

Потребность в гарантиях отказоустойчивости систем продолжает расти. Но, сами понимаете, нельзя всем подряд рекомендовать одни и те же механизмы защиты. Как минимум, сами данные бывают очень разными — и нельзя обойтись простым резервным копированием для realtime-систем. Но стоимость реализации разных схем также сильно отличается друг от друга, а приложения часто бывают не готовы к тому, чтобы их действительно защищали с гарантией катастрофоустойчивости. Под катом — подробный разбор популярных среди наших заказчиков методов резервирования с использованием облака, а также анализ их применимости для разных ситуаций.
О том, почему спрос на DR продолжает расти, я уже рассказывал в предыдущем посте. В действительности, сужение спектра гарантий от разработчиков и производителей, ответственные лица хотят переложить их на кого-то другого. И российское облако при этом выглядит наиболее привлекательно.
Но когда происходит переход от теории (о, хорошо бы нам резервные мощности в облаке) к практике (давайте все это внедрим и подключим), возникает проблема выбора метода защиты.
Бэкап для операционных данных
Самый простой, очевидный и базовый уровень защиты — это бэкап. Мы реализуем его по следующей схеме.

Прямо с СХД делается бэкап — по заданному графику и расписанию. Но поскольку процесс растянут во времени, после завершения каждого этапа данные на хранилище с копиями могут отличаться от реальных (и значительно).
Бэкап может быть локальным, но это не дает высоких гарантий отказоустойчивости. Что если из-за непредвиденных обстоятельств не работает СХД или сервер? В такой ситуации получается, что резервная копия есть, а восстановиться — некуда!
Поэтому сегодня все чаще практикуется резервное копирование на другую площадку. Если вы дублируете облаком свою инфраструктуру, оно получится так само. А для нагрузок, находящихся в одном из ЦОДов Oxygen мы делаем бэкап в другой ЦОД. Если что-то случилось с первым (а в жизни может быть все что угодно — вплоть до перерубания кабеля лопатой каким-нибудь рабочим), восстановление сразу же происходит во втором ЦОДе.
Тем не менее бэкап подходит только для тех случаев, когда потеря данных не слишком критична. Вряд ли я скажу для вас что-то новое, если подчеркну, что облачный бэкап подходит для тех случаев, когда мы вполне можем позволить себе потерять работу за последний день.

Но что нужно учитывать точно, так это запуск и перенос виртуальных машин. При аварийном восстановлении ВМ должны переехать в другой ЦОД. И если их много, то на запуск потребуется время.
Да, в простых случаях вы можете просто запустить ВМ на новой площадке. Но по факту обычно требуется ряд дополнительных действий по подключению клиентов, монтированию баз данных и, конечно, оптимизации производительности. Ведь бэкапы обычно хранятся на недорогих и не слишком быстрых дисках. И если даже там лежат полные копии виртуальных машин, после запуска они будут работать не слишком поворотливо. Возможно, это подойдет как временная мера, но все равно нужно учитывать дополнительные затраты, связанные с переносом нагрузок на быстрые системы хранения.
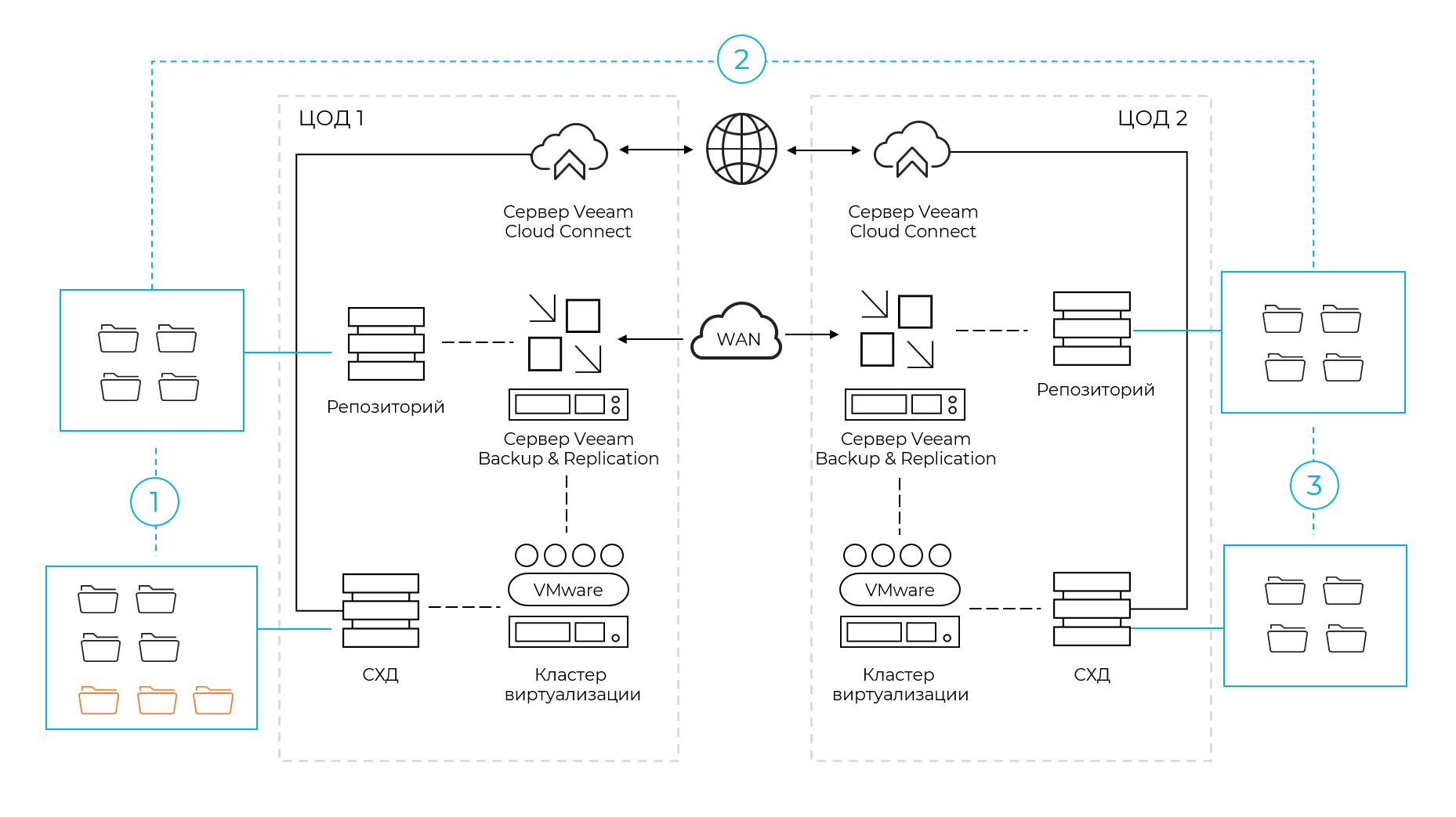
Репликация на уровне виртуализации
Разумеется, не все бизнес-процессы и поддерживающие их ИТ-инфраструктуры могут довольствоваться бэкапом. Поэтому также часто применяется схема с репликацией данных между системами виртуализации, развернутыми на разных площадках.
ВМ реплицируются “на горячую”, например, раз в 5 минут. Между площадкой заказчика и облачным ЦОД или между двумя облачными ЦОДами переливаются измененные данные.

Такой подход делает возможным быстрый старт в случае восстановления, потому что ВМ попадают сразу в систему виртуализации. Их можно быстро запустить. Благодаря этому сильно сокращаются затраты времени, которые характерны для второго плеча резервного копирования.

А учитывая, что у нас на резервной площадке развернута готовая серверная инфраструктура, все настройки сети и подключений можно воспроизвести заранее. Об этом, конечно, нужно позаботиться заранее, настроив все компоненты сети и предусмотрев переключение каналов связи…но в случае с облачным провайдером тут все делают за вас.
Минус — такого решения — увеличенные затраты. Если в схеме с бэкапом все хранится просто просто на репозитории системы резервного копирования, то при репликации на уровне виртуализации ВМ хоть и выключены, но помещаются сразу на целевую продуктивную систему хранения. Таким образом, вы потребляете в два раза больше емкости, а также платите за резервирование ресурсов. То есть фактически счет за хранение удваивается, а за резервирование процессоров приходится платить примерно +15% от мощности в основном ЦОДе.
Но зато появляется возможность восстановиться быстро и даже безболезненно переключить нагрузку. Вы можете работать из одного ЦОДа или из второго, менять местами активную площадку (например, в 2:22, когда никто не работает). В этом случае процесс репликации пойдет в обратную сторону, автоматически.
Такой подход очень сильно купирует риски, связанные с нештатными и непрогнозируемыми ситуациями. Бывает, что в ЦОДах происходят аварии. Некоторые объекты могут вообще загореться. И плюс резервирования на уровне виртуализации в том, что можно уйти на другой ЦОД при первых же показателях перегрузки или какой-либо другой опасности. Уйти, пока все еще работает и вообще избежать прекращения сервиса.
Oxygen предлагает облако на базе VMware, и поэтому мы используем для подобных включений продукт VMware Cloud Director Availability. Он полностью стандартизован, и поэтому для тех нагрузок, которые уже крутятся на VMware организовать любое переключение можно в пару кликов.
Что стоит учитывать при подобной схеме защиты — так это асинхронность репликации. Разница между основной и резервной площадкой очень маленькая, но все же они не одинаковые. И это делает схему неподходящей для самых критически важных систем.
Не две площадки, а одна распределенная

И вот мы приходим к идеальной, надежной и самой правильной с точки зрения отказоустойчивости схеме. В этом случае обе площадки активно работают. Падение любой из них с точки зрения пользователя не вызывает ничего, кроме временного роста нагрузки на одно из облаков и (возможно) просадки по производительности.
Но добиться такой схемы очень сложно как с точки зрения архитектуры, так и на уровне программных продуктов.
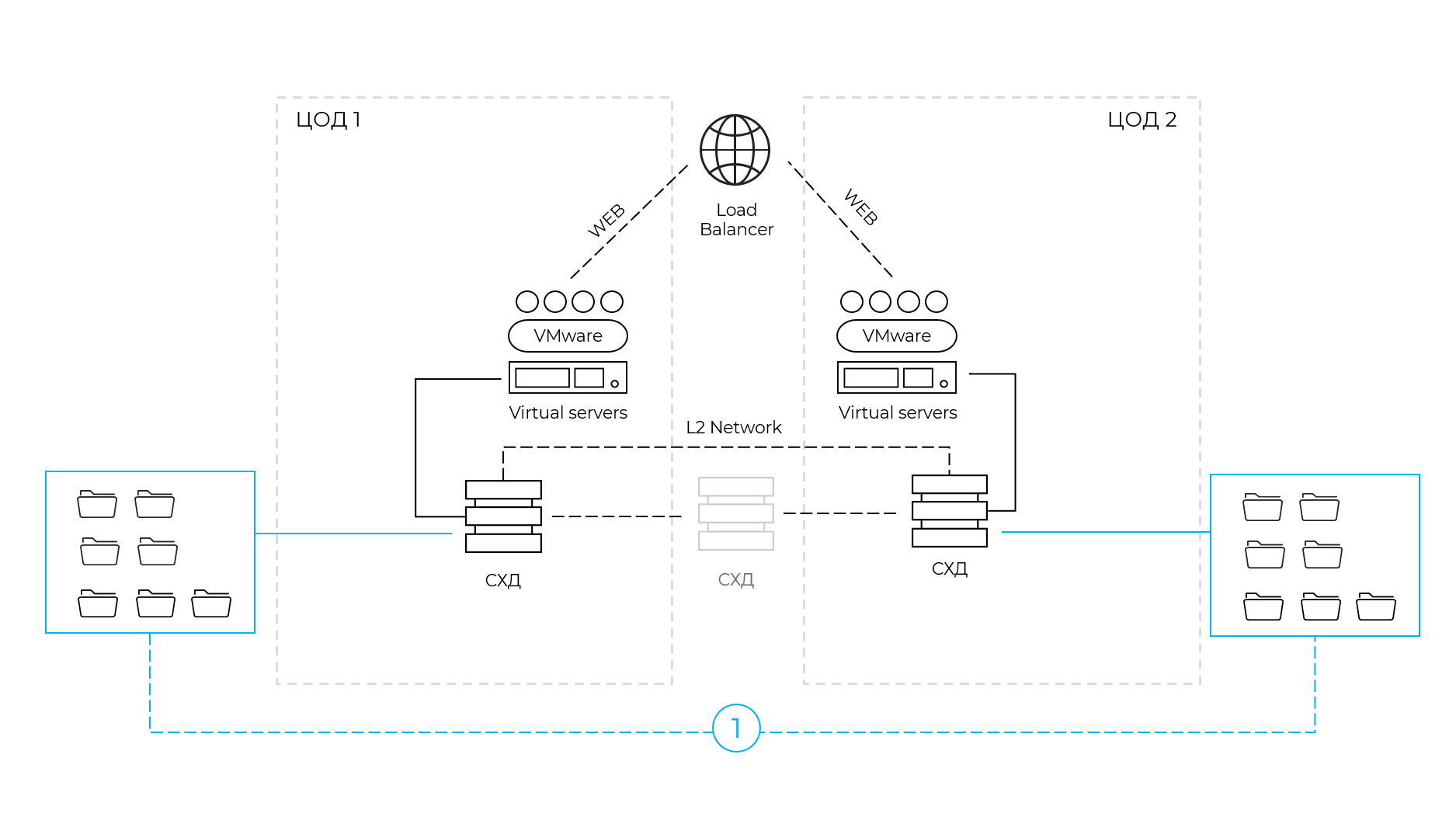
Если инфраструктура содержит СУБД, то ее копии на двух площадках должны быть синхронизированы мгновенно. Расхождений не должно быть вообще. Подобный опыт широко применяется в банковской сфере, когда транзакция записывается сразу в 2 местах. Синхронно. И если где-то запись не произошла, отчета об успешной операции не будет.
Большие и дорогие СУБД умеют строить такой кластер и гарантировать запись на две распределенные площадки. Например, СУБД в ЦОД1 записывает данные и тут же отдает их в СУБД2. Вторая записывает и подтверждает, что транзакция сделана, рапортует в ЦОД1. И только теперь первая СУБД подтверждает факт записи.
Однако сегодня мы активно идем в сторону импортозамещения, организации все чаще используют PostgreSQL, MongoDB и прочие СУБД, для которых подобную запись не так уж просто реализовать.
Поэтому мы пришли к схеме, когда высочайшие гарантии доступности можно предоставить на уровне СХД. Происходит запись на диск, и система обеспечивает идентичное состояние накопителя на другой стороне. При таком раскладе контроллеры договариваются друг с другом и синхронная репликация происходит действительно очень быстро.

Задержка составляет примерно 2 мс на 100 км. И чтобы гарантировать этот уровень у нас, например, есть канал 40 Гбит/с между двумя ЦОД. В результате синхронизации операция занимает не 1 мс, а 3 мс, но для большинства задач это абсолютно приемлемо. А для тех приложений, которые не готовы работать в кластере и внутренними механизмами обеспечивать репликацию в реальном времени, такой метро-кластер — настоящее спасение.
Заключение
Чтобы реализовать комплексную защиту для всей инфраструктуры разумно применять все 3 или хотя бы 2 из 3 подходов. Поэтому при подключении облачного DR нужно составить перечень всех систем, классифицировать их и расставить приоритеты, а дальше — активировать репликацию нужного уровня, предварительно проверив, что в случае аварийного включения все будет работать хорошо
При этом стоит следить за архитектурой и состоянием резервных копий/мощностей или выбирать сервисы, которые готовы гарантировать консистентность архивов, готовность второй площадки моментально принять нагрузку на себя, соответствие сетевой адресации и так далее.
Учитывая что в жизни есть непрогнозируемые факторы, начиная с банального отсутствия электричества, поломок систем охлаждения. обрывов оптики и так далее, свою систему аварийного восстановления необходимо регулярно проверять и тренировать. Ведь в конечном счете страшна не только потеря данных (хотя она страшна), но также затянутое время восстановления как самой информации, так и сервисов, репутационные риски и неприятности в общении с регуляторами. И нам приходится постоянно думать об этом — причем не только за себя, но и за тех, кто заказывает подобный сервис.
Mudrist
Люблю ваши веселые картинки. :)