГГц), 32 ГБ оперативной памяти, работающий под ОС Debian 9.

Тестируемый контроллер ASR-81605ZQ штатно имеет блок защиты памяти и при работе с массивом из жестких дисков у него активны кэши и на чтение и на запись. Напомним, что объем собственной памяти у этой модели – 1 ГБ. Массив RAID6 с блоком в 256 КБ создавался из шести жестких дисков Seagate ST10000NM0086 с интерфейсом SATA и объемом 10 ТБ. Общий объем тома составил около 36 ТБ.
В качестве SSD-накопителей для тома maxCache выступали две пары устройств: два Samsung 850 EVO второго поколения по 1 ТБ с интерфейсом SATA и два Seagate 1200 SSD (ST400FM0053) по 400 ГБ с интерфейсом SAS, из которых создавались массивы RAID1. Конечно, первая модель уже может считаться устаревшей и не только морально. Но для иллюстрации бюджетного сценария она подойдет. Вторая формально лучше подходит под «корпоративную» категорию, но и ее сложно считать современной. В настройках самого массива maxCache есть только опция Flush and Fetch Rate, которая оставалась на значении по умолчанию (Medium). Возможности выбрать приоритет по операциям или дисковым томам нет. Отметим, что накопители были не в новом состоянии и TRIM в данной конфигурации не используется.
После создания тома maxCache нужно включить в свойствах логического тома параметры для его использования. Всего здесь предусмотрено три опции: включение кэша на чтение, включение кэша на запись и тип кэша на запись.
В качестве тестового инструмента применялась утилита fio, а набор сценариев включал в себя последовательные и случайные операции с разным числом потоков. Стоит заметить, что исследование производительности продуктов с кэширующими технологиями синтетическими тестами сложно признать оптимальным вариантом. Адекватно оценивать эффект лучше на реальных задачах, поскольку синтетическая нагрузка в определенной степени противоречит самой идее кэширования. Кроме того, в данном случае мы рассматриваем низкоуровневые операции, а по факту пользователь обычно имеет дело с файлами и в работу с ними включаются, как мы говорили выше, файловая система тома, операционная система и непосредственно программное обеспечение. Так что именно синтетика, привлекательная своей простотой и повторяемостью, имеет смысл не сама по себе, а в основном для сравнения «как было и как стало» в сложных для алгоритмов кэширования сценариях и достаточно грубой оценки эффекта.
Посмотрим сначала, на что способен наш массив сам по себе. Напомним, что в последовательных операциях интересна скорость в МБ/с и задержки (в логарифмическом масштабе), а на случайных – IOPS и тоже задержки.
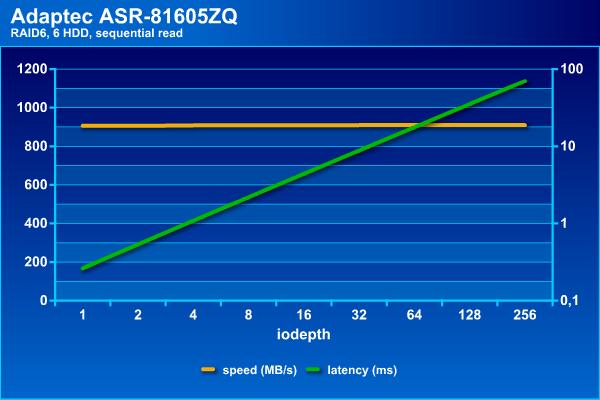
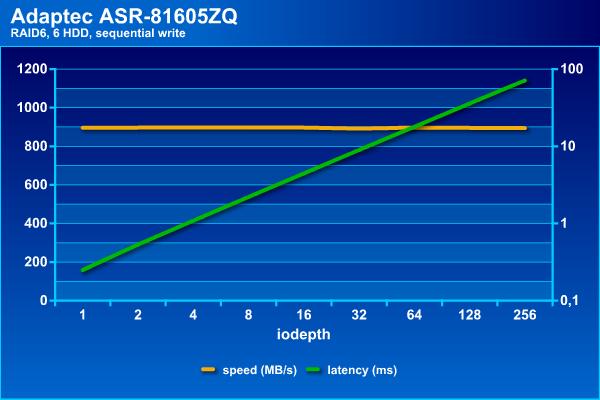
Скорость потоковых операций с массивом данной конфигурации находится на уровне 900 МБ/с. При этом задержки не превышают 70 мс даже при большом числе потоков.
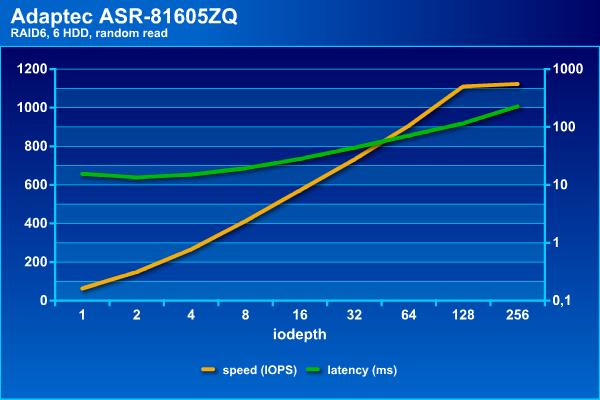
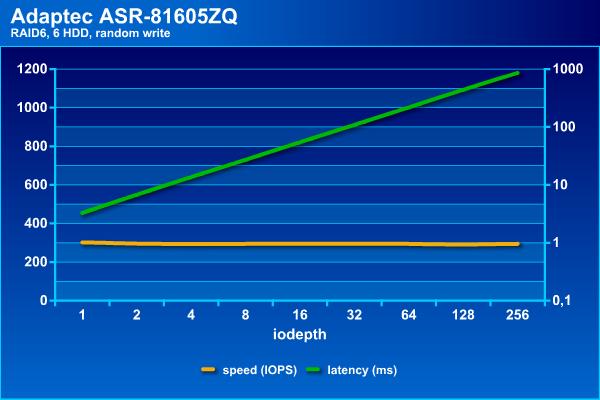
Для жестких дисков случайные операции являются самой сложной нагрузкой, что видно по результатам. Если поставить порог времени ожидания на уровне 100 мс, то на чтении можно получить около 1100 IOPS, а на записи независимо от нагрузки массив способен дать около 300 IOPS. Отметим, что с массивом RAID60 из 36-ти дисков на том же контроллере можно получить и более интересные цифры, благодаря конфигурации трех блоков по 12 винчестеров. Это позволяет добавить чередование и поднять скорости до 3500 и 1200 IOPS на случайном чтении и записи соответственно (в этой конфигурации были достаточно старые SAS-винчестеры от HGST по 2 ТБ). Отрицательная сторона такого варианта – дополнительные расходы на объем, поскольку «теряется» не два диска на том, а два на каждую группу.
Итак, без кеширования наш массив смотрится достаточно грустно на случайных операциях. Конечно это «сырая» скорость тома и программы редко дают исключительно случайную нагрузку (напомним, что здесь у нас все-таки массив для хранения файлов большого объема, а не базы данных).

Посмотрим, чем могут помочь в данной ситуации SSD. В тестах будет использоваться четыре доступных варианта конфигурации – только чтение, чтение и запись Write Through, чтение и запись Write Back, чтение и запись Instant Write Back:
- WB — write back enabled. maxCache will store the data on the SSD and write it back to the hard disks when there is little or no impact on performance. This is the default policy.
- INSTWB — instant write back enabled. In addition to the default policy, maxCache will create dirty pages on-the-fly for full-stripe writes if there is room on the SSD and the number of dirty pages is below the threshold.
- WT — write through enabled. Similar to instant write back, but full-stripe writes go to both the cache and hard disk and no dirty pages are created on-the-fly.
Начнем с накопителей SATA, имеющих достаточно большой объем. Графики в этот раз будут раздельные – скорость и задержки для каждого из четырех сценариев теста.
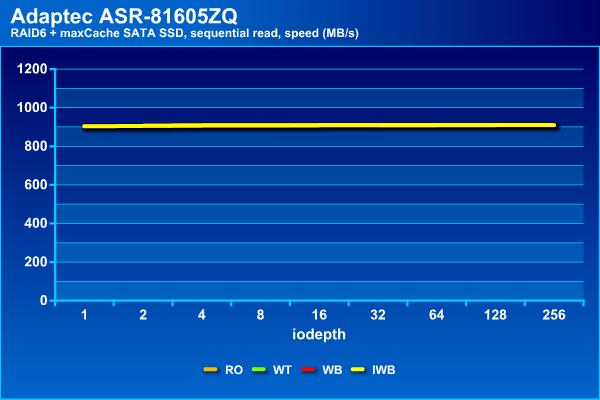
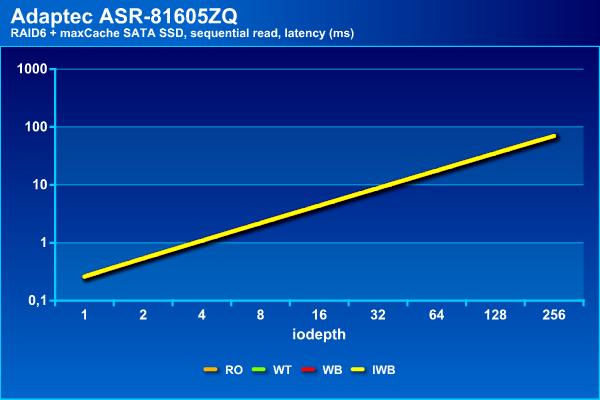
На операциях последовательного чтения массив показывает стабильные результаты независимо от типа используемого кэша, что вполне ожидаемо. При этом они мало отличаются от массива без кэша – все те же 900 МБ/с и задержки около 70 мс.
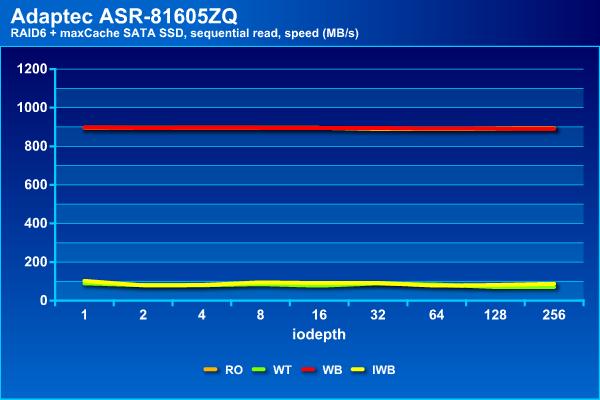
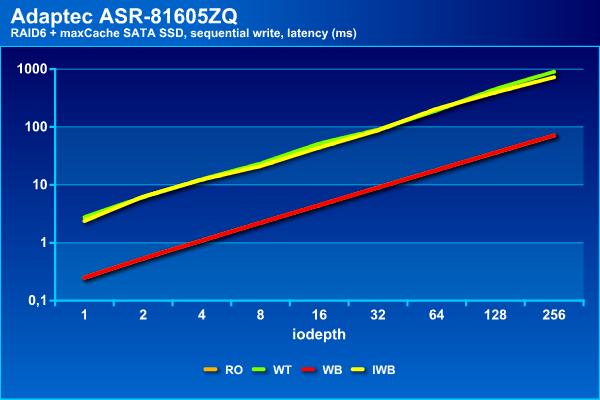
На последовательной записи есть две группы – только на чтение и с Write Back демонстрируют результаты аналогичные массиву без кэша – около 900 МБ/с и до 100 мс, а Write Through и Instant Write Back способны вытянуть не более 100 МБ/с и с существенно большими задержками.
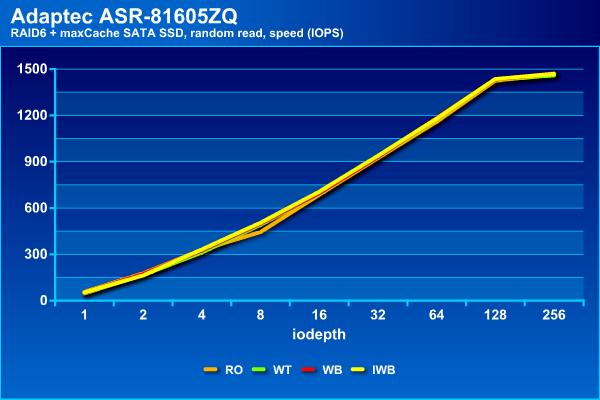
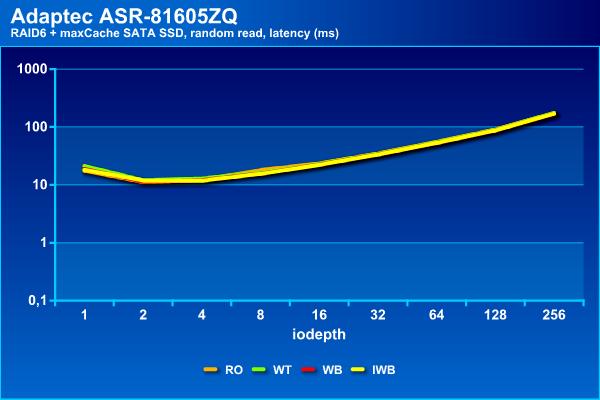
Напомним, что на чтении массив из винчестеров показал максимальное около 1100 IOPS, но на этой границе задержки уже начали превышать 100 мс. С кэшированием SATA SSD можно добиться немного более высоких результатов – около 1500 IOPS и с теми же задержками.
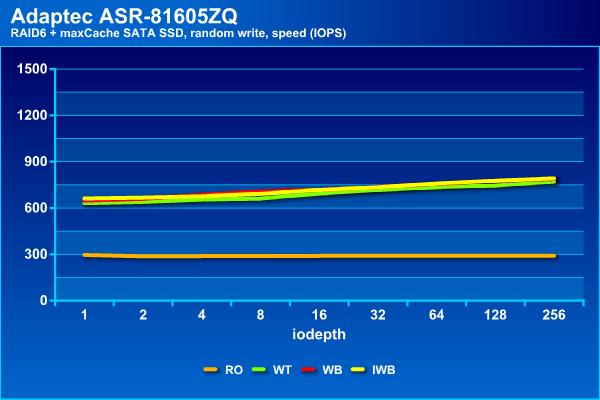
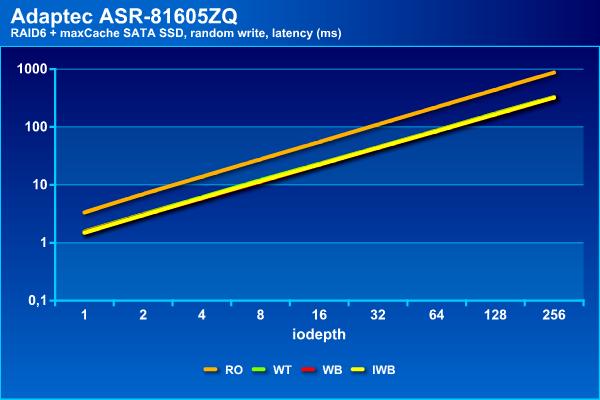
На операциях случайной записи мы видим наибольший эффект – рост показателей в два с половиной раза с одновременным увеличением нагрузочной способности. При использовании кэша можно иметь задержки до 100 мс при в два-три раза большем числе потоков.
Общие заключение по данной конфигурации: на последовательном чтении не мешает, на последовательной записи в некоторых конфигурациях не мешает, на случайном чтении добавляет около 35%, на случайной записи увеличивает производительность в пару раз.
Посмотрим теперь на вариант кэширующего тома второй пары накопителей SSD. Отметим, что в нашем случае у них был существенно меньший объем, интерфейс SAS 12 Гбит/с и более высокие скоростные характеристики (заявленные производителем).
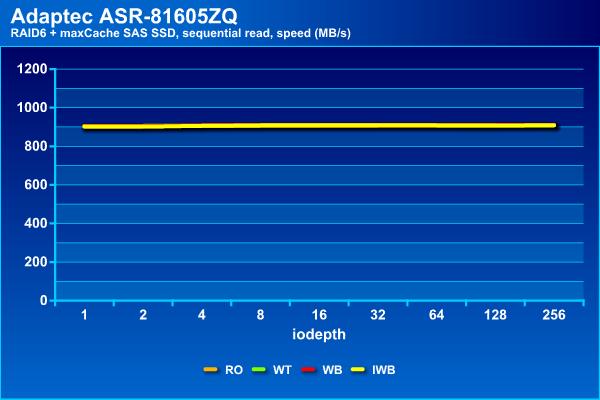
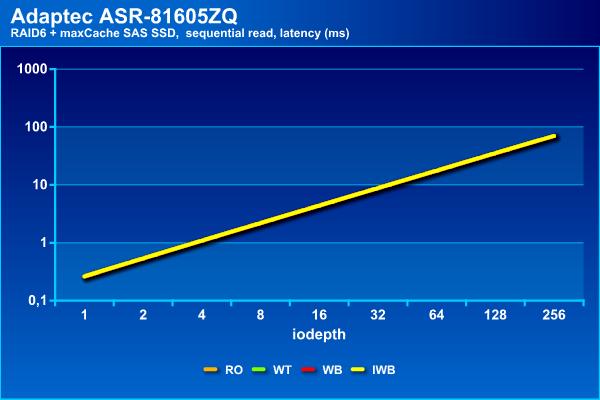
На последовательном чтении результаты не отличаются от приведенных ранее, что вполне ожидаемо.
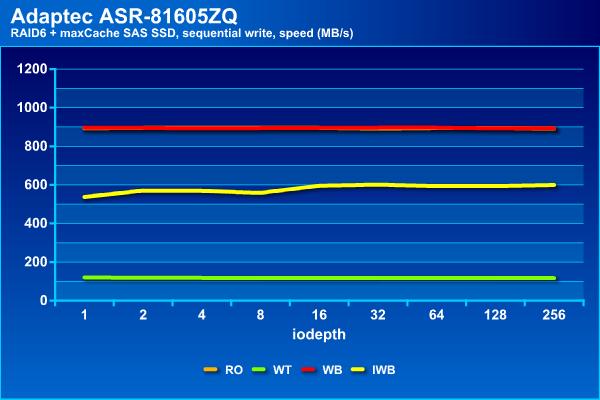
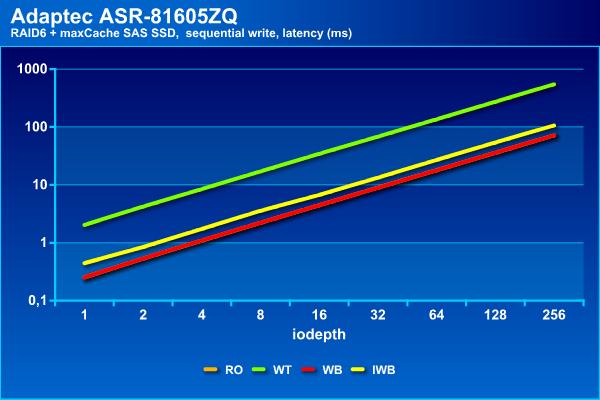
На последовательной записи теперь у нас три группы – отстает конфигурация с кэшем записи Write Through, примерно половину максимальной скорости показывает Instant Write Back и только Write Back не отличается от массива без кэша. Такой же расклад и со временем ожидания.
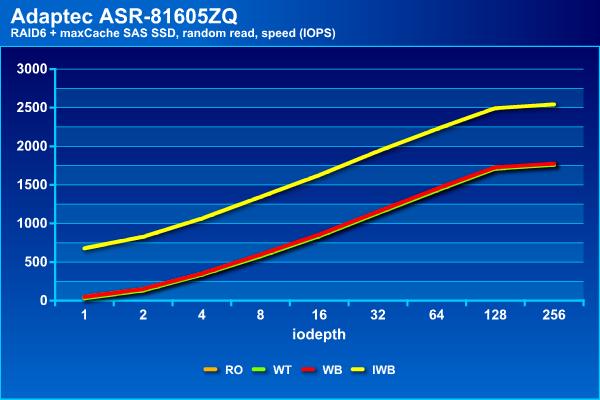
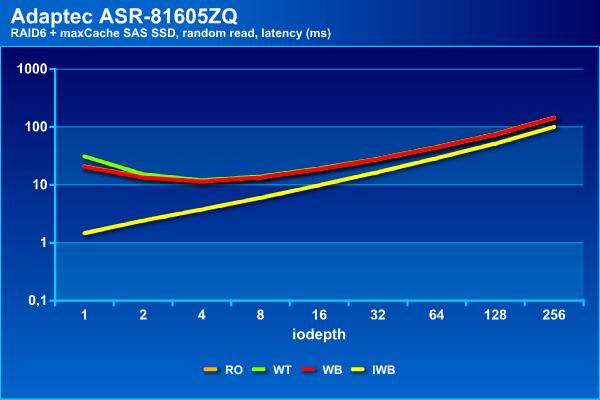
Зато на случайном чтении Instant Write Back показал себя лучше всего, достигая 2500 IOPS, тогда как остальные конфигурации способны вытянуть только до 1800 IOPS. Заметим, что все варианты с кэшированием записи заметно быстрее «чистого» массива. При этом время ожидания не превышает 100 мс даже при большом числе потоков.
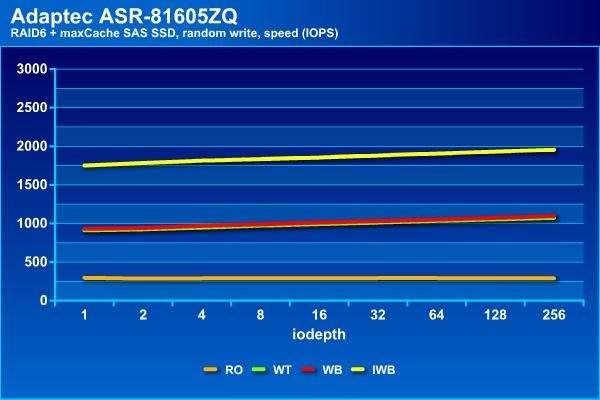
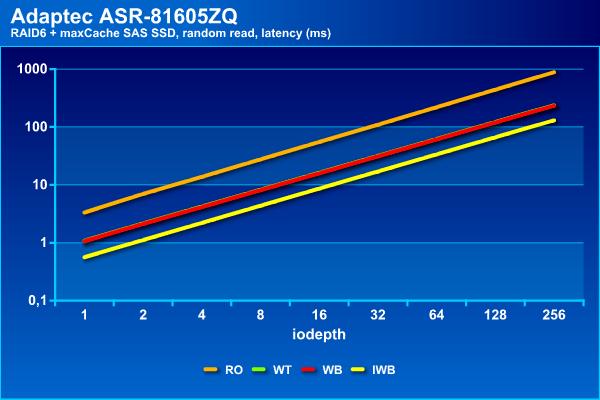
На операциях случайного чтения Instant Write Back снова выходит вперед, показывает почти 2000 IOPS. Во второй группе находятся конфигурации Write Through и Write Back c 1000 IOPS.
Последний участник, не использующий кэш на операциях записи, показывает около 300 IOPS, как и просто массив из винчестеров.
Пожалуй, для этого кэширующего тома интереснее всего смотрится вариант Instant Write Back. Правда он медленнее на операциях потокового чтения. Возможно, это получится исправить использованием конфигурации RAID10 для тома maxCache, но это будет «стоить» уже четырех отсеков в корпусе СХД.
В целом, можно говорить о том, что применение технологии maxCache действительно может быть полезно для повышения производительности массивов из жестких дисков, особенно если в нагрузке много случайных операций. Однако считать, что это настолько же эффективно, как замена жесткого диска на SSD в настольном компьютере или рабочей станции, все-таки нельзя.
Наибольший эффект, который был отмечен в тестах – увеличение скоростей случайных операций в 2-3 раза. Конечно, были использованы не самые быстрые SSD, что явно сказывалось в некоторых тестах (например, последовательной записи в режиме Write Through). Кроме того, хотелось бы еще раз обратить внимание на то, что выбор конфигурации кэширования существенно влияет на результаты. Учитывая, что изменение настроек возможно «на лету» без потери данных, стоит самостоятельно проверить все варианты на своих задачах и выбрать оптимальный вариант.
Комментарии (16)

pansa
02.08.2018 22:19За послдение пару лет на нескольких десятках серверов 90% железных проблем — это геморрой с платами адаптека. Каких только чудес не насмотрелись. Может нам фатально не везло, конечно… но вернёмся к кэшу, ага. Если я не ошибаюсь, то есть еще один нюанс — возможность юзать ssd кэширование является платной опцией. Да, там относительно недорого, что-то в районе 100-200$, однако, учитывая общее качество реализации всего у этой компании, есть большие опасения. В итоге была взята программная линуксовая реализация — bcache ( www.kernel.org/doc/Documentation/bcache.txt ). Да, увы, она требует свежего ядра, поэтому RHEL и CentOs — давай досвиданья. Однако, к bcache доверия больше. Все нужные фичи есть, плюс куча метрик, которые можно смотреть даже без консоли на JAVA и лишней пары гигов RAM (разработчики адаптек мне, конечно, в этом не поверят, но вы — верьте =).
Серьезных нагрузочных тестов погонять, увы, не успелось, но пока 4 хоста по 55Тб в raid60 с bcache'ем на 1тб вполне себе шуршат…
Если у кого есть продолжительный опыт с bcache — будет интересно.Anynickname
03.08.2018 04:03За послдение пару лет на нескольких десятках серверов 90% железных проблем — это геморрой с платами адаптека.
За десяток лет десяток различных моделей контроллеров от 2805 до 81605ZQ, различных серверов — и никаких проблем.
Может нам фатально не везло, конечно…
Есть ещё много вариантов. Например, что вы банально «не умеете их готовить».
возможность юзать ssd кэширование является платной опцией. Да, там относительно недорого, что-то в районе 100-200$
Нет никаких «платных опций». Оно идет в старших линейках контроллеров, в которых помимо этого и памяти больше, и BBU, и пр.
Однако, к bcache доверия больше.
Как вообще можно опцию аппаратного рейда сравнивать с какой-то линуксовой реализацией уровня «побаловаться на домашнем NAS»? И это в эпоху, когда всё виртуализировано, крутится под гипервизорами и знать не знает о физическом железе. Прям mdadm какой-то.pansa
03.08.2018 08:55> Есть ещё много вариантов. Например, что вы банально «не умеете их готовить».
Безусловно, друг мой, такое вполне может быть! Но тогда мы не умеем их готовить вместе с саппортом адаптека, которые самое лучше, что могли советовать — это обновить прошивку (как обычно — без гарантии сохранности данных).
> Нет никаких «платных опций». Оно идет в старших линейках контроллеров, в которых помимо этого и памяти больше, и BBU, и пр.
Сознаюсь — я соврал! Эта фича платная у LSI, который вроде поадекватнее. 274$ стоит — специально нашел в почте.
> Как вообще можно опцию аппаратного рейда сравнивать с какой-то линуксовой реализацией уровня «побаловаться на домашнем NAS»
Ничего сложного в сравнении не вижу. Обоснуете про «поиграться» или тут как с Пастернаком?
> И это в эпоху, когда всё виртуализировано, крутится под гипервизорами и знать не знает о физическом железе. Прям mdadm какой-то.
Вы таки виртуализируете файловые стораджи? Не, ну если мне бы надо было освоить бюджет среднего города РФ, то я бы безусловно обратился в VMWare и виртуализировал бы всё и вся, но некоторым приходится деньги считать.
И вы таки будете смеяться, но в паре мест мы правда переключились на mdadm с АДаптека. Потому что — а ну зачем нужен контроллер, который:
а) спонтанно зависает несколько раз в год
б) может сделать зеркало неработоспособным при вылете одного(!) диска
в) может превратить массив в тыкву при обновлении фирмвари
г) внезапно может сказать, что the target logical device cannot be larger than the maximum possible size 3720Gb, при том, что Current size: 5700 Gb. И что вообще за 3720Gb?
Это я только так слёту вспомнил. Но это, конечно, мы может и сами виноваты. Что выбрали адаптек.
zacat
03.08.2018 12:43Тоже используем mdadm в проде под зеркало для файловой системы.
Согласен с pansa на счет рейд контроллеров: если что случиться не восстановишь данные + переносимоть хромает :)
Правда, нужно упомянуть об одной проблеме: checkarray в первое воскресенье месяца. У нас серверов не так много: настроили в разные дни скриптами + лимиты.
pansa, как вы решали этот нюанс?
bcache используем в одном сервере между схд и гипервизором. Работает стабильно, только bcache во writeback немного сглаживает random io, не кэширует все подряд.
Из минусов — его разработчик теперь пилит bcachefs, а не bcache, поэтому новых уже фич нет.karl77 Автор
03.08.2018 12:47С переносимостью (по крайней мере, у Adaptec не последнего поколения) особых проблем нет. Думаю что с восстановлением тоже (была неприятная история недавно из-за ошибки пользователя, но все хорошо закончилось).
У mdadm тоже встречаются «истории» (недавно в зеркале пропал диск, часть софта делала вид, что он есть и пыталась использовать с жуткими записями в логах, а после пересканирования шины диск поменял букву...).
С другой стороны, ошибки могут быть везде и всегда. Вопрос их «глубины», цены, отношения производителя/разработчика и т.п.
karl77 Автор
03.08.2018 07:49Была только одна проблема с Adaptec, да и то с чужих слов и в сценарии «еж + уж» (6-я серия и 12 Гбит/с бекплейны).
На указанных контроллерах опция кэширование идет в комплекте.
Есть аналогичные тесты bcache и dm_cache. Если интересно, могу сделать материал. enchanceio «не взлетел», flashcache вызывал падение ОС при попытке его протестировать :). btier — это немного другая история.
amarao
02.08.2018 23:45Стандартная поправка по любым бенчмаркам чего-либо, имеющего SSD.
Надо:
1) Учитывать max latency для записи. По моим наблюдениям SSD хуже, чем HDD по этому параметру.
2) обязательно делать бенчмарк поверх файловой системы с включенным fsync'ом (опция fio fsync=1), если делать его поверх блочного устройства, то не сработает.
По наблюдениям у хороших устройств fsync-тест на 20-30% ниже обычного, у плохих — в разы, а иногда и в десятки раз. В частности, samsung'овые EVO совершенно катастрофически себя ведут под такой нагрузкой.
В реальной жизни мы имеем fsync после каждой транзакции в базе данных и после каждой операции системы управления системными пакетами (apt, yum, и даже виндовый апдейт), т.е. производительность в условиях fsync максимально приближена к OLTP/системным апдейтам.karl77 Автор
03.08.2018 07:53Тестирование поверх файловой системы — совсем другая история. Хотя конечно это более полезный с практической точки зрения вариант для подавляющего числа пользователей.
Не говоря уже о выборе самой этой файловой системы, ее настроек и тестов. Например, btrfs с настройками по умолчанию шикарно ведет себя на случайной записи из-за COW, но вот потом последовательное чтение этого файла становится по факту случайным.amarao
03.08.2018 10:25Тут вопрос не в файловой системе и не в особенностях её работы, а в том, чтобы тест отправлял flush в устройство после каждой записи. Многие устройства делают агрессивный writeback, и только flush'ем можно заставить их всё сохранять.
karl77 Автор
03.08.2018 12:41В статье проверяется блочное устройство. Так что fsync не получится использовать. А тестировать fio поверх файловой системы, на мой взгляд, не очень корректно/полезно.
Что касается max latency правильнее иметь большой массив данных после теста и его уже анализировать. Не факт, что тот же fio полезную цифру выдаст.
С винчестерами (см. первые графике в статье) конечно все стабильнее.amarao
03.08.2018 13:02На блочное устройство можно отправлять (если это scsi) команды SYNCHRONIZE CACHE(10) или SYNCHRONIZE CACHE(10), которые заставляют устройство скидывать кеш. Самый простой с практической стороны метод — писать внутрь одного файла на файловой системе с fsync'ами.
Бенчмаркать блочное устройство только на чтение и запись без учёта flush'ей — это всё равно, что dd гонять без oflags=direct. Циферку видишь, а интерпретировать в IRL производительность не можешь.
karl77 Автор
03.08.2018 16:33А почему это касается только тестов с SSD?
Безусловно для некоторых задач важен flush. Но он сам по себе несколько противоречит идее кэширования. Кроме того, мы в данном случае тестируем аппаратный контроллер. И если уж «идти до конца», то там, кроме кэша на SSD, будет еще кэш в оперативной памяти контроллера и кэши на жестких дисках (если не выключили).
Так что все зависит от постановки задач — сколько соломинок требуется подстелить (тех же двойных блоков питания, двух контроллеров, бекплейна с парой экспандеров, трех ИБП, нескольких линий подачи питания и т.п. до уже совсем другой истории).
На мой взгляд, для протестированных конфигураций больше интересна скорость без fsync, чем с ним. Иначе получится что с одной стороны мы хотим кэшировать, а с другой — обеспечить синхронизацию каждой операции записи.
А dd гонять вообще очень странное занятие, если хочется оценить скорость. О чем и на этом сайте немало написано.amarao
03.08.2018 18:05+1SSD это касается потому, что жёсткие диски обычно ничего особо не writeback'чат. Чуть-чуть может быть, но в целом что сказали, то записали.
А flush надо учитывать, потому что редко кто применяет блочное устройство без чего-либо, делающего транзакции (где-то вверху по стеку). Даже если это субд, которая самолично управляет блочным устройством, она всё равно flush'ит.
А для чего вы хоте ли бы использовать блочное устройство без файловой системы?
karl77 Автор
03.08.2018 19:57Так тестировались же не «чистые» SSD, а не самые простые массивы. Проверка варианта с файловой системой — это уже другой тест.
Для примера сравнил опцию в «сложносочиненной» схеме — fio на файле по 10 Гбит/с сети через NFS с сервера с массивом RAID, для которого используется кэш writeback — разницы нет никакой. Правда не забываем, что используется и directio=1.
Так что вопрос в итоге сводится к частоте подачи команды flush. Что, на мой взгляд, определяется требованиями решаемых задач.
quartz64
8-ая серия = MaxCache 3.0
серия 3100 (новая) = MaxCache 4.0. Отличается, прежде всего, возможностью нарезать кэш нужными кусками под определённые кэшируемые тома.
Для приблизительной оценки производительности годится, но в production десктопные накопители под SSD-кэш с Write-Back ставить нельзя. Во-первых, у них отсутствует встроенная защита RAM-кэша, во-вторых — стабильность производительности (QoS задержки) никто не обещает, особенно на запись.
RAID-60 служит не только для преодоления ограничений на размер простой RAID-группы. Основная цель — уменьшить т.н. fault domain, делая на больших nearline дисках составные массивы не более чем из 8–12 дисков в подмассиве. Большие объёмы современных HDD в сочетании с UER на уровне 10^-15 означают долгий ребилд и большую вероятность побить данные во время ребилда.
Опишите подробнее методологию тестирования: параметры fio (randrepeat, ioengine, direct, norandommap, refill_buffers), размер тестируемой области, время тестирования. У Вас есть основной том размером 36 ТБ и кэш размером 1 ТБ или 400 ГБ. Если Вы просто будете запускать тесты с разной глубиной очереди произвольной длительности на весь размер тома, то получите низкий и нестабильный процент попадания в кэш. Но SSD-кэш нужен для тех случаев, когда есть некая нагрузка на случайный доступ, суммарный размер которой более-менее сопоставим с размером кэша. Раз уж у нас всё равно синтетика, то интересно было бы узнать потолок производительности для идеальной нагрузки, которая на 100% умещается в кэш, т.е. задать область тестирования, например, в 50 ГБ и перед тестами добиться заполнения кэша. Могу заранее сказать, что при этом вы упрётесь в производительность SSD минус 10–20%. Поведение в реальных приложениях может сильно отличаться. Помню, как в ранних реализациях SSD-кэша от конкурента Adaptec он поначалу не умел фильтровать последовательный доступ.
karl77 Автор
Спасибо за комментарий, поправил про версию. Новая серия контроллеров использует другой стек и не очень удобна, если нужна переносимость существующих томов с данными. На 6-7-8 проблем с переносом не было ни в одну ни в другую сторону.
Да, конечно данные SATA накопители чисто десктопные. Но не всегда есть возможность заплатить в два-три раза больше. Так что для сравнения вполне подойдут. Более существенно то, что в такой конфигурации нет TRIM и они уже сильно «использованные». В итоге чистая последовательная запись (на момент проведения тестирования) — около 90 МБ/с на том же оборудовании, что уже медленнее винчестеров (чтение — около 300 МБ/с).
И про RAID60 конечно так и есть. Но в данной статье речь преимущественно о скорости работы.
Тест запускался так:
fio --rw=test --bs=blocksize --ioengine=libaio --iodepth=iodepth --direct=1 --group_reporting --name=test --numjobs=1 --runtime=runtime --filename=device
С синтетикой проверять кэширование непросто, о чем и было сказано в статье. Зато она может показать «самый сложный» сценарий. Лучше бы конечно реальные приложения, но их не всегда удобно масштабировать, повторять и т.п.