Начнем с того, что все имеющиеся на рынке накопители, можно четко разделить на классы:
— диски для обычных desktop-ов (применяются в домашних ПК, в ноутбуках и в desktop-серверах low-cost дата-центров);
— серверные диски со скоростью 7200 оборотов в минуту (RPM);
— Enterprise-диски со скорость 10 000 и 15 000 RPM;
— твердотельные накопители.
Особенности выбора твердотельных накопителей мы, пожалуй, рассмотрим в отдельной статье, а сейчас остановимся преимущественно на жестких дисках и рассмотрим какой диск где и когда целесообразно применять.
Начнем с обычных дисков для PC. Это отличные диски с довольно большой емкостью и хорошей производительностью, но их главный недостаток в том, что они не рассчитаны на работу в RAID-массиве в силу своих конструктивных особенностей. В этих дисках вибрации, вызываемые вращением шпинделя, практически никак не компенсируются. Конечно эти вибрации минимальны и в случае применения 1-2 дисков в домашних условиях они не являются проблемой. Однако, если рассматривать серверный случай, когда дисков много, влияние вибраций может быть довольно существенным, так как возникают взаимные вибрации, резонанс усиливает эффект. Так, когда в корпусе установлено сразу 12 дисков, да еще и работают довольно мощные серверные вентиляторы по 5000-9000 оборотов в минуту — уровень вибрации нарастает довольно значительно, а с ними и % ошибок, потерь, что и оказывает негативное влияние на производительность. Производительность дисков десктопного типа падает в этих случаях в разы, так как они испытывают значительные трудности с позиционированием головок, теряют дорожку. Это хорошо можно видеть из популярного графика зависимости производительности от вибрационной нагрузки:
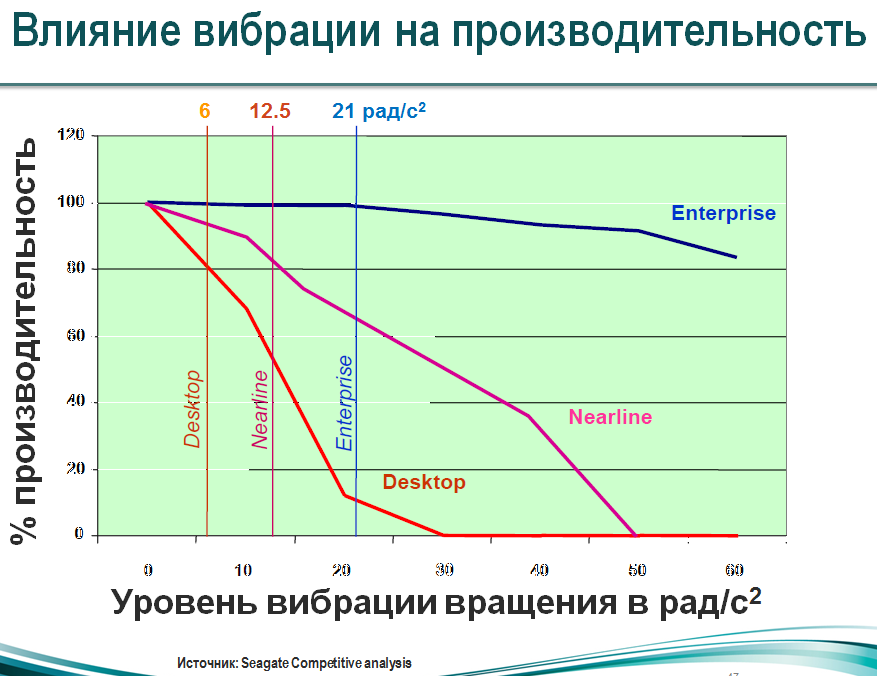
Другое дело диски SATA RE (RAID Edition) или же серверные диски со скоростью 7200 RPM. Они менее подвержены вибрациям и в меньшей степени зависят от них. Как видим из графика — вероятность возникновения ошибки в результате вибраций на 50% ниже для них.
Но не только вибрации являются проблемой, другая основная проблема всех дисков — уровень невозобновимых ошибок. Что это означает на практике?
Для SATA PC дисков уровень невозобновимых ошибок 1 ошибка на 1014 бит, или 1 ошибка на 12,5 ТБ данных. Диск на 1ТБ имеет 1000/12500х1014 бит. 5 дисков имеют емкость 5х(1000/12500х1014) бит, а вероятность возникновения ошибки при работе этих дисков в массиве RAID5 будет составлять (5х(1000/12500х1014))/1014x100% = 40%.
Как видим, использовать 5 PC-дисков в RAID5 просто нельзя, так как вероятность возникновения невосстановимой ошибки при ребилде очень высока и ребилд завершится скорее неудачно. Таким образом мы получим массив, который заведомо выйдет из строя в случае ребилда и данные будут утеряны. Ранее я не знал об этой особенности и в 2008-м году, когда собирал свой первый сервер еще на PC-шных накопителях, построил именно RAID5-массив, с целью экономии дискового пространства и денег, и менее, чем через месяц, данные были потеряны. Сейчас мне удивительно, что массив прожил так долго :)
Конечно, можно применять более надежные уровни RAID, такие, как RAID10 или в крайнем случае RAID6, но при большом количестве дисков мы также будем получать довольно высокую степень вероятности возникновения невосстановимой ошибки во время ребилда.
Другое дело серверные диски со скоростью 7200 оборотов в минуту (RPM) SATA RE или диски Near Line (NL) SAS. Вероятность невосстановимой ошибки для них на порядок меньше уже за счет их технических особенностей, 1 ошибка возникает на 1015 бит данных. Тем не менее, при использовании не только большого количества накопителей, но и накопителей большого объема — этого может быть уже недостаточным и в таких случаях все же придется применять SAS-накопители Enterprise класса, степень надежности которых 1 невосстановимая ошибка на 1016 бит данных.
Стоит также отметить, что на самом деле для дисков SATA RE, Near Line (NL) SAS и дисков SAS Enterprise-класса, по сути дисков, которые умеют эффективно взаимодействовать с RAID-контроллером, вероятность возникновения невосстановимой ошибки еще значительно меньше, как раз за счет этой способности. Так, при работе с нагруженным массивом (базы данных, с которыми работают сразу много пользователей, активная запись и считывание данных) начинают играть роль уже восстановимые ошибки, с которыми обычные диски работают неэффективно. Они пытаются перечитать проблему многократно — в тех же Western Digital значение установлено на 64 прохода головки с разными параметрами высоты, угла, только после чего головка переходит к обработке других задач. За счет этого сильно возрастает время ожидания, которое RAID не терпит и непременно сочтет диск потерянным и попытается восстанавливать диск, в результате чего нагрузка на массив приобретет критичный характер, так как одновременно с рабочей нагрузкой будет идти еще и ребилд. Результат предсказуем — крах всего массива.
Диски, которые умеют работать с RAID, могут сообщить RAID-контроллеру, что есть проблема с чтением блока данных, запросить этот блок с других дисков и в это время обрабатывать другие запросы, а получив блок — перезаписать его в другом месте проблемного диска. За счет этого никакого падения производительности RAID-массива не происходит и вероятность потери данных снижается значительно. Однако следует отметить, что не все софтовые рейд-контроллеры, установленные на чипсетах, умеют «понимать» такие диски, потому порой недостаточно иметь диски RE для надежного массива, а все же требуется применение аппаратного контроллера или другой платформы, которая корректно работает с RAID.
Тем не мене, если есть желание собрать более надежное хранилище, нежели хранилище на PC-накопителях, можно купить более дешевые диски, нежели диски RE, к примеру Constellation CS, которые предназначены для работы исключительно с софтовыми рейдами и лишены недостатка десктопных (попыток многократного перечитывания данных в ущерб другим задачам), при этом полноценно, само собой, с контроллерами они не взаимодействуют, так что cбои RAID полностью не исключены.
Вне зависимости от того, какой накопитель Вы применяете, Вы также должны помнить о том, что у дисков есть кеш — 32, 64 МБ и более. Что это значит для RAID-массива? С точки зрения производительности кеш является плюсом, как для чтения, так и для записи. Однако с точки зрения надежности записи — это минус. Используя кеш, рейд-контроллер будет думать, что уже записал данные на массив, но на самом деле они могут быть только в кеше, а на диск записаны быть позднее. В зависимости от размера массива растет и размер общего кеша, и в случае 12 накопителей кеш составляет уже почти гигабайт. Что произойдет с данными при отключении питания? Правильно. Они будут утеряны. И если речь идет о файлопомойке, тут, наверное, не на столько критично, но если же речь идет о базах данных — будет весело. Потому рекомендуется для данных особой критичности, такие, как базы данных, все же отключать кеш на запись. Это снизит производительность диска на 8-15% в режиме баз данных, однако в значительной степени увеличит надежность. По этой причине, если Вы приобретаете хранилище данных большой емкости, крупные производители отключают там кеш по умолчанию и включить его невозможно. Применяя же диски в серверах, особенно в low-сost дата-центре, где питание к серверу не резервировано, нужно помнить об этом риске и учитывать его.
Также отметим еще одну ключевую особенность дисков SAS Enterprise-класса, на них данные хранятся еще более надежно, так как минимальный размер кластера составляет 520 байт, а не 512, добавляется еще 8 байт для проверки четности. Применяется большое количество алгоритмов восстановления данных без участия контроллера. Именно по этой причине объем этих дисков не бывает очень большой.
К слову на счет объема, крайняя рекомендация, если у Вас есть задача хранить данные надежно, не пытайтесь использовать диски большего объема, нежели это необходимо, так как в случае ребилда восстановление будет занимать больше времени. Как правило контроллеры не анализируют то, сколько реально занято на диске и восстанавливают весь диск в целом, потому разница во времени восстановления между 1 ТБ и 6 ТБ накопителем будет более, чем в 6 раз.
Подведем итоги. Исходя из вышеизложенного понятно, что для небольшого RAID-массива, применение самых дорогостоящих дисков Enterprise класса не принципиально и не дает никаких преимуществ в надежности. Тем не менее, применение серверных дисков весьма желательно, так как в этом варианте на порядок большая вероятность того, что ребилд завершится успешно. Не следует применять диски большего объема, чем это необходимо, за исключением случаев, когда нужно обеспечить более высокую производительность по IOPS (в некоторых дисках большего объема все же может быть выигрыш по скорости за счет большего количества головок и пластин). В случаях, когда необходим большой объем и много дисков и при этом достаточный уровень надежности — можно смотреть в сторону SAS NL, которые по сути являются модифицированным вариантом накопителей SATA RE за счет интерфейса SAS, однако имеют все те же 7200 RPM. Для повышения уровня надежности целесообразно применять RAID более высокого уровня. Когда же объем массива не принципиален и требуется максимальная надежность, нужно однозначно применять SAS 15000 RPM Enterprise.
Теперь, выбирая в аренду сервер в Нидерландах, у нас на площадке Switch, при помощи конфигуратора, расположенного в нижней части страницы http://www.ua-hosting.company/servers, либо, модифицируя одно из спец. предложений:



Приходит понимание того, какие диски и какой из серверов лучше использовать и для каких задач, когда лучше использовать диски в RAID, а когда по отдельности, распределяя файлы софтом в зависимости от популярности (скрипт балансера в зависимости от нагрузки). Почему 4 диска большего объема, в плане надежности, может быть лучше, чем 12 меньшего, но хуже в плане времени восстановления в случае ребилда. Ну и самое важное — почему наше предложение реально крутое для серверного сегмента и мы реально приблизили цену к desktop-площадкам, при этом сохранив на порядок более высокую надежность без преувеличений! Так что если Вам, либо Вашим знакомым нужен хороший сервер — welcome, распродажа некоторых конфигураций из списка ниже ограничена, очень скоро цены на эти конфигурации будут выше, мы хоть и щедры, но не безгранично :):




Да, если у кого-то есть реальный опыт применения тех или других накопителей для определенных задач — не стесняйтесь делиться им в комментариях. Интересно все, вплоть до статистики отказов. На эту тему, как и по поводу проблематики выбора SSD-накопителя, мы постараемся опубликовать материал позднее.
Комментарии (31)

Pilat
09.07.2016 22:57+4Начнем с того, что все имеющиеся на рынке накопители, можно четко разделить на классы:
— SATA
— SAS
— SSD
Скорость вращения — параметр вторичный.
Далее, те же «все диски» делятся по типу использования
— для линейного доступа
— для конкурентного доступа
Опять же, скорость вращения — параметр вторичный.
Так вот, я не увидел в Вашем обзоре разделение дисков на типы с точки зрения работы в конкурентной среде, например виртуализация, параллельное выполнение долгих операций, параллельный доступ нескольких процессов, запись больших и маленьких блоков. А вот тут разные диски проявляют себя очень по разному.HostingManager
09.07.2016 23:58-1Начнем с того, что SATA/SAS — это всего лишь интерфейсы, а не диски. А диски различаются не только по скорости вращения, как Вы верно отметили, или отсутствию вращающихся частей (твердотельные накопители), но по многочисленным другим характеристикам, которые важны для одних задач и менее важны для других.
Разделение дисков на типы с точки зрения работы в конкурентной среде — зависит от задачи, и подобный обзор вместить в одну статью крайне сложно, потому и запрошено было обсуждение этих проблем в комментариях.
Pilat
10.07.2016 00:30+1Крайне просто. SATA — диски для десктопа, SAS — для сервера. В целом это именно так. А в статье об этом ни слова. Первый вопрос, который у клиентов хостера возникает, Вы вообще не рассмотрели.
electronus
10.07.2016 00:37Я бы не был так категоричен
Pilat
10.07.2016 01:45А это не категорично, но в целом (как правило) это именно так. SAS или SATA — неочевидный выбор для начинающих пользоваться серверными хостингами, возникающий в каждом втором обсуждении, и должен ИМХО рассматриваться в первую очередь.
vorphalack
10.07.2016 08:38+1после появления Nearline SAS — выбор уже не так очевиден. натуральный гибрид ежа и ужа получился. банка SATA, контроллер и интерфейс — SAS
HostingManager
10.07.2016 10:45Крайне просто. SATA — диски для десктопа, SAS — для сервера. В целом это именно так. А в статье об этом ни слова. Первый вопрос, который у клиентов хостера возникает, Вы вообще не рассмотрел.
Pilat, нет же, такое впечатление, что Вы любите комментировать, но не любите читать. Еще раз прочитайте публикацию внимательно. Desktop-диски — это те диски, которые не умеют взаимодействовать эффективно с RAID и для производительности которых очень критичны вибрации.
SATA RE, SATA ENTERPRISE — хорошие СЕРВЕРНЫЕ ДИСКИ, и они идут с интерфейсом SATA. Если диск имеет интерфейс SATA — это во все не означает, что он десктопный.
Также, как в прочем и твердотельные накопители, SSD могут быть, как с интерфейсом SATA, так и SAS, так и вообще PCI Express.

LynXzp
10.07.2016 20:28"… вероятность возникновения ошибки при работе этих [5-ти] дисков в массиве RAID5 будет составлять (5х(1000/12500х1014))/1014x100% = 40%. Как видим, использовать 5 PC-дисков в RAID5 просто нельзя..." Как я понял 40% это вероятность возникновения ошибки при восстановлении RAID5 из ШЕСТИ дисков (один то вылетел, его считать не нужно).
HostingManager
11.07.2016 10:34Ребилд проводится на всех дисках, когда диск заменили или просто было продолжено использование сбойного диска после того, как он вышел из попытки считывания проблемного кластера. Именно потому все же считаем все диски и случай был рассмотрен с 5 дисками.
SyavaSyava
10.07.2016 21:11+1Скандалы, интриги, расследования!
Мы все – т.е. тьфу, диски – умрём после прочтения числа зверя 10^14 бит!
А если серьёзно – то эти байки и городские мифы про BER, RAID5 и крутые корпоративные диски, невозмутимо беседующие с контроллером за чашкой чая среди волнующих вибраций уже порядком поднадоели.
Ну да ладно, эмоции в сторону, поехали.
Начнём с пресловутого «количество неисправимых ошибок чтения на число прочитанных бит». Кстати, у автора они почему-то «невозобновимые», но спишем это на опечатку. Для краткости будем далее именовать этот параметр как BER (bit error ratio).
Первая ошибка автора – BER им взято как 10^14. Тогда как у производителей дисков указано как «менее 1 на 10^14». Не «ровно», а «менее». Может быть 0,5 на 10^14. Может быть 0,0005 на 10^14. Т.е. в среднем – не более, а сколько – фиг его знает.
Можно предположить, что автор взял максимальное значение для страховки, как предельный случай. Хорошо. Но зачем тогда вычислять вероятность наступления ошибки, тем более приводить такие ужасные цифры, как 40%? Какова вероятность вероятности 40%, если значение BER неизвестно?
Т.е. по итогам этого всего материала можно заключить только, что в массиве RAID уровня 5 при ребилде есть некоторая вероятность отказа ещё одного из оставшихся дисков, что сделает невозможным этот самый ребилд и приведёт к отказу всего массива.
Пффф, как сейчас модно говорить. А то мы не знали. Ещё на серверную в момент ребилда метеорит может упасть. Вероятность этого даже ещё больше – целых 50%. Либо упадёт, либо нет.
Но если серьёзно – то конечно BER имеет некоторый шанс вызвать проблемы.
Но важно понимать, что это далеко не единственная причина потенциальных проблем, и если значимость фактора BER сопоставима с другими влияющими факторами – то в принципе можно расслабиться и сидеть на стуле ровно: всё сводится к приемлемой степени риска. Для кого-то и 10% нормально, а кому-то и 1% неприемлем.
Итак, мы выяснили, что приводимая автором цифра в 40% фактически высосана из пальца. Попробуем определить более реалистичное значение.
Увы – реальных данных в природе на этот счёт встречается очень мало, что кстати косвенно может говорить о том, что проблема в целом надумана.
После беглого поиска нашёл довольно старое (2005 год) практическое исследование на сайте Майкрософта:
https://www.microsoft.com/en-us/research/publication/empirical-measurements-of-disk-failure-rates-and-error-rates/
В выводах по результатам этого исследования авторы солидарны со мной – «SATA uncorrectable read errors are not yet a dominant system-fault source».
Но помимо всего прочего, там есть конкретные цифры по ошибкам этого типа: при ожидаемом уровне в 112 ошибок, соответствующих значению BER в 10^14, реально получено 4 ошибки. Т.е. в 28 раз меньше ожидаемого.
Таким образом, ужасные 40% автора в реальности ближе к 1,5%, что на мой взгляд, вполне сопоставимо с вероятностью отказа по другим причинам. И это для RAID-массива уровня 5, применяемого относительно редко и в специфических случаях. Про RAID6, специальные технологии контроля поверхности диска от производителей контроллеров и т.п. – даже и говорить не стоит.
Так же нужно учесть, что это был 2005 год – технологии не стоят на месте, и на мой взгляд надёжность хранения данных на современных дисках выше, чем ранее – т.е. этот процент сейчас скорее всего ещё сильно меньше.
Немного личного опыта, в противовес неудачному опыту автора:
Дома для всяких кинов и торрентов имеется сервер с массивом из 4-х 2 ТБ дисков как раз в RAID5. Диски кстати самые презираемые WD Green, по общему мнению – точно не подходящие для RAID, тем более пятого уровня. Контроллер – LSI 9260, потом 9271.
За примерно 4 года практически круглосуточной работы (торренты качаются/раздаются постоянно) было:
— Один раз в самом начале работы один из дисков «выбило» из массива. Т.к. на тот момент в горячем резерве ничего небыло, то после углубленной диагностики диск был признан исправным и возвращён в массив. Было сделано предположение, что виновата автопарковка головок для экономии энергии, которая и была отключена на всех дисках. Т.к. после этого подобных инцидентов небыло, то скорее всего предположение оказалось верным.
— Умерло 2 диска (не сразу). В обоих случаях в наличии уже были диски в горячем резерве, и массив благополучно перестроился на них. Оба диска при диагностике были мёртвыми совершенно – в системе определялись, т.е. никакой постепенной смерти, предупреждений SMART и т.п.HostingManager
11.07.2016 10:32Действительно, брался худший сценарий и на практике вероятности могут быть меньше. Тут была больше цель показать, зачем при использовании больших массивов использовать диски RE, а не десктопные, почему не стоит использовать RAID массивы низкого уровня, такие, как RAID5 (безопасность). Само собой, что при выходе из строя одного из дисков в RAID5-массиве, может добавится вероятность краха всего массива по причине того, что RAID станет работать в критичном режиме, если во время не отследить вылетевший диск.
Pilat
10.07.2016 21:53Все эти рассуждения про надёжность не имеют практического значения. Параметры дисков (надёжность) указаны для абстрактных дисков, при этом не учитываются другие факторы — происхождение, бракованная партия, условия хранения… Это учитывается производителями типа HP, но не noname сборщиками. Естественно, обычные SAS диски 15К летят с огромной и неизвестной точно вероятностью. Статистика отказов тоже не имеет практического значения, так как отказ в течении трёх лет говорит ни о чём — к тому времени выпускаются совсем другие диски.
Теперь насчёт приведённых предложений. Что Вам пришло в голову запускать на сервере с 4x4ТБ SATA и 32Gb памяти и линией с трафиком 100Тб?HostingManager
11.07.2016 10:29Вы не совсем правильно понимаете указанную вероятность отказа производителем. Вероятность отказа в течении скажем миллиона часов, если речь идет о MTBF, не означает, что 1 диск «проживет» 114 лет, это означает, что из партии в 114 дисков в течении года может выйти из строя один диск (худший сценарий).
Кроме прочего, тут не рассматривалась вероятность отказа диска поностью, тут рассматривалась вероятность невосстановимой ошибки.
Что Вам пришло в голову запускать на сервере с 4x4ТБ SATA и 32Gb памяти и линией с трафиком 100Тб?
Это хорошее предложение для файлового-архива и бекап-решения. С хорошим быстрым каналом. В прочем, параметры этого сервера подлежат корректировке, и если есть желание — можно поставить вместо какого-то из дисков SSD (сделав запрос в отдел продаж) или же увеличить объем трафика, если включенного трафика будет недостаточно.
merlin-vrn
11.07.2016 16:46Вероятность отказа в течении скажем миллиона часов, если речь идет о MTBF, не означает, что 1 диск «проживет» 114 лет, это означает, что из партии в 114 дисков в течении года может выйти из строя один диск (худший сценарий).
Это было бы корректно, если бы для дисков была бы справедлива эргодическая гипотеза (среднее по времени эквивалентно среднему по ансамблю). Но эта гипотеза очевидно не верна для любых объектов, которые способны «стареть», т. е. изнашиваться, каковыми являются жёсткие диски.
Из парти в 114 дисков один умрёт в течение первого года эксплуатации? А насколько интенсивной предполагается эта эксплуатация? А если я про второй год, 1 из 114 выживших или от первоначального количества, или уже не один? А на десятый год?
В общем, MTBF — это конечно хорошо, но это не про диски. Диски не умирают в соответствии с теорией вероятностей или термодинамикой. Они умирают от скрытых дефектов, например, плохая балансировка ведёт к вибрации, которая усиливает износ, из-за чего ещё сильнее повышается вибрация, и так далее.HostingManager
11.07.2016 19:48C течением времени вероятность нарастает. Само собой, что интенсивность эксплуатации играет не последнюю роль. Те же десктопные диски производитель считает возможным использовать лишь 8*5 = 40 часов в неделю и значение MTBF указано из этого расчета. После 2-х лет работы (для жестких дисков, которые более подвержены износу ввиду движущихся частей), вероятность выхода из строя нарастает экспоненциально.
merlin-vrn
12.07.2016 21:06Как-то ваши сроки совершенно не согласуются со статистикой backblaze. А они там прямо по модели диска таблицу выстроили. И для seagate barracuda 7200.11 среднее время жизни (при круглосуточной нагрузке) 4.3 года. И другие диски тоже долго жили. Как вы это объясните? У вас другая статистика? Ну так покажите же. В идеале — статистика в виде «столько-то дисков вылетело на N-том месяце жизни», чтобы видеть распределение наглядно и можно было хоть что-то объяснять, а то пока от вас есть какие-то общие слова и умозрительные выводы, взятые с потолка.
И немного про математику. Вероятность нарастает экспоненциально — это очень интересно, при условии, что вероятность не может быть больше единицы. Вы уж определитесь, какое из слов в предложении лишнее.HostingManager
12.07.2016 23:30https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D1%81%D0%BF%D0%BE%D0%BD%D0%B5%D0%BD%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5
Вы извините, я не математик, а физик, и в физике у нас возможны и экспоненциальный рост к единице и сказанная мной фраза не является ошибочной.
На счет той статистики, которую Вы приводите, это при какой нагрузке? Эта статистика при домашнем пользовании. Причем после 4-х лет — вероятность отказа очень сильно стремится к единице по причине именно механического износа.
Есть реальные данные, пользователь привел ниже, из 120 дисков в течении 2,5 лет сбойный диск раз в месяц. Но опять же, эти все значения зависят от нагрузки.
У нас очень много выделенных серверов, но не все пользователи меняют диски (запрашивают у нас замену), когда они вышли из строя. Так как не все умеют сопровождать свои серверы или следят за ними должным образом, а сопровождение у нас заказывает лишь небольшой % клиентов. Потому, к сожалению, наши данные так же были бы малообъективны.
Однако, тут, они примерно дают представление, какой диск и в каких случаях лучше использовать. В этом смысл был этой статьи, объяснить целесообразность применения дисков. Мы не утверждаем, что статистика, приведенная в статье только такая и другой быть не может. Очень много разных параметров нужно учесть. Но понять, какой диск выбрать для того или иного сценария — возможно.
turone
11.07.2016 08:54Я что-то не совсем понял фразу,
сильно возрастает время ожидания, которое RAID не терпит и непременно сочтет диск потерянным и попытается!!! восстанавливать диск… — крах всего массива.
Почему контроллер настроен сам восстанавливать диск? В основном обслуживающий персонал принимает решение, о замене и ребилде массива. И почему во время ребилда должен наступить крах? — просто выдаст ошибку: мол не могу сделать ребилд — поменяйте диск.HostingManager
11.07.2016 10:37Потому, что во время ребилда есть вероятность возникновения невосстановимой ошибки на каком-либо другом диске. Что же касается самого ребилда, если диск «выпал» из массива на время, так как слишком долго пытался считать проблемный кластер, то после завершения попытки — он сам же и вернется в массив, при этом будет автоматически запущен ребилд.
merlin-vrn
11.07.2016 09:12+3Хватит гнать пургу. На хабре уже была пара статей с независимой статистикой дисков. Они там вообще покупают самые дешёвые диски (т.е. домашние SATA) и отлично с ними живут. «Домашние» SATA на 2 Тб вполне способны под серверной нагрузкой нормально трудиться по три года (если не выйдут из строя за первых три месяца по причине брака) — средний возраст Seagate Barracuda 7200.11 (ST31500341AS) у них вообще 4.3 года.
А тот факт, что честных официальных данных такого рода, не похожих на рекламу нет, намекает, что производители отлично понимают: дешёвые диски работают прекрасно. Они потому и гонят весь этот маркетинговый буллшит, что по-другому просто не могуть продать невменяемо дорогие «серверные» диски. При честном рассчёте стоимость их производительности (iops/руб) и объёма (гб/руб) оказывается больше. То, что на быстрых дисках получаются массивы производительнее, объясняется тем фактом, что эти диски сами по себе меньше по объёму, а значит для получения массива того же объёма мы берём больше шпинделей и значит автоматически получаем больше iops.
Все эти модели MTBF и BER — фикция: предполагается, что вероятность выхода диска из строя не зависит от того, сколько он проработал — а это совершенно не так, вероятности появления ошибок однозначно нарастают по мере эксплуатации. И пока я не видел ни у одного производителя реалистичной модели, которая это учитывает. Единственный показатель на эту тему, из которого можно делать какие-то выводы — это срок гарантии; я ему доверяю, потому, что производители в гарантийном случае сами платят рублём, и чтобы платить меньше хотя бы как-то анализируют ситуацию и срок дают правдоподобный.
Умирание RAID5 больше связано с тем, что диски ставят из одной партии, работают они в массиве одинаковое время и под одинаковой нагрузкой, и соответственно умирают обычно тоже вместе. Если в таком массиве вылетел диск — жди, что все посыпятся. Наблюдал неоднократно, что в течение месяца все диски массива — из одной партии — один за другим были заменены.
Simol
11.07.2016 10:20Странный способ получить 40% имея только данные о количестве, без времени.
1 ошибка на 12,5 ТБ, то есть на 1 ТБ винте 1/12,5 ошибок.
Если 1 ошибка это неправильны 1 бит, то вероятность ошибки 1/8Е12
У 5 винтов 5/8Е12. тут 40% и близко даже нет
HostingManager
11.07.2016 10:47-1Вероятность невосстановимой ошибки не зависит от времени. Она может быть в любой момент, потому в грубом приближении этот способ для конкретной вероятности ошибки верный.
kvant21
11.07.2016 10:21+2Ужас какой.
Во-первых, RAID5 на действительно больших массивах перестраивается так долго и так тормозит, что использовать его просто нет смысла. Так что появления URE вы с высокой вероятностью просто не дождетесь, плюнете и пересоберете массив начисто :)
Во-вторых, любой приличный RAID-контроллер умеет отключать кэш на дисках, иначе к чему все эти навороты с батарейками?
В-третьих, SAS 15K никому не нужны, потому что есть SSD за те же деньги в 2.5" форм-факторе и гораздо быстрее. Линейки 15К дисков давным-давно не обновляются.
В-четвертых, хотя идея про неправильное поведение десктопных дисков при ошибках верная, в объяснении у вас каша. Если контроллер «теряет» диск при длительном времени ответа, с чего бы ему начинать ребилд после этого? Ничего он не начнет пока вы диск не поменяете.
А на самом-то деле проблема как раз в том, что контроллер НЕ потеряет диск с длительным временем доступа, и весь массив будет ждать чтения сбойного сектора.HostingManager
11.07.2016 10:43Батарейки — для того, чтоб рейд-контроллер завершил операции и подсчет четностей (контрольных сумм), они не помогут спасти кеш дисков. То, что контроллер умеет отключать кеш — однозначно, об этом и писалось в статье, что его следует отключать.
По поводу того, с чего контроллер решил восстанавливать, если диск «подвис» в результате того, что долго не мог считать проблемный сектор и НА ВРЕМЯ из-за этого был исключен из массива, то после того, как попытки чтения будут завершены и сектор будет все же считан, либо отмечен, как проблемный — диск вернется в массив и будет начата процедура ребилда.
Проблема как раз в том, что контроллер потеряет диск с очень длительным временем доступа, так как массив не может ждать, пока диск ответит, слишком долго.
sergeysakirkin
11.07.2016 10:21Парк 20 физических серверов. в среднем возраст 2,5 года, 120 дисков. замена сбойного диска обычно 1 раз в месяц. Без разговоров и нудных бессмысленных тестов. Диски все EE/RE.
HostingManager
11.07.2016 10:39Вот, реальные данные, как видим, картина может быть даже хуже расчетной.
К слову сказать, у нас парк более 1000 серверов, но мы не видим картины полноценно, так как не все пользователи отслеживают проблемы с дисками, у кого-то диск может быть уже не в рейд-массиве, а люди просто об этом не догадываются.
Sergey_datex
Что за ерунда? Диск не может ничего запросить у другого диска.
redmanmale
Мне кажется, имелось в виду, что в случае возникновения проблемы с чтением, диск сообщит об этом контроллеру, а уже он, в свою очередь, запросит
electronus
Рейд контроллер при получении сообщения о проблеме чтения с диска восстановит несчитанный блок по данным с других дисков массива и отдаст данные ОС. А потом уже будет разбираться что делать дальше.
HostingManager
Совершенно верно.
lovecraft
Тут имелось ввиду, что десктопный винчестер будет тупить, пока не прочитает сектор. Если он будет тупить больше какого-то количества секунд (как правило 8-и), то контроллер выкинет его из массива и начнет ребилд. Если диск поддерживает TLER, то он протупит несколько секунд (можно настроить), а потом честно скажет, что прочитать ничего не может. Контроллер восстановит данные с другого диска или по чексуммам, а диск останется в массиве и ребилда не будет. Управляется эта штука через SCT Error Recovery Control (совершенно не понимаю, почему статью переместили на Geektimes)