
Все, кто имеют дело с разработкой UI в кровавом enterprise наверняка слышали о «типизированном JavaScript», подразумевая под этим «TypeScript от Microsoft». Но кроме этого решения существует как минимум ещё одна распространённая система типизации JS, и тоже от крупного игрока IT-мира. Это flow от Facebook. Из-за личной нелюбви к Microsoft раньше всегда использовал именно flow. Объективно это объяснял хорошей интеграцией с существующими утилитами и простотой перехода.
К сожалению, надо признать, что в 2021 году flow уже значительно проигрывает TypeScript как в популярности, так и в поддержке со стороны самых разных утилит (и библиотек), и пора бы егозакопать поставить на полку, и перестать жевать кактус перейти на де-факто стандарт TypeScript. Но под этим хочется на последок сравнить эти технологии, сказать пару (или не пару) прощальных слов flow от Facebook.
JavaScript это замечательный язык. Нет, не так. Экосистема, построенная вокруг языка JavaScript — замечательная. На 2021 год она реально восхищает тем, что вы можете использовать самые современные возможности языка, а потом изменением одной настройки системы сборки транспилировать исполняемый файл для того, чтобы поддержать его выполнение в старых версиях браузеров, в том числе в IE8, не к ночи он будет помянут. Вы можете «писать на HTML» (имеется ввиду JSX), а потом с помощью утилиты
Чем хорош JavaScript как скриптовый язык, исполняемый в вашем браузере?
Как и почти в любом скриптовом (интерпретируемом) языке в JavaScript можно… писать неработающий код. Если до этого кода не доберётся браузер, то не будет ни сообщения об ошибке, ни предупреждения, вообще ничего. С одной стороны это хорошо. Если у вас есть большой-большой веб-сайт, то даже синтаксическая ошибка в коде обработчика нажатия кнопки не должна приводить к тому, что сайт не загружается у пользователя целком.
Но и, разумеется, это плохо. Потому что сам факт наличия чего-нибудь неработающего где-нибудь на сайте это плохо. И было бы здорово до того, как код попадёт на работающий сайт, проверить все-все скрипты на сайте и убедиться, что они хотя бы компилируются. А в идеале — и работают. Для этого используются самые разные наборы утилит (мой любимый набор — npm + webpack + babel/tsc + karma + jsdom + mocha + chai).
Если мы живём в идеальном мире, то все-все скрипты на вашем сайте, даже однострочные, покрыты тестами. Но, к сожалению, мир не идеален, и для всей той части кода, что не покрыта тестами, мы можем только понадеяться на какие-нибудь автоматизированные средства проверки. Которые могут проверить:
Кроме ошибок семантики могут быть ещё более страшные ошибки: логические. Когда программа отрабатывает без ошибок, но результат совсем не тот, что ожидался. Классический со сложением строк и чисел:
Существующие средства статического анализа кода (eslint, например), может попытаться отследить значительное количество потенциальных ошибок, которые программист допускает в своём коде. Например:
Обратите внимание, что все эти правила по сути представляют собой ограничения, которые линтер накладывает на программиста. То есть линтер фактически уменьшает возможности языка JavaScript, чтобы программист допускал меньше потенциальных ошибок. Если включить все-все правила, то будет нельзя делать присваивания в условиях (хотя JavaScript это изначально разрешает), использовать дубликаты ключей в литералах объектов и даже нельзя будет вызывать
Добавление типов переменных и проверка вызовов с учётом типов — это дополнительные ограничения языка JavaScript, чтобы уменьшить количество потенциальных ошибок.

Попытка умножить число на строку

Попытка обратиться к несуществующему (неописанному в типе) свойству объекта

Попытка вызвать функцию с несовпадающим типом аргумента
Если мы напишем этот код без средств проверки типов, то код упешно траспилируется. Никакие средства статического анализа кода, если они не используют (явно или неявно) информацию о типах объктов, не смогут эти ошибки найти.
То есть добавление типизации в JavaScript добавляет дополнительные ограничения на код, который пишет программист, но зато позволяет найти такие ошибки, которые в противном случае случились бы во время выполнения скрипта (то есть скорее всего у пользователя в браузере).
Оба «движка» для поддержки типов в JavaScript обладают примерно одинаковыми возможностями. Однако если вы пришли из языков со сторогой типизацией, даже в типизированном JavaScript есть очень важное отличие от той же Java: все типы по сути описывают интерфейсы, то есть список свойств (и их типы и/или аргументы). И если два интерфейса описывают одинаковые (или совместимые) свойства, то их можно использовать вместо друг-друга. То есть следующий код корректен в типизированным JavaScript, но явно некорректен в Java, или, скажем, C++:
Данный код является корректным с точки зрения типизированного JavaScript, так как интерфейс MyTypeB требует наличие свойства
Данный код можно переписать чуть короче, используя литеральный интерфейс для переменной
Тип переменной
Подобное поведение значительно уменьшает количество проблем при работе с разными библиотеками, пользовательским кодом и даже просто с вызовом функций. Типичный пример, когда некоторая библиотека определяет допустимые опции, а мы передаём их в виде объекта options:
Обратите внимание, что тип
Ни TypeScript от Microsoft, ни flow от Facebook не поддерживаются браузерами. Как впрочем и самые новые расширения языка JavaScript пока не нашли поддержки в некоторых браузерах. Так как же этот код, во-первых, проверяется на корректность, а во-вторых, как он исполняется браузером?
Ответ — траспилирование. Весь «нестандартный» JavaScript код проходит через набор утилит, которые превращают «нестандартный» (неизвестный браузерам) код в набор инструкций, который браузеры понимают. Причём для типизации всё «превращение» заключается в том, что все уточнения типов, все описания интерфейсов, все ограничения из кода просто удаляются. Например, код из примера выше превращается в…
т.е.
Такое преобразование обычно делается одним из следующих способов.
Примеры настроек проекта под flow и под TypeScript (с использованием tsc).
Разница между подходами babel+strip и tsc с точки зрения сборки небольшая. В первом случае используется babel, во-втором будет tsc.

Но есть разница, если используется такая утилита как eslint. У TypeScript для линтинга с помощью eslint есть свой набор плагинов, которые позволяют найти ещё больше ошибок. Но они требуют, чтобы в момент анализа линтером у него была информация о типах переменных. Для этого в качестве парсера кода необходимо использовать только tsc, а не babel. Но если для линтера используется tsc, то использовать для сборки babel будет уже неправильно (зоопарк используемых утилит должен быть минимальным!).


Когда библиотека публикуется в npm-репозитории, публикуется именно JavaScript-версия. Предполагается, что опубликованный код не нужно подвергать дополнительным преобразованиям, чтобы использовать его в проекте. То есть код уже прошёл необходимую траспиляцию через babel или tsc. Но тогда информация о типах в коде уже, получается, потеряна. Что делать?
Во flow предполагается, что кроме «чистой» JavaScript версии в библиотеке будут лежать файлы с расширением
В TypeScript предлагается держать рядом не исходные файлы а только список определений (definitions). Если есть файл
И для flow, и TypeScript есть способ добавления описаний типов для тех библиотек, которые эти описания не содержат изначально. Но сделано оно по разному.
Для flow «нативного» способа, поддерживаемого самой компанией Facebook не предложено. Но есть проект flow-typed, который собирает в своём репозитории такие определения. Фактически параллельный для npm способ версионирования таких определений, а также не очень удобный «централизованный» способ обновления.
У TypeScript стандартным способом написания таких определений является их публикация в специальных npm-пакетах с префиском "@types". Для того, чтобы добавить себе в проект описание типов для какой-либо библиотеки достаточно подключить соответствующую @types-библиотеку, например
Попытка сравнить flow и TypeScript. Отдельные факты собраны из статьи Nathan Sebhastian «TypeScript VS Flow», часть собрана самостоятельна.
Нативная поддержка в различных фреймофорках. Нативная — без дополнительным подходом с паяльником и сторонними библиотеками и плагинами.
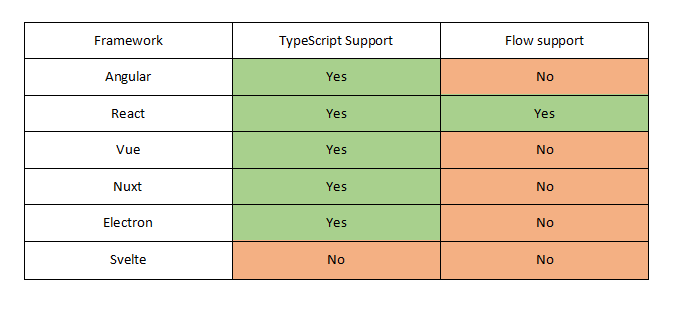
Различные линейки
Смотря на эти цифры у меня просто не остаётся морального права рекомендовать flow к использованию. Но почему же я использовал его сам? Потому что раньше была такая штука, как flow-runtime.
flow-runtime это набор плагинов для babel, который позволяет встроить типы от flow в runtime, использовать их для определения типов переменных в runtime, и, самое главное для меня, позволяло проверять типы переменных в runtime. Что позволяло в runtime во время, например, автотестов или ручного тестирования отловить дополнительные баги в приложении.
То есть прямо во время выполнения (в debug-сборке, разумеется), приложение явно проверяло все-все типы переменных, аргументов, результаты вызова сторонних функций, и всё-всё-всё, на соответствие тех типов.
К сожалению, под новый 2021 год автор репозитория добавил информацию о том, что он перестаёт заниматься развитием данного проекта и в целом переходит на TypeScript. Фактически последняя причина оставаться на flow для меня стала deprecated. Ну что же, добро пожаловать в TypeScript.
К сожалению, надо признать, что в 2021 году flow уже значительно проигрывает TypeScript как в популярности, так и в поддержке со стороны самых разных утилит (и библиотек), и пора бы его
Зачем нужна безопасность типов в JavaScript?
JavaScript это замечательный язык. Нет, не так. Экосистема, построенная вокруг языка JavaScript — замечательная. На 2021 год она реально восхищает тем, что вы можете использовать самые современные возможности языка, а потом изменением одной настройки системы сборки транспилировать исполняемый файл для того, чтобы поддержать его выполнение в старых версиях браузеров, в том числе в IE8, не к ночи он будет помянут. Вы можете «писать на HTML» (имеется ввиду JSX), а потом с помощью утилиты
babel (или tsc) заменить все теги на корректные JavaScript-конструкции вроде вызова библиотеки React (или любой другой, но об этом в другом посте).Чем хорош JavaScript как скриптовый язык, исполняемый в вашем браузере?
- JavaScript не нужно «компилировать». Вы просто добавляете конструкции JavaScript и браузер обязан их понимать. Это сразу даёт кучу удобных и почти бесплатных вещей. Например, отладку прямо в браузере, за работоспособность которой отвечает не программист (который должен не забыть, например, включить кучу отладочных опций компилятора и соответствующие библиотеки), а разработчик браузера. Вам не нужно ждать по 10-30 минут (реальный срок для C/C++), пока ваш проект на 10к строк скомпилируется, чтобы попробовать написать что-то по другому. Вы просто меняете строку, перезагружаете страницу браузера и наблюдаете за новым поведением кода. А в случает использования, например, webpack, страницу еще и за вас перезагрузят. Многие браузеры позволяют менять код прямо внутри страницы с помощью своих devtools.
- Это кросс-платформенный код. В 2021 году уже почти можно забыть о разном поведении разных браузеров. Вы пишете код под Chrome/Firefox, заранее запланировав, например, от 5% (enterprise-код) до 30% (UI/мультимедиа) своего времени, чтобы потом подрихтовать результат под разные браузеры.
- В языке JavaScript почти не нужно думать о многопоточности, синхронизации и прочих страшных словах. Вам не нужно думать о блокировках потоков — потому что у вас один поток (не считая worker'ов). До тех пор, пока ваш код не будет требовать 100% CPU (если вы пишете UI для корпоритавного приложения), то вполне достаточно знать, что код исполняется в одном единственном потоке, а асинхронные вызовы успешно оркестрируются с помощью Promise/async/await/etc.
- При этом даже не рассматриваю вопрос, почему JavaScript важен. Ведь с помощью JS можно: валидировать формы, обновлять содержимое страницы без перезагрузки её целиком, добавлять нестандартные эффекты поведения, работать с аудио и видео, да можно вообще целиком клиент своего enterprise-приложения написать на JavaScript.
Как и почти в любом скриптовом (интерпретируемом) языке в JavaScript можно… писать неработающий код. Если до этого кода не доберётся браузер, то не будет ни сообщения об ошибке, ни предупреждения, вообще ничего. С одной стороны это хорошо. Если у вас есть большой-большой веб-сайт, то даже синтаксическая ошибка в коде обработчика нажатия кнопки не должна приводить к тому, что сайт не загружается у пользователя целком.
Но и, разумеется, это плохо. Потому что сам факт наличия чего-нибудь неработающего где-нибудь на сайте это плохо. И было бы здорово до того, как код попадёт на работающий сайт, проверить все-все скрипты на сайте и убедиться, что они хотя бы компилируются. А в идеале — и работают. Для этого используются самые разные наборы утилит (мой любимый набор — npm + webpack + babel/tsc + karma + jsdom + mocha + chai).
Если мы живём в идеальном мире, то все-все скрипты на вашем сайте, даже однострочные, покрыты тестами. Но, к сожалению, мир не идеален, и для всей той части кода, что не покрыта тестами, мы можем только понадеяться на какие-нибудь автоматизированные средства проверки. Которые могут проверить:
- Что вы корректно используете синтаксис языка JavaScript. Проверяется, что набранный вами текст может быть понят интерпретатором языка JavaScript, что вы не забыли закрыть открытую фигурную скобку, что строковые лексемы корректно ограничены кавычками и прочее, и прочее. Эту проверку выполняют почти все утилиты сборки/траспилирования/сжатия/обфускации кода.
- Что семантика языка используется корректно. Можно попытаться проверить, что те инструкции, которые записаны в написанном вами скрипте могут быть корректно поняты интерпретатором. Например, пусть есть следующий код:
var x = null; x.foo();
Данный код является корректным с точки зрения синтаксиса языка. Но с точки зрения семантики он некорректен — попытка вызова метода у null вызовет сообщение об ошибке во время выполнения программы.
Кроме ошибок семантики могут быть ещё более страшные ошибки: логические. Когда программа отрабатывает без ошибок, но результат совсем не тот, что ожидался. Классический со сложением строк и чисел:
console.log( input.value ) // 1
console.log( input.value + 1 ) // 11
Существующие средства статического анализа кода (eslint, например), может попытаться отследить значительное количество потенциальных ошибок, которые программист допускает в своём коде. Например:
- Запрет на бесконечный цикл for с некорректным условием окончания цикла
- Запрет на использование async-функций в качестве аргумента конструктора Promise
- Запрет на присваивания в условиях
- и другие
Обратите внимание, что все эти правила по сути представляют собой ограничения, которые линтер накладывает на программиста. То есть линтер фактически уменьшает возможности языка JavaScript, чтобы программист допускал меньше потенциальных ошибок. Если включить все-все правила, то будет нельзя делать присваивания в условиях (хотя JavaScript это изначально разрешает), использовать дубликаты ключей в литералах объектов и даже нельзя будет вызывать
console.log().Добавление типов переменных и проверка вызовов с учётом типов — это дополнительные ограничения языка JavaScript, чтобы уменьшить количество потенциальных ошибок.
Попытка умножить число на строку
Попытка обратиться к несуществующему (неописанному в типе) свойству объекта
Попытка вызвать функцию с несовпадающим типом аргумента
Если мы напишем этот код без средств проверки типов, то код упешно траспилируется. Никакие средства статического анализа кода, если они не используют (явно или неявно) информацию о типах объктов, не смогут эти ошибки найти.
То есть добавление типизации в JavaScript добавляет дополнительные ограничения на код, который пишет программист, но зато позволяет найти такие ошибки, которые в противном случае случились бы во время выполнения скрипта (то есть скорее всего у пользователя в браузере).
Возможности типизации JavaScript
| Flow | TypeScript | |
|---|---|---|
| Возможность задать тип переменной, аргумента или тип возвращаемого значения функции | |
|
| Возможность описать свой тип объекта (интерфейс) | |
|
| Ограничение допустимых значений для типа | |
|
| Отдельный type-level extension для перечислений | |
|
| «Сложение» типов | |
|
| Дополнительные «типы» для сложных случаев | |
|
Оба «движка» для поддержки типов в JavaScript обладают примерно одинаковыми возможностями. Однако если вы пришли из языков со сторогой типизацией, даже в типизированном JavaScript есть очень важное отличие от той же Java: все типы по сути описывают интерфейсы, то есть список свойств (и их типы и/или аргументы). И если два интерфейса описывают одинаковые (или совместимые) свойства, то их можно использовать вместо друг-друга. То есть следующий код корректен в типизированным JavaScript, но явно некорректен в Java, или, скажем, C++:
type MyTypeA = { foo: string; bar: number; }
type MyTypeB = { foo: string; }
function myFunction( arg : MyTypeB ) : string {
return `Hello, ${arg.foo}!`;
}
const myVar : MyTypeA = { foo: "World", bar: 42 } as MyTypeA;
console.log( myFunction( myVar ) ); // "Hello, World!"
Данный код является корректным с точки зрения типизированного JavaScript, так как интерфейс MyTypeB требует наличие свойства
foo с типом string, а у переменной с интерфейсом MyTypeA такое свойство есть.Данный код можно переписать чуть короче, используя литеральный интерфейс для переменной
myVar.type MyTypeB = { foo: string; }
function myFunction( arg : MyTypeB ) : string {
return `Hello, ${arg.foo}!`;
}
const myVar = { foo: "World", bar: 42 };
console.log( myFunction( myVar ) ); // "Hello, World!"
Тип переменной
myVar в данном примере это литеральный интерфейс { foo: string, bar: number }. Он по прежнему совместим с ожидаемым интерфейсом аргумента arg функции myFunction, поэтому данный код не содержит ошибок с точки зрения, например, TypeScript.Подобное поведение значительно уменьшает количество проблем при работе с разными библиотеками, пользовательским кодом и даже просто с вызовом функций. Типичный пример, когда некоторая библиотека определяет допустимые опции, а мы передаём их в виде объекта options:
// Где-то внутри библиотеки
interface OptionsType {
optionA?: string;
optionB?: number;
}
export function libFunction( arg: number, options = {} as OptionsType) { /*...*/ }
// В пользовательском коде
import {libFunction} from "lib";
libFunction( 42, { optionA: "someValue" } );
Обратите внимание, что тип
OptionsType не экспортирован из библиотеки (и не импортирован в пользовательский код). Но это не мешает вызывать функцию с использованием литерального интерфейса для второго аргумента options функции, а для системы типизации — проверить этот аргумент на совместимость типов. Попытка сделать что-то подобное в Java вызовет у компилятора явное непонимание.Как это работает с точки зрения браузера?
Ни TypeScript от Microsoft, ни flow от Facebook не поддерживаются браузерами. Как впрочем и самые новые расширения языка JavaScript пока не нашли поддержки в некоторых браузерах. Так как же этот код, во-первых, проверяется на корректность, а во-вторых, как он исполняется браузером?
Ответ — траспилирование. Весь «нестандартный» JavaScript код проходит через набор утилит, которые превращают «нестандартный» (неизвестный браузерам) код в набор инструкций, который браузеры понимают. Причём для типизации всё «превращение» заключается в том, что все уточнения типов, все описания интерфейсов, все ограничения из кода просто удаляются. Например, код из примера выше превращается в…
/* удалено: type MyTypeA = { foo: string; bar: number; } */
/* удалено: type MyTypeB = { foo: string; } */
function myFunction( arg /* удалено: : MyTypeB */ ) /* удалено: : string */ {
return `Hello, ${arg.foo}!`;
}
const myVar /* удалено: : MyTypeA */ = { foo: "World", bar: 42 } /* удалено: as MyTypeA */;
console.log( myFunction( myVar ) ); // "Hello, World!"
т.е.
function myFunction( arg ) {
return `Hello, ${arg.foo}!`;
}
const myVar = { foo: "World", bar: 42 };
console.log( myFunction( myVar ) ); // "Hello, World!"
Такое преобразование обычно делается одним из следующих способов.
- Для удаления информации о типах от flow используется плагин для babel: @babel/plugin-transform-flow-strip-types
- Для работы с TypeScript можно использовать одно из двух решений. Во-первых можно использовать babel и плагин @babel/plugin-transform-typescript
- Во-вторых вместо babel можно использовать собственный транспилер от Microsoft под названием tsc. Эта утилита встраивается в процесс сборки приложения вместо babel.
Примеры настроек проекта под flow и под TypeScript (с использованием tsc).
| Flow | TypeScript |
|---|---|
| webpack.config.js | |
|
|
| Настройки транспилера | |
| babel.config.js | tsconfig.json |
|
|
| .flowconfig | |
|
|
Разница между подходами babel+strip и tsc с точки зрения сборки небольшая. В первом случае используется babel, во-втором будет tsc.
Но есть разница, если используется такая утилита как eslint. У TypeScript для линтинга с помощью eslint есть свой набор плагинов, которые позволяют найти ещё больше ошибок. Но они требуют, чтобы в момент анализа линтером у него была информация о типах переменных. Для этого в качестве парсера кода необходимо использовать только tsc, а не babel. Но если для линтера используется tsc, то использовать для сборки babel будет уже неправильно (зоопарк используемых утилит должен быть минимальным!).
| Flow | TypeScript |
|---|---|
| .eslint.js | |
|
|
Типы для библиотек
Когда библиотека публикуется в npm-репозитории, публикуется именно JavaScript-версия. Предполагается, что опубликованный код не нужно подвергать дополнительным преобразованиям, чтобы использовать его в проекте. То есть код уже прошёл необходимую траспиляцию через babel или tsc. Но тогда информация о типах в коде уже, получается, потеряна. Что делать?
Во flow предполагается, что кроме «чистой» JavaScript версии в библиотеке будут лежать файлы с расширением
.js.flow, содержащие исходный flow-код со всеми определениями типов. Тогда при анализе flow сможет подключить эти файлы для проверки типов, а при сборке проекта и его выполнения они будут игнорироваться — будут использованы обычные JS-файлы. Добавлять .flow-файлы в библиотеку можно простым копированием. Правда это значительно увеличит размер библиотеки в npm.В TypeScript предлагается держать рядом не исходные файлы а только список определений (definitions). Если есть файл
myModule.js, то при анализе проекта TypeScript будет искать рядом файл myModule.js.d.ts, в котором ожидает увидеть определения (но не код!) всех типов, функций и прочего, что нужно для анализа типов. Создавать такие файлы из исходного TypeScript траспилер tsc умеет самостоятельно (см. опцию declaration в документации).Типы для legacy-библиотек
И для flow, и TypeScript есть способ добавления описаний типов для тех библиотек, которые эти описания не содержат изначально. Но сделано оно по разному.
Для flow «нативного» способа, поддерживаемого самой компанией Facebook не предложено. Но есть проект flow-typed, который собирает в своём репозитории такие определения. Фактически параллельный для npm способ версионирования таких определений, а также не очень удобный «централизованный» способ обновления.
У TypeScript стандартным способом написания таких определений является их публикация в специальных npm-пакетах с префиском "@types". Для того, чтобы добавить себе в проект описание типов для какой-либо библиотеки достаточно подключить соответствующую @types-библиотеку, например
@types/react для React или @types/chai для chai.Сравнение flow и TypeScript
Попытка сравнить flow и TypeScript. Отдельные факты собраны из статьи Nathan Sebhastian «TypeScript VS Flow», часть собрана самостоятельна.
Нативная поддержка в различных фреймофорках. Нативная — без дополнительным подходом с паяльником и сторонними библиотеками и плагинами.
Различные линейки
| Flow | TypeScript | |
|---|---|---|
| Основной contributor | Microsoft | |
| Сайт | flow.org | www.typescriptlang.org |
| GitHub | github.com/facebook/flow | github.com/microsoft/TypeScript |
| GitHub Starts | 21.3k | 70.1k |
| GitHub Forks | 1.8k | 9.2k |
| GitHub Issues: open/closed | 2.4k / 4.1k | 4.9k / 25.0k |
| StackOverflow Active | 2289 | 146 221 |
| StackOverflow Frequent | 123 | 11 451 |
Смотря на эти цифры у меня просто не остаётся морального права рекомендовать flow к использованию. Но почему же я использовал его сам? Потому что раньше была такая штука, как flow-runtime.
flow-runtime
flow-runtime это набор плагинов для babel, который позволяет встроить типы от flow в runtime, использовать их для определения типов переменных в runtime, и, самое главное для меня, позволяло проверять типы переменных в runtime. Что позволяло в runtime во время, например, автотестов или ручного тестирования отловить дополнительные баги в приложении.
То есть прямо во время выполнения (в debug-сборке, разумеется), приложение явно проверяло все-все типы переменных, аргументов, результаты вызова сторонних функций, и всё-всё-всё, на соответствие тех типов.
К сожалению, под новый 2021 год автор репозитория добавил информацию о том, что он перестаёт заниматься развитием данного проекта и в целом переходит на TypeScript. Фактически последняя причина оставаться на flow для меня стала deprecated. Ну что же, добро пожаловать в TypeScript.
sovaz1997
Тем не менее, Typescript не является "серебряной пулей" и на самом деле даёт иллюзию типо-безопасности. При этом, конечно, плюсов у него много.
JustDont
Вы сами вольны определить, будет ли у вас типобезопасность, или её иллюзия.
sovaz1997
Это так не работает) Чтобы гарантировать что-то, надо в любом случае в рантайме проверять
JustDont
Это работает именно так. "Иллюзия" начинается ровно там, где вы её намеренно создали.
Или вы про то, что TS в рантайме нет? Это не имеет ни малейшего отношения ни к типобезопасности кода TS, ни к её отсутствию.
pavelrevers
И все же иллюзия. И, часто, мы никак не можем это контролировать
Простейший пример «type predicate» www.typescriptlang.org/docs/handbook/2/narrowing.html#using-type-predicates. Его невозможно сделать типобезопасным
И таких примеров в TS много(
nin-jin
А что там небезопасного в «type predicate»?
JustDont
Вероятно имеется в виду, что можно намеренно или нечаянно наврать в коде проверки типов и получить в итоге поломку.
Что, однако, не имеет никакого отношения к типобезопасности.
amakhrov
Это практически из той же оперы, что и type assertion.
И в том, и в том случае программист говорит компилятору, что программисту лучше знать, какой там будет тип.