В книге «Совершенный код» Стива Макконнелла описана яркая философская идея, что основной вызов, который стоит перед разработчиком, — это управление сложностью кода. Одним из способов управления сложностью является декомпозиция. Собственно, о разделении большого куска кода на более простые и маленькие и пойдет речь.
Модули
Zend Framework предлагает нам делить наш код на модули. Чтобы не изобретать велосипед и идти в русле фреймворка, пусть наши части, на которые мы хотим логически разрезать проект, и будут модулями в терминах Zend Framework. Только мы доработаем межмодульное взаимодействие, чтобы каждый из них работал исключительно в своей области ответственности и ничего не знал о других модулях.
Каждый модуль состоит из набора классов с типовым назначением: контроллеры, слушатели событий, обработчики событий, обработчики команд, сервисы, команды, события, фильтры, сущности и репозитории. Все перечисленные типы классов организовываются в некоторую иерархию, где верхний слой знает о нижних слоях, но нижние ничего не знают о верхних (да, слоистая архитектура, она самая).
На вершине логической иерархии стоят контроллеры и слушатели событий. Первые принимают команды от пользователей в виде http-запросов, вторые реагируют на события в других модулях.
С контроллером все понятно — это обычный стандартный MVC-контроллер, предоставляемый фреймворком. Слушатель же событий мы решили сделать один на все модули. Он реализует интерфейс агрегатора слушателей Zend\EventManager\ListenerAggregateInterface и привязывает обработчики событий к событиям, взяв описание из конфигурации каждого из модулей.
class ListenerAggregator implements ListenerAggregateInterface
{
/**
* @var array
*/
protected $eventsMap;
/**
* @var ContainerInterface
*/
private $container;
/**
* Attach one or more listeners
*
* Implementors may add an optional $priority argument; the EventManager
* implementation will pass this to the aggregate.
*
* @param EventManagerInterface $events
*
* @param int $priority
*/
public function attach(EventManagerInterface $events, $priority = 1)
{
$events->addIdentifiers([Event::DOMAIN_LOGIC_EVENTS_IDENTIFIER]);
$map = $this->getEventsMap();
$container = $this->container;
foreach ($map as $eventClass => $handlers) {
foreach ($handlers as $handlerClass) {
$events->getSharedManager()->attach(Event::EVENTS_IDENTIFIER, $eventClass,
function ($event) use ($container, $handlerClass) {
/* @var $handler EventHandlerInterface */
$handler = $container->get($handlerClass);
$handler->handle($event);
}
);
}
}
}
}
После чего в каждом из модулей задается карта событий, на которые подписываются слушатели данного модуля.
'events' => [
UserRegisteredEvent::class => [
UserRegisteredHandler::class,
],
]
Фактически модули общаются между собой исключительно посредством контроллеров и событий.
Если нам нужно подтянуть какую-то визуализацию данных из другого модуля (виджет), то мы используем вызов контроллера другого модуля через forward() и добавляем результат к текущей модели вида:
$comments = $this->forward()->dispatch(
'Dashboard\Controller\Comment',
[
'action' => 'browse',
'entity' => 'blog_posts',
'entityId' => $post->getId()
]
);
$view->addChild($comments, 'comments');
Если же нам нужно сообщить другим модулям, что у нас что-то произошло, мы кидаем событие, чтобы другие модули отреагировали.
Служебные классы
Контроллеры и слушатели событий мы рассмотрели выше, теперь пройдемся по оставшимся классам модуля, которые в логической иерархии занимают более низкий слой: обработчики событий, обработчики команд, сервисы и репозитории.
Начну, пожалуй, с последних. Репозитории. Концептуально — это коллекция для работы с определенным типом сущностей, которая может хранить данные где-то в удаленном хранилище. В нашем случае в БД. Их можно реализовать, либо используя стандартные Zend-овские TableGateway и QueryBuilder, либо подключая любую ORM. Doctrine 2 — пожалуй, лучший инструмент для работы с БД в условиях крупного монолита. И репозитории как понятие там есть уже из коробки.
Например, в контексте Doctrine 2 репозиторий будет выглядеть так:
class UserRepository extends BaseRepository
{
/**
* @param UserFilter $filter
* @return City|null
*/
public function findOneUser(UserFilter $filter)
{
$query = $this->createQuery($filter);
Return $query->getQuery()->getOneOrNullResult();
}
/**
* @param UserFilter $filter
* @return \Doctrine\ORM\QueryBuilder
*/
private function createQuery(UserFilter $filter)
{
$qb = $this->createQueryBuilder('user');
if ($filter->getEmail()) {
$qb->andWhere('user.email = :email')
->setParameter('email', $filter->getEmail());
}
if ($filter->getHash()) {
$qb->andWhere('user.confirmHash =:hash')
->setParameter('hash', $filter->getHash());
}
return $qb;
}
}
Для получения сущностей из репозитория могут использоваться как параметры простых типов, так и DTO-объекты, которые хранят набор параметров, по которым нужно организовать выборку из БД. В нашей терминологии — это фильтры (так их назвали, потому что с их помощью мы фильтруем сущности, возвращаемые из репозитория).
Сервисы — классы, которые либо выступают фасадами к логике приложения, либо инкапсулируют логику работы с внешними библиотеками и API.
Обработчики событий и обработчики команд — это фактически сервис с одним публичным методом handle(), при этом они занимаются изменением состояния системы, чего не делают ни одни другие шаблонные классы. Под изменением состояния системы мы подразумеваем любые действия по записи в БД, в файловую систему, отправка команд в сторонние API, которые приведут к изменению возвращаемых этим API данных и т.д.
В нашей реализации обработчик события отличается от обработчика команды лишь тем, что DTO, который в него передается в виде параметра, наследуется от Zend-овского Event. В то время как в обработчик команды может прийти команда в виде любой сущности.
class UserRegisteredHandler implements EventHandlerInterface
{
/**
* @var ConfirmEmailSender
*/
private $emailSender;
/**
* @var EventManagerInterface
*/
private $eventManager;
public function __construct(
ConfirmEmailSender $emailSender,
EventManagerInterface $eventManager
) {
$this->emailSender = $emailSender;
$this->eventManager = $eventManager;
}
public function handle(Event $event)
{
if (!($event instanceof UserRegisteredEvent)) {
throw new \RuntimeException('Неверно задан обработчик события');
}
$user = $event->getUser();
if (!$user->isEmailConfirmed()) {
$this->send($user);
}
}
protected function send(User $user)
{
$hash = md5($user->getEmail() . '-' . time() . '-' . $user->getName());
$user->setConfirmHash($hash);
$this->emailSender->send($user);
$this->eventManager->triggerEvent(new ConfirmationEmailSentEvent($user));
}
}
class RegisterHandler
{
/**
* @var UserRepository
*/
private $userRepository;
/**
* @var PasswordService
*/
private $passwordService;
/**
* @var EventManagerInterface
*/
private $eventManager;
/**
* RegisterCommand constructor.
* @param UserRepository $userRepository
* @param PasswordService $passwordService
* @param EventManagerInterface $eventManager
*/
public function __construct(
UserRepository $userRepository,
PasswordService $passwordService,
EventManagerInterface $eventManager
) {
$this->userRepository = $userRepository;
$this->passwordService = $passwordService;
$this->eventManager = $eventManager;
}
public function handle(RegisterCommand $command)
{
$user = clone $command->getUser();
$this->validate($user);
$this->modify($user);
$repo = $this->userRepository;
$repo->saveAndRefresh($user);
$this->eventManager->triggerEvent(new UserRegisteredEvent($user));
}
protected function modify(User $user)
{
$this->passwordService->encryptPassword($user);
}
/**
* @throws CommandException
*/
protected function validate(User $user)
{
if (!$user) {
throw new ParameterIsRequiredException('На заполнено поле user в команде RegisterCommand');
}
$this->validateIdentity($user);
}
protected function validateIdentity(User $user)
{
$repo = $this->userRepository;
$persistedUser = $repo->findByEmail($user->getEmail());
if ($persistedUser) {
throw new EmailAlreadyExists('Пользователь с таким email уже существует');
}
}
}
DTO объекты
Выше были описаны типовые классы, которые осуществляют логику работы приложения и взаимодействие приложения с внешними API и библиотеками. Но для согласованной работы всего вышеперечисленного нужен “клей”. Таким “клеем” выступают Data Transfer Objects, которые типизируют общение между различными частями приложения.
В нашем проекте они имеют разделение:
— Сущности — данные, которые представляют основные понятия в системе, как то: пользователь, словарь, слово и т.д. В основном, выбираются из БД и представляются в том или ином виде в скриптах вида.
— События — DTO, наследуемые от класса Event, содержащие данные о том, что было изменено в каком-то модуле. Их могут бросать обработчики команд или обработчики событий. А принимают и работают с ними исключительно обработчики событий.
— Команды — DTO, содержащие необходимые обработчику данные. Формируются в контроллерах. Используются в обработчиках команд.
— Фильтры — DTO, содержащие параметры выборки из БД. Формировать может кто угодно; используются в репозиториях для построения запроса к БД.
Как происходит взаимодействие частей системы
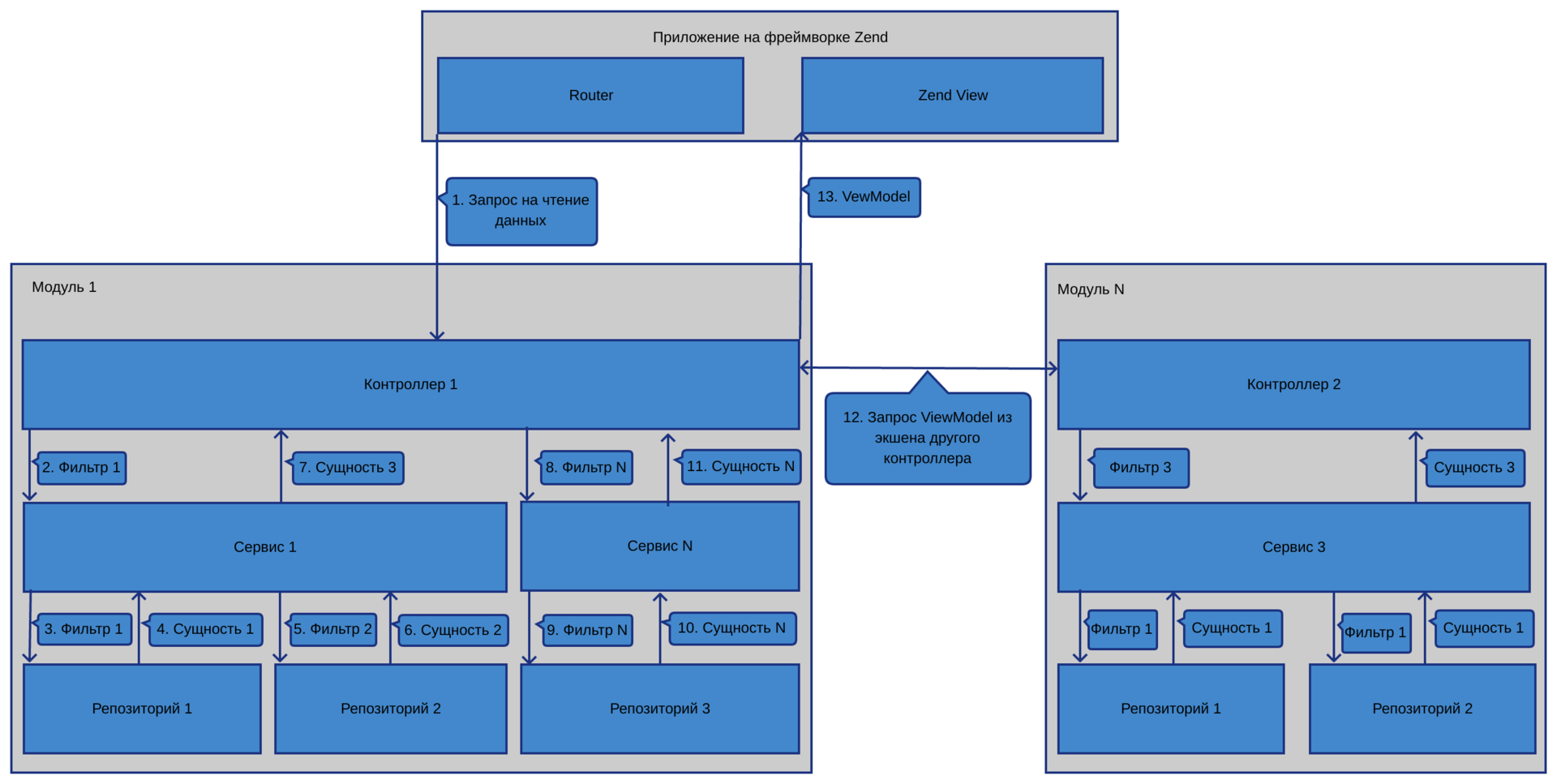
Взаимодействие с системой подразделяется на чтение данных и изменение данных. Если запрошенный URL должен только отдать данные, то взаимодействие построено таким образом:
1) Данные от пользователя в сыром виде приходят в экшн контроллера.
2) Используя Zend-овский InputFilter, фильтруем их и валидируем.
3) Если они валидные, то в контроллере формируем DTO фильтра.
4) Дальше все зависит от того, получаются ли результирующие данные из одного репозитория или компонуются из нескольких. Если из одного, то мы репозиторий вызываем из контроллера, передав в метод поиска сформированный на 3-ем шаге объект. Если же данные нужно компоновать, то мы создаем сервис, который выступит фасадом к нескольким репозиториям, и уже ему передаем DTO. Сервис же дергает нужные репозитории и компонует данные из них.
5) Полученные данные отдаем во ViewModel, после чего происходит рендеринг скрипта вида.
Визуализировать компоненты, участвующие в получении данных, а также движение этих данных можно с помощью схемы:
Если запрошенный URL должен изменить состояние системы:
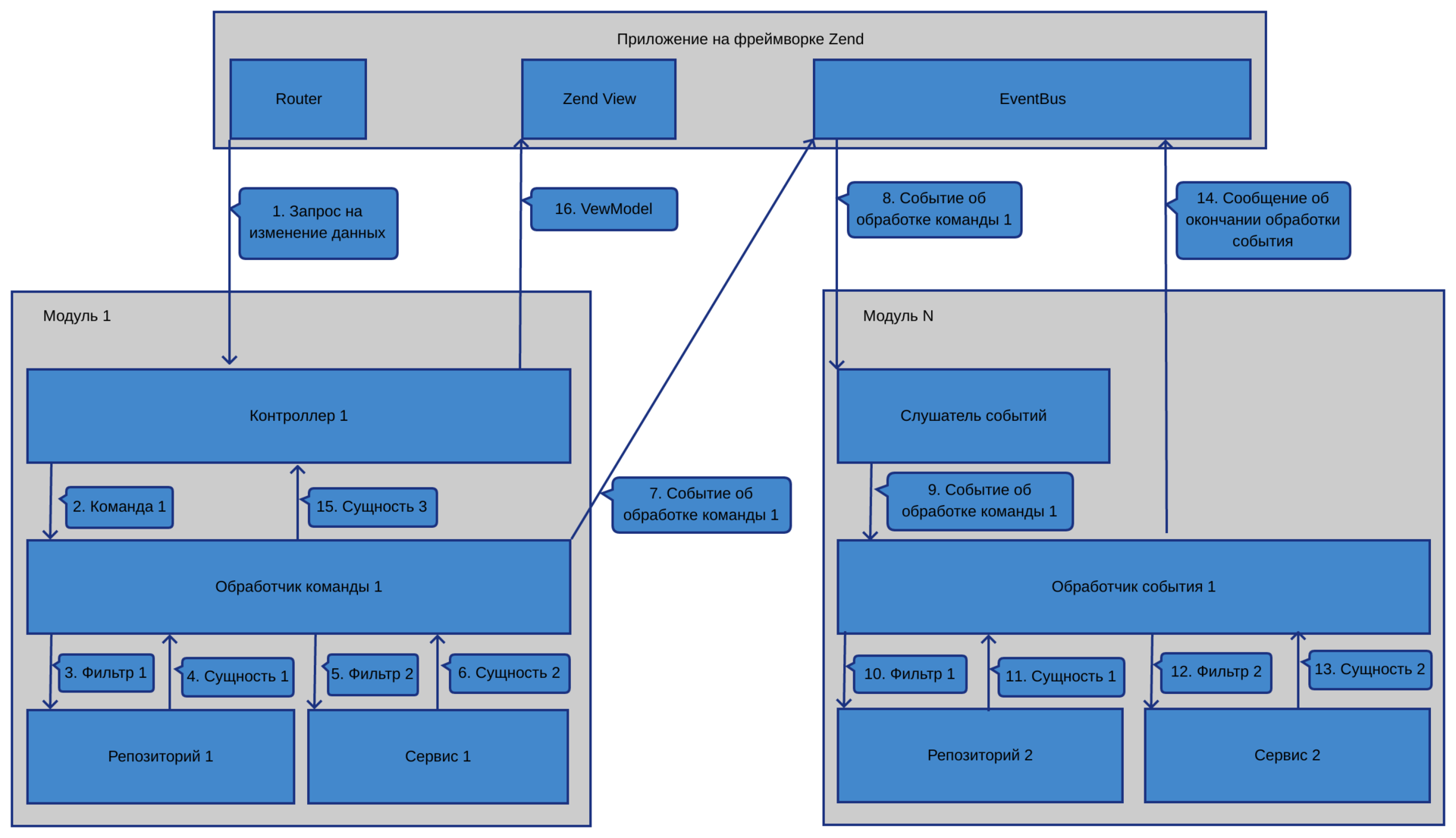
1) Данные от пользователя в сыром виде приходят в экшн контроллера.
2) Используя Zend-овский InputFilter, фильтруем их и валидируем.
3) Если они валидные, то в контроллере формируем DTO команды.
4) Запускаем в контроллере обработчик команды, передав в него команду. Правильным считается передавать команду в шину команд. Мы использовали как шину Tactician. Но в итоге решили напрямую запускать обработчик, т.к. с шиной команд хоть и получали дополнительный уровень абстракции, который теоретически давал нам возможность часть команд пускать асинхронно, но в итоге испытывали неудобство в том, что приходилось подписываться на ответ от команды, чтобы узнать результат ее отработки. А так как у нас не распределенная система и выполнять что-то асинхронно — это скорее исключение, чем правило, то решили пренебречь абстракцией в угоду удобству использования.
5) Обработчик команды меняет данные, используя сервисы и репозитории, и формирует событие, передав туда измененные данные. После чего кидает событие в шину событий.
6) Обработчик(и) событий ловит событие и выполняет свои преобразования. Если необходимо, также кидает событие с информацией о том, какие преобразования были сделаны.
7) После отработки всех обработчиков событий поток управления возвращается от команды в контроллер, где при необходимости берется результат, возвращенный обработчиком команды, и посылается во ViewModel.
Схематически взаимосвязь между элементами, а также то, как происходят вызовы между компонентами, изображено на рисунке:
Пример межмодульного взаимодействия
Самый простой и наглядный пример — это регистрация пользователя с отправкой письма для подтверждения email-адреса. В этой цепочке отрабатывают 2 модуля: User, который знает все о пользователях и имеет код, позволяющий оперировать сущностями пользователей (в том числе и регистрировать); а также модуль Email, который знает, как, что и кому отсылать.
Модуль пользователей ловит в свой контроллер данные из формы регистрации и сохраняет пользователя в базу, после чего генерирует событие UserRegisteredEvent($user), передавая ему сохраненного пользователя.
public function handle(RegisterCommand $command)
{
$user = clone $command->getUser();
$this->validate($user);
$this->modify($user);
$repo = $this->userRepository;
$repo->saveAndRefresh($user);
$this->eventManager->triggerEvent(new UserRegisteredEvent($user));
}
На данное событие могут быть подписаны от нуля до нескольких слушателей в других модулях. В нашем примере модуль Email, который формирует хеш подтверждения, передает хеш в шаблон письма и сгенерированное письмо отправляет пользователю. После чего, опять же, генерирует событие СonfirmationEmailSentEvent($user), куда подставляет сущность пользователя, к которой добавлен хеш подтверждения.
protected function send(User $user)
{
$hash = md5($user->getEmail() . '-' . time() . '-' . $user->getName());
$user->setConfirmHash($hash);
$this->emailSender->send($user);
$this->eventManager->triggerEvent(new ConfirmationEmailSentEvent($user));
}
После чего уже модуль User должен будет поймать событие об отправке письма и сохранить хеш подтверждения в базу данных.
На этом межмодульное взаимодействие должно быть закончено. Да, часто хочется напрямую дернуть код из соседнего модуля, но это приведет к связанности модулей и убьет на корню возможность в долгосрочной перспективе вынести каждый из модулей в свой отдельный проект.
Вместо заключения
Таким, на самом деле, нехитрым структурированием кода можно добиться разделения проекта на независимые небольшие части. Нарезанный на подобные части проект поддерживать гораздо легче, чем проект, написанный сплошняком.
Кроме того, разрабатывая код с использованием подобного подхода, гораздо легче будет перейти к микросервисному подходу. Т.к. уже фактически будут существовать микросервисы, пусть и в контексте одного проекта. Нужно будет только вынести каждый модуль в свой отдельный проект и заменить Zend-овскую шину событий на свою реализацию, которая будет слать события по HTTP или через RabbitMQ. Но это уже чисто теоретические домыслы и пища для размышлений.
Бонусы для читателей Хабра
Онлайн-курсы
Мы дарим вам доступ на год к курсу английского для самостоятельного изучения «Онлайн курс».
Для получения доступа просто перейдите по ссылке. Срок активации промокода — до 1 сентября 2017 года.
Индивидуально по Скайпу
Летние интенсивные курсы английского — заявку оставляем по ссылке.
Занятия проходят в любое удобное для вас время.
Промокод на 35% скидки: 6habra25
Действителен до 22 мая. Введите его при оплате или воспользуйтесь ссылкой.
Комментарии (34)

Delphinum
16.05.2017 13:52Zend Framework предлагает нам делить наш код на модули
Скорее позволяет, нежели предлагает. Для микросервисов на zend я бы предложил посмотреть в сторону Zend-Expressive, а не Zend-Mvc.debugger84
16.05.2017 14:06Как было замечено в статье — у нас уже сложилась большая кодовая база и никто переписывать ее не будет. И статья адресована тем, у кого похожая ситуация, когда проект пишется и развивается с Zend 2.0.0.
Ну а так, совет с Zend-Expressive дельный. Сами его используем в сопутствующих проектах (частях системы), которые начинали разрабатывать в течении последнего года.Delphinum
16.05.2017 14:47У нас есть проекты на zf1 и ничего, выделяем модули в микросервисы на Zend-Expressive. Как правило ничего переписывать не нужно, если используется модульная архитектура зенда, достаточно дописать адаптеры HTTP REST -> Zend -> HTTP REST и все отлично заработает.
boom
16.05.2017 14:21Мы реализовали тоже самое :)
https://github.com/t4web/EventSubscriber/ — конфигуратор обработчиков событий — это для того, чтобы все собития в системе были описаны в конфиге и было видно какие именно обработчики (и в каком порядке) выполняются на определенное событие.
https://github.com/t4web/DomainModule — Доменная модель, с репозиторием
https://github.com/sebaks/zend-mvc-controller — а еще создали абстракцию над контроллерами зенда (по сути паттерн Команда), что позволило абстрагировать обработчик URI от его окружения
https://github.com/sebaks/view — есть еще конфигуратор view, который позволяет описывать повторяющиеся html-блоки и использовать их повторно (с возможностью замены логики отображения ViewModel)
+ еще куча модулей — https://github.com/t4web

Fesor
16.05.2017 14:34tl;dr: делайте так чтобы ваши модули имели низкую связанность (low coupling) но при этом не жертвуйте зацеплением (high cohesion). И вообще почитайте про GRASP.
Fesor
16.05.2017 15:25private function createQuery(UserFilter $filter)
в этом методе мы только что нарушили open-close принцип. Вместо этого предлагаю делегировать конструирование запроса самому объекту filter. А еще лучше — паттерн спецификация но это чуть сложнее.
Та же история с вашими обработчиками событий. Почему бы не сделать что-то типа event subscriber-а а не делать тучу if-ов.
Если они валидные, то в контроллере формируем DTO фильтра.
Почему DTO а не сам фильтр? Почему так сложно для такой простой задачи? Модульности мы тут не получили а просто получили лазанью
$this->eventManager->triggerEvent(new UserRegisteredEvent($user));
опять же, лучше использовать доменные ивенты. Иначе у вас такие штуки будут размазаны по всему коду. Это не столь удобно. А вот когда у вас сами сущности записывают что с ними происходит — такие вещи намного проще хэндлить.
Особенно с доктриной. Тогда мы просто по postFlush можем пройтись по всем сущностям и обработать их события. Плюсы:
- события будут обработаны строго если мы успешно закоммитили транзакцию
- проще с точки зрения отладки так как события не асинхронны
- проще с точки зрения тестирования, так как проверять такие ивенты можно без моков.
oxidmod
16.05.2017 18:53На счет доктрины и постФлаш. Да, это проще, но разве это не протекания доменной логики в инфраструктурный слой?
oxidmod
17.05.2017 16:16Реквестирую ваше мнение, уважаемый Fesor
Fesor
17.05.2017 17:00Думал что отписался...
но разве это не протекания доменной логики в инфраструктурный слой?
это если у вас доменная логика в инфраструктурном слое. Я же предлагаю такой подход:
class Order { use DomainEvents; public function __construct() { $this->id = Uuid::uuidv4(); $this->remember(new OrderAddedEvent($this->id); } }
соответственно в инфраструктурном слое мы всего лишь проходимся по всем сущностям в IM и забираем ивенты. Обработкой этих ивентов уже могут заниматься разные слои, так как направление зависимостей снаружи-внутрь у нас сохраняется.

aprusov
16.05.2017 14:56+1Таким, на самом деле, нехитрым структурированием кода можно добиться разделения проекта на независимые небольшие части.
Тут же у вас вроде явная статическая зависимость от User:
protected function send(User $user)
Модуль пользователей ловит в свой контроллер данные из формы регистрации и сохраняет пользователя в базу, после чего генерирует событие UserRegisteredEvent($user), передавая ему сохраненного пользователя.
Нарезанный на подобные части проект поддерживать гораздо легче, чем проект, написанный сплошняком.
Очень спорное утверждение, особенно на вашем искусственном и простом примере. Вместо простого линейного когда имеем сложную цепочку событий да еще и в разных модулях. И все ради чего этот оверинжиниринг? Все равно же имеем статическую зависимость между модулями. Можно и от нее конечно же избавиться, введя некий контракт взаимодействия, который будет на том же уровне что и модули, но это же ад, сложно представить проект где такое надобно.
Кроме того, разрабатывая код с использованием подобного подхода, гораздо легче будет перейти к микросервисному подходу. Т.к. уже фактически будут существовать микросервисы, пусть и в контексте одного проекта.
Не понятно чем это поможет. Обычно микросервисы ради микросервисов делать бесмысленно, слишком сложный инфраструктурный слой. Деплой, мониторинг всего этого добра дорогой. Микросервисы обычно решают конкретную боль, а если их наплодили ради модной архитектуры, то они только эту боль добавляют.
debugger84
16.05.2017 15:44Вроде же тут же вроде явная статическая зависимость от User:
protected function send(User $user)
Да, вы правы, это зависимость. Код сам по себе вообще не может существовать в вакууме. Он всегда от чего-то и в какой-то мере зависит. В статье, возможно, не достаточно ясно представлено назначение DTO объектов, под словом «клей». Более детально — то это наши объекты, которые выражают предметную область нашего проекта. Они формируют термины, в которых части проекта общаются между собой. И да, для того, чтобы части проекта могли друг с другом взаимодействовать им нужно общаться на одном и том же языке.
Можно эту зависимость ослабить, используя интерфейсы в описании вместо объектов, но особого практического смысла в этом не вижу.
Очень спорное утверждение, особенно на вашем искусственном простом примере. Вместо простого линейного когда имеем сложную цепочку событий в разных модулях.
Для того, чтобы не ломать голову что за чем идет и по какому событию и ввели карту событий в конфиге, чтобы было видно наглядно
'events' => [ UserRegisteredEvent::class => [ UserRegisteredHandler::class, ], ]
Ее можно хранить хоть в глобальном конфиге для всех модулей, хоть для каждого модуля отдельно (тогда в файле кеша конфигов она полностью построится и там ее можно будет найти). На самом деле, из опыта, цепочки получаются не такие уж и монструозные. Обычно один ивент — это один, два обработчика, как-то привыкаешь по ним дебаггером ползать — и какого-то дискомфорта не ощущаешь.
Не понятно чем это поможет.
Иногда сильно помогает, когда поддерживаешь систему, в которой не все уголки исследованы, а те что исследованы — не все умещаются в памяти. Ставится задача бизнесом в терминах бизнеса: отправить письмо человеку, который был на групповом занятии, после окончания этого занятия. И вместо того, чтобы долго и нудно рыться по коду где там то занятие, как и кем закрывается. Смотришь на карту ивентов, которая является набором событий в системе языком бизнеса, находишь, кем-то заботливо оставленный ивент завершения группового занятия и цепляешь туда следующим обработчиком свой новый обработчик, особо не вникая в дебри уже написанного кода.
aprusov
16.05.2017 16:53На самом деле, из опыта, цепочки получаются не такие уж и монструозные.
А как вы решаете какой код (бизнес-задача) к какому модулю относится? Это же очень не тривиальная задача при таком подходе, ведь бизнес более гибкий, он обычно оперирует «фичами», которые на стыке нескольких модулей лежат и относятся к каждому из них в равной степени.
И вместо того, чтобы долго и нудно рыться по коду где там то занятие, как и кем закрывается.
Не совсем понимаю, чем уступает Find Usages в хорошей IDE поиску события в некоторой карте, которого еще может и не быть в системе. Да и чем не устраивает просто явный вызов сервиса, который отвечает за отправку такого письма, прямо в контроллере завершения занятия после прочих действий?
Контроллер же как раз весь этот «клей» и делает более прозрачным образом. А сервис отправки письма позволяет придерживаться SRP без явного усложнения архитектуры.Fesor
16.05.2017 18:48А как вы решаете какой код (бизнес-задача) к какому модулю относится?
фичи формируют контексты (boundary context). Контексты пересекаются но в целом весьма изолированы. Их нутро не зависит друг от друга.
Возьмем к примеру каталог товаров и прикинем какие у нас тут есть контексты:
- пользователи — авторизация, восстановление доступа, управление профилем
- ордеры — весь цикл жизни ордера в системе
- каталог товаров — управление каталогом, просмотр деталей о продукте
- поиск — весь поиск.
В этом примере наиболее интересный "модуль" — это поиск. Он может искать для нас продукты в каталоге и ордеры. Но они ничего не знает о ордерах или продуктах. Скажем когда мы ищем ордеры — мы просим модуль поиска найти для нас "ордеры" и он всего-лишь вернет нам айдишки и информацию которая важна нам для поиска. Далее для этих айдишек мы можем уже запросить детали у модуля каталога.
Синхронизация этих модулей — ивенты. Кто-то обновил продукт — кидаем ивент — синхронизируем данные в других контекстах.
Профит тут в том что мы можем отдельно посадить чувака заниматься поиском, и отдельно чувака заниматься ордерами. Можем перевести поиск на свою СУБД которая хорошо умеет полнотекстовый поиск (например эластика). И при этом если у нас добавляются фичи в каталог — это не сильно влияет на поиск.
Контроллер же как раз весь этот «клей» и делает более прозрачным образом. А сервис отправки письма позволяет придерживаться SRP без явного усложнения архитектуры.
тут есть большая разница между "контроллерами" как прослойкой между http и приложением и "GRASP контроллерами" которые декларируют контрол флоу фичи. То есть в примере автора — это хэндлеры команд. У меня — application level services. У вас — контроллеры которые просто ничего не знают о HTTP например (или знают и вам норм но тогда зачем вы SRP упомянули).
Если вам интересно почему отправлять email-ы по ивентам удобнее — могу написать подробно. У меня был набросок статьи на эту тему в gist но там про доменные ивенты а не просто ивенты.
aprusov
17.05.2017 09:41Профит тут в том что мы можем отдельно посадить чувака заниматься поиском, и отдельно чувака заниматься ордерами.
А минус что всегда нужен архитектор или даже несколько, которые будут проектировать эту систему и следить за «чуваками», чтобы не накосячили и не запороли весь концепт, ибо каждый из них «почти» ничего не знает о другом — «слабая связанность».
Мне кажется, задачи грамотно поделить между людьми можно и не имея такую слабую связанность через эвенты, тут архитектура не так важна, как взаимодействие внутри команды.
Скажем когда мы ищем ордеры — мы просим модуль поиска найти для нас «ордеры» и он всего-лишь вернет нам айдишки и информацию которая важна нам для поиска. Далее для этих айдишек мы можем уже запросить детали у модуля каталога.
Это очень простая бизнес-задача, давайте чуть усложним. Допустим у вас уже есть модуль поиска, который ищет объекты одинаковым способом, как вы описали.
И тут бизнес хочет фичу, чтобы поиск работал для всех сущностей как и раньше, но особым образом ранжировал товары, исходя из статистики прошлых продаж за месяц, при этом для пользователей из «Москвы» больший вес имеют товары с большей ценой, а для остальной страны наоборот с меньшей. При этом товары должны отдаваться в общей выдаче вместе с новостями и статьями по поисковой фразе. Фантазия конечно, но бывают задачи и намного сложнее с точки зрения взаимодействия множества сущностей в проекте.
Как тут быть с определением контекста? Как вам поможет та структура «контекстов» которую вы уже имплементировали ранее? Не кажется ли вам что с таким подходом такие фичи будут пилиться годами рефакторинга или отфутболиваться потому что слишком дорого что-то менять?
Если вам интересно почему отправлять email-ы по ивентам удобнее — могу написать подробно.
Да, было бы интересно подробнее, потому как мы в команде не используем эвенты в конечном проекте и проблем особых нет. Мне кажется они нужны исключительно для отчуждаемых пакетов в качестве точек расширения, внутри монолитного конечно приложения их польза для меня спорна.
oxidmod
17.05.2017 10:04Решает элементарно через стратегии, к примеру. Компонент поиска все также не знает что он ищет, но делегирует поиск в стратегию. В перспективе когда стратегий станет много можно будет даже выделить отдельный компонент, который сможет определять лучшую стратегию для каждого поиска))
aprusov
17.05.2017 10:10Вопрос даже не в том как это реализовать, а в том в какой модуль эту логику поместить, чтобы потомки голову не сломали искать)
Решает элементарно через стратегии, к примеру.
А не рановато ли еще вводить дополнительную абстракцию, увеличивая сложность, когда у нас всего один случай не стандартного поиска? Эта абстракция пойдет лесом при следующей хотелке, с этим столкнулся на своем опыте уже не раз))oxidmod
17.05.2017 10:34Абстракции как раз снижают сложность.
Ели абстракция идет лесом, то увы, была выбрана неверная абстракцияaprusov
17.05.2017 11:12Абстракции как раз снижают сложность.
Вы про какую сложность сейчас говорите? Любая абстракция добавляет когнитивную нагрузку, даже если она убирает банальное дублирование кода.
Ели абстракция идет лесом, то увы, была выбрана неверная абстракция
Вот я так раз за разом и говорю «увы», уничтожая очередную абстракцию в проекте, которая закладывалась на будущее, а когда будущее наступило, она увы не подошла, потому что программист думал не о том что хочет бизнес сейчас, а о сферическом компоненте в будущем, который будет подбирать лучшую из ровно одной реализованной стратегии поиска =)oxidmod
17.05.2017 11:31потому что программист думал не о том что хочет бизнес сейчас, а о сферическом компоненте в будущем
Это проблема не абстракции, а не слишком опытного программиста. Да, изначально следует писать просто, но в тоже время так, что бы внедрение дополнительной абстракции, вынос в другой компонент был максимально простым.
Абстракция снижает сложность, потому что вместо анализа пары десятков строк кода в попытке понять что тут происходит вы видите взаимодействие в системе. Даже банальный вынос куска кода в метод снижает сложность. При условии что метод адекватно именованaprusov
17.05.2017 11:44Это проблема не абстракции, а не слишком опытного программиста.
Согласен, поэтому опытный программист как раз не спешит выделять абстракцию, пока картина мира более-менее не устаканилась или не ясна. Это не всегда возможно понять на первых этапах реализации фичи, поэтому он часто предпочтет дублирование кода слабой абстракции, а потом порефакторит если будет «болеть». А если не будет, то и трогать не надо — есть куча более полезных дел в жизни проекта )
Даже банальный вынос куска кода в метод снижает сложность.
С этим согласен, но опять же мера нужна — иногда выделение в 100500 мелких методов усложняет понимание кода. Именно поэтому есть рефакторинги Extract Method и обратный ему Inline Method, все это очень зависит от конкретной задачи и даже от конкретной команды и все приходит только с опытом, нет готовых рецептов на все случаи.
Fesor
17.05.2017 11:49чтобы не накосячили и не запороли весь концепт, ибо каждый из них «почти» ничего не знает о другом — «слабая связанность».
Ну а как вы хотите по другому делать дела? Не ну конечно можно заморочиться и поискать толковых самоорганизующихся разработчиков но вы как бы сами намекаете что так не выйдет.
В целом достаточно хотя бы описать точки взаимодействия и жестко задекларировать контракты которые будут покрыты тестами. Но какой-то лид на проекте который будет поддерживать это все всеравно нужен. Мы же про большие проекты а не бложики.
Не кажется ли вам что с таким подходом такие фичи будут пилиться годами
Нет, не кажется. Просто разработчик пилящий поиск затребует у команды занимающейся ордерами новых ивентов для сбора статистики. Ну то есть есть какие-то тригеры в системе которые должны вызывать пересчет статистики которая будет учитываться при ранжировании. Это как раз таки с ивентами делать легко относительно.
Можно вообще заморочиться и организовать event sourcing на стороне управления заказами и тд и тогда любая статистика может учитываться и воспроизводиться. Это даст еще буст и возможность экспериментировать.
aprusov
17.05.2017 12:48Мы же про большие проекты а не бложики.
Да, вот тут как раз интересен реальный опыт в такого рода монолитном проекте. Как там разбито все по модулям, как пришли к такому разделению и как решается к какой зоне ответственности относится та или иная бизнес-фича. Просто читая такие статьи о красивых, гибких и правильных архитектурах всегда задаюсь вопросом, а что за «сложные» и «крупные» проекты такие, где это все реально применяется на практике? Где это программистам так «везет» что их абстракции и концепты не ломаются о суровую реальность действительно сложных бизнес-требований. Обычно же все это на примере «бложика» рассматривается, вот и недопонимание)
На мой взгляд, когда проект действительно очень крупный, работает несколько команд мне кажется уже проще придерживаться микросервисной архитектуры, чем использовать такой подход с эвентами в монолите. Тогда и контракты и границы сервисов более очевидны и команды могут быть разного уровня компетентности.oxidmod
17.05.2017 12:50А в микросервисах без ивентов никуда)))
aprusov
17.05.2017 12:52Так кто ж спорит что никуда, там им самое место. Но мы же говорим про монилит )
Fesor
17.05.2017 13:28Представьте себе что хороший монолит от микросервисов отличается только тем, что ивенты ходят в пределах одной машины а не между разными машинами. А ну далее тот факт что все ходит в пределах одной машины позволяет вам просто больше идти на компромисы различные. Ну и деплоить независимо не можем, в чем собственно большой профит микросервисов но если вы деплоитесь раз в неделю то как бы и не надо.
aprusov
17.05.2017 14:49Представьте себе что хороший монолит от микросервисов отличается только тем, что ивенты ходят в пределах одной машины а не между разными машинами.
Не считаю это признаком «хорошести» монолита. Все-таки критерии «хороший» / «плохой» тут вообще не уместны, мне больше по душе понятие «приемлемый», когда архитектура успешно решает все бизнес задачи и разработка нормально поддерживает и развивает кодовую базу.
Эвенты это всего лишь способ слабого взаимодействия модулей, это не серебряная пуля, которая решает проблемы да и не всегда эти проблемы то и есть даже в крупных проектах. Эвент — это осознанная точка расширения, пихать их бездумно «на будущее» очень большая ошибка, имхоFesor
17.05.2017 17:03Эвенты это всего лишь способ слабого взаимодействия модулей
доменные ивенты — это события в пределах предметной области. "Заказ создан", "товар добавлен в карзину", "товар убран из корзины".
То есть мы любую операцию спокойно разделяем на две состовляющие. Логика которая вызывает ивенты — тригеры для действий, и сами действия. Намного проще тестировать.
Ну и опять же, ивенты нужны для связи разных контекстов. Это не маленькие такие модули.
пихать их бездумно «на будущее» очень большая ошибка, имхо
Так я и не предлагаю их пихать бездумно. Вы прекрасно должны понимать чем является каждый ивент для предметной области. Есть даже подходы — event sourcing, которые подразумевают что у вас весь стэйт это просто поток ивентов которые лежат по порядку. Произошло что-то — дописываем ивент. Что-то надо отменить — дописываем ивент невилирующий предыдущий.
Для таких вещей нужно хорошо понимать что делаешь.
Fesor
17.05.2017 13:30Тогда и контракты и границы сервисов более очевидны
не совсем так. Просто у вас нет выбора. А неверно выбранные границы начинают приносить боль сразу. Что может сильно ударить по скорости разработки.
Если команда не умеет монолиты делать нормально в микросервисы им тем паче лезть не стоит.
oxidmod
17.05.2017 10:21DEL
aprusov
17.05.2017 10:24Абстракции часто имеют свойство быть не правильными или преждевременными, тогда они добавляют геморрой и увеличивают сложность. Чтобы более-менее правильно выделить абстракцию, нужно иметь больше одного случая, то есть выделять методом рефакторинга кода. Это не должно быть гаданием на кофейной гуще куда пойдет дальше бизнес и творчеством программиста.
Goodkat
EnglishDom
Бонусы для читателей Хабра:)