
Как хранить результаты нагрузочных тестов так, чтобы работать с ними было удобно? Если команда нагрузки сталкивается с такой проблемой, то возникает необходимость хранения данных. В частности, требуется, чтобы они сразу соответствовали фильтрам, а также чтобы приходилось реже выполнять сложные агрегатные функции и получать результаты быстрее.
Меня зовут Вячеслав Смирнов, я ускоряю и тестирую инфраструктурные сервисы в Miro. Ещё я развиваю сообщество нагрузочников @qa_load в telegram: делюсь там кое-какой экспертизой. В частности, если выполнять тесты производительности регулярно, по несколько раз в день, то вскоре в популярном хранилище тестов InfluxDB фильтровать результаты тестов производительности становится сложно. Сегодня я расскажу про 12 шагов, как можно ускорить InfluxDB. Основным из них является ускорение с помощью nginx кэширования. Пример использования кэширующего nginx, в качестве источника данных для Grafana можно найти тут. Все остальные примеры, которые мы будем разбирать я вынес сюда. А слайды оставил здесь.
")
1. Когда оптимизация InfluxDB важна
Оптимизация важна, если у вас большой продукт. Глазами нагрузочника, это не продукт, в котором много кода, а тот, который написали вместе. Например, 30 команд, включая фронтовиков, бэкендеров и прочих. При этом команда нагрузки лишь одна из них, которая отвечает за инфраструктуру тестирования.
Она обслуживает все запросы остальных команд. А фичовые команды имеют разные предпочтения: кто-то хочет использовать JMeter, кто-то Gatling или k6. Кроме того, как правило, все эти команды хотят сохранять свои метрики. Причём сохранять метрики хотят долго, например, для всех своих версий, чтобы смотреть тренды производительности: деградирование или улучшение.
В этом случае, если выбирать не энтерпрайзное решение, в котором свои способы улучшения, и не InfluxDB Cloud, а опенсорсное решение v1.8 или v2.2, то полезно выполнить следующие шаги, чтобы ускориться:
Поменять настройки в разных местах, выставить ограничения;
Оптимизировать запись в InfluxDB c Telegraf и MQ;
Оптимизировать выборку c Grafana и nginx;
Вычислить медленные запросы;
И закэшировать их с Continuous Queries.
2. Разделение данных на разные базы и серверы InfluxDB
В InfluxDB сложно отделить данные от индексов, в нём всё — это индекс. Поэтому самый простой способ сделать InfluxDB быстрее — просто поделить индексы. Рассмотрим несколько способов, как это сделать.
Разные базы данных для команд и стендов
Первый способ — сделать разные базы данных для команд и стендов
Представим, что вашу базу данных, ваш гигантский индекс пишет 7 разных команд, а потом каждый из них выбирает и строит свои метрики. Вы можете им предложить писать также, как писали, но только использовать 7 баз данных. Это супер ускорит метрики.
Дело в том, что когда баз данных несколько, проще делать бэкапы, сложнее угробить всё хранилище сразу, и в принципе всё работает быстрее.

Разные сервисы данных на новые и архивные
Следующий способ разделения — разные серверы для новых и архивных данных. Можно делить не только на команды, но и на старый медленный архив (то, что в прошлом) и на сервер с новенькими свежими данными.
Можно пойти дальше и разделить сервер со свежими данными на несколько серверов. Например, в один сервер будут писать три команды, в другой — ещё две.
Контейнеры vs InfluxDB
Когда база данных одна, очень легко сделать аналитику, например, получить среднее время отклика по всем тестам, которые есть.
Однако, если у вас куча данных и они ещё делятся на новые и архивные, то такое сделать сложно.
Тесты показывают, что 7 Docker-контейнеров работают быстрее, чем один InfluxDB, в котором 7 баз данных. Потому что Docker тратит все ресурсы на один контейнер пока остальные спят. Так получается круче.
3. «Архивирование» медленной базы InfluxDB в Grafana
Как сделать так, чтобы пользователи, которые пользуются вашим InfluxDB, не увидели, что вы его поделили под капотом? Я назвал это «архивированием».
Если вы работаете в Grafana, то есть два варианта, как можно это сделать:
Первый путь: в каждую панельку, в каждый запрос захардкодить имя источника данных, откуда данные выбираются;
Второй вариант: создать переменную с типом source, в которой хранится источник данных. Этот подход делает из Grafana витрину для данных, в которой можно выбрать источник.
И если мы выбираем второй вариант, то тут появляется:

Представим, что у вас есть некий DataSource, который называется JMeter. Год назад он работал со старым источником данных (old DB), а сейчас вы создали новую быструю версию new DB. В таком, случае можно в Grafana сказать: «Так, JMeter, ты теперь смотришь на новую версию, а я создал DataSource типа JMeter-2022 года (архив метрик до 2022 года), который будет смотреть на старую версию».

Таким образом, вы ничего не будете терять. Пользователи, как работали с JMeter, так и работают, просто теперь есть более быстрая версия вашего решения.
4. Сокращение фильтров по тегам в Grafana
В Grafana можно сократить количество запросов, если скрыть некоторые панельки в строчки. Например, здесь 5 строчек скрыты:

Всё, что я не вижу — это не запросы, а просто HTML.
Но что нельзя скрыть? Нельзя скрыть верхнюю строчку с переменными для фильтров. Поэтому если у вас вдруг на доске 70 фильтров, то это перебор. Сделайте, например, 6, остальные лучше убрать, потому что их никак не скрыть, они постоянно выполняются.
Ещё один трюк с фильтрами:

Если у вас мало фильтров, но в одном фильтре выдаётся тысяча значений, то не делайте Query, который выбирает эту тысячу значений. Вместо этого сделайте текстовый фильтр, в который вы зададите регулярку. Это подходит к VictoriaMetrics, Prometheus, ClickHouse, InfluxDB и ускоряет практически все выборки. Иначе, Grafana будет тормозить на фильтре, в котором 20 тысяч значений, так как ей сложно такой большой json, список и структуру поддерживать. Текстовые фильтры решают эту проблему.
5. Сокращение объёма метрик
Другой способ — вообще вставлять чего-либо поменьше. Разберём как это сделать на примере с Gatling. Вот его настройки по умолчанию:

Тут совсем не включена отправка в Graphite, а у Graphite выставлено, что по умолчанию нужно писать метрики каждую секунду. Что можно с этим сделать?

Можно чуть-чуть уплотнить эти метрики и, например, писать в Graphite каждые 60 секунд с максимальным размером кадра стека (для TCP это 64 КБ). Это ускорит, потому что Influx’у, Graphite’у и всем этим источникам выгоднее, чтобы к ним сразу прислали побольше данных, но пореже.
Более того, можно вообще присылать без деталей и по UDP (с возможными потерями).

Ведь на самом деле для того, чтобы провести аналитику, не нужно в каждый момент времени, прямо во время запуска теста, видеть время отклика по конкретному endpoint. Это можно сделать потом, даже если с потерями.
Дело в том, что если InfluxDB зависает, то все инструменты в TCP будут делать retry, например, посылать TCP-пакет 5-10 раз. А так как источник данных уже завис, ситуация только усугубится. В UDP такой проблемы нет.
Аналогично с JMeter:

Тут очередь запросов размером в 5000. Я рекомендую сделать примерно такую математику:

Пусть в нашем тесте 1200 rps, нам нужно слать метрики один раз в 60 с. Для этого чуть-чуть меняем настройки, например, говорим, что наше окно теперь не 5000 очередь, а 72000 (1200 х 60 с). Далее выбираем один из вариантов: fixed или timed. Они отличаются только тем, что timed после отправки полностью очищает набор собранных метрик, а fixed постоянно хранит эту очередь, добавляет в конец новые значения и удаляет старые. На мой взгляд, это лишние действия, которые не нужны.
Ещё один момент со стороны тестов:

Если записывать результаты тестов по каждому ID и параметру, то в результате получится гигантский индекс. В нём может быть вообще миллион значений. Он будет тяжёлым и медленным. В итоге получится таймаут, появятся какие-то лимиты, в которые вы упрётесь и ничего с ними не сделаете.
Способ ускорения InfluxDB в данном случае: не использовать переменные в имени запроса, но лишь обозначить, что в определённом месте будет такая-то переменная. Таким образом вы получите всего лишь одно значение, а значит и маленький индекс.

Также, если вы записываете всю статистику и все метрики в хранилище, чтобы потом отдельно открыть график по каждой странице и посмотреть, то после каждого теста вы, очевидно, тратите много времени на работу с графиками, стремитесь к высокой точности метрик, чтобы ещё больше времени тратить на их анализ. И так пока хранилище метрик не начнёт тормозить. Но если мы поставим SLA в сам тест, то есть assertion на время загрузки, то вы можете оценивать производительность вашей системы во время теста просто по количеству ошибок. Например, мы превысили SLA на 5%, тогда у вас будет 5% ошибок, с которыми вы столкнётесь.
Можно расставить assertion и для JMeter и Gatling:
6. Кэширование ответов от InfluxDB с nginx
Когда мы работаем с InfluxDB, обычно присутствуют два элемента: Grafana и InfluxDB.
В этом случае, если что-то начинает тормозить, то тормозит всё и у всех. Поэтому в эту связку полезно добавить третий элемент — nginx, который ускоряет работу в определённых обстоятельствах.

Что это за обстоятельства? Допустим, прошёл тест и команда из 3 человек строит отчёт по результатам. У всех троих он тормозит, никто не доволен. Но если добавить nginx в эту схему, то тормозить будет только у одного (у того, кто самый первый его открыл), а у остальных всё сработает очень быстро. При этом InfluxDB разгрузится и сработает быстрее, чем до этого.
В чём дело?

В InfluxDB v1.8 есть несколько endpoints. Но те из них, которые отвечают за выборку данных в /query, работают с методами GET и POST. Их можно кэшировать.
Метод GET используется для запросов SELECT и SHOW TAG VALUES, а POST — для всяких ALTER, CREATE, DELETE. Однако в Grafana-доске нет запросов к InfluxDB с использованием ALTER или DELETE. Получается, что 99,9999% — это все запросы на SELECT и SHOW из Grafana, а это именно то, что можно кэшировать. Поэтому мы можем создать nginx Docker-контейнер с несложным конфигом:

Тут ключевые строчки — это proxy_pass и proxy_cache. Всё остальные можно оставить со значением по умолчанию, но они тоже нужны.
Если перенастроить Grafana DataSource, чтобы он смотрел не на InfluxDB, а на nginx, то всё ускорится. Каким образом настроить конфиг — можно найти тут. Кроме этого, есть пример настройки DataSource:

Очень важно в этой схеме сделать так, чтобы Grafana-доска использовала абсолютный, а не относительный интервал времени, как, например, последние 6 или 24 часа.

Почему? Потому что относительный интервал постоянно меняется каждую миллисекунду, и кэширование не будет работать, так как это уже новый URL.
Для этого я рекомендую в каждую Grafana-доску с InfluxDB добавить текстовую HTML-панель (она есть в Grafana, это не запрос к DataSource, а просто статический HTML). И вписать туда ссылку, при клике на которую вы будете получать статические интервалы с копированием всех переменных. Он уже будет кэшироваться.
Вот ссылка на доску Grafana со статическим интервалом:

/d/${__dashboard}/?from=${__from}&to=${__to}&${db:queryparam}
При отображении на доске она будет заменена. Например, на это, что уже можно кэшировать. В отличие от этой ссылки, где now-30m&to=now будет каждую мсек менять своё фактическое значение при отправке запроса на обновление отображаемых данных
7. Мониторинг производительности InfluxDB
По мониторингу у меня два момента:

Первое — это процессор и память. Чем они интересны?
Количество ядер, задействованных в CPU — это примерное количество одновременно выполняемых запросов на InfluxDB. Например, 2 параллельных запроса — это 2 ядра CPU в сотку.
Объём памяти (RAM) — это примерно объём задействованных shards из вашего индекса.
Что такое вообще shard? Shard — часть индекса, например, за 1 час. Когда вы создаёте базу данных, ваш запрос на InfluxDB выглядит примерно так:
CREATE DATABASE "JMeter"
WITH DURATION INF REPLICATION 1
SHARD DURATION 1h NAME "autogen";
А теперь как это все померить? Это и есть второй момент: у InfluxDB есть ещё внутренние метрики. Их так много (около 200), что новичку в них сложно разобраться. Поэтому я выделил всего три внутренние метрики из всего этого многообразия:
shard : path : size : размеры индексов;
database : numSeries : количество значений тегов;
httpd : интенсивность (количество и длительность) запросов.
Размер файлика, когда он загружается в память — примерно самая критичная метрика в InfluxDB. Дело в том, что если памяти не хватает, то InfluxDB просто перезапускается и всё пересчитывает по новой.
Выглядит это так:

Вы делаете несложный запрос. Метрика там называется diskBytes. Это самая важная метрика. При этом на диске данный shard может быть 300 МБ, а в памяти под 2 ГБ. Название метрики тут не несёт смысла.
Поэтому если вы видите, что shards разрослись, то вам нужно добавить память или грохнуть эти shards, потому что у вас может не быть 140 ГБ оперативной памяти на слабеньком Docker-контейнере.
Следующая важная метрика — это количество уникальных значений тегов:

Третья метрика — это количество конкурентных запросов, которая позволяет примерно оценить, сколько CPU вам понадобится:

В данном случае мне всегда нужны либо 0, либо 1 ядро.
8. Конфигурирование сервера InfluxDB
Как только мы получили данные мониторинга, их можно законфигурировать. Предлагаю сделать это для небольшого количества метрик.
Первая из них — это количество конкурентных запросов:
Обычно на сервере с InfluxDB нет 140 ядер, поэтому стоит выставить какое-то адекватное ограничение. Например, max-concurrent-queries = 5.
Что касается длительности выполнения запросов, поделюсь с вами своей внутренней эвристикой:
Когда запрос в InfluxDB зависает, то каждую секунду он аллоцирует примерно 100 МБ оперативной памяти. Получается примерно такой расчет: если на сервере 6000 МБ оперативки, то можно зависнуть на гипотетическом одном запросе примерно на 60s, а дальше память всё равно кончится. Если же взять 5 конкурентных запросов для тех же 6000 МБ оперативки, то 60s надо ещё поделить на 5.
Если у вас слишком длинный запрос, то вы получите не очень говорящую ошибку: query-timeout limit exceeded.

Ещё можно ограничить максимальное количество тегов ответа:

Это как произведение размера в одном теге на размер другого тега. Выглядит это ограничение так: max-select-series = 10100. Если вы превысите, то получите ошибку max-select-series limit exceeded.
Есть ещё важный момент касательно количества точек при группировке по времени. К примеру, я обладатель монитора с шириной 1920 точек. Поэтому даже если мне InfluxDB вернёт 20 тысяч точек, чтобы я их отобразил на графике, то Grafana не сможет это сделать, потому что есть физическое ограничение моего монитора. Так зачем же мне вообще возвращать группировку больше, чем 1920 точек? Незачем.
В данном запросе у меня вообще вернётся 11-12 точек, так как я группирую 10 минут по 1 минуте:

Поэтому разумно выставить ограничение max-select-buckets = 1920.
Если вдруг я выполню запрос за 10 минут с группировкой по 1 мс, то получу exception:

Ну и правильно! Надо сделать группировку побольше.
Ещё совет: если вы всё-таки хотите хранить гигабайты значений и не упираться ни во что, то можете перейти с быстрого индекса inmem на медленный индекс tsi1, используя index-version:
Самое последнее — можно установить порог, после которого текст вашего запроса попадёт в лог. Я лично выставляю 2 секунды: log-queries-after = "2s".

9. Анализ логов InfluxDB
Если у нас что-то залогируется, то мы в самой последней строчке этого лога увидим, что в базе данных jmeter10000 что-то идёт не так:

Если вы видите такие сообщения в логе, то только по одному логу понять, что тут не так, сложно. Но просто понять, что работа с базой данных jmeter10000 медленная.
10. Замер длительности ответа на запрос из Grafana в InfluxDB
Как рекомендация от человека, который видел это много раз, следующим шагом стоит сделать следующее. Вы идёте в DataSource с этой базой данных в Grafana и говорите: «Дай-ка я тебя чуть-чуть подтюню», то есть сделаю лучше: добавлю Access Browser и HTTP метод POST.
Так как вы используете POST, у вас в теле запроса есть структурированное тело запроса без URL-encoding, длинной строчки, всяких %20 и прочей красоты, которую вы должны декодировать в голове. Поэтому вы просто открываете web-консоль в доске Grafana с этим DataSource и смотрите какая там длительность и текст запросов, чтобы если что улучшить. Например, у вас есть запрос, который считает среднее время с группировкой по всему тесту:

Этот запрос тормозит. Его можно улучшить кэшированием ответа на него в самой базе данных. Для этого можно создать аналогию индекса через Continuous Queries.
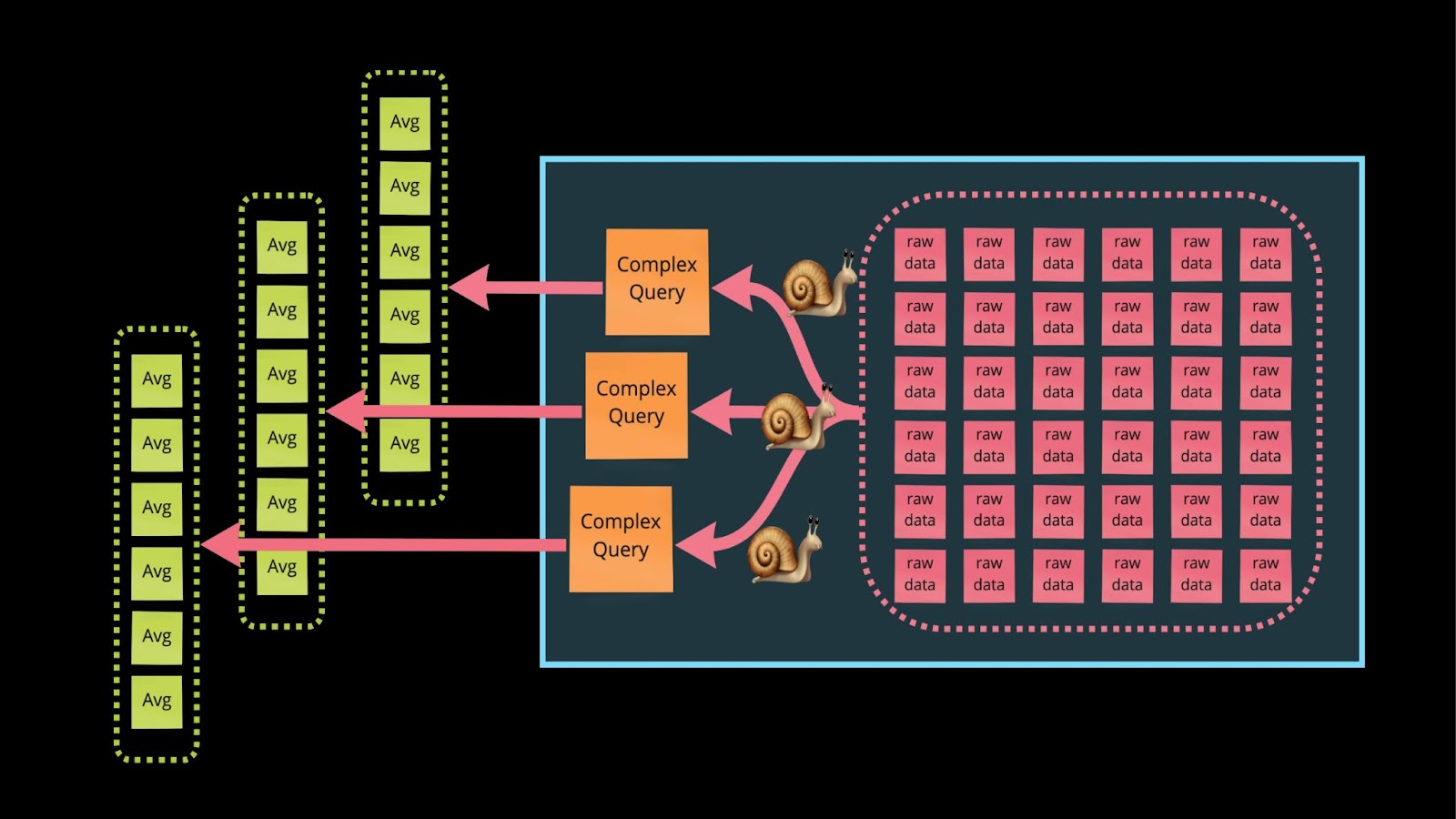
Что такое Continuous Queries? Представим, что команда из трёх человек навалилась на задачу и считает среднее время ответов по всем 6 тестам, которые они сделали за всю историю запусков. Они получают ответы и InfluxDB напрягается. Continuous Queries позволит им закэшировать ответ, чтобы он был дан на запрос в будущем.
11. Подготовка данных для ответа с помощью Continuous Queries
Разберём на примере:

В данном случае ключевой строкой является №3:
RESAMPLE EVERY 10m FOR 1d
Она означает, что InfluxDB каждые 10 минут в один поток будет выполнять группирующий запрос и обновлять в нём же самом ответ.

В одном проекте, где мне надо было сделать гигантскую аналитику, такой способ ускорил работу в разы.
Мой изначальный запрос выглядел так:

После изменения он стал простым: без всяких фильтров, сложных группировок или агрегатных функций. Он просто берёт последнее значение из заранее приготовленного архива или предрасчёта. Это называется Retention Policy — очень далёкий аналог названия индексов в InfluxDB.
12. Смена БД InflfluxDB v1.8, InflfluxDB v2, VictoriaMetrics или ClickHouse
Если ни один способ вам не понравился, вы можете перейти на альтернативные технологии:
— InfluxDB v2.2;
В нём есть новый быстрый движок. Кроме этого теперь все новые прикольные фичи имплементируются именно там, а InfluxDB v1.8 теперь на поддержке. В этой новой версии есть HTTP GET метод и /query, оставленный для обратной совместимости. Поэтому закэшировать работу можно так же как и в InfluxDB 1.8, то есть с помощью nginx.
— VictoriaMetrics;
VictoriaMetrics кэширует ответы, жмёт метрики и по-другому хранит перцентили в bucket’ах. У неё есть свои приколы и хорошая документация. Это как сжатый Prometheus со своими плюсами.
— ClickHouse.
Быстр (при наличии памяти) и удобен. Также, как Victoria, жмёт метрики. Для него есть свои оптимизации.
Но! Разгонный потенциал InfluxDB v1.8 огромен. Несмотря на то, что в нём самые старые технологии: REST вместо TCP, тем не менее эти REST с помощью «тут подкрутил, там настроил» хорошо конфигурируются, что позволяет за половину дня ускорить работу системы в 1000-10000 раз.
ИТОГО
Я рассказал 12 шагов, как подойти к ускорению и хранению ваших метрик:
Когда оптимизация InfluxDB важна;
Разделение данных на разные базы и серверы InfluxDB;
«Архивирование» медленной базы InfluxDB в Grafana;
Сокращение фильтров по тегам в Grafana;
Сокращение объёма метрик;
Кэширование ответов от InfluxDB с nginx;
Мониторинг производительности InfluxDB;
Конфигурирование сервера InfluxDB;
Анализ логов InfluxDB;
Замер длительности ответа на запрос из Grafana в InfluxDB;
Подготовка данных для ответа с помощью Continuous Queries;
Смена БД InfluxDB v1.8, InfluxDB v2, VictoriaMetrics или ClickHouse.
Резюмируются они в три тезиса:
Делите ваши большие индексы на маленькие;
Кэшируйте всё, что можно: ответы в Influx, ответы на nginx;
Ускоряйте всё это дело с помощью настроек или удалением чего-то.
На предстоящей конференции HighLoad++ 24 и 25 ноября будет доклад по тестированию от разработчика в Tarantool. Можно будет узнать много полезного о фаззинге. Причем простым языком и с примерами на Lua.