
Мы подготовили для вас его текстовую версию, для удобства разбив её на смысловые блоки.
- 0 (вводная часть). Зачем мы здесь собрались. Краткая история GPGPU.
- 1. Пишем для OpenCL.
- 2. Алгоритмы в условиях массового параллелизма.
- 3. Сравнение технологий.
Основная цель цикла — написать простую, но полноценную программу на OpenCL и объяснить базовые понятия. Программу на OpenCL напишем уже в следующей части цикла, понять которую можно, не читая вводную. Однако во вводной вы найдёте понятия и тезисы, важные при программировании с OpenCL.
Цикл будет полезен и тем, кто уже знаком с OpenCL: в нём мы поделимся некоторыми хаками и неочевидными наблюдениями из собственного опыта.
CPU — в помойку?
В статье будем рассматривать технологию GPGPU. Разберёмся, что значат все эти буквы. Начнем с последних трёх — GPU. Все знают аббревиатуру CPU — Central Processor Unit, или центральный процессор. А GPU — Graphic Processor Unit. Это графический процессор. Он предназначен для решения графических задач.
Но перед GPU есть ещё буквы GP. Они расшифровываются как General-Purpose. В аббревиатуре опускают словосочетание Computing on. Если собрать всё вместе, получится General-Purpose Computing on Graphic Processor Unit, что по-русски — вычисления общего назначения на графическом процессоре.
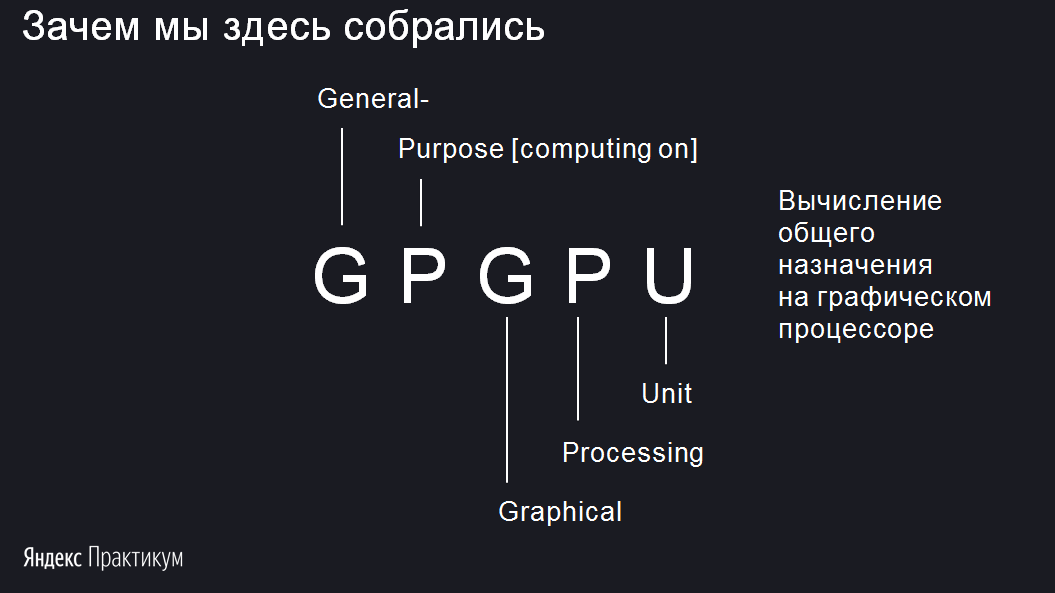
То есть процессор графический, но мы почему-то хотим вычислять на нём что-то, что вообще к графике никакого отношения не имеет. Например, прогноз погоды, майнинг биткоинов. Моя задача в ближайшее время — объяснить, зачем нужно на процессоре для графики обучать, например, нейросети.
Самое распространённое место, где можно обнаружить GPU, — ваша родная видеокарта. Всем известно, что если вставить в неё штекер монитора, появится картинка. На самом деле видеокарта — это не только гнездо для монитора, но и полноценное вычислительное устройство.
Давайте немного отвлечёмся от видеокарты и вернёмся в 2000 год, когда процессоры CPU набирали всё больше и больше мегагерц. Компания Intel тогда прогнозировала, что к 2010 году тактовая частота одного ядра процессора достигнет 10 гигагерц. Сейчас мы знаем, что эти ожидания не сбылись.

По графику видно: рост действительно был очень хороший, но где-то в районе 2004–2005 года он резко остановился. И дальше процессоры стали даже немножко терять в мощности. Развитие центральных процессоров в итоге пошло за счёт увеличения количества ядер. Сейчас в мощных компьютерах у CPU может быть 16 ядер. Но тактовая частота ядра за последние 10 лет не росла.
Если посмотреть на другой график, где сравниваются CPU и GPU, можно увидеть, что процессоры в видеокартах эту тенденцию перехватили. Графический процессор продолжил наращивать мощность и во многом опередил центральные процессоры по производительности. Удивительный факт — процессор, который находится в видеокарте, выполняет гораздо больше операций с плавающей точкой в секунду, чем главный, центральный процессор.

Источник. По вертикали GFLOPS, т. е. миллиарды арифметических операций с плавающей точкой в секунду
Остаётся вопрос: в чём GPU уступают CPU? Может, дело не в процессоре, а в памяти? Для сравнения возьмём современную оперативную память DDR4 и графическую память GDDR5. Но и тут оказывается, что графический контроллер во много раз превосходит обычный CPU: доступ к графической памяти у GPU гораздо быстрее — 400 Гб/сек против 35 Гб/сек.
И ещё сравним какой-нибудь современный процессор и не очень современную видеокарту. Например, GeForce GTX 1080 Ti, которую сейчас можно купить только на Авито, и довольно современный процессор Core i9 с хорошей памятью.

Получается, видеокарта обгоняет процессор… И если Core i9 может сделать 460 миллиардов арифметических операций с плавающей точкой в секунду, то GTX1080Ti уже 11 триллионов. В общем, GTX намного превосходит Core i9 и по производительности, и по скорости доступа к памяти.
Когда я увидел это сравнение, у меня возник вопрос: а может, этот медленный CPU вообще не нужен? Что если выбросить его, оставить только GPU и все задачи решать на графическом адаптере? Ответ такой: GPU, конечно, очень классный, но годится не для любых задач. Если избавиться от CPU, всё будет немножечко лагать. Так делать не надо.
GPU хорош для массового параллелизма, когда одновременно выполняется огромное количество очень похожих вычислений. Но тут есть такие весы. На одной чаше latency — задержка, на другой флопсы — количество операций. Например, если операция длится секунду, это очень долго. Но если вы одновременно можете выполнить 100 миллиардов таких операций, у вас получились 100 миллиардов операций в секунду. Для CPU это довольно плохо, потому что нам нужно, чтобы всё работало последовательно. А для GPU — нормально. Главное — не задержка, а результат. Числа в этом примере, конечно, сильно утрированы, реальный параллелизм GPU — порядка нескольких тысяч.
Массовый параллелизм
Хороший пример задачи массового параллелизма — Ray Tracing, или трассировка лучей. В экране много пикселей, и из каждого пикселя выпускается луч, чтобы получить качественный рендер всей сцены. Эти лучи можно обрабатывать параллельно, независимо вычисляя цвет каждого пикселя экрана. Значит, это задача массового параллелизма. Существует прекрасный сайт, на котором вы можете, не отходя от браузера, попрактиковаться в написании трассировщика лучей, работающего на GPU. Там можно найти немало любопытных примеров.
Майнинг биткоинов. Чтобы намайнить биткоины, нужно вычислить много хешей и найти среди них обладающий определёнными свойствами. И у этой задачи, к сожалению, или к счастью, нет существенно лучшего решения, чем просто вычислять хеши, пока вам наконец не повезёт. Хеши считаются независимо, и это можно делать параллельно. Значит, это задача массового параллелизма. Майнинг прекрасно ложится на видеокарту.
Обучение нейросетей. Основная затратная операция, которая используется в Deep Learning, — свёртка изображений. Это вычислительно сложная операция, ведь для подсчёта одного значения свёртки с ядром 5⨯5 нужно произвести 25 умножений и 24 сложения. Радует одно: все значения можно считать независимо. А значит, это задача массового параллелизма.
Многие учёные используют GPU в своих задачах, потому что научных данных часто бывает очень много, они долго обрабатываются, и графический процессор тут иногда применим. Если вы один из таких учёных, то спешу вас обрадовать: на самом деле в программировании под GPU нет ничего сложного, и в этом цикле статей мы напишем полноценную программу под него.
Тем, кто серьёзно заинтересовался вычислениями на видеокартах, я рекомендую прекрасные лекции Николая Полярного. Там он разбирает эту тему гораздо подробнее, чем я. С его разрешения я взял вот эту картинку, которая хорошо показывает соотношение CPU и GPU.

Здесь приведены усреднённые данные. На блок L1/Local memory пока не смотрите, разберём его чуть позже. Видно, что CPU может иметь производительность в 20 гигафлопс, а GPU — в 5000 гигафлопс. Канал памяти у GPU гораздо выше. Но есть одно узкое местечко — шина PCI-E. Она соединяет RAM и GRAM и пропускает всего 8 Гб. Глядя на эту картинку, попробуйте ответить на вопрос: есть ли смысл решать все задачи массового параллелизма с помощью графического процессора?
Предположим, задача — сложить два массива чисел по 10 миллиардов: первое складываем с первым, второе со вторым и так далее. Нужно получить сумму, третий набор чисел. Поручать ли такую задачу графическому процессору?
Понятно, что это задача массового параллелизма. Но есть один момент. Для того, чтобы эти числа сложить на GPU, их нужно сначала передать на GRAM по узенькому мостику в 8 Гб/сек. Видеокарта посчитает всё очень быстро, это факт. Но потом вам нужно будет эти данные передавать по мостику обратно. И окажется, что гораздо быстрее просто передать по большему каналу в CPU, и он своими жалкими 20 гигафлопсами сложит числа быстрее, чем если бы они ехали по шине в GPU.
Правда, уже есть некоторые решения этой проблемы. Технология NVLink позволяет ускорить передачу данных в видеопамять с 8 до 40 Гб/сек. Более того, у некоторых дешёвых видеокарт нет видеопамяти, и они могут обращаться напрямую к RAM. Но мы не будем затрагивать этот момент.
Краткая история GPGPU
Технология GPGPU появилась не сразу. До этого графический адаптер использовался исключительно по назначению. Но когда люди увидели, какие у GPU мощности, им захотелось использовать эти мощности для своих неграфических задач. Тогда приходилось выкручиваться и как-то маскировать свою неграфическую задачу под графическую. Видеокарта думала, что рисует треугольники, а на самом деле вычисляла и обрабатывала научные данные. К счастью, разработчики видеокарт увидели эту проблему и пошли навстречу. Так появилась OpenCL и другие технологии, о которых я немного расскажу.
До появления OpenCL возникла очень популярная технология, отличающаяся только одной буквой, — OpenGL. Она решала графические задачи, нужные в первую очередь для видеоигр.
Я выделил три этапа развития OpenGL:
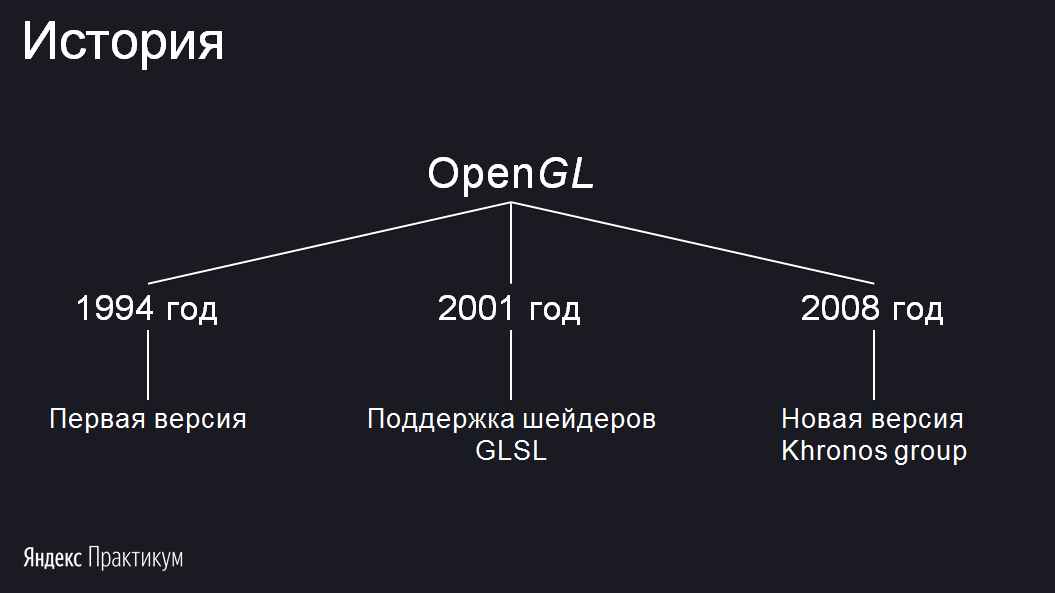
Первая версия появилась в 1994 году. В 2001 году произошло важное событие: стало возможным написание шейдеров на языке GLSL. Если раньше вы могли просить нарисовать треугольники с конкретными параметрами и текстурами, то в 2001 году появилась возможность запускать свой код на видеокарте, то есть самому писать обработчик, который будет вычислять цвет пикселя и его положение. В 2008 году разработка OpenGL перешла консорциуму Khronos Group. Запомните это название, оно вам ещё встретится.
Идея, лежащая в основе OpenGL, состоит в том, что любую геометрическую фигуру можно приблизить треугольниками. Отрисовывать их OpenGL может с огромной скоростью. Если видеоигра, использующая OpenGL, содержит шейдеры, то они будут скомпилированы в момент запуска игры на компьютере пользователя. Код шейдеров будет исполнен непосредственно процессором видеокарты — это и есть та лазейка, которую использовали ранее для неграфических вычислений с OpenGL.
Назвать OpenGL современной технологией уже нельзя. Ей на смену пришли Vulkan и Metal. И если OpenGL направлена на графику, то Vulkan и Metal более универсальны. Останавливаться на них не будем.

Как я уже сказал, если вам нужна графика, то можно либо замаскировать задачу под графическую, либо использовать специальную технологию, предназначенную для решения неграфических задач на видеокартах. Для этого есть две основных технологии — OpenCL, виновница сегодняшнего торжества, и её конкурент CUDA.

Главное их отличие друг от друга — в том, что CUDA поддерживает только видеокарты NVIDIA. Никакие другие адаптеры запустить CUDA-код не смогут. С другой стороны, в этом есть плюсы. Вы знаете, на каких видеокартах код будет запускаться, поэтому под них можно его хорошо отладить и предварительно скомпилировать.
У карт NVIDIA есть несколько версий API, и вы решаете, под какую версию API из доступных скомпилировать код CUDA. Если выбрать какую-то одну, код на более старых видеокартах не пойдёт, а на более новых не будет супероптимальным. Поэтому лучше компилировать сразу под несколько версий.
В OpenCL возможности предкомпиляции нет, потому что вы не знаете, на каком устройстве код будет запускаться. Исключения, конечно, бывают. Например, вы заключили договор с клиентом, и он говорит, что программа будет запускаться на такой-то видеокарте. Тогда вы можете скомпилировать под неё и отправлять заказчику только собранный OpenCL-код. Но для конечного пользователя так лучше не делать.
Обе эти технологии ушли или уходят с macOS, на ней остаётся Metal. Но что я хочу сказать: видеокарта одна, и бэкенд, на котором всё будет выполняться, один. А значит, любые технологии похожи между собой.
В следующей части мы разберём основные понятия, которые необходимо знать, чтобы написать программу с использованием OpenCL.
Комментарии (29)

Myclass
31.08.2021 15:52+1Если избавиться от CPU, всё будет немножечко лагать. Так делать не надо.
Извиняюсь, но так инженеры не выражаются. Это первое. Второе. Я рассказываю своим студентам тоже разницу между CPU и GPU. Так вот. Если провести параллель, то CPU это пассажирский самолёт, а GPU — истребитель. Можно их сравнивать? Ну для детского воображения — да. Но не взаимоисключающе, а как для своих нужд хорошо отлаженные инструменты.
Не вдаюсь в детали, но сравнение неуместно. Потому что вроде идёт разговор о замещении одного другим, но список задач сводится к шейдерам. Но организация компьютера — это не треугольники и шейдеры. Это намного больше. И CPU занимается своим делом, а GPU и видеокарта — своим. И почему-то уверен, что так и останется ещё долгое время. Архитектура Von-Neumann уже не одно десятилетие пережило. Конечно оба можно в одно интегрировать, но сказать, что одно можно заменить другим — не является истинной. В таких вещах разделение задач только на пользу.
xjossy Автор
31.08.2021 19:43+3Спасибо за замечание! Одна из основных идей этой вводной статьи - показать, что сравнение действительно некорректно. Несмотря на то, что по измеримым характеристикам (флопсы) GPU во много раз превосходит CPU, последний нельзя заменить на первый. Причина - их действительно не во всех случаях можно сравнивать.
Но если задача действительно допускает массовый параллелизм, хорошо ложится на видеокарту, правильно реализована на ней, то тогда сравнение обретает смысл: соотношение времени её работы на CPU и GPU получится примерно такое как теоретическое отношение производительности этих устройств.

nikolay_karelin
01.09.2021 21:52+1Прошу прощения, но технологии GPGPU уже больше 10 лет. И, насколько, я знаю, все современные суперкомпьютеры построены с использованием видеокарт. Просто это оказался самый дешевый вариант массивно-параллельных вычислений.

TakashiNord
31.08.2021 17:28+1нашел стандартную задачу на собеседование или тест
Обработка данных:
Исходные данные: последовательность из 1 миллиона чисел (int, от 1 до 100) (14, 45, 77, 1, ...) Сжать данные, чтобы они занимали как можно меньше места Разжать данные в оригинальную последовательностьУсловия:
Должна быть многопоточность Вычисления должны делаться на GPUMyclass
31.08.2021 19:04+2А можете поделится идеями, как такое задание решается. Спасибо заранее.

Balling
31.08.2021 20:53-4CUDA.
Myclass
31.08.2021 22:40+2Я просто хотел принцип услышать, а не то, что в каком-то языке для этого функция есть. Примеры с сортировком в том и заключаются, что человек понимает суть команды, неважно в c# или в Javе, потому что известно, что за команой .Sort стоит например Quick Sort алгоритм. Но всё равно — спасибо. Попробую посмотреть в этом направлении. Может быть что-нибудь найду интересное.
quwy
31.08.2021 22:42+2<sarcasm_mode>
Заменяем int на byte и сходу получаем трехкратное "сжатие". А если немного поколдовать над битами, то потом еще на 12.5% можно ужать.
</sarcasm_mode>

le2
31.08.2021 20:07-21. GPU не является Машиной Тьюринга. Не может посчитать, к примеру, экспоненциальную функцию — сигмоиду, соответственно инференс только на GPU в общем случае невозможен. После GPU все равно досчитывает CPU.
2. Память GPU, конечно, быстрая, только данные туда в начале должны попасть. Накладные расходы на передачу из RAM в GPU-RAM, а потом еще обратно! приводят к тому что внезапно самый быстрый практический инференс на легких нейронках получается на CPU с векторными расширениями (NEON, AVX).
3. В моих домашних применениях наличие 2080TI никак не ускоряет видеомонтаж, потому что CPU в 48 аппаратных потоков делает это быстрее.
Итого, я не говорю что GPU это плохо. Просто практическое применение несколько отрезвляет.Balling
31.08.2021 20:32+2>CPU в 48 аппаратных потоков делает это быстрее
2080 Ti может не только 1 поток сжимать, но и не только два. А еще она может сжимать lossless hevc. А еще там есть поддержка NVFBC, которая дает 0.5% CPU при захвате экрана. А и ещё b-frames each и middle.
А и ваша любимая x264 поддерживает opencl.
Myclass
01.09.2021 00:33Просто практическое применение несколько отрезвляет
ну вот — опять всё портите :) А такой масштаб для маркетинга имеет место быть! Не всем-же обязательно знать, что в их вычислительном процессе где-нибудь будет узкое место (bottleneck) — продаваться ведь может в общем на ура. А потом и на поиски этого «узкого места» можно и новые проекты поставить на ноги и доп. буджет освоить итд.
Такой радикальный подхот замечаю при внедрении новых систем, где необдуманно за основу берётся какая-нибудь функция, которую старая система вроде хуже делала, но при этом полностью или частично пренебрегаются и другие, немаловажные функции. И когда система запускается, начинается бесконечное допиливание системы. Потому что старая система не настолько была плохая, как её описывали, чтобы продать/купить новую.
Конкретный пример. У нас в новой архитектуре предусмотрели замену импорта данных на JSON, который раньше был на csv. Ведь это так модерно и круто. А то, что время импорта потом увеличилось в разы — это никого поначалу не волновало, ведь в Big Data все так делают. И не важно, что схема файла почти никогда не будет изменена. Потом приходит осознание, но после этого — многое уже просто так не вернёшь назад. Только за деньги и кучу времени.

masai
01.09.2021 03:21+4GPU не является Машиной Тьюринга. Не может посчитать, к примеру, экспоненциальную функцию — сигмоиду, соответственно инференс только на GPU в общем случае невозможен. После GPU все равно досчитывает CPU.
Очень странное заявление. GPU вполне может симулировать машину Тьюринга.
И сигмоида на GPU прекрасно программируется. Вот пример реализации. Тут даже думать особо не нужно, чтобы запрограммировать, так как экспонента — это стандартная функция.

Balling
31.08.2021 20:49>Если избавиться от CPU, всё будет немножечко лагать.
Не правда. Просто нужна ос, грузящаяся с GPU (благо 2080 Ti имеет USB 10 гбит/с, с которого можно грузиться даже в нормальной ситуации через USB Attached SCSI Protocol). users.atw.hu/gerigeri/DawnOS/history.htmlDawn now works on GPU-s: with a new OpenCL capable emulator, Dawn now boots and works on Graphics Cards, GPU-s and IGP-s (with OpenCL 1.0). Dawn is the first and only operating system to boot and work fully on a graphics chip.
>что к 2010 году тактовая частота одного ядра процессора достигнет 10 гигагерц. Сейчас мы знаем, что эти ожидания не сбылись.
Внутреннее разрешение времени в VISA debug framework-e Intel во всех современных чипсетах десять пикосекунд. Надеюсь, не надо объяснять, что это как раз 10 GHz. А вот что там внутри самого Bigcore (это то, что мы, простые люди, и называем CPU) да фиг знает. Не смотря на то, что ucode взломали и частитчно дизассемблировали, во внутрь ещё не заглянули. Для этого надо сам ucode эксплойтнуть.
Balling
31.08.2021 21:07>35 Гб/сек против 400 Гб/сек.
Первое это ГБ. А не Гбит. Да и второе тоже.
А 484 ГБ это довольно сложные вычисления, получающие из 8 чипов скорости 11 Gbit/s: superuser.com/questions/1186150/whats-the-difference-between-gpu-memory-bandwidth-and-speed/1186160#1186160
11 Гбит/с * 352 бита шина / 8 = 484 ГБ/с.

habrabkin
31.08.2021 22:41Бииткоины уже давным давно не майнят на видеокартах. Этим занимаются ASIC микросхемки.
Dimkasan
02.09.2021 11:02понятно же, что под биткойнами здесь подразумевают работу с криптовалютами. Это как подгузники называют памперсами, хотя памперсы - это подгузники определенного производителя :)
maximnik0q
Автор насчет CUDA вы проморгали новость что теперь это открытая технология.И есть неофицальные порты на Амд видиокарты- по каким то причинам Амд не хочет выпускать официальный порт для своих карт,видимо из за требования упоменать владельца технологии.
xjossy Автор
Действительно проморгал. Расскажете подробнее? Желательно с ссылками
maximnik0q
https://developer.nvidia.com/cuda-llvm-compiler
Оригинал где я прочел про новость на оппеннете
https://www.opennet.ru/opennews/art.shtml?num=32562
maximnik0q
Исходники https://developer.download.nvidia.com/compute/cuda/opensource/
masai
Увы, маловато, чтоб говорить, что CUDA — открытая технология.
DeepFakescovery
в CUDA самое ценное это их CUDNN - предтюненные conv/matmul программы для всех своих видюх. Исходника на них не получить. А обычные cuda программы портировать на тот же opencl как бы справится и пара индусов.
nikolay_karelin
А также другие закрытые библиотеки, типа cuFFT (ее немного юзает Tensorflow) и cuBLAS (насколько я знаю, cuDNN на ней основан отчасти).
Я когда-то FFT для OpenCL искал. Нашел один пример, неоптимизированный, только для 2^n размеров массивов...
DeepFakescovery
На самом деле всё это очень печально. Каждый вендор занимается своими разработками по мл. Это хорошо если нужно что-то проанализировать, сделать какую-то модель для внутреннего использования, так что сгодится какой-то 1 вендор. Но если МЛ идёт в продакшн к пользователям, то начинается попа-боль. Потому что у пользователей есть не только нвидиа, но и амд, а есть еще встроенная в интел проц видяха, которая и не очень быстрая, но зато освобождает процессорное время, что тоже очень неплохо. Т.е. вместо того чтобы всем объединиться и делать какой-то единый стандарт/фреймворк итд итп, мы имеем 3 гиганта которые работают порознь, а так же араву разработчиков библиотек, которые делают различные плохо портируемые фреймворки под конкретные типы железа, конкретные компиляторы и ОС. Единственное это Microsoft хоть как-то пытается это всё стандартизировать. Я использую их onnxruntime , который работает одинаково хорошо на всех видяхах для инференса моделей. Так же их DirectML тоже перспективен и выдает неплохую скорость тренировки в tensorflow-directml, но для линукса нет.
masai
К сожалению, CUDA — это не открытая технология. Возможно, вы перепутали с какой-то другой технологией. Достаточно посмотреть лицензию, которая, например, в явном виде запрещает реверс-инжиринг SDK.
maximnik0q
А это что ?
https://developer.download.nvidia.com/compute/cuda/opensource/
Лицензия наверное на бинарный пакет который содержит компоненты из источников 3-й стороны,которые реверсировать нельзя.
masai
А вы смотрели, что внутри? Если скачать здоровенный архив из поддиректории image/, то там внутри будут исходники apt, bash, make и других утилит и библиотек. Nvidia их использует, например, в своих образах для Docker и по лицензии GPL должна распространять исходники вместе с программами.
Исходников каких-то компонентов CUDA Toolkit (например, cuBLAS) я внутри не заметил. Может плохо смотрел, конечно.
Для меня открытая технология — это всё же когда больше одной компании влияет на её развитие, когда есть спецификации железа, чтобы любой мог реализовать, ну и когда есть исходники всех компонентов.
А то у Nvidia много опенсорса, тут я спорить не буду. Достаточно на их гитхаб зайти.