
В первой статье попробуем познакомить читателей с базовыми понятиями. Статья рассчитана скорее на новичков, которые в базе понимают сетевые технологии, но никогда не сталкивались с промышленными решениями по защите от DDoS, и если данный материал вызовет интерес, то в следующем цикле статей начнем подробно раскрывать технические детали.
Чем характерно решение по защите от DDoS-атак для операторов связи?
Особенность построения решений по анализу трафика и выявления DDoS-атак для оператора связи неразрывно связана с архитектурой построения его сетей, а также с возможностями сетевого оборудования. Давайте рассмотрим это на примере: упрощенно архитектура магистральной IP/MPLS сети Ростелеком (AS12389) выглядит следующим образом.

Здесь upstream — вышестоящий оператор связи, peer — равноправный оператор связи или также крупный контент-генератор, а customer — клиент AS12389
А теперь давайте мысленно переложим дизайн сети на географию:

И, наконец, в цифрах представим количество взаимосвязей с upstream/peer/customer (https://radar.qrator.net)

Таким образом, даже никогда не имевшему дело с проектированием или эксплуатацией операторской сети легко понять: сеть имеет множество стыков и подключений, а природа маршрутизации трафика асимметрична, т. е. трафик в направлении к какому-либо IP-префиксу и от него идет по разным маршрутам. В отличии от дата-центров или корпоративных сетей у операторов связи нет границы в классическом понимании, и поставить средства анализа в одной или нескольких точках на границе не представляется возможным. Поэтому архитектурно эффективно строить AntiDDoS систему, состоящую из двух подсистем:
- Подсистема выявления аномалий: осуществляет сбор и анализ данных о трафике.
- Подсистема фильтрации: осуществляет блокировку паразитного трафика.
Как происходит детектирование DDoS-атак?
Для возможности анализировать трафик и выявлять аномалии по отношению к любому IP-адресу — принадлежащему, напрямую подключенному или транзитом проходящему через AS12389 - необходимо анализировать весь трафик (каждого маршрутизатора, каждого IP-интерфейса). Чтобы решить данную задачу эффективно (с экономической точки зрения), информацию о трафике собираем с помощью протоколов сетевой телеметрии (J-Flow v5/9, Netstream, IPFIX). Далее для простоты все семейство этих протоколов будем называть NetFlow. Данные протоколы не позволяют анализировать информацию прикладного уровня и передают информацию до 4-го уровня модели OSI, например, J-Flow v5 имеет следующую структуру заголовка:

- Source IP address — IP-адрес источника
- Destination IP address — IP-адрес назначения
- Next-Hop IP address — IP-адрес следующего маршрутизатора, на который будет передан сетевой поток.
- Input ifIndex — SNMP индекс интерфейса, через который маршрутизатор получает flow
- Output ifIndex — SNMP индекс интерфейса, через который маршрутизатор передает flow
- Packets — общее количество полученных пакетов в рамках потока
- Bytes — общее количество байт полученных в рамках потока
- Start time of flow — время начала потока
- End time of flow — время окончания потока
- Source port — порт источника
- Destination port - порт назначения
- TCP Flags — TCP флаги
- IP protocol — номер IP протокола
- ToS — тип сервиса
- Source AS — номер автономной системы IP источника
- Destination AS — номер автономной системы IP назначения
- Source Mask - маска сети IP источника
- Destination Mask — маска сети IP назначения
- Padding — отступы для эффективного использования всей длины заголовка
J-Flow v9 и IPFIX дополнительно добавляют информацию об:
- ICMP type/code
- IPv6
- MPLS
- BGP Peer AS
Но ключевое отличие v9 и IPFIX от v5 в том, что пользователь сам может определить какие поля хочет анализировать посредством создания шаблона. NetStream мы пока не используем в продуктивной системе, но планируем в ближайшее время добавить.
На данный момент AS12389 — это более 300 маршрутизаторов, поэтому для сбора NetFlow развернута инфраструктура коллекторов, которые позволяют на высокой скорости принимать, обрабатывать и писать в базу данных. С учетом того, что по сети передаются терабиты в секунду, то даже при использовании механизма сэмплирования с высоким коэффициентом (>4k) маршрутизаторы генерируют более 300 тыс NetFlow записей в секунду. Сэмплинг позволяет анализировать не каждый прошедший через маршрутизатор пакет, а выборочно в соответствии с проприетарным алгоритмом, который реализуют вендоры в своем оборудовании, что снижает нагрузку на Control Plane или на сервисную карту маршрутизатора.
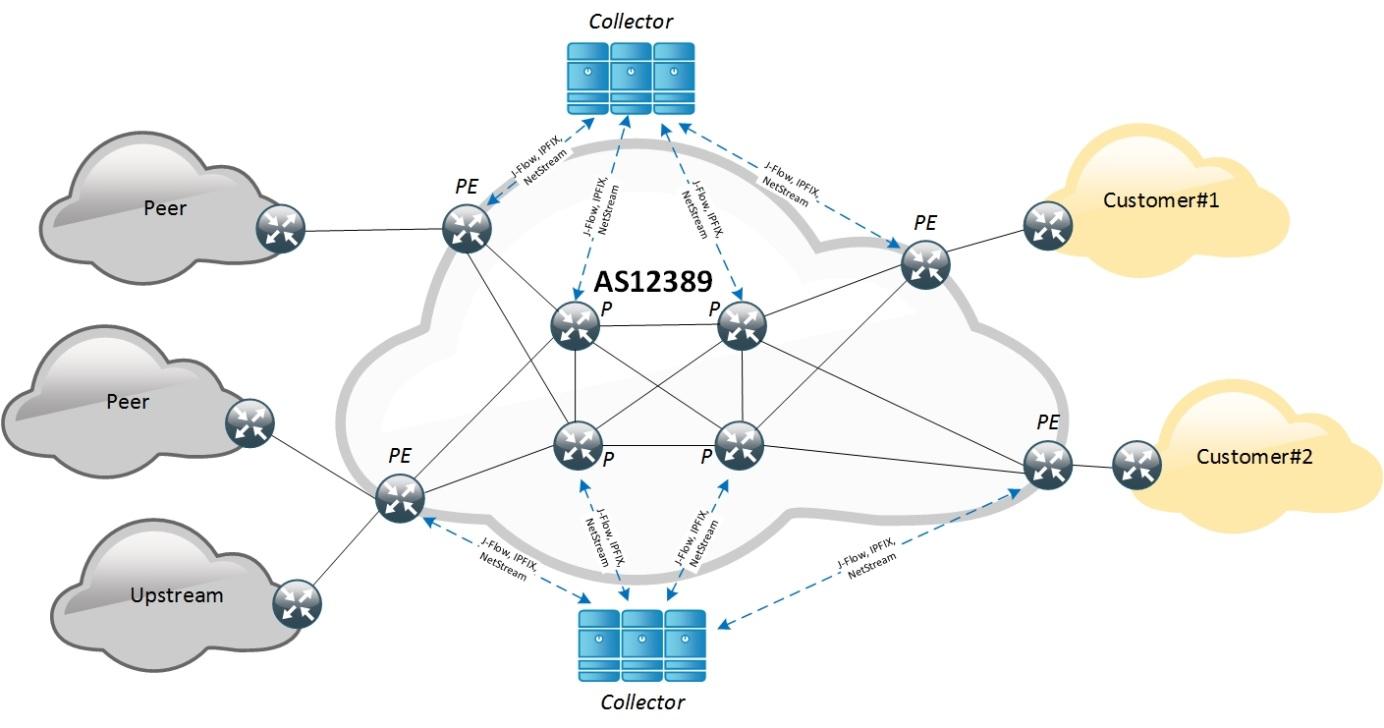
На коллекторах создаются так называемые Binning Table, в которые мапится NetFlow и собирается статистика по объектам защиты. Под объектом защиты мы понимаем сущность в системе, которая описывается каким-либо из следующих признаков:
- IP prefix list (CIDR блоки и группы)
- ASN, в том числе с возможностью задания атрибутов AS-Path и community
- Сетевые интерфейсы
- Flow Filter — логическое выражение, описывающие различные парметры и комбинации полей IP и транспортного заголовка. Например, "dst host 1.1.1.1 and proto tcp and dst port 80".
Список доступных полей:
- Average packet lengths
- Destination addresses
- Destination ports
- ICMP codes
- ICMP types
- Protocols
- Source addresses
- Source ports
- TCP flags
- TOS bits
- Average packet lengths
На основании полученной статистики система формирует динамический профиль нормального поведения трафика для объекта защиты. Также вручную можно задать статический профиль в форме пороговых значений для наиболее популярных сигнатур атак. Например, большинство DDoS-атак типа Amplification (NTP, DNS, Chargen, SSDP и.т.д.) отлично детектируются данным методом. В случае отклонения трафика от пороговых значений система генерирует сообщение об аномалии.
В зависимости от процента превышения порога аномалии разделяются на три типа по уровню критичности: low, medium и high. Чаще всего low-аномалии характеризуются всплеском легитимного трафика, например, запущенная маркетинговая компания, в ходе которой пользователей на защищаемый веб-сайт пришло больше, чем обычно. Поэтому специалисты дежурной смены более пристально следят за medium и high аномалиями.
Как происходит фильтрация DDoS-атак?
После того, как система выявила аномалию в отношении защищаемого ресурса, его трафик можно перенаправить на фильтрацию в ручном, либо автоматическом режиме.
Существует несколько методов фильтрации:
- Flow Specification фильтры;
- Black-Hole Routing — при оказании AntiDDoS сервиса мы его не используем, поэтому в этой статье уделим совсем немного места;
- Интеллектуальная фильтрация в Центрах очистки трафика (ЦОТ).
Всего на сети развернуто два гео-резервируемых ЦОТ в отказоустойчивом варианте на каждой площадке (GR + HA).
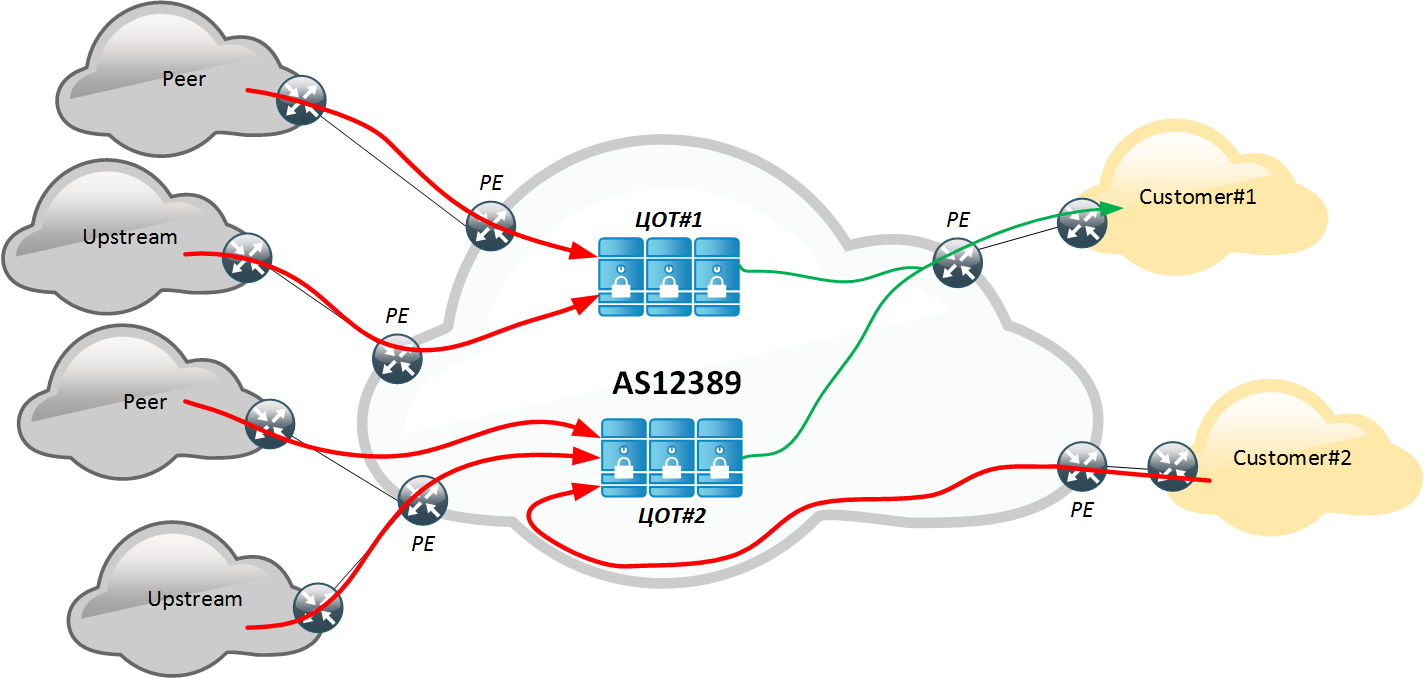
Перенаправление осуществляется путем анонсирования внутри AS12389 more-specific маршрута к защищаемому объекту через ЦОТ. Тем самым весь трафик, включая паразитный, стягивается в ЦОТ, где происходит его фильтрация, затем «чистый» трафик доставляется в сеть клиента. Для того чтобы избежать петель маршрутизации, мы используем механизм доставки трафика через MPLS, передавая маршрутные метки через BGP Labeled-Unicast (механизмам доставки очищенного трафика будет посвящена отдельная статья). Выбрав данный метод, а также единожды настроив свое оборудование, мы исключаем необходимость дополнительных настроек на стороне клиента. Таким образом, любой, кто имеет подключение к AS12389, может быть защищен. Ответный трафик от клиента маршрутизируется по best-path, т.е. без изменения в маршрутизации, и тем самым не попадает в ЦОТ. Поэтому образуется безусловная асимметрия, у которой есть как свои недостатки (возможность в применении определенных контрмер и анализе ответов приложения), так и преимущества (не увеличивает задержку для ответного трафика).
Асимметрия в способе доставке трафика влияет на набор возможных контрмер (правил фильтрации), что заставляет разработчиков системы искать такие варианты определения паразитного трафика и ботов, которые бы основывались только на входящем трафике.
Несмотря на то, что детектирование атак не включает в себя прикладной уровень, фильтрация трафика происходит вплоть до уровня L7 модели OSI, с применением как сигнатурных, так и поведенческих методов.
ЦОТ построен на специализированном оборудовании на базе ATCA-платформ, что позволяет получать высокую производительность фильтрации (включая прикладной уровень) на одно шасси. В последние годы, с появлением таких технологий, как Intel DPDK, HyperScan, сетевых карт 10G и 40G, а также увеличением количества ядер CPU, появилась возможность достаточно эффективно распараллеливать обработку сетевых потоков, поэтому в ближайшее время мы планируем уходить с ATCA на сервера x86 архитектуры.
Для чего тогда нужен Flow Specification и как его использовать?
Все современные маршрутизаторы операторского класса имеют встроенные механизмы фильтрации вплоть до L4 OSI, которые могут называться у разных производителей по-своему, но в общем случае принято называть Access Control List (ACL). ACL реализован аппаратно в линейных картах и способен фильтровать как транзитные пакеты, так и те, что предназначены самому маршрутизатору на скорости канала или на близкой к ней (line-rate), что делает эту технологию достаточно полезной в случае, если нам нужно срезать паразитный трафик как можно ближе к источнику атаки, т.е. на границе нашей сети. Но т.к. ACL конфигурируется локально на каждом маршрутизаторе, а как мы говорили, у нас их больше 300, то в случае атаки оперативное применение фильтров становиться невозможным. С целью централизованного управления (создание, удаление) ACL был разработан протокол BGP Flow Specification (RFC 5575).
Некоторые операторы предоставляют FlowSpec как сервис своим клиентам, Ростелеком пока это не делает, т.к. активно использует его в собственных целях, а количество правил, поддерживаемых маршрутизаторами, пока еще недостаточно велико. Мы рекомендуем вам обратиться к своему оператору и узнать о наличие подобного сервиса, т.к. FlowSpec реализован в таких проектах, как ExaBGP, что позволяет получить доступный инструмент для установки фильтров на сети оператора и защищаться от атак, направленных на канал, не покупая дорогостоящий сервис. Этот вариант защиты устроит далеко не всех, но может оказаться достаточной и недорогой альтернативой полноценного AntiDDoS сервиса.
Система, которую используем мы, позволяет распространять эти фильтры напрямую из web-интерфейса. Таким образом мы можем настроить тригеры и создавать задания фильтрации из задетектированной системой аномалии автоматически.
Разные производители сетевого оборудования, а также разные версии операционных систем этих производителей могут применять данные фильтры либо ко всем интерфейсам, либо к выборочным, таким образом снижая нагрузку на оборудование, не прогоняя каждый пакет из каждого интерфейса через цепочку правил.
В основном FlowSpec мы используем как первый эшелон фильтрации для тех атак, которые хорошо поддаются шаблонизации до L4: сюда отлично укладываются почти все UDP-based Amplification атаки. Это позволяет не гнать паразитный трафик до ЦОТ, а срезать его как можно раньше, и уже для оставшегося трафика выполнять «тонкую» очистку.
Есть ли место для Blackhole?
В самом базовом случае, в том числе, когда паразитный трафик направлен в сторону ресурса, на котором ничего не опубликовано (а такое тоже бывает), в распоряжении оператора есть возможность отправить весь трафик к этому ресурсу в Blackhole. Для этого на каждом маршрутизаторе задается маршрут, next-hop которого смотрит в discard, т.е. трафик попросту сбрасывается. При необходимости централизованного распространения Blackhole используют систему route-reflector’ов, трафик к префиксу прописывают на одном из них, и в результате данный маршрут получают все маршрутизаторы.
А что насчет Blackhole community?
Хорошим тоном для оператора является использование различных BGP CommunitiesAttribute для возможности клиента управлять своим трафиком. Одним из таких community является Blackhole Community. Обычно данную информацию операторы публикуют в ремарках базы данных маршрутной информации к своей автономной системе, например, RIPE. Для «Ростелекома» данным community является 12389:55555. Префиксы с данным community принимаются вплоть до /32, при этом с другими – не специфичнее, чем /24.
Взаимодействуют ли операторы между собой в части защиты от DDoS-атак?
В каких-то вопросах — да, в основном это касается включения BGP FlowSpec на своих стыках, но делают это довольно осторожно, т.к. периодически выявляются баги в реализации протокола на оборудовании того или иного вендора. В остальных случаях, т.к. услуга защиты от DDoS атак все-таки является коммерческой, то в силу конкуренции отсутствуют технические и организационные методы взаимодействия обмена информацией об атаках (такие как IoC).
На базе каких решений строятся операторские системы выявления и защиты от DDoS-атак?
В России наибольшую популярность снискали следующие решения:
- Arbor Networks "SP" и "TMS"
- Radware "DefensePro"
- МФИ Софт "Периметр"
- Иновентика технолоджес "InvGuard"
- NSFocus "ADS" и «NTA»
- Huawei "AntiDDoS8000/10000"
Однако не все из представленных выше производителей имеют end-to-end решение (коллектора NetFlow для анализа трафика и устройства фильтрации) и часто поставляются в паре с другим вендором, например, таким как Genie Networks "GenieATM". А некоторые поддерживают работу с разными решениями для сбора NetFlow. Сравнение представленных решений заслуживает отдельной статьи, поэтому не будем подробно останавливаться на каждом из них.
Чем отличаются операторы от облачных сервисов?
Оператор связи предоставляет сервис только тем клиентам, которые физически подключены к его сети, потому что, как вы уже поняли, собирать статистику по трафику и перенаправить на фильтрацию в ЦОТ оператор может только внутри своей сети. Подключение к услуге по защите от DDoS-атак не требует каких-либо действий со стороны клиента (в нашем случае). Также оператор защищает весь канал, а не отдельно взятые приложения и сервисы, что позволяет получить полноценную защиту для всей IT-инфраструктуры.
На начальном этапе своего развития облачные сервисы брали под защиту только web-сайты. Перенаправление трафика происходило путем изменения А-записи в DNS на IP адрес из IP-пула облака. Очищенный трафик до клиентов доставлялся методом reverse-proxy. Этот метод перенаправления и доставки до сих пор актуален и является наиболее популярным. Но в случае, если у заказчика помимо web-сайта имелись и другие критичные ресурсы (DNS, почтовые сервера и т.д.), которые необходимо было защищать, данный метод не позволял перенаправить в облако весь трафик. Тогда облачные сервисы начали подключать сети заказчиков по VPN, что по сути сделало их оверлейными интернет-провайдерами, которые начали фильтровать не отдельно взятое приложение, а весь канал.
В последнее время операторы также начинают разворачивать на своей сети кластеры с reverse-proxy и WAF, что позволяет брать под защиту клиентов, расположенных вне их сети. Тем самым мы видим, что условная граница между операторами и облачными сервисами начинает стираться.
Пожалуй, не имеет большого смысла сравнивать сферического оператора со сферическим облаком, т.к. даже последние могут значительно отличаться между собой. Например, одни разрабатывают систему самостоятельно, вторые строят на базе готовых промышленных решений различных вендоров, третьи имеют распределенную по миру сеть ЦОТ, подключенных к разным upstream операторам, четвертые имеют один или несколько ЦОТ на территории одной страны с подключением к одному из местных операторов связи, пятые требуют обязательной установки сенсоров на площадке заказчика, шестые специализируются только на web-трафике. Данную тему мы постараемся раскрыть в своих будущих статьях.
Подводя итоги, как мы увидели выше, для оператора связи характерны следующие черты:
- вследствие своего размера оператор связи имеет возможность «получить» большое количество трафика для фильтрации;
- большому оператору связи его архитектура позволяет фильтровать на входе в сеть;
- после первоначальной фильтрации поток «грязного» трафика становится гораздо меньше, и его уже можно анализировать в ЦОТ;
- качество фильтрации зависит от ряда параметров, среди них основные — это возможности системы фильтрации и опыт NOC/SOC;
- оператору связи, если клиент уже пользуется его услугами, зачастую проще и быстрее подключить его на защиту и начать фильтрацию трафика.
В заключение хотелось бы сказать, что наша компания с 2008 года занимается развитием инфраструктуры по анализу трафика и защиты от DDoS-атак, за это время мы несколько раз модернизировали подходы как в части сбора аналитики, фильтрации трафика, доставки очищенного трафика, так и реализовали дополнительные опции, такие как CloudSignaling. В следующих статьях, рассказывая об используемых нами технологиях, мы обязательно покажем ретроспективу и раскроем причины, которые управляли нами при выборе пути развития.
Комментарии (12)

mike_y_k
29.03.2017 19:17Как и заявлено — пока азы, но не совсем для новичков ;).
Если продолжение таки будет и вглубь, и вширь — будет весьма интересно посмотреть на взгляд изнутри.

porutchik
29.03.2017 19:51-1Как с помощью flowspec можно отличить валидный dns-ответ с udp 53 порта от невалидного?
Если никак, то технология мертворождённая. А если блокировать всё, то и ЦОТ не нужны.
0din
29.03.2017 23:09Никак, не для этих целей. FS имеет смысл использовать для volumetric атак, но не для всех. Например, он не подходит для защиты от атак типа DNS Amplification на DNS сервер, при этом вам не нужно анализировать пакет на валидность, если этот тип атаки идет на любой другой сервис, можно блокировать не задумываясь.
Один из сложных сценариев: защита рекурсивного DNS сервера от DNS Amplification. В этом случае трафик нужно гнать в ЦОТ и там фильтровать на прикладном уровне. Но и тут сложность не в написании/разработке контрмер, зачастую все примитивно и достаточно применить фильтрацию по регулярному выражению. Основная задача — иметь достаточно производительные ЦОТ и широкие каналы.
p.s. некоторые SYN-флуд (100mpps+), по тому к какому эффекту приводят, можно легко отнести к volumetric. FS для TCP сервиса тоже будет бесполезен в таком случае.

SbWereWolf
30.03.2017 03:40+2можете похвастаться статистикой отражённых атак?
0din
01.04.2017 11:02мы подготовим отдельную статью или в рамках одной из статей осветим подробнее статистику с распределением по типам атак, а пока можем привести такие цифры:
1. В среднем в сутки наблюдаем до 700 атак.
2. Максимальная мощность атаки в bps — 214Gbps
3. Максимальная мощность атаки в pps — 100Mpps
4. В среднем в месяц 1-2 атаки выше 50 Гбит/с

ximaera
В частности, вы сами предлагаете детектировать атаки с помощью средств сетевой телеметрии. Например, атаку прикладного уровня на HTTPS-сервис таким образом не детектировать, а это один из самых токсичных методов атаки: если забитый канал начнёт работать тут же, как очистится, то после атаки в правильное место Web-приложения может потребоваться даже перезагрузка сервера :-( Так что даунтайм будет огромный.
При выборе решения по защите, особенно новичку (для которых заявлена ваша статья), этот аспект и сферу применения решений операторского уровня в целом понимать нужно обязательно.
0din
В статье написано, что есть две фазы: детектирование и фильтрация. В ходе фильтрации используется в том числе прикладной анализ. В ходе же детектирования, прикладной уровень в _простом случае_ не анализируется, но это не мешает детектировать отклонения от нормы по netflow для high rate application атак, причем достаточно быстро — десятки секунд. Для slow rate можно делать интересные вещи, о которых некоторые могли не знать, например, анализировать не скорость bps/pps, а число new/concurent session, которое опять же будет отклоняться от нормы. Вы безусловно правы, что netflow не лучшее для этого средство, но для тех случаев, где важно иметь еще более высокую скорость реакции и точность детектирования — используются схемы:
1. с WAF, который выступает в качестве Reverse-proxy, а также добавлят механизмы защиты отличные от DDoS
2. Установка на площадке клиента дополнительного устройства, которое стоит в inline и проводит анализ на прикладном уровне в real-time.
Но «токсичность», на самом деле, не в детектировании и вы это прекрасно понимаете, а в возможности отфильтровать, когда клиент не готов отдавать закрытый SSL/TLS ключ и схема с keyless SSL его не устраивает. В данном случае многие облачные провайдеры (почти все) вынуждены будут развести руками и сказать, что атаку видим, но помочь ничем не можем. И из этой ситуации есть выход, но это всегда «инфраструктурные» истории: отдавать лог; ставить анализатор лога у заказчика; встраивание в приложение и.т.д. Нужно эту тему шире раскрывать…
И да, статья не о том как новичку выбирать сервис, она скорее для тех, кто интересуется технологией.
ximaera
Я не говорю, что эта методика вообще неработоспособна. Вопрос в том, что она не обеспечивает полное покрытие и потому подходит только для случаев, когда целевых атак не ожидается, все угрозы являются спорадическими и маловероятными («да кому нас нужно атаковать»), а даунтайм в случае нападения рассматривается как приемлемый риск.
А вот если риск оценивается как вероятный и/или даунтайм совершенно неприемлем, то необходимо использовать гарантированно надёжные методы: анализ всего трафика вплоть до layer 7 в inline и real time и постоянная непрерывная фильтрация.
Ну и замечу, что если таки риск маловероятен и даунтайм приемлем, то в таких случаях обычно эффективнее вообще не подключаться ни к какому оператору защиты, дабы не платить абонентскую плату, а ограничиться составлением регламента реагирования на инцидент и заключением соглашения о намерениях с каким-нибудь надёжным вендором. Бюджет у NOC/CISO обычно не резиновый, чтобы им разбрасываться, особенно в кризисные годы.
Если требуется высокая реакция и точность, то проще и надёжнее всего просто настроить постоянную маршрутизацию через узлы очистки. Схемы с дополнительными CPE на каждой площадке клиента и постоянными переключениями туда-сюда не только сложны и менее надёжны, но ещё и обычно более дороги.
Речь не совсем об этом. «Токсичность» в данном случае заключается в том, что атака длительностью 2-10 минут приводит ОС и/или СУБД приложения в полностью неработоспособное состояние, для ликвидации которого может требоваться перезагрузка сервера.
Это достаточно типичная ситуация, например, для приложений, работающих под ОС серверного семейства Windows: в результате повышенной нагрузки ОС может перестать реагировать на внешние раздражители или вообще показать «синий экран смерти» (красный в последних версиях). И на практике на семействе ОС от Microsoft проблема не заканчивается.
«Поинцидентное» переключение под защиту поможет справиться с «школьными» атаками типа amplification, однако в случае вышеописанной атаки оно окажется неэффективным. Так что, повторюсь, главный вопрос — в оценке рисков и в управлении ими.
Именно исходя из оценки рисков, вырабатывается та или иная стратегия защиты и реагирования. Технологии служат инструментом реализации этой стратегии и поэтому вторичны. Рассказывать о технологиях, не упоминая области их применимости — это как рассказывать про инженерное устройство мостов, не рассказав перед этим про сопромат :-) Поэтому «сопромат» в статьях такого уровня необходим.
flx
ximaera — отличные комментарии, но статья не про это.
Cтатья про то как Ростелеком решает проблему DDoS для себя и своих заказчиков. И с этой целью она отлично справляется. Очень хочется прочитать Часть2. Коллеги молодцы.
FeRViD
Не совсем согласен, т.к. у любой статьи всегда имеется определенный уровень абстракции, на который она изначально рассчитана.
Про мосты можно тоже по-разному рассказывать, можно «на-пальцах», а можно так глубоко свалиться в детали, что вообще уйти в петлевую квантовую гравитацию. :-)