

Хранение данных — непростая задача, особенно когда к ним нужно обеспечить бесперебойный доступ. И сегодня мне хотелось бы поговорить о гиперконвергентных системах и связанных с ними программно-определяемых хранилищах, позволяющих использовать накопители в стандартных серверах х86 из того же кластера, что и вычислительные узлы. Чтобы не разводить холивара, сразу скажу, что в этом посте не будет глубокого технического разбора той или иной системы. Мы поговорим об архитектуре и особенностях ее применения в ЦОДе.
Итак, используем ли мы гиперконвергенцию в ЦОД Oxygen? Да, конечно. Будем ли мы рекомендовать ее для широкого спектра задач? Нет, не будем. Почему — подробнее разбираемся под катом.
В прошлый раз крупными мазками я рассказал об архитектуре хранения, которую мы используем в ЦОДе Oxygen. Если коротко, то мы в основном работаем с СХД NetApp, которые позволяют кластеризовать дисковое хранилище и предоставить пользователям доступ не только к самой емкости, но также к инструментам управления и мониторинга. Подробнее — здесь.

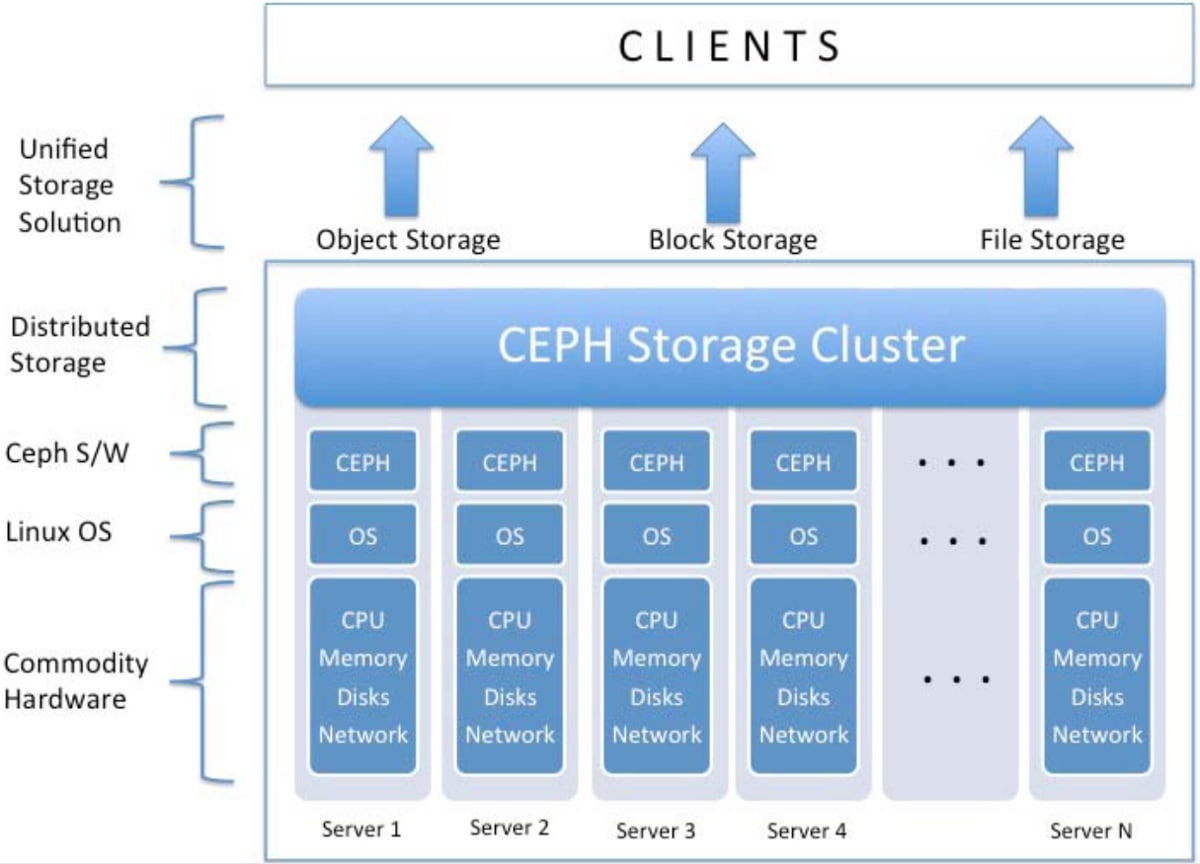
В комментариях к посту мне попались вопросы про гиперконвергентные решения. И действительно, почему же не использовать подобные хранилища? Ведь они не требуют специализированного железа (а значит их проще реализовать), а кроме этого бывают не только чисто российскими, но и вообще бесплатными. Взять один только open-source проект Ceph…

Так что, можно все-таки решить вопрос гиперконвергентно?
Прежде чем дать ответ на этот вопрос, давайте разберемся, в чем именно заключается концепция гиперконвергентной системы. В сущности можно выделить два подхода.
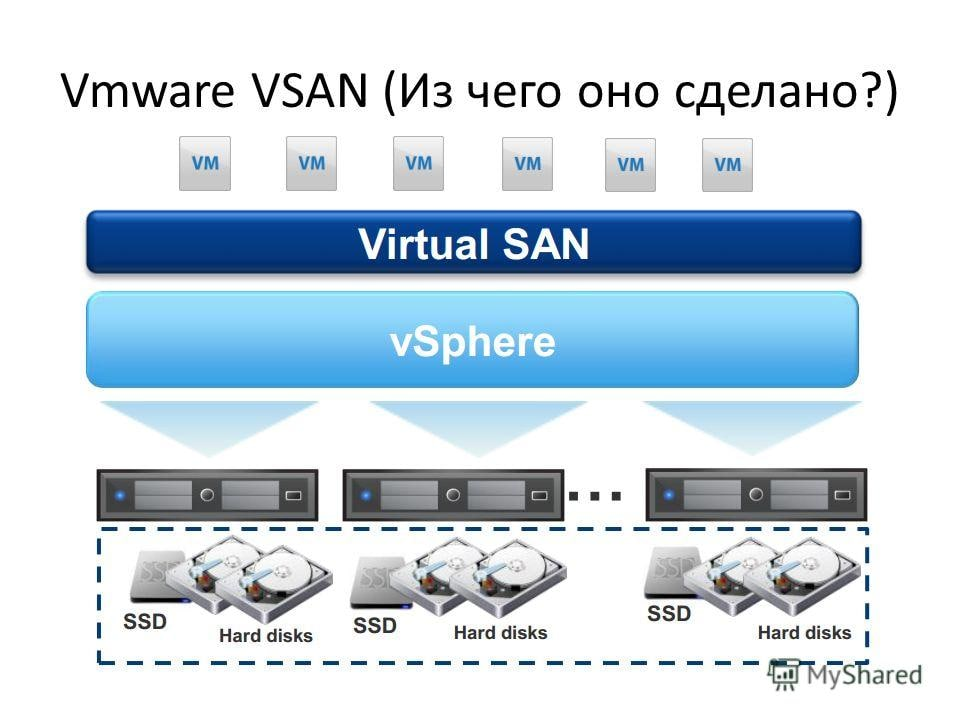
Первый способ — истинная гиперконвергенция, когда в действительности для хранения данных используются ровно те же самые узлы, на которых происходят вычисления. В этом случае мы устанавливаем в серверы дополнительные диски и используем программный слой для распределения данных между ними. Тут чаще всего используется одна из разновидностей RAID, чтобы оптимизировать размещение данных. Такой подход неплохо подходит для задач, которым требуется определенный вид хранения.
Второй способ — формирование программно-определяемого хранилища. В этом случае серверы используются специально как система хранения. В них устанавливается максимальное количество дисков, а общее хранилище используется одним или несколькими приложениями. В этом случае можно добиться большей скорости передачи данных и более высокой емкости.
3 причины, почему мы почти не используем гиперконвергенцию
Все это звучит красиво, верно? И в действительности в редких случаях мы прибегаем к организации гиперконвергентных хранилищ. Но следует учитывать ряд нюансов, которые мешают делать это повсеместно.

Емкость. В один сервер 1U, как правило, можно установить до 8 дисков (реже до 12) формата 2,5-дюйма. Таким образом, мы получаем 6 или 10 дисков (2 диска уходят на кеш) на 1U. На 2U мы получим 12 или 20 соответственно. Тем временем, дисковая полка или система хранения может вместить до 36 дисков, занимая те же самые 2U. Получается, что в той же стойке можно разместить намного больше данных при работе с СХД, чем с гиперконвергентной системой.

Стоимость. Что бы кто ни говорил о сложности ввоза хранилищ данных среднего уровня, их все равно поставляют сегодня в Россию. Можно назвать этот процесс параллельным импортом или как-то еще, но оборудование купить можно. И даже при подросших из-за сложной логистики цен, стоимость 1 Гб хранимой информации оказывается намного ниже для СХД. При этом стоимость систем SDS от VMware, NetApp, EMC и других поставщиков корпоративных систем, оказывается весьма высокой. Все это стоит денег и делает хранилище дороже по сравнению с отлаженным размещением данных в сетевых СХД.

Надежность. Если мы все же спустимся на уровень доступных и открытых SDS, не так много систем хранения позволяют изменить настройки хранилища без перезагрузки. Что уж говорить о, например, замене оборудования или обновлении версии. Тут возможны всякие неприятности, вплоть до необходимости отката, если система не будет загружаться в новой конфигурации. А что делать пользователям в это время, особенно если речь идет о mission-critical системах? В прошлом посте (ссылка) я уже рассказывал о том, что мы проводим обновление ПО и замены блоков СХД в облаке Oxygen, вообще не прерывая доступ пользователей к данным. У меня был опыт работы с целым рядом гиперконвергентных систем. Но сделать такое с ними (не буду называть имен) было практически невозможно.
Когда же все-таки нужна гиперконвергенция стораджа
Но, конечно, нельзя сказать, что гиперконвертентные хранилище вообще не нужны. Более того, мы используем их в некоторых случаях для решения задач наших клиентов. Из моего опыта, чаще всего подобные решения бывают полезны в следующих ситуациях:
Нужно организовать выделенное хранилище на 10 Тбайт. В ЦОДе находится изолированная от других систем инфраструктура одного из заказчиков. Требования к безопасности таковы, что данные не могут размещаться на одном оборудовании с другими клиентами — то есть мы не можем делить ресурсы одной СХД. Но создавать отдельное хранилище на 10 Тбайт — просто смешно! Поэтому прекрасно подойдет установка дисков в те же серверы, которые используются для вычислений…или в отдельные серверы в ту же стойку. Такой подход позволяет создать изолированное хранилище “малой кровью”. И это отличный кейс применения SDS-системы корпоративного уровня, потому что мы очень дорожим данными клиентов.
Тестовая или любая другая среда без особых требований к доступности. Этот случай также касается изолированной инсталляции. Есть серверы, на них крутятся какие-то задачи, и при этом имеются как свободные слоты для дисков, так и неиспользованная пропускная способность сети в кластере. В этом случае для решения второстепенных задач можно использовать бесплатных или более доступных SDS (включая OpenSource). Кстати, оно может дополнять арендуемую емкость высокопроизводительных кластеризованных СХД, которая используется для критически важных задач.
Всему свое время и место

Подводя итог скажу, что использование SDS при хранении данных оказывается неоправданным для критически важных нагрузок, и поэтому мы в Oxygen используем подобные решения только для узких нишевых задач. Для других целей применяются кластеризованные СХД различного уровня. И это не приводит к росту тарифов на хостинг, в чем вы можете убедиться сами.
В следующем посте я подробнее расскажу о том, как мы решаем задачу резервного копирования в нашем ЦОД. Так что если вам интересно продолжение темы, подписывайтесь на наш блог и давайте обсуждать вопросы хранения данных дальше и глубже.
Комментарии (16)

borovinskiy
04.08.2022 13:11А на сколько Ceph получился дороже, интересно? И по каким параметрам было сравнение (IOPS, емкость, что-то еще)?
Если смотреть на Гугл с Амазоном, то на сколько могу судить у них есть локальные диски (быстрые) и видимо SDS. У Mail, я так понял, активно используется Ceph для продажи клиентам.
Есть ли ограничения на рассуждения о высокой стоимости SDS? Например "сказанное справедливо для продажи классической виртуализации, когда важны IOPS, а для холодного отказоустойчивого хранения не справедливо".
Mikhail_nmv Автор
04.08.2022 14:08+1В стоимости железа цена сопоставима, ну плюс минус. Но если брать стоимость содержания и обслуживания. Персонал, тестовые кластера и т.п. Тут стоимость, при учете малого и среднего размера кластера SDS, ниже у СХД.
При больших и очень больших размерах инсталляций преимущество Ceph увеличивается.
Поэтому сказанное справедливо для малых и средних инсталляций, с высоким уровнем IOPS и с высокими требованиями к надежности.
awsswausa
05.08.2022 15:33Стоимость решения считается не от стоимости оборудования и поддержки.
Стоимость решения считается от стоимости информации. И там как по учебнику, сколько вы можете потерять информации и сколько вы можете допустить простой при восстановлении.
Проще говоря, если в вашей фирме все продажи идут через сайт, а падение сайта остановит работа склада, менеджеров, водителей, бухгалтерии... И убытки будет в 20 миллионов в сутки. То вам уже все равно сколько стоит сервер, программа, поддержка, персонал.
И строить решение на прокмокс и ceph можно при условии что стоимость информации у вас равна зарплате админа, в 30-40 тысяч. В случаи ЧП просто его уволите и наймете нового

beho1der
04.08.2022 14:10В статье хорошо бы упомянуть,что данная статья актуальна в расчете того что используются коммерческие SDS,стоимость лицензий которых приближается к стоимости железных хранилок.
Mikhail_nmv Автор
04.08.2022 14:24Совершенно верно.
Но и открытые SDS, при высоких требованиях к отказоустойчивости, начинаю дорого стоить. В первую очередь это персонал и тестовые среды.beho1der
04.08.2022 14:31+1для VSAN персонал тоже нужен,помню сколько в первых версиях было проблем у них,не знаю как сейчас,но раньше и там не все так просто...
Mikhail_nmv Автор
04.08.2022 14:38+1Когда у тебя публичное облако на VMware то персонал по vSAN идет сразу из коробки))))

outlingo
04.08.2022 22:52Когда у тебя публичное облако на VMWare, к тебе приходят <рестрикции со стороны вендора вызванные текущей политической коньюнктурой>.

vasilisc
04.08.2022 15:31+1Используем гиперконвергентную архитектуру на базе Proxmox VE + Ceph.
https://pve.proxmox.com/wiki/Hyper-converged_Infrastructure
Всё хорошо - реально (!), только если помнить главный минус любой SDS системы что сеть - это "не быстро". Это так же автоматически означает, что дисковый I/O у виртуальных машин никогда не может быть лучше поверх классических СХД. Вечно стараться приближаться к их показателям IOPS, latency и т.д., но никогда не достигать. Лучше всего это расписано в статье
https://yourcmc.ru/wiki/index.php?title=Производительность_Ceph
На практике же, если задача требует сервер с хорошими показателями на запись, то просто такое решение развёртывается на отдельных физических серверах. Другими словами, не зацикливаться на SDS и не решать ею абсолютно все вопросы.
Так как Proxmox VE + Ceph - это open source, дающий shared storage, то в целом получаешь много админских плюшек (переезд в онлайн ВМ с ноды на ноду, "ночной администратор" High Availability) и даром, не считая своих знаний и труда.
В SDS Ceph есть возможность создавать пулы типы erasure code, что оптимально под надёжное хранение холодных данных с минимальными "потерями" дискового пространства. Такое решение тоже имеет право на существование.
https://docs.ceph.com/en/latest/rados/operations/erasure-code/


outlingo
04.08.2022 23:22+3Вообще, у вас какие-то странные вещи написаны про гиперконвергентность. В частности вот тут:
В один сервер 1U, как правило, можно установить до 8 дисков (реже до 12) формата 2,5-дюйма. Таким образом, мы получаем 6 или 10 дисков (2 диска уходят на кеш) на 1U. На 2U мы получим 12 или 20 соответственно. Тем временем, дисковая полка или система хранения может вместить до 36 дисков, занимая те же самые 2U
Суть гиперконвергентности в том, что вы размещаете диски в уже имеющемся оборудовании (как правило, в гипервизорах). И если у вас есть 15 гипервизоров, то у вас есть бесплатное место на 90 дисков внутри этих гипервизоров. В то время как с СХД вам как раз и потребуется 6U на три полки.
А если у вас еще и какая-нибудь любимая адептами классических СХД FC SAN, то вам потребуется дополнительная коммутация под неё, еще пара юнитов под FC фабрики - в то время как гиперконвергентное решение будет работать поверх то сети которая уже есть.
Так что всё намного интересней если говорить именно о гиперконвергентных решениях а не просто об SDS.
awsswausa
05.08.2022 11:04+1Судя по статье, такое ощущение что сейчас 2008 год. И мы вкатывается в ИТ с помощью изоленты и windows 98
Ivan_2424
Аааатличные картинки. :) Особенно с водосточной трубой. Ну и за пост спасибо. Я как-то не задумывался, что СХД выгоднее хотя бы с точки зрения плотности.
mariya_kry