

Каждый веб-разработчик, да и многие пользователи рано или поздно сталкиваются с Internet Archive и необходимостью сохранить или восстановить вид важного им сайта в определённое время. С каждым годом всё очевиднее, что поговорка «интернет помнит всё» ошибочна — форумы закрываются, старые сайты тихо исчезают, информация пропадает без следа (вот хорошая статья по теме). При этом пока не существует общепринятого способа на лету сохранять важный контент без лишних телодвижений (представьте, что будет с серверами archive.org, если, скажем, в следующем обновлении Chrome будет при загрузке страницы отправлять адрес на архивацию). Спасение утопающих — дело рук самих утопающих, поэтому в этой статье мы разберём инструмент, позволяющий не просто сохранять нужные сайты, но и встраивать этот процесс в повседневную работу.
Удивительно, что на Хабре ещё не было статей про ArchiveBox — продвинутый архиватор сайтов с огромным количеством поддерживаемых форматов и интерфейсов. Первая бета вышла в 2017 году, тогда это был проект по сохранению закладок Bookmark Archiver. Получив поддержку и перелопатив горы кода, Ник Свитинг переделал инструмент под хранение вообще всего интересного пользователю контента, переименовал проект и собрал 8k звёзд и десятки контрибьюторов на гитхабе благодаря непрерывному улучшению кода и фич в течение нескольких лет. Вообще ArchiveBox — пример того самого хрестоматийного open-source проекта, от которого у авторов горят глаза и простаивают крутые офферы.
Фичи
- Список сайтов можно подать на вход кучей разных способов (TXT, RSS, XML, JSON, CSV, SQL, HTML, Markdown, и т.д.), но самое интересное это импорт из всех основных браузеров (закладки, история) и «закладочных» сервисов (Pocket, Pinboard, Instapaper, Reddit Saved, OneTab и другие).
- Хранение данных в HTML, JSON, PDF, PNG, и WARC — без самописных, проприетарных или новомодных форматов. При этом доступны и необычные методы экспорта, вроде извлечения текста (как в режиме Reader в браузерах) или Git-репозитория для скачанного со страницы кода.
- Взаимодействие через терминал, веб-интерфейс, Python API, REST API и десктопное приложение (последние два варианта пока в альфе) на всех основных ОС (на винде нужен Docker или WSL)
- Архивирование по расписанию (в сочетании с использованием истории браузера получается цепочка автосохранения всех посещённых сайтов)
- Опционально — отправка URL на archive.org (чтобы иметь бэкап не только локально, но и на проверенных серверах)
- Проект полностью опенсорсный, все надстройки опциональны и доустанавливаются в виде модулей. При отключенном экспорте в Internet Archive вообще все данные остаются на локальной машине, а при использовании Headless Chromium вместо Chrome можно обеспечить себе полную приватность.
- Запланировано: использование JS-скриптов во время архивирования, для вырезания рекламы/попапов/разворачивания веток комментариев прямо на лету.
- Уже работает, но нестабильно: сохранение контента за логином/пейволлом по кукам.
Впечатляет, да? Давайте попробуем ArchiveBox в деле.
Установка
Докер-установка подробно описана в вики, мы же рассмотрим классический вариант для линуксов (для голой системы, ведь вы можете накатить ArchiveBox на сервер чтобы не захламлять рабочую машину):
Вынесем работу с архивами под отдельного пользователя (ArchiveBox всё равно не запустится из-под рута, чтобы уберечь неопытного пользователя от фатальных ошибок)
adduser archive
usermod -aG sudo archive
su - archive
Установим pip и собственно ArchiveBox:
sudo apt-get update
sudo apt-get install python3-pip
pip3 install archivebox
Зависимости можно доустановить вручную, но для первого знакомства проще взять готовый скрипт, который накатит их все, а потом уже решить, какие из них необходимы:
curl https://raw.githubusercontent.com/pirate/ArchiveBox/master/bin/setup.sh | sh
Альтернатива:
sudo apt install -y git wget curl youtube-dl nodejs npm ripgrep chromium-browser
npm i -g npm
pip3 install --upgrade pip setuptools
npm install -g 'git+https://github.com/ArchiveBox/ArchiveBox.git'
Для инициализации нужна пустая директория в любом месте:
mkdir box && cd box
archivebox init
Готово. Теперь можно продолжить работу в терминале, но проще работать в веб-интерфейсе:
archivebox server --createsuperuser 0.0.0.0:8000
# адрес и порты, конечно, можно заменить на произвольные
Флаг --createsuperuser позволит создать админа до старта сервера. Логинимся в дашборд и добавляем первый сайт:

На скриншоте выбраны все возможные методы архивирования (синее выделение)
В это время в терминале:
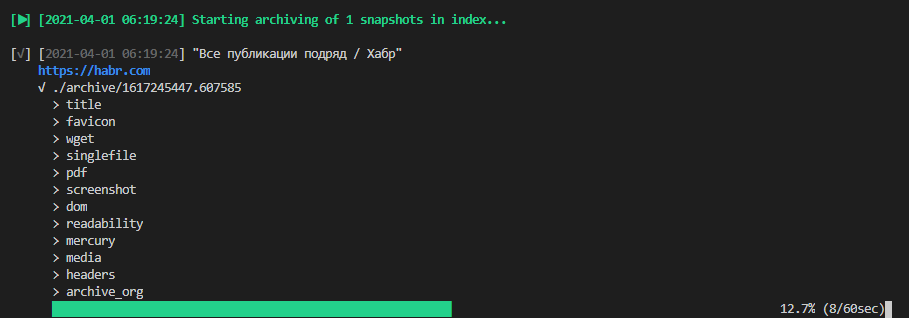
По окончании процесса станет доступен снапшот, который можно посмотреть превьюхой для каждого из визуальных методов, открыть отдельно или изучить список скачанных файлов:
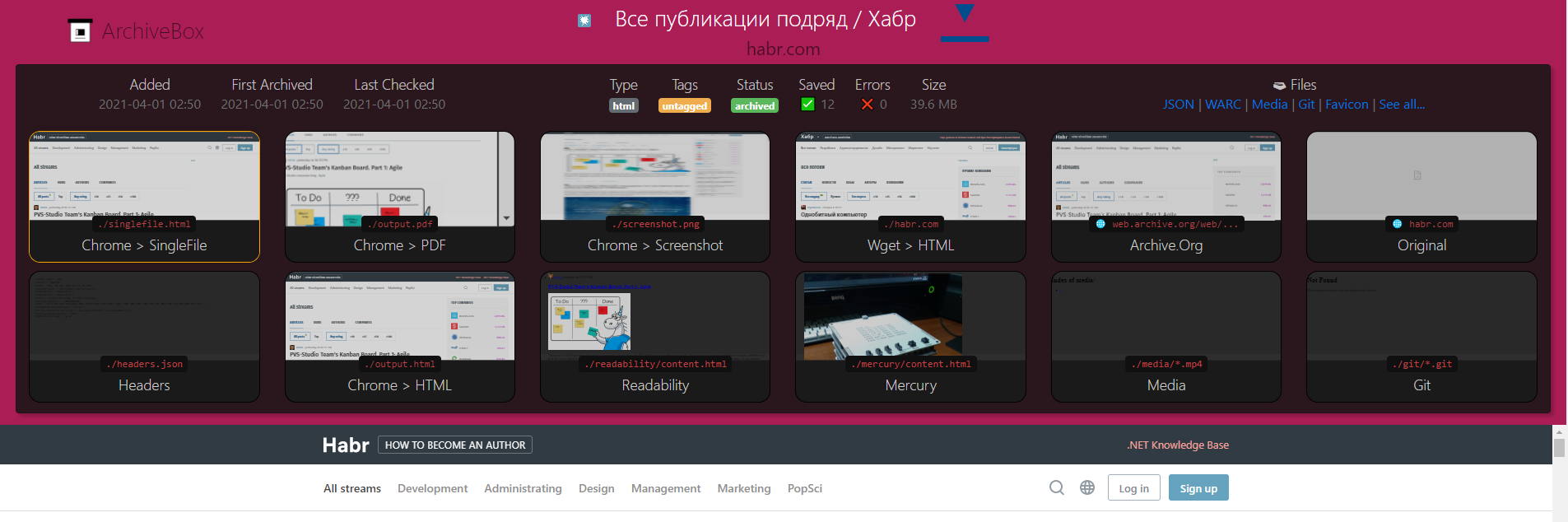
Заключение
Разбираться во всех функциях и возможностях ArchiveBox придётся долго, но учитывая готовые и будущие интеграции с API, можно уже бежать его изучать, потому что применять его можно будет почти из любой инфраструктуры. Очень приятно, что проект активно развивается и уже в достаточной мере оброс сообществом, чтобы разработка и багфиксы не прекращались даже на неделю. Учитывая как далеко он ушел от своих конкурентов, при большей ориентированности на рядового пользователя ArchiveBox может стать очень успешным и полезным приложением.
На правах рекламы
Создание VDS с нужными вам параметрами в течение минуты, в том числе для создания и хранения архивов большого объёма — до 4000 ГБ!

nidalee
Как бы к этому добру еще прокси прикрутить, чтобы побаненные в РФ сайты архивировать?..
А то я смотрю там и chrome, и wget, и curl, и youtube-dl… Видимо, только VPN или изначально дедик за бугром. А с ним можно получать разворот от самого сайта, мол, не нужен нам тут ваш дедик.
Эх, нет в жизни счастья.
UP: ага, нашел: можно ставить через докер и прикрутить прокси уже к нему.