
Хочу поделиться с вами обзором интересных докладов недавно прошедшего Форума искусственного интеллекта Samsung AI Forum 2021. Это мероприятие проводится штаб-квартирой Samsung Research уже пятый год подряд, на него приглашают с докладами всемирно известных ученых, ведущих исследователей и инженеров из Samsung Electronics, представителей инновационных стартапов и уже состоявшегося бизнеса, построенного вокруг ИИ.
В этом году, как и в прошлом, форум проводился онлайн и транслировался в прямом эфире на канале Samsung Electronics в YouTube. Благодаря этому, аудитория существенно выросла, кроме того участники получили возможность пообщаться со спикерами в рамках сессий вопросов и ответов. Программа форума была двухдневной и очень интенсивной, поэтому я решил разбить свой обзор на два поста - по одному на каждый день. Сегодня – мой обзор первого дня Samsung AI Forum 2021.

Первый день форума был организован подразделением Samsung Advanced Institute of Technology (SAIT) - это центр исследований и разработок Samsung Electronics, специализирующийся на технологиях, которые компания рассматривает с точки зрения горизонта внедрения 5-10 лет. Помимо разработки новых алгоритмов искусственного интеллекта, SAIT занимается устройствами дополненной реальности, исследованием новых материалов для дисплеев и электроники, метафотоникой, голографией и многим другим; подробнее с ключевыми направлениями проектов SAIT можно ознакомиться на сайте.
Итак, перейдем к программе.
Keynotes
Форум открылся с вступительного слова Кинама Кима (Kinam Kim), президента и главного исполнительного директора Samsung Electronics, заместителя председателя Совета директоров и глава подразделения Device Solutions. Он отметил: «В последние годы искусственный интеллект демонстрирует алгоритмический прогресс и оказывает огромное влияние на мировую экономику – в медицине, науке и промышленности. Так, беспрецедентная скорость разработки вакцины против COVID-19 стала возможной только благодаря применению искусственного интеллекта для анализа огромных объемов реальных данных. Samsung продолжает оставаться ключевым поставщиком технологий для экосистемы ИИ, предоставляя компоненты памяти и обработки данных, лежащие в основе большинства вычислительных систем. Мы также активно применяем искусственный интеллект для оптимизации наших процессов разработки и производства».

Сразу после него с докладом выступил Йошуа Бенджио (Yoshua Bengio), профессор Университета Монреаля. Профессор Бенджио – один из пионеров современного искусственного интеллекта и лауреат Премии Тьюринга, часто называемой «Нобелевской премией в области компьютерных наук». В своей лекции он рассказал о новой архитектуре нейронных сетей GFlowNet, подходящей как для поиска новых лекарств и материалов с заданными свойствами, так и для оптимального управления процессами без явного описания (Black-Box Processes). Часто применяемое для этих задач обучение с подкреплением (Reinforcement Learning, RL) не дает полной желаемой информации. Это связано с тем, что для стандартных RL-алгоритмов результатом является единственная последовательность действий с наивысшим вознаграждением. Но, например, для задачи синтеза молекул лекарств, где сами исследования так же важны, как и конечная формула, желательно не просто генерировать одну последовательность действий с наивысшей наградой, а иметь возможность получить целый спектр оптимальных решений. И именно для решения этой проблемы возглавляемая Йошуа Бенджио исследовательская группа предложила GFlowNet, новый генеративный метод на основе потоковой сети, который может превратить заданное вознаграждение в генеративную политику с вероятностью пропорциональной награде. Интересно, что авторы не только предложили новый метод, но уже смогли экспериментально показать его превосходство над альтернативными подходами, например, такими как методы Монте-Карло с марковскими цепями (Markov Chain Monte Carlo, MCMC), в реальной задаче крупномасштабного поиска новых молекул лекарств. Более подробно об архитектуре GFlowNet можно прочитать в статье на Arxiv.
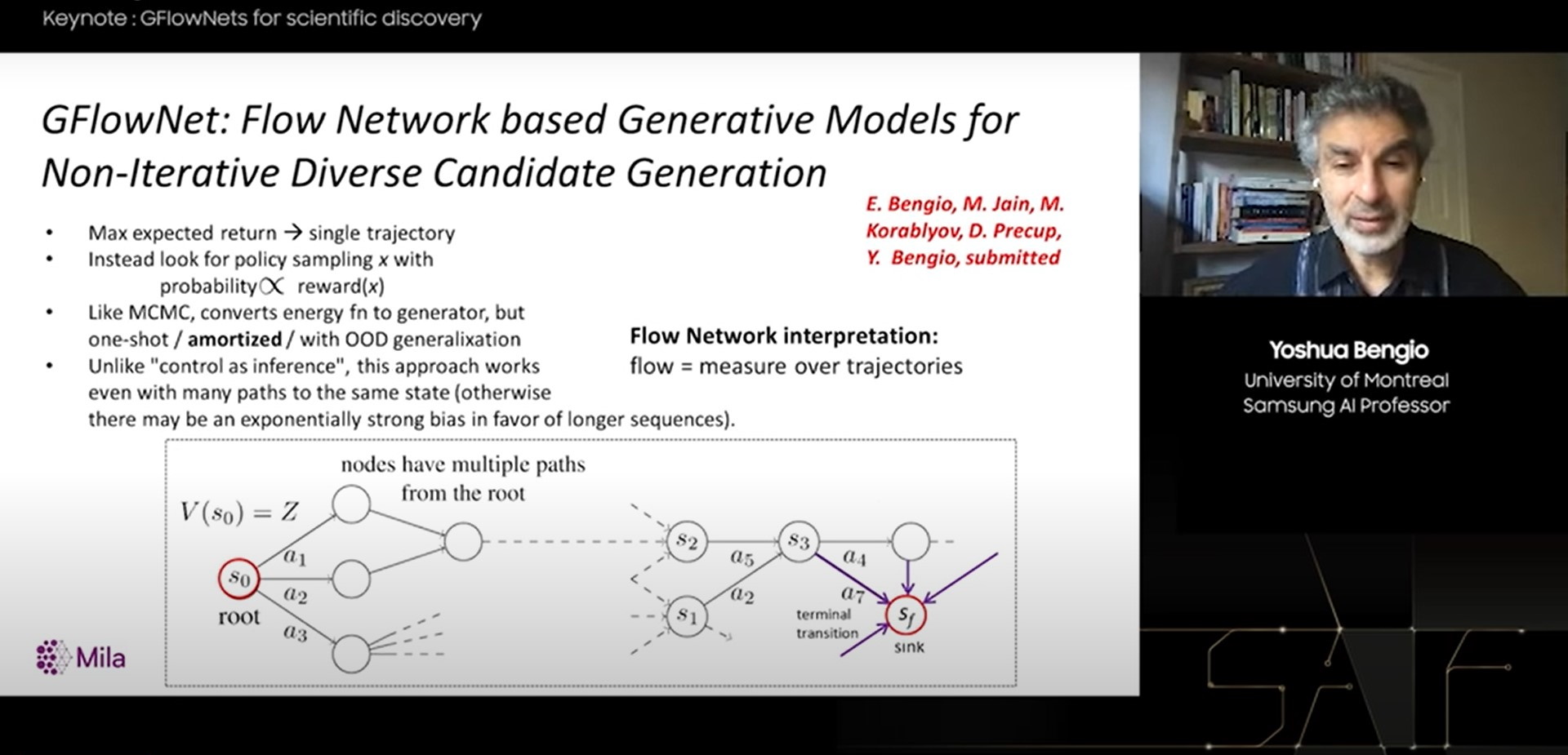
Дальнейшая программа первого дня форума была разделена на 3 технологические сессии.
Session 1. Scalable & Sustainable AI Computing (Масштабируемые и устойчивые вычисления на основе ИИ)
Эту сессию открывал старший вице-президент SAIT Чангю Чой (Changkyu Choi) с презентацией «На пути к энергоэффективным вычислениям с искусственным интеллектом». Сейчас использование ИИ становится мейнстримом как в индустрии, так и в научных исследованиях. Ученые полагаются на силу нейронных сетей в решении важнейших вызовов современной науки, таких как уменьшение времени разработки новых лекарств, вычисление плотности темной материи во вселенной или построение полномасштабной карты нейронных связей в человеческом мозге. Эти применения требуют обучения на огромных массивах данных, приводя к моделям с триллионами синаптических весов. Все это приводит к огромному росту энергопотребления инфраструктурой, необходимой для обучения ИИ. Мистер Чой привел такой пример – популярная сейчас модель GPT-3 для генерации текста на естественном языке имеет 125 миллиардов весов. На ее обучение необходимо потратить 1,3 ГигаВатт-часов, что примерно равно энергопотреблению всей Южной Кореи с ее развитой промышленностью и 52 миллионами жителей за 1 минуту. Имеющиеся решения на основе GPU и специализированных чипов для обучения ИИ уже не могут эффективно решить эту проблему. Например, подсчитано, что для другой задачи, построения нейронной карты головного мозга, применение GPU дает лишь 10% падения энергопотребления. Узким местом, мешающим повысить энергоэффективность обучения ИИ на порядок и более, является ограниченная скорость записи в память, которая не масштабируется с ростом вычислительных мощностей. По словам мистера Чоя, для решения этой проблемы инженеры SAIT разрабатывают подход Near Memory Processing, при котором «железо», отвечающее за обучение ИИ, встраивается напрямую в чипы памяти DRAM.

Как раз будущему ИИ в железе был посвящен следующий доклад – Кунле Олукотуна (Kunle Olukotun), профессора Стэнфорда и со-основателя и CTO калифорнийского стартапа SambaNova. Профессор Олукотун перечислил ключевые технологические тренды, которые будут определять дизайн специализированных процессоров для ИИ – помимо уже упоминавшейся энергоэффективности и терабайтного размера данных для обучения, это разряженные нейронные сети (Sparse NN), конвергенция обучения и использования ИИ на одном и том же железе (Convergence of Training and Inference) и переход к моделям исполнения нейронных сетей на основе графов потока данных (Dataflow Graphs). В качестве примера использования этих подходов Кунле Олукотун привел новый процессор Cardinal SN10, разработанный в его компании SambaNova. Это процессор нового типа, который они назвали RDU – Reconfigurable Dataflow Unit. Архитектура RDU позволяет при компиляции кода нейронных сетей автоматически распределять его во времени и в пространстве чипа. По мнению профессора, RDU оптимален для ускорения терабайтных моделей ИИ, связанных, например, с генерацией текстов на естественных языках или визуализацией медицинских изображений сверхбольшого разрешения. В целом, при обучении нейронных сетей процессоры SambaNova показывают 20-кратное превосходство над недавно выпущенными на рынок процессорами Nvidia A100.

Последним в этой сессии выступал CEO и сооснователь компании Cerebras System Эндрю Фельдман (Andrew Feldman). Его компания разрабатывает системы для глубокого обучения на порядки более эффективные, чем традиционные GPU. В 2019-м году Cerebras показала самый большой из когда-либо произведенных процессоров из 1,2 триллиона транзисторов и 400 тысяч специализированных ядер ИИ на чипе. В апреле 2021-го они представили еще больший процессор – уже с 2,6 триллионами транзисторов и 750 тысячами ядер ИИ. Главное преимущество таких процессоров перед GPU – увеличение пропускной способности памяти в десятки тысяч раз за счет ее расположения на одной кремниевой пластине с процессором (как мы помним из доклада Чангю Чоя в начале этой сессии, сейчас именно низкая пропускная способность памяти ограничивает рост эффективности систем ИИ).

Session 2. AI for Scientific Discovery (ИИ для научных открытий)
Первым в этой сессии выступил Енсан Чой (Young Sang Choi), корпоративный вице-президент и руководитель лаборатории машинного обучения SAIT. Эта лаборатория в том числе занимается задачей дизайна новых материалов с использованием алгоритмов ИИ. Для этой задачи исследовательская группа доктора Чоя, используя графовое представление молекул, применяет так называемые Transformers, многообещающий подход в обработке естественных языков. Этот подход позволяет уменьшить время анализа свойств смоделированных материалов, например, таких как проводимость или токсичность, с часов до секунд. Еще одна инновация лаборатории Енсан Чоя – полностью автоматизированный химический синтез. Все вместе это значительно ускоряет и удешевляет поиск новых веществ и материалов с требуемыми свойствами. Помимо решения фундаментальных задач, лаборатория машинного обучения SAIT занимается и более насущными проблемами. Так, по инициативе лаборатории был создан Samsung Particulate Matter Research Institute, цель которого моделирование и предсказание загрязнения воздуха с использованием ИИ на основании данных со спутниковых и атмосферных датчиков.

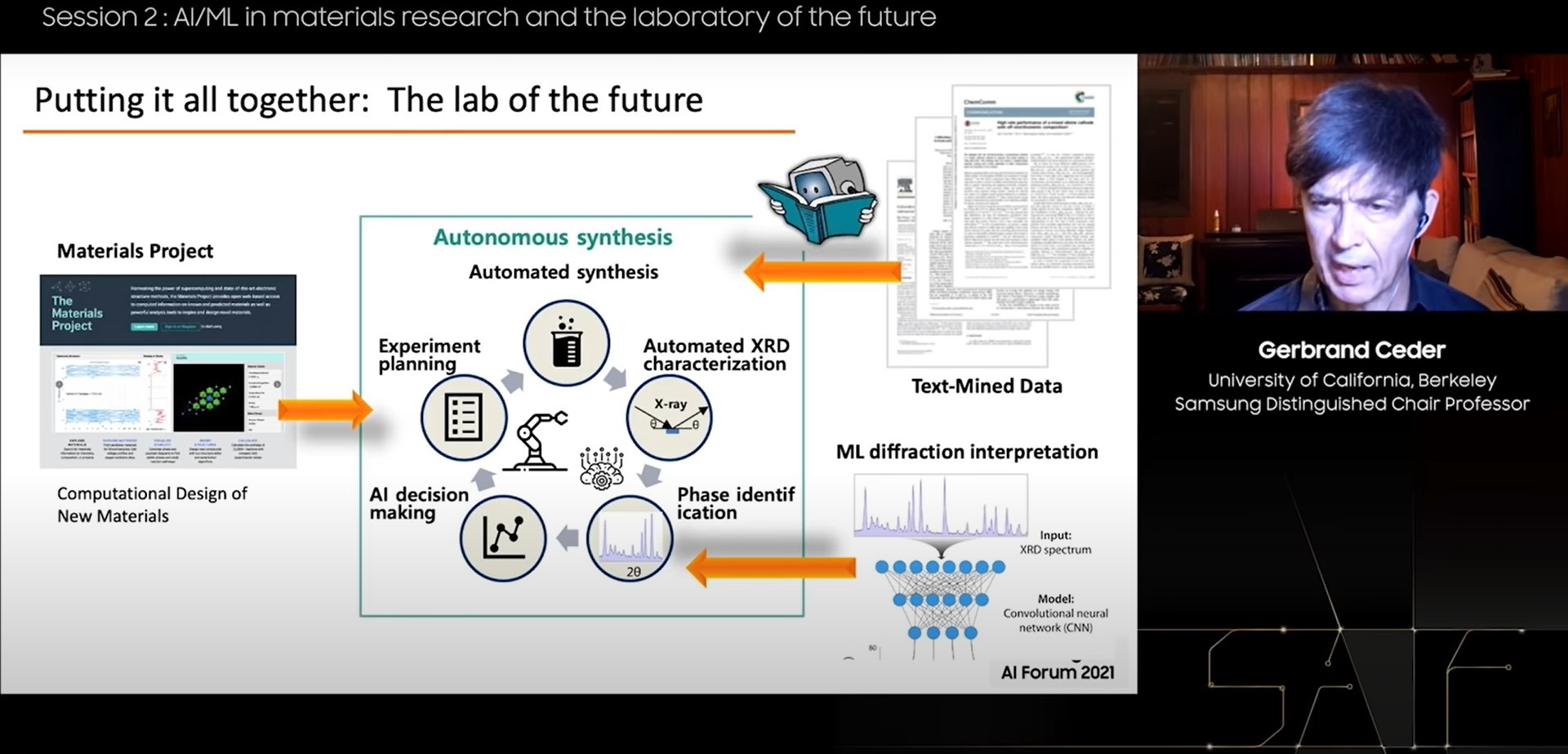
Более подробно об использовании ИИ в дизайне материалов и лабораториях будущего рассказал профессор Университета Калифорнии в Беркли Жербран Седер (Gerbrand Ceder), выступавший следом. До недавнего времени путь от открытия до коммерциализации в массовых продуктах новых материалов, таких как тефлон, поликарбонатные пластмассы или литий-ионные аккумуляторы, в среднем занимал от 15 до 18 лет. Столько времени необходимо для экспериментального получения, дорогостоящим методом проб и ошибок, информации о наиболее подходящей технологии крупномасштабного синтеза, структуре дефектов в массовых образцах и пр. С целью уменьшить это время как минимум в два раза профессор Седер с коллегами запустил в 2011-м году Materials Genome Initiative (по аналогии с Human Genome Project) – коммьюнити и открытую базу данных веществ и материалов, в том числе полученных в ходе моделирования и симуляции. Сейчас в базе более 160 тысяч зарегистрированных пользователей, которые загружают почти 2 терабайта данных ежемесячно. Чтобы автоматизировать поиск новых материалов группа Жербрана Седера активно применяет методы обработки естественных языков для выделения информации о синтезе из научных статей и обучает генеративные модели на этих данных. Еще один элемент лаборатории будущего, по мнению профессора Седера, – предсказание структуры материалов с помощью машинного обучения на основании данных рентгеноскопии. Вместе эти инновации могут обеспечить полностью автоматизированный цикл синтеза материалов с заданными свойствами.
Третий выступающий в этой сессии – Брайс Мередиг (Bryce Meredig) из компании Citrine Informatics – рассказывал о той же задаче, использовании ИИ при создании новых материалов, но с точки зрения ее решения в промышленности. По словам Брайса Мередига, основные проблемы, которые приходится решать его команде – кластеризованность известных данных и их общий недостаток. Последняя, наверное, является общей головной болью при разработке большинства индустриальных приложений ИИ. Метод ее решения тоже вполне стандартный в этой области – обучение на данных из симуляций (Transfer Learning from Simulation). Помимо этого, Citrine активно дополняет данные для обучения информацией из различных физических и термодинамических симуляций.

Session 3. Trustworthy Computer Vision (Надежность алгоритмов компьютерного зрения)
Последняя сессия первого дня форума началась с доклада Джеджун Хана (Jae-Joon Han), вице-президента по технологиям и руководителя лаборатории компьютерного зрения SAIT. Современные алгоритмы компьютерного зрения широко применяются в распознавании лиц и безопасности. При их разработке учитывается большой круг вопросов об их надежности, безопасности и применимости к людям разных рас и национальностей. Но компьютерное зрение может также использоваться в индустриальных задач. Для Самсунга одной из наиболее важных задач является автоматизация визуального осмотра новых полупроводниковых элементов, таких как платы памяти, процессоры и пр., на предмет дефектов. Группа доктора Хана активно применяет алгоритмы компьютерного зрения для этой задачи, делая особый акцент на так называемой объяснимости (Explainability) результатов, чтобы понять, как можно уменьшить число дефектов в будущем.

Выступавший следующим Антонио Торральба (Antonio Torralba) из Массачусетского технологического института прочитал лекцию о том, как научить компьютер видеть. Общеизвестная проблема современных алгоритмов компьютерного зрения и шире – ИИ, построенного на глубоких нейронных сетях, - невозможность объяснить, почему данная модель дала неправильный результат на конкретном примере. Чтобы понять, как нейронная модель запоминает и генерирует визуальные образы, и почему она ошибается, группа профессора Торральба разработала алгоритм, позволяющий убирать нейроны, отвечающие за конкретные классы объектов натренированной GAN сети. Например, можно из сгенерированого изображения гостинной убрать нейроны, отвечающие за окна, тогда на их месте нейронная сеть сгенерирует глухую стену, не затронув остальные объекты в комнате. Вы можете протестировать работу алгоритма сами: https://ganpaint.io/. Помимо решения задачи объяснимости ИИ, такой подход позволяет более эффективно обучать модели на малых данных, используя автоматизированную разметку на реальных и синтетических данных.

В конце третьей сессии выступил Дэниэл Бибиреата (Daniel Bibireata), вице-президент компании Landing.ai, основанной всемирно-известным ученым в области ИИ профессором Эндрю Энгом (Andrew Ng) из Стэнфорда. Дэниэл рассказал о том, каких ловушек надо избегать при создании промышленных систем компьютерного зрения. Он процитировал данные опроса, проведенного Accenture, от том, что 75% компаниям, пилотировавшим у себя системы визуального анализа дефектов при помощи ИИ, оказалось не под силу их масштабировать на весь производственный процесс. Оказалось, что даже при успешном пилотировании достижение и поддержка показателей системы на уровне, необходимом в производстве, является нетривиальной задачей. Чтобы этого избежать Landing.ai практикует дата-центричный подход – при построении ИИ системы инженеры компании добавляют новые данные в обучающую выборку в случае наличия нераспознанных дефектов. Этот подход смещает фокус разработки с многократного обучения модели на сбор и разметку дополнительных данных. В качестве примера Дэниэл Бибиреата привел пример системы распознавания дефектов на стальных листах – их подход позволил увеличить точность распознавания с 76% до 93%.

По окончании технологических сессий были представлены результаты соревнования для студентов и выпускников корейских вузов Samsung AI Challenge, на котором участники пытались предсказать размер запрещенной зоны, используя базу данных молекулярной структуры материалов. В соревновании приняли участие 220 студенческих команд, 3 из которых заняли призовые места.

Также были объявлены лауреаты корпоративной премии Samsung AI Researcher of the Year 2021 – ими стали Филлип Исола (Phillip Isola) и Джейкоб Андреас (Jacob Andreas) из MIT, Джуди Хофманн (Judy Hoffman) и Дийи Янг (Diyi Yang) из Технологического университета Джорджии, а также Ярин Гал (Yarin Gal) из Оксфорда.

На этом обзор первого дня Samsung AI Forum 2021 завершен. Но был еще второй день, о нем я расскажу в следующем посте.

Владимир Пичугин
Ведущий инженер управления развития технологических проектов
Исследовательский центр Samsung в Москве