
Автор: Игорь Мастерной, Senior Developer, лидер Java-сообщества DataArt
18–19 мая в Киеве прошла JEEСonf — одно из самых ожидаемых событий для всего Java-сообщества Восточной Европы. DataArt выступил партнером конференции. На четырех сценах выступали докладчики со всего мира: Фолькер Симонис — представитель SAP в JCP и контрибьютор OpenJDK, Юрген Хёллер — главный инженер Pivotal, отец всеми любимого Spring Framework, Клаус Ибсен создатель Apache Camel, и Хью МакКи — евангелист в Lightbend.
График был очень насыщенным: за два дня более 50 выступлений, по 45 минут на каждое. 10 минут перерыва — и бежим на новый доклад. На то, чтобы посмотреть все видео, когда они появятся в сети, потребуется много времени. Поэтому кратко опишу доклады, которые я счел наиболее интересным и на которых побывал лично.
15 years of Spring
Конференцию открывал Юрген Хёллер. Он рассказал о 15-летней (!) истории Spring Framework, начиная с «любимых» XML configs в версии 0.9 и заканчивая реактивным Spring WebFlux, которой появился из исследовательских проектов под влиянием Reactive Manifesto. Юрген говорил о сосуществовании Spring MVC и Spring WebFlux в Spring WEB, объснил, почему их решили не объединять в одно целое. Дело в том, что основная абстракция Spring MVC — Servlet API 3.0 и блокирующий IO, тогда как в Spring WebFlux используется абстракция Reactive Streams и non-blocking IO. Свой сервис на SpringWebFlux можно запустить на любом сервере, который поддерживает non-blocking IO: Netty, новые версии Tomcat (> 8.5), Jetty. Создание реактивных контроллеров WebFlux мало чем отличается от их создания с помощью Spring MVC, но отличия все же есть. Обрабатывая пользовательский запрос, реактивный контроллер не обрабатывает его в привычном понимании, а создает pipeline для обработки запроса. Dispatcher вызывает метод контроллера, который создает pipeline и тут же отдает его в виде publisher stream. Publisher stream в Reactive Spring представлен в виде двух абстракций: Flux/Mono. Flux возвращает стрим объектов, а Mono — всегда один объект.
Юрген также упомянул удобство использования Java 8-стиля при работе с Spring 5.0 и обещал release candidate Spring 5.1 в июле 2018 и релиз в сентябре, в котором будет поддержка Java 11 и работа над fine tuning новых фич Spring 5.0
Python/Java integration
Докладов было много, и выбрать самый интересный в следующем слоте было сложно. Описания были одинаково интересные, поэтому я доверился чутью и решил послушать Тамаша Розмана — вице-президента компании BlackRock из Венгрии. Но лучше бы еще раз послушал про Events Sourcing и CQRS. Судя по описанию, компания занимается Data Science для крупного инвестиционного фонда. Цель доклада была показать, как они создали масштабируемую, устойчивую систему, одинаково удобную и для дата-аналитиков с их Python, и для Java-разработчиков основной системы. Однако мне показалось сомнительным, что построенная система действительно получилась удобной. Чтобы подружить Python и Java, инженеры в BlackRock придумали запускать Python-интерпретатор в виде процесса из Java-приложения. Пришли они к этому по нескольким причинам:
- Jython (Python на JVM) не подошел из-за устаревшего code base 2.7 vs СPython 3.6.
- Вариант переписать логику Data Science на Java они сочли слишком долгим процессом.
- Apache Spark решили не брать, поскольку, как объяснил докладчик, нельзя миксовать джобы, написанные на Java и Python. Хотя не совсем ясно, почему не подошли UDF, UDFA [2]. Также не подошел Spark, потому что какой-то job framework у них уже был, и вводить новый не сильно хотелось. Да и, как оказалось, Big Data у них тоже нет, и вся обработка сводится к статистикам над жалкими 100 MB файлами.
Общение из Java c Python процессом организовали при помощи memory mapped files (один файл используется в качестве файла входных данных) и команд (второй файл — вывод Python процесса). Таким образом, общение представляло собой что-то в виде:
Java: calcExr | 1 + javaFunc (sqrt(36)) Python: 1 + javaFunct|6 Java: 1 + success|64 Python: success| 65
Основными проблемами такой интеграции Тамаш назвал накладные расходы при сериализации и десериализации входных/выходных параметров.

Java 10 App CDS
После доклада о тонкостях запуска Python очень хотелось послушать что-то глубоко техническое из мира Java. Поэтому я пошел на доклад Фолькера Симониса, в котором он рассказывал о фичеApplication class data sharing из Java 10+. В современном мире, построенном на микросовервисах в Docker, возможность шеринга Java Codecache и Metaspace ускоряет запуск приложения и экономит память. На картинке результаты запуска докеризированных томкатов с общим/shared архивом Tomcat-классов. Как видим, для второго процесса некоторый объем страниц в памяти уже помечен как shared_clean — значит, на них ссылается текущий и еще как минимум один процесс (второй запущенный томкат).

Подробно о том, как поиграть с CDS в OpenJDK 10, можно найти по ссылке: App CDS. Помимо деления/sharing классов приложения между процессами, в дальнейшем планируется и возможность поделиться интернированными строками в JEP-250.
Основные ограничения AppCDS:
Не работает с классами до 1.5.
- Нельзя использовать классы, загруженные из файлов (только .jar-архивы).
- Нельзя использовать классы, модифицированные класслоадером.
- Классы, загруженные несколькими загрузчиками классов, могут переиспользоваться только один раз.
- Не работает byte-code rewriting, что может привести к просадкам в производительности до 2 %. JDK-8074345

Natural language processing pipeline with Apache Spark
Доклад про NLP и Apache Spark представил Виталий Котляренко — инженер из Grammarly. Виталий показал, как в Grammarly прототипируют NLP-джобы на Apache Zeppelin. Примером стало построение простого пайплайна для тематического моделирования на базе алгоритма LDA архива интернета common crawl. Результаты тематического моделирования применили для фильтрации сайтов с нежелательным контентом в качестве примера функции родительского контроля. Для создания пайплайна использовали Terraform scripts и AWS EMR Spark cluster, который позволяет развернуть Spark Cluster c YARN в Амазоне. Схематично пайплайн выглядит следующим образом:
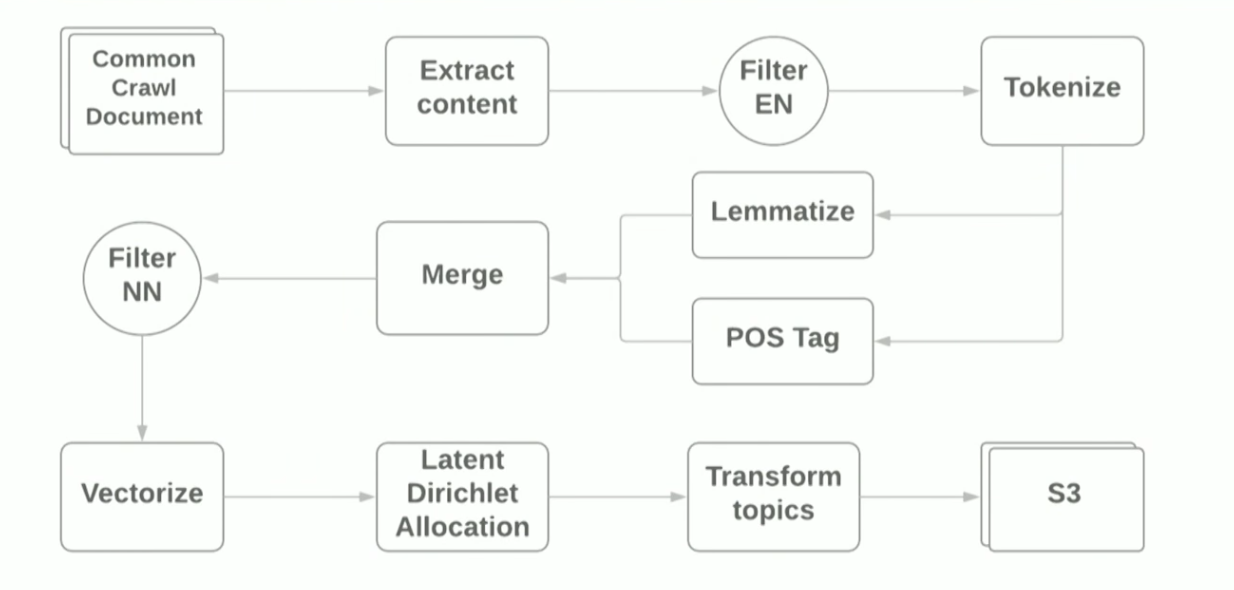
Целью доклада было показать, что с применением современных фреймворков сделать прототип для ML-задач достаточно просто, однако, используя стандартные библиотеки, все равно наталкиваешься на трудности. Например:
- На первом же шаге чтения WARC-файлов при помощи библиотеки HadoopInputFormat иногда вылетали IllegalStateExceptions из-за некорректных заголовков файлов пришлось переписать библиотеку и пропускать некорректные файлы.
- Зависимости на guava — библиотеки определения языка — конфликтовали с зависимостями, которые тянет за собой Spark. Помогла Java 8, с помощью которой получилось выбросить зависимости на guava в используемой библиотеке.
Во время демо мы следили за выполнением джобы с помощью стандартного Spark UI и мониторинговой подсистемы Ganglia, которая автоматически доступна при развертывании на AWS EMR. Основное внимание автор обращал на heat map Server Load Distribution, которая показывает распределение нагрузки между нодами в кластере, и давал общие советы по оптимизации работы Spark Job: увеличение количества partitions, оптимизация сериализации данных, анализ GC-логов. Более подробно об оптимизации Spark Jobs можно почитать тут. Исходные файлы для демо можно найти в гитхабе автора доклада.
Graal, Truffle, SubstrateVM and other perks: what are those and why do you need them
Самым ожидаемым для меня был доклад Олега Чирухина из JUG.ru. Он рассказал, как можно оптимизировать готовый код при помощи Грааля. Что же такое Грааль? Грааль — это бренд Oracle Labs, который объединил в себе JIT (just-in-time) компилятор, фреймворк для написания DSL языков — Truffle — и особенную JVM (SubstrateVM) — универсальную Closed-world виртуальную машину, под которую можно писать на JavaScript, Ruby, Python, Java, Scala. Доклад фокусировался именно на JIT-компиляторе и его тестировании в продакшне.
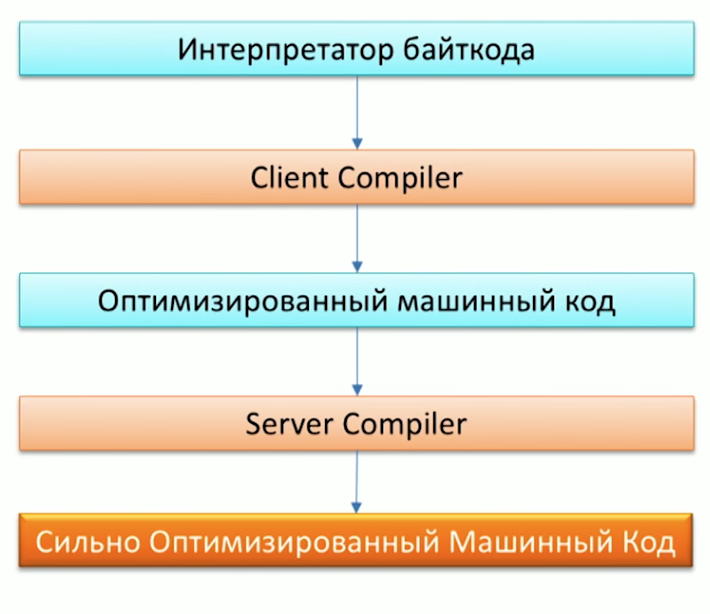
Для начала напомним процесс выполнения кода Java-машиной и обратим внимание, что в Java уже есть два компилятора: С1 (Client compiler) и С2 (Server Compiler). Грааль можно использовать в качестве C2-компилятора.
На вопрос, зачем нам еще один компилятор, очень хорошо ответил один из сотрудников Oracle Labs доктор Крис Ситон в статье Understanding How Graal Works. Если коротко, то изначальная задумка проекта Graal, как и проекта Metropolis, переписать части кода JVM, написанные на С++, на Java. Это даст возможность в дальнейшем удобно дополнять код. Например, одна из оптимизаций — Partial Escape Analysis — уже есть в Граале, но не в Hotspot — потому что расширять код Грааля много проще, чем код С2.
Звучит замечательно, но как это будет работать на практике в моем проекте, спросите вы? Грааль подходит для проектов:
- Которые много мусорят, создавая много мелких объектов.
- Написанных в стиле Java 8, с кучей стримов и лямбд.
- Использующих различные языки: Ruby, Java, R.
Одними из первых в продакшне Грааль начали использовать в Twitter. Об этом подробнее можно почитать в интервью Кристиана Талингера, выходивших на Хабре (интервью_1 и интервью_2). Там он объясняет, что с помощью замены C2 на Graal Twitter начал экономить около 8 % CPU utilization, что очень неплохо, учитывая масштаб организации.
На конференции мы тоже смогли убедиться в скорости Graal, запустив под ним один из Scala-бенчмарков — Scala DaCapo. В результате на Graal бенч прошел за ~7000 мс, а на обычной JVM за ~14000 мс! Почему так произошло, можно увидеть, посмотрев на gclog-тесты. Количество Allocation failure при использовании Graal значительно меньше, чем у Hotspot. Однако все равно нельзя сказать, что Грааль станет решением проблем перформанса вашего Java-приложения. Олег в докладе показал и историю неудачи, сравнив работу Apache Ignite под Граалем и без — там заметного изменения производительности не произошло.

Designing Fault Tolerant Microservices
Очередной доклад об отказоустойчивой микросервисной архитектуре прочитал Орхан Гасимов из компании AppsFlyer. Он представил популярные дизайн-паттерны для построения распределенных приложений. Многие из них мы, возможно, хорошо знаем, однако лишний раз пройтись и вспомнить о каждом из них совсем не помешает.
Основные проблемы отказоустойчивости сервисов, с которыми призваны бороться паттерны, описанные в докладе: сеть, пиковые нагрузки, RPC-механизмы общения между сервисами.
Для решения проблем с сетью, когда один из сервисов перестал быть доступен, нам необходима возможность быстро заменить его на другой такой же. На практике этого можно достигнуть с помощью нескольких инстансов одного и того же сервиса и описания альтернативных путей к этим инстансам, что представляет собой паттерн Service Discovery. Заниматься heartbeat сервисов и регистрировать новые сервисы будет отдельный инстанс — Service Registry. В качестве Service Registry принято использовать всем известные Zookeeper или Consul. Которые, в свою очередь тоже имеют распределенную природу и поддержку отказоустойчивости.
Решив проблемы с сетью, переходим к проблеме пиковых нагрузок, когда некоторые сервисы находятся под нагрузкой и выполняют обработку запросов значительно медленнее штатного режима. Для ее решения можно применить Auto-scaling-паттерн. Он возьмет на себя не только задачи автоматического масштабирования высоконагруженных сервисов, но еще и остановку инстансов после окончания периода пиковой нагрузки.
Завершающей главой доклада автора было описание возможных проблем внутреннего межсервисного общения RPC. Особенное внимание Урахан уделил тезису «Пользователь не должен ждать сообщения об ошибке долго». Такая ситуация может возникнуть, если его запрос обрабатывает цепочка сервисов, и проблема в конце цепи: соответственно, пользователь может ждать обработки запроса каждым из сервисов в цепи и только на последнем этапе получает ошибку. Хуже всего, если конечный сервис перегружен, и после длительного ожидания клиент получит бессмысленный HTTP-ERROR:500.
Для борьбы с такими ситуациями можно применить Timeouts, однако в таймаут могут попасть запросы, которые все-таки могут быть правильно обработаны. Для этого логику таймаутов можно усложнить и добавить особенное пороговое значение количества ошибок сервиса за интервал времени. При выходе количества ошибок за пределы порогового значения мы понимаем, что сервис находится под нагрузкой и считаем его недоступным, дав ему необходимое время справиться с текущими задачами. Такой подход описывает паттерн Circuit Breaker. Также CircuitBreaker.html">Circuit Beaker можно использовать как дополнительную метрику для мониторинга, которая позволит быстро отреагировать на возможные проблемы и четко определить, какие цепочки сервисов их испытывают. Для этого каждый вызов сервисов необходимо обернуть в Circuit Breaker.
Также в докладе автор вспомнил о паттерне N-Modular redundancy, призванном «обрабатывать запросы быстрее, если это возможно», и привел красивый пример его использования для валидации адреса клиента. Запрос в их системе через кэш адресов, отправлялся сразу на несколько Geo Map-провайдеров, в результате чего побеждал самый быстрый ответ.
Помимо описанных паттернов, были упомянуты:
- Fast Path pattern, который можно применить, например, при кэшировании результатов запросов. Тогда обращение в кэш — fast path.
- Error Kernel pattern — паттерн из мира Akka который предполагает деление задачи на подзадачи и делегирование подзадач нижестоящим акторам. Таким образом достигается гибкость обработки ошибок выполнения подзадач.
- Instance Healer, который предполагает наличие специального сервиса — супервизора, управляющего другими сервисами и реагирующего на изменения их состояния. Например, в случае возникновения ошибок в сервисе, супервизор может перезапустить проблемный сервис.

Clustered Event Sourcing and CQRS with Akka and Java
Последний доклад, на который я хочу обратить ваше внимание, прочитал один из евангелистов и архитекторов компании Lightbend Хью МакКи. Компания Lightbend (ранее Typesafe) — что-то вроде Oracle, но для языка Scala. Так же компания активно разрабатывает фреймворк Akka.io. В докладе Хью рассказал о реализации популярного подхода CQRS (Command Query Responsibility Commands/SEGREGATION) на Akka-фреймворке. Схематично архитектура CQRS системы выглядит вот так:
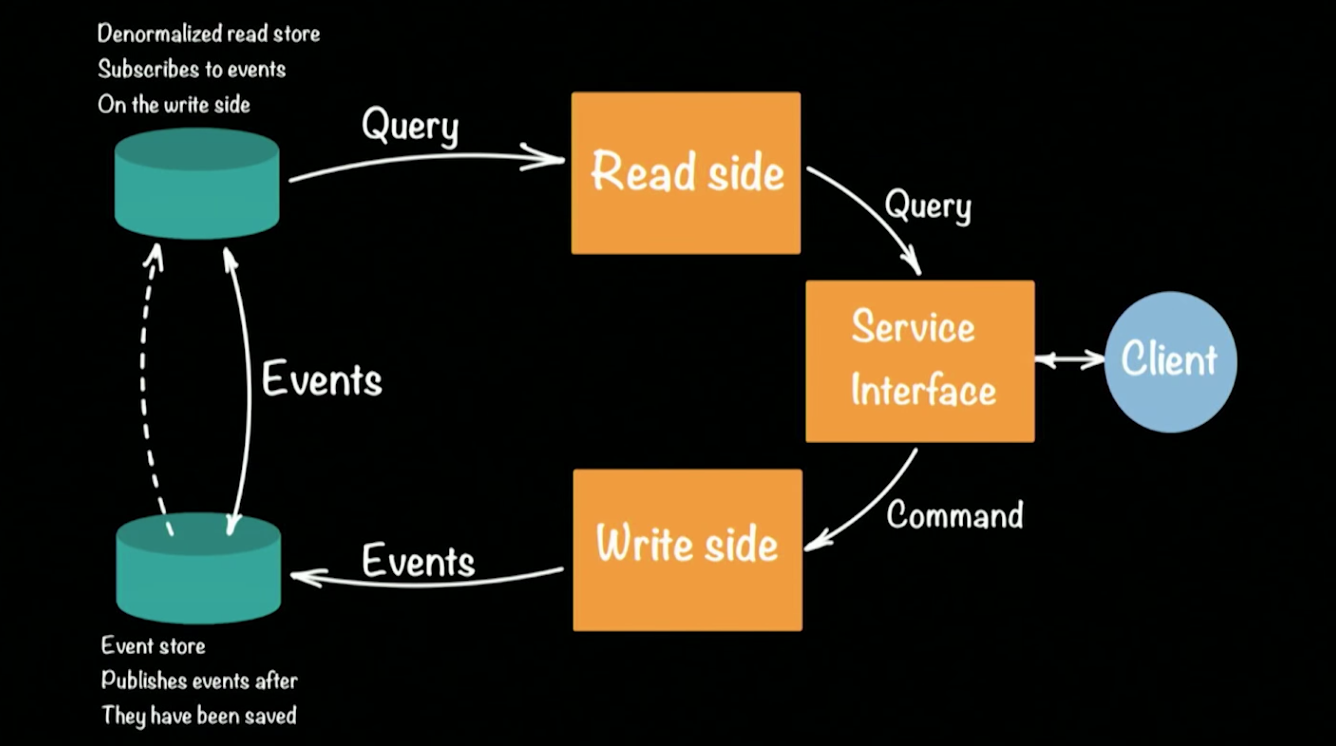
В качестве примера работающей системы Хью взял прототип работы банка. Клиент в CQRS-архитектуре делает две операции: query, command. Каждая команда (например, банковская транзакция перевода денег с одного счета на другой) порождает событие (свершившийся факт), которое будет записано в EventStore (например: Cassandra). Агрегация цепочки (положить деньги на счет, перевести со счета на счет, снять в банкомате) событий формирует текущее состояние клиента, его баланс денег на счету. Запросы текущего состояния идут в отдельное хранилище, некий snapshot хранилища ивентов, поскольку хранить полную историю банковского аккаунта бессмысленно. Вполне достаточно периодически обновлять слепок состояния для каждого пользователя.
Такой подход дает возможность автоматически восстанавливаться при возникновении ошибок: для это нам необходимо достать последний слепок состояния пользователя и применить к нему все события которые произошли до возникновения ошибки. Из-за наличия двух хранилищ, CQRS-архитектура хорошо переносит возникающие пиковые нагрузки (spikes). Большое кол-во ивентов нагрузит Event Store, но не затронет Read Store, и пользователи по прежнему смогут выполнять запросы в базу.
Вернемся к прототипированию банковской системы на Akka и CQRS. Каждый клиент банка/счет/возможная команда в системе будет представлен одним(!) Актором. Крупный банк может поддерживать сотни тысяч счетов, и это не составит проблемы для Akka. Фреймворк из коробки поддерживает кластеризацию и может быть запущен на сотнях JVM. При отказе одной из машин в кластере, Акка предоставляет специальные механизмы, которые позволяют автоматически реагировать на подобные ситуации: в нашем случае актор клиента может быть пересоздан вновь на любой доступной машине в кластере, а его состояние будет заново прочитано из хранилища.
Под актор не создается отдельного потока — это и дает возможность поддерживать десятки тысяч акторов в пределах одной JVM. При этом актор гарантирует, что каждый запрос будет обработан отдельно (!) в порядке поступления запросов. Такая гарантия автоматически нивелирует возможные race conditions при обработке запросов. Подробнее разобраться в прототипе системы можно, открыв ее код по ссылкам в GitHub. Каждый подпроект показывает реализацию наиболее сложных этапов построения прототипа:
- Distributed actors akka clustering — простой пример создания Akka cluster’a.
- Akka cluster singleton показывает, как реализовать singleton-паттерн в распределенной среде Akka.
- Entity distributed sharding akka cluster sharding — пример управления распределением сущностей в кластере и маршрутизацией запросов клиентов.
- CQRS — Write side akka persistence — запись ивентов в хранилище.
- CQRS — Read side akka persistence query — обработка клиентских запр
Записи всех докладов появятся в сети в течение нескольких недель. Надеюсь, что эта статья поможет вам определиться с порядком просмотра, тем более, что посмотреть выступления, думаю, стоит.